■AI×DevOps Study #8 の概要
2026年3月19日に開催した「AI×DevOps Study」第7回の勉強会資料です。
「AI×DevOps Study」は、AI駆動開発やそこに関係するマイクロサービスについて理解を深める場になります。
株式会社ScalarではAIを使ったチーム開発を進めており、参画しているメンバーや協力会社の方から、具体的なAI駆動開発を実施する方法、その中で生まれたマイクロサービスアーキテクチャを使用したAI駆動開発の事例や実際に使えるエージェントについてお話頂き、参加者の皆様と知識の共有や交換を目的としています。
(弊社製品であるScalarDBも絡んだお話も一部出てきますが、汎用的な内容となっておりますのでフラットにお楽しみいいただけます)
■今回のテーマ
「POSシステム開発におけるClaude Codeエージェント設計と成果物の差分検証」
複雑な要件下でのAI駆動開発において、個人のプロンプト力に依存せず、 チーム全体で高品質なコードを安定して出力するための「エージェント設計(ガードレール構築)」に焦点を当てます。
1. イントロダクションとエンジニアの役割の変化
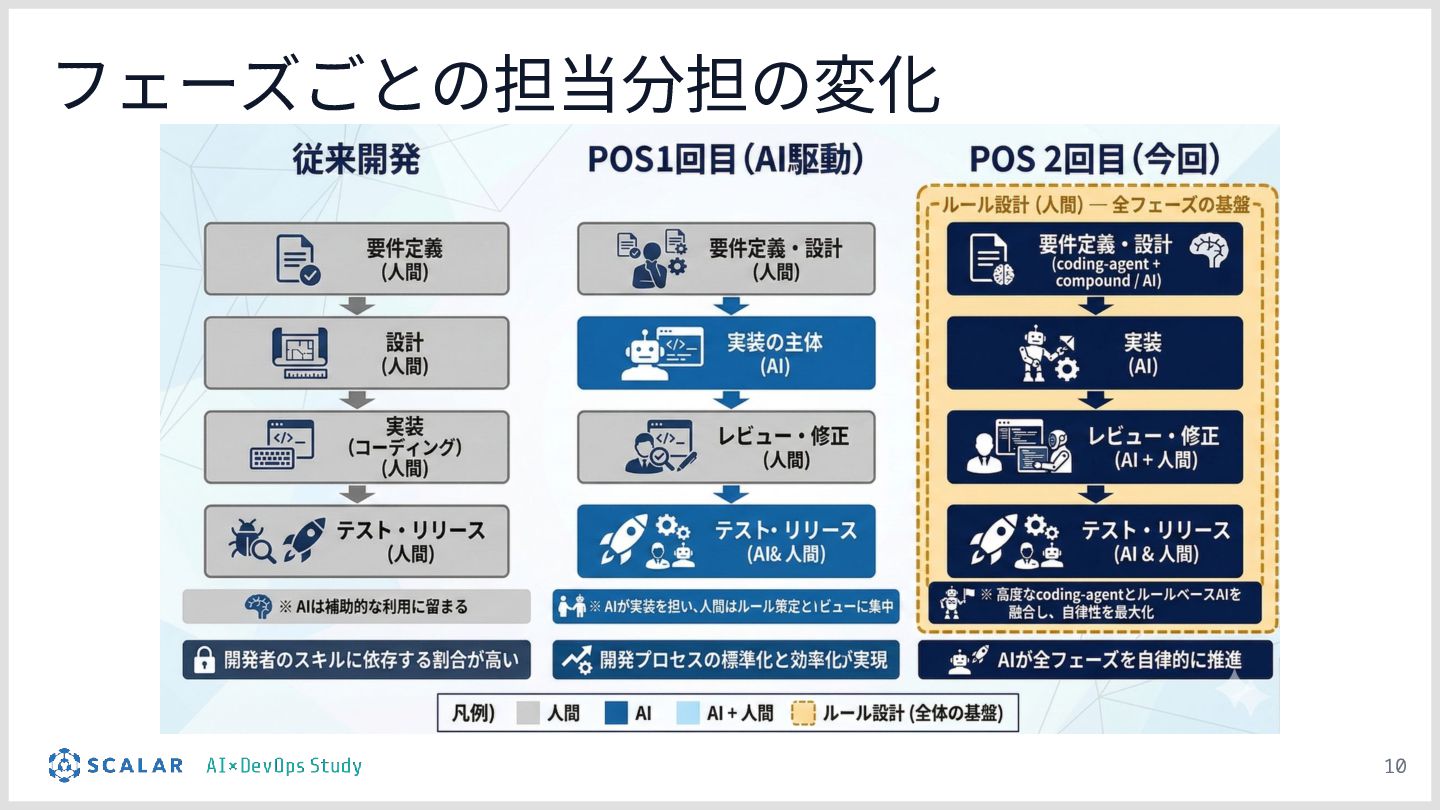
AI能力の脱・属人化:AIによるコーディングが普及する中、個人の「プロンプト力」によるアウトプット品質のバラツキが新たな課題となっています。
新しい開発スタイル:AIを単なる「実行役」とし、人間は「コンテキストとガードレールの設計」に責任を持つという、これからのエンジニアの役割のシフトと、チーム全員が一定品質を出せる仕組み作りについて提示します。
2. Vibe Codingの限界と「エージェント設計」の必要性
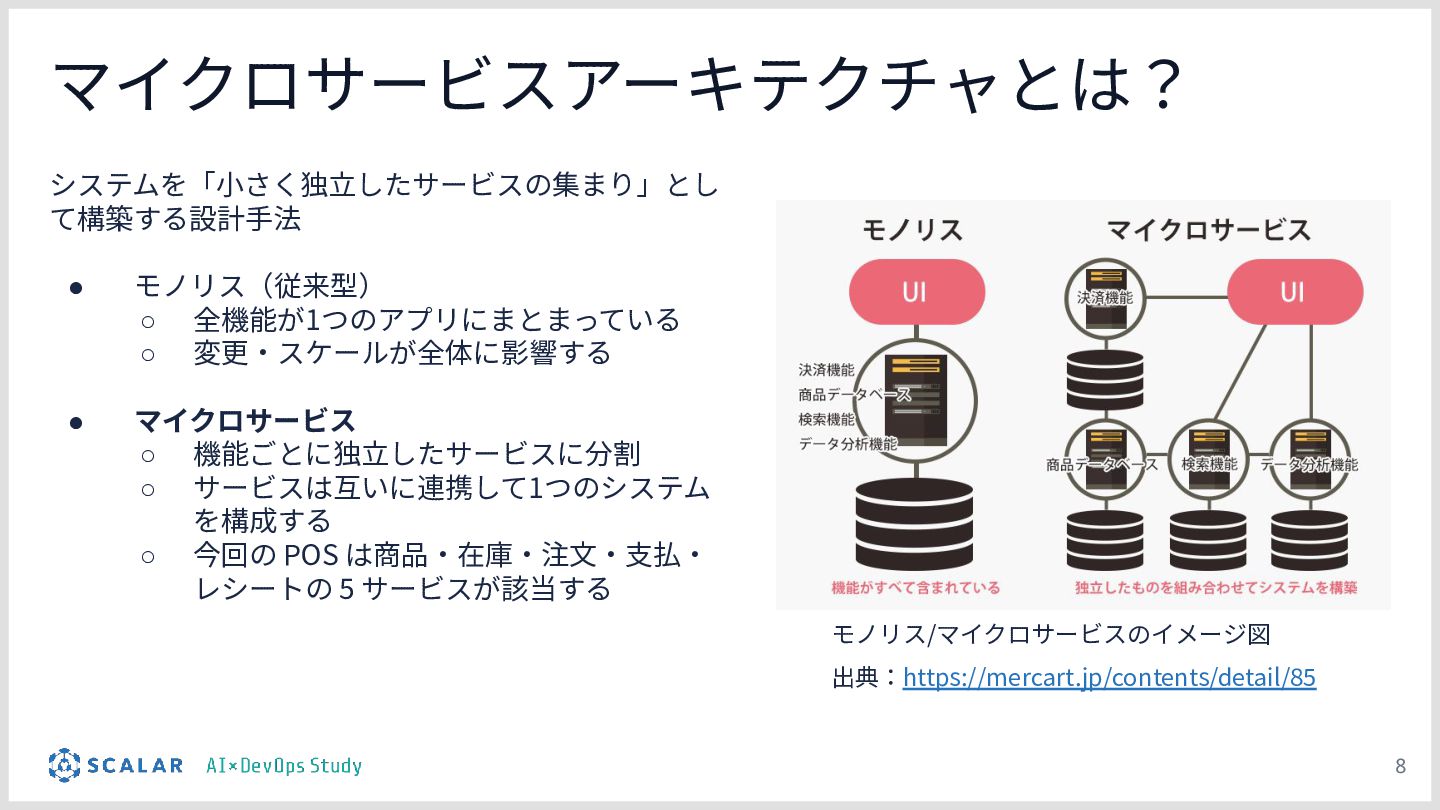
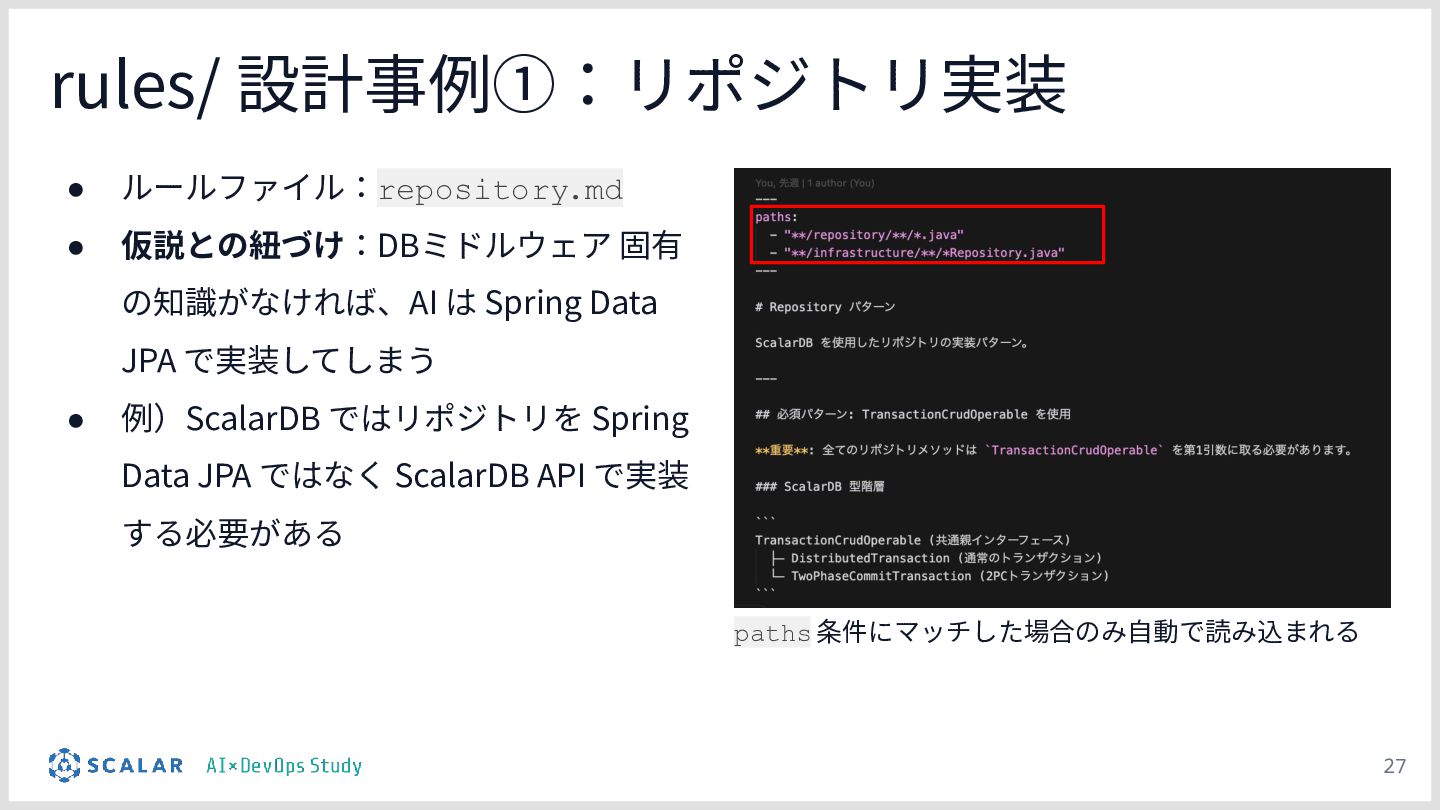
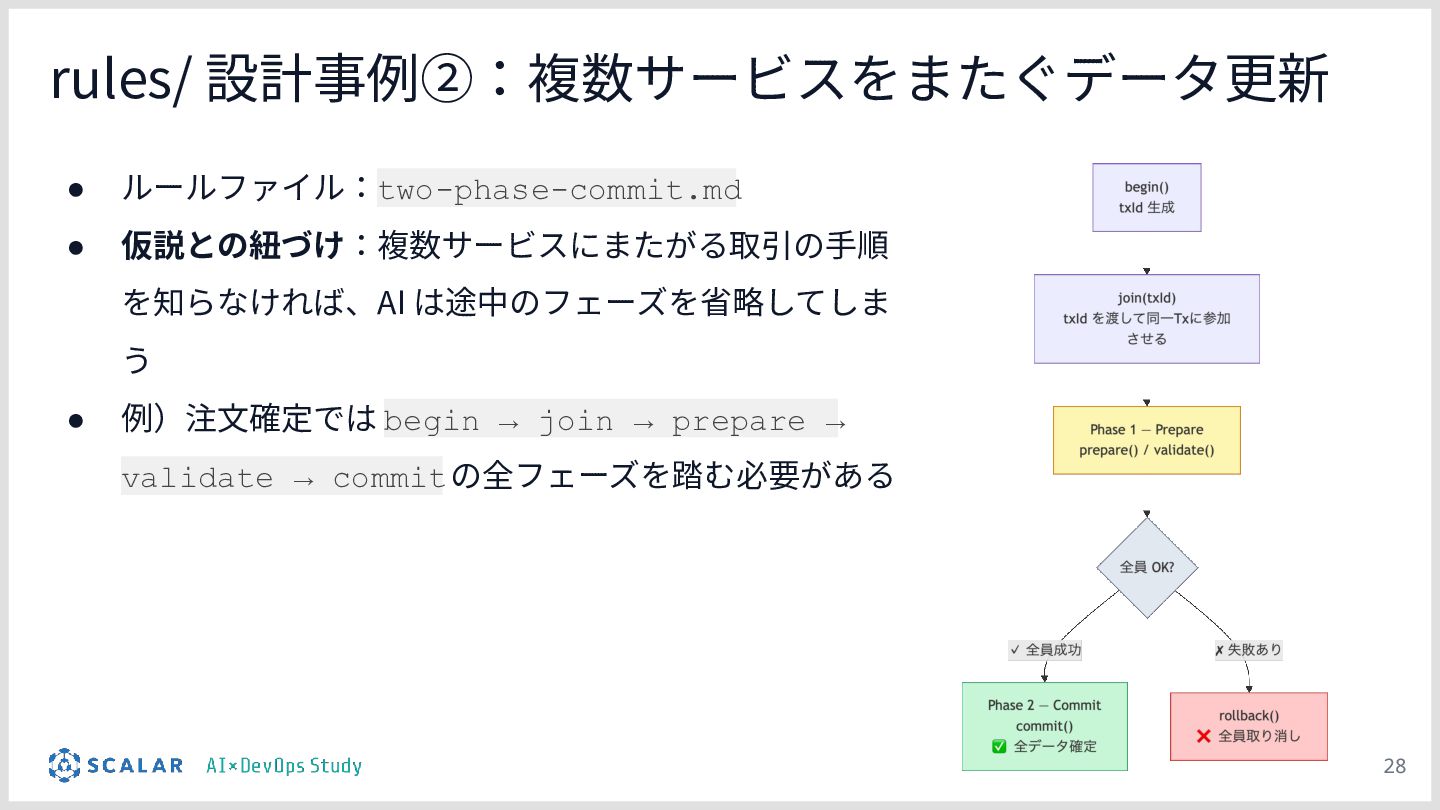
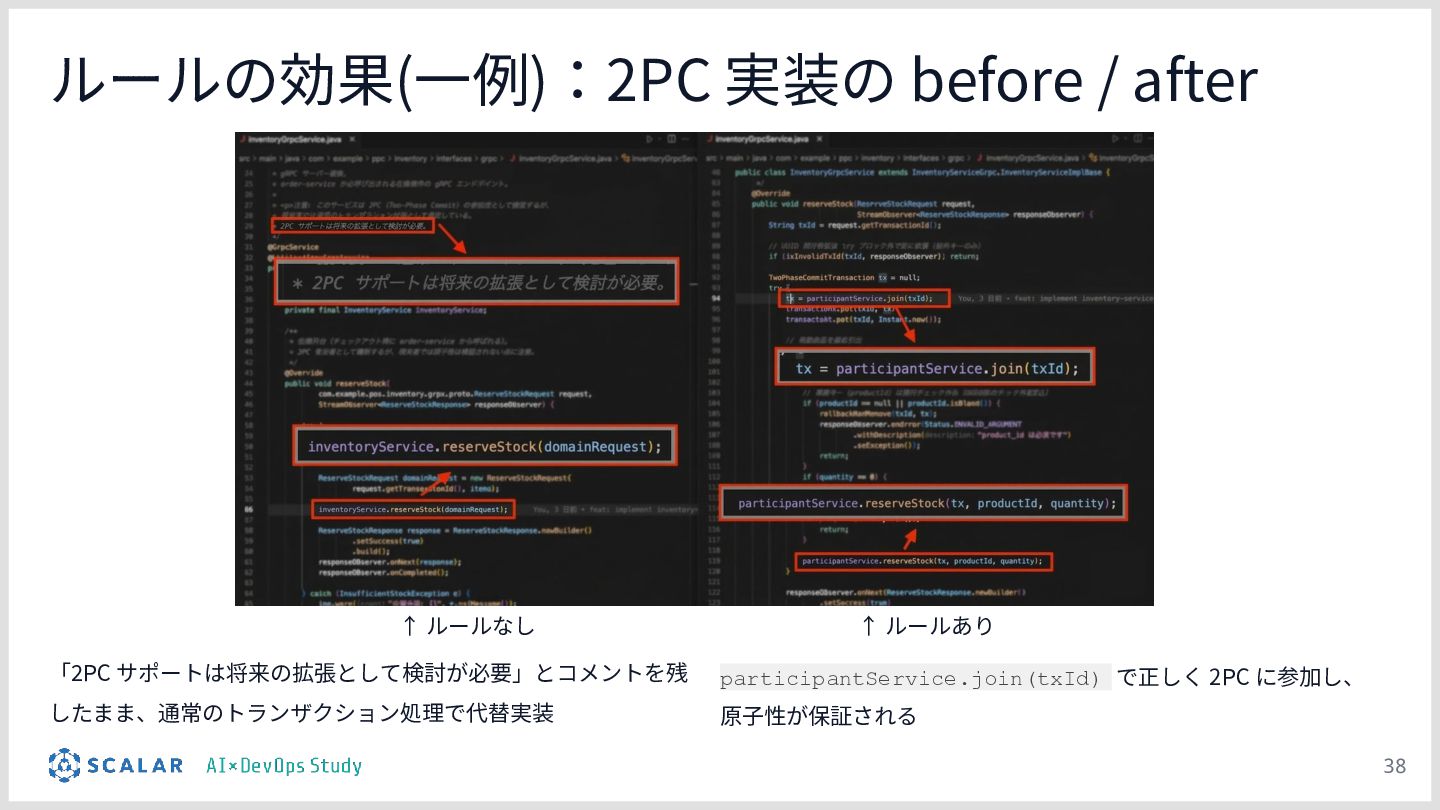
複雑な要件への対応課題:ScalarDBを用いた分散トランザクション(2PC)やマイクロサービス構成といった高度なアーキテクチャにおいて、事前のコンテキスト共有がない単なるAIへの指示出し(Vibe Coding)では、解釈のブレや規約違反が発生しやすい問題を解説します。
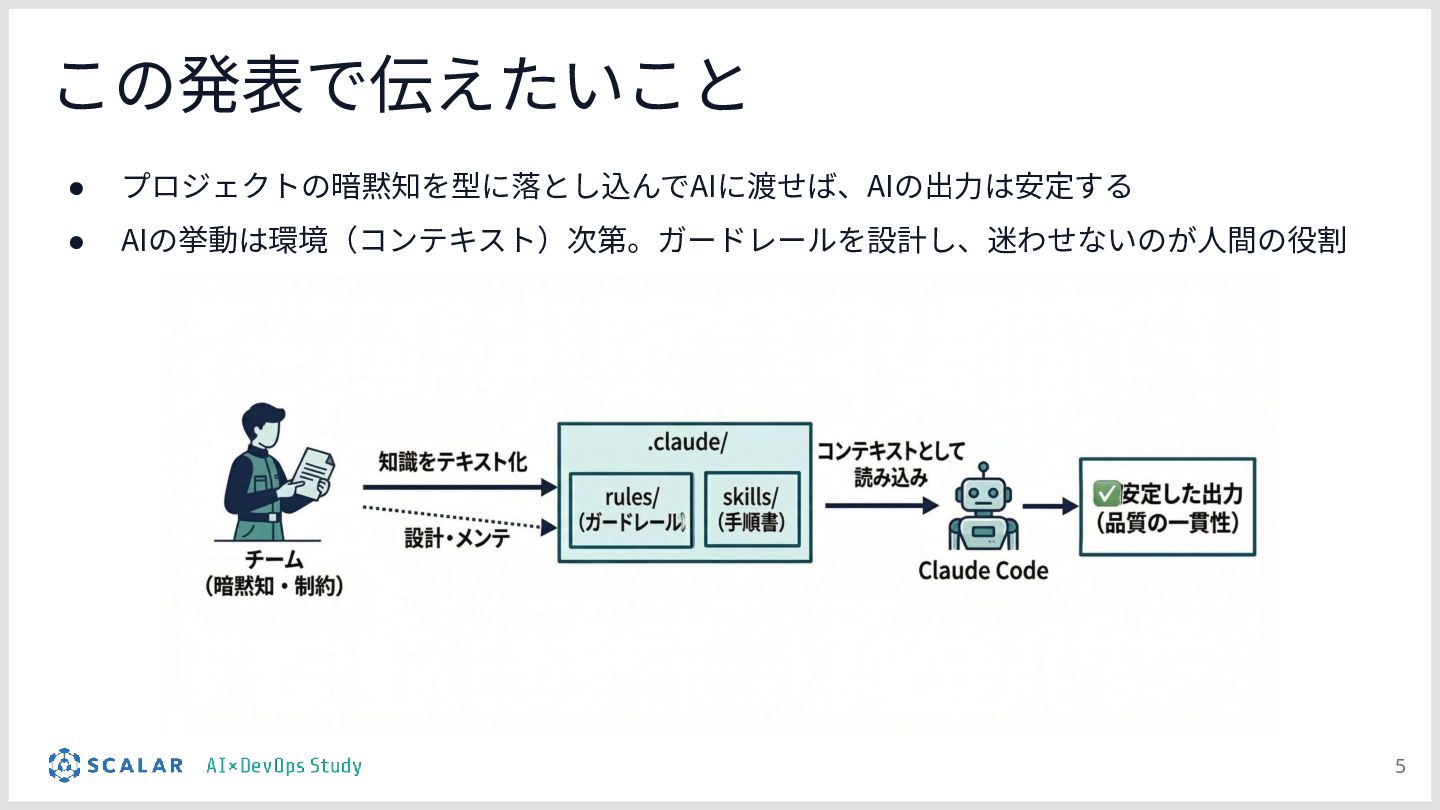
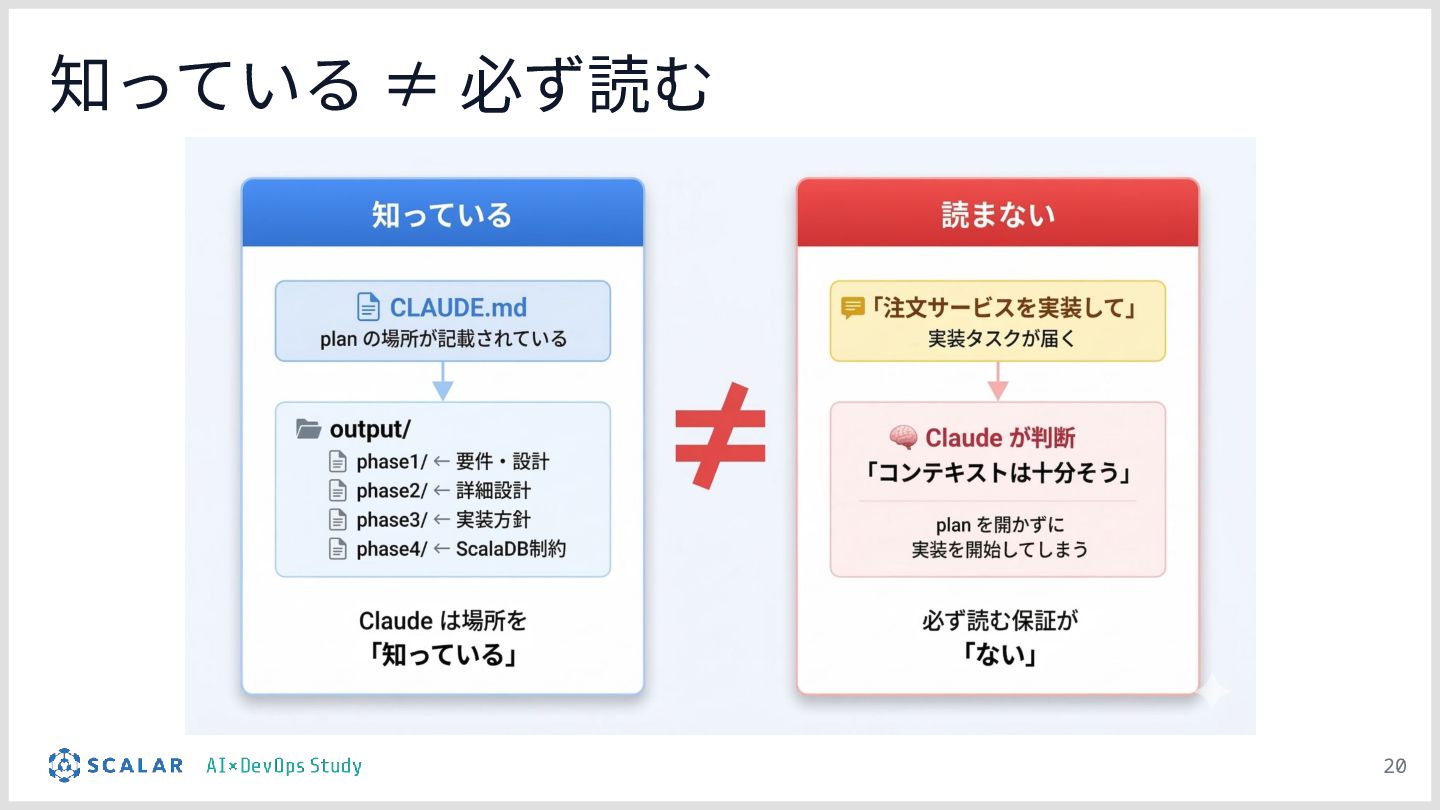
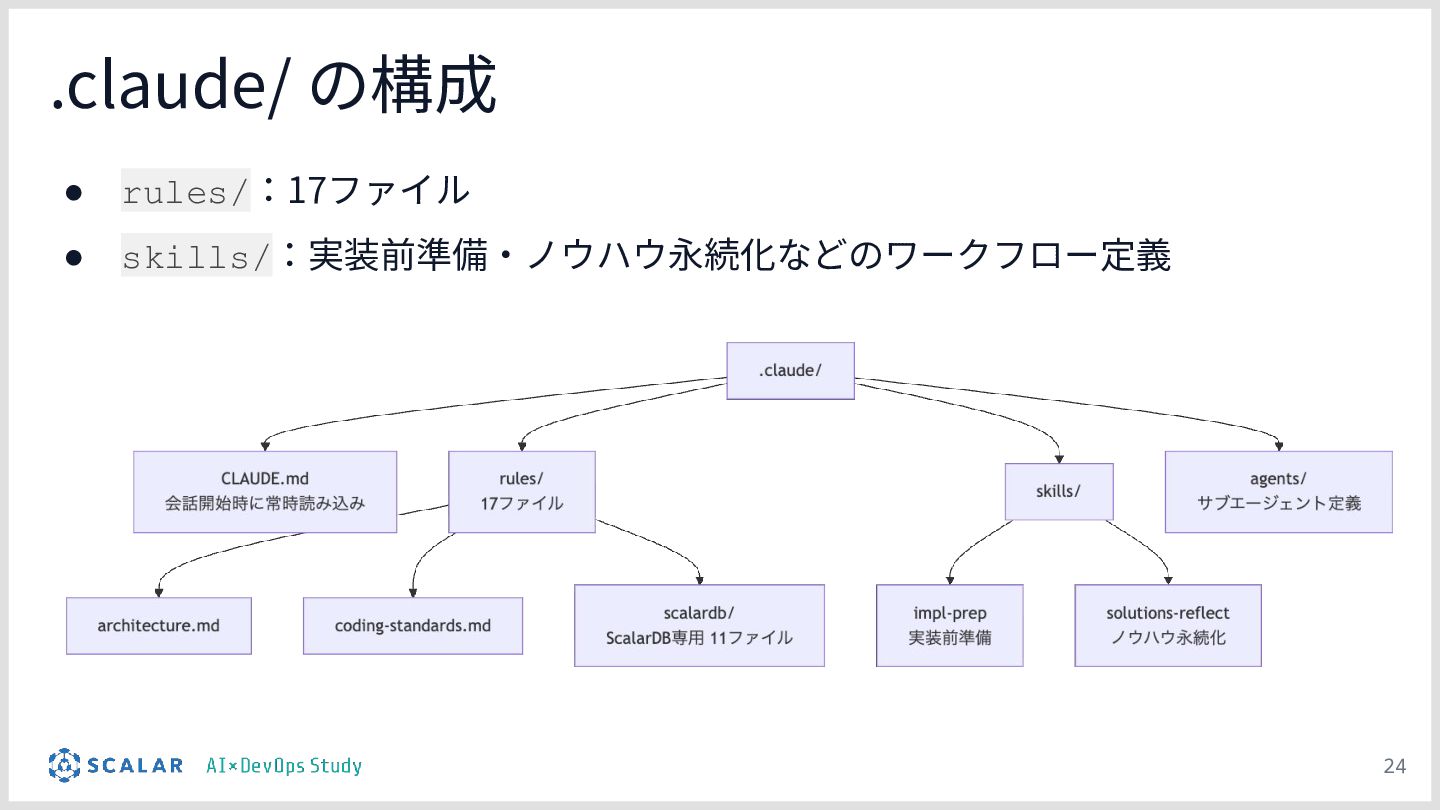
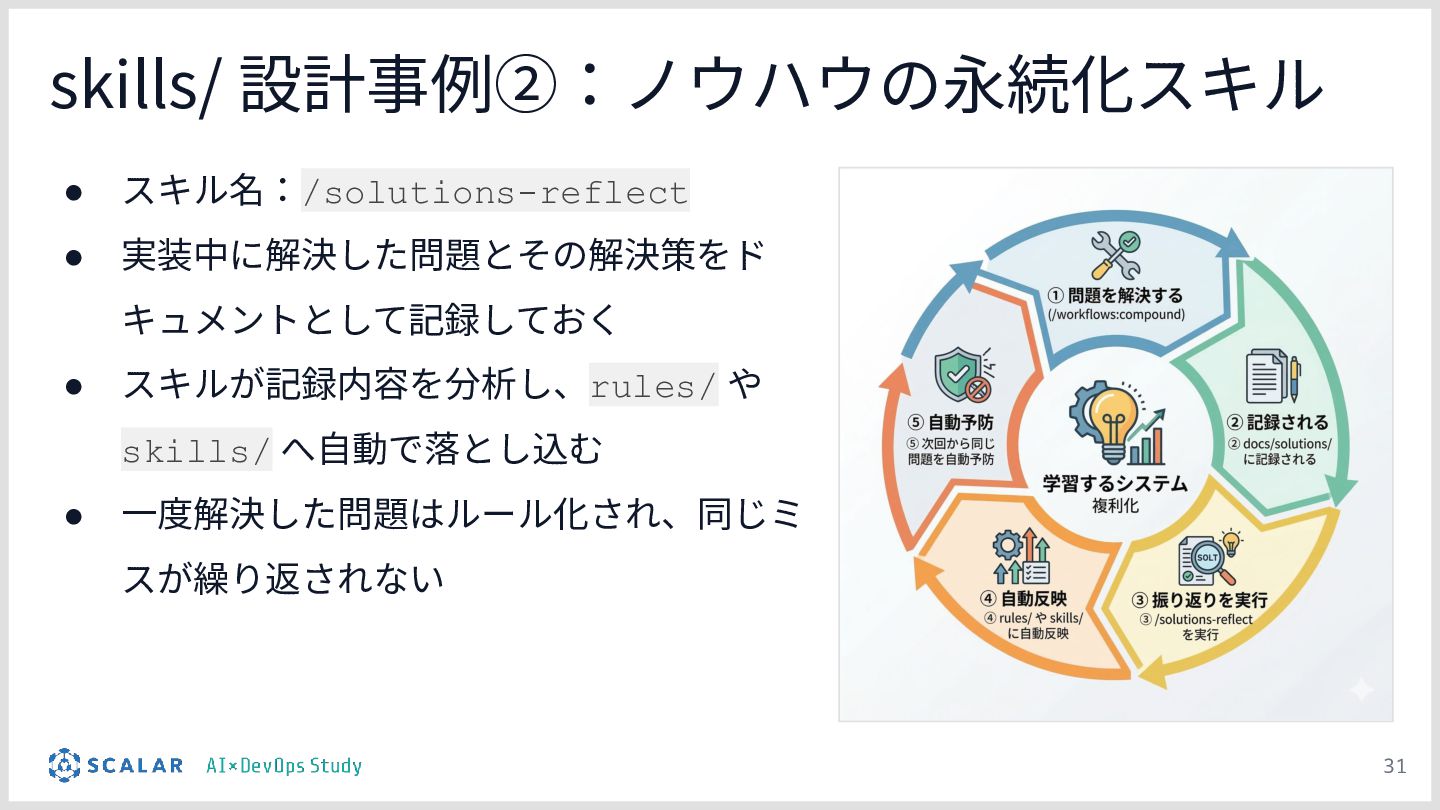
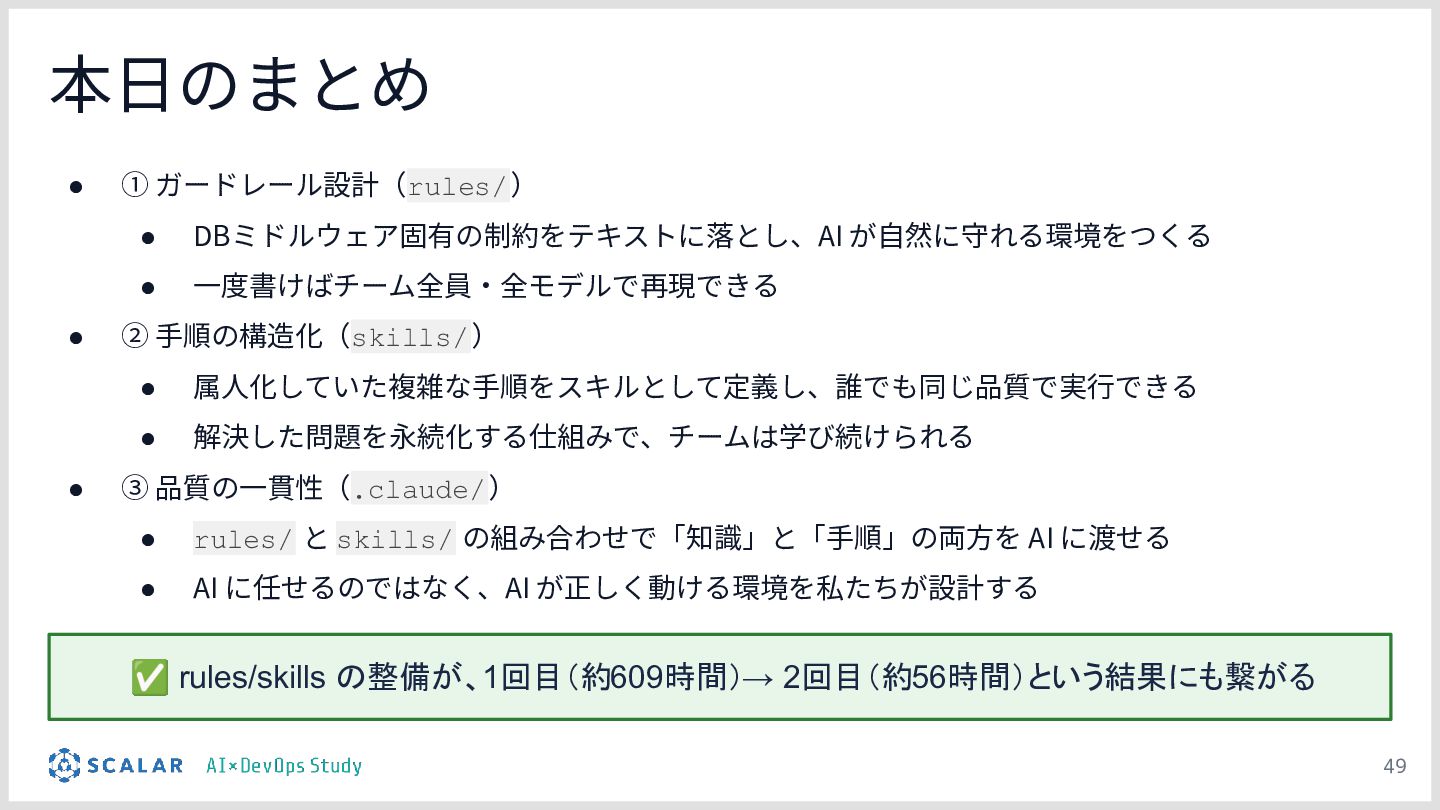
暗黙知の明文化(仮説):プロジェクトの暗黙知をClaude Codeのプロジェクト設定(.claude/)に明文化し、絶対ルール(rules/)と標準ワークフロー(skills/)を持たせる「ガードレール設計」の有効性について説明します。
3. デモ検証:ガードレール設計による成果物の差分(Before/After)
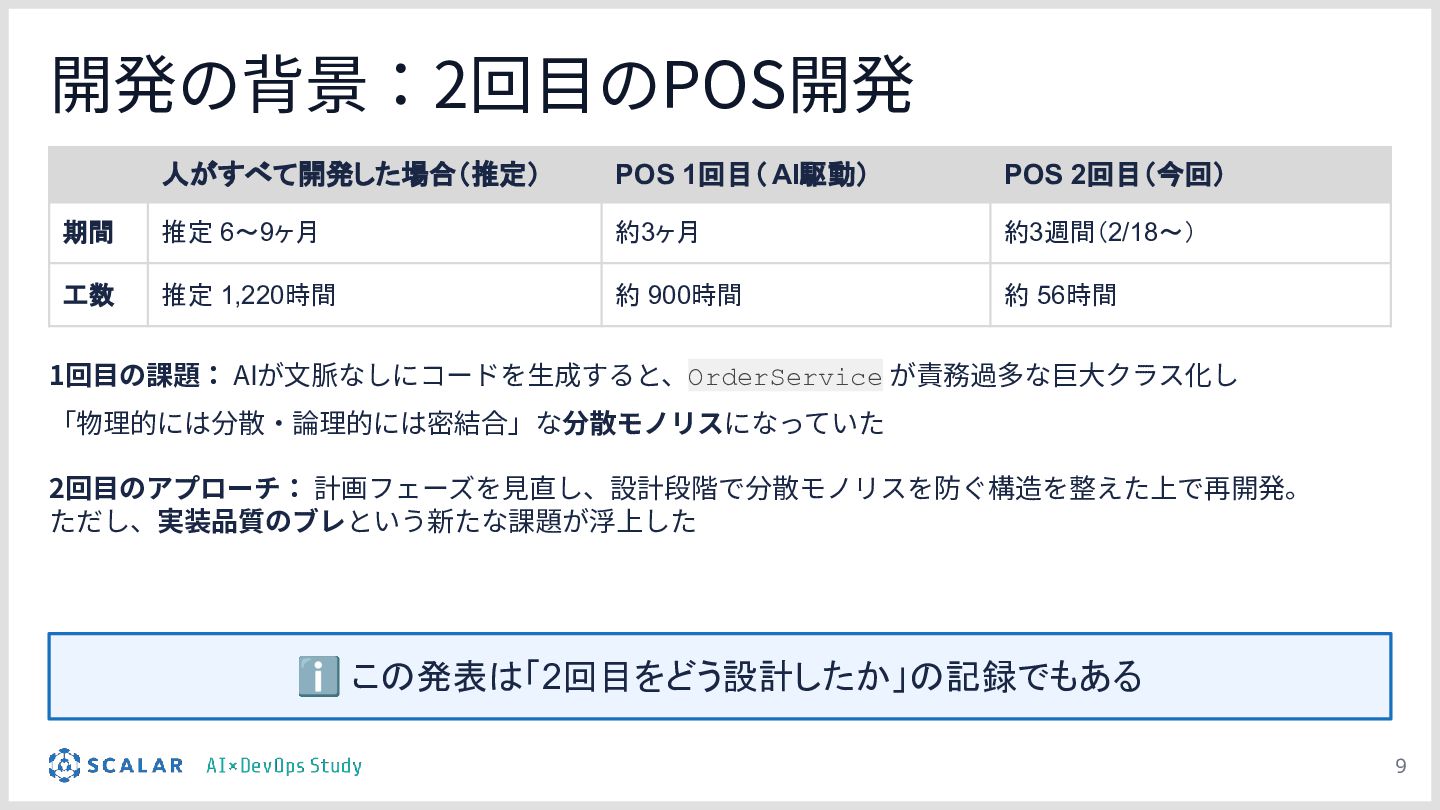
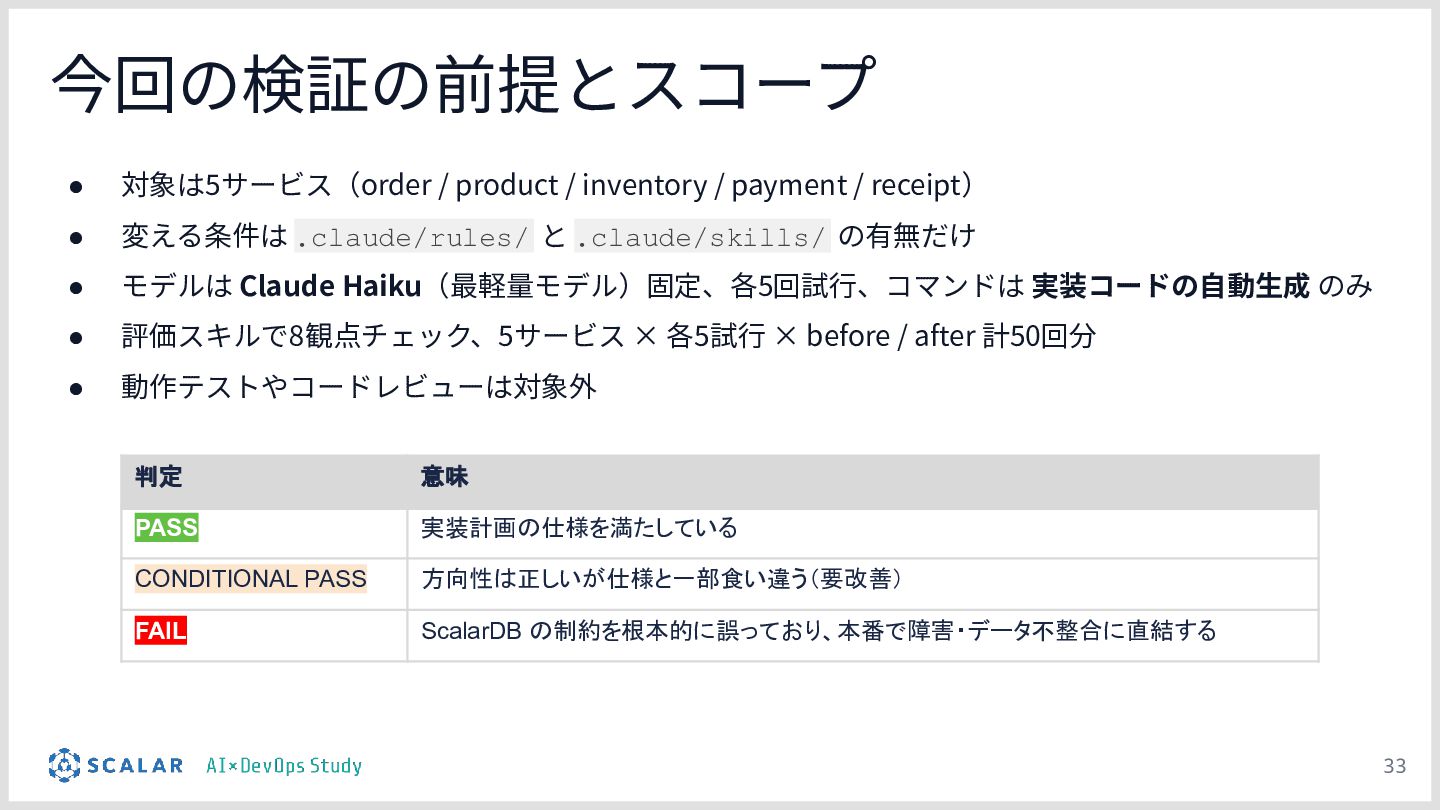
差分比較デモ:POSシステム(在庫引当・決済等の注文サービス)の実装を題材に、「設定を持たないClaude Code(Before)」と「プロジェクト設計を反映したClaude Code(After)」に対して同一の指示を出し、出力を比較します。
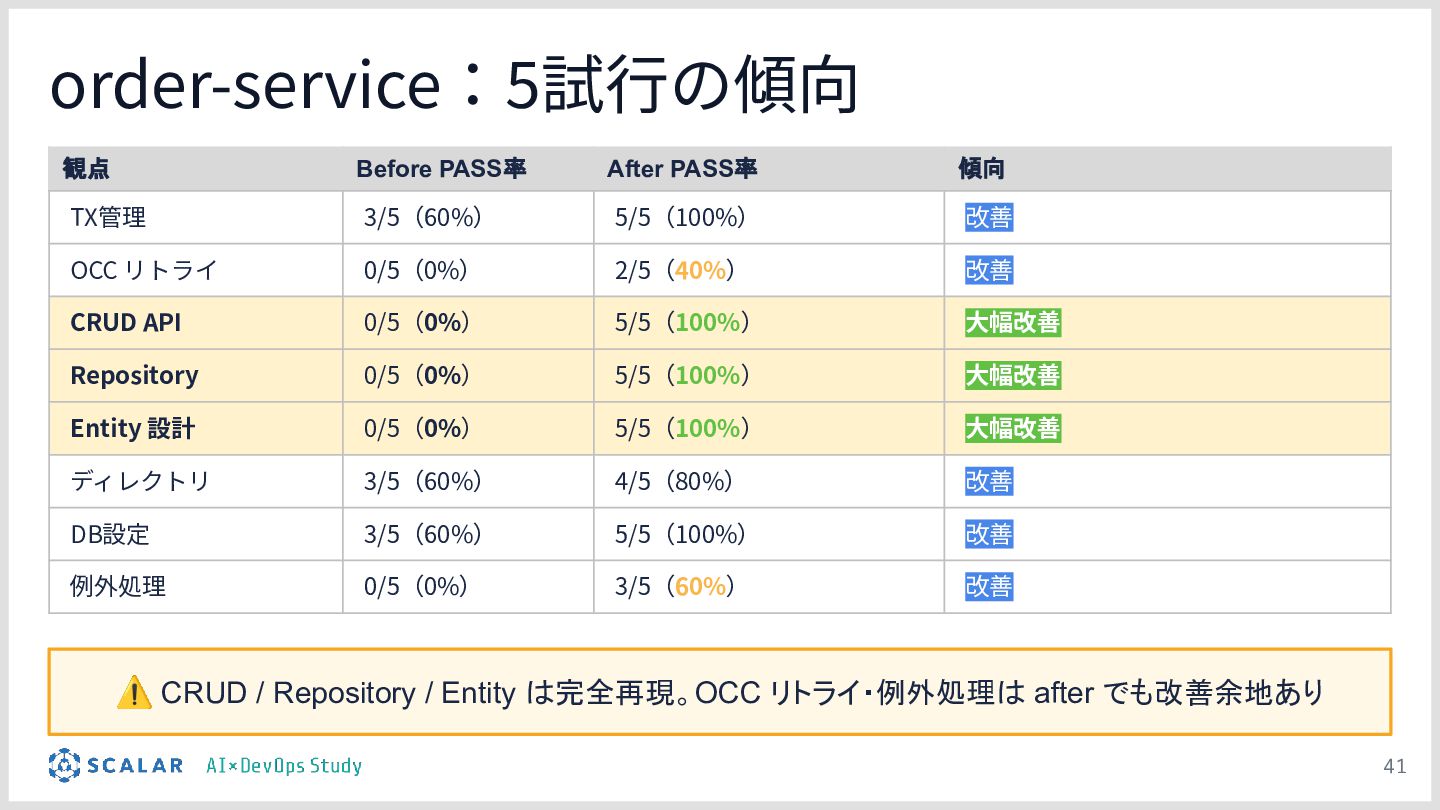
検証のポイント:株式会社ScalarやEvery社のツールを活用しつつ、OCCリトライロジック、分散トランザクションのシーケンス、独自の例外処理規約などが、設定の有無でどれだけ正確に実装されるかを実演します。
4. 結果と考察:設定ファイル(.claude/)の資産化
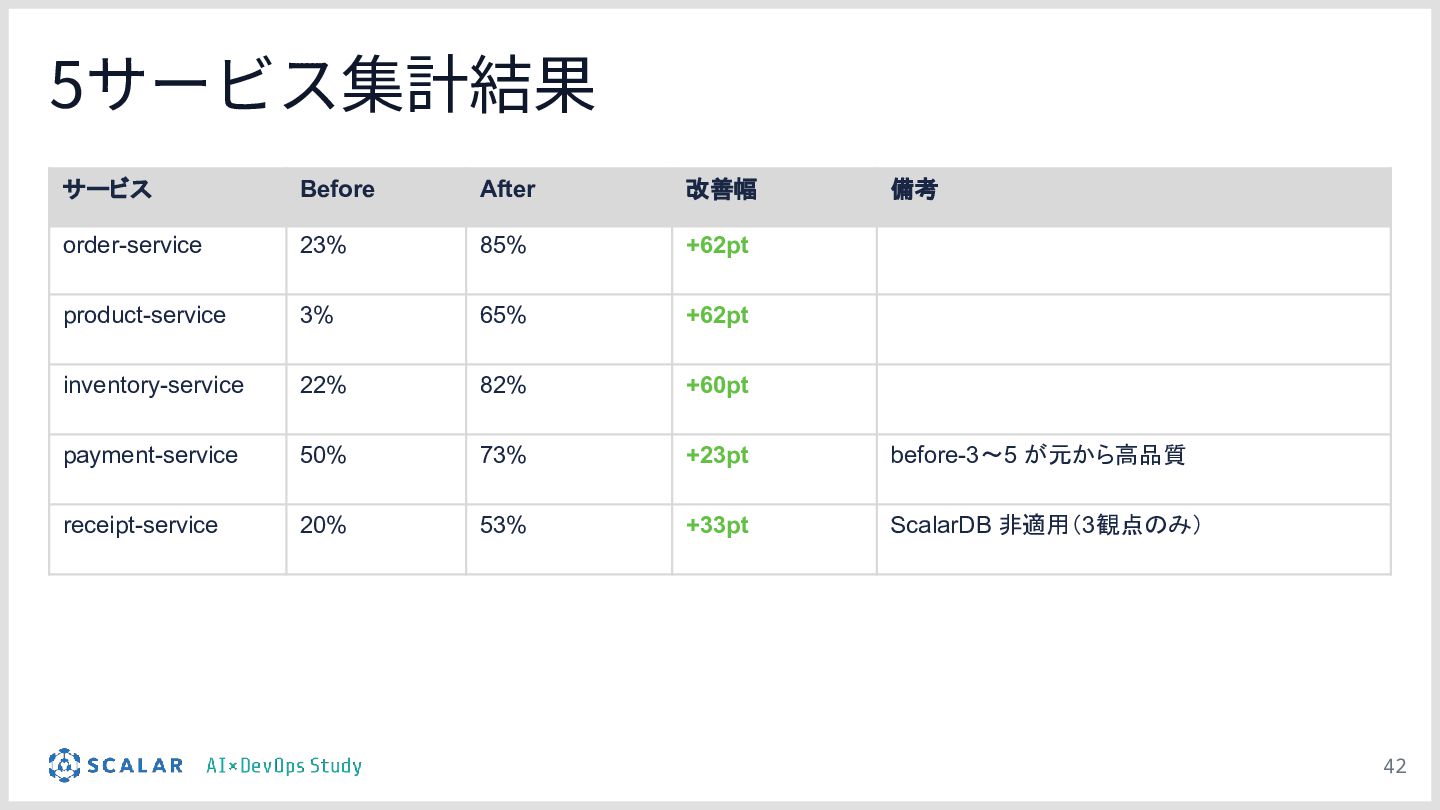
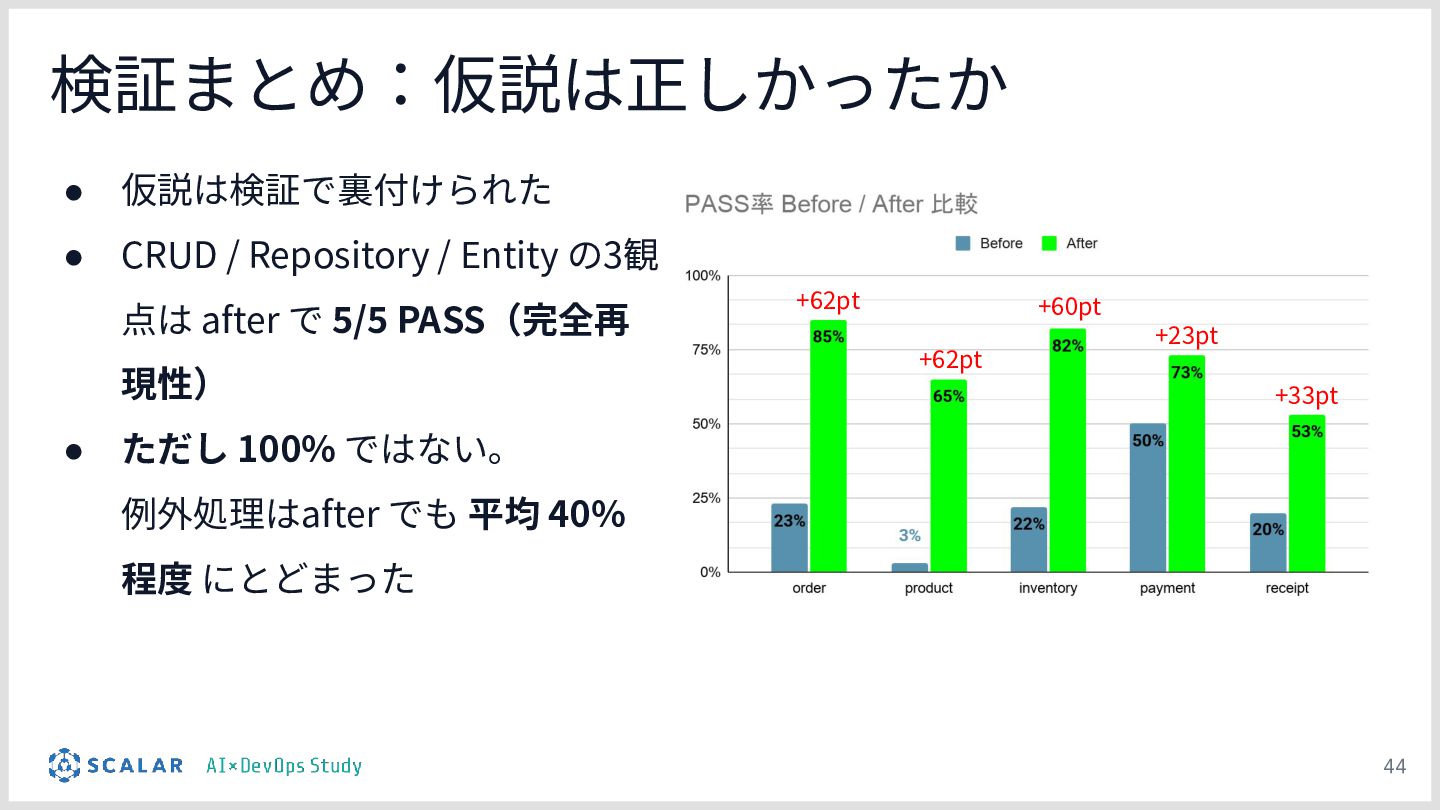
設計が品質に直結する:デモの結果を通じて、エージェントの「設計(作り込み)」がいかに成果物の品質向上とブレの排除に直結するかを実証します。
チーム資産としての運用:整備された .claude/ ディレクトリが、単なる設定ファイルを超えて「プロジェクトの資産(チームの共通言語)」として機能し、持続的な品質担保に繋がることを考察としてまとめます。
■登壇者情報(敬称略)
鹿島司
札幌の株式会社マーベリックスでWebエンジニアとして勤務しています。フロントエンド領域を得意とし、主にReactの経験が豊富です。 AI駆動の開発案件にジョインし、今回のPOSシステムの開発を通じて「AIとの協働をいかに効率よく行うか」について現場のエンジニア目線で実践と探究をしています。
中堀翔太
札幌の株式会社マーベリックスでWebエンジニアを務めています。 JavaやAWS、フロントエンドなど、要件定義から保守まで一貫して担ってきた経験を活かし、現在はAI駆動型の開発案件にて、コーディングエージェントを活用したバックエンド開発を担当しています。 マイクロサービスやScalarDBを用いた分散トランザクションといった複雑な実装に対し、AIといかに協働して挑むかを実践しています。
箱崎一輝
札幌の株式会社マーベリックスで、Webエンジニア兼リーダーを務めています。 これまで社内のGoogle Workspace全社導入を推進し、組織の働きやすい環境づくりに貢献しました。 今年からはAI駆動型の開発案件に本格的にジョイン。リーダーとしてチームをまとめながら、実際の現場で「AIをどうUI/UX開発に組み込むか」、日々の実践を通じて探求しています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
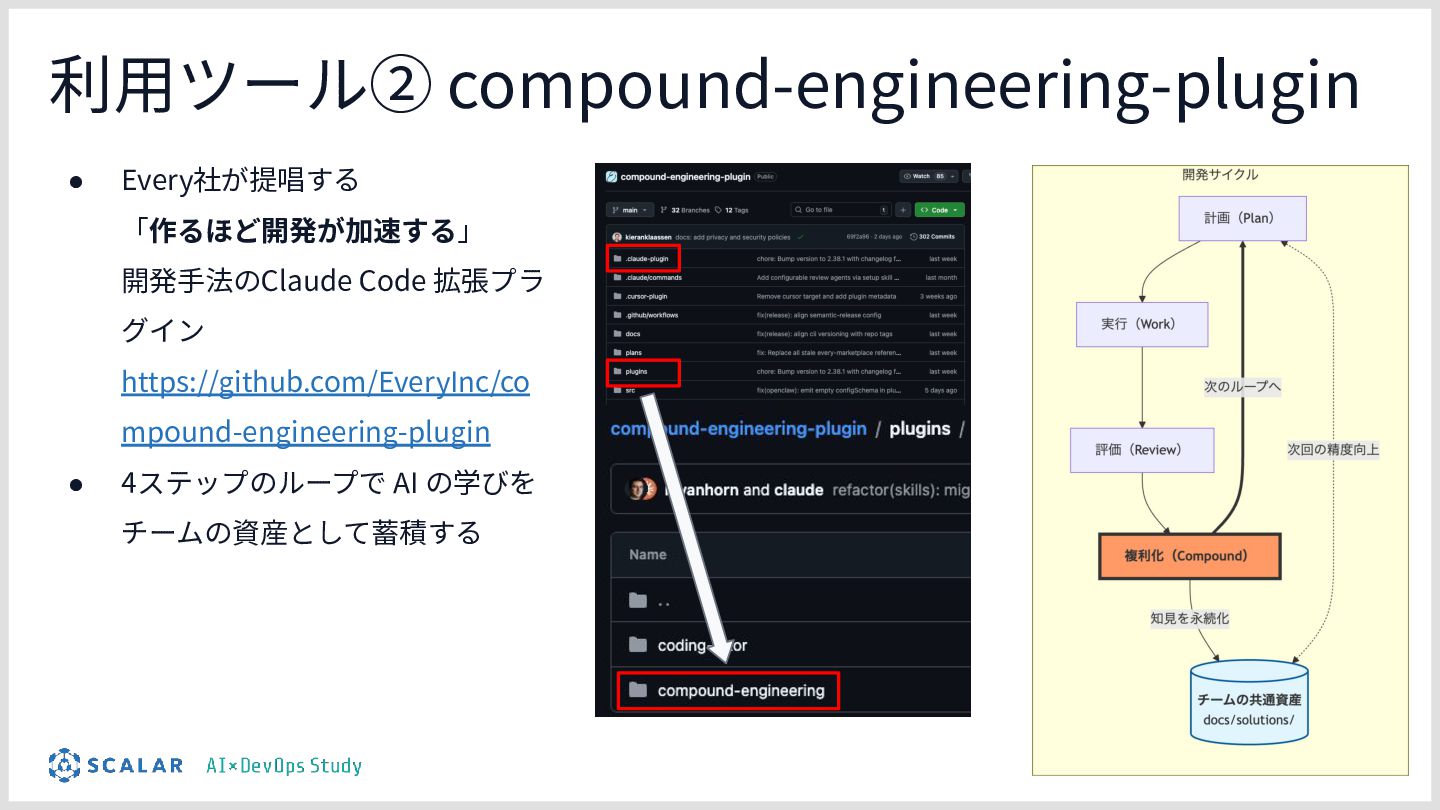{kind=link}
{kind=link}
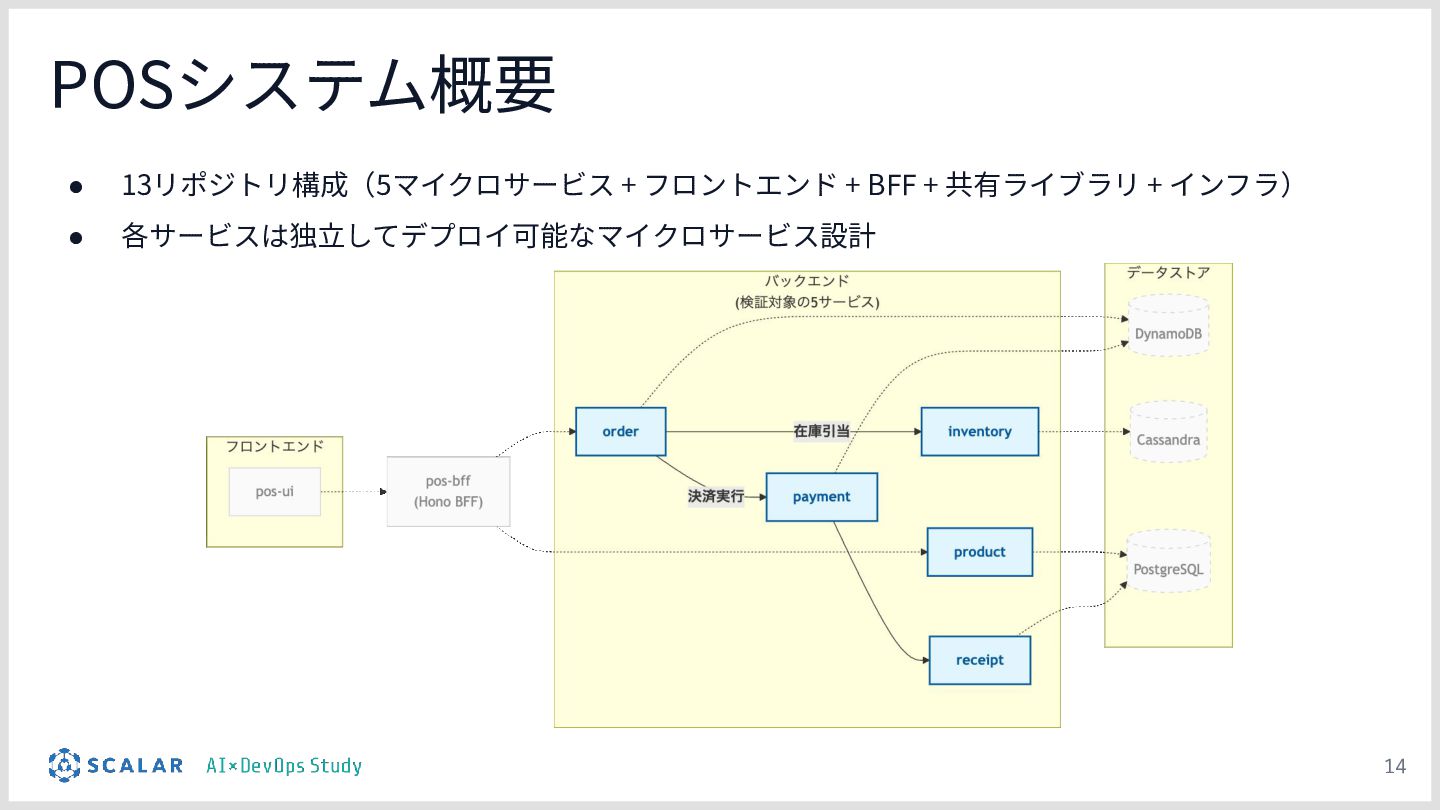{kind=link}
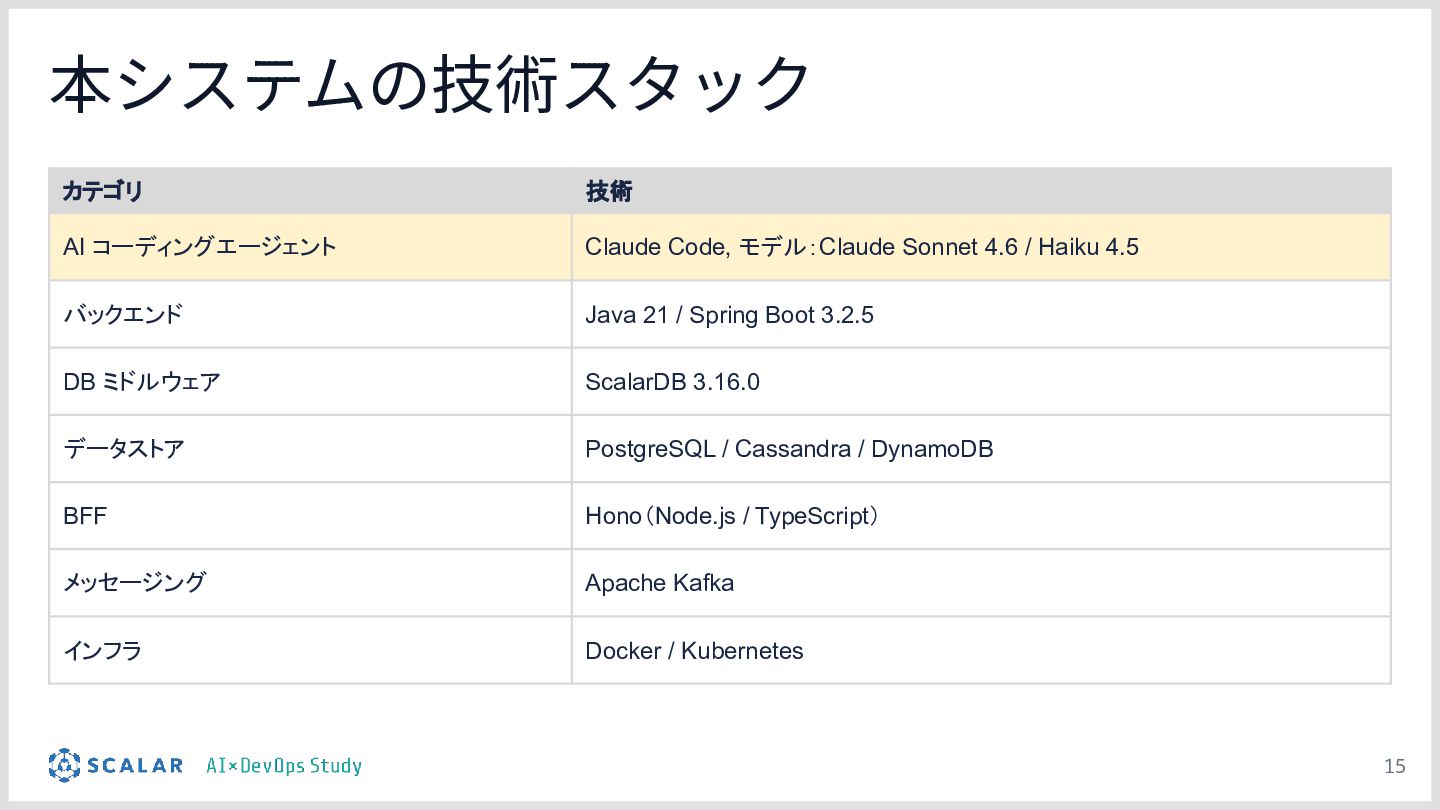{kind=link}
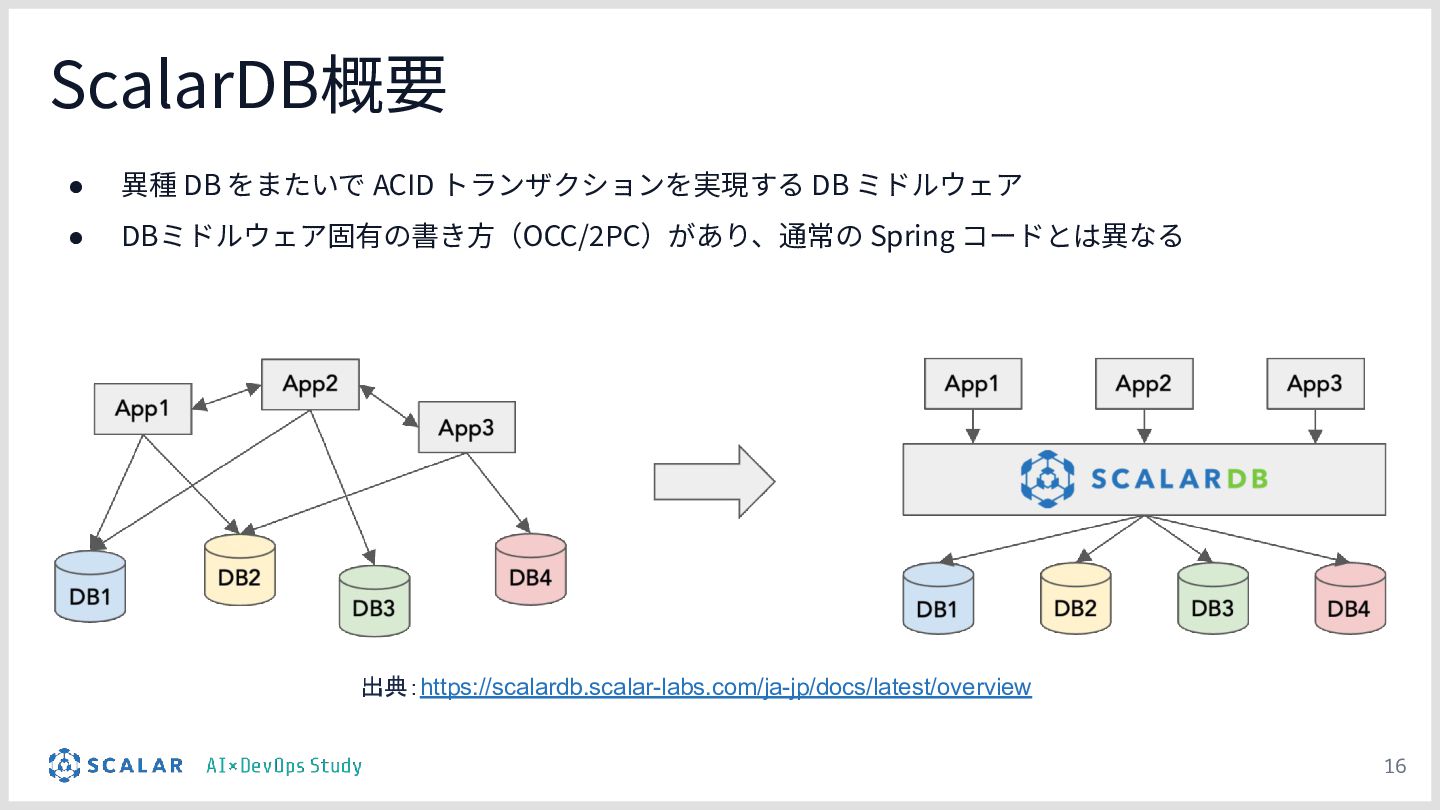{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}