Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2018-07-23 HPCS輪講 High Performance Computing §1...
Search
TAKAHASHI Shuuji
July 23, 2018
Research
99
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2018-07-23 HPCS輪講 High Performance Computing §16.5.2-16.5.3
TAKAHASHI Shuuji
July 23, 2018
More Decks by TAKAHASHI Shuuji
See All by TAKAHASHI Shuuji
Intro to Kubernetes
shuuji3
0
120
データ指向アプリケーションデザイン §1.4 - 1章まとめ
shuuji3
0
130
2020-02-09 Gfarmワークショップ2020
shuuji3
0
64
2019-12-26 Programming Environment - Interoperable Computing by Federated Kubernetes
shuuji3
0
56
2019-10-15 HPCS Lab. SSチーム論文読み会 "POSIX is Dead! Long Live... errr... What Exactly?" (POSIXは死んだ! 長生き... えー... 一体どういうこと?)
shuuji3
0
89
2019-09-20 分散オブジェクトストレージ Ceph のための Spark ストレージコネクタの設計
shuuji3
0
270
HPCS Lab. SSチーム 論文読み会 "The benefits and costs of writing a POSIX kernel in a high-level language"
shuuji3
0
140
High Performance Computing: Modern Systems and Practices §1.2-1.3
shuuji3
0
95
2018-06-08 HPCS輪講 High Performance Computing §6.4-6.5.2
shuuji3
0
59
Other Decks in Research
See All in Research
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
590
AIで最適化を解けるか?
mickey_kubo
0
140
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
11
8.7k
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.3k
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
「AIとWhyを深堀る」をAIと深堀る
iflection
0
520
NLP colloquium: AI Safety Survey
kanekomasahiro
0
850
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
180
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
340
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
370
Featured
See All Featured
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Navigating Team Friction
lara
192
16k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
340
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
ラッコキーワード サービス紹介資料
rakko
1
3.9M
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Transcript
High Performance Computing -Modern Systems and Practices- §16.5.2-16.5.3 OpenACC Directives
本 pp.495-501 / PDF pp.515-521 HPCS Lab. システムソフトウェアチーム B4 高橋 宗史 2018/07/23 1
2
3
目次 • 16.5.2 OpenACC Kernels 構文 ◦ 三角行列とベクトルの積の演算を、OpenACC の kernels
ディレクティブを利用して高速化する。 • 16.5.3 データ管理 (Data Management) ◦ ホストのメモリとアクセラレータのメモリ間のデータ転送の 制御方法について。 4
16.5.2 OpenACC Kernels 構文 コンパイラによる解析 • コンパイラがコード上に kernels ディレクティブを検出すると、ディレクティブが修飾 するセクションを解析し、アクセラレータ上で順番に実行される「並列カーネル
(parallel kernel)」に変換する。 • (カーネルによっては、gangs-workerモデルのギャングやワーカーの数とはベクト ルのサイズが異なる場合もある。) • ワークロードの分割の仕方は、典型的な例では、コード上のループのネストごとに1 つのカーネルを割り当てるような方法がとられる。 5
16.5.2 OpenACC Kernels 構文 kernels と parallel ディレクティブの違い • 主な違い:
parallel 構文はプログラマーが各種パラメータを設定して、アクセラレー ターの実行リソースに対してワークロードを分割することができるため、自由度が高 い。一方 kernels 構文では、パラメータの設定が不要。 • そのため、OpenACC のビギナーには、比較的簡単な kernels ディレクティブがお すすめ。 • ただし、ピーク・パフォーマンスが出ない場合があることに注意が必要。 6
16.5.2 OpenACC Kernels 構文 kernels ディレクティブの構文 #pragma acc kernels [clause...]
{構文ブロック} • clause として受け付けるもの 1. async と wait (parallel と同様) 2. データ管理 (data management) clause ▪ アクセラレータとホスト間のデータ転送方法を指定。 (後半の16.5.3で詳しく説明する。) • parallel ディレクティブと同様の制約がある。 1. 並列領域内ではコード分岐を書いてはいけない。 2. 分岐の結果アクセラレート領域に入るようなコードを書いてはいけない。 7
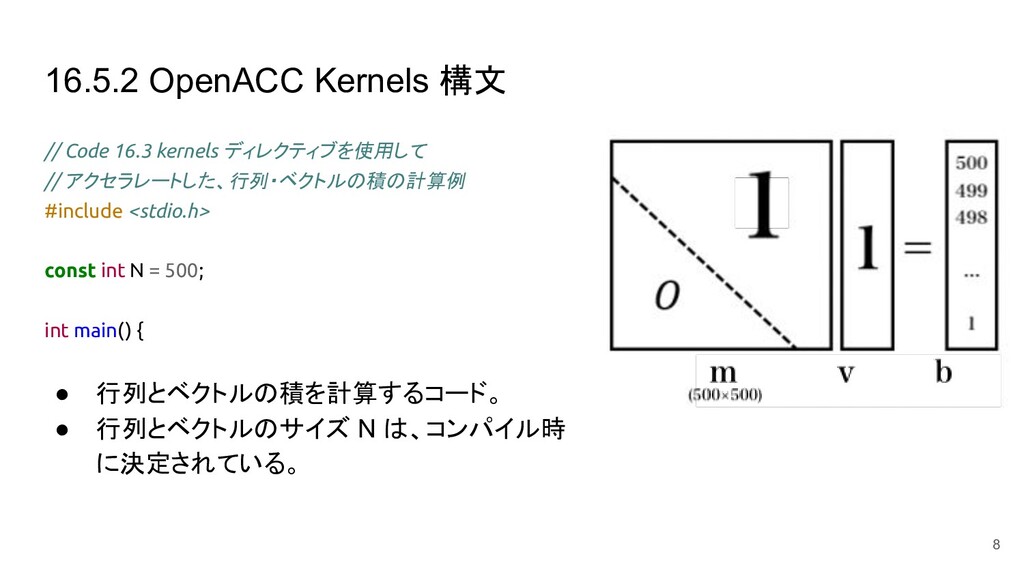
16.5.2 OpenACC Kernels 構文 // Code 16.3 kernels ディレクティブを使用して //
アクセラレートした、行列・ベクトルの積の計算例 #include <stdio.h> const int N = 500; int main() { • 行列とベクトルの積を計算するコード。 • 行列とベクトルのサイズ N は、コンパイル時 に決定されている。 8
16.5.2 OpenACC Kernels 構文 // 上三角行列を初期化する double m[N][N]; for (int
i = 0; i < N; i++) { for (int j = 0; j < N; j++) { m[i][j] = (i > j) ? 0 : 1.0; } } 9
16.5.2 OpenACC Kernels 構文 // ベクトルを1で初期化する double v[N]; for (int
i = 0; i < N; i++) { v[i] = 1.0; } // 結果を格納するベクトルを 0で初期化する double b[N]; for (int i = 0; i < N; i++) { b[i] = 0; } 10
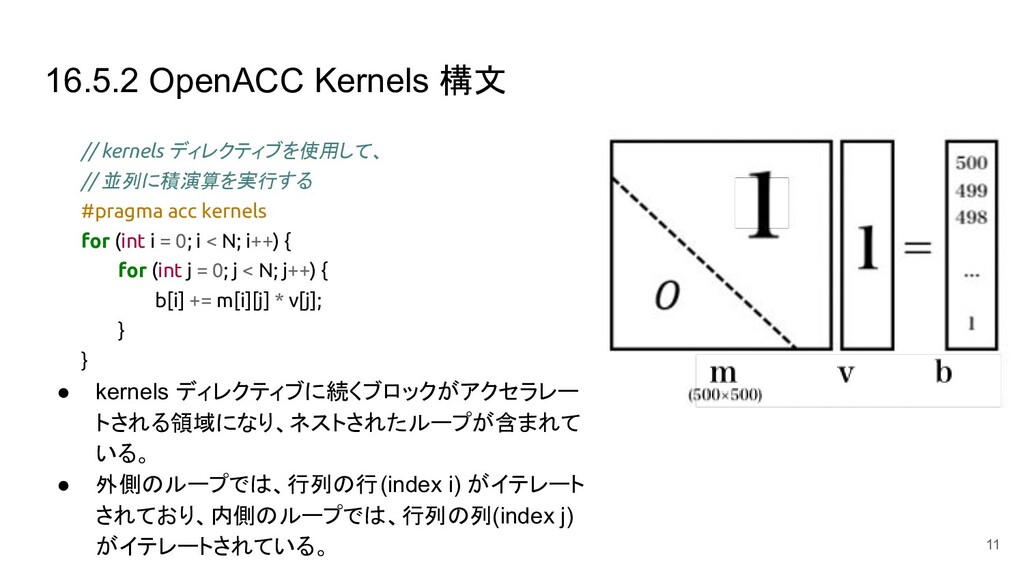
16.5.2 OpenACC Kernels 構文 // kernels ディレクティブを使用して、 // 並列に積演算を実行する #pragma
acc kernels for (int i = 0; i < N; i++) { for (int j = 0; j < N; j++) { b[i] += m[i][j] * v[j]; } } • kernels ディレクティブに続くブロックがアクセラレー トされる領域になり、ネストされたループが含まれて いる。 • 外側のループでは、行列の行 (index i) がイテレート されており、内側のループでは、行列の列 (index j) がイテレートされている。 11
16.5.2 OpenACC Kernels 構文 // 結果を確認 double r = 0;
for (int i = 0; i < N; i++) { r += b[i]; } printf("Result: %f (expected %f)\n", r, (N+1) * N / 2.0); } • Code 16.2 の #pragma acc parallels のコードとは 違い、async clause を書かなくても並列実行領域は 同期的に実行される。 • そのため、ブロックの後にある「結果を確認」のセク ションは、アクセラレートされたカーネルの計算が完 了するまで、実行が待機される。 12
16.5.2 OpenACC Kernels 構文 // 結果を確認 double r = 0;
for (int i = 0; i < N; i++) { r += b[i]; } printf("Result: %f (expected %f)\n", r, (N+1) * N / 2.0); } • 正しい結果は、500 + 499 + ‥‥ + 1 で計算でき る。 13
16.5.2 OpenACC Kernels 構文 // 結果を確認 double r = 0;
for (int i = 0; i < N; i++) { r += b[i]; } printf("Result: %f (expected %f)\n", r, (N+1) * N / 2.0); } // => Result: 125250.000000 (expected 125250.000000) 14
16.5.2 OpenACC Kernels 構文 // 結果を確認 double r = 0;
for (int i = 0; i < N; i++) { r += b[i]; } printf("Result: %f (expected %f)\n", r, (N+1) * N / 2.0); } // => Result: 125250.000000 (expected 125250.000000) (16.5.2 終わり。質問?) 15
目次 • 16.5.2 OpenACC Kernels 構文 ◦ 三角行列とベクトルの積の演算を、OpenACC の kernels
ディレクティブを利用して高速化する。 • 16.5.3 データ管理 (Data Management) ◦ ホストのメモリとアクセラレータのメモリ間のデータ転送の 制御方法について。 16
16.5.3 Data Management (データ管理) • アクセラレートしたプログラムの最終的な速度は、ホストプロセッサとGPU間のデー タ転送効率に強く依存する。 • 例: AMDのaccelerated
processing unitの場合の工夫 ◦ ホストプロセッサとアドレス空間を共有する。 ◦ これにより、ポインタを渡すだけで済むので、データコピーが発生せず、 2コンポーネント間 のデータ構造の通信のオーバーヘッドが不要になる。 ◦ アクセラレータがデータアレイの特定の要素に計算を実行する必要がある場合でも、ポス トプロセッサと同じように、ポインタ値・要素のインデックス・データ型・デリファレンス (メモ リから望む値をフェッチすること) に元に、データの結果アドレスを計算するだけで済む。 17
16.5.3 Data Management (データ管理) • しかし、現在のスーパーコンピュータで使用されている多くのアクセラレータでは、メ モリモジュールが分離されているため、明示的なデータ転送が必要になってしまっ ている。 • こうしたデータ転送は、1)
必要ないデータへのアクセスが行われないように構成さ れているか、2) 必要がなければ転送を完全に回避できるようになっているのが理 想。 ◦ 1) は、配列やベクトル要素の一部分しか計算に必要ない場合や、データオフロードの遅 延を増大してしまう場合がある。 ◦ 2) は、GPUの計算結果として生成されたデータセットがホストに元々ある配列を上書きす るような場合が考えられる。 18
16.5.3 Data Management (データ管理) • 残念ながら、C/C++コードが複雑であるため、コンパイラによるデータアクセスパ ターンの静的解析を行っても、影響を受けるデータ構造のどの部分をアクセラレー タにオフロードすべきかは、必ずしも確実に決定できるわけではない。 • OpenACCのデフォルトの選択は、効率性<正確性であり、完全な双方向コピーを
実行するという戦略。 ◦ つまり、アクセラレータの計算実行前に、初期状態の関係するすべてのデータ構造をデバ イスに転送し、アクセラレート領域の計算実行完了後に、更新された関連するデータセット すべてをコピーバックするという戦略。 19
16.5.3 Data Management (データ管理) • ただし、この戦略は実行時に関連する配列のサイズが分かっている時に限る。 • 配列が動的にアロケートされる場合や、ポインターで渡される場合は、ランタイム時 のout-of-boundsアクセスエラーを防ぐために、明示的にデータ範囲を指定するの がよい考え。
• OpenACCの実装では、アクセラレータがホストのメモリにダイレクトアクセスできる 場合には、データ転送をさらに最適化している場合もある (可能なら、データ転送自 体を無くすような最適化を行うこともある)。 20
16.5.3 Data Management (データ管理) • ただし、この戦略は実行時に関連する配列のサイズが分かっている時に限る。 • 配列が動的にアロケートされる場合や、ポインターで渡される場合は、ランタイム時 のout-of-boundsアクセスエラーを防ぐために、明示的にデータ範囲を指定するの がよい考え。
• OpenACCの実装では、アクセラレータがホストのメモリにダイレクトアクセスできる 場合には、データ転送をさらに最適化している場合もある (可能なら、データ転送自 体を無くすような最適化を行うこともある)。 (約1/4おわり 質問?) 21
16.5.3 Data Management (データ管理) • ホストメモリ↔アクセラレータメモリ間のデータコピーを制御するために、 OpenACCが提供する4つのclauseを紹介する。 1. copy (変数リスト)
2. copyin (変数リスト) 3. copyout (変数リスト) 4. create (変数リスト) 22
16.5.3 Data Management (データ管理) 1. copy (変数リスト) 並列領域から出るタイミング・入るタイミングでデータコピーを実行する。 • まず、ランタイムシステムが、変数リストで指定された各変数ごとに、要求されたデータがアクセ
ラレータのメモリに存在するかどうかをチェックする。 • もし存在すれば、参照カウントを+ 1する。 • 存在しなければ、アクセラレータ上に十分なメモリをアロケートし、ホストメモリからアロケートメ モリへデータをコピー、データ構造の参照カウント =1にセットする。 • そして、並列領域から抜け出すごとに、参照カウントを -1する。 • もし、参照カウントが0になったら、対応するデータをホストメモリへコピーバックし、アクセラレー タ上のメモリセグメントを解放する。 23
16.5.3 Data Management (データ管理) 2. copyin (変数リスト) 並列領域に入るタイミングでデータコピーを実行する。 copy の1方向バージョン。
• 並列領域へ入るタイミングで行われる操作は、 copyと同じように実行される。 • しかし、並列領域から出るタイミングで、変数リストで指定されたすべてのデータ構造の参照カ ウントが-1される。 • もし、特定の変数の参照カウントが 0になったら、アクセラレータ上のメモリセグメントを解放する が、ホストメモリへのデータ転送は行わない。 24
16.5.3 Data Management (データ管理) 3. copyout (変数リスト) 並列領域から出るタイミングでデータコピーを実行する。 copyin の逆バージョン。
• 並列領域から入るタイミングで、データが既にアクセラレータのメモリ上に存在していれば、参 照カウンタを+1する。 • もし存在しなければ、十分なメモリセグメントをデバイス上にアロケートし、参照カウントを 1に セットする。 • アロケートされたメモリは初期化されない (この時点ではデータ転送は行われない ) • 並列領域から出るタイミングで、関連するデータ構造の参照カウントが -1される。 • もし、参照カウント=0ならば、データをホストメモリにコピーバックし、アクセラレータ上の対応す るメモリセグメントを解放する。 25
16.5.3 Data Management (データ管理) 4. create (変数リスト) アクセラレータ上にローカルの計算で使われるデータ構造を作る。 • ホストメモリ↔アクセラレータメモリ間でデータの転送を行わない。
• 影響する並列領域に入ったタイミングでデバイスメモリ上にデータ構造がすでに存在していれ ば、ランタイムは参照カウンタを +1する。 • もし存在しなければ、デバイス上に適切なサイズのメモリをアロケートし、参照カウントを 1にセッ トする。 • 領域から出るタイミングで参照カウンタを -1し、0になったら対応するメモリを開放する。 26
16.5.3 Data Management (データ管理) 変数リストの例: #pragma acc kernels copyin(a[5:10], b[5:t])
copyout(mat[:N][16:32]) • variable[index:size]という形式。 • a[5:10] • aの「index 5から、10 elements」を表す。 • インデックス5〜10という意味ではないので注意。 • b[5:t] • bの「index 5から、t elements」 • mat[:N][16:32] • 2次元配列 mat の「0〜N-1行目×16〜47列目(16+32)」を表す。 • indexを省略すると0、sizeを省略すると配列全体のサイズとなる。 27
16.5.3 Data Management (データ管理) 変数リストの例: #pragma acc kernels copyin(a[5:10], b[5:t])
copyout(mat[:N][16:32]) • variable[index:size]という形式。 • a[5:10] (約2/4おわり 質問?) • aの「index 5から、10 elements」を表す。 • インデックス5〜10という意味ではないので注意。 • b[5:t] • bの「index 5から、t elements」 • mat[:N][16:32] • 2次元配列 mat の「0〜N-1行目×16〜47列目(16+32)」を表す。 • indexを省略すると0、sizeを省略すると配列全体のサイズとなる。 28
16.5.3 Data Management (データ管理) 配列の4つの定義方法 • コンパイラのサポートのおかげで、OpenACCはC/C++のプログラム上で配列を定 義する複数の方法をサポートしている。ここでは、4つの定義方法を紹介する。 1. int
cnt[4][500]; 2. typedef double vec[1000]; vec *v1; 3. float *farray[500]; 4. double **dmat; 29
16.5.3 Data Management (データ管理) 1. 固定サイズの静的なアロケート int cnt[4][500]; • 静的なアロケートをされた配列に対するデータ転送範囲の指定に関しては、重要な
制限が1つある。 • 最初の次元の範囲指定を要素のサブセットするにすることは許されるが、残りの次 元は範囲全体を指定しなければならないという制限。 • OK: #pragma acc kernels copy(cnt[2:2][:500]) • NG: #pragma acc kernels copy(cnt[:4][0:100]) 30
16.5.3 Data Management (データ管理) 2. 固定長の配列へのポインタ typedef double vec[1000]; vec
*v1; 3. 静的にアロケートされたポインターの配列 float *farray[500]; 4. ポインターの配列へのポインタ double **dmat; 31
16.5.3 Data Management (データ管理) 配列の定義に関する注意点 • 多次元配列の定義には、静的な範囲指定とポインタ宣言を混在させることができ る。 • 一般の場合に範囲指定の制約を正しく守るために意識しておくと役に立つのは、ラ
ンタイムシステムは、アクセラレータ上でホストから来るデータ構造の構成を反映さ せて、データ構造の値を格納するのに必要なポインタをアロケートするということ。 • データ構造が定義された後には、ホストまたはデバイス上に埋め込まれたポインタ は変更しない方がよい。 32
16.5.3 Data Management (データ管理) 配列の定義に関する注意点 • 多次元配列の定義には、静的な範囲指定とポインタ宣言を混在させることができ る。 • 一般の場合に範囲指定の制約を正しく守るために意識しておくと役に立つのは、ラ
ンタイムシステムは、アクセラレータ上でホストから来るデータ構造の構成を反映さ せて、データ構造の値を格納するのに必要なポインタをアロケートするということ。 • データ構造が定義された後には、ホストまたはデバイス上に埋め込まれたポインタ は変更しない方がよい。 (約3/4おわり。質問?) 33
16.5.3 Data Management (データ管理) • 前のコードに改善したデータ管理手法を適用したバージョンを以下で説明する。 (Code 16.4) 34
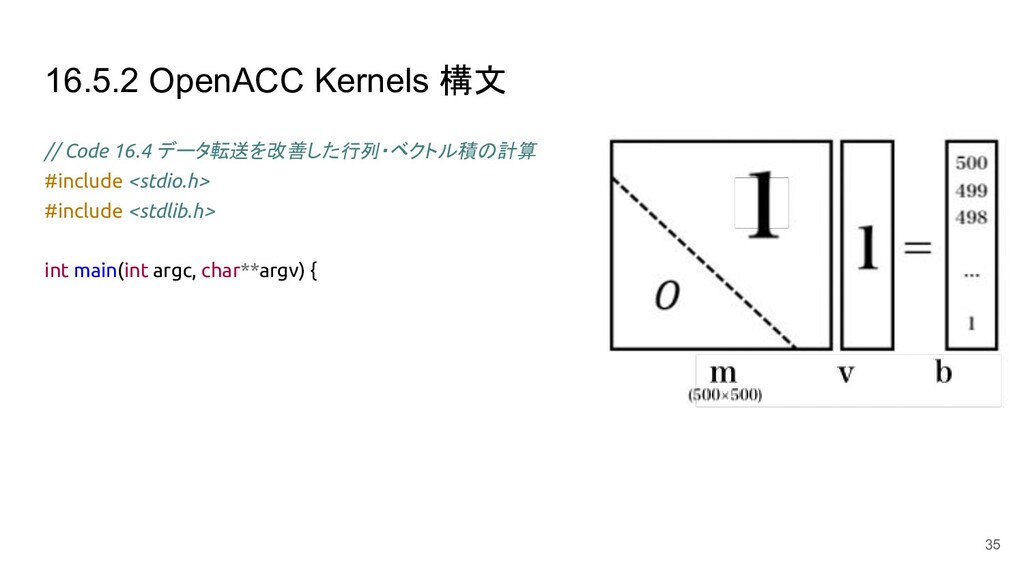
16.5.2 OpenACC Kernels 構文 // Code 16.4 データ転送を改善した行列・ベクトル積の計算 #include <stdio.h>
#include <stdlib.h> int main(int argc, char**argv) { 35
16.5.2 OpenACC Kernels 構文 // コマンドライン引数からサイズ N を入力 unsigned N
= 1024; if (argc > 1) N = strtoul(argv[1], 0, 10); • 配列のサイズをコマンドラインから指定できるようにしてい る • 今回の実行例ではN=2000とする • cf. strtoul() - man page - https://man.cx/strtoul 36
16.5.2 OpenACC Kernels 構文 // 上三角行列を初期化する double **restrict m =
malloc(N * sizeof(double *)); for (int i = 0; i < N; i++) { m[i] = malloc(N * sizeof(double)); for (int j = 0; j < N; j++) m[i][j]=(i>j) ? 0 : 1.0; } • 1次元配列ではなく2つのインデックス表記でアクセスできる ように、行列 m をポインターの配列へのポインターとして定 義している。 37
16.5.2 OpenACC Kernels 構文 // 入力ベクトルを1で初期化する double *restrict v =
malloc(N * sizeof(double)); for (int i = 0; i < N; i++) v[i] = 1.0; // 結果を格納するベクトルを作成 (初期化はしていない ) double *restrict b = malloc(N * sizeof(double)); • ポインタに restrict 属性を宣言することで、 pointer aliasing が存在しないことをコンパイラに伝え、より最適化 されたコードの生成を促している。 ◦ cf. restrict - Wikipedia - https://en.wikipedia.org/wiki/Restrict 38
16.5.2 OpenACC Kernels 構文 // kernels ディレクティブ + copyin +
copyout で積演算 #pragma acc kernels copyin(m[:N][:N], v[:N]) copyout(b[:N]) for (int i = 0; i < N; i++) { b[i]=0; for (int j = 0; j < N; j++) b[i] += m[i][j] * v[j]; } • 行列 m と ベクトル v は計算で参照するだけなので、 copyin の変数リストに指定している。 • ベクトル b は後で計算結果で上書きされるため、ホストメモ リー上で初期化する必要はない。そのため、 copyout の変 数として宣言している。 • アクセラレータは内積の部分計算を累積する際に簡単に 0 で初期化できるため、この処理を明示的にアクセラレートす る領域に移動している。 39
16.5.2 OpenACC Kernels 構文 // 結果を確認 double r = 0;
for (int i = 0; i < N; i++) { r += b[i]; } printf("Result: %f (expected %f)\n", r, (N + 1) * N / 2.0); return 0; } 40 (今回はN=2000)
16.5.2 OpenACC Kernels 構文 // 結果を確認 double r = 0;
for (int i = 0; i < N; i++) { r += b[i]; } printf("Result: %f (expected %f)\n", r, (N + 1) * N / 2.0); // => Result: 2001000.000000 (expected 2001000.000000) return 0; } 41 (今回はN=2000)
16.5.2 OpenACC Kernels 構文 // 結果を確認 double r = 0;
for (int i = 0; i < N; i++) { r += b[i]; } printf("Result: %f (expected %f)\n", r, (N + 1) * N / 2.0); // => Result: 2001000.000000 (expected 2001000.000000) return 0; } (約4/4おわり。質問?) 42 (今回はN=2000)
目次 • 16.5.2 OpenACC Kernels 構文 ◦ 三角行列とベクトルの積の演算を、OpenACC の kernels
ディレクティブを利用して高速化する。 • 16.5.3 データ管理 (Data Management) ◦ ホストのメモリとアクセラレータのメモリ間のデータ転送の 制御方法について。 43
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![16.5.2 OpenACC Kernels 構文 kernels ディレクティブの構文 #pragma acc kernels [clause...]](https://files.speakerdeck.com/presentations/cf23946a388a48af89fb1b8ad80ee561/slide_6.jpg){kind=link}
{kind=link}
![16.5.2 OpenACC Kernels 構文 // 上三角行列を初期化する double m[N][N]; for (int](https://files.speakerdeck.com/presentations/cf23946a388a48af89fb1b8ad80ee561/slide_8.jpg){kind=link}
![16.5.2 OpenACC Kernels 構文 // ベクトルを1で初期化する double v[N]; for (int](https://files.speakerdeck.com/presentations/cf23946a388a48af89fb1b8ad80ee561/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![16.5.3 Data Management (データ管理) 変数リストの例: #pragma acc kernels copyin(a[5:10], b[5:t])](https://files.speakerdeck.com/presentations/cf23946a388a48af89fb1b8ad80ee561/slide_26.jpg){kind=link}
![16.5.3 Data Management (データ管理) 変数リストの例: #pragma acc kernels copyin(a[5:10], b[5:t])](https://files.speakerdeck.com/presentations/cf23946a388a48af89fb1b8ad80ee561/slide_27.jpg){kind=link}
{kind=link}
![16.5.3 Data Management (データ管理) 1. 固定サイズの静的なアロケート int cnt[4][500]; • 静的なアロケートをされた配列に対するデータ転送範囲の指定に関しては、重要な](https://files.speakerdeck.com/presentations/cf23946a388a48af89fb1b8ad80ee561/slide_29.jpg){kind=link}
![16.5.3 Data Management (データ管理) 2. 固定長の配列へのポインタ typedef double vec[1000]; vec](https://files.speakerdeck.com/presentations/cf23946a388a48af89fb1b8ad80ee561/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}