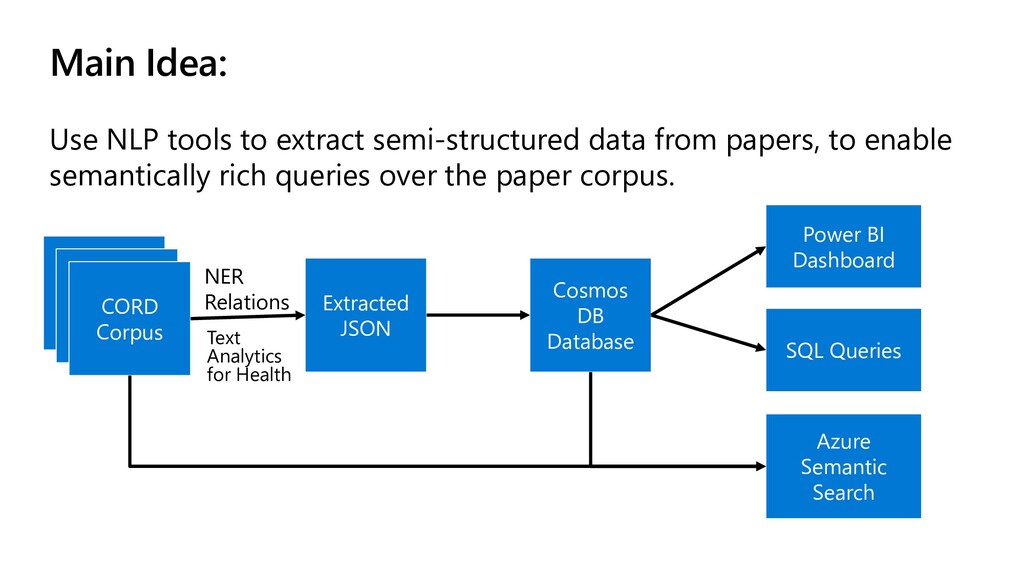
In this presentation, I show how different Azure resources can be used to extract insights from dataset of COVID scientific papers. The process includes the following:
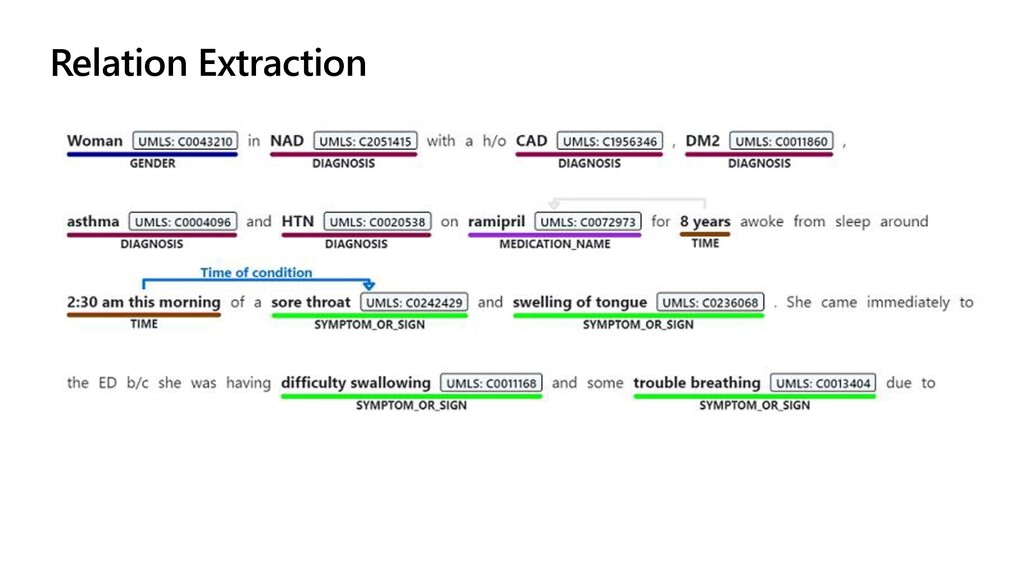
- Extracting entities using Text Analytics for Health on Azure Batch
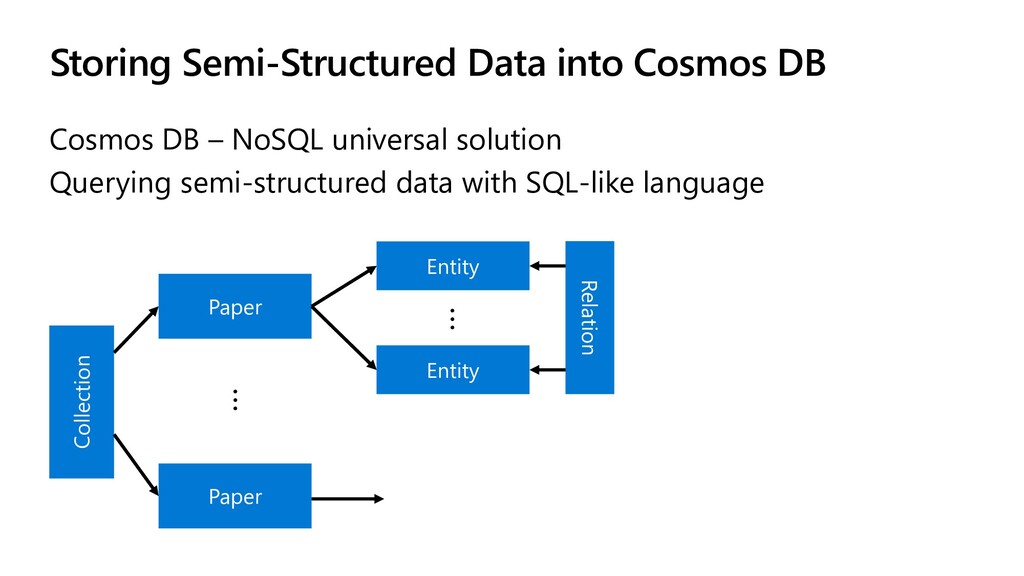
- Storing semi-structured data in Cosmos DB and doing SQL Queries
- Using SQL Queries in Cosmos DB Notebooks to gain further insights into data
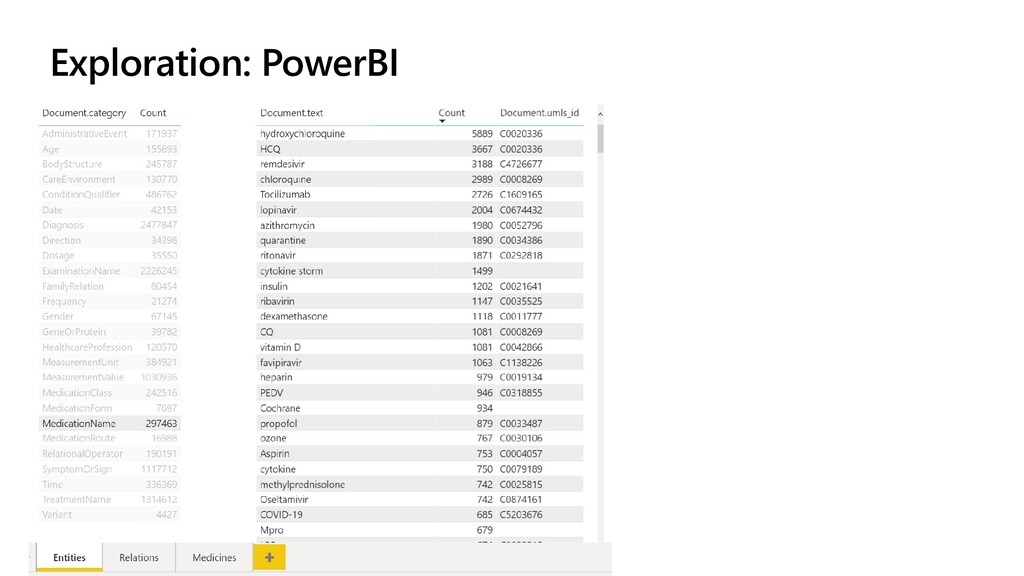
- Adding Power BI dashboard for no-code exploration of data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}