Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ECS EC2からFargateへ 移行した理由とメリット
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
akano yuki
July 02, 2021
Technology
340
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ECS EC2からFargateへ 移行した理由とメリット
AWS様主催の「そろそろマネージド、クラウドネイティブで行こう!」というイベントで登壇させていただいた際の資料です
akano yuki
July 02, 2021
More Decks by akano yuki
See All by akano yuki
日本最大級のマッチングアプリ「タップル」で実現する Datadog を活用したセキュリティとパフォーマンスの統合オブザーバビリティ
sekino
0
2.6k
計画的に負荷リスクを排除するためのキャパシティプランニング
sekino
5
12k
Other Decks in Technology
See All in Technology
Retriever と Reranker、結局どうする?
kazuaki
1
550
GMOフィナンシャルゲートが挑む、「止まらない」決済インフラ構築の裏側【SORACOM Discovery 2026】
soracom
PRO
0
120
ガバメントクラウドでのランサムウェア対策
techniczna
1
430
クラウドセキュリティ入門 ~安全なクラウド利用のための基礎知識~
lhazy
6
4.1k
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
160
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
150
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
5
1.4k
PLaMo 3.0 Primeの構造化出力サポート
pfn
PRO
0
150
NYC Summit 2026 における Amazon Bedrock AgentCore のアップデート
ren8k
3
290
20260801_スクフェス大阪
kgnkhkr
0
150
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
370
AI工学特論: MLOps・継続的評価
asei
11
3.1k
Featured
See All Featured
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2.1k
4 Signs Your Business is Dying
shpigford
187
22k
Automating Front-end Workflow
addyosmani
1370
210k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
Paper Plane (Part 1)
katiecoart
PRO
1
9.9k
Designing for Performance
lara
611
70k
Deep Space Network (abreviated)
tonyrice
0
240
Documentation Writing (for coders)
carmenintech
77
5.4k
Code Reviewing Like a Champion
maltzj
528
40k
Prompt Engineering for Job Search
mfonobong
0
390
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Transcript
ECS EC2からFargateへ 移行した理由とメリット 赤野裕喜
自己紹介 • 赤野 裕喜 / Akano Yuki • 2013年サイバーエージェント新卒入社 •
趣味: #キャンプ #サウナ • アバターサービス、ECサービスなどでバックエンドエンジニ アとして開発 • 2019年 3月頃からタップルにSREとして参加
目次 1. タップル プロダクト概要 2. タップルのシステム構成概要 3. Fargate移行への道のり a. 移行した理由
b. 移行計画 c. 移行時に発生した問題 4. コスト 5. 運用してきて感じたメリット 6. まとめ
タップル プロダクト概要
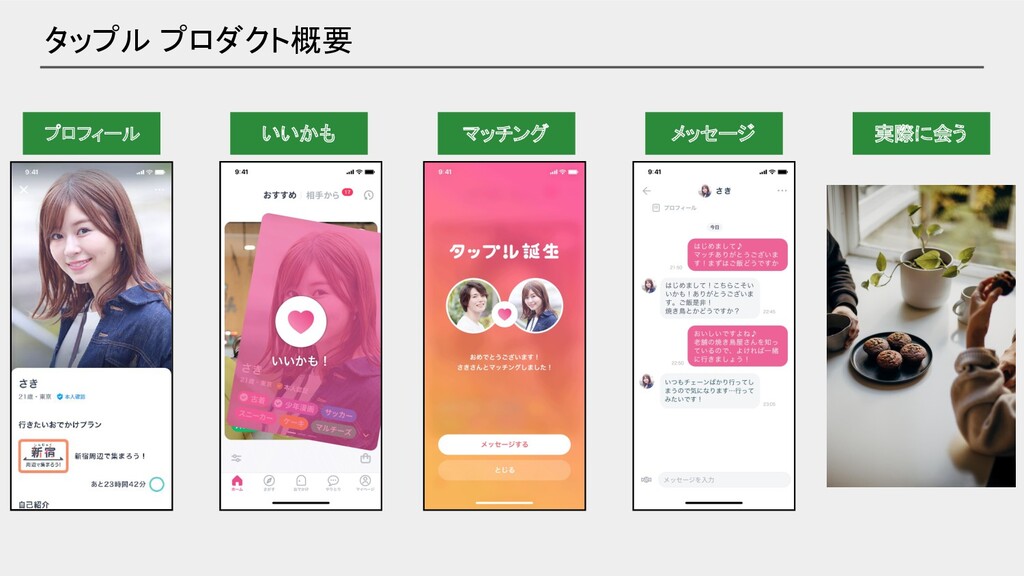
タップル プロダクト概要
タップル プロダクト概要 プロフィール いいかも マッチング メッセージ 実際に会う
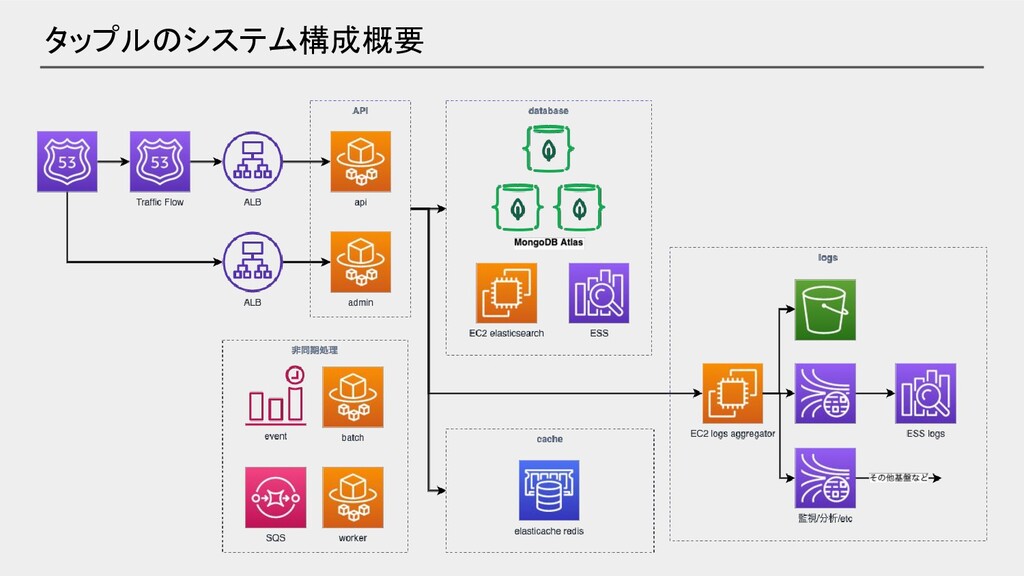
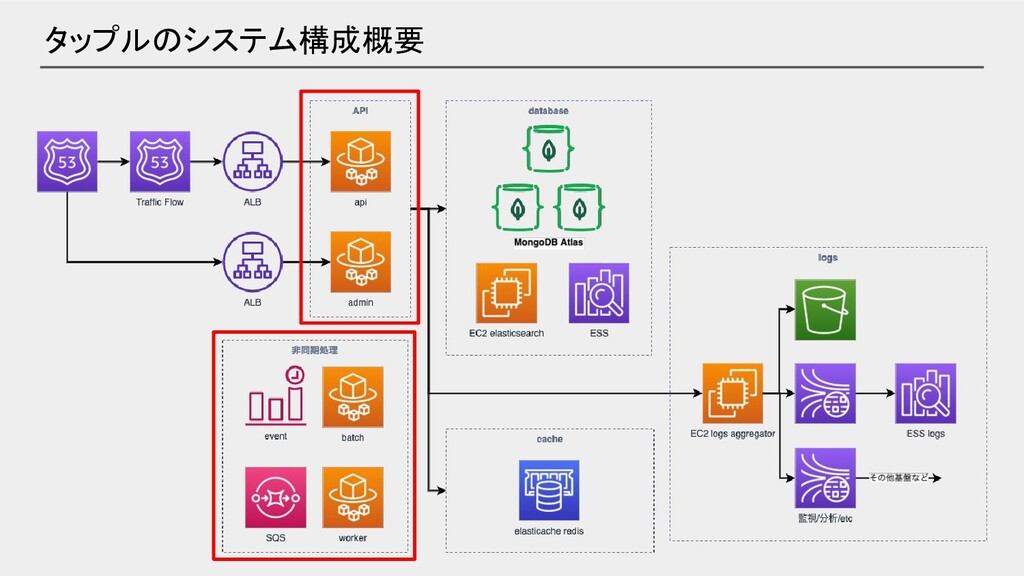
タップル システム構成概要
タップルのシステム構成概要
タップルのシステム構成概要
API nodejs fluentd datadog agent ・max 600タスク ・ステップスケーリング タスクCPU 1024
タスクメモリ 2048 Batch nodejs datadog agent ・Cloudwatchイベント Cron式 バッチ毎に設定 Worker nodejs datadog agent ・max 70タスク ・ターゲット追跡スケーリング ・イベントドリブンな非同期処理 タスクCPU 1024 タスクメモリ 2048
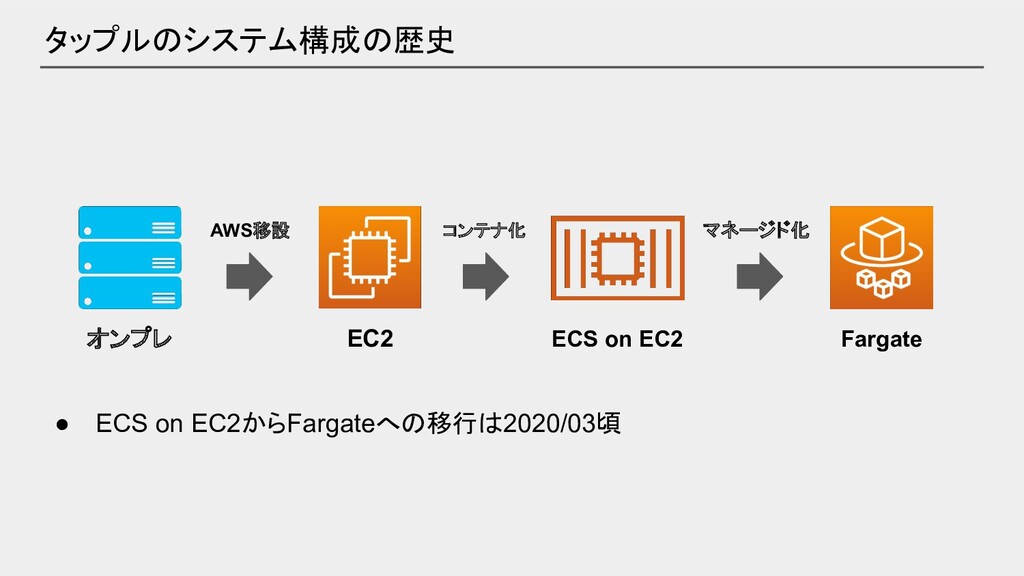
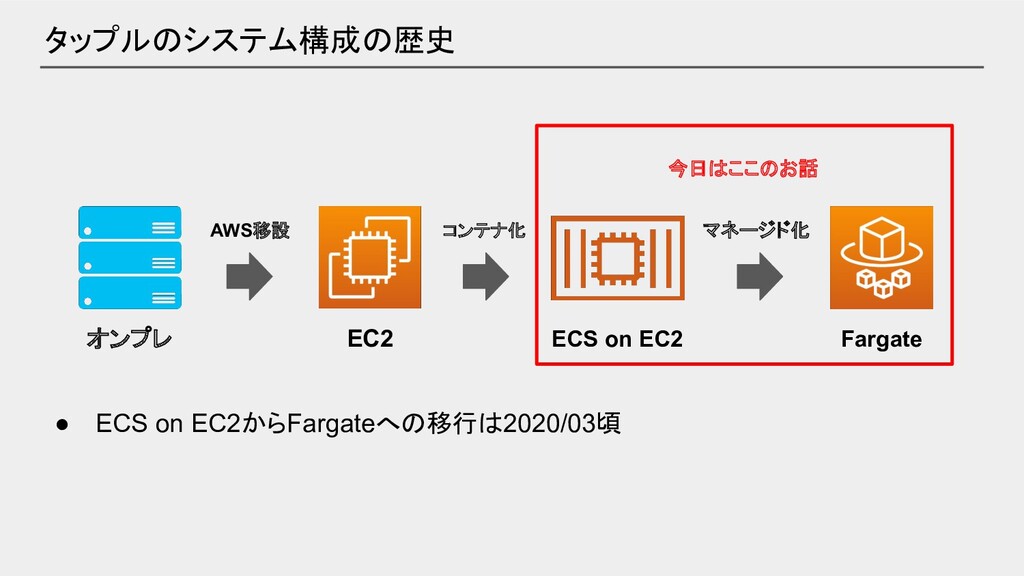
タップルのシステム構成の歴史 オンプレ EC2 ECS on EC2 AWS移設 コンテナ化 マネージド化 Fargate
• ECS on EC2からFargateへの移行は2020/03頃
タップルのシステム構成の歴史 オンプレ EC2 ECS on EC2 AWS移設 コンテナ化 マネージド化 Fargate
• ECS on EC2からFargateへの移行は2020/03頃 今日はここのお話
Fargate移行への道のり
• EC2クラスターの管理コストを無くしたい ◦ EC2関連の管理作業をしたくない • 開発メンバーがコンテナでの運用に慣れてきた ◦ ECSを使い始めて1年ほど経過していた Fargateへ移行することにした理由 •
デプロイの速度を速くしたい ◦ 先にEC2の台数を手動で増やすオペレーション • オートスケールの速度を速くしたい ◦ スパイクアクセス発生時にレイテンシが悪化することが多かった
Fargateへの移行計画 1. テスト環境で正常に動くことを確認 2. 負荷試験環境で検証 a. パフォーマンス検証 b. スケーリングポリシーの調整 3.
ステージング環境でリグレッションテスト 4. 本番環境へリリース a. リリースへの準備 b. カナリアリリース
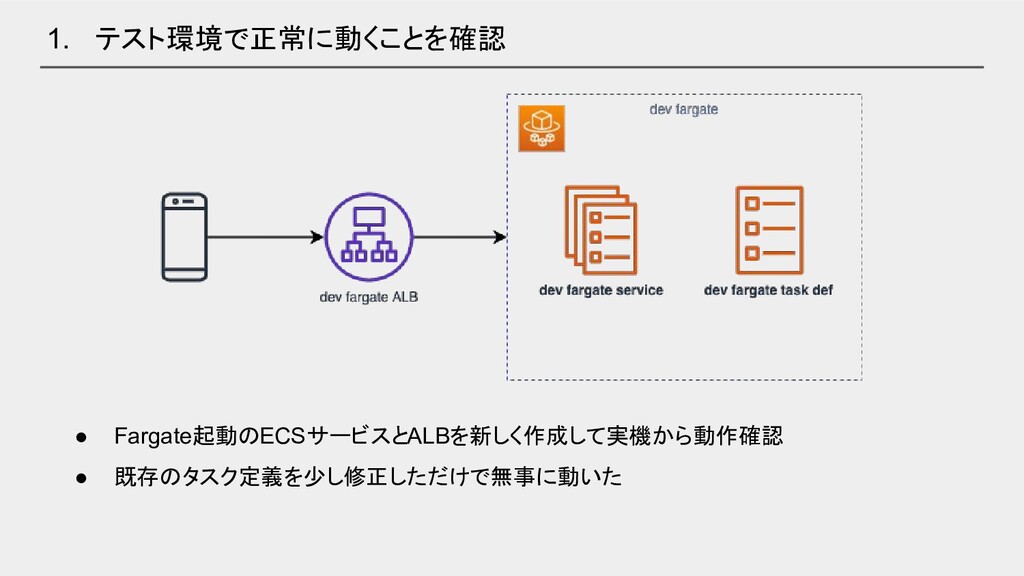
1. テスト環境で正常に動くことを確認 • Fargate起動のECSサービスとALBを新しく作成して実機から動作確認 • 既存のタスク定義を少し修正しただけで無事に動いた
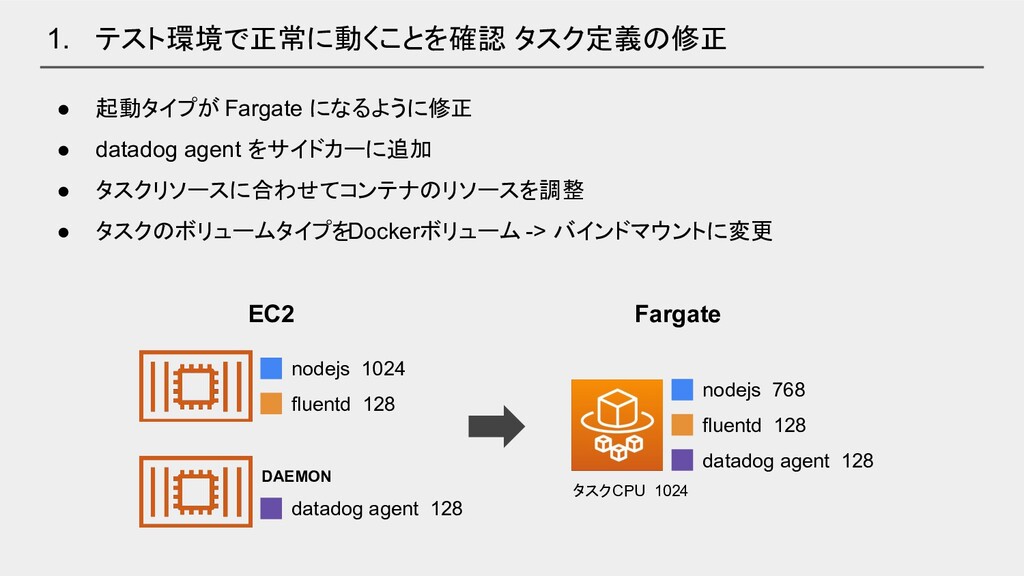
1. テスト環境で正常に動くことを確認 タスク定義の修正 • 起動タイプが Fargate になるように修正 • datadog agent
をサイドカーに追加 • タスクリソースに合わせてコンテナのリソースを調整 • タスクのボリュームタイプをDockerボリューム -> バインドマウントに変更 タスクCPU 1024 nodejs 768 fluentd 128 datadog agent 128 nodejs 1024 fluentd 128 datadog agent 128 DAEMON EC2 Fargate
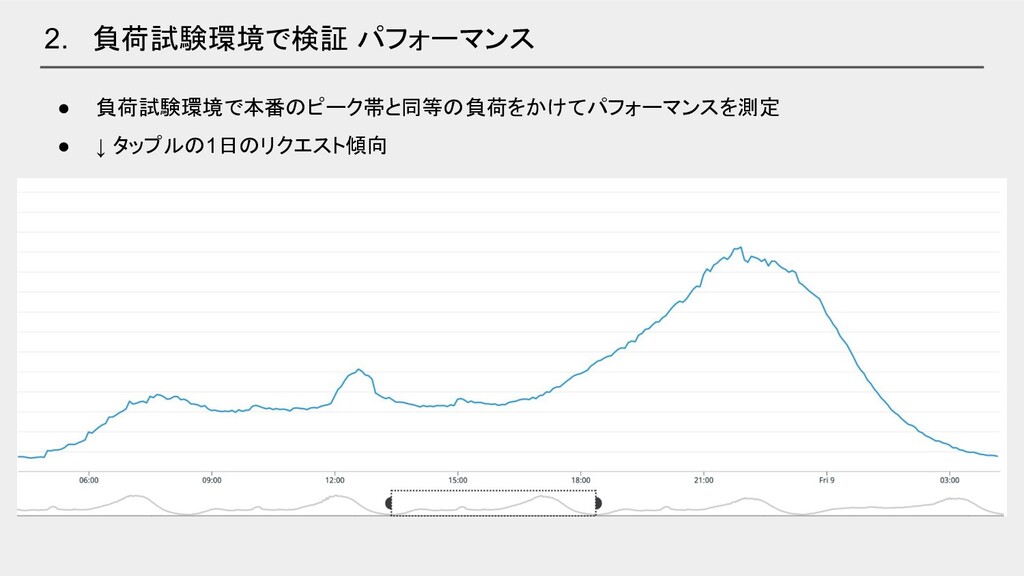
2. 負荷試験環境で検証 パフォーマンス • 負荷試験環境で本番のピーク帯と同等の負荷をかけてパフォーマンスを測定 • ↓ タップルの1日のリクエスト傾向
タスクCPU 1024 2. 負荷試験環境で検証 パフォーマンス • 同じタスク数だとEC2に比べてパフォーマンスが劣化した ◦ nodejs に割り当てるCPUユニットが減ってしまったことが原因
▪ nodejs は1コア分のリソースしか使えない ▪ サイドカーに datadog agent を追加している nodejs 768 fluentd 128 datadog agent 128 nodejs 1024 fluentd 128 25%減 • タスク数を増やすことで改善
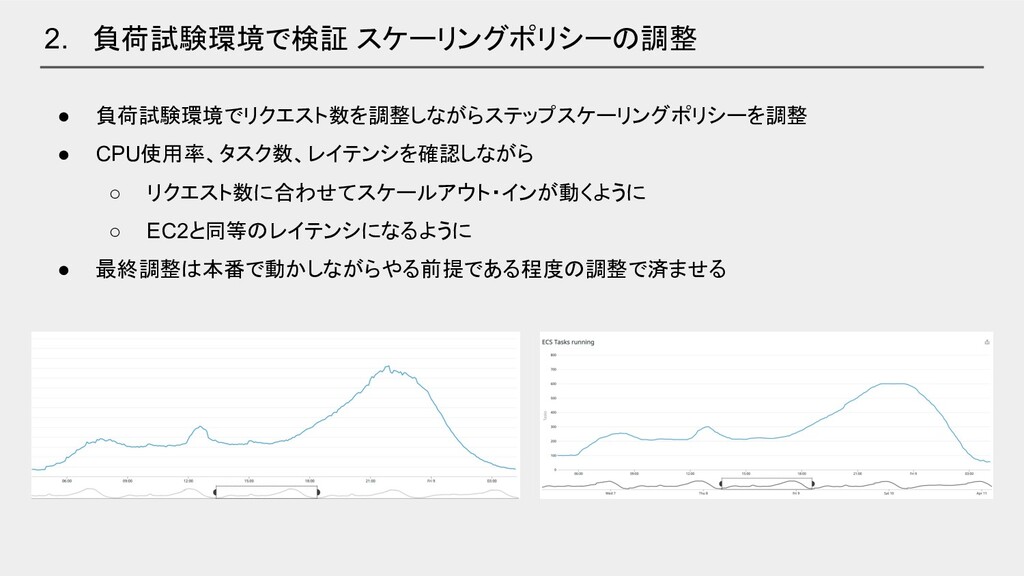
• 負荷試験環境でリクエスト数を調整しながらステップスケーリングポリシーを調整 • CPU使用率、タスク数、レイテンシを確認しながら ◦ リクエスト数に合わせてスケールアウト・インが動くように ◦ EC2と同等のレイテンシになるように • 最終調整は本番で動かしながらやる前提である程度の調整で済ませる
2. 負荷試験環境で検証 スケーリングポリシーの調整
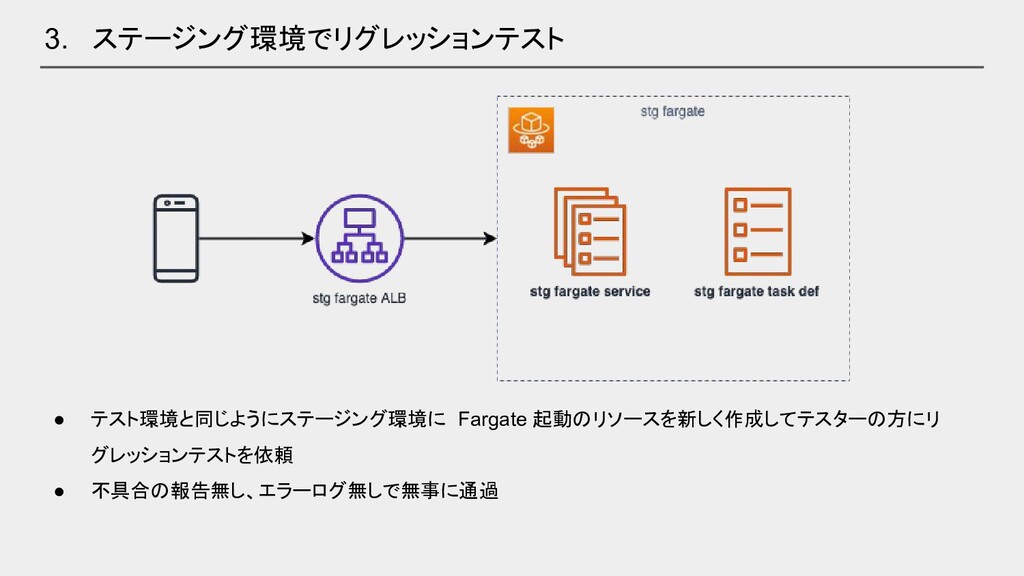
• テスト環境と同じようにステージング環境に Fargate 起動のリソースを新しく作成してテスターの方にリ グレッションテストを依頼 • 不具合の報告無し、エラーログ無しで無事に通過 3. ステージング環境でリグレッションテスト
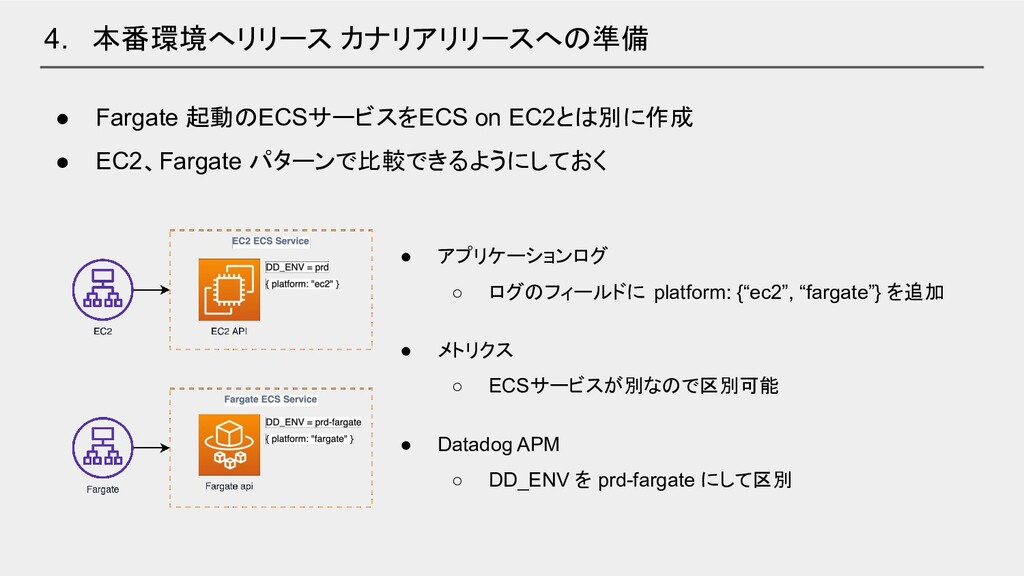
4. 本番環境へリリース カナリアリリースへの準備 • Fargate 起動のECSサービスをECS on EC2とは別に作成 • EC2、Fargate
パターンで比較できるようにしておく • アプリケーションログ ◦ ログのフィールドに platform: {“ec2”, “fargate”} を追加 • メトリクス ◦ ECSサービスが別なので区別可能 • Datadog APM ◦ DD_ENV を prd-fargate にして区別
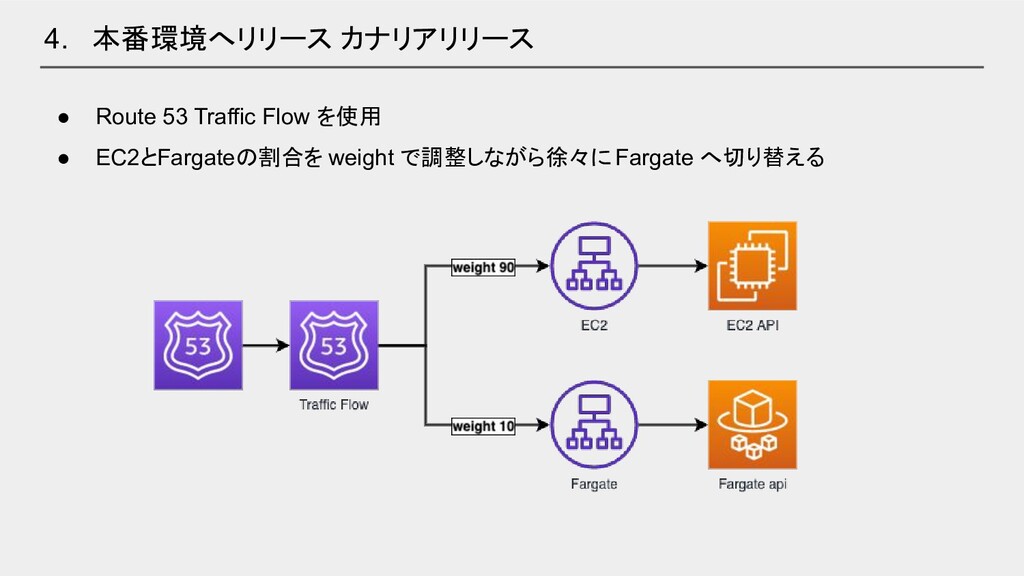
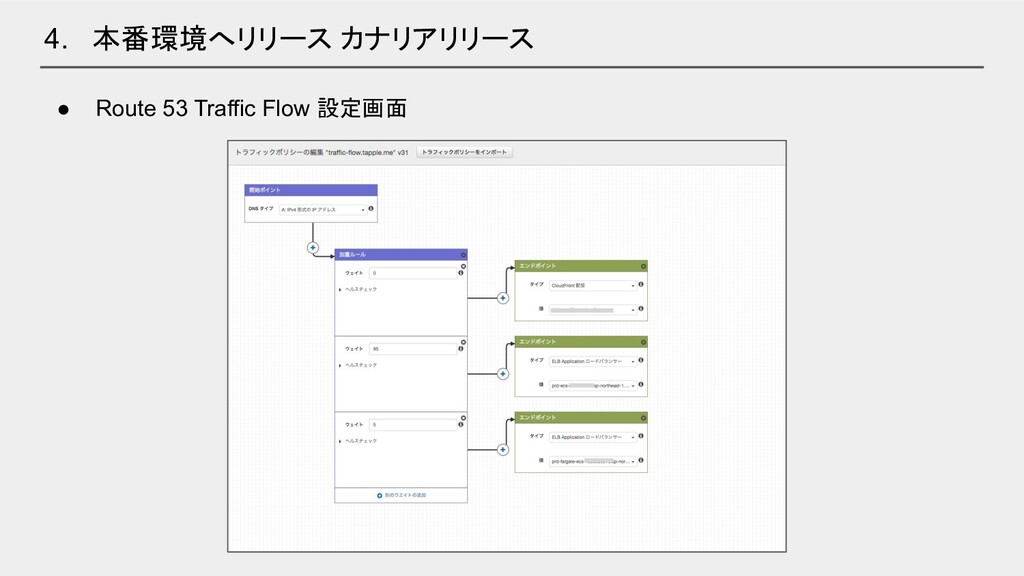
4. 本番環境へリリース カナリアリリース • Route 53 Traffic Flow を使用 •
EC2とFargateの割合を weight で調整しながら徐々に Fargate へ切り替える
4. 本番環境へリリース カナリアリリース • Route 53 Traffic Flow 設定画面
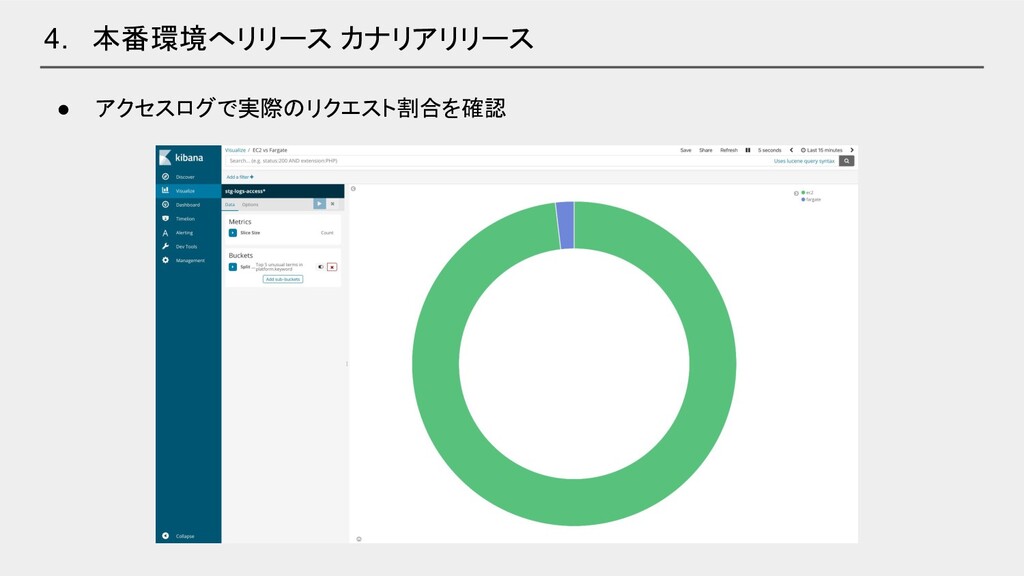
4. 本番環境へリリース カナリアリリース • アクセスログで実際のリクエスト割合を確認
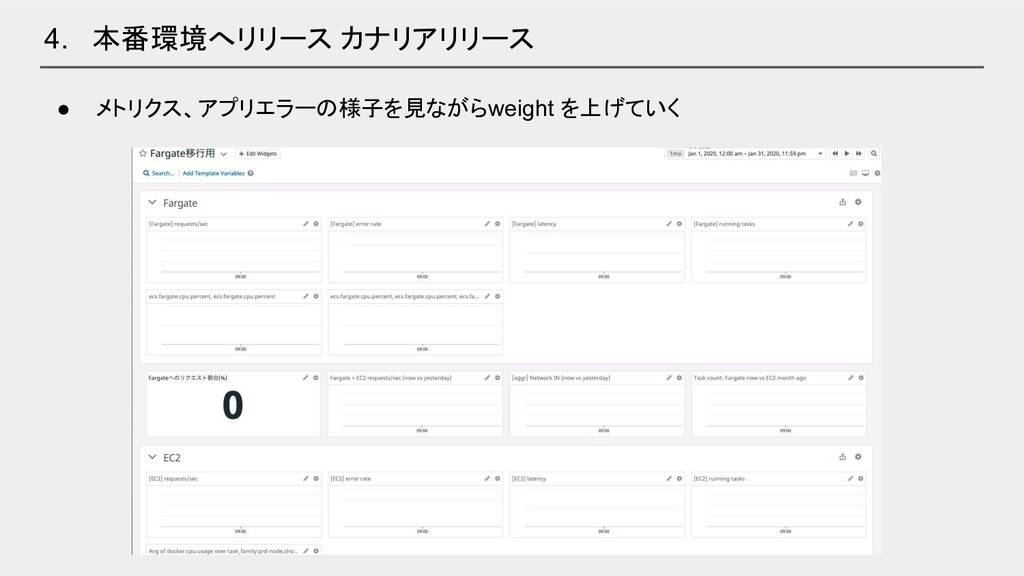
4. 本番環境へリリース カナリアリリース • メトリクス、アプリエラーの様子を見ながら weight を上げていく
4. 本番環境へリリース カナリアリリース • 1週間ほどかけながら徐々に切り替えるスケジュールで進めていた
移行時に発生した問題
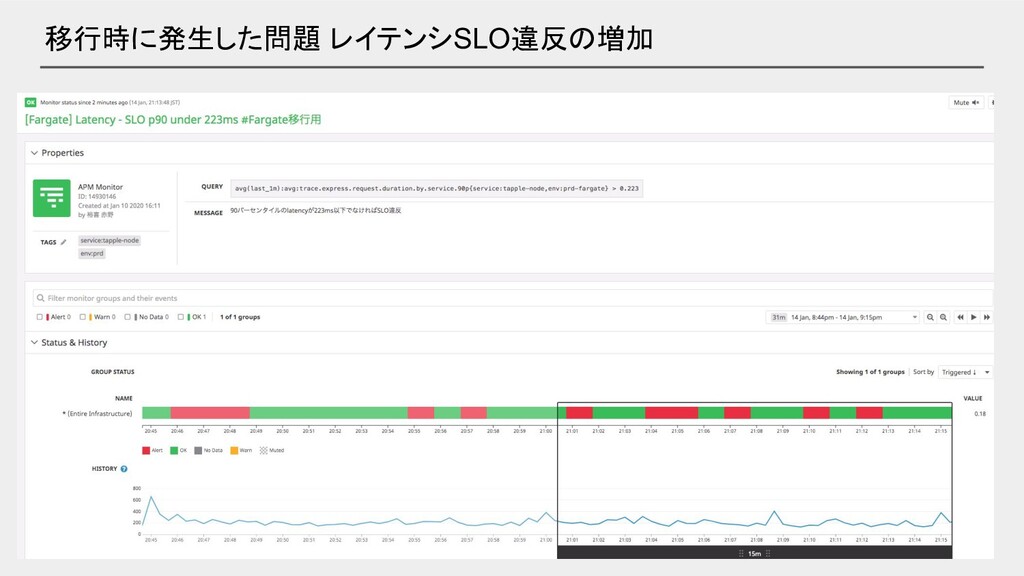
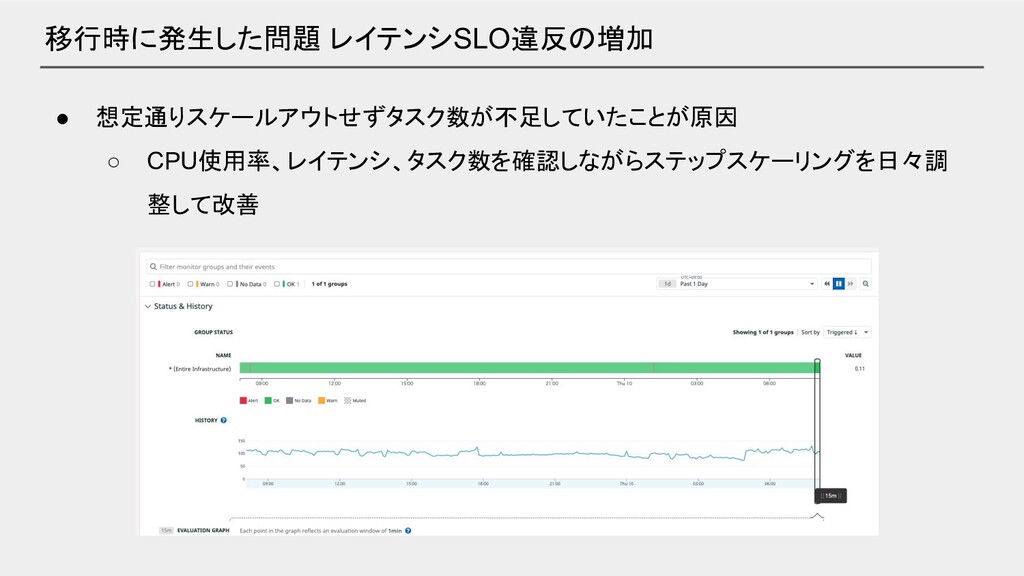
移行時に発生した問題 レイテンシSLO違反の増加
移行時に発生した問題 レイテンシSLO違反の増加 • 想定通りスケールアウトせずタスク数が不足していたことが原因 ◦ CPU使用率、レイテンシ、タスク数を確認しながらステップスケーリングを日々調 整して改善
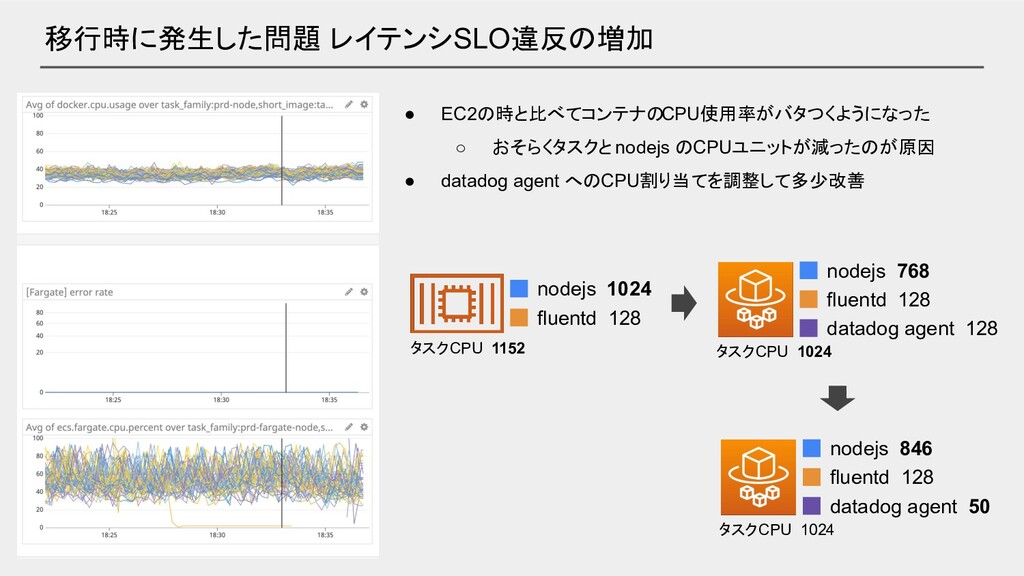
移行時に発生した問題 レイテンシSLO違反の増加 タスクCPU 1024 nodejs 768 fluentd 128 datadog agent
128 nodejs 1024 fluentd 128 • EC2の時と比べてコンテナのCPU使用率がバタつくようになった ◦ おそらくタスクと nodejs のCPUユニットが減ったのが原因 • datadog agent へのCPU割り当てを調整して多少改善 タスクCPU 1024 nodejs 846 fluentd 128 datadog agent 50 タスクCPU 1152
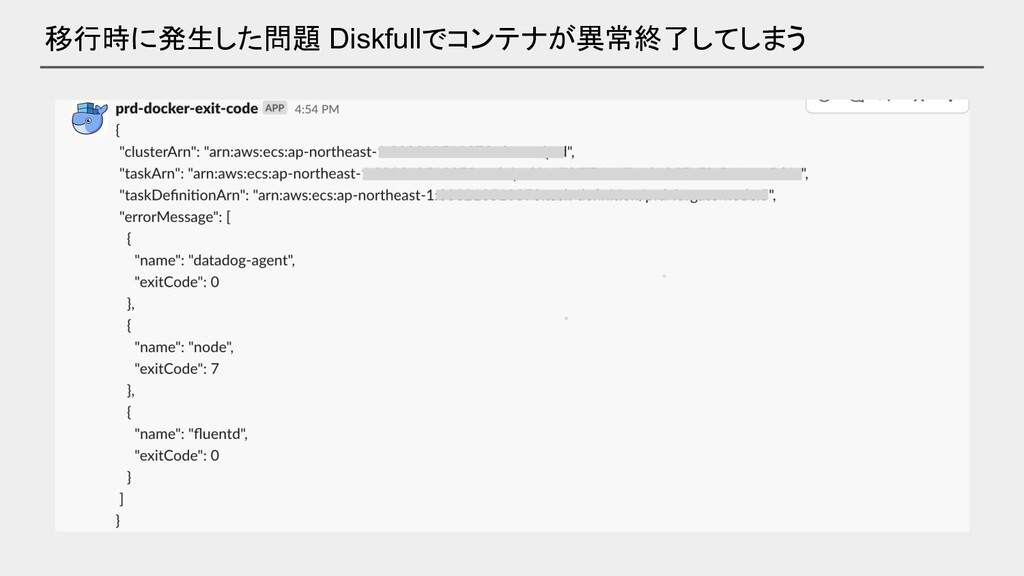
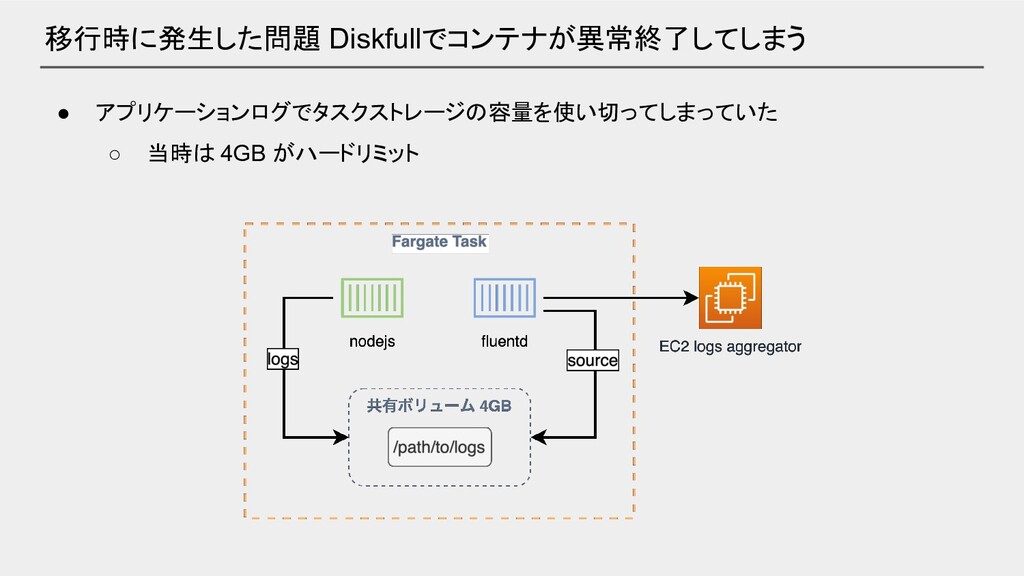
移行時に発生した問題 Diskfullでコンテナが異常終了してしまう
移行時に発生した問題 Diskfullでコンテナが異常終了してしまう • アプリケーションログでタスクストレージの容量を使い切ってしまっていた ◦ 当時は 4GB がハードリミット
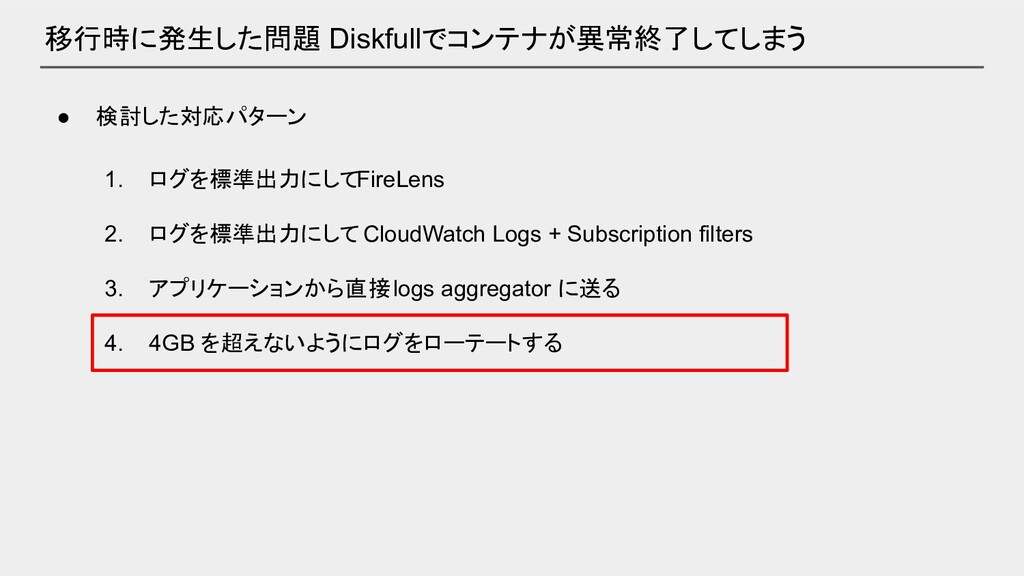
移行時に発生した問題 Diskfullでコンテナが異常終了してしまう • 検討した対応パターン 1. ログを標準出力にしてFireLens 2. ログを標準出力にして CloudWatch Logs
+ Subscription filters 3. アプリケーションから直接 logs aggregator に送る 4. 4GB を超えないようにログをローテートする
移行時に発生した問題 Diskfullでコンテナが異常終了してしまう • 検討した対応パターン 1. ログを標準出力にしてFireLens 2. ログを標準出力にして CloudWatch Logs
+ Subscription filters 3. アプリケーションから直接 logs aggregator に送る 4. 4GB を超えないようにログをローテートする
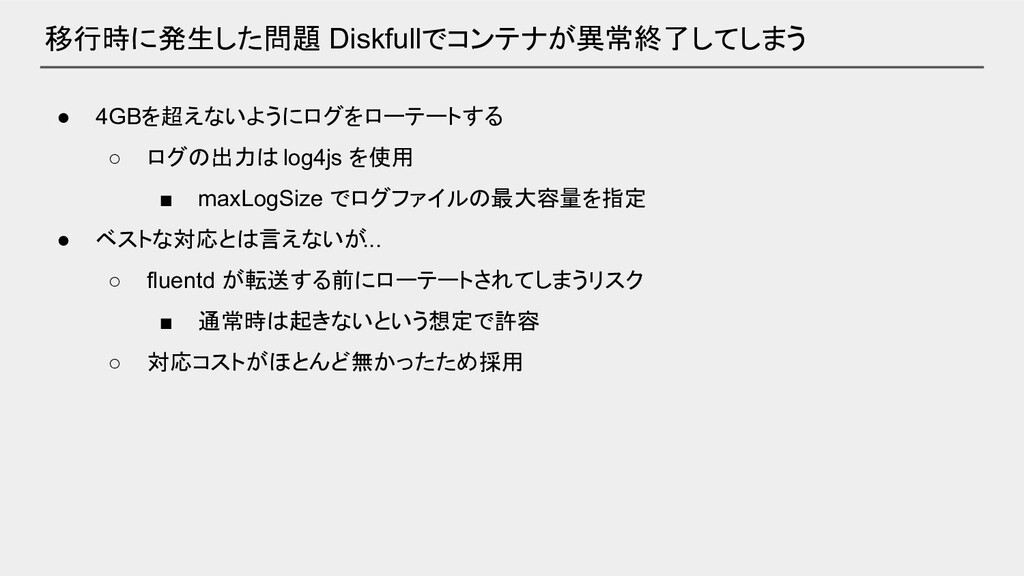
移行時に発生した問題 Diskfullでコンテナが異常終了してしまう • 4GBを超えないようにログをローテートする ◦ ログの出力は log4js を使用 ▪ maxLogSize
でログファイルの最大容量を指定 • ベストな対応とは言えないが... ◦ fluentd が転送する前にローテートされてしまうリスク ▪ 通常時は起きないという想定で許容 ◦ 対応コストがほとんど無かったため採用
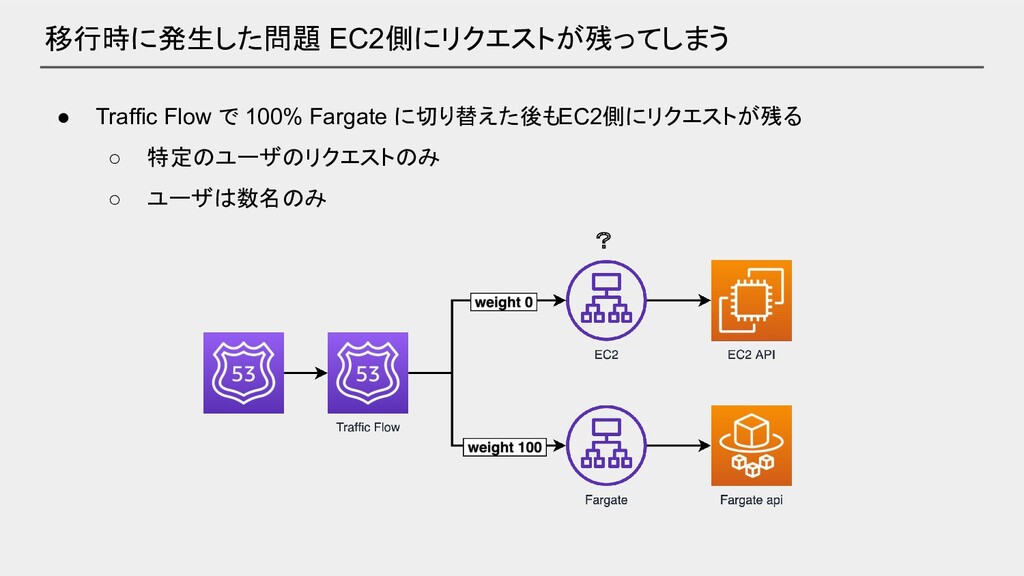
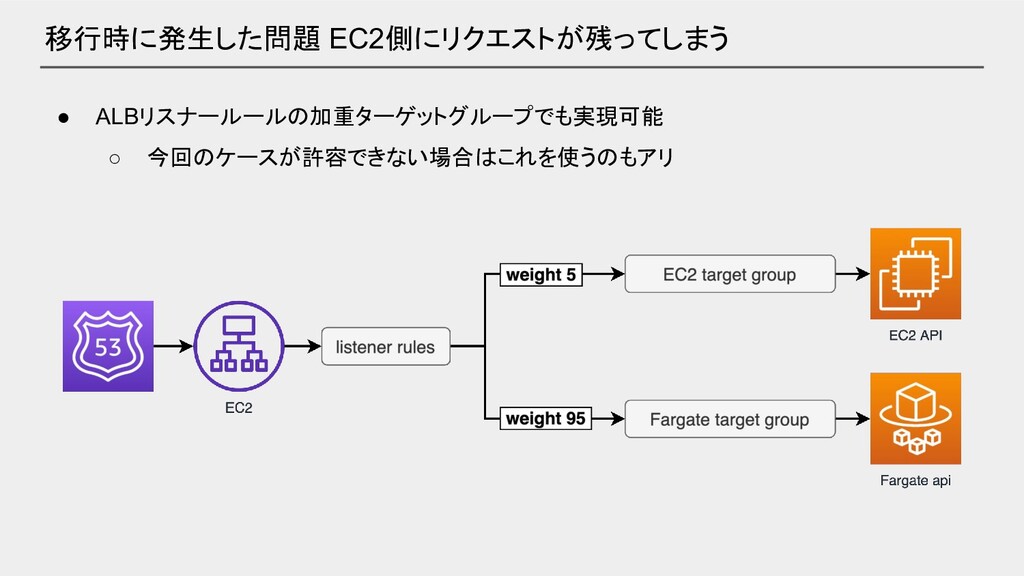
移行時に発生した問題 EC2側にリクエストが残ってしまう • Traffic Flow で 100% Fargate に切り替えた後もEC2側にリクエストが残る ◦
特定のユーザのリクエストのみ ◦ ユーザは数名のみ ?
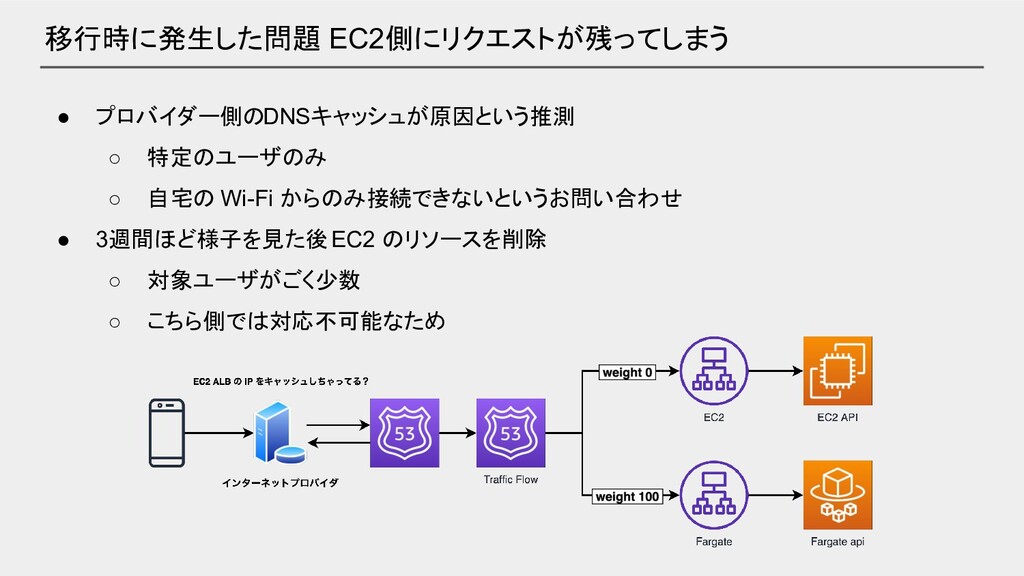
移行時に発生した問題 EC2側にリクエストが残ってしまう • プロバイダー側のDNSキャッシュが原因という推測 ◦ 特定のユーザのみ ◦ 自宅の Wi-Fi からのみ接続できないというお問い合わせ
• 3週間ほど様子を見た後 EC2 のリソースを削除 ◦ 対象ユーザがごく少数 ◦ こちら側では対応不可能なため
移行時に発生した問題 EC2側にリクエストが残ってしまう • ALBリスナールールの加重ターゲットグループでも実現可能 ◦ 今回のケースが許容できない場合はこれを使うのもアリ
コスト💰
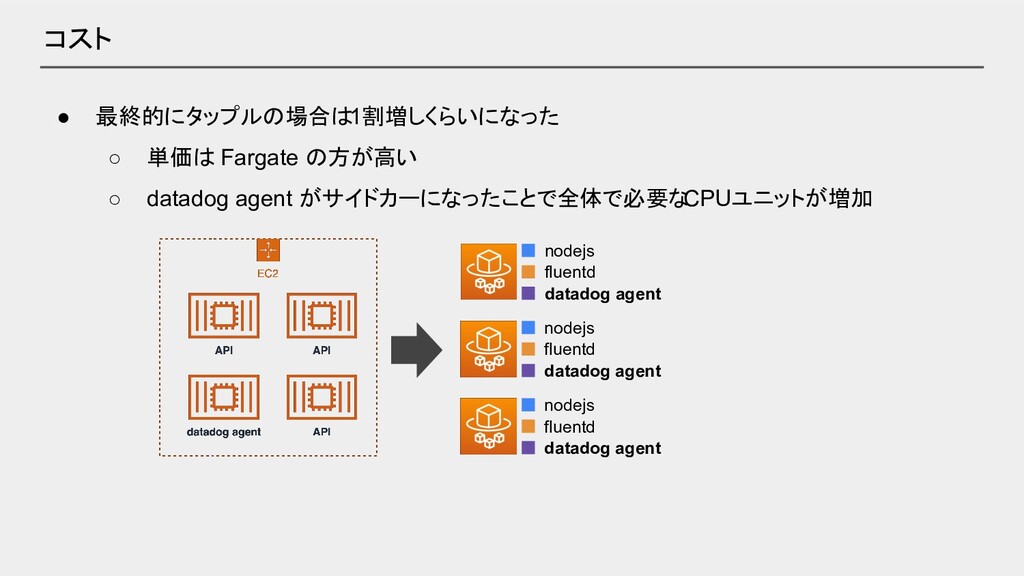
• 最終的にタップルの場合は1割増しくらいになった ◦ 単価は Fargate の方が高い ◦ datadog agent がサイドカーになったことで全体で必要な
CPUユニットが増加 コスト nodejs fluentd datadog agent nodejs fluentd datadog agent nodejs fluentd datadog agent
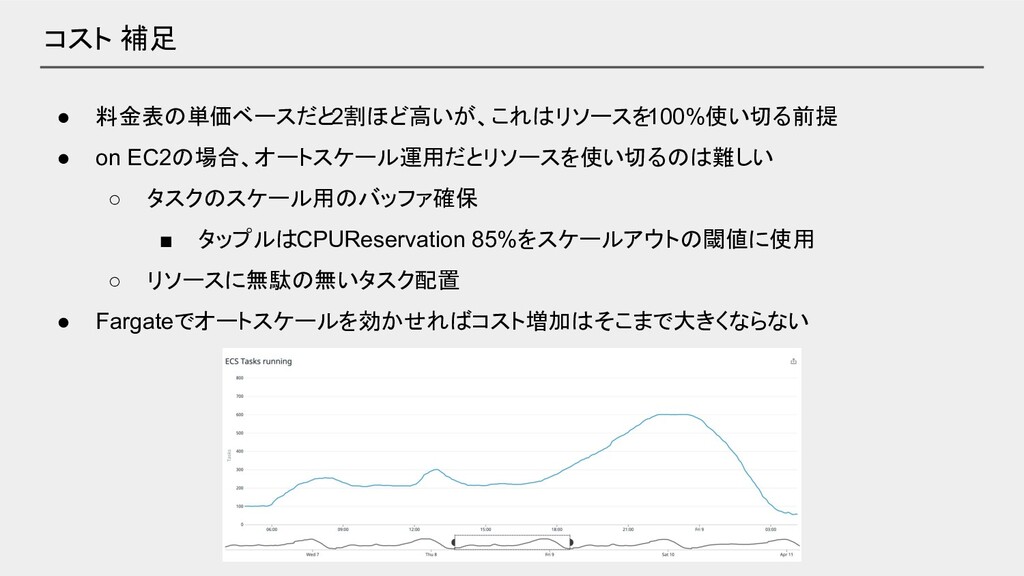
コスト 補足 • 料金表の単価ベースだと2割ほど高いが、これはリソースを 100%使い切る前提 • on EC2の場合、オートスケール運用だとリソースを使い切るのは難しい ◦ タスクのスケール用のバッファ確保
▪ タップルはCPUReservation 85%をスケールアウトの閾値に使用 ◦ リソースに無駄の無いタスク配置 • Fargateでオートスケールを効かせればコスト増加はそこまで大きくならない
運用してきて感じたメリット
運用してきて感じたメリット • デプロイ作業が楽になりスピードも速くなった ◦ EC2を事前にスケールアウトするオペレーションが不要になった ◦ 当時の比較でタスクに入れ替わりが 10分以上 -> 5分
ほどになった • 管理コスト削減 ◦ EC2関連の作業が無くなった • オートスケールが早くなりスパイク耐性が向上した ◦ スパイクアクセス時のレイテンシ悪化が改善した ◦ 定時運用しているPUSH配信の分割数を減らすことができた ▪ PUSH通知の開封率向上に貢献
まとめ
まとめ • 1年以上運用してきて Fargate で問題になったことは無く、移行して良かったと感じている • 当初はコンテナにログインできなくなることに多少の懸念はあったが、今は ECS Exec がある
• コスト増加の部分にもメリットに対して支払ったと思えば不満は無い
ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}