Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
大規模深層学習を支える最先端技術 - GPU と InfiniBand - / 2019-06...
Search
Shinnosuke Furuya
June 14, 2019
Technology
54
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
大規模深層学習を支える最先端技術 - GPU と InfiniBand - / 2019-06-14 Interop Tokyo 2019
Shinnosuke Furuya
June 14, 2019
More Decks by Shinnosuke Furuya
See All by Shinnosuke Furuya
計算力学シミュレーションを支える NVIDIA の最新情報 / 2023-10-26 CMD2023
sfuruyaz
0
470
これからの計算工学に NVIDIA GPU がもたらすものとは -NVIDIA HPC SDK と NVIDIA Modulus の紹介- / 2023-06-01 JSCES
sfuruyaz
0
580
GPU コンピューティングを活用した物性研究 / 2023-04-04 ISSP
sfuruyaz
0
410
GPU で加速される計算力学シミュレーション / 2022-11-16 CMD2022
sfuruyaz
0
660
材料シミュレーションが加速する! GPU コンピューティングの最新情報 / 2022-10-27 SCSK
sfuruyaz
0
80
GTC 2022 Re:Cap / 2022-04-20 JAWS-UG-HPC
sfuruyaz
0
950
GPU で加速される様々なアプリケーション / 2021-11-25 GPU2021
sfuruyaz
0
230
物性シミュレーションのための GPU コンピューティング / 2021-11-24 ISSP
sfuruyaz
0
110
計算力学シミュレーションに GPU は役立つのか? / 2021-09-21 CMD2021
sfuruyaz
0
220
Other Decks in Technology
See All in Technology
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
130
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
220
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
CIで使うClaude
iwatatomoya
0
260
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.4k
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
180
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
1
130
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
13
2k
Claude Code 珍プレー好プレー
shinyasaita
0
330
SRE Next 2026 何でも屋からの脱却
bto
0
730
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
130
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
160
Featured
See All Featured
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
410
Paper Plane (Part 1)
katiecoart
PRO
0
9.6k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
What's in a price? How to price your products and services
michaelherold
247
13k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
330
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
650
Building the Perfect Custom Keyboard
takai
2
810
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
190
Transcript
Shinnosuke Furuya, Ph.D., HPC Developer Relations, NVIDIA, 06/14/2019 ⼤規模深層学習を⽀える最先端技術 -
GPU と InfiniBand -
2 ディープラーニング (深層学習)
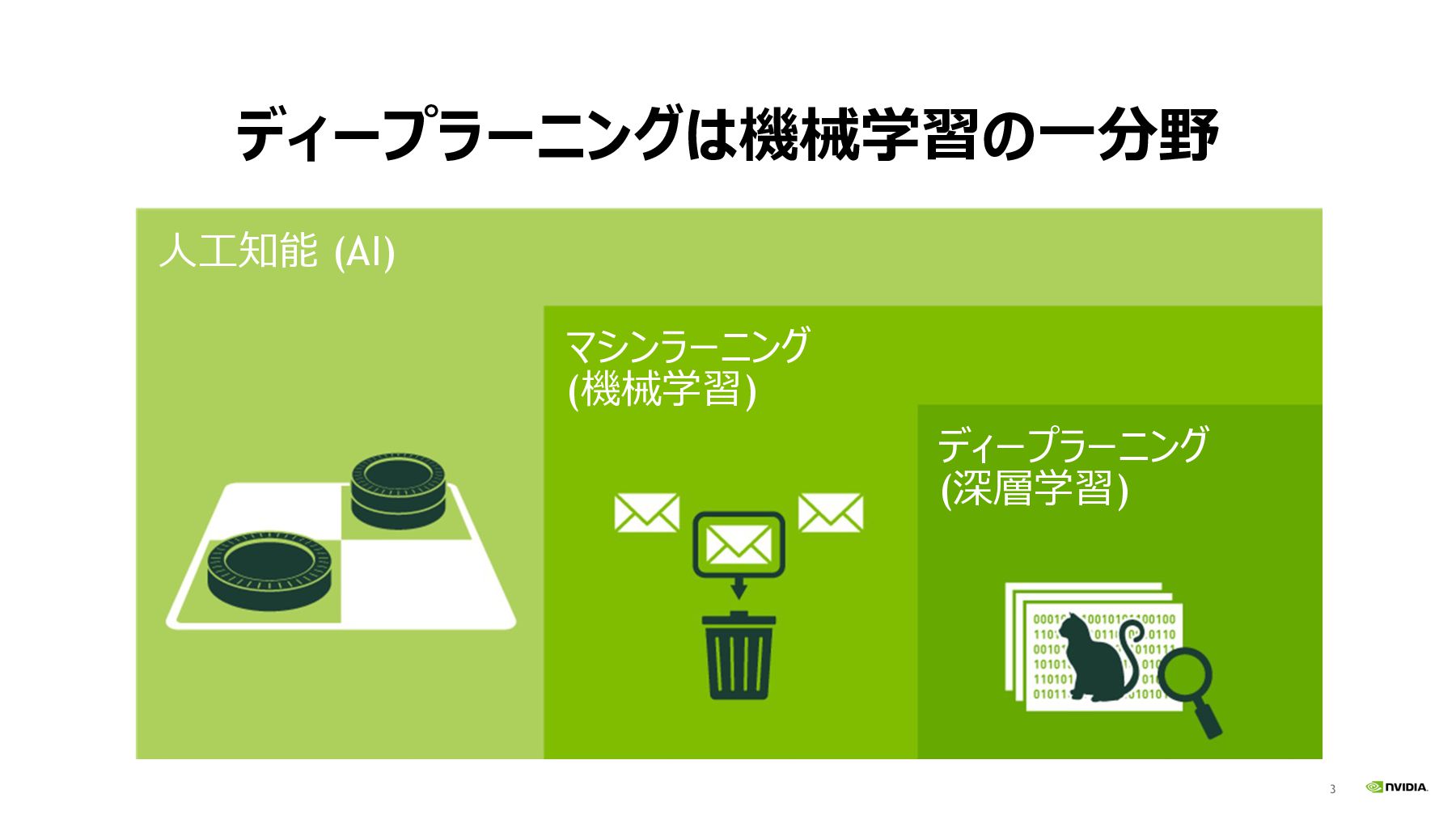
3 ディープラーニングは機械学習の⼀分野 ⼈⼯知能 (AI) ディープラーニング (深層学習) マシンラーニング (機械学習)
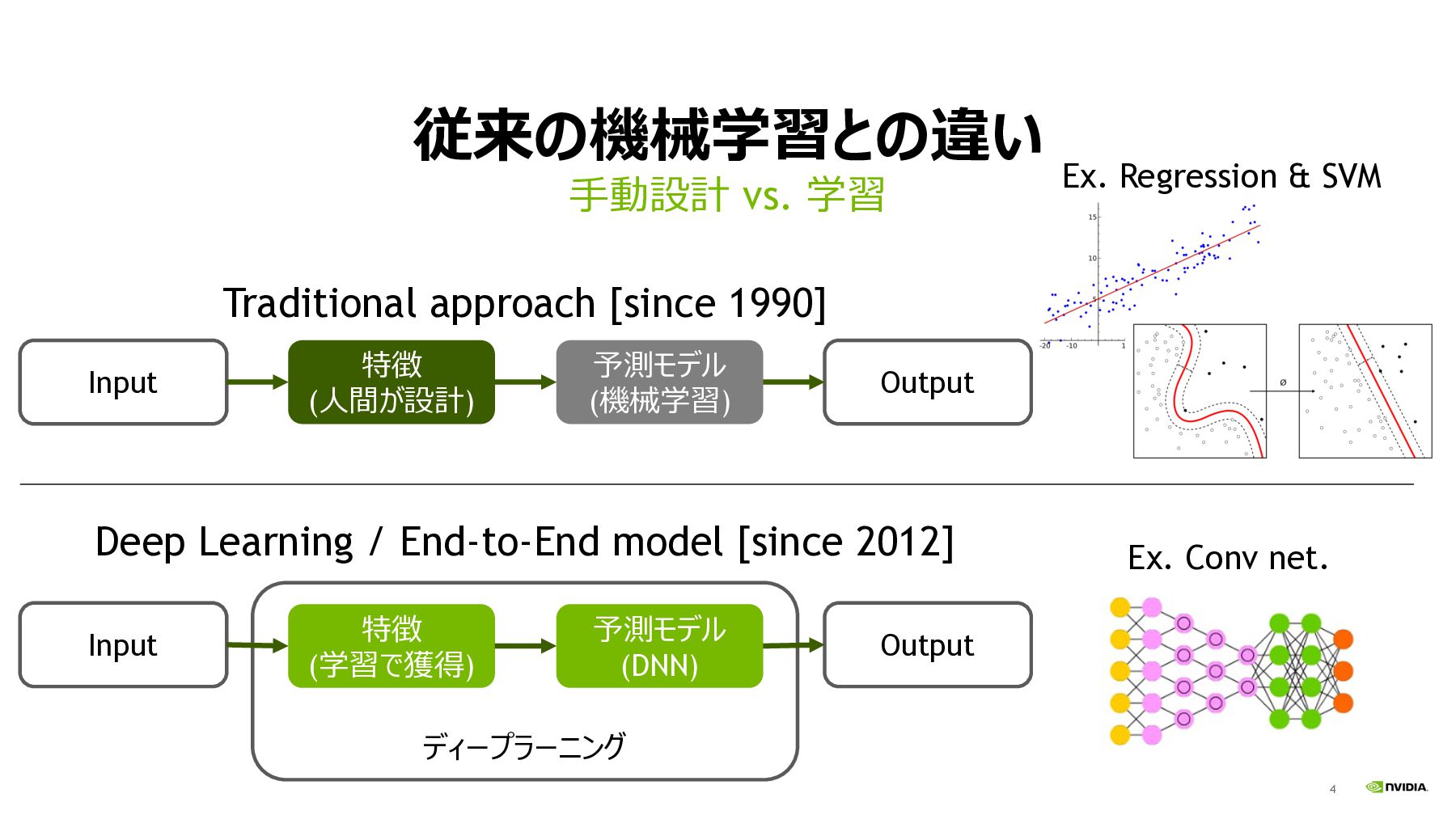
4 従来の機械学習との違い ⼿動設計 vs. 学習 予測モデル (機械学習) 特徴 (⼈間が設計) Input
Output ディープラーニング 予測モデル (DNN) 特徴 (学習で獲得) Input Output Traditional approach [since 1990] Deep Learning / End-to-End model [since 2012] Ex. Conv net. Ex. Regression & SVM
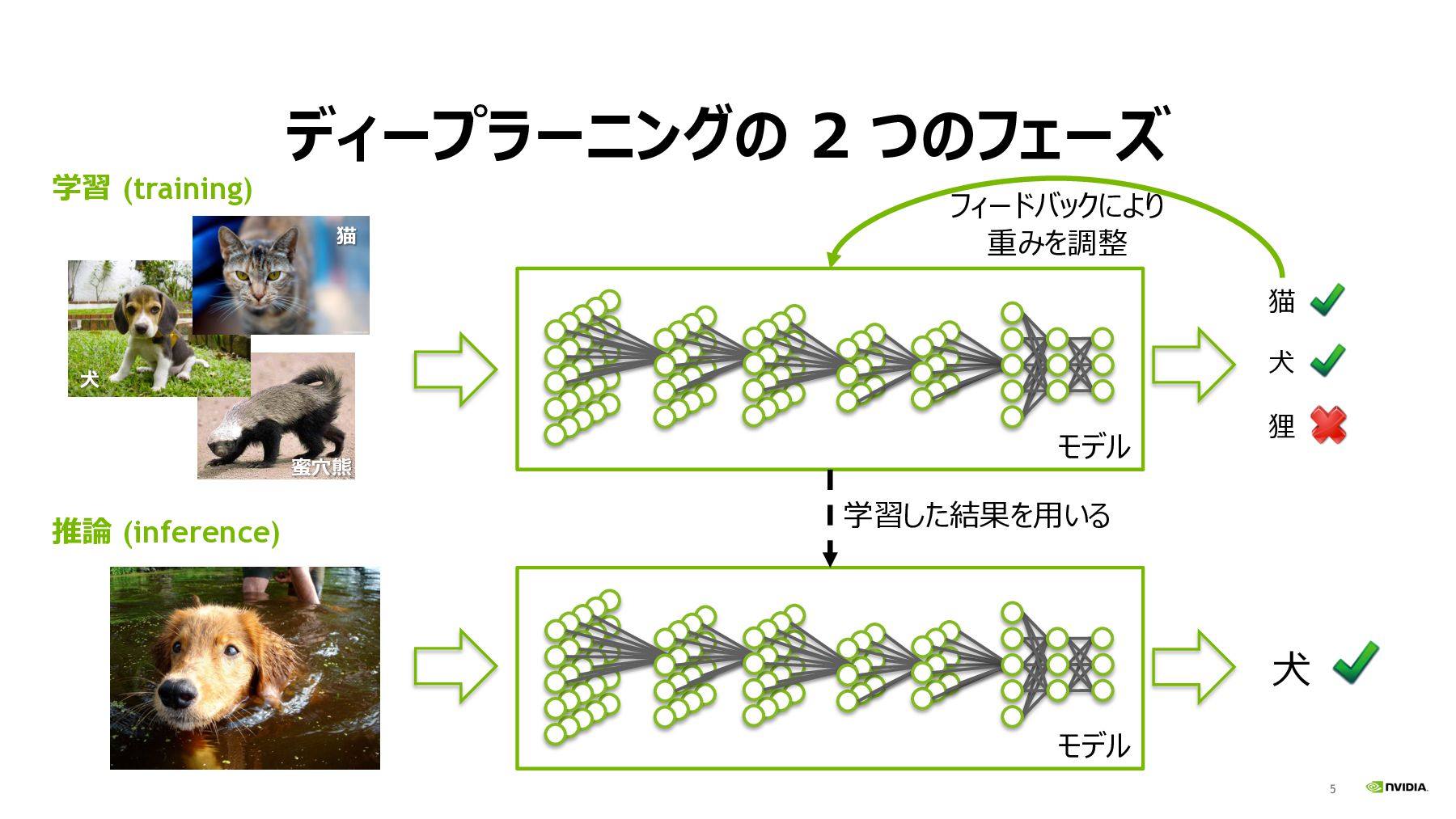
5 ディープラーニングの 2 つのフェーズ モデル ⽝ 推論 (inference) 蜜⽳熊 学習
(training) モデル ⽝ 狸 猫 フィードバックにより 重みを調整 学習した結果を⽤いる ⽝ 猫
6 ディープラーニングを加速する 3 つの要因 “Google’s AI engine also reflects how
the world of computer hardware is changing. (It) depends on machines equipped with GPUs… And it depends on these chips more than the larger tech universe realizes.” DNN BIG DATA GPU
7 NVIDIA TESLA プラットフォーム
8 NVIDIA GPU 製品のおおまかな⼀覧 Maxwell (2014) Pascal (2016) Volta (2017)
GeForce ゲーミング Quadro プロフェッショナル グラフィックス M40 M6000 GTX 980 HPC ⽤ GRID ⽤ DL ⽤ M60 GP100 P5000 Kepler (2012) K6000 GTX 780 K80 K2 K520 GTX 1080 TITAN X V100 データセンタ & クラウド Tesla P40 P100 P6 TITAN V Fermi (2010) M2070 6000 GTX 580 P4 GV100 M6 M10 Turing (2018) RTX 8000 RTX 2080 Ti T4
9 NVIDIA TESLA V100 AI と HPC のための⼤きな⾶躍 TENSOR コアを搭載した
VOLTA アーキテクチャ 210 億トランジスタ | TSMC 12nm FFN | 815mm2 5120 CUDA コア 7.8 FP64 TFLOPS | 15.7 FP32 TFLOPS 125 Tensor TFLOPS 総レジスタファイル 20MB | 16MB キャッシュ 900 GB/s の 32GB HBM2 300 GB/s NVLink
10 NVIDIA DGX SYSTEMS DGX-2 DGX Station DGX-1 2 Tensor
PFLOPS 500 Tensor TFLOPS 1 Tensor PFLOPS 16x Tesla V100 4x Tesla V100 8x Tesla V100 NVSwitch 接続 NVLink 全結合 NVLink ハイブリッドキューブ 8x IB EDR | 2x 100GbE 2x 10GbE 4x IB EDR | 2x 10GbE
11 5 年間で 500 倍 2 個の GeForce GTX 580
(2012年 12⽉) フレームワーク システム ソフトウェア スタック cuda-convnet NCCL N/A cuDNN N/A cuBLAS 5.0 cuFFT 5.0 NPP 5.0 CUDA 5.0 Res Mgr R304 DGX-2 (2018年 3⽉) AlexNet フレームワーク システム ソフトウェア スタック NV Caffe 0.17 NCCL 2.2 cuDNN 7.1 cuBLAS 9.2 cuFFT 9.2 NPP 9.2 CUDA 9.2 Res Mgr R396 0 2 4 6 8 2 個の GTX 580 DGX-2 AlexNet を学習する時間 6 日 18 分
12 GPU スパコン
13 スパコンランキング TOP500 上位 5/10 が GPU スパコン システム名 概要
サイト ピーク性能 (TFlops) 1 Summit IBM POWER9, NVIDIA Tesla V100, Mellanox IB EDR アメリカ 143,500.0 2 Sierra IBM POWER9, NVIDIA Tesla V100, Mellanox IB EDR アメリカ 94,640.0 5 Piz Daint Intel Xeon, NVIDIA Tesla P100, Cray Aries interconnect スイス 21,230.0 7 ABCI Intel Xeon, NVIDIA Tesla V100, Mellanox IB EDR ⽇本 19,880.0 9 Titan AMD Opteron, NVIDIA Tesla K20x, Cray Gemini interconnect アメリカ 17,590.0 Source: https://www.top500.org
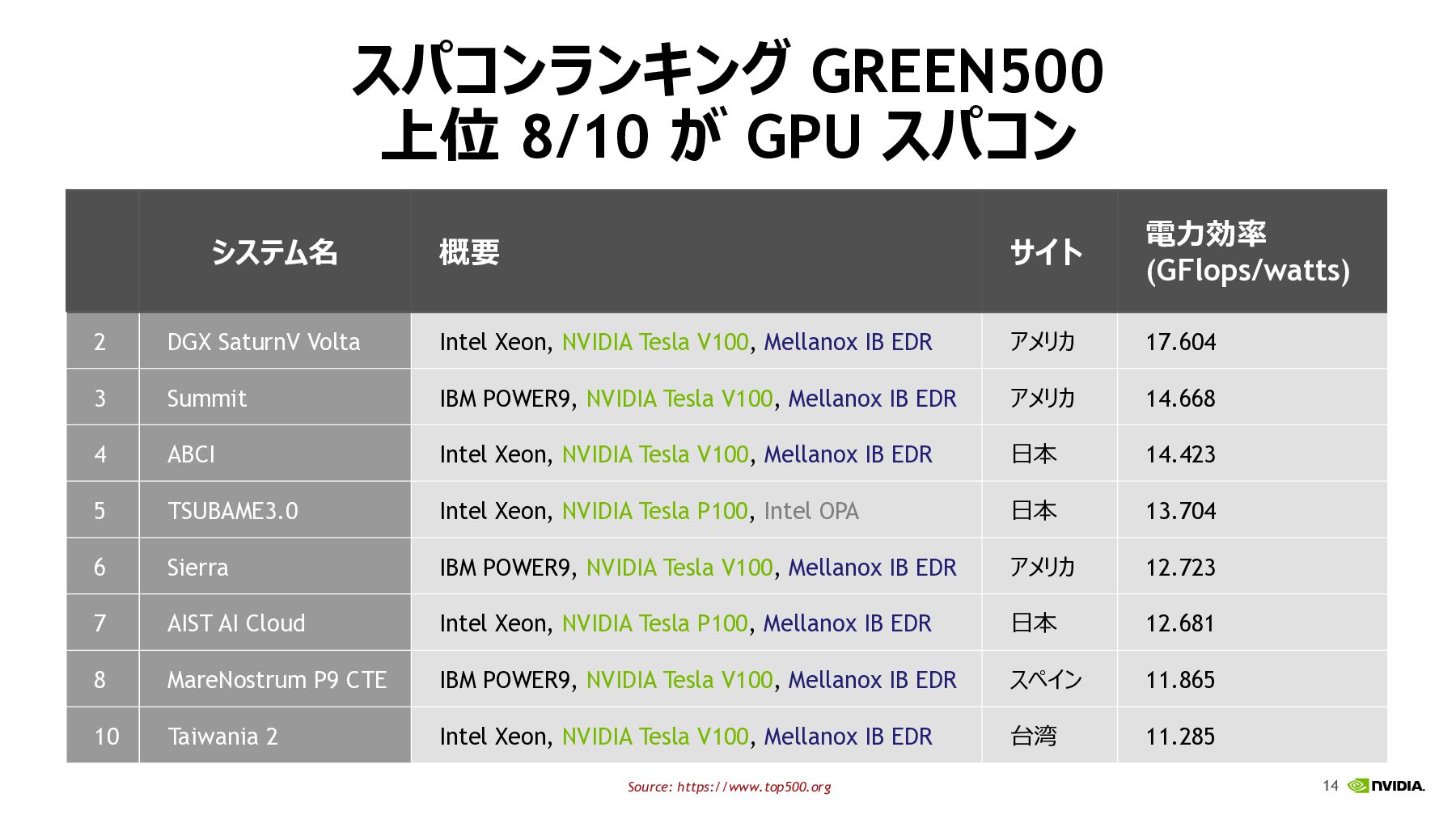
14 スパコンランキング GREEN500 上位 8/10 が GPU スパコン システム名 概要
サイト 電⼒効率 (GFlops/watts) 2 DGX SaturnV Volta Intel Xeon, NVIDIA Tesla V100, Mellanox IB EDR アメリカ 17.604 3 Summit IBM POWER9, NVIDIA Tesla V100, Mellanox IB EDR アメリカ 14.668 4 ABCI Intel Xeon, NVIDIA Tesla V100, Mellanox IB EDR ⽇本 14.423 5 TSUBAME3.0 Intel Xeon, NVIDIA Tesla P100, Intel OPA ⽇本 13.704 6 Sierra IBM POWER9, NVIDIA Tesla V100, Mellanox IB EDR アメリカ 12.723 7 AIST AI Cloud Intel Xeon, NVIDIA Tesla P100, Mellanox IB EDR ⽇本 12.681 8 MareNostrum P9 CTE IBM POWER9, NVIDIA Tesla V100, Mellanox IB EDR スペイン 11.865 10 Taiwania 2 Intel Xeon, NVIDIA Tesla V100, Mellanox IB EDR 台湾 11.285 Source: https://www.top500.org
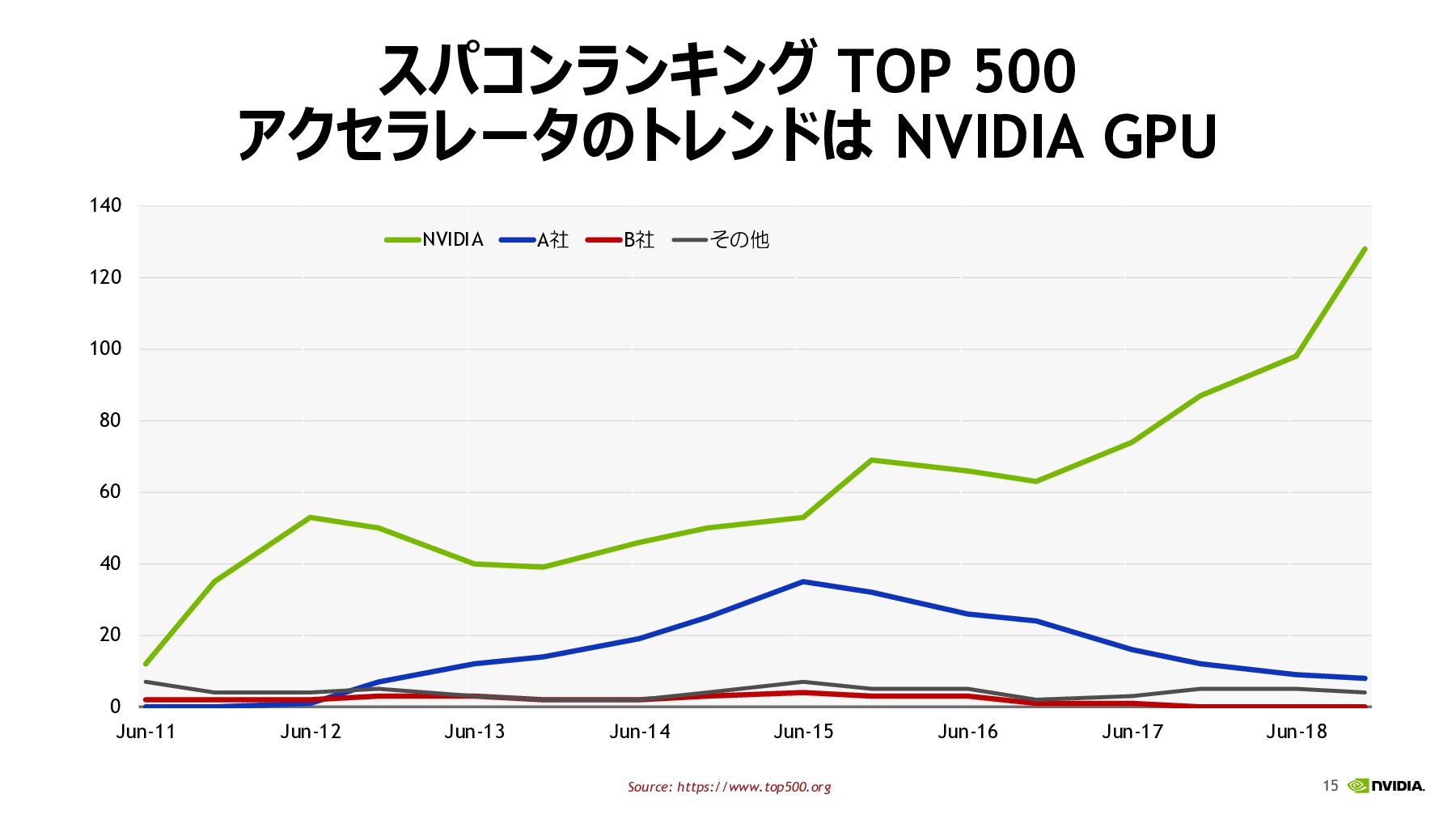
15 スパコンランキング TOP 500 アクセラレータのトレンドは NVIDIA GPU 0 20 40
60 80 100 120 140 Jun-11 Jun-12 Jun-13 Jun-14 Jun-15 Jun-16 Jun-17 Jun-18 NVIDIA A社 B社 その他 Source: https://www.top500.org
16 ⼤規模深層学習
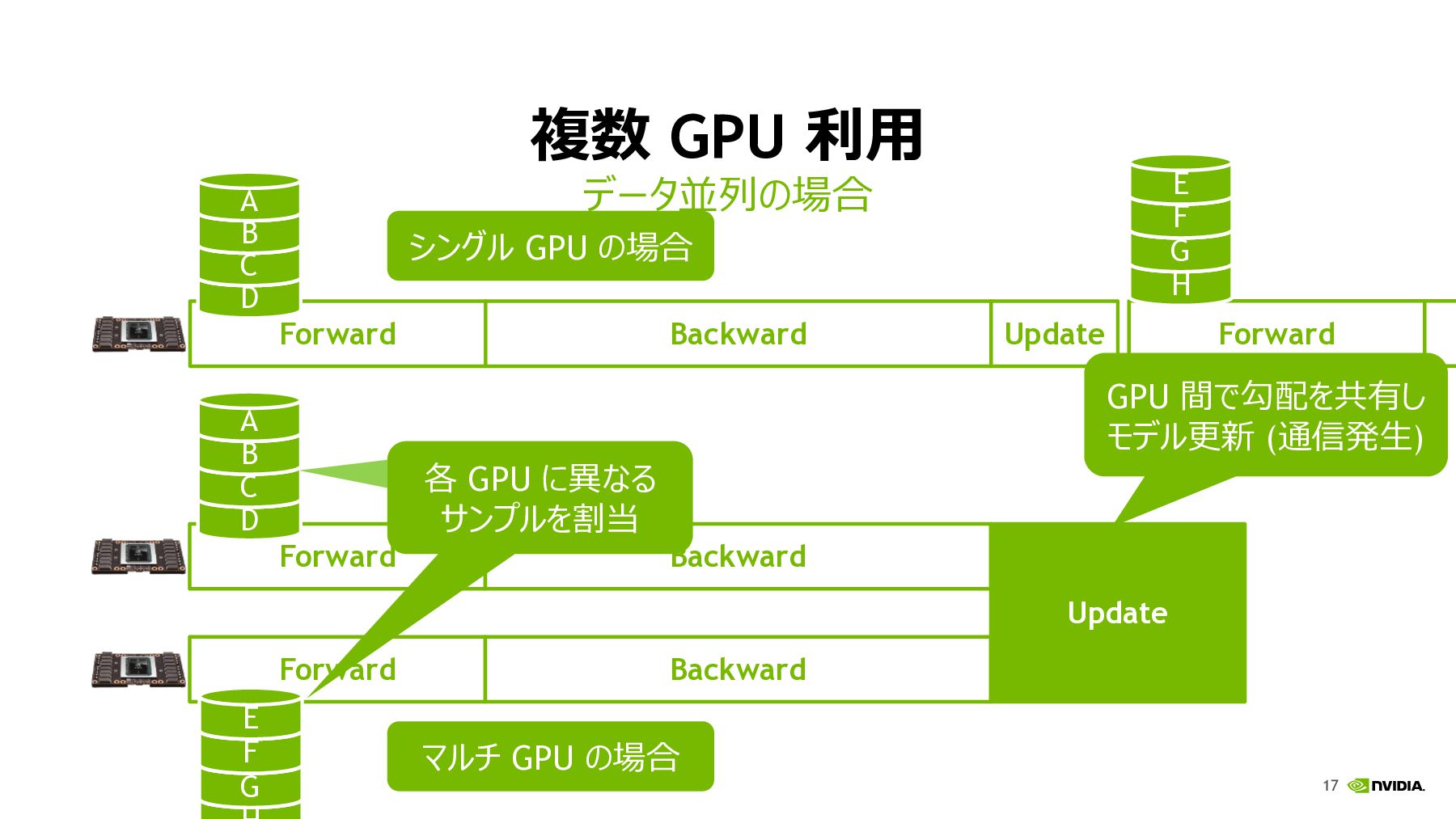
17 複数 GPU 利⽤ データ並列の場合 マルチ GPU の場合 Forward Backward
Forward Backward Update D C B A G F E 各 GPU に異なる サンプルを割当 シングル GPU の場合 Forward Backward Update Forward H G F E GPU 間で勾配を共有し モデル更新 (通信発⽣) D C B A
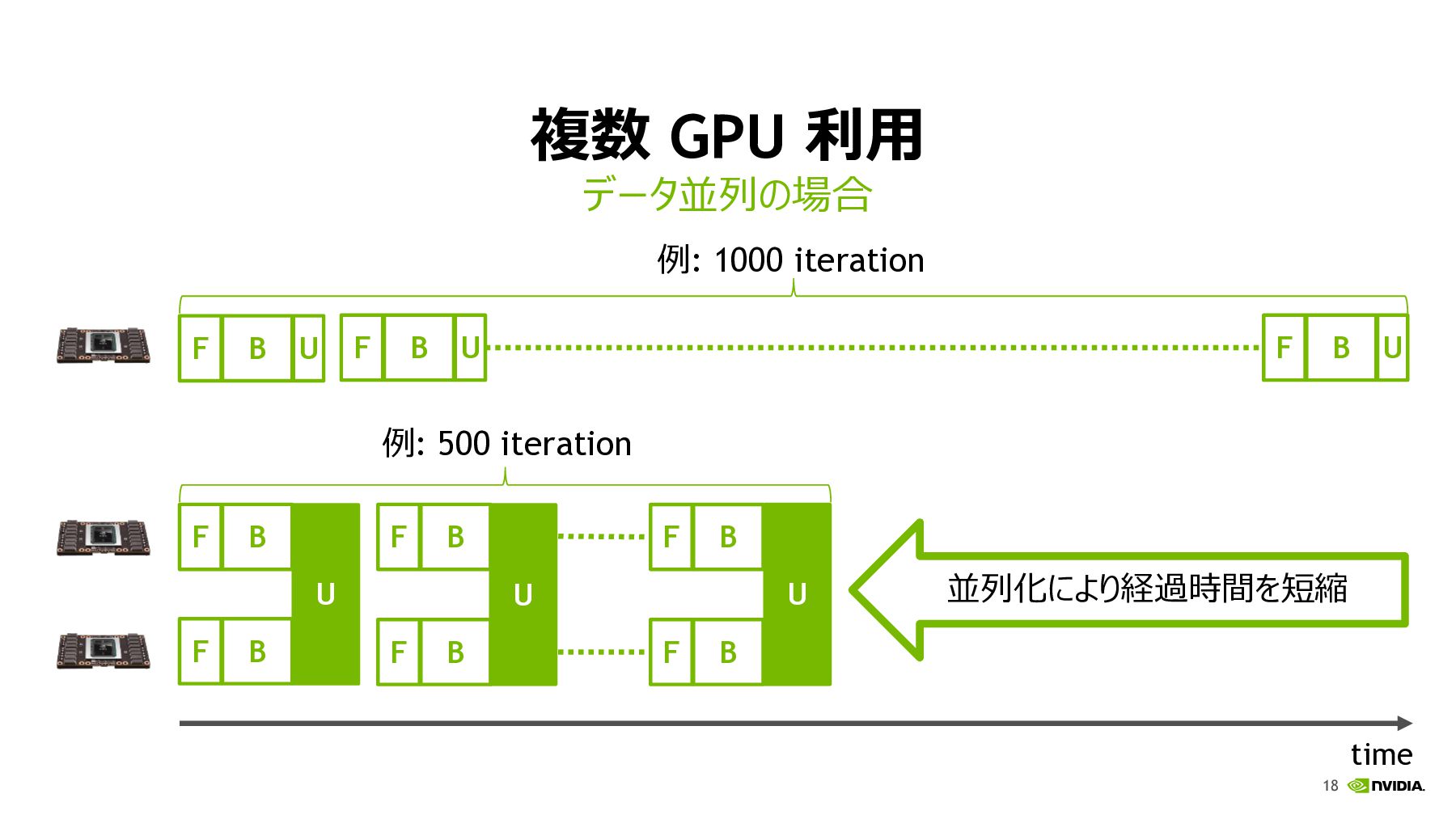
18 データ並列の場合 複数 GPU 利⽤ time F B U F
B U F B U 例: 1000 iteration F B U F B 例: 500 iteration F B F B U F B F B U 並列化により経過時間を短縮
19 ⼤規模深層学習の実施 計算量が多く⼤量の GPU が必要 ⼩規模 : DGX-1 が 1
台 ノード間通信なし ⼩〜中規模 : DGX-2 が 1 台 ノード間通信なし ⼤規模 : DGX-2 が 16 台 ノード間通信が発⽣ x8 x16 x 256 ノード内は NVLink で超⾼速に結合、ノード間は InfiniBand で⾼速に結合
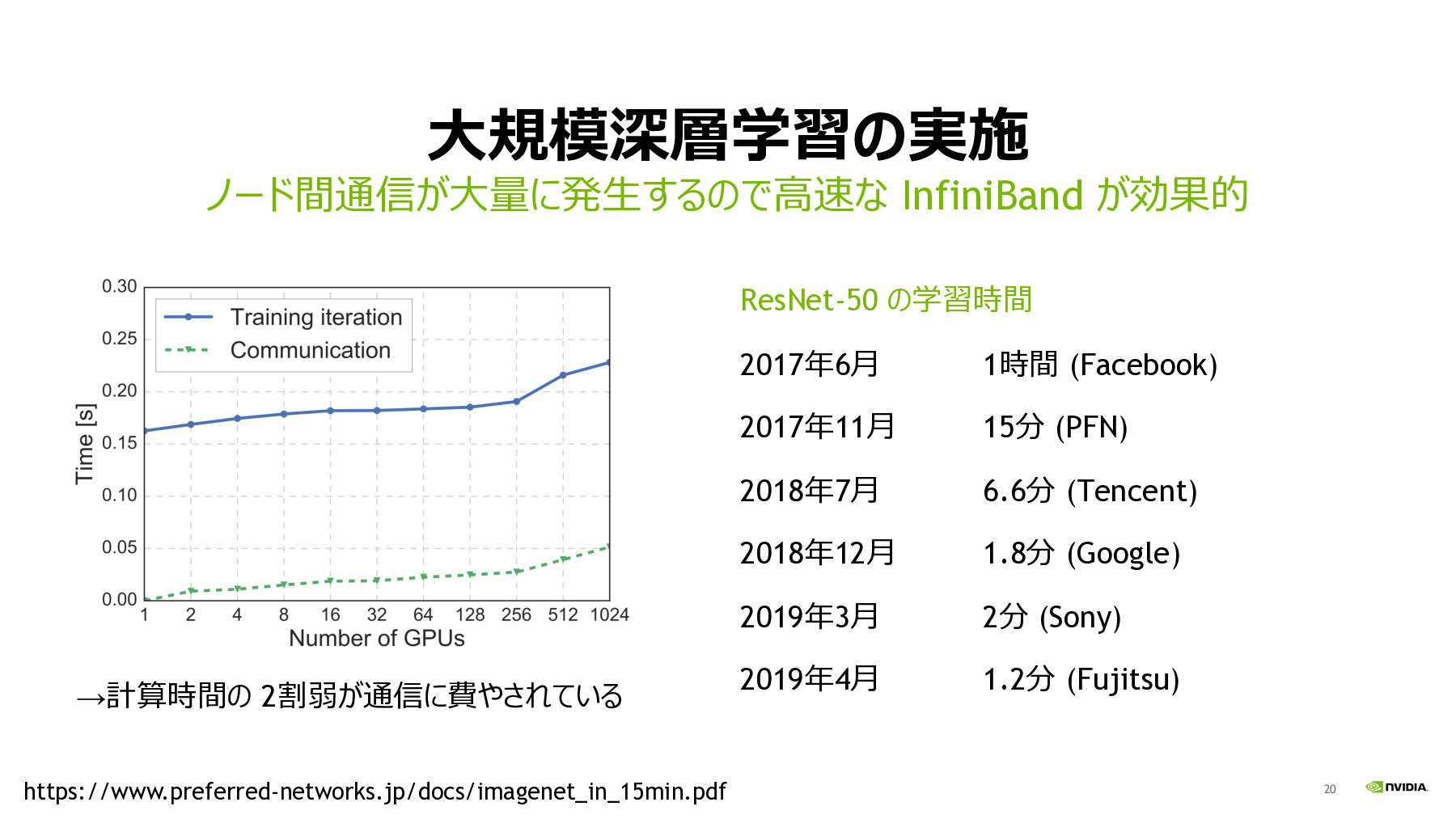
20 ⼤規模深層学習の実施 ResNet-50 の学習時間 2017年6⽉ 1時間 (Facebook) 2017年11⽉ 15分 (PFN)
2018年7⽉ 6.6分 (Tencent) 2018年12⽉ 1.8分 (Google) 2019年3⽉ 2分 (Sony) 2019年4⽉ 1.2分 (Fujitsu) ノード間通信が⼤量に発⽣するので⾼速な InfiniBand が効果的 https://www.preferred-networks.jp/docs/imagenet_in_15min.pdf →計算時間の 2割弱が通信に費やされている
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}