Gen NVLink Transformer Engine 2nd Gen MIG Confidential Computing DPX Instructions World’s Most Advanced Chip H100 PCIE Includes NVIDIA AI Enterprise H100 SXM NVIDIA AI Enterprise is a 5-Year Subscription
Tensor Core FLOPs shown with sparsity | Speedups compared to prior generation HIGHEST PERFORMANCE FOR AI AND HPC 4-way / 8-way H100 GPUs with 32 PetaFLOPs FP8 3.6 TFLOPs FP16 in-network SHARP Compute NVIDIA Certified High-Performance Offering from All Makers FASTEST, SCALABLE INTERCONNECT 4th Gen NVLINK with 3X faster All-Reduce communications 3.6 TB/s bisection bandwidth NVLINK Switch System Option Scales Up to 256 GPUs SECURE COMPUTING First HGX System with Confidential Computing
and deploy enterprise AI with unmatched performance, security, and scalability 5-YEAR SUBSCRIPTION OF NVIDIA AI ENTERPRISE A cloud native software suite for development and deployment of AI NVIDIA ENTERPRISE SUPPORT Including access to NVIDIA AI experts, priority notifications of the latest security fixes and maintenance releases ENTERPRISE TRAINING SERVICES Developers, data scientists, and IT professionals learn how to get the most out of the NVIDIA AI platform Software activation: www.nvidia.com/activate-h100
and NVIDIA L40 Highlights • 3rd Gen RT Cores, 4th-Gen Tensor Cores • Up to 2x faster Graphics and AI training performance than Ampere • Up to 2x the single-precision floating-point throughput over the Ampere, support for FP8 format • 3x Encode & 3x Decode - support for AV1 Enc/Dec • 48GB of GDDR6 ECC memory for working with the largest 3D models, renderings, simulation, and AI datasets
most demanding industries & workloads • Most powerful professional GPU ever • 2X the performance of the A6000 • RTX A6000 will still be available • For customers needing NVLink/largest possible GPU memory • Available from channel partners starting in December • Anticipate OEM availability early in 2023 Ada for the enterprise *Preliminary specifications, subject to change
performance vs. Ampere Generation • Powerful Compute and AI • Accelerated Rendering, Training, and Inference • Data Center Ready • Secure and Measure Boot w. RoT Available starting in December 2022 Unprecedented visual computing performance for the data center *Preliminary specifications, subject to change
| Metaverse | HPC NGC ngc.nvidia.com Software ON-PREM CLOUD EDGE Services NeMo LLM service LLM Customization | Managed API | Playground Riva Studio Custom voice | No-code GUI BioNeMo service Predict 3D protein structures, properties Base Command Training tools | Workflow mgmt | Monitoring, reporting Fleet Command Managed Edge AI | Layered Security | Monitoring, reporting Enterprise Catalog NVIDIA AI SW | Support | Proprietary SW Containers Performance optimized AI Models Speech, CV, data science, more Jupyter Notebooks End-to-end example workflows Helm Charts Automate deployments on K8s Support NVIDIA AI Enterprise Support Business Standard | Business critical |Dedicated TAM Containers!!
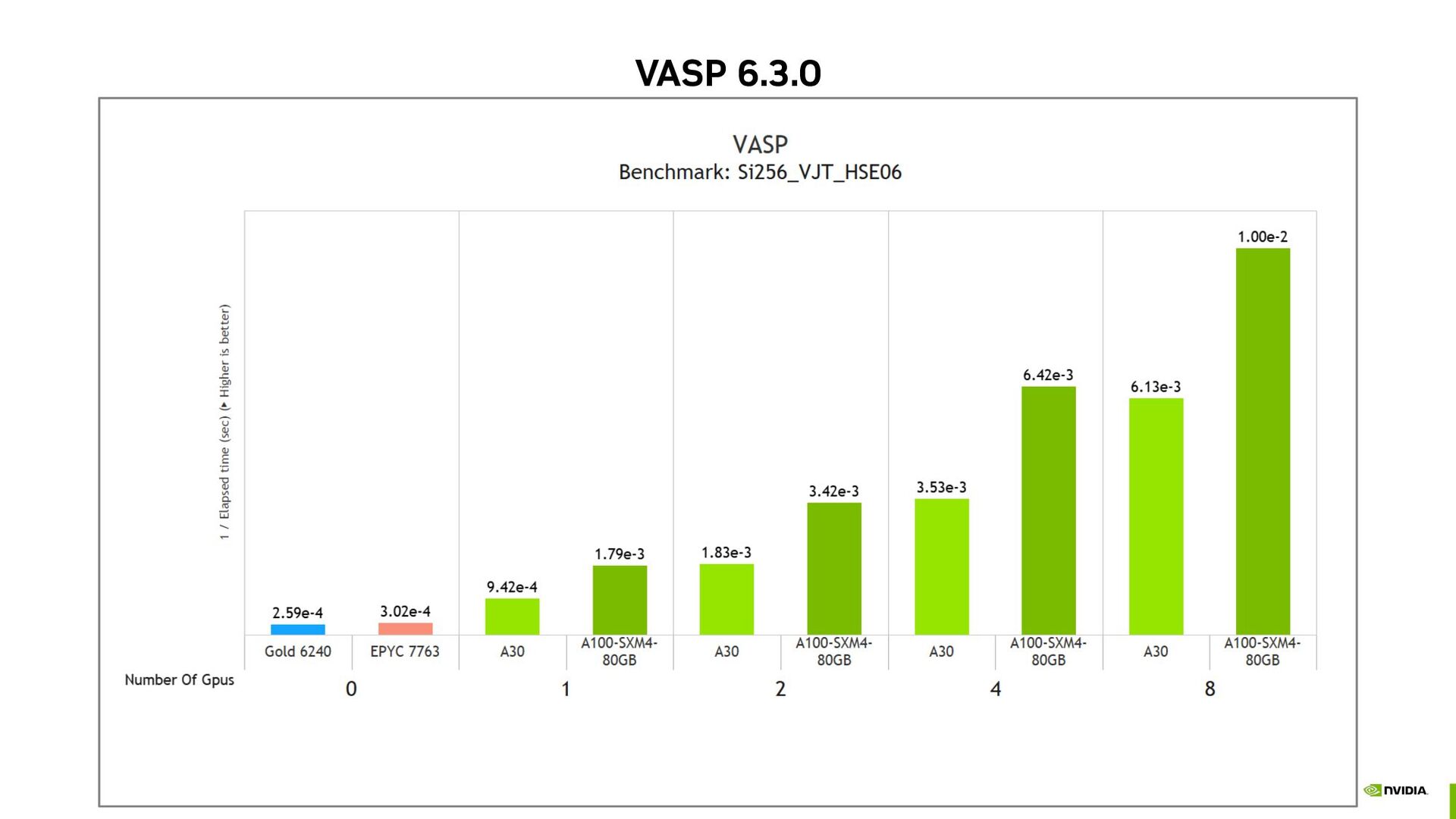
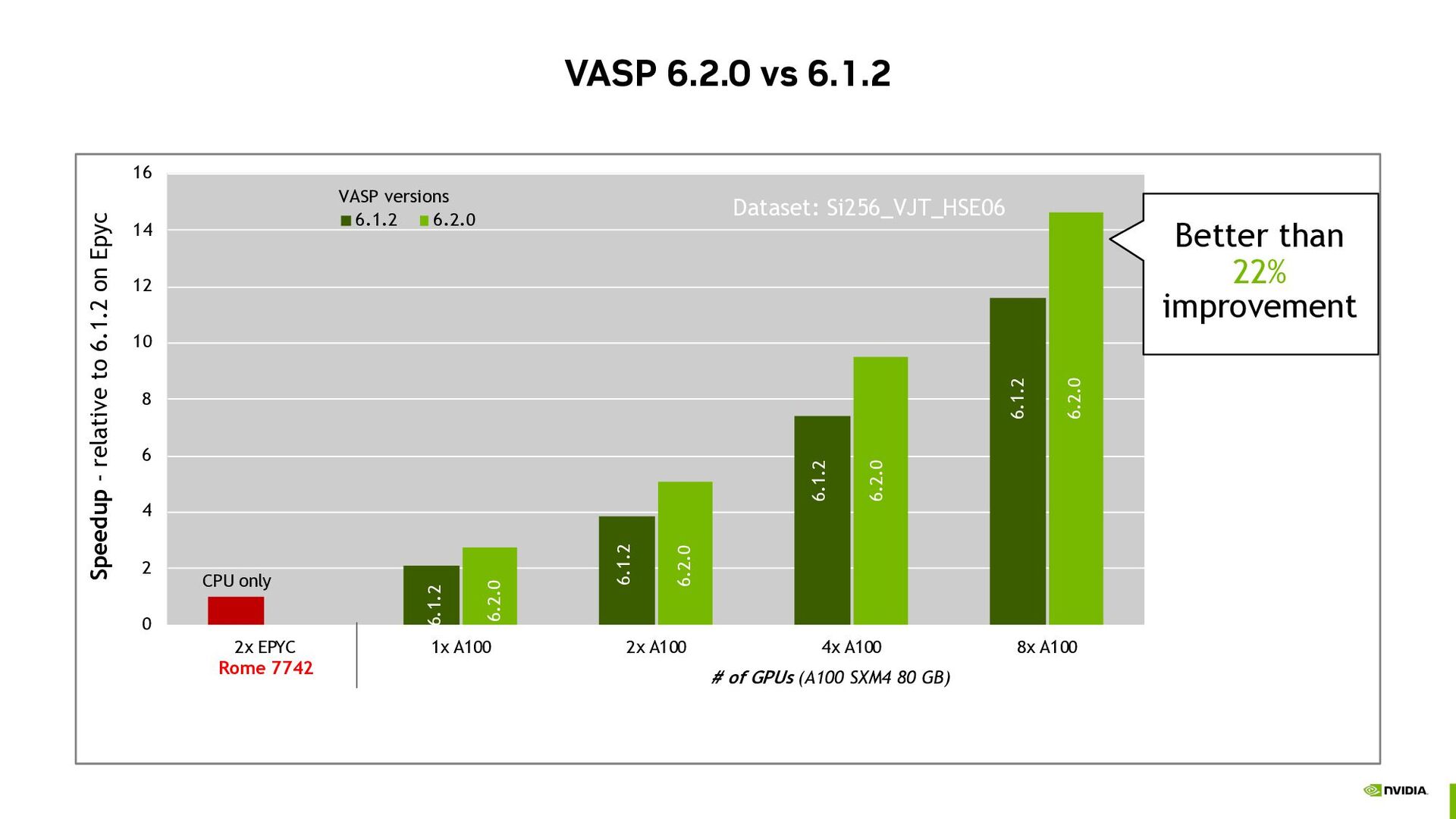
• New acceleration • Acceleration work in progress • On acceleration roadmap LEVELS OF THEORY Standard DFT (incl. meta-GGA, vdW-DFT) Hybrid DFT (double buffered) Cubic-scaling RPA (ACFDT, GW) Bethe-Salpeter Equations (BSE) PROJECTION SCHEME Real space Reciprocal space SOLVERS / MAIN ALGORITHM Davidson (+Adaptively Compressed Exch.) RMM-DIIS Davidson+RMM-DIIS Direct optimizers (Damped, All) Linear response EXECUTABLE FLAVORS Standard variant Gamma-point simplification variant Non-collinear spin variant
{kind=link}
{kind=link}
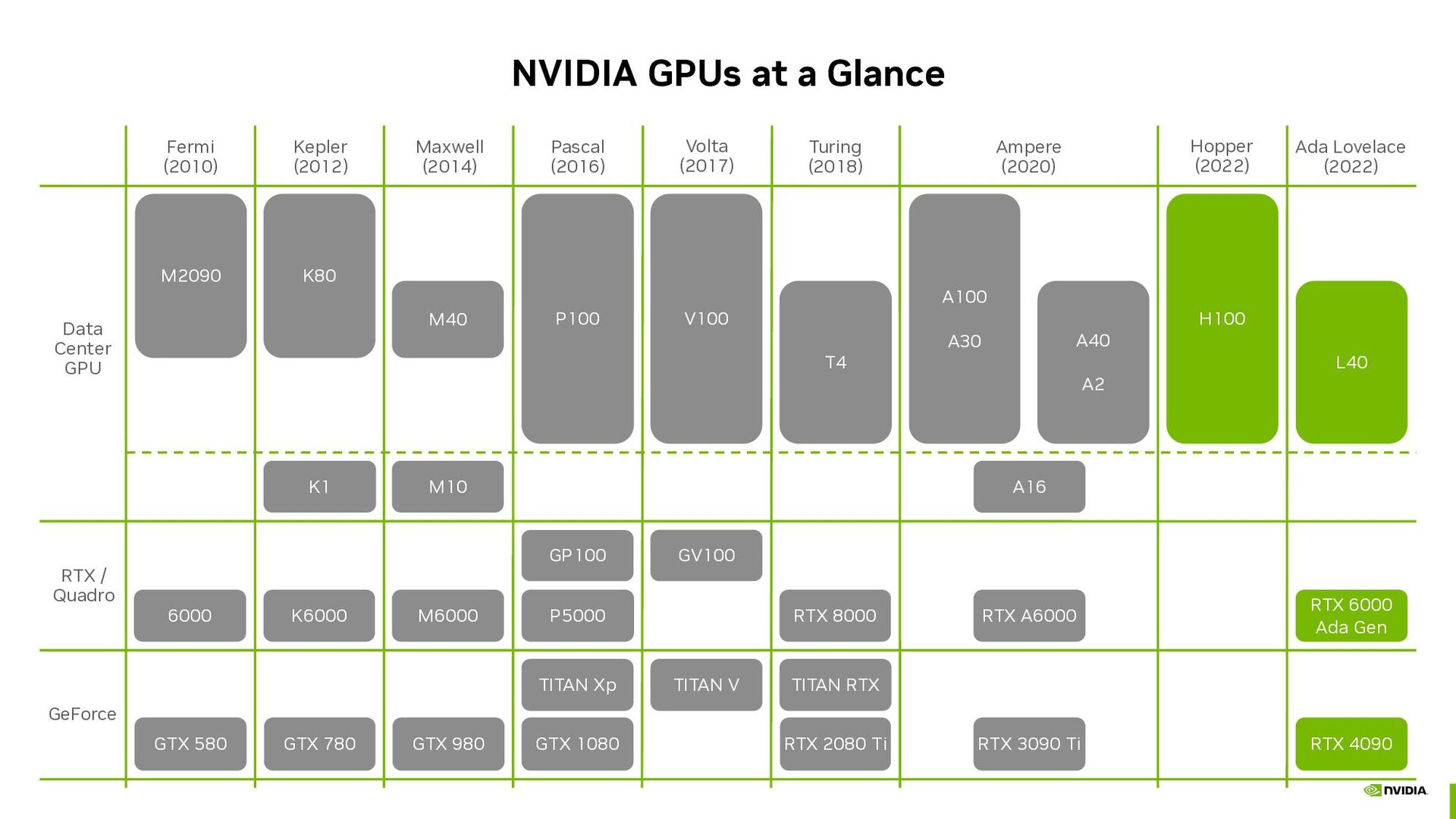{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
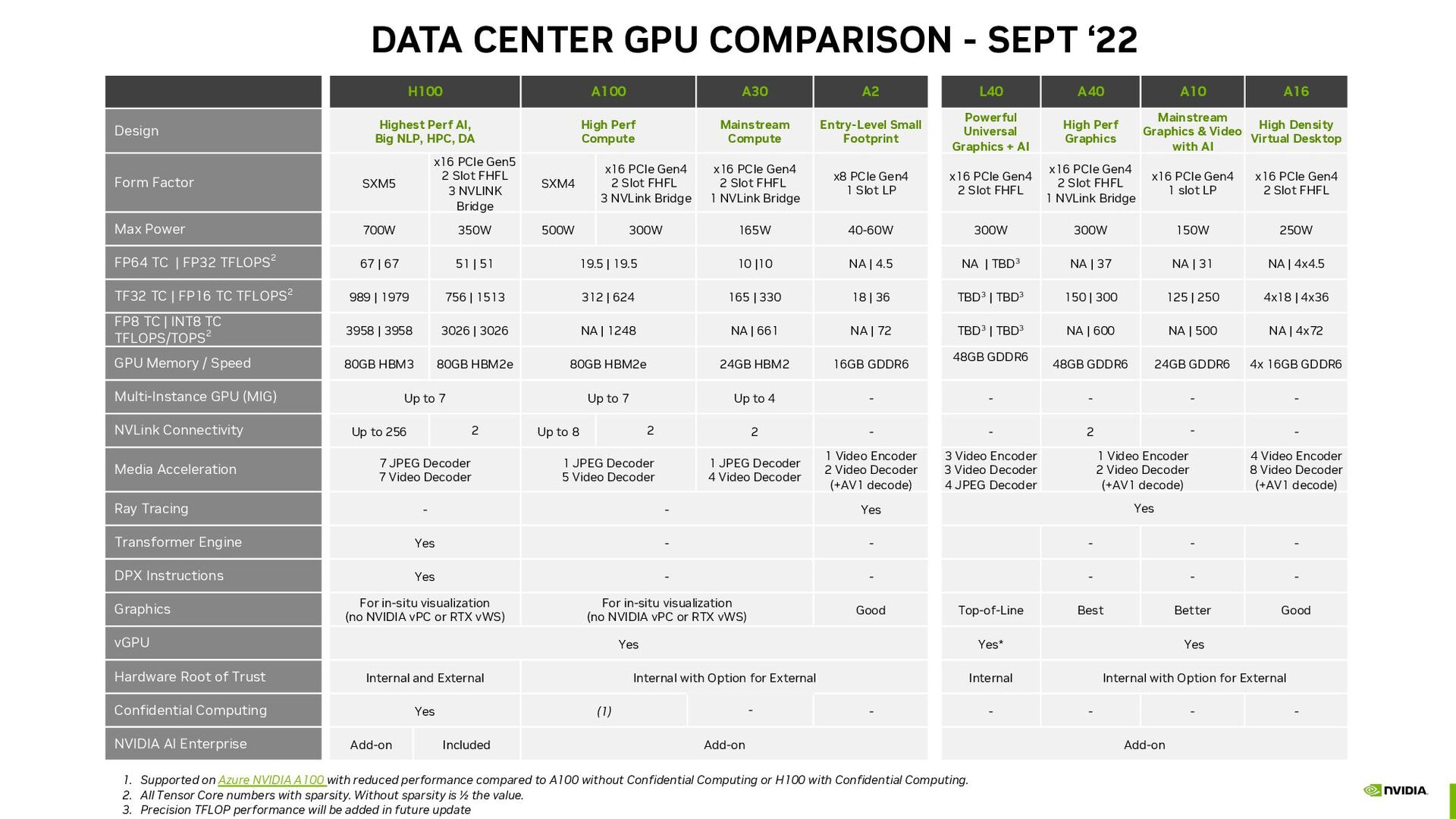{kind=link}
{kind=link}
{kind=link}
{kind=link}
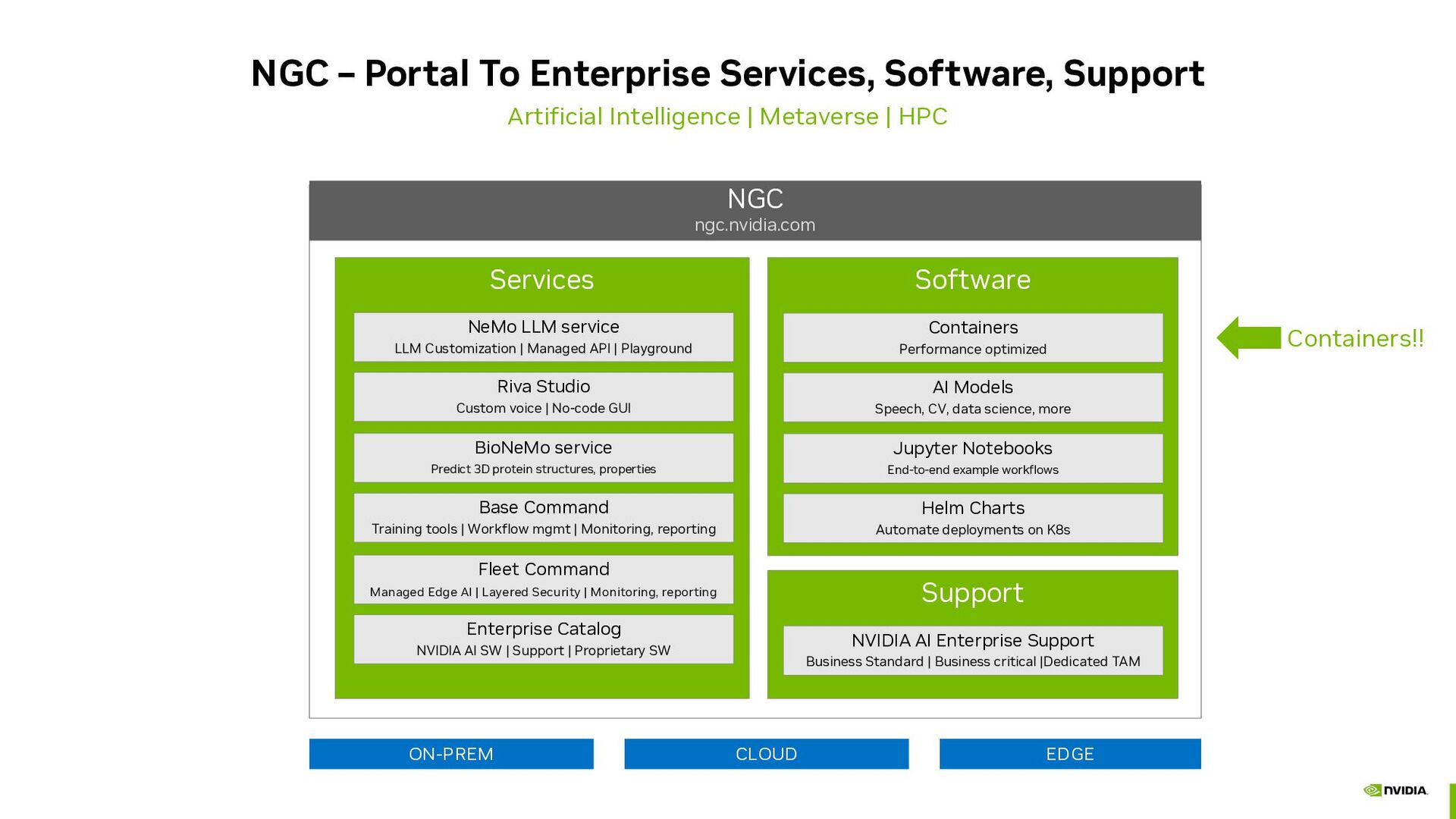{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}