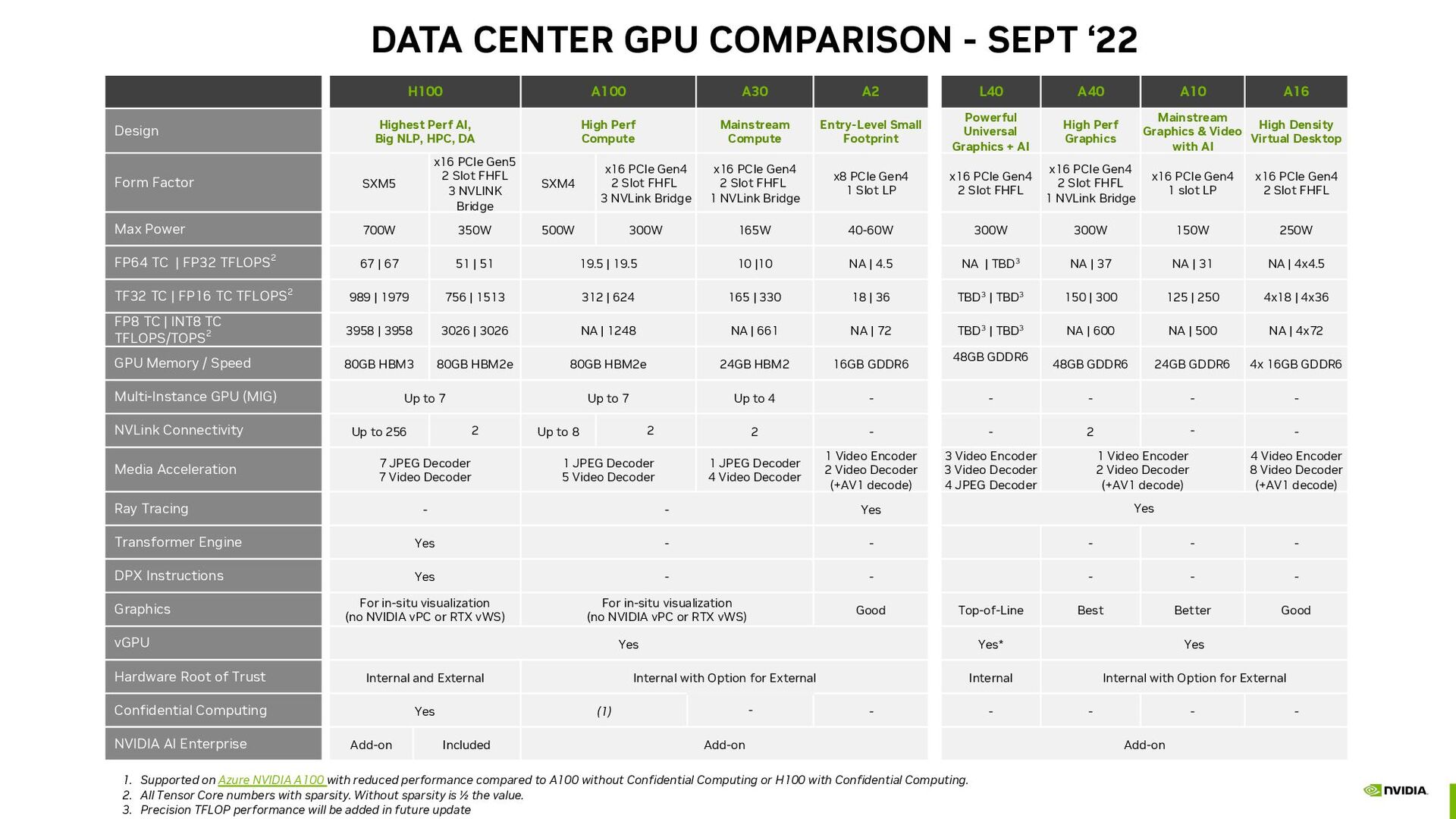
Gen NVLink Transformer Engine 2nd Gen MIG Confidential Computing DPX Instructions World’s Most Advanced Chip H100 PCIE Includes NVIDIA AI Enterprise H100 SXM NVIDIA AI Enterprise is a 5-Year Subscription
Tensor Core FLOPs shown with sparsity | Speedups compared to prior generation HIGHEST PERFORMANCE FOR AI AND HPC 4-way / 8-way H100 GPUs with 32 PetaFLOPs FP8 3.6 TFLOPs FP16 in-network SHARP Compute NVIDIA Certified High-Performance Offering from All Makers FASTEST, SCALABLE INTERCONNECT 4th Gen NVLINK with 3X faster All-Reduce communications 3.6 TB/s bisection bandwidth NVLINK Switch System Option Scales Up to 256 GPUs SECURE COMPUTING First HGX System with Confidential Computing
and deploy enterprise AI with unmatched performance, security, and scalability 5-YEAR SUBSCRIPTION OF NVIDIA AI ENTERPRISE A cloud native software suite for development and deployment of AI NVIDIA ENTERPRISE SUPPORT Including access to NVIDIA AI experts, priority notifications of the latest security fixes and maintenance releases ENTERPRISE TRAINING SERVICES Developers, data scientists, and IT professionals learn how to get the most out of the NVIDIA AI platform Software activation: www.nvidia.com/activate-h100
and NVIDIA L40 Highlights • 3rd Gen RT Cores, 4th-Gen Tensor Cores • Up to 2x faster Graphics and AI training performance than Ampere • Up to 2x the single-precision floating-point throughput over the Ampere, support for FP8 format • 3x Encode & 3x Decode - support for AV1 Enc/Dec • 48GB of GDDR6 ECC memory for working with the largest 3D models, renderings, simulation, and AI datasets
performance vs. Ampere Generation • Powerful Compute and AI • Accelerated Rendering, Training, and Inference • Data Center Ready • Secure and Measure Boot w. RoT Available starting in December 2022 Unprecedented visual computing performance for the data center *Preliminary specifications, subject to change
most demanding industries & workloads • Most powerful professional GPU ever • 2X the performance of the A6000 • RTX A6000 will still be available • For customers needing NVLink/largest possible GPU memory • Available from channel partners starting in December • Anticipate OEM availability early in 2023 Ada for the enterprise *Preliminary specifications, subject to change
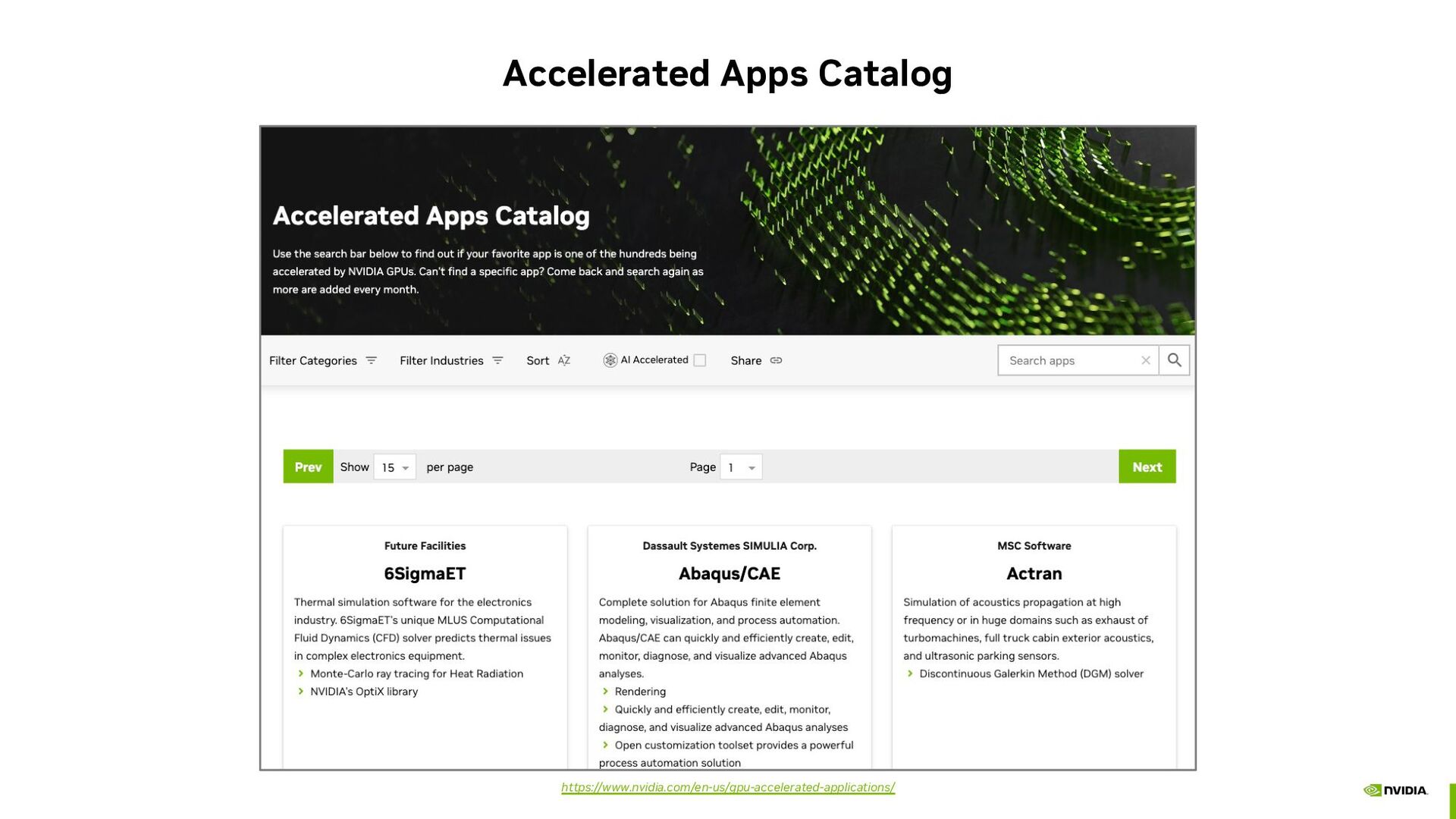
Computational Structural Mechanics • Actran • Discontinuous Galaerkin Method solver • Altair AcuSolve • Linear solvers for flow, temperature, turbulence model, and mesh movement equations • Altair EDEM • EDEM Simulator, a DEM solver | Integration with Ansys and Abaqus for FEA for bulk material simulation | Integration with Adams, Siemens and RecurDyn for Multi-body Dynamics | Integration with Ansys Fluent for Particle-Fluid Systems • Altair nanoFluidX • Extremely fast | Single and Multiphase Flows | Arbitrary motion definition | Time-dependent acceleration | Inlets/outlets | Surface tension and adhension | Steady-state thermal solutions through coupling • Altair OptiStruct • Direct Solver | Eigenvalue solvers | Iterative solver • Altair ultraFluidX • CUDA-accelerated high-fidelity flow field computations based on the Lattice Boltzmann method | CUDA-aware MPI support for multi-GPU and multi-node usage | Efficient implementation of tailor-made automotive features, including rotating wheels, belt systems, boundary layer suction and porous media support • Ansys Fluent • Linear equation solver | Radiation heat transfer model | Discrete Ordinate Radiation model • Ansys Icepak • Linear Equation Solver • Ansys Mechanical • Direct and iterative solvers • Ansys Polyflow • Direct Solvers • MSC Nastran • Direct sparse solver • Particleworks • Explicit and Implicit methods • Rocky DEM • Explicit DEM solver | 1-way & 2-way coupling with ANSYS Fluent and ANSYS Mechanical • Simcenter STAR-CCM+ • Steady and unsteady, constant density flows using the segregatd flow solver on Linux only | Compatible with most turbulence models, RANS, DDES and Reynolds Stress Models | OpenGL based Rendering • Simulia Abaqus/Standard • Direct sparse solver | AMS Solver | Steady State Dynamics • XFlow • Single & Multiphase flow | Enforced motion | Adaptive refinement https://www.nvidia.com/en-us/gpu-accelerated-applications/
GPUs for Ansys Fluent, Part 1 • https://www.ansys.com/blog/unleashing-the-full-power-of-gpus-for-ansys-fluent • 32X Speed Up for Automotive External Aerodynamics • Laminar Flow Over a Sphere • Backward Facing Step • Unleashing the Full Power of GPUs for Ansys Fluent, Part 2 • https://www.ansys.com/blog/unleashing-the-full-power-of-gpus-for-ansys-fluent-part-2 • Speeding Up CFD Simulations of All Sizes • Air Flow Through a Porous Filter • Thermal Management Using Conjugate Heat Transfer Modeling (CHT) • Water-Cooled Traction Inverter • Louvered-fin Heat Exchanger • Vertical Mounted Heat Sink • Revolutionizing CFD Simulations Through GPUs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}