확보 ◦ 공정한 비교를 해야함 ◦ 불필요하게 기존 모델보다 안 좋은 모델을 만드는데에 큰 노력을 기울이지 않도록 ◦ 아쉽게도 학외 소속에게는 데이터를 공개하지 않는 경우가 무척 많음4 • 비공개 데이터셋 ◦ 내가 관심있는 도메인에서의 모델 성능은 다를 수 있음 ◦ 데이터 수집에 대한 고민 ▪ 어노테이션 ▪ 정합성 확인 ◦ 데이터 탐색이 필수적 4오픈된 데이터이고 논문 작성을 위한 용도라 하더라도 거절하는 경우가 많음
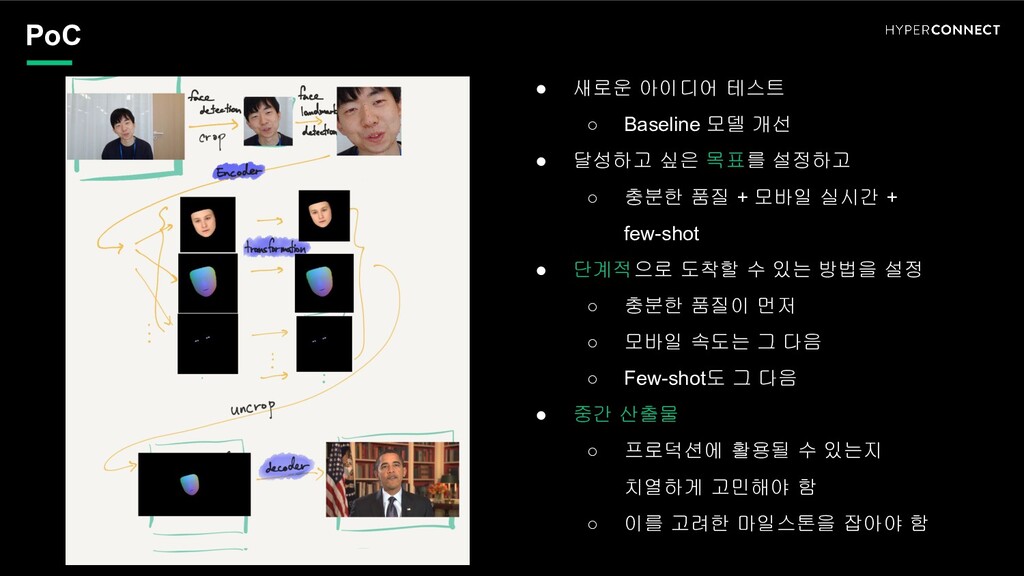
달성하고 싶은 목표를 설정하고 ◦ 충분한 품질 + 모바일 실시간 + few-shot • 단계적으로 도착할 수 있는 방법을 설정 ◦ 충분한 품질이 먼저 ◦ 모바일 속도는 그 다음 ◦ Few-shot도 그 다음 • 중간 산출물 ◦ 프로덕션에 활용될 수 있는지 치열하게 고민해야 함 ◦ 이를 고려한 마일스톤을 잡아야 함
같은 종류의 어그멘테이션 등을 활용해야 • 모델 최적화하는 사람의 역량에 따라 다를 수 있음 ◦ 논문 재현 시 리포팅된 결과보다 좋은 결과가 종종 나옴 • 논문에서는 측정하기 용이한 메트릭을 주로 보지만 프로덕션 환경에서는 다양한 메트릭을 모아야 할 수도 있음 • 콘텐츠를 생성하는 모델은 평가도 어려움
생각대로 잘 되지 않고 시행착오를 많이 겪게 됨 ◦ 모두의 인내와 이해가 필요한 시간 ◦ 방향 설정도 불명확한게 보통이므로 길고 긴 고통의 시간이 될 수 있음 • 몇 가지 접근 방법 ◦ 리터러쳐 서베이에서 유망해보였던 모델 재현하면서 아이디어 얻기 ◦ 다른 도메인의 아이디어 훔쳐오기
해당 정보를 잘 활용할 수 있는 구조 제안 ◦ Image attention block ◦ Target feature alignment • 드라이버의 랜드마크로부터 표정만 추출하여 타겟에게 입힐 수 있는 기법 개발 ◦ Landmark transformer ◦ 추가 레이블 데이터 없이
수 있는 것 ◦ 우리가 풀고자 하는 문제가 무엇인지 명확하게 정의하는 것 ◦ 앞으로 진행해야 하는 실험이 무엇인지 알게 되는 것 ◦ Ablation 테스트 등을 통해 불필요한 컴포넌트를 이해하는 것 • 어차피 숨기고 있어봐야 몇 달 내로 비슷한/더 좋은 기술이 나옴6 6Few-shot Video-to-Video Synthesis
이루어짐 • 최종적인 모델에서 예전에는 의미가 있었으나 더 이상 의미 없는 부분이 있을 수 있음 • Ablation 테스트로 제거 ◦ 열심히 만들었던 컴포넌트가 사실 별로 쓸모 없었다는 결과는 무척 흔하게 나옴 ◦ 결과적으로 프로덕션 환경에서 불필요한 부분을 제거하므로 이득
있음을 회사에서는 인지해야 함 ◦ 팀에서는 리스크를 스스로 판단하고 움직일 수 있어야 함 ◦ 하지만 전문성이 잘 맞는 분야에서는 놀라운 결과를 단시간에 낼 수도 있음 • 팀은 제품에 기여해야 함 ◦ 팀에서 해당 고민을 꼭 해줘야 함 ▪ 기계학습 기술은 약간의 변형을 통해 다방면으로 사용될 가능성이 있음 ▪ 능동적으로 다른 팀과 기술의 활용에 대한 이야기를 해야 함 ◦ 소프트웨어 개발력 + 기계학습 연구력 + 제품 아이디어
◦ 이 기술이 회사에 쓸모 있을까? ▪ 연구를 위한 연구를 대부분의 회사에서는 빛을 발하기 힘듦 • 내가 이 연구를 하면 재미있을까? ◦ 연구에서 막히는 경우 인내심을 발휘할 수 있는 이유 • 기술을 가장 잘 이해하고 있는 것은 연구자 본인 ◦ 사내 다른 팀들과 지속적으로 이야기 해야함
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}