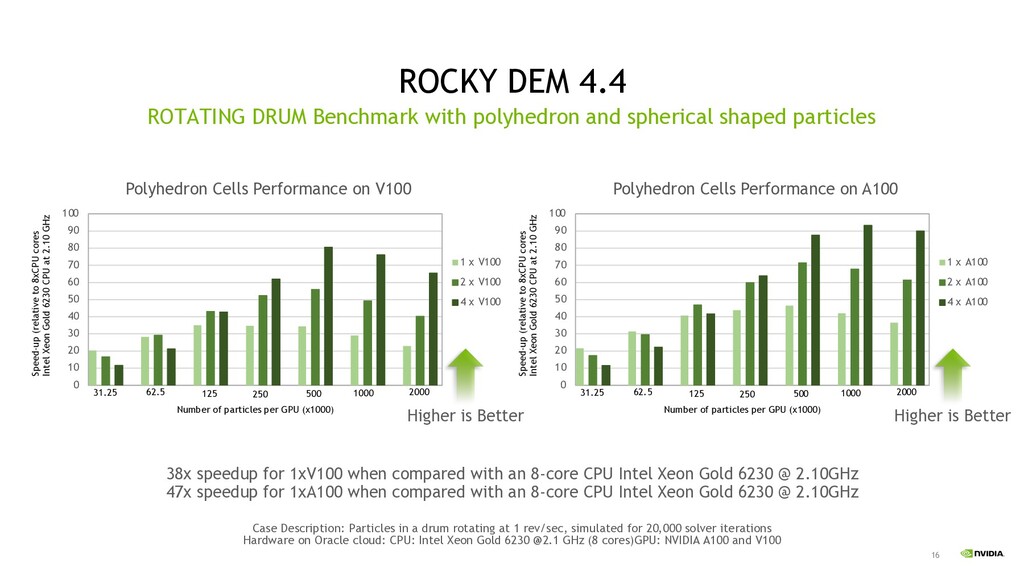
spherical shaped particles 0 10 20 30 40 50 60 70 80 90 100 Polyhedron Cells Performance on V100 1 x V100 2 x V100 4 x V100 Speed-up (relative to 8xCPU cores Intel Xeon Gold 6230 CPU at 2.10 GHz 31.25 62.5 125 250 500 1000 2000 Number of particles per GPU (x1000) 0 10 20 30 40 50 60 70 80 90 100 Polyhedron Cells Performance on A100 1 x A100 2 x A100 4 x A100 Speed-up (relative to 8xCPU cores Intel Xeon Gold 6230 CPU at 2.10 GHz 31.25 62.5 125 250 500 1000 2000 Number of particles per GPU (x1000) Higher is Better Higher is Better 38x speedup for 1xV100 when compared with an 8-core CPU Intel Xeon Gold 6230 @ 2.10GHz 47x speedup for 1xA100 when compared with an 8-core CPU Intel Xeon Gold 6230 @ 2.10GHz Case Description: Particles in a drum rotating at 1 rev/sec, simulated for 20,000 solver iterations Hardware on Oracle cloud: CPU: Intel Xeon Gold 6230 @2.1 GHz (8 cores)GPU: NVIDIA A100 and V100
HPC Applications FASTEST INTERCONNECTS >900 GB/s Cache Coherent NVLink CPU To GPU (14x) >600GB/s CPU To CPU (2x) NEXT GENERATION ARM NEOVERSE CORES >300 SPECrate2017_int_base est. Availability 2023 HIGHEST MEMORY BANDWIDTH >500GB/s LPDDR5x w/ ECC >2x Higher B/W 10x Higher Energy Efficiency
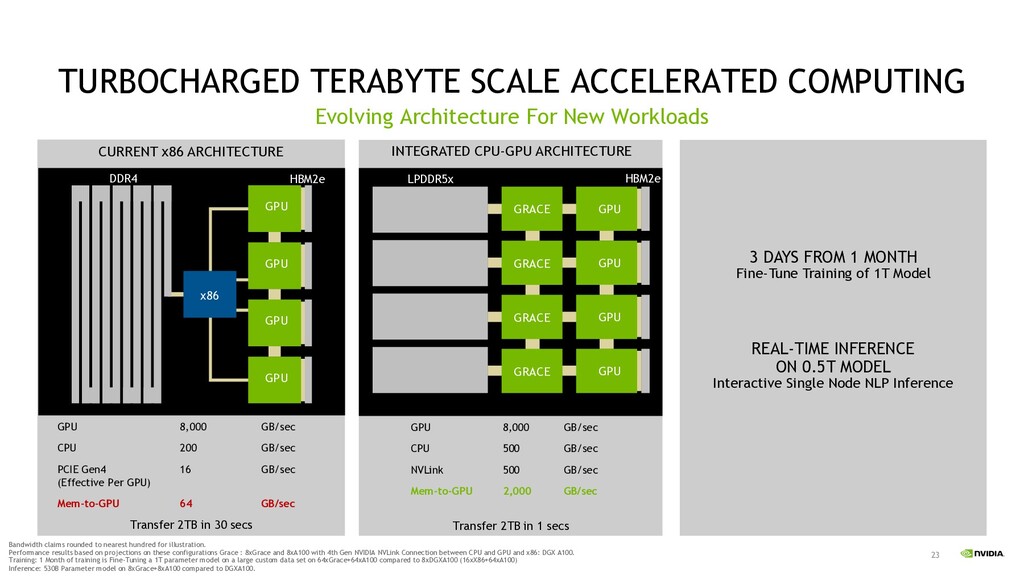
Workloads CURRENT x86 ARCHITECTURE DDR4 HBM2e INTEGRATED CPU-GPU ARCHITECTURE LPDDR5x HBM2e 3 DAYS FROM 1 MONTH Fine-Tune Training of 1T Model GPU GPU GPU GPU GRACE GRACE GRACE GRACE GPU GPU GPU GPU x86 Transfer 2TB in 30 secs Transfer 2TB in 1 secs GPU 8,000 GB/sec CPU 200 GB/sec PCIE Gen4 (Effective Per GPU) 16 GB/sec Mem-to-GPU 64 GB/sec GPU 8,000 GB/sec CPU 500 GB/sec NVLink 500 GB/sec Mem-to-GPU 2,000 GB/sec REAL-TIME INFERENCE ON 0.5T MODEL Interactive Single Node NLP Inference Bandwidth claims rounded to nearest hundred for illustration. Performance results based on projections on these configurations Grace : 8xGrace and 8xA100 with 4th Gen NVIDIA NVLink Connection between CPU and GPU and x86: DGX A100. Training: 1 Month of training is Fine-Tuning a 1T parameter model on a large custom data set on 64xGrace+64xA100 compared to 8xDGXA100 (16xX86+64xA100) Inference: 530B Parameter model on 8xGrace+8xA100 compared to DGXA100.
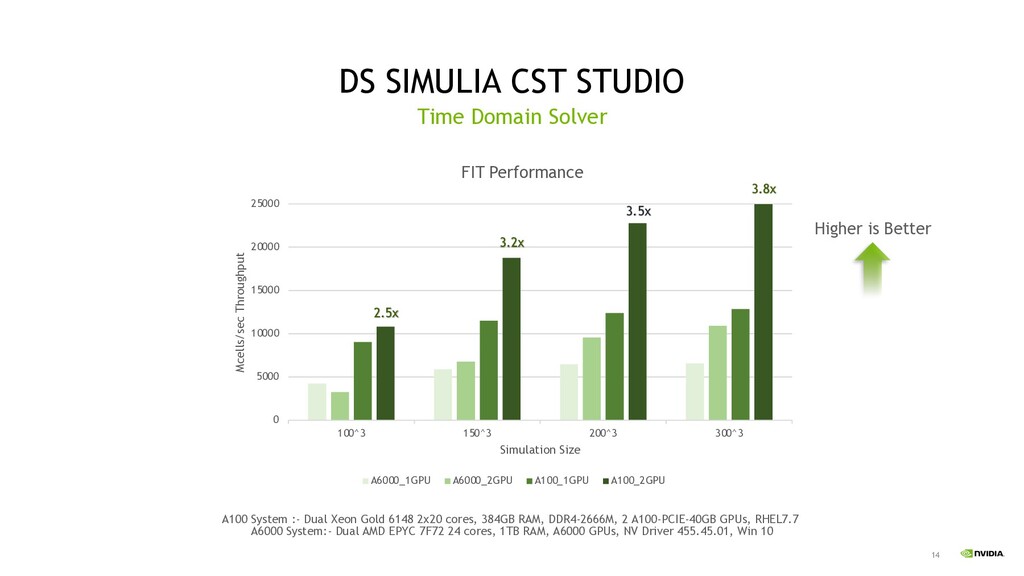
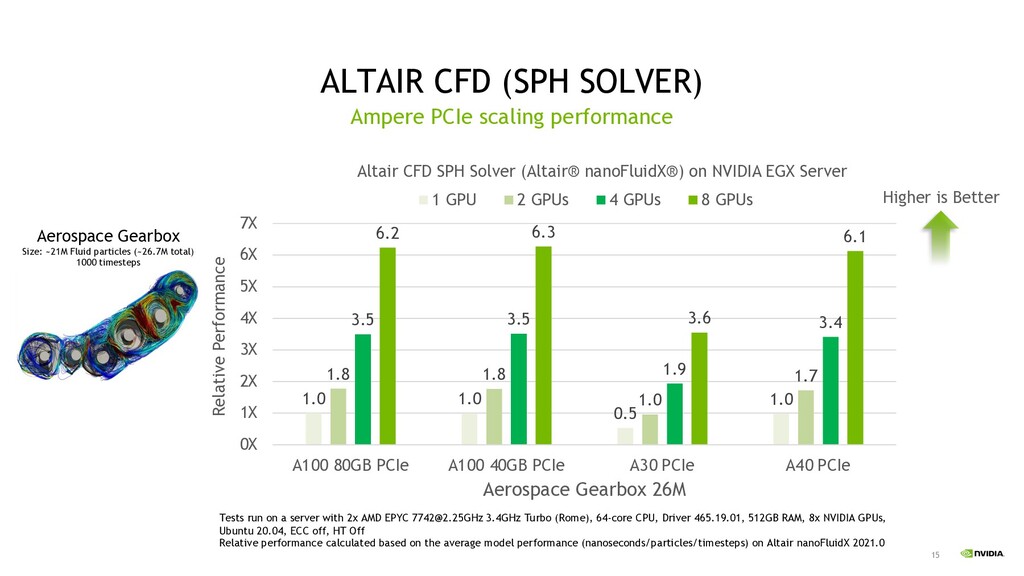
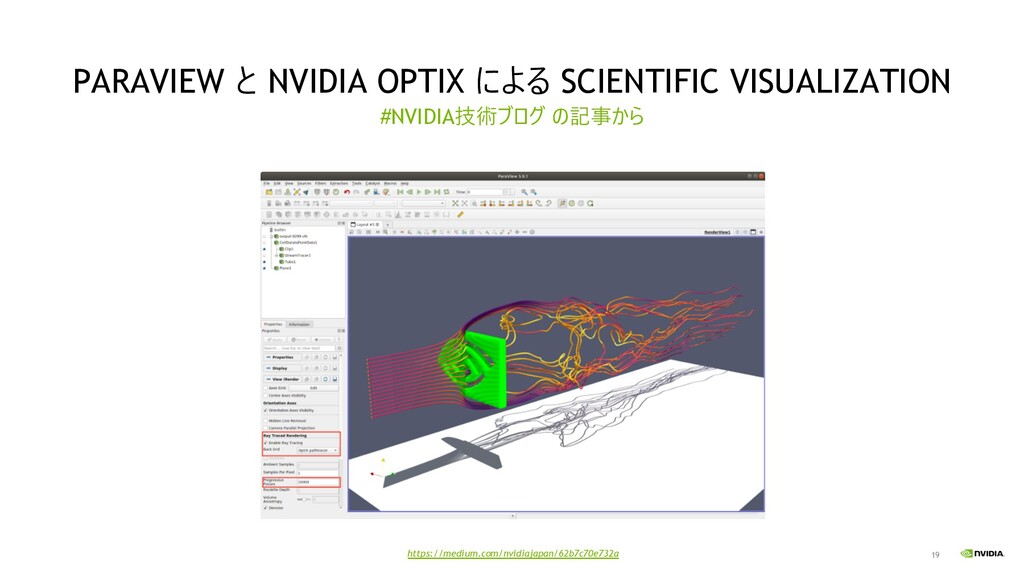
for FP64, A40 & A10 for FP32 GPU accelerated application performance Simulia CST Studio, Altair CFD and Rocky DEM got excellent performance on GPU Paraview with GPU acceleration Ray tracing accelerated with RT core In future Grace CPU improve memory bandwidth between CPU and GPU
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}