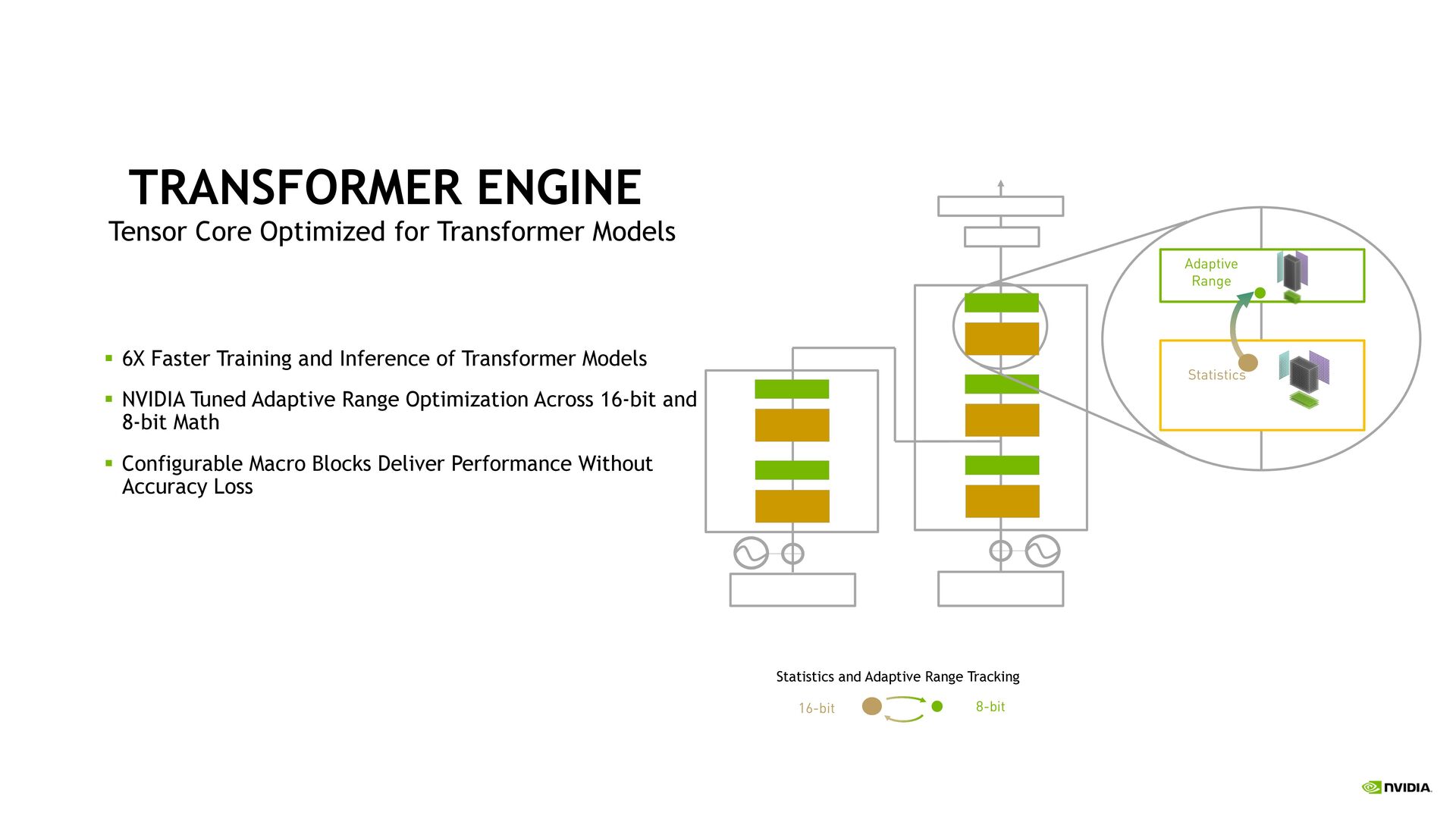
Faster Training and Inference of Transformer Models § NVIDIA Tuned Adaptive Range Optimization Across 16-bit and 8-bit Math § Configurable Macro Blocks Deliver Performance Without Accuracy Loss 8-bit 16-bit Statistics and Adaptive Range Tracking Statistics Adaptive Range
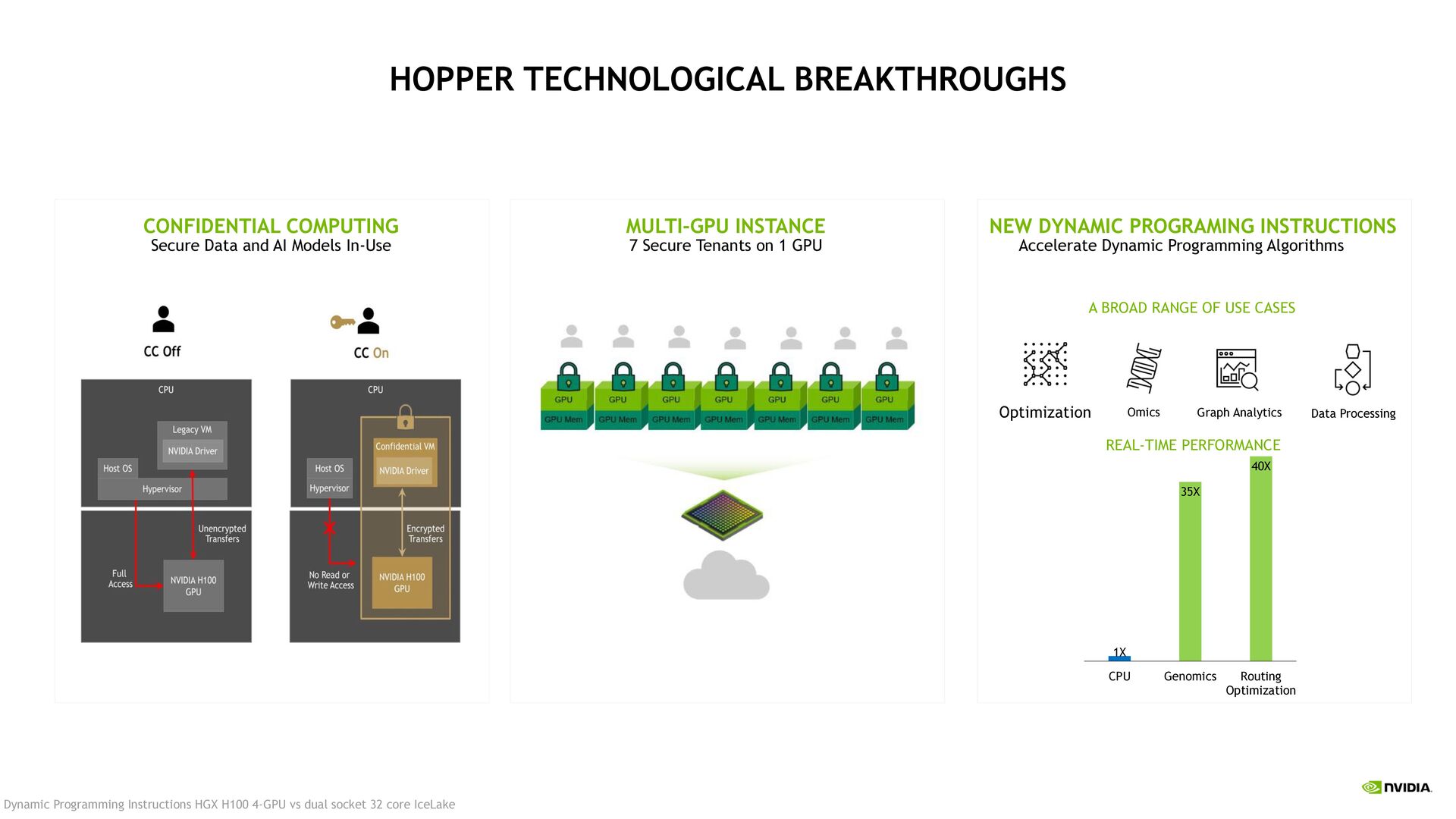
Algorithms MULTI-GPU INSTANCE 7 Secure Tenants on 1 GPU CONFIDENTIAL COMPUTING Secure Data and AI Models In-Use Optimization Omics Graph Analytics Data Processing A BROAD RANGE OF USE CASES 1X 35X 40X CPU Genomics Routing Optimization REAL-TIME PERFORMANCE Dynamic Programming Instructions HGX H100 4-GPU vs dual socket 32 core IceLake
Core FLOPs shown with sparsity | Speedups compared to prior generation HIGHEST PERFORMANCE FOR AI AND HPC 4-way / 8-way H100 GPUs with 32 PetaFLOPs FP8 3.6 TFLOPs FP16 in-network SHARP Compute NVIDIA Certified High-Performance Offering from All Makers FASTEST, SCALABLE INTERCONNECT 4th Gen NVLINK with 3X faster All-Reduce communications 3.6 TB/s bisection bandwidth NVLINK Switch System Option Scales Up to 256 GPUs SECURE COMPUTING First HGX System with Confidential Computing
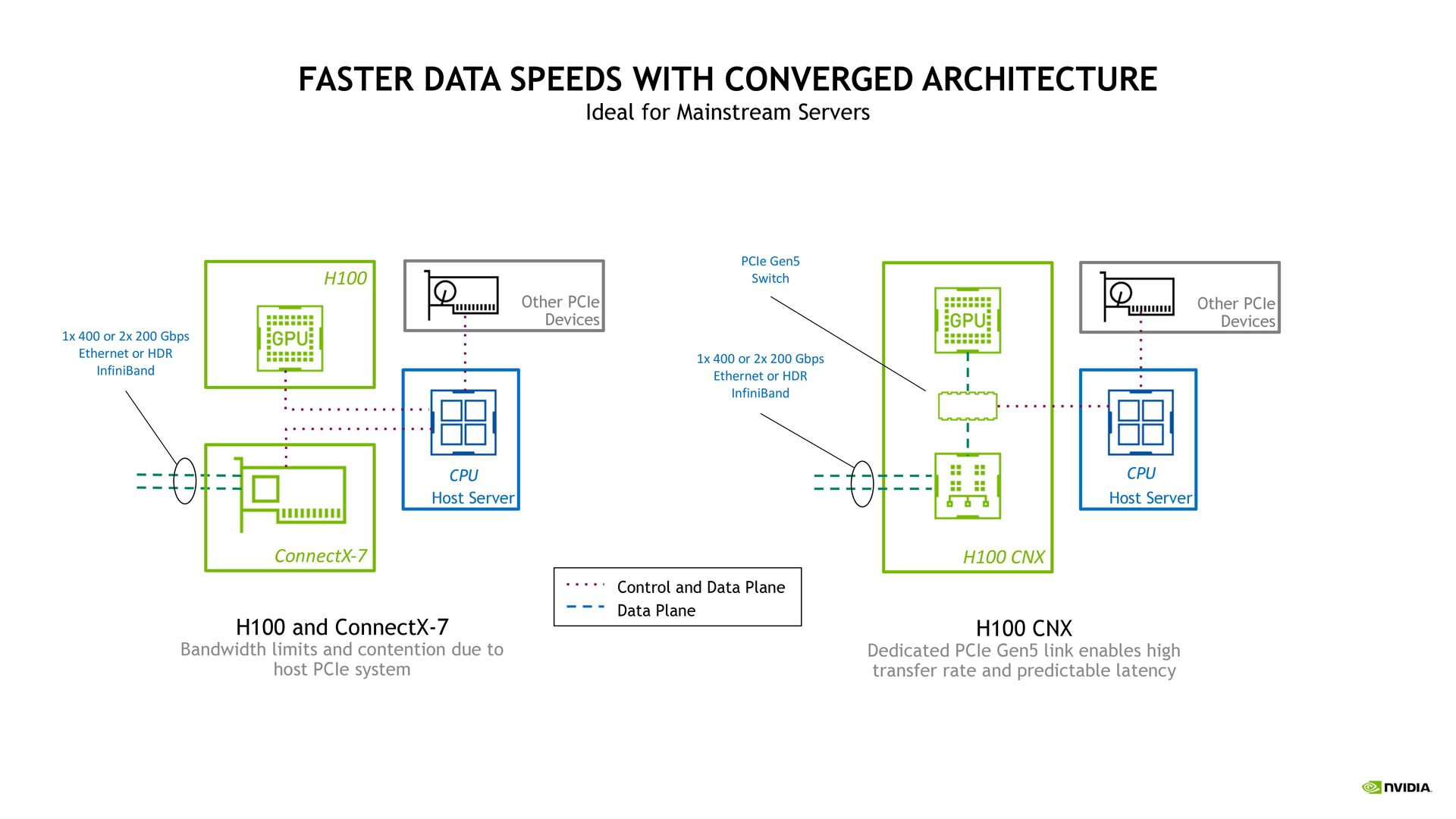
Mainstream Servers Traditional Server Optimized for Accelerated Computing H100 CNX Memory CPU ConnectX-7 Gen-4 GPU Gen-5 Memory CPU ConnectX-7 Gen-4 GPU 350W | 80GB | 400 Gb/s Eth or IB PCIe Gen 5 within board and to host 2-Slot FHFL | NVLink
H100 CNX Dedicated PCIe Gen5 link enables high transfer rate and predictable latency H100 CNX Host Server CPU H100 and ConnectX-7 Bandwidth limits and contention due to host PCIe system H100 Host Server CPU ConnectX-7 1x 400 or 2x 200 Gbps Ethernet or HDR InfiniBand 1x 400 or 2x 200 Gbps Ethernet or HDR InfiniBand Control and Data Plane Data Plane PCIe Gen5 Switch Other PCIe Devices Other PCIe Devices
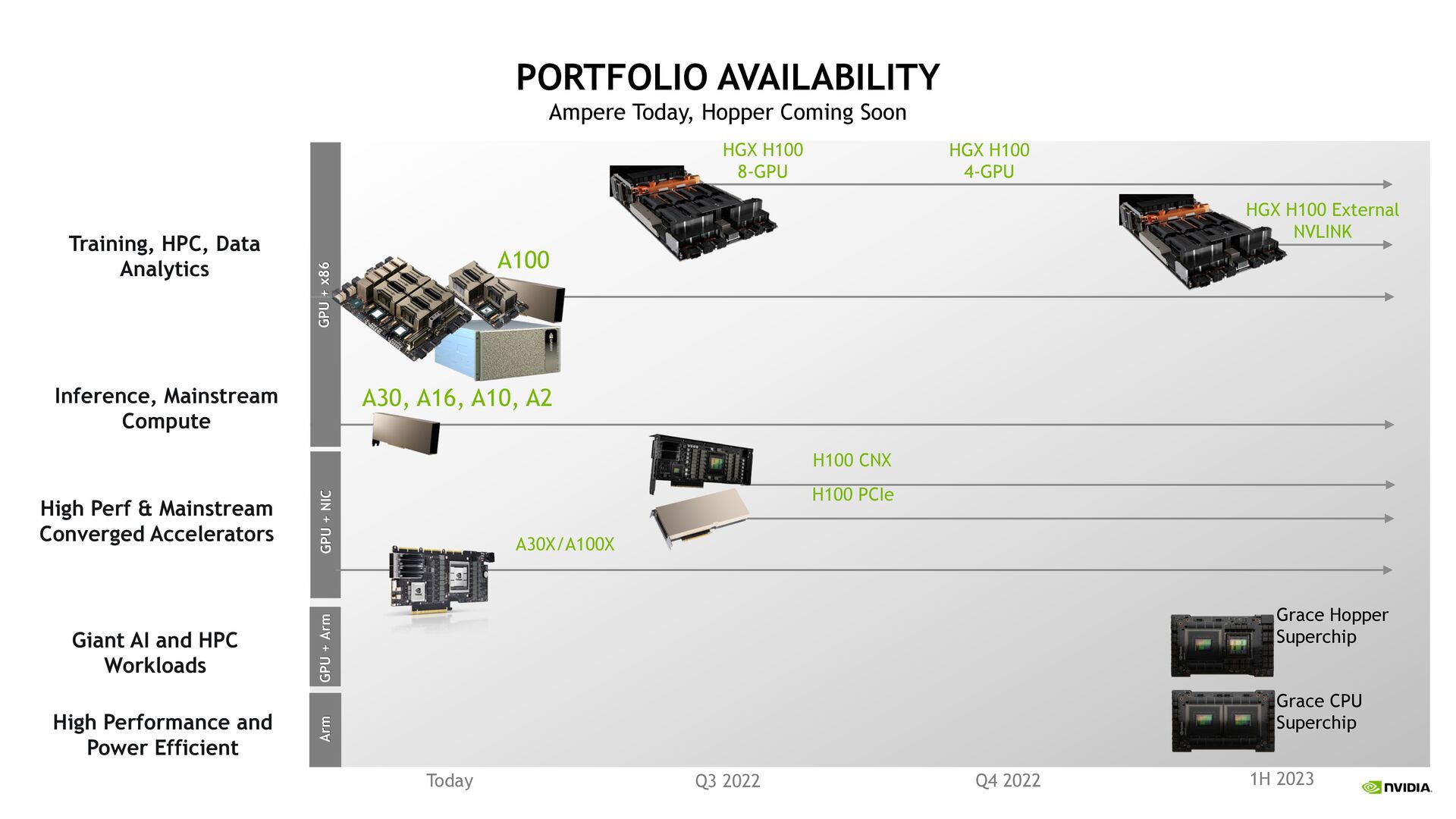
HPC 600GB Memory GPU for Giant Models New 900 GB/s Coherent Interface 30X Higher System Memory B/W to GPU In A Server Runs Nvidia Computing Stacks Available 1H 2023
HIGHEST CPU PERFORMANCE Superchip Design with 144 high-performance Armv9 Cores Estimated Specrate2017_int_base of over 740 HIGHEST MEMORY BANDWIDTH World’s first LPDDR5x memory with ECC, 1TB/s Memory Bandwidth HIGHEST ENERGY EFFICIENCY 2X Perf/Watt, CPU Cores + Memory in 500W 2X PACKING DENSITY 2x density of DIMM based designs RUNS FULL NVIDIA COMPUTING STACKS RTX, HPC, AI, Omniverse AVAILABLE 1H 2023
Breed Infrastructure for AI Development Built on NVIDIA DGX ANNOUNCING NVIDIA DGX H100 ANNOUNCING DGX SuperPOD WITH DGX H100 1 ExaFLOPS of AI Performance in 32 Nodes Scale as large as needed in 32 node increments 4th Generation of the World’s Most Successful Platform Purpose-Built for Enterprise AI The World’s First AI System with NVIDIA H100 COMING LATE 2022 32 DGX H100 | 1 EFLOPS AI NVLINK SWITCH SYSTEM | QUANTUM-2 IB | 20TB HBM3 | 70 TB/s BISECTION B/W (11X) 8x NVIDIA H100 | 32 PFLOPS FP8 (6X) | 0.5 PFLOPS FP64 (3X) 640 GB HBM3 | 3.6 TB/s (1.5X) BISECTION B/W X-Factors compare performance over DGX SuperPOD with DGX A100 supercomputer configuration with same number of nodes
Reductions SHARPv3 Large Message Data Reductions CONNECTX-7 INFINIBAND 16 Core / 256 Threads Datapath Accelerator Full Transport Offload and Telemetry Hardware-Based RDMA / GPUDirect MPI Tag Matching and All-to-All BLUEFIELD-3 INFINIBAND 16 Arm 64-Bit Cores 16 Core / 256 Threads Datapath Accelerator Full Transport Offload and Telemetry Hardware-Based RDMA / GPUDirect Computational Storage Security Engines MPI Tag Matching and All-to-All Optimized Multi-Tenant In-Network Computing
HIGH FIDELITY SURROGATES ADOPTED BY LEADING RESEARCH INSTITUTIONS COLLABORATION PARTNERS NEW MODULUS FEATURES FNO, AFNO Accelerating Scientific Simulations Omniverse Integration Interactive visualization PyTorch Integration To support the growing ecosystem Available Early April Up to 4,000x speedup to simulate wind farms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}