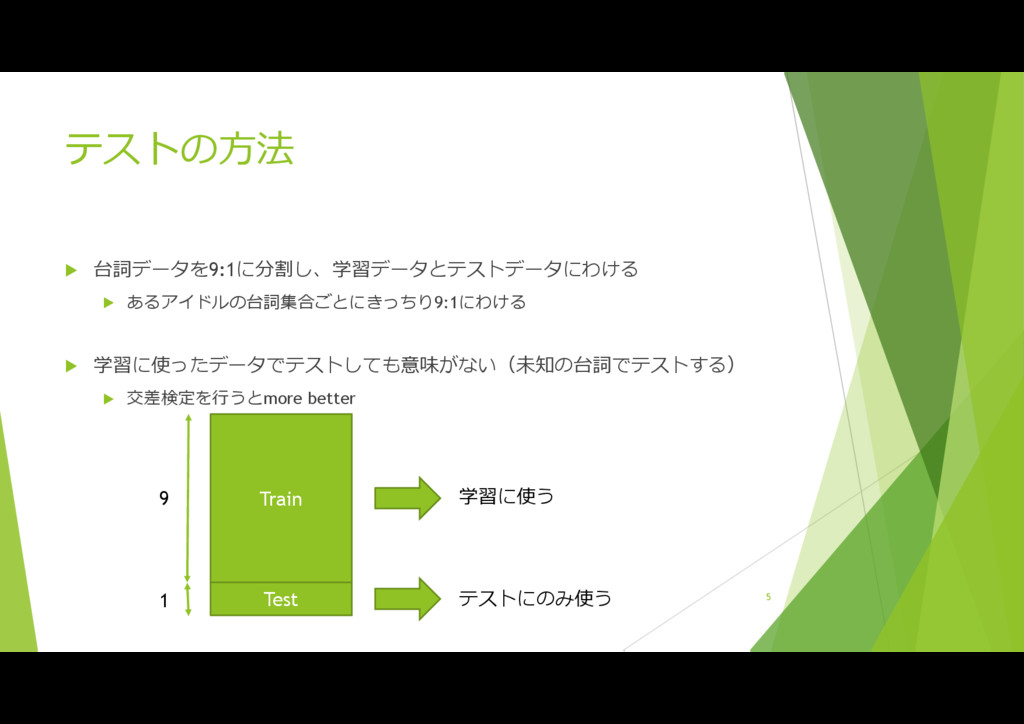
fastText(Facebook) 特徴量としてなにを使うか 文字n-gram たとえば「こんにちは」の2-gramなら、「こん んに にち ちは」の5つに分割 形態素n-gram 「こんにちは」は一つの形態素「こんにちは」になる(と思う) 「こんにちは、プロデューサーさん!」なら以下のように5つに分割 こんにちは 感動詞,*,*,*,*,*,こんにちは,コンニチハ,コンニチワ 、 記号,読点,*,*,*,*,、,、,、 プロデューサー 名詞,一般,*,*,*,*,プロデューサー,プロデューサー,プロデューサー さん 名詞,接尾,人名,*,*,*,さん,サン,サン ! 名詞,サ変接続,*,*,*,*,* 4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Webインターフェース版の実行例 台詞を入力すると、スコア上位のアイドルから順に表示する 判定した台詞はデレステのSSR[夢みるプリンセス]喜多日菜子のもの 今回の学習データには含まれていないが、ちゃんと判定に成功している 9](https://files.speakerdeck.com/presentations/2663bc51b74a451fb82b3ed394910ab0/slide_8.jpg){kind=link}
{kind=link}