Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2018-06-08 HPCS輪講 High Performance Computing §6...
Search
TAKAHASHI Shuuji
June 08, 2018
Research
59
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2018-06-08 HPCS輪講 High Performance Computing §6.4-6.5.2
TAKAHASHI Shuuji
June 08, 2018
More Decks by TAKAHASHI Shuuji
See All by TAKAHASHI Shuuji
Intro to Kubernetes
shuuji3
0
120
データ指向アプリケーションデザイン §1.4 - 1章まとめ
shuuji3
0
130
2020-02-09 Gfarmワークショップ2020
shuuji3
0
64
2019-12-26 Programming Environment - Interoperable Computing by Federated Kubernetes
shuuji3
0
56
2019-10-15 HPCS Lab. SSチーム論文読み会 "POSIX is Dead! Long Live... errr... What Exactly?" (POSIXは死んだ! 長生き... えー... 一体どういうこと?)
shuuji3
0
89
2019-09-20 分散オブジェクトストレージ Ceph のための Spark ストレージコネクタの設計
shuuji3
0
270
HPCS Lab. SSチーム 論文読み会 "The benefits and costs of writing a POSIX kernel in a high-level language"
shuuji3
0
140
High Performance Computing: Modern Systems and Practices §1.2-1.3
shuuji3
0
95
2018-07-23 HPCS輪講 High Performance Computing §16.5.2-16.5.3
shuuji3
0
99
Other Decks in Research
See All in Research
論文紹介:HalluCitation Matters
wasyro
0
130
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
11
8.7k
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
340
Using our influence and power for patient safety
helenbevan
0
370
「AIとWhyを深堀る」をAIと深堀る
iflection
0
520
IA for theory
gpeyre
0
260
Language and AI
ayaniwa
0
170
某助成金プロジェクト採択に向けて企業研究所のアウトリーチ専任者がやったこと
afroscript
0
110
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
370
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
Featured
See All Featured
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.6k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Crafting Experiences
bethany
1
210
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
300
Odyssey Design
rkendrick25
PRO
2
730
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
The Curious Case for Waylosing
cassininazir
1
430
Transcript
High Performance Computing -Modern Systems and Practices- §6.4 - §6.5.2
[本] pp.199-207 / [PDF] pp.223-231ov HPCS Lab. システムソフトウェアチーム B4 高橋 宗史 2018/06/08 1
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 2
目次 2/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.5 記憶の階層
(MEMORY HIERARCHY) ◦ 6.5.1 データの再利用と局所性 (DATA REUSE AND LOCALITY) ◦ 6.5.2 記憶の階層 (MEMORY HIERARCHY) ◦ (6.5.3 メモリシステムの性能 (MEMORY SYSTEM PERFORMANCE)) 3
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 4
6.4 プロセッサ・コア・アーキテクチャ (PROCESSOR CORE ARCHITECTURE) 1/4 現代のマルチコアプロセッサ (「ソケット」とも呼ばれる) は、様々な要素から構成されて いる。
構成要素 • 複数のコア • 潜在的に複雑なキャッシュの階層 • 外部メインメモリや I/O バスへの1つ以上のインターフェイス • 補助的な論理回路 5
6.4 プロセッサ・コア・アーキテクチャ (PROCESSOR CORE ARCHITECTURE) 2/4 SMPプロセッサの詳細には様々なものあるが、以下のようないくつかの共通のパラメー タで特徴づけることができる。 • 1ソケットあたりのコア数
• 各キャッシュレベルのサイズや相互接続性 ◦ キャッシュレベルは、通常は最大で 2次 or 3次 (L2、L3と書く) • コアのクロック周波数 • コアあたりのALUの数 (ILP) • ダイのサイズ ◦ 通常 1 - 4cm² 6
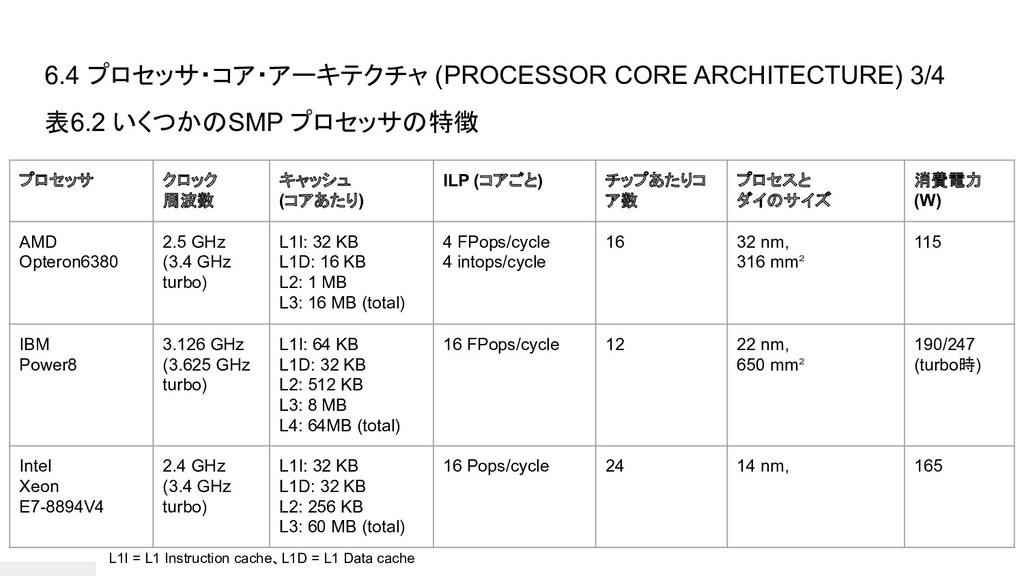
6.4 プロセッサ・コア・アーキテクチャ (PROCESSOR CORE ARCHITECTURE) 3/4 表6.2 いくつかのSMP プロセッサの特徴 プロセッサ
クロック 周波数 キャッシュ (コアあたり) ILP (コアごと) チップあたりコ ア数 プロセスと ダイのサイズ 消費電力 (W) AMD Opteron6380 2.5 GHz (3.4 GHz turbo) L1I: 32 KB L1D: 16 KB L2: 1 MB L3: 16 MB (total) 4 FPops/cycle 4 intops/cycle 16 32 nm, 316 mm² 115 IBM Power8 3.126 GHz (3.625 GHz turbo) L1I: 64 KB L1D: 32 KB L2: 512 KB L3: 8 MB L4: 64MB (total) 16 FPops/cycle 12 22 nm, 650 mm² 190/247 (turbo時) Intel Xeon E7-8894V4 2.4 GHz (3.4 GHz turbo) L1I: 32 KB L1D: 32 KB L2: 256 KB L3: 60 MB (total) 16 Pops/cycle 24 14 nm, 165 L1I = L1 Instruction cache、L1D = L1 Data cache
6.4 プロセッサ・コア・アーキテクチャ (PROCESSOR CORE ARCHITECTURE) 4/4 • アプリケーション・プログラマの観点からは詳細の多くは問題にならないかもしれな いが、以下の点は、実行パフォーマンスを決定するのに支配的となっている。 ◦
命令を発行する割合 ◦ 1命令発行ごとのオペレーションの実行数 ◦ メモリへの平均アクセス時間 (§ 6.5) ◦ I/Oリクエストによる遅延 • § 6.5 では、メモリとキャッシュの階層の詳細と、局所性がメモリへの平均アクセス 時間の削減に果たす役割について議論する。 8
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 9
6.4.1 実行パイプライン (EXECUTION PIPELINE) 1/6 • 初期の世代の逐次実行のコンピュータは、「フェッチ―実行―ライトバック」 (fetch―execute―writeback) と呼ばれるサイクルで、1度に1つの命令のみを発 行・実行していた。
• 初期の真空管やトランジスタ技術で可能な低クロック周波数では、このサイクルで 十分だった。 • しかし、技術の発展(小規模・中規模集積回路など)によりクロック周波数が向上す ると、この直接的なアプローチは許容できないものになってきた。 • 命令完了までに発行する命令全体の複雑さのため、非常に多くの論理回路のレイ ヤーが必要になり、結果として遅延が可能なクロック周期に限界を課してしまった。 10
6.4.1 実行パイプライン (EXECUTION PIPELINE) 2/6 • パイプライン構造は、特定の計算命令の全体を、全体として同じ機能を達成する小 さな命令 (microoperation) 列に分割するために採用されてきた。
• 命令発行から完了までの時間は、実際には同じ目的を持つ1つの論理関数の実行 より長くなるが、パイプラインの各ステージにかかる時間は短くなる。 • クロック速度は命令の発行サイクル時間によって制限されており、また、命令の発 行サイクル時間自体も、最も長いパイプラインを通る伝達の遅延によって決定され る。そのため、実行パイプラインを、同じ遅延を持つできるだけ多くのステージに分 割することで、クロック速度をかなり高くすることができる。 • 初期の実行パイプラインは4か5ステージだったが、最終的には、より長いパイプラ インに置き換えられた。 11
6.4.1 実行パイプライン (EXECUTION PIPELINE) 3/6 • Chapter 2 (HPC ARCHITECTURE1:
SYSTEMS AND TECHNOLOGIES) で 議論したように、パイプラインの論理回路構造は、各パイプラインステージが同時 に実行できるため、非常に細かい粒度の並列性を持つ形式を活用する一般的な手 法の一つとなっている。 • 機能パイプラインの並列度が、形成されるパイプライン全体のステージ数と等しくな るのが理想。 • 実行パイプラインは、クロックサイクルの削減と、パイプラインを構成するステージ の並列性の両方から恩恵を受けられる。 • しかし、その他のさまざまな要因 (次スライド) により、パイプラインを効率的に実行 できる度合いには制限が課されている。 12
6.4.1 実行パイプライン (EXECUTION PIPELINE) 4/6 パイプラインの実行効率に制限をかける6つの要因 1. 関数全体のサイズが必要な論理回路層の数に制限をかけている。そのため、パイ プラインを分割できる最大のステージ数が限定される。 2.
各ステージ上の論理回路層の数の偏りにより、あるステージが他のステージよりも わずかに長くなってしまい、それにより、シグナルが実行パイプラインを伝達する速 度に遅れが生じる。 3. 連続するパイプラインステージ間にある境界のオーバーヘッドが各ステージに追加 の伝達遅延を加えてしまう。これにより、信号が実行パイプラインを進む速さが制限 される。 13
6.4.1 実行パイプライン (EXECUTION PIPELINE) 5/6 パイプラインの実行効率に制限をかける6つの要因 4. 必ずしもすべての関数の実行が同一ではなく、必要な機能ステージ数も同じわけで はない。他の実行サイクルがより少ないステージしか必要ない場合、より多くのス テージが必要な関数がハードウェアの一部を浪費してしまう。
5. ある命令の中間値が後の命令で必要になったとしても、できるだけ早い段階で後続 の命令が発行されるため、そのときには中間値が利用できなくなってしまうことがあ る。逆に、前の命令の結果を得るための待ち時間が生じてしまうこともある。 14
6.4.1 実行パイプライン (EXECUTION PIPELINE) 6/6 6. 条件命令が実行パイプラインを効率的に使用するのを複雑化してしまう。条件命令 は不連続な命令位置へ移動する分岐を実行することだが、実行するためには、条 件文の値が真かつ決定されていなければならない。小さな実行列の数を増大させ ることにより、実行パイプライン内の実行の流れを乱し、「バブル」(bubble)
とも呼 ばれる遅延の挿入を引き起こす。その結果、実行が遅くなってしまう。 • 上記のようなさまざまな隠れた要因が存在しても実行速度を向上するために、コア のアーキテクチャは多くの形態・機能を伴って進化してきた。 • §6.4.2 以降では、その進化を簡単に紹介する。 15
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 16
6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) • スーパースカラ・アーキテクチャは、1つの命令を発行するだけで、複数の操作を実 行可能にした。 • これが可能になったのは、浮動小数点・整数/論理の関数ユニットを含む、複数の ALUを組み合わせたため。
• 同じ命令で複数のデータ値に実行できるようにするために、SIMD 命令を加えられ るようになった。これは ILP (Instruction-level parallelism) として知られ、プロ セッサが利用できる粒度の細かい並列性を提供し、特殊なケースでは、トータルの スループットが劇的に向上する。 • 残念なことに、20年以上に渡る経験により、一般にそのようなピーク性能はめった に発揮されず、高度な設計のために、複雑性・オーバーヘッド・消費電力を増大さ せてしまうことが分かってきている。 17
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 18
6.4.3 分岐予測 (BRANCH PREDICTION) 1/3 • 条件分岐の問題は §6.4.1 で議論した。条件文のブール値の決定と、次に実行さ れる命令の仮想アドレスの発行の間にある遅延によってバブル
(bubble) が生じ る。 • このバブルを削減するために取られる手法が、 「分岐予測 (branch prediction)」と呼ばれる統計的なアプローチ。 • 名前が暗に示しているように、発行された分岐命令に対して、ハードウェアが2つの 異なる命令のいずれが発行されるかを予測するというもの。 • この技術には長い歴史があるので、詳しく知りたい人は参考文献の[2-6](PDF p.248)を参照。 19
6.4.3 分岐予測 (BRANCH PREDICTION) 2/3 • 今の議論における分岐予測のキーアイデアは、「2つのうちの一方の分岐はより実 行されやすい」という分岐予測の特定の役割に依存しているということ。 • 例1:
分岐がループの最後で使われていた場合 ◦ ループを抜けて続く文を実行するよりも、条件文が実行の流れをループの上 に戻す確率が非常に高くなる。 • 例2: 分岐がエラーハンドリングに関係している場合 ◦ 通常の計算の流れでは、エラーハンドリングが実行されるよりも、次の命令が 発行される確率がとても高くなる。 20
6.4.3 分岐予測 (BRANCH PREDICTION) 3/3 • 分岐予測をする場合、間違った選択がなされる可能性が常に存在するため、ハー ドウェア・アーキテクチャは、他の経路の計算をロールバックすることが可能でなけ ればならない。このロールバック機構そのものにも、アーキテクチャの長い歴史が ある。
• システムソフトウェアのようなコードでは、分岐命令を非常に多用しているため、分 岐予測アーキテクチャの支援が効率性の向上につながる。 21
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 22
6.4.4 フォワーディング (FORWARDING) 1/2 • 実行パイプラインの概念の要点は、連続した命令を発行する時間の方が、パイプラ インの多数のステージを通って命令が完了するまでの時間よりも、潜在的に非常に 短いこと。 • 連続する2つの命令がある時、2番目の命令が引数として一つ前の(1番目の)命令
の結果の値を必要とするというような、1つ以上の優先順位の制約を課す状況が起 こることがある。 • 通常、命令のオペランドは、コアのレジスタセットから読み込まれる。しかし、上のよ うな状況下では、1番目の命令の結果の値が計算され、レジスタ・バンクにライト バックされてから、2番目の命令がこの中間値が格納されているレジスタから同じ値 を読み込むまでに、十分な時間がない。 • この問題を解決するのがフォワーディングという手法。 23
6.4.4 フォワーディング (FORWARDING) 2/2 「フォワーディング」(forwarding) • フォワーディングは、下流の実行パイプラインのセグメントから、適切な上流のセグ メントへデータを移動する、データ転送のチャンネルを追加すること。 • これにより、引数の値が時間内に利用可能になり、命令がより密接して連続して並
ぶようにすることができる。 • 1つ以上の互いに無関係な命令で必要なギャップを埋めるというコンパイラによる 命令の並び替えを、フォワーディングとを組み合わせることで、パイプラインステー ジを充填し、バブルを削減することができる。 24
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 25
6.4.5 Reservation Station (RESERVATION STATIONS) 1/3 • 異なる命令は完了するのに異なる時間がかかる。そのため、実行パイプラインは、 浮動小数点の掛け算よりも、簡単なブール論理演算においてより短いリンクでマル チパスになる。
• 厳密な命令の順序が維持された場合、すなわち命令の完了順序が命令発行の順 序と同じであることが強制された場合、命令の処理速度が、バックストリーム命令 の繰り返しのストールを伴うような最も遅い命令によって制約されてしまうという問 題が起こる。 • この問題は、1960年代に概念が生まれ、1970年代にデータフローの考えが生まれ た reservation station という手法により対処されるようになった。 26
6.4.5 Reservation Station (RESERVATION STATIONS) 2/3 reservation station • 特別な目的のために作られたユーザーには見えないバッファ・レジスターで、前に
計算した結果の値を一時的に保持する。 • reservation station には、次の2つの情報が感知できる特別な機能がある。 ◦ どの後続の命令が reservation station に保持した値を要求するか。 ◦ その命令が引数の値を取得するべき reservation station はどれか。 • もしある命令が、オペランドの値を、指定した reservation station で利用可能にな る前に取得しようとしたとしても、その命令は reservation station で遅延されること になるが、実行パイプライン自体の進行は妨げられずに済む。 27
6.4.5 Reservation Station (RESERVATION STATIONS) 3/3 reservation station • こうした複雑な
out-of-order スケジュール機構 (よく Tomasulo algorithm として 参照される) を達成するための手法としては、これ以外にも様々な代替のアーキテ クチャ手法がある。 • しかし、いずれの場合でも、reservation station を活用することにより、実行パイプ ラインの操作においてかなりの柔軟性が得られ、非常に効率的な実行が可能に なっている。 28
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 29
6.4.6 マルチスレッディング (MULTITHREADING) 1/3 • ここまでのプロセッサコアの実行パイプラインの議論は、1つ以上の命令を持つ、単 一の命令ストリームを前提としてきた。 • 詳細は複雑なことが分かるが、分岐命令を除き、1命令発行ごとに1つずつインクリ メントするプログラムカウンタ
(あるいは命令ポインタ) が1つだけあるという、フォン ・ノイマンのオリジナルの概念に基づいている。 30
6.4.6 マルチスレッディング (MULTITHREADING) 2/3 • フォン・ノイマンのアイデアはきれいでエレガントなアプローチだが、これまでに議論 してきたような多数のエッジケースに悩まされることになる。 • 問題の多くは、単一の命令ストリームの近接する命令間の相互関係が原因で引き 起こされている。
• 1980年代に、Burton Smithにより、シングルプロセッサコア上でこの問題に対処す る方法の1つとして、マルチスレッディング (multithreading) という概念が導入さ れた。 31
6.4.6 マルチスレッディング (MULTITHREADING) 3/3 マルチスレッディング (multithreading) • 最もシンプルなバージョンでは、マルチスレッドは複数の命令ストリーム (= スレッド)
を合わせたもの。各スレッドは、命令ポインタとそのスレッドに関連するレジスタセッ トを持つ。 • 実行パイプラインの残りの部分はスレッド間で共有され、ラウンドロビンの命令発行 スケジューラが、異なるスレッドから次に実行する各命令フェッチを選択する。 • この工夫により、実行パイプラインの遅延が隠蔽され、もし十分な数のスレッドが実 行されれば、メインメモリのレイテンシも同様に隠すことができる。 32
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 33
コラム: Burton SmithさんとMTA (BURTON SMITH AND THE MTA) 1/6 •
先導的なコンピュータ・アーキテクト、マ ルチスレッディング・アーキテクチャの 父。 • Eckern-Mauchly Award (エッカート・モー クリー賞)、Seymour Cray Award (シーモ ア・クレイ賞) を受賞。 • Denelcor 社を共同設立し、後にTera Computer Company を設立。マルチ スレッディング・アーキテクチャの商業 化を先導した。 34 Photo by Dimitrij Krepis via Wikimedia Commons (@SC07)
コラム: Burton SmithさんとMTA (BURTON SMITH AND THE MTA) 2/6 •
2000年、Silicon Graphics の Cray Reserch business unit を買収後、Tera は Cray に社名を変更。 • HPC開発に活気を与え続けている画期 的な設計のTera MTA (multithreaded architecture) のチーフアーキテクトに なった。 • 2005年にMicrosoftのテクニカルフェロー になり、未来の技術とコンピュータを発展 させてきた。 • -2018/4/2 35 Photo by Dimitrij Krepis via Wikimedia Commons (@SC07)
コラム: Burton SmithさんとMTA (BURTON SMITH AND THE MTA) 3/6 •
MTA-1は、San Diego Supercomputer Centerで稼働していた。 • 初期のシステムは、ヒ化ガリウム (GaAs) をベースにした超高速な論理回路を使用し たユニークな実装だった。 • このアーキテクチャは、4つのプロセッサを 組み込んでおり、128個の独立したレジス タのセットとプログラムカウンターにより、 計512スレッドの同時実行が可能だった。 36 Cray Super Computers http://www.angelfire.com/nj2/sirdom/wp/
コラム: Burton SmithさんとMTA (BURTON SMITH AND THE MTA) 4/6 •
各プロセッサは高速なALUと統合されて おり、ローカルスレッドはそのALUで計算 を実行させることができた。このALUの 共有により、使用率・計算効率、性能の 最大化が実現した。 • MTAの強みは、ALUからメモリアクセス の遅延を隠蔽し、操作の非同期性を調 整する能力にあった。 37 Cray Super Computers http://www.angelfire.com/nj2/sirdom/wp/
コラム: Burton SmithさんとMTA (BURTON SMITH AND THE MTA) 5/6 •
これにより、必要なデータキャッシュを削 減することができ、データキャッシュの一 貫性を維持するための複雑さとコストを 排除することができた。 • また、すべての word に対してempty/full bit を加えたり、タグ付けされたメモリを使 用することで、粒度の細かい同期を可能 にした。 38 Cray Super Computers http://www.angelfire.com/nj2/sirdom/wp/
コラム: Burton SmithさんとMTA (BURTON SMITH AND THE MTA) 6/6 •
プロトタイプ MTA-1 の後継機として、CMOS バージョンのより安価で高密度にパックした MTA-2 を開発。 39 ASCII.jp:スーパーコンピューターの系譜 http://ascii.jp/elem/000/001/053/1053541/ • 2009年には、更に進化した Cray XMT System を開発。 Cray Super Computers - Cray XMT http://www.craysupercomputers.com/crayXMT.htm
目次 2/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.5 記憶の階層
(MEMORY HIERARCHY) ◦ 6.5.1 データの再利用と局所性 (DATA REUSE AND LOCALITY) ◦ 6.5.2 記憶の階層 (MEMORY HIERARCHY) ◦ (6.5.3 メモリシステムの性能 (MEMORY SYSTEM PERFORMANCE)) 40
6.5 記憶の階層 (MEMORY HIERARCHY) 1/3 「メモリ・ウォール」(memory wall) または「フォン・ノイマン・ボトルネック」(von Neumann bottoleneck)
• プロセッサのソケットのデータアクセスに対するピーク需要の割合と、メインメモリ技 術(主にDRAM半導体)の実効スループットとレイテンシのギャップを示す用語。 41
• 図 6.6 に示すように、プロ セッサの性能向上は平均 60 %/年 だが、 メインメモリは 9
%/年 し かない。 • 時間が経つにつれ、 プロセッサとメモリのス ピード差は約 100 倍まで 達してしまった。 42 6.5 記憶の階層 2/3 図 6.6 - プロセッサの性能は 4桁のオーダーで向上しているが、 メインメモリは、同じ期間で 2桁のオーダーしか向上していない。
6.5 記憶の階層 (MEMORY HIERARCHY) 3/3 • この課題に対処し、二次記憶装置の範囲のさらに先へ進むために、一般のコン ピュータアーキテクチャ、特にSMPアーキテクチャは、ストレージコンポーネントの 連続したレイヤーの階層構造を発展させてきた。 •
この階層構造は、階層の一方向では、密度と容量が増えるように、別の方向では、 高いバンド幅と低いレイテンシを含む高いアクセス速度が得られるように構造化さ れている。 43
目次 2/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.5 記憶の階層
(MEMORY HIERARCHY) ◦ 6.5.1 データの再利用と局所性 (DATA REUSE AND LOCALITY) ◦ 6.5.2 記憶の階層 (MEMORY HIERARCHY) ◦ (6.5.3 メモリシステムの性能 (MEMORY SYSTEM PERFORMANCE)) 44
6.5.1 記憶の再利用と局所性 (MEMORY REUSE AND LOCALITY) 1/5 • この記憶の階層のアーキテクチャが成功した基礎には、テータの局所性を活用した データの再利用という戦略がある。
• たとえば、ある変数の値がプログラムから繰り返し、頻繁に利用されるならば、プロ セッサに非常に近い超高速なメモリデバイスに保存していれば、ピークパフォーマ ンスに近い性能が発揮できる。 • 局所性には2種類、時間的な局所性と空間的な局所性がある。 45
6.5.1 記憶の再利用と局所性 (MEMORY REUSE AND LOCALITY) 2/5 1. 時間的な局所性 (temporal
locality) • 前のスライドの例が一例。 • 最近使用されたデータほど使用される確率が高い、というデータの性質を反映して いる。 • 時間的な局所性が高い = 一定時間内に、特定の変数へのアクセス頻度が高い。 • 時間的な局所性が低い = もしアクセスされるとしても、一定時間内の変数へのアク セスが1回だけか、たかだか数回。 46
6.5.1 記憶の再利用と局所性 (MEMORY REUSE AND LOCALITY) 3/5 2. 空間的な局所性 (spatial
locality) • 連続したアドレス空間で近接したデータの局所性に関連があることを示している。 • 空間的な局所性が高い = ある変数に近接する変数が最近アクセスされた場合、そ の変数 (仮想アドレスが付いた値) へのアクセス率が高くなる。 47
6.5.1 記憶の再利用と局所性 (MEMORY REUSE AND LOCALITY) 4/5 • 仮想アドレスの付いた変数の再利用のパターンに関係する2つの形式の局所性 が、プロセッサとメモリ技術の、バンド幅とレイテンシにおける不一致の影響を緩和
するための基礎を提供している。 48
6.5.1 記憶の再利用と局所性 (MEMORY REUSE AND LOCALITY) 5/5 • 実用的な関心からの2番目の要因は、単位面積当たりの記憶容量の特性・アクセ スのサイクル時間・電力消費の間のトレードオフの関係。
• 17章 (Mass Storage) では、利用できる技術は多様であること、データストレージ 技術はこれらのパラメータの面から様々に異なることが示される。 (※17章は輪講では扱わない) • 一般に、高速なメモリ技術ほど、半導体のダイの面積を多く必要としたり、同じ容量 の他のメディアと比較してより多くの電力を消費する。 • すべてのソフトウェアと、与えられたユーザーアプリケーションに必要なすべての データを格納できるほど巨大なメインメモリのレイヤーを作るのは現実的ではない。 一方、プロセッサ・コアが発行する命令のスループットがピークに達した時でも十分 に使用できるほど高速に動作させる必要はある。 49
目次 2/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.5 記憶の階層
(MEMORY HIERARCHY) ◦ 6.5.1 データの再利用と局所性 (DATA REUSE AND LOCALITY) ◦ 6.5.2 記憶の階層 (MEMORY HIERARCHY) ◦ (6.5.3 メモリシステムの性能 (MEMORY SYSTEM PERFORMANCE)) 50
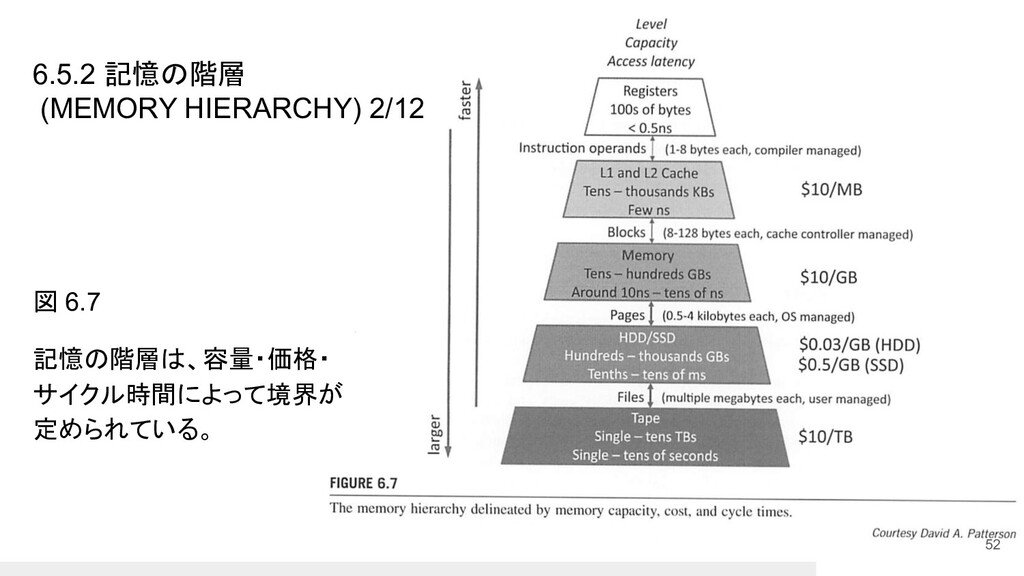
6.5.2 記憶の階層 (MEMORY HIERARCHY) 1/12 • SMPシステムを含む現代のコンピュータ・アーキテクチャが、データの局所性を活 用してこれらのトレードオフに対して行ってきた伝統的な対処の手段は、記憶の階 層構造 (メモリスタックとしても知られている)
の中にある。 • 図 6.7 (次スライド) に示すように、記憶の階層は、メモリ・ストレージ技術のレイ ヤーから構成される。 • 各レイヤーは、メモリ容量・コスト・サイクル時間のそれぞれに異なるトレードオフを 持ち、それらはバンド幅とレイテンシーに反映されている。 51
図 6.7 記憶の階層は、容量・価格・ サイクル時間によって境界が 定められている。 52 6.5.2 記憶の階層 (MEMORY HIERARCHY)
2/12
6.5.2 記憶の階層 (MEMORY HIERARCHY) 3/12 テープ・アーカイブ・ストレージ • 最も遅いが、最も大きな容量を持つ。 • デバイスによっては数千本のテープモジュールからなり、機械的に動作するライブ
ラリに格納されている。 • 合計容量はエクサバイトに及ぶこともある。 • 1 MB あたりたった 1 セント程度の費用しかかからない。 • 欠点は、テープが外れていた場合、アクセスに数分かかることもあること。 • 直線上になっているため、端から端まで移動するのに時間がかかる。 • テープストレージ + HDD/SSD (次スライド) = 3次記憶装置 (tertiary storage) と呼 ばれる。 53
6.5.2 記憶の階層 (MEMORY HIERARCHY) 4/12 ハードディスク・ドライブ (HDD) • テープと同様に磁気メディアを利用。 •
ディスク上のデータは、軸に沿って回転する「シリンダ」と呼ばれる同心円のリング にレイアウトされている。 • 回転するディスク上を半径方向に沿ってアームが移動し、必要なデータがアーム ヘッドで検出されるまで待機する。 • 通常のディスク容量は数 TB。ピーク転送速度は 300 MB/s 程度。アクセス時間の 上限は約 10 ms。 • メインメモリへのアクセスより 10 万倍遅いが、1,000 倍の容量を持つテープドライ ブよりは 1 万倍高速。 54
6.5.2 記憶の階層 (MEMORY HIERARCHY) 5/12 不揮発性ランダムアクセスメモリ (SSD) • メインメモリよりは遅いが、ディスクよりは非常に高速なレスポンスを持つため、だん だんディスクドライブを部分的に置換してきている。
• 通常、大容量ストレージは、ファイルや、ファイルと他のディレクトリを格納するディ レクトリと呼ばれる論理的なデータモジュールの形式でユーザーに表示される。 55
6.5.2 記憶の階層 (MEMORY HIERARCHY) 6/12 プロセッサ・コアのレジスタ • 記憶の階層の最上位に位置する。 • クロックと同じ速度で動作し、複数のアクセスポートをサポートし、各命令サイクル
でレジスタバンクとの複数の読み書きが実行可能。 • ネイティブのプロセッサの速度で動作するためには、チップ上に広い面積が必要 で、サイクルごとに非常に多くの電力を消費する。 • レジスタはメモリのアドレス空間とは独立した独自のアドレス空間を持つ。 • 命令セット・アーキテクチャ (instruction-set architecture; ISA) は、同一のレジスタ とメインメモリ上の変数の間で、データを明示的に移動させるように論理的に構造 化されている。 56
6.5.2 記憶の階層 (MEMORY HIERARCHY) 7/12 メインメモリ • DRAM 半導体デバイスにより提供される。 •
DRAM 半導体を利用したコンポーネントの多くは、業界標準のインターフェイスに 準拠したソケットに差し込まれるPCカードにマウントされる。 • SMP プロセッサの場合、たいていコアあたり最大 4 GB のメモリが提供されるが、 ソケットあたりのコア数によっては、コアあたり 1 GB まで下がることもある。 • しかし、レジスタから DRAM へのアクセス時間は、100〜200 クロックサイクルもあ るため、効率的な計算のためには時間がかかりすぎる。 57
6.5.2 記憶の階層 (MEMORY HIERARCHY) 8/12 キャッシュシステム • プロセッサ・コアのレジスタと SMP のメインメモリモジュールの間には、タイミングと
バンド幅に極端な差があるこれらのデバイス間でインピーダンス整合をとるための キャッシュシステムが存在する。 • 論理的には、キャッシュシステムは、別個に参照が可能という点ではなく、メモリア クセス要求を受け付けるという点で、ユーザにとって透過的。 58
6.5.2 記憶の階層 (MEMORY HIERARCHY) 9/12 • もしコアによってリクエストされた変数のアドレスが変数の値のコピーをキャッシュの どこかに保持しており、目的のコアレジスタに対する読み込み命令だった場合、 キャッシュはその値を提供する。 •
もしコピーが存在しない場合、キャッシュシステムは自動的にリクエストをメインメモ リに受け渡し、データアクセスを実行する。 • データの局所性が適用される場合、キャッシュの「ヒット」が起こりやすくなるため、 キャッシュのアクセス時間は、遅いメインメモリではなく、高速なキャッシュのアクセ ス時間となる。 59
6.5.2 記憶の階層 (MEMORY HIERARCHY) 10/12 • モダンな SMP プロセッサの場合、通常、キャッシュは高速なメモリの単一のレイ ヤーではなく、速度と容量のバランスを取った複数レイヤーの構成。
• 典型的な構成では、1次、2次、3次 (L1, L2, L3) の3層構成になっている。 • L1キャッシュは最も高速で容量の小さいキャッシュで、通常、十分なピーク幅を提 供するためにデータと命令の2種類に分かれている。(L1d + L1i) • L2キャッシュは、少し遅いが容量が大きい。 • L1、L2 ともに SRAM 回路で構成される。 • L3キャッシュは更に容量が大きく、低レイヤーのキャッシュだが遅い。 • L3キャッシュのみ、高密度を達成するために SRAM 回路ではなく、別の DRAM チップになっている。 60
6.5.2 記憶の階層 (MEMORY HIERARCHY) 11/12 • 単純な階層構造により、各コアにそれぞれ独立した L1、L2、L3 キャッシュを提供し ているが、複数コアが同一のデータで作業することはよくある。
• そのため、1つ以上のコアがキャッシュの一部を共有できるようにすることで、1レイ ヤー上のデータの最大量を増加させることが可能になっている。 61
6.5.2 記憶の階層 (MEMORY HIERARCHY) 12/12 キャッシュ別の共有の有無 • L1キャッシュは、通常、自分のバンド幅の最大まで需要があるため、共有されるこ とはない。 •
L3キャッシュは、複数のプロセッサコアやそのサブセットと共有されるのが普通。 • L2キャッシュは、1つのコア専用に使用されることも、2つ以上のコアで共有されるこ ともある。 • キャッシュ共有のトレードオフの一部には、バンド幅、共有したコアの間でのキャッ シュアクセスの競合の可能性がある。◻ 62
目次 1/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.4 プロセッサ・コア・アーキテクチャ
(PROCESSOR CORE ARCHITECTURE) ◦ 6.4.1 実行パイプライン (EXECUTION PIPELINE) ◦ 6.4.2 命令レベル並列性 (INSTRUCTION-LEVEL PARALLELISM) ◦ 6.4.3 分岐予測 (BRANCH PREDICTION) ◦ 6.4.4 フォワーディング (FORWARDING) ◦ 6.4.5 Reservation Station (RESERVATION STATIONS) ◦ 6.4.6 マルチスレッディング (MULTITHREADING) ◦ [コラム] Burton Smith さんと MTA (BURTON SMITH AND THE MTA) 63
目次 2/2 6. 対称型マルチプロセッシング (SYMMETRIC MULTIPROCESSOR ARCHITECTURE) • 6.5 記憶の階層
(MEMORY HIERARCHY) ◦ 6.5.1 データの再利用と局所性 (DATA REUSE AND LOCALITY) ◦ 6.5.2 記憶の階層 (MEMORY HIERARCHY) ◦ (6.5.3 メモリシステムの性能 (MEMORY SYSTEM PERFORMANCE)) 64
おわり 65
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}