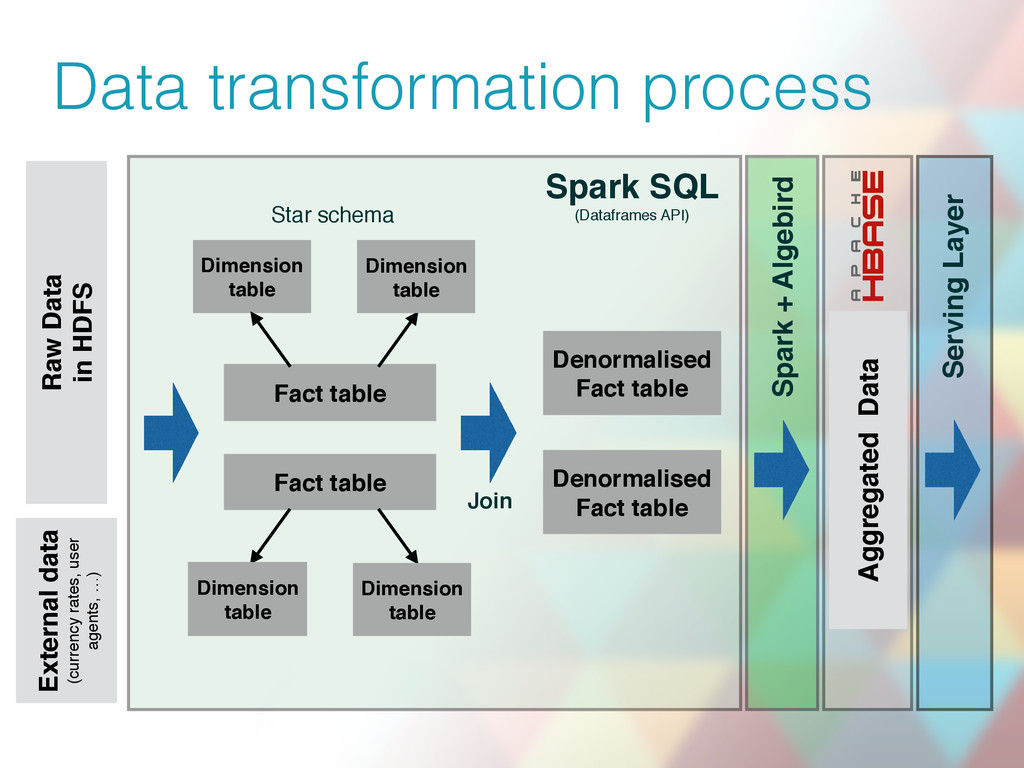
Vinted is an online lifestyle marketplace and a social network geared towards young women. We currently have 10 million members and we process and analyze up to 1 billion events daily. To overcome the limitations imposed by the implementation of our initial analytics solution based on MySQL, we evaluated Hive, Impala and Scalding, finally arriving at a solution built on Spark, Kafka and HBase.
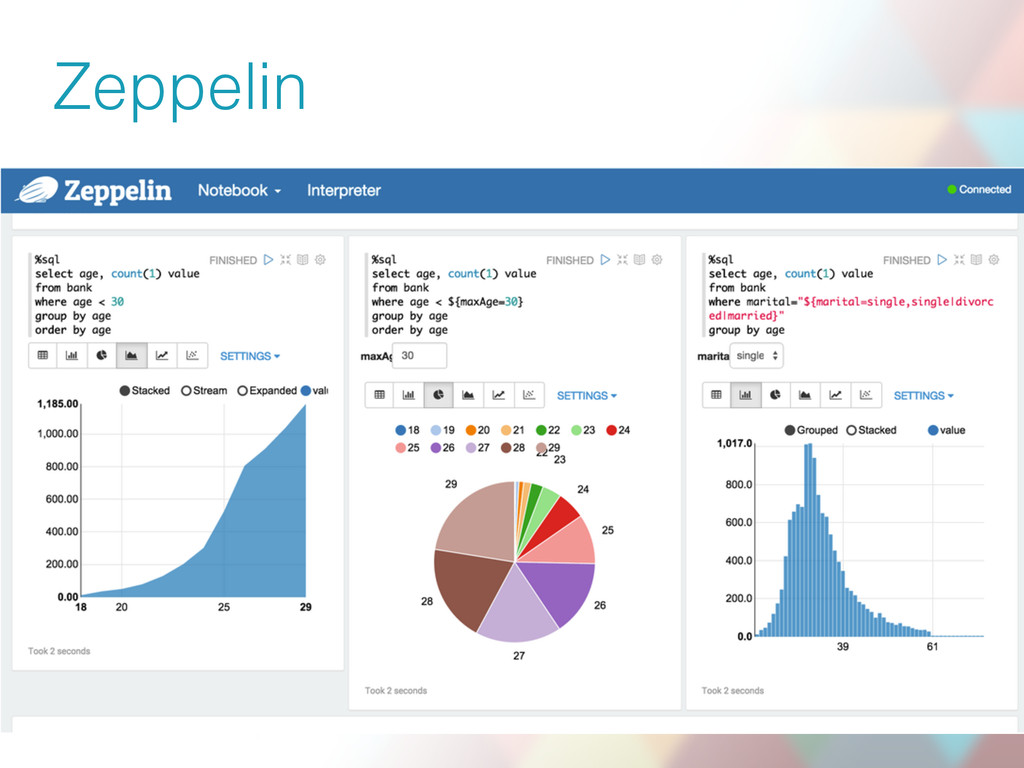
This is a lessons-learnt talk about our bumpy road to Big Data analytics on the Hadoop platform. We will cover our Kafka-based data ingestion pipeline, fact table preparation, data aggregation and talk about how all of this leads to a sub-second slicing of pre-aggregated data cubes. In addition, we will mention how our pipeline is reused for ad-hoc data analysis with the help of interactive notebooks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
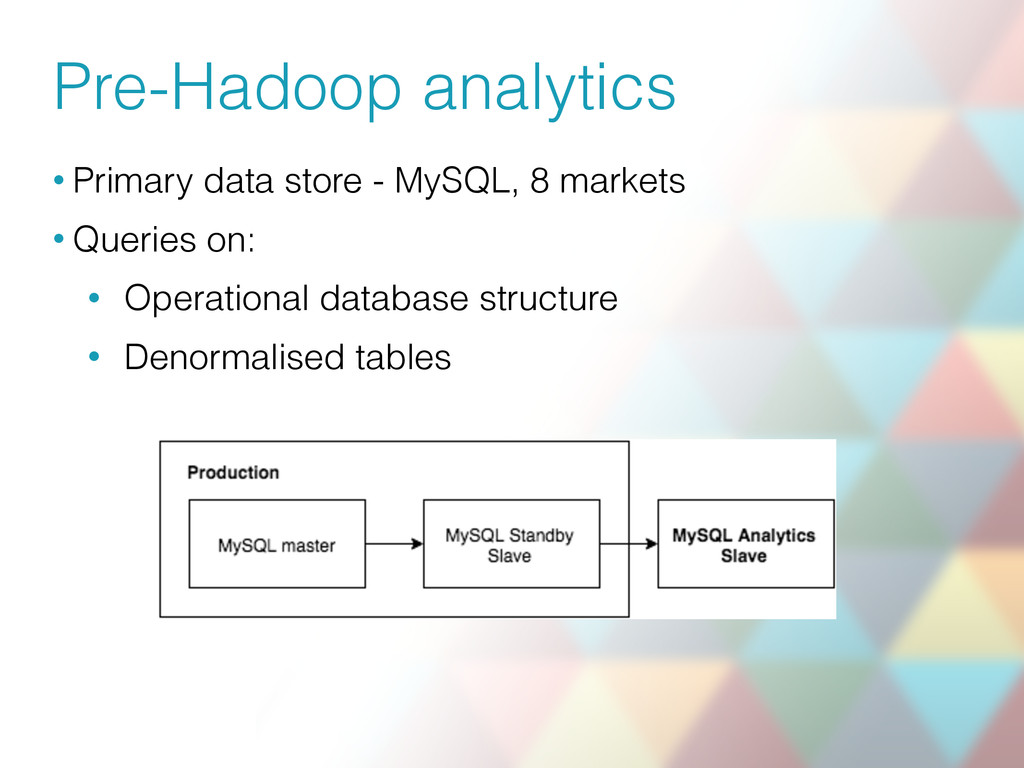{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
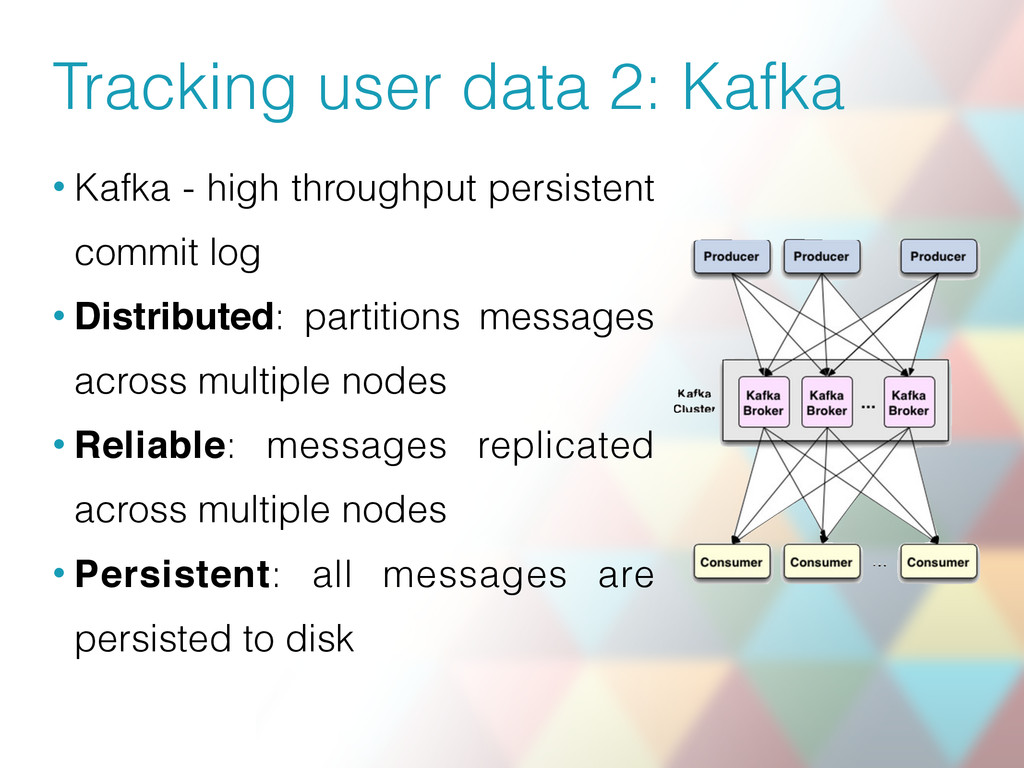{kind=link}
{kind=link}
{kind=link}
{kind=link}
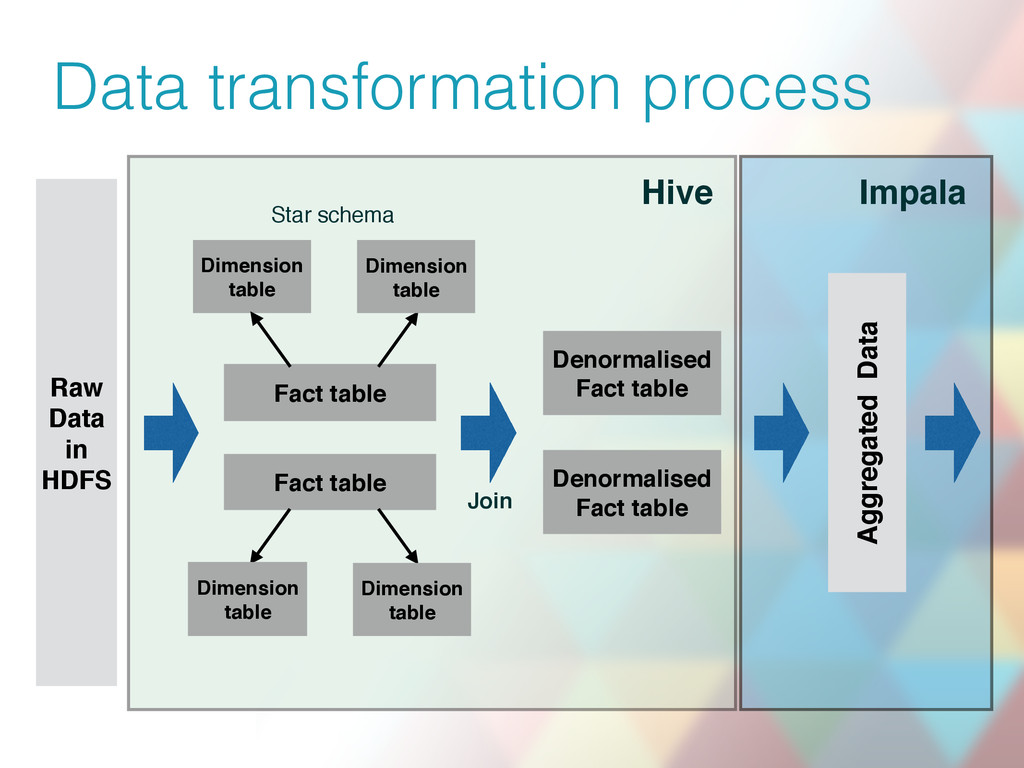{kind=link}
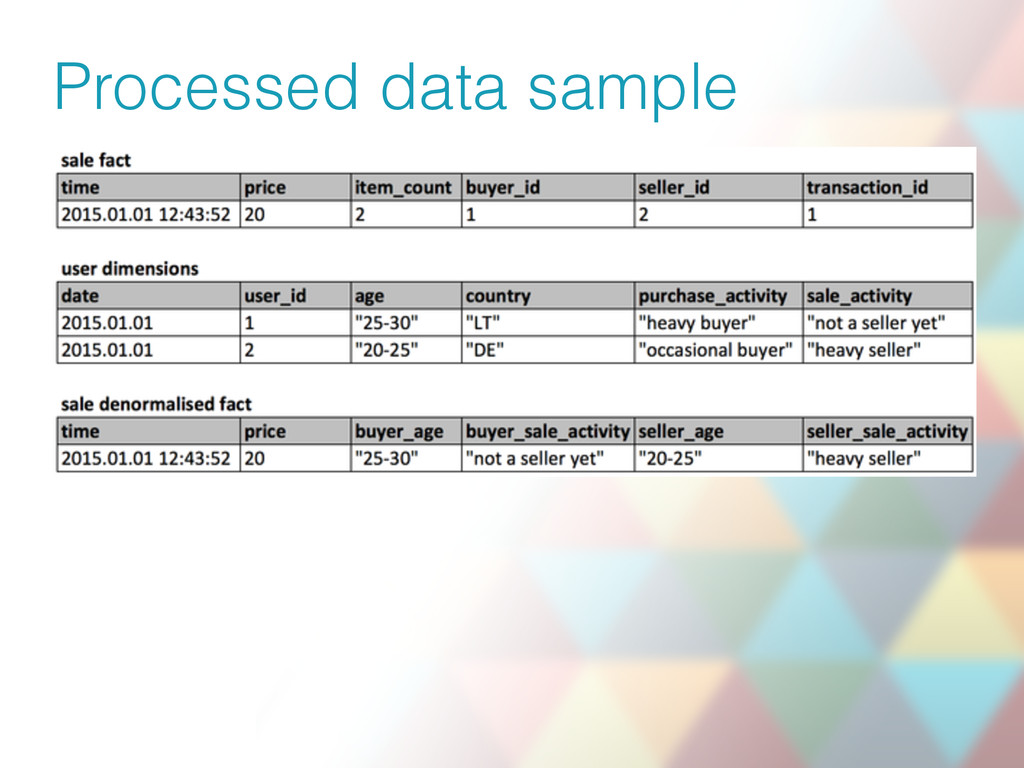{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Our data ingestion helpers def readCoreTables( name: String, portals: List[String],](https://files.speakerdeck.com/presentations/36ee96ca52164bd79013383af18f605e/slide_30.jpg){kind=link}
![Custom functionality def seqContains = udf((seq: Seq[String], elem: String) =>](https://files.speakerdeck.com/presentations/36ee96ca52164bd79013383af18f605e/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}