Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
深層学習を用いた自然言語処理③
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
shu_suzuki
January 24, 2019
Technology
0
120
深層学習を用いた自然言語処理③
長岡技術科学大学 自然言語処理研究室
B3ゼミ発表資料
shu_suzuki
January 24, 2019
Tweet
Share
More Decks by shu_suzuki
See All by shu_suzuki
文献紹介:Investigating Evaluation of Open-Domain Dialogue Systems With Human Generated Multiple References
shu_suzuki
0
200
文献紹介:Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study
shu_suzuki
0
86
文献紹介: How to Make Context More Useful? An Empirical Study on Context-Aware Neural Conversational Models
shu_suzuki
0
360
文献紹介:Conversational Response Re-ranking Based on Event Causality and Role Factored Tensor Event Embedding
shu_suzuki
0
180
文献紹介:Modeling Semantic Relationship in Multi-turn Conversations with Hierarchical Latent Variables
shu_suzuki
0
80
文献紹介:ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation
shu_suzuki
0
220
文献紹介:Better Automatic Evaluation of Open-Domain Dialogue Systems with Contextualized Embeddings
shu_suzuki
0
130
文献紹介:Why are Sequence-to-Sequence Models So Dull?
shu_suzuki
0
75
文献紹介:Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
shu_suzuki
0
220
Other Decks in Technology
See All in Technology
脳が溶けた話 / Melted Brain
keisuke69
1
1.1k
OPENLOGI Company Profile for engineer
hr01
1
61k
「お金で解決」が全てではない!大規模WebアプリのCI高速化 #phperkaigi
stefafafan
5
2.4k
来期の評価で変えようと思っていること 〜AI時代に変わること・変わらないこと〜
estie
0
110
20260323_データ分析基盤でGeminiを使う話
1210yuichi0
0
190
GitHub Advanced Security × Defender for Cloudで開発とSecOpsのサイロを超える: コードとクラウドをつなぐ、開発プラットフォームのセキュリティ
yuriemori
1
110
ハーネスエンジニアリング×AI適応開発
aictokamiya
1
660
夢の無限スパゲッティ製造機 #phperkaigi
o0h
PRO
0
390
ADK + Gemini Enterprise で 外部 API 連携エージェント作るなら OAuth の仕組みを理解しておこう
kaz1437
0
230
RGBに陥らないために -プロダクトの価値を届けるまで-
righttouch
PRO
0
130
Kubernetesの「隠れメモリ消費」によるNode共倒れと、Request適正化という処方箋
g0xu
0
150
AIエージェント時代に必要な オペレーションマネージャーのロールとは
kentarofujii
0
210
Featured
See All Featured
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
200
Navigating Weather and Climate Data
rabernat
0
150
Designing for humans not robots
tammielis
254
26k
We Have a Design System, Now What?
morganepeng
55
8k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
90
Rebuilding a faster, lazier Slack
samanthasiow
85
9.4k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
190
Making the Leap to Tech Lead
cromwellryan
135
9.8k
First, design no harm
axbom
PRO
2
1.1k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Leo the Paperboy
mayatellez
5
1.6k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
0
180
Transcript
深層学習を用いた自然言語処理(3) seq2seqを用いた言語モデルによる文章生成 鈴木脩右 2019/1/24 長岡技術科学大学 自然言語処理研究室 1
目次 言語モデル seq2seq おわりに 2
言語モデル
言語モデルとは • 単語の並びに対して確率を与える • 自然な単語の並びかを確率で評価 例) 「You say goodbye」→ 高確率 「You
say good die」→ 低確率 • 様々なアプリケーションに応用可能 例)機械翻訳,対話システム • 確率分布により文章生成が可能 3
数式による表現 w1 , · · · , wm という順序で単語が出現する確率 (同時確率)
は次式で表される P(wt |w1 , · · · , wm ) = m t=1 P(wt |w1 , · · · , wt−1 ) 4
評価方法 モデルの予測性能を perplexity(確率の逆数) で評価 L = − 1 N n
t tnk log ynk perplexity = eL tnk :onehot ベクトルの正解ラベル, ynk :確率分布,L:損失関数 5
seq2seq
seq2seq(sequence to sequence)とは • 時系列データを別の時系列データに 変換するモデル • Encoder-Decoder モデルとも呼ばれる •
2 つの RNN モデルを利用する 6
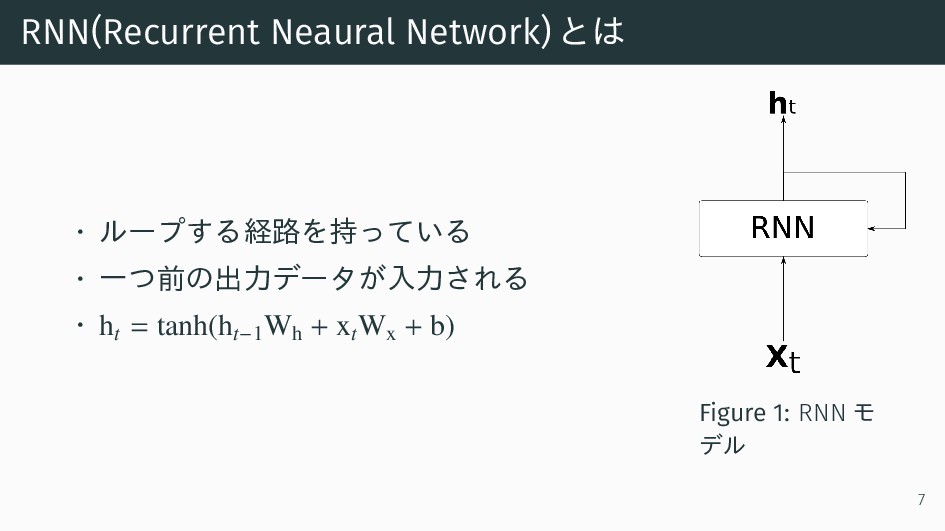
RNN(Recurrent Neaural Network)とは • ループする経路を持っている • 一つ前の出力データが入力される • ht =
tanh(ht−1 Wh + xt Wx + b) Figure 1: RNN モ デル 7
RNN言語モデル Figure 2: RNN 言語モデル 8
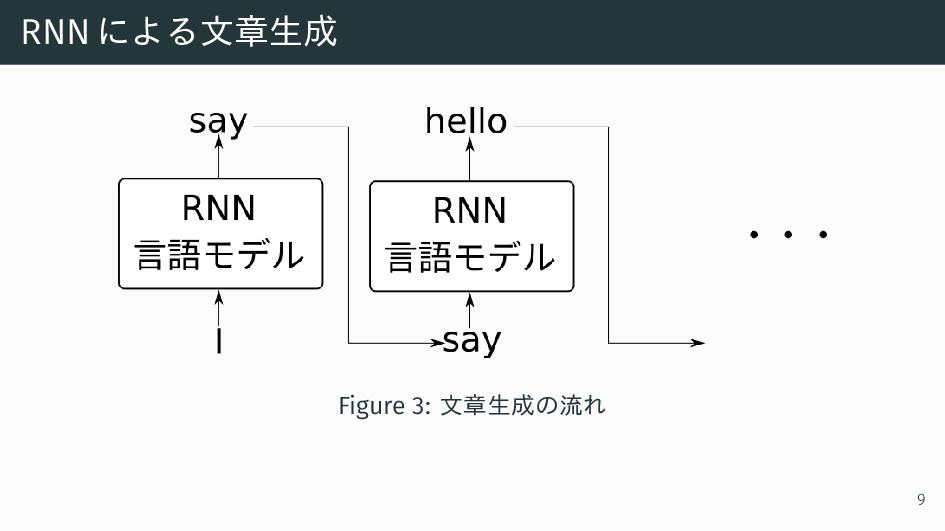
RNNによる文章生成 Figure 3: 文章生成の流れ 9
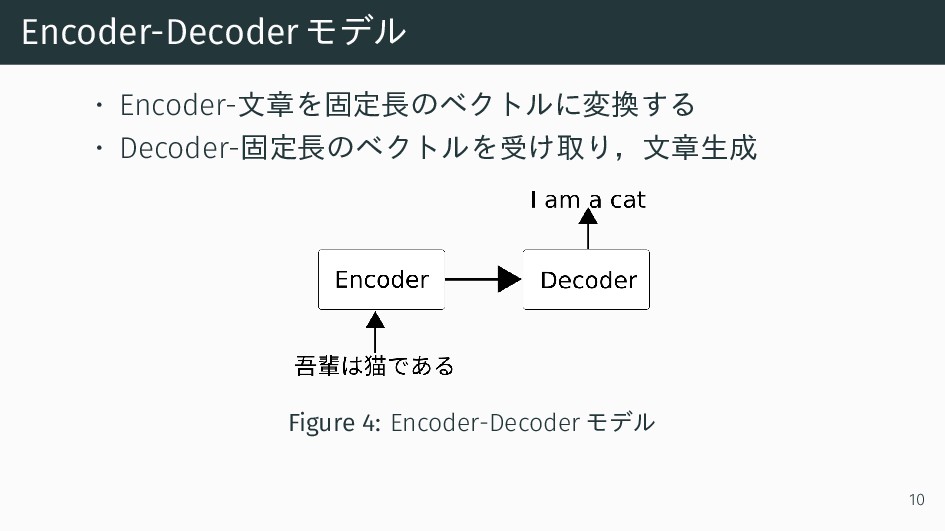
Encoder-Decoderモデル • Encoder-文章を固定長のベクトルに変換する • Decoder-固定長のベクトルを受け取り,文章生成 Figure 4: Encoder-Decoder モデル 10
seq2seqの改良 • Encoder で固定長のベクトルに変換するため,長文に対応 できない → 単語ベクトルを行列にまとめて Decoder に渡す • Decoder
はまとまった行列を受け取れない → 対応関係にある単語の情報を抜き出す (Attention) • 行列と,単語の重要度の重み付き和で Attention を実現 → 単語の重要度は,固定長ベクトルと行列の類似度に よって算出される 11
おわりに
まとめ • 言語モデルは,単語の羅列を確率として解釈する • seq2seq は時系列データを別の時系列データに変換する • RNN はループする経路を持っている •
Encoder は文章をベクトルに変換する • Decoder はベクトルを受け取り,文章生成する • Attention という手法で,seq2seq を改良できる 12
参考文献 [1] 藤康毅. ゼロから作る Deep Learning ②. オライリー・ジャ パン,2018. [2]
高知宏. 自然言語処理と深層学習. オーム社,2017. 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 [1] 藤康毅. ゼロから作る Deep Learning ②. オライリー・ジャ パン,2018. [2]](https://files.speakerdeck.com/presentations/627b395bca69465fadb65af573df5c4f/slide_15.jpg){kind=link}