of words and phrases and their compositionality” 単語を100~300次元程度の密なベクトルで表現する 大量の文章からアルゴリズムで人手を介さずに抽出する 類似した単語の一覧が類似度とともに取得できる 「お仕事」 「仕事」 0.679117977619 「予定」 0.663984596729 「レッスン」 0.637667179108 ベクトルの加減算ができる 「king – man + women = queen」 「tokyo – japan + france = paris」 4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
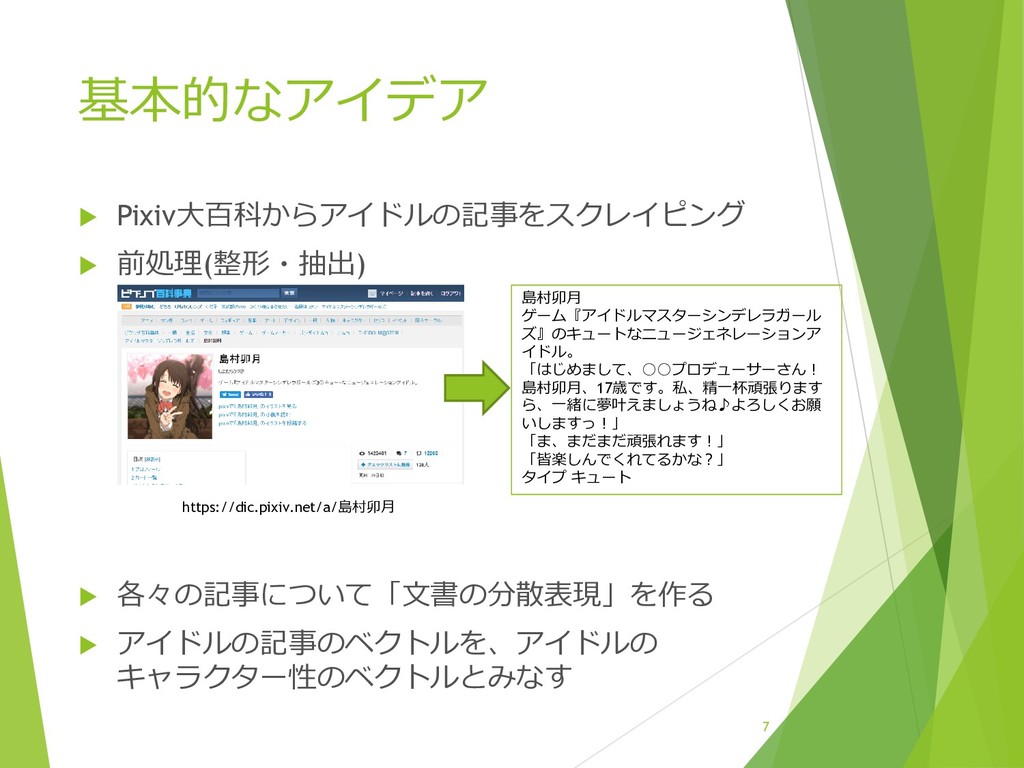{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
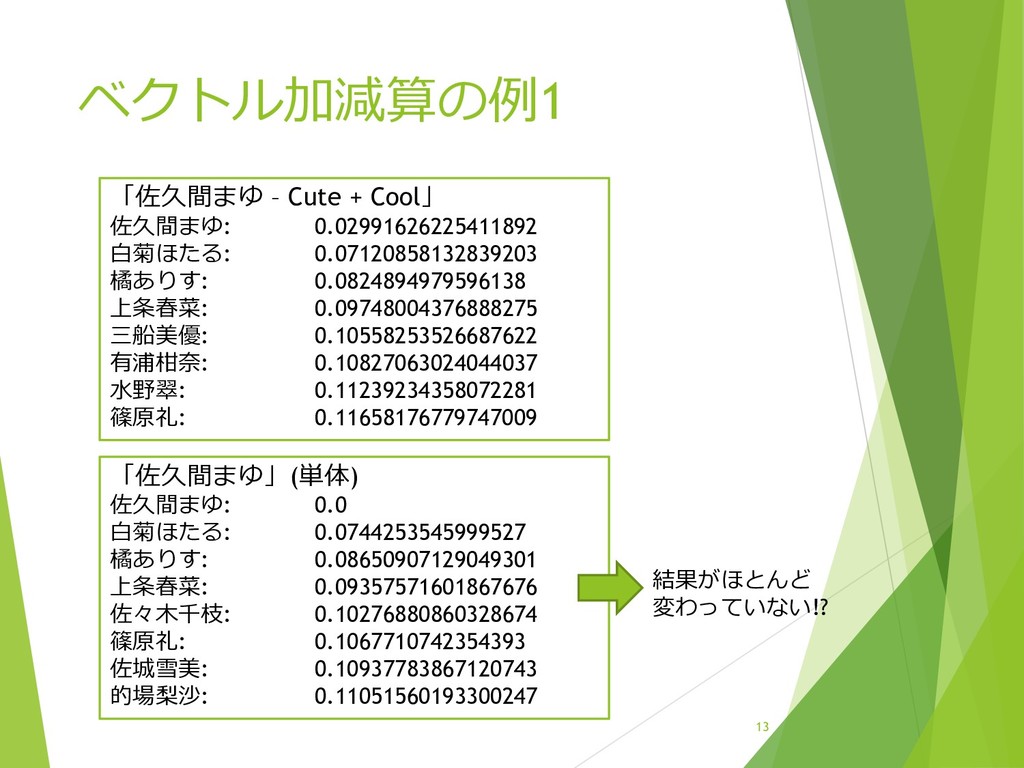{kind=link}
{kind=link}
{kind=link}
{kind=link}
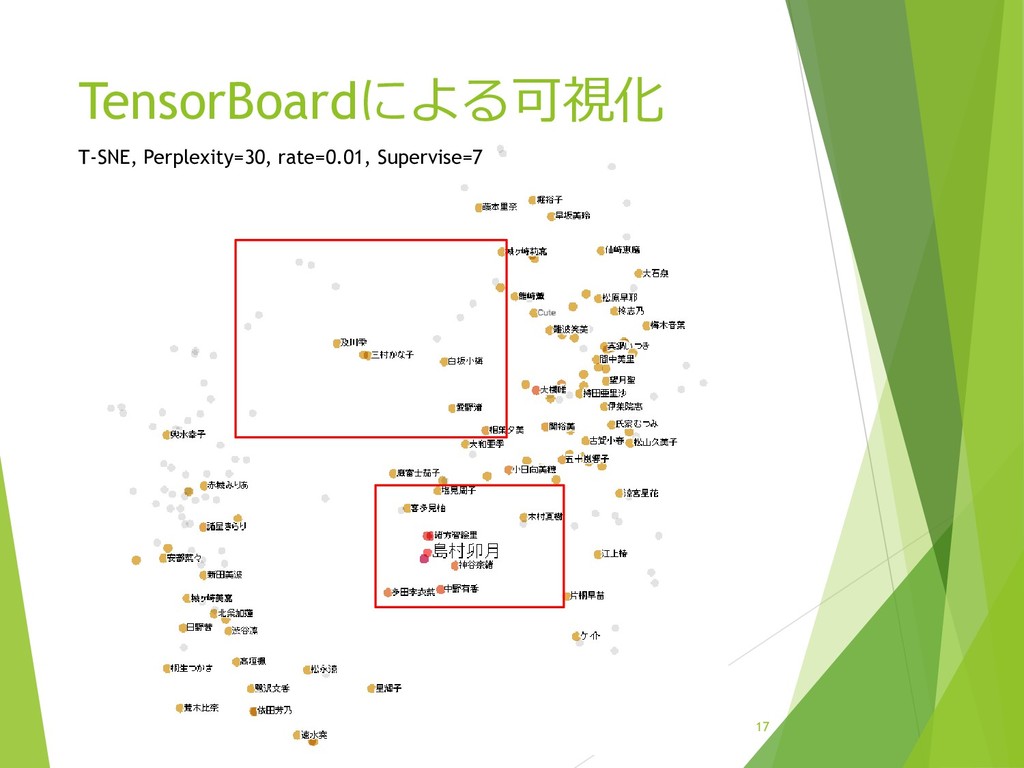{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}