Performance Power Efficient Cores • 72 flagship Arm Neoverse V2 Cores with SVE2 4x128b SIMD per core • Fast On-Chip Fabric • 3.2 TB/s of bisection bandwidth connects CPU cores, NVLink-C2C, memory, and system IO • High-Bandwidth Low-Power Memory • Up to 480 GB of data center enhanced LPDDR5X Memory that delivers up to 500 GB/s of memory bandwidth • Coherent Chip-to-Chip Connections • NVLink-C2C with 900 GB/s bandwidth for coherent connection to CPU or GPU • Industry Leading Performance Per Watt • Up to 2X perf / W over today’s leading servers
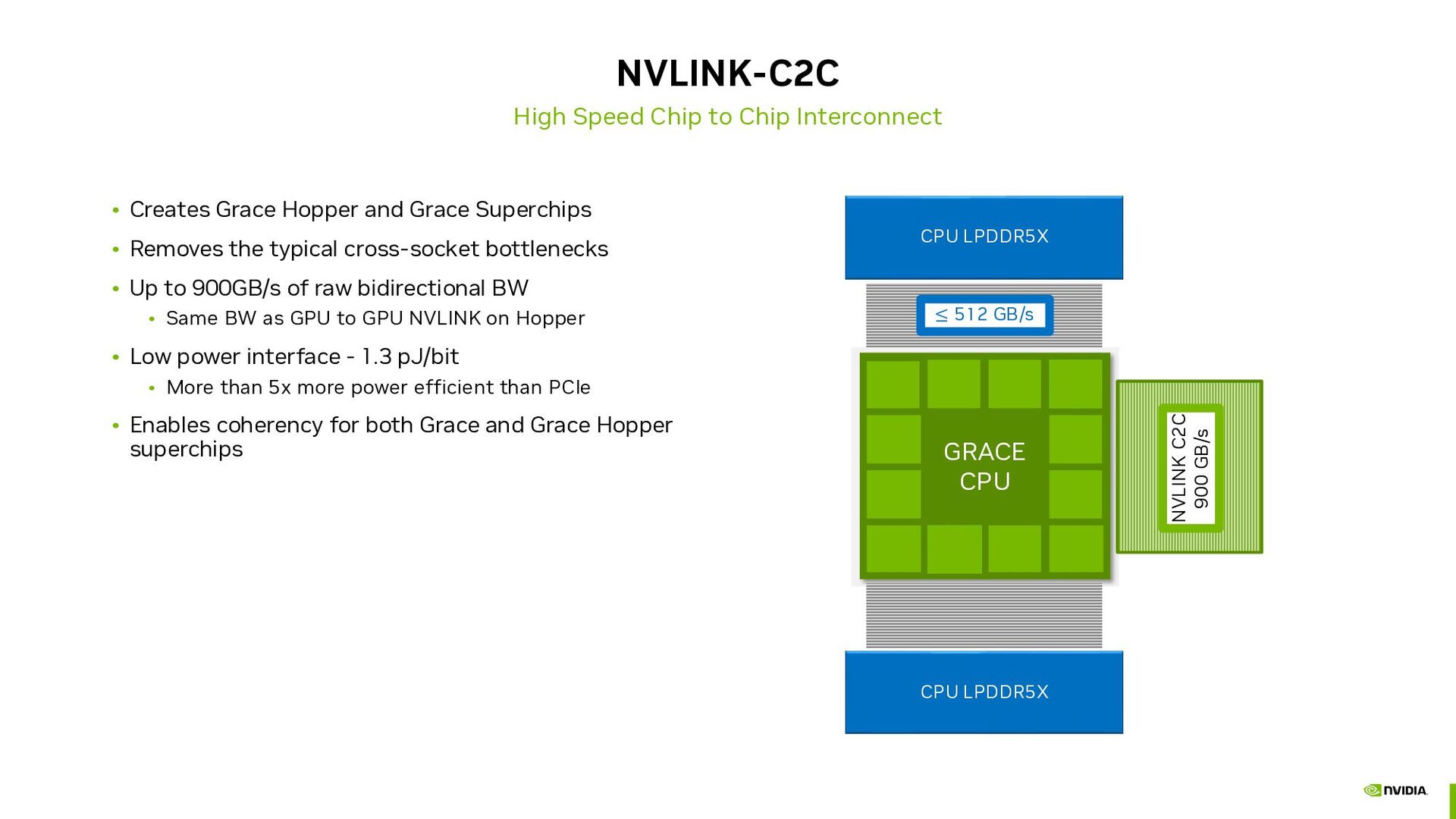
Hopper and Grace Superchips • Removes the typical cross-socket bottlenecks • Up to 900GB/s of raw bidirectional BW • Same BW as GPU to GPU NVLINK on Hopper • Low power interface - 1.3 pJ/bit • More than 5x more power efficient than PCIe • Enables coherency for both Grace and Grace Hopper superchips GRACE CPU NVLINK C2C 900 GB/s CPU LPDDR5X CPU LPDDR5X ≤ 512 GB/s
where CPU performance and system memory size and bandwidth are critical; tightly coupled CPU & GPU for flagship AI & HPC. Most versatile compute platform for scale out. GH200 Grace Hopper Superchip Large Scale AI & HPC CPU-based applications where absolute performance, energy efficiency, and data center density matter, such as scientific computing, data analytics, enterprise and hyperscale computing applications Grace CPU Superchip CPU Computing
for the Modern Data Center • High Performance Power Efficient Cores • 144 flagship Arm Neoverse V2 Cores with SVE2 4x128b SIMD per core • Fast On-Chip Fabric • 3.2 TB/s of bi-section bandwidth connects CPU cores, NVLink-C2C, memory, and system IO • High-Bandwidth Low-Power Memory • Up to 960GB of data center enhanced LPDDR5X Memory that delivers up to1TB/s of memory bandwidth • Fast and Flexible CPU IO • Up to 8x PCIe Gen5 x16 interface • PCIe Gen 5 up to 128GB/s; 2X more bandwidth compared to PCIe Gen 4 • Full NVIDIA Software Stack • AI, Omniverse
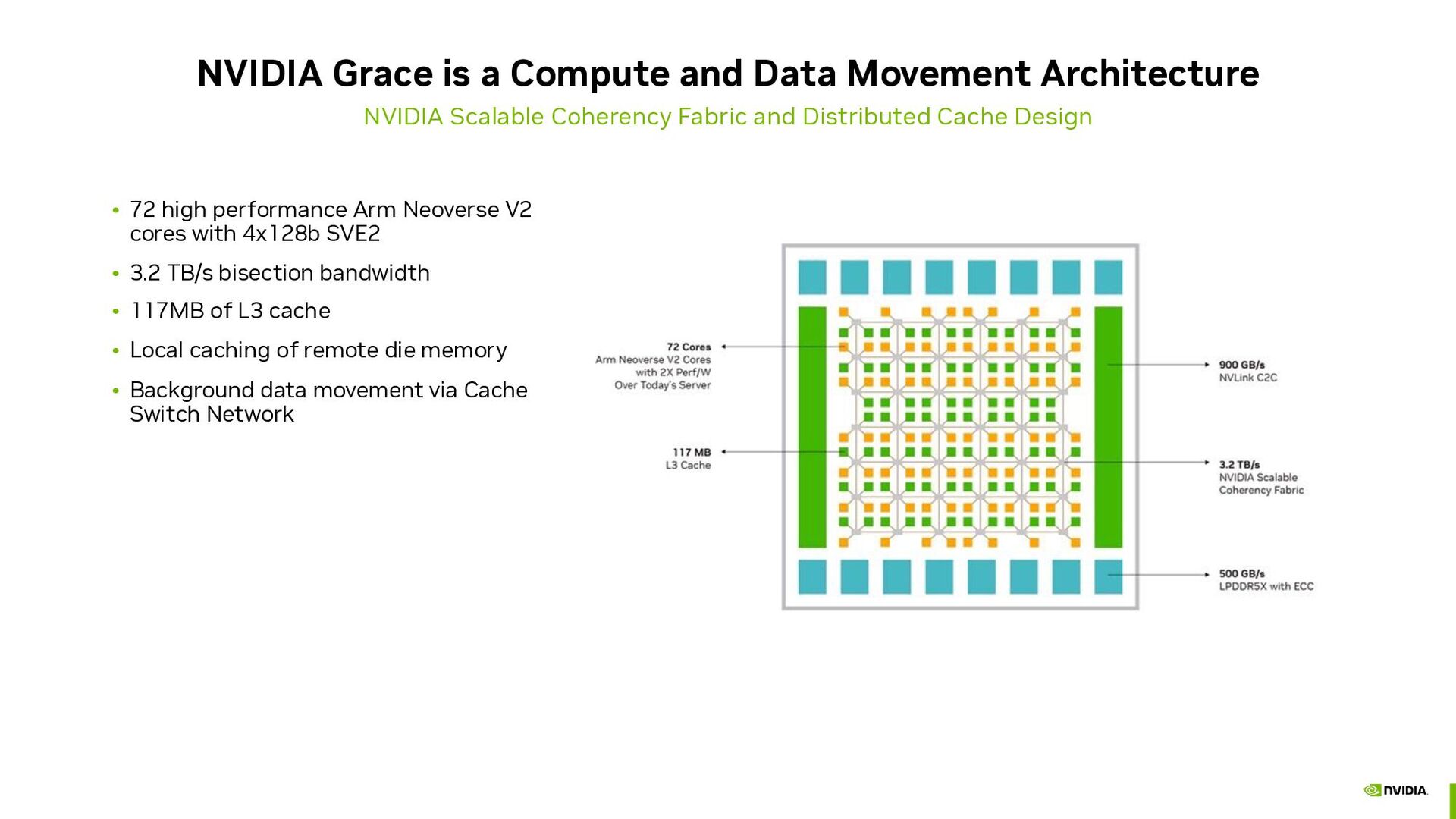
Scalable Coherency Fabric and Distributed Cache Design • 72 high performance Arm Neoverse V2 cores with 4x128b SVE2 • 3.2 TB/s bisection bandwidth • 117MB of L3 cache • Local caching of remote die memory • Background data movement via Cache Switch Network
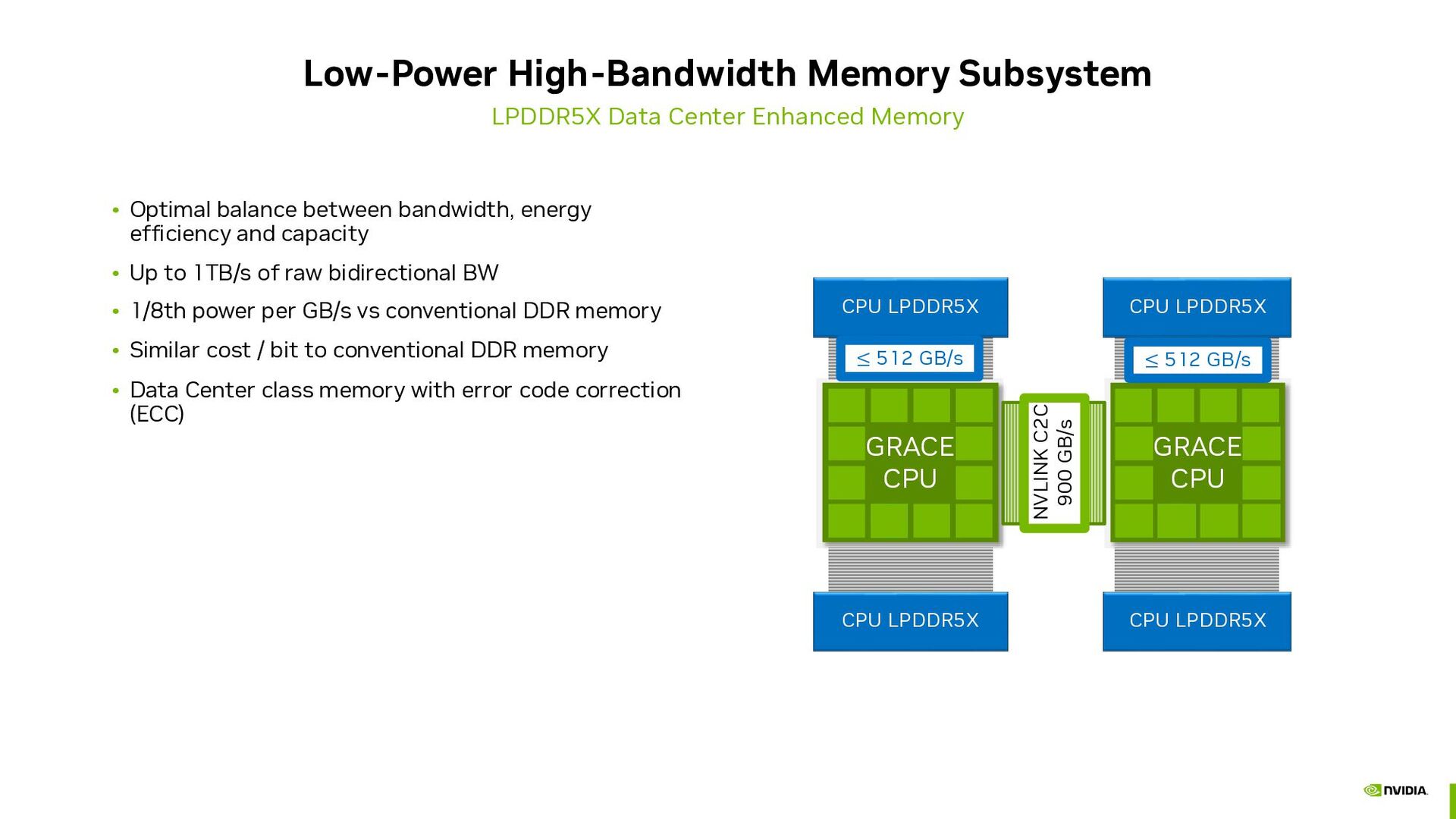
Optimal balance between bandwidth, energy efficiency and capacity • Up to 1TB/s of raw bidirectional BW • 1/8th power per GB/s vs conventional DDR memory • Similar cost / bit to conventional DDR memory • Data Center class memory with error code correction (ECC) GRACE CPU GRACE CPU NVLINK C2C 900 GB/s CPU LPDDR5X CPU LPDDR5X CPU LPDDR5X CPU LPDDR5X ≤ 512 GB/s ≤ 512 GB/s
Performance Power Efficient Cores • 72 flagship Arm Neoverse V2 Cores with SVE2 4x128b SIMD per core • Fast On-Chip Fabric • 3.2 TB/s of bisection bandwidth connects CPU cores, NVLink-C2C, memory, and system IO • High-Bandwidth Low-Power Memory • Up to 480 GB of data center enhanced LPDDR5X Memory that delivers up to 500 GB/s of memory bandwidth • Coherent Chip-to-Chip Connections • NVLink-C2C with 900 GB/s bandwidth for coherent connection to CPU or GPU • Industry Leading Performance Per Watt • Up to 2X perf / W over today’s leading servers
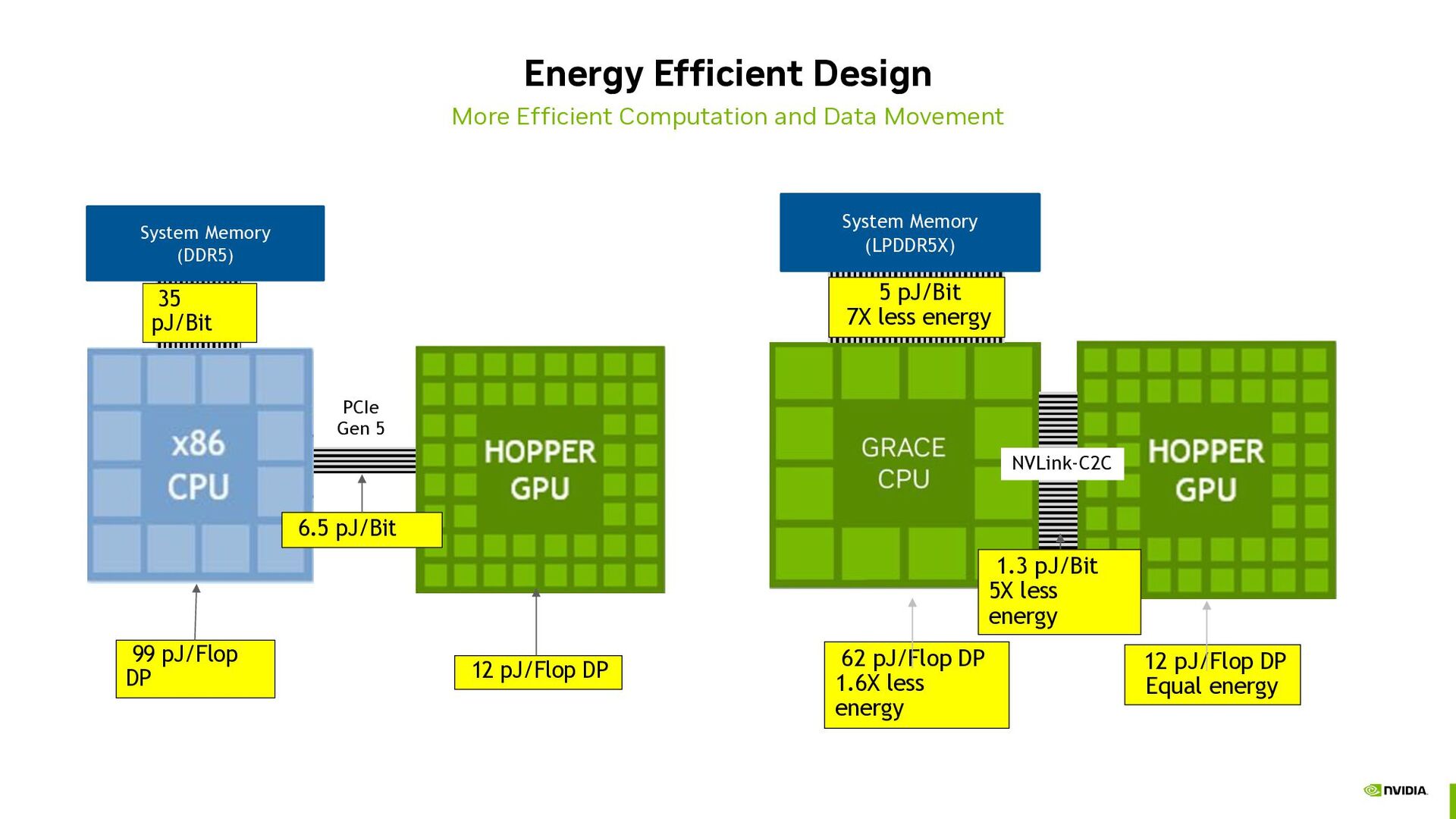
Memory (DDR5) 35 pJ/Bit 6.5 pJ/Bit 99 pJ/Flop DP 12 pJ/Flop DP PCIe Gen 5 62 pJ/Flop DP 1.6X less energy System Memory (LPDDR5X) 5 pJ/Bit 7X less energy 12 pJ/Flop DP Equal energy 1.3 pJ/Bit 5X less energy NVLink-C2C
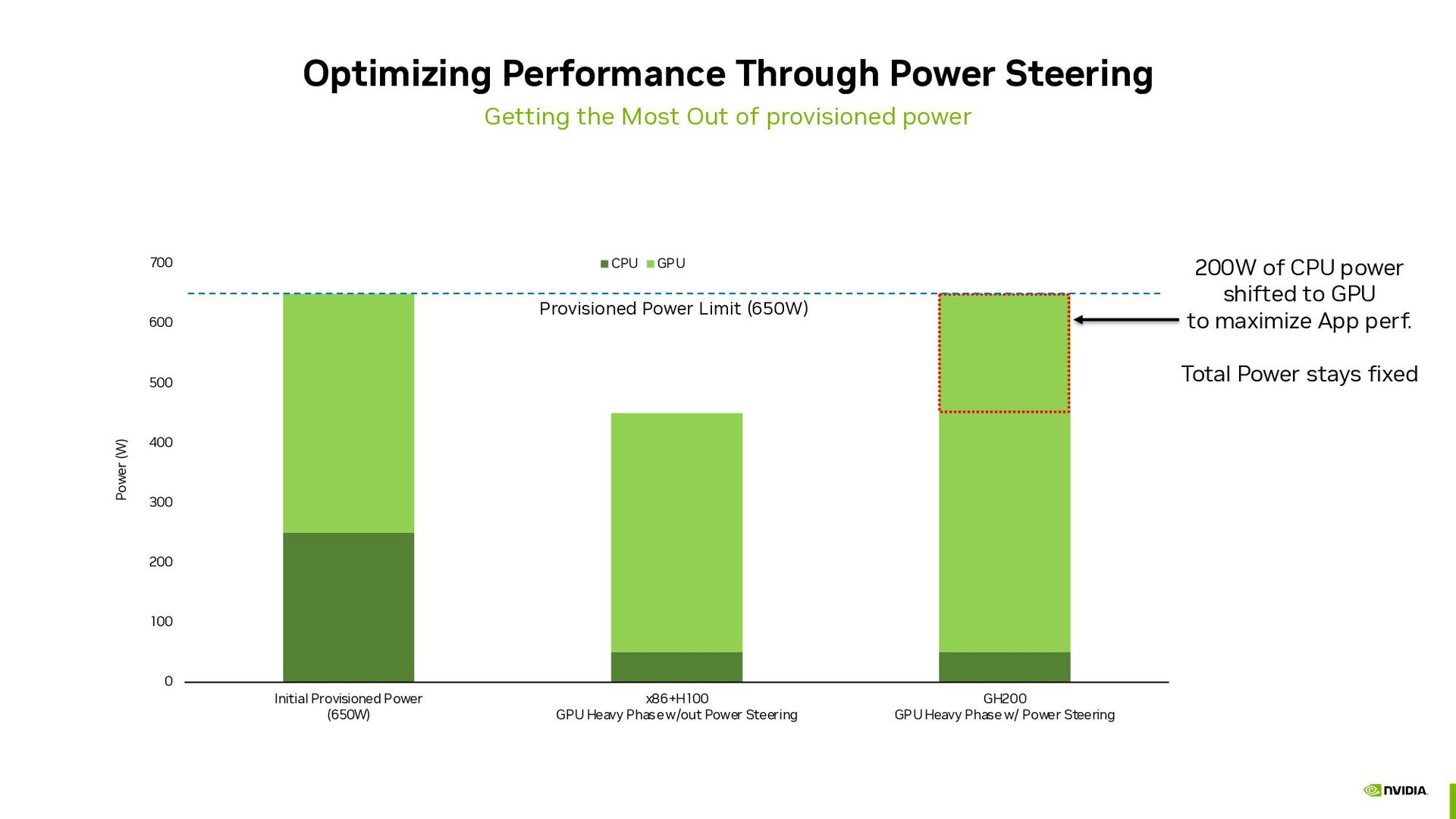
provisioned power 0 100 200 300 400 500 600 700 Initial Provisioned Power (650W) x86+H100 GPU Heavy Phase w/out Power Steering GH200 GPU Heavy Phase w/ Power Steering Power (W) Chart Title CPU GPU 200W of CPU power shifted to GPU to maximize App perf. Total Power stays fixed Provisioned Power Limit (650W)
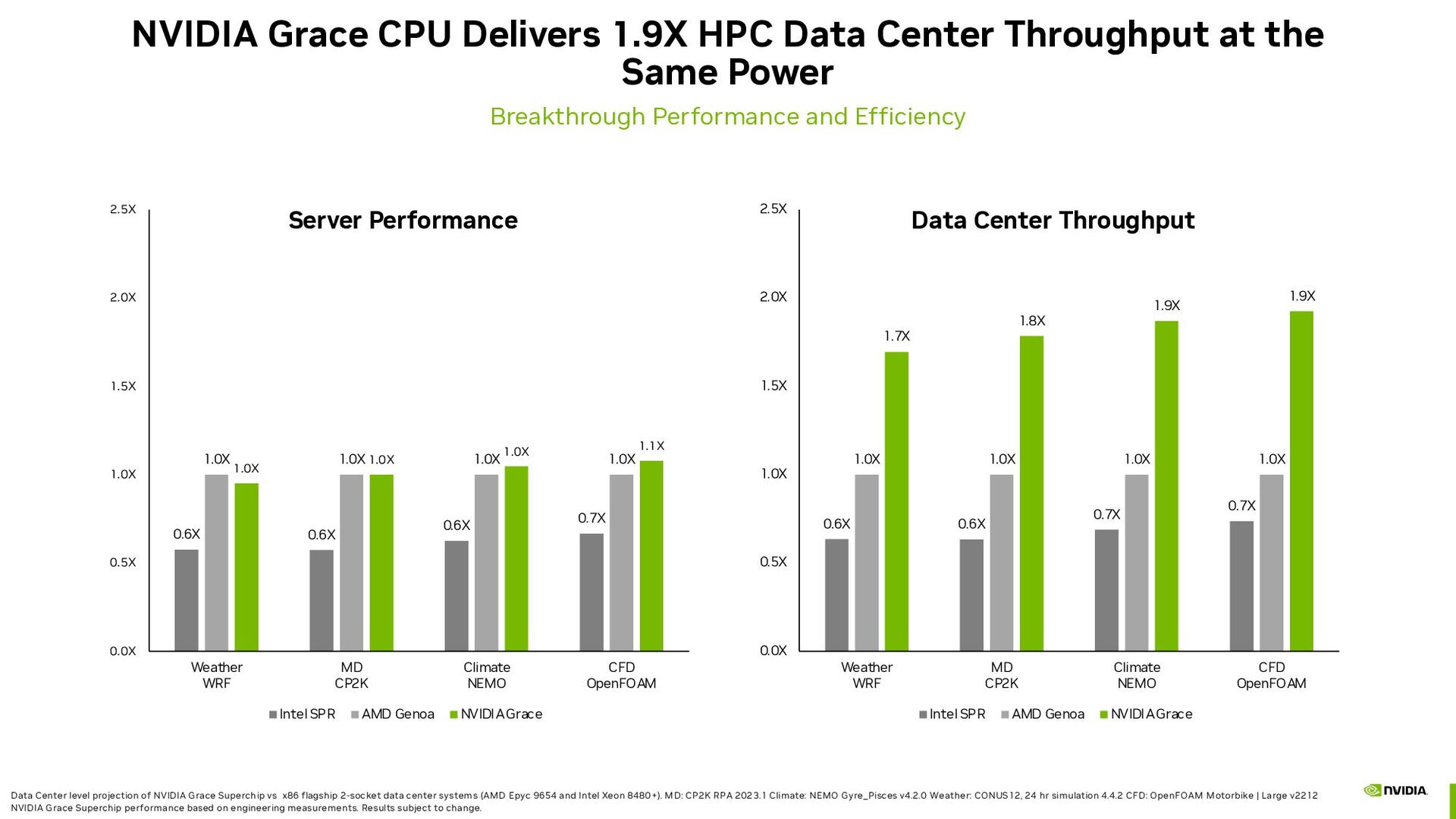
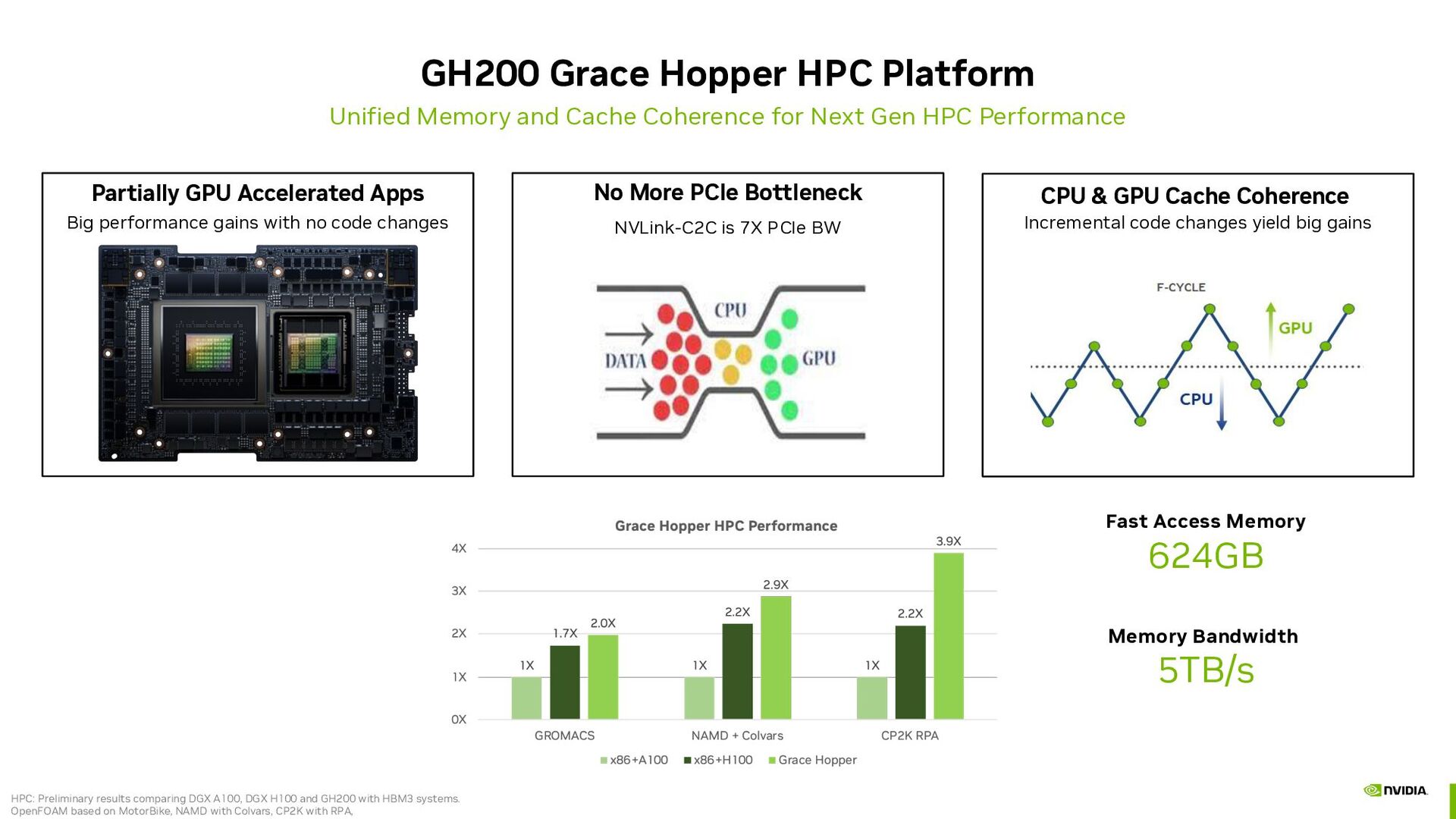
for Next Gen HPC Performance Fast Access Memory 624GB Memory Bandwidth 5TB/s Partially GPU Accelerated Apps No More PCIe Bottleneck CPU & GPU Cache Coherence Big performance gains with no code changes Incremental code changes yield big gains NVLink-C2C is 7X PCIe BW HPC: Preliminary results comparing DGX A100, DGX H100 and GH200 with HBM3 systems. OpenFOAM based on MotorBike, NAMD with Colvars, CP2K with RPA,
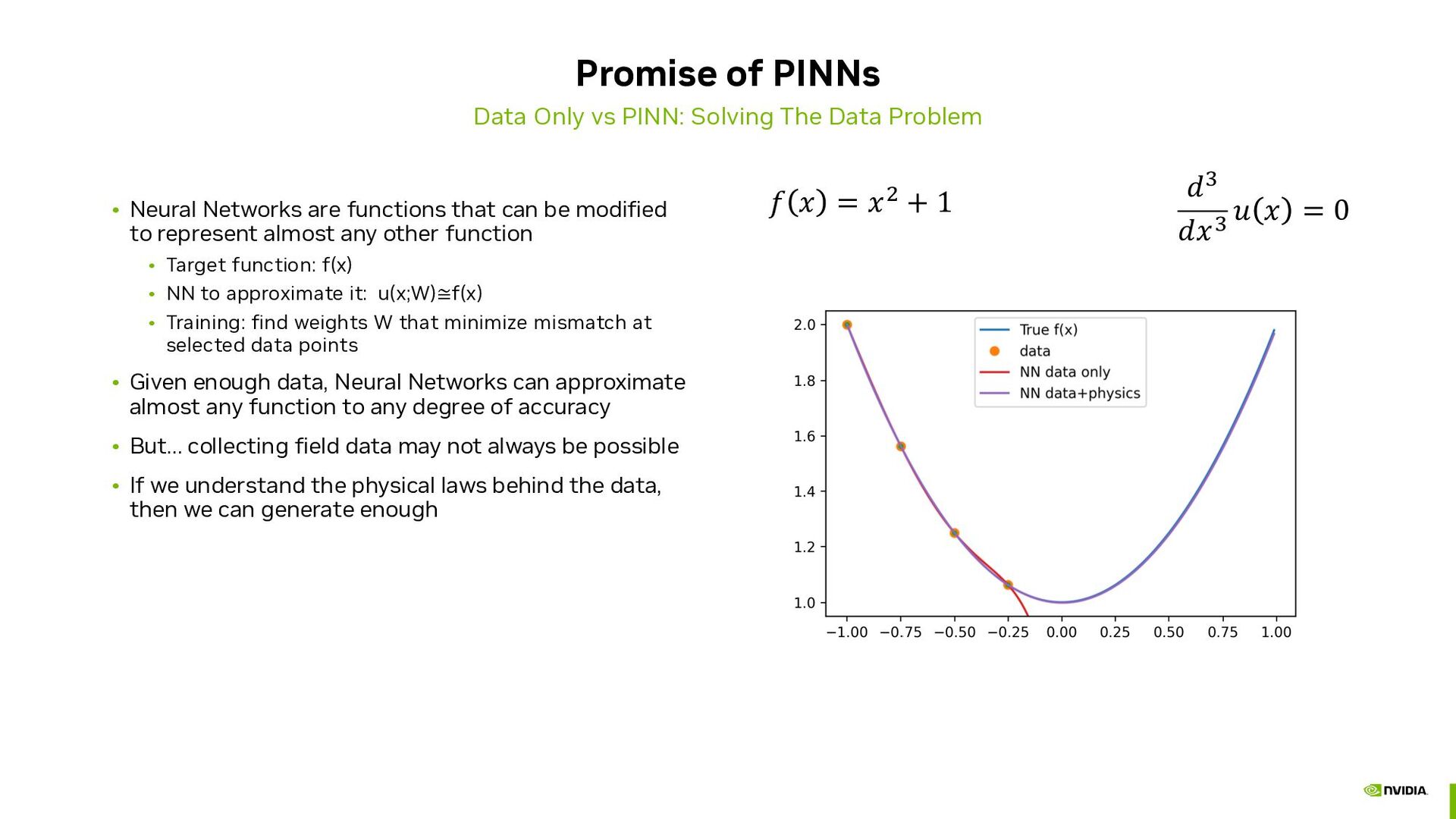
Problem • Neural Networks are functions that can be modified to represent almost any other function • Target function: f(x) • NN to approximate it: u(x;W)≅f(x) • Training: find weights W that minimize mismatch at selected data points • Given enough data, Neural Networks can approximate almost any function to any degree of accuracy • But… collecting field data may not always be possible • If we understand the physical laws behind the data, then we can generate enough ! " = "! + 1 &" &"" ' " = 0
APIs for ease of use • Import your PyTorch model* • Reference case studies and recipes as starting points • Facilitates open collaboration within the Physics-ML scientific community • Model architecture Zoo • Well documented features and functionality for ease of use • Source code: https://github.com/NVIDIA/modulus
San Jose, CA and Virtual Come to GTC—the conference for the era of AI—to connect with a dream team of industry luminaries, developers, researchers, and business experts shaping what’s next in AI and accelerated computing. From the highly anticipated keynote by NVIDIA CEO Jensen Huang to over 600 inspiring sessions, 200+ exhibits, and tons of networking events, GTC delivers something for every technical level and interest area. Be sure to save your spot for this transformative event. You can even take advantage of early-bird pricing when you register by February 7. March 18-21, 2024 | www.nvidia.com/gtc The In-Person GTC Experience Is Back Plask
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}