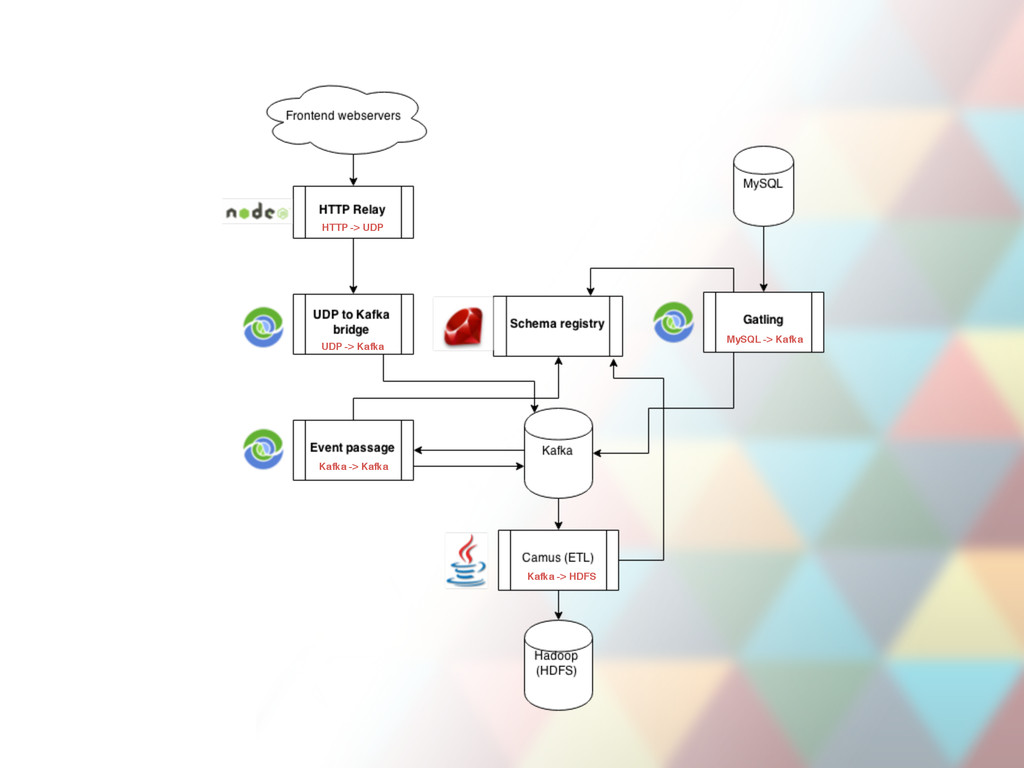
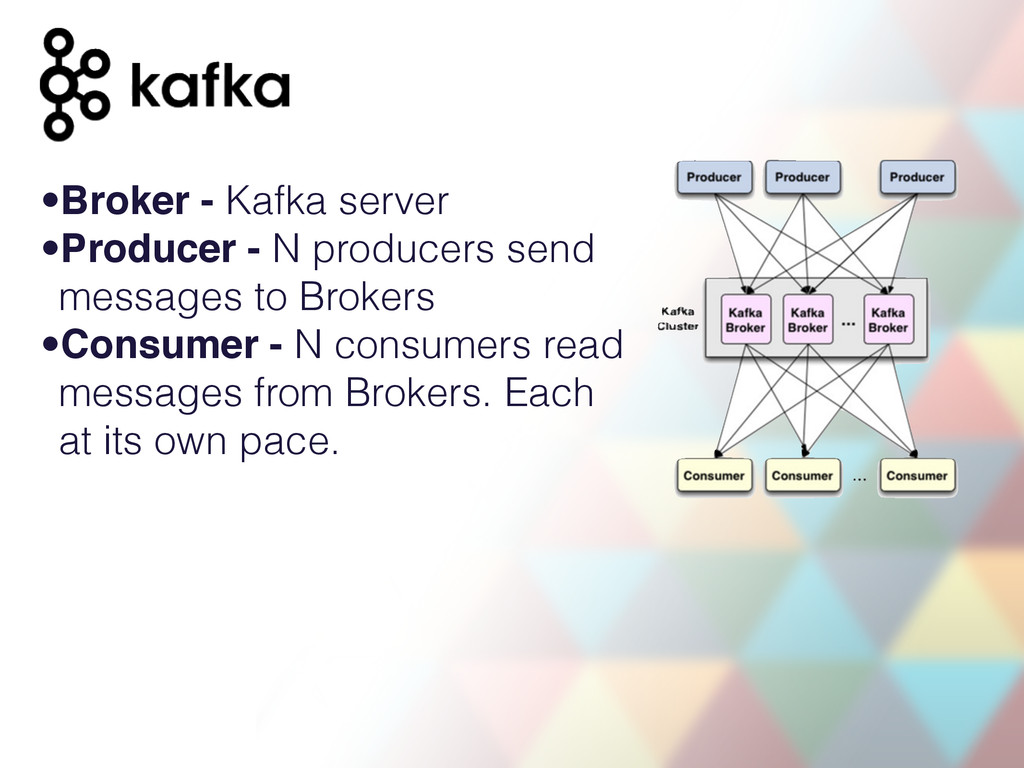
multiple nodes •Reliable: messages replicated across multiple nodes •Persistent: all messages are persisted to disk •Performant: works just fine with 70 000 message writes per second. Up to 700Mb/s (when replicating/rebalancing).
+ 9 hosts. • 1 service in pre-production state. • 1 service in hackathon state. • 4 people proficient at writing Clojure code. • Clojure code written using Sublime, Vim, Emacs. • ~1800 LOC, ~1500 lines of test code • Still learning
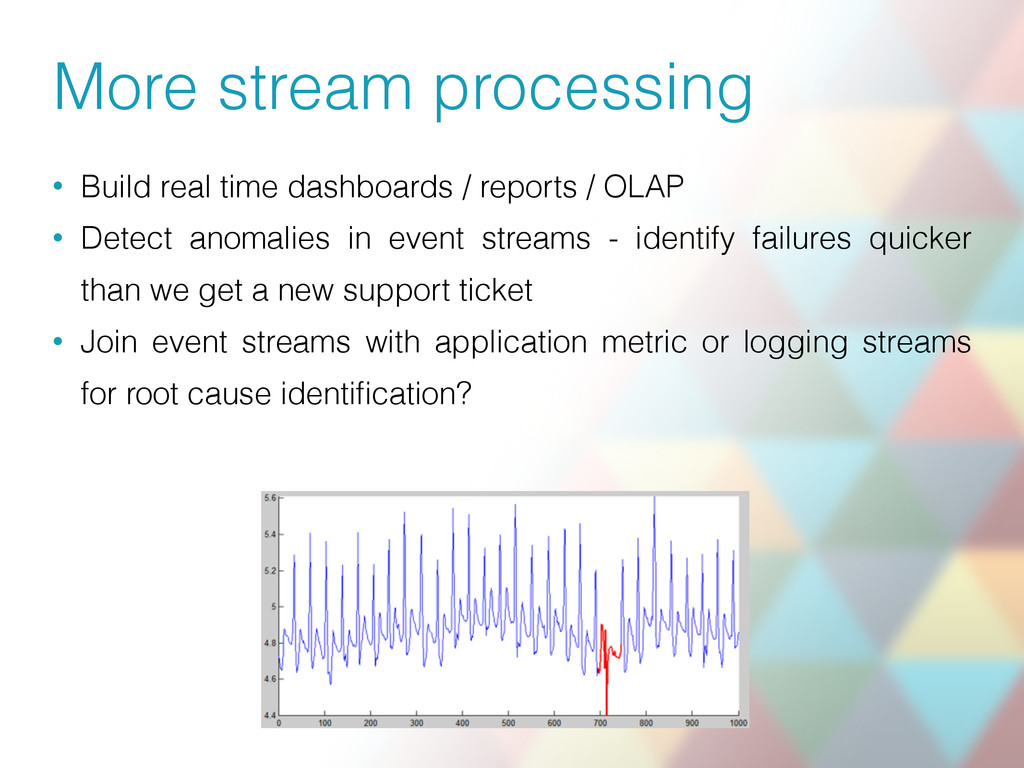
/ OLAP • Detect anomalies in event streams - identify failures quicker than we get a new support ticket • Join event streams with application metric or logging streams for root cause identification?
about real- time data's unifying abstraction • All Aboard the Databus! Linkedin’s Scalable Consistent Change Data Capture Platform • Wormhole pub/sub system: Moving data through space and time • The “Big Data” Ecosystem at LinkedIn • The Unified Logging Infrastructure for Data Analytics at Twitter • Kafka: A Distributed Messaging System for Log Processing • Building LinkedIn’s Real-time Activity Data Pipeline
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Component (defrecord Database [host port connection] ;; Implement the Lifecycle](https://files.speakerdeck.com/presentations/277cae97970647cb9797fefa687f91c8/slide_16.jpg){kind=link}
![What’s next? (def prop-sorted-first-less-than-last (prop/for-all [v (gen/not-empty (gen/vector gen/int))] (let](https://files.speakerdeck.com/presentations/277cae97970647cb9797fefa687f91c8/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
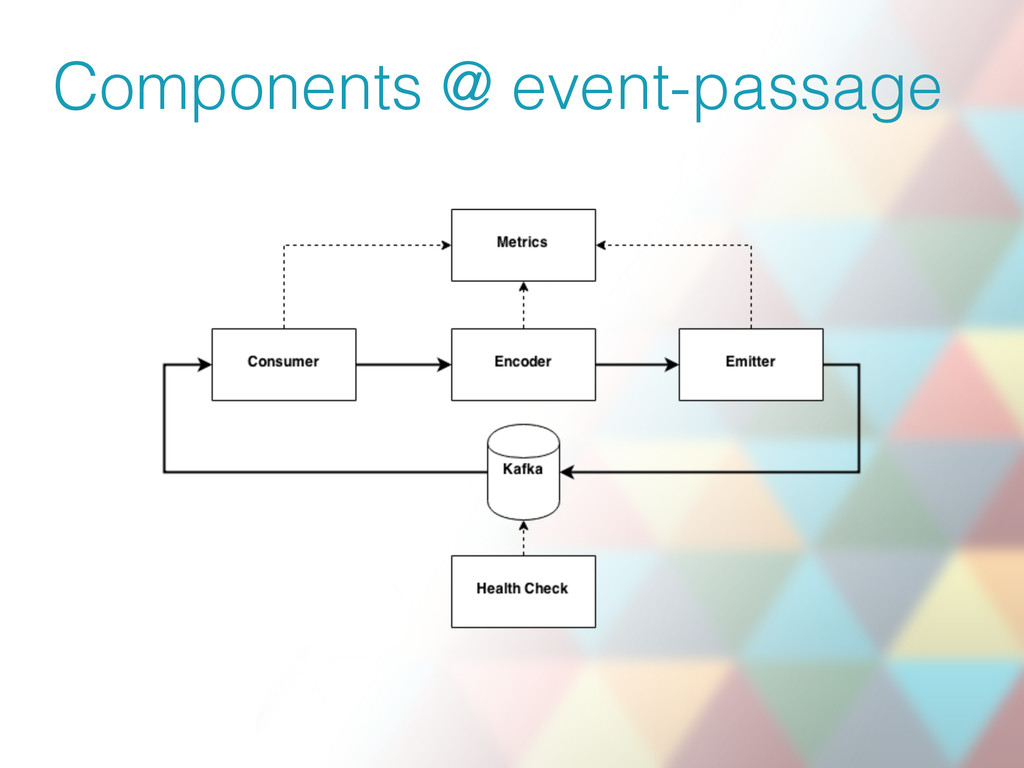{kind=link}