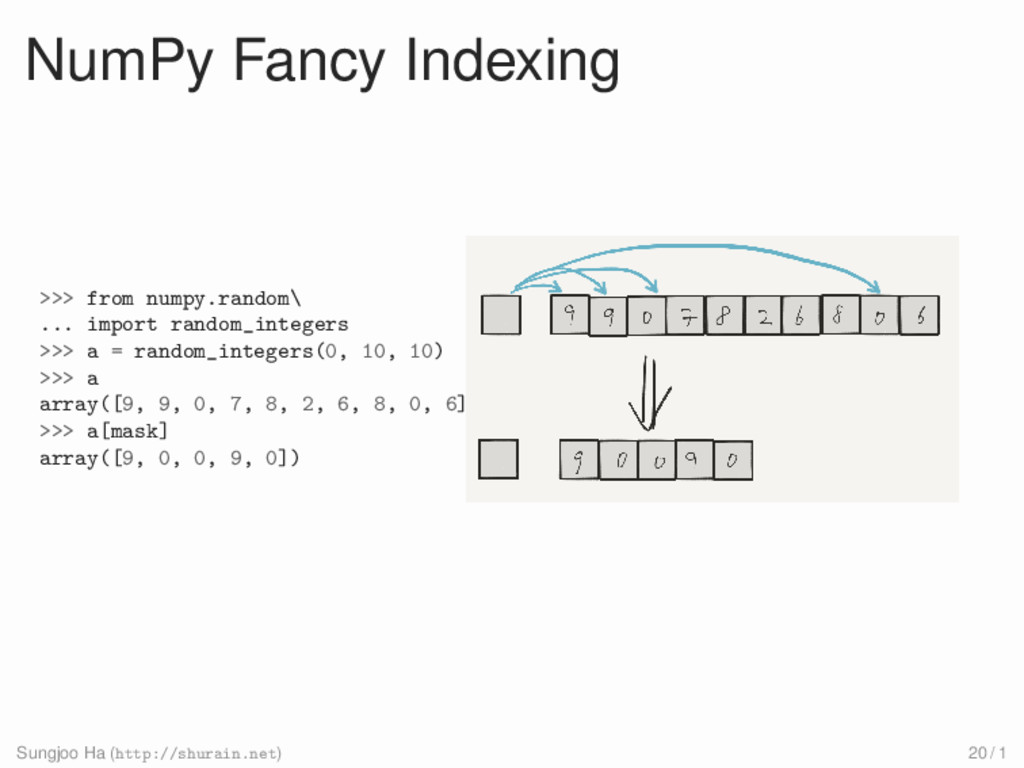
1, 2, 3, 4], [5, 6, 7, 8, 9]]) >>> a[[1, 2, 4], [2, 3, 4]] array([ 7, 13, 24]) >>> a[3:, [0, 1, 3]] array([[15, 16, 18], [20, 21, 23]]) >>> mask = np.array([0, 1, 0, 0, 1], dtype=np.bool) >>> a[mask, 1] array([ 6, 21]) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 0 Sungjoo Ha (http://shurain.net) 22 / 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![리스트 인덱싱 >>> l = [[0, 1, 2], [3, 4,](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_10.jpg){kind=link}
{kind=link}
![파이썬 슬라이싱 >>> l = [[0, 1, 2], [3, 4,](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_12.jpg){kind=link}
![NumPy 슬라이싱 >>> a = np.arange(6).reshape(2, 3) >>> a[:, 1]](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_13.jpg){kind=link}
{kind=link}
![인덱싱 그리고 슬라이싱 >>> a[0] array([0, 1, 2, 3, 4])](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_15.jpg){kind=link}
{kind=link}
![NumPy Fancy Indexing >>> a = np.arange(6) >>> a[np.array(mask)] array([0,](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fancy Indexing >>> a[0, 1] 1 >>> a[[0, 1]] array([[0,](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![벡터화된 연산 >>> a = np.array([1, 2, 5]) >>> b](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_26.jpg){kind=link}
![브로드캐스팅 >>> a = np.array([1, 2, 5]) >>> a +](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Reduction >>> l = [[0, 1, 2], [3, 4, 5]]](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_33.jpg){kind=link}
{kind=link}
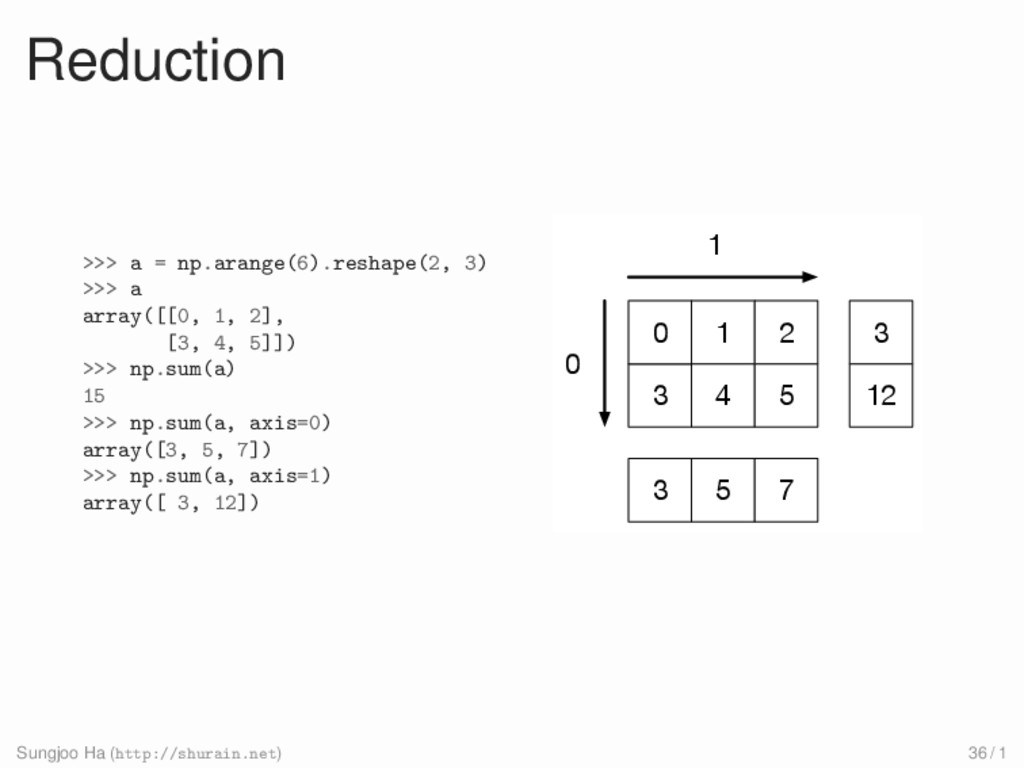{kind=link}
{kind=link}
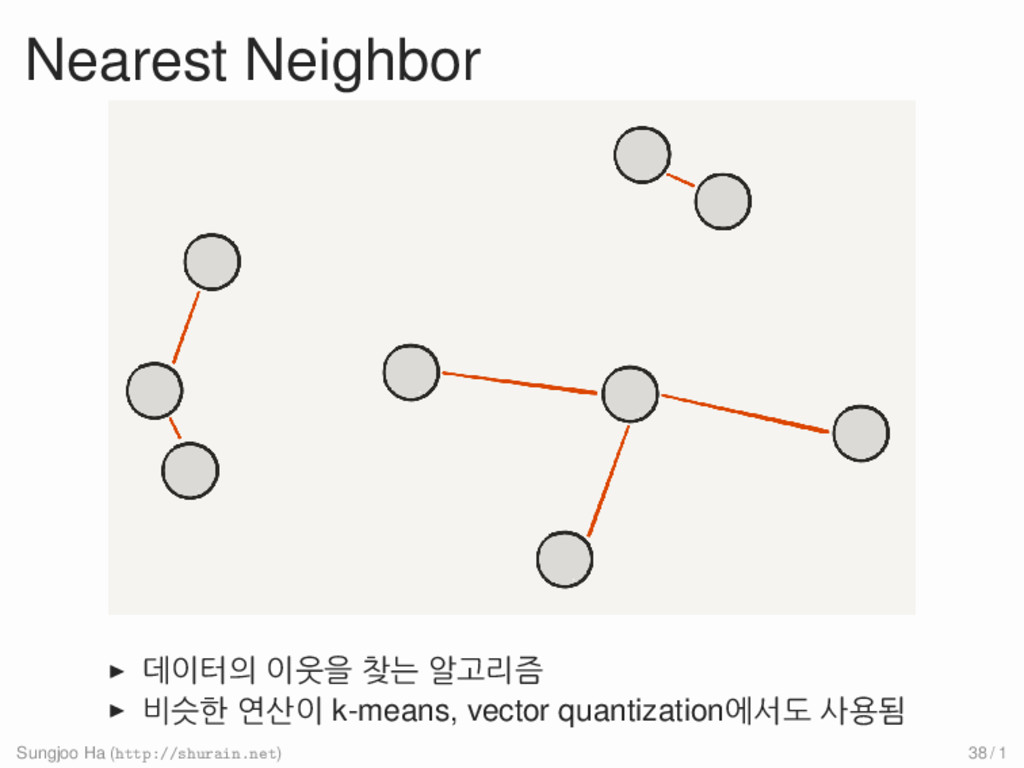{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Nearest Neighbor Indexing oneself = np.arange(n) distance[oneself, oneself] = np.inf](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![감사합니다 Email : [email protected] Twitter : @shurain Homepage : http://shurain.net](https://files.speakerdeck.com/presentations/9320b47961fb49859bbd7d02dec64b03/slide_46.jpg){kind=link}