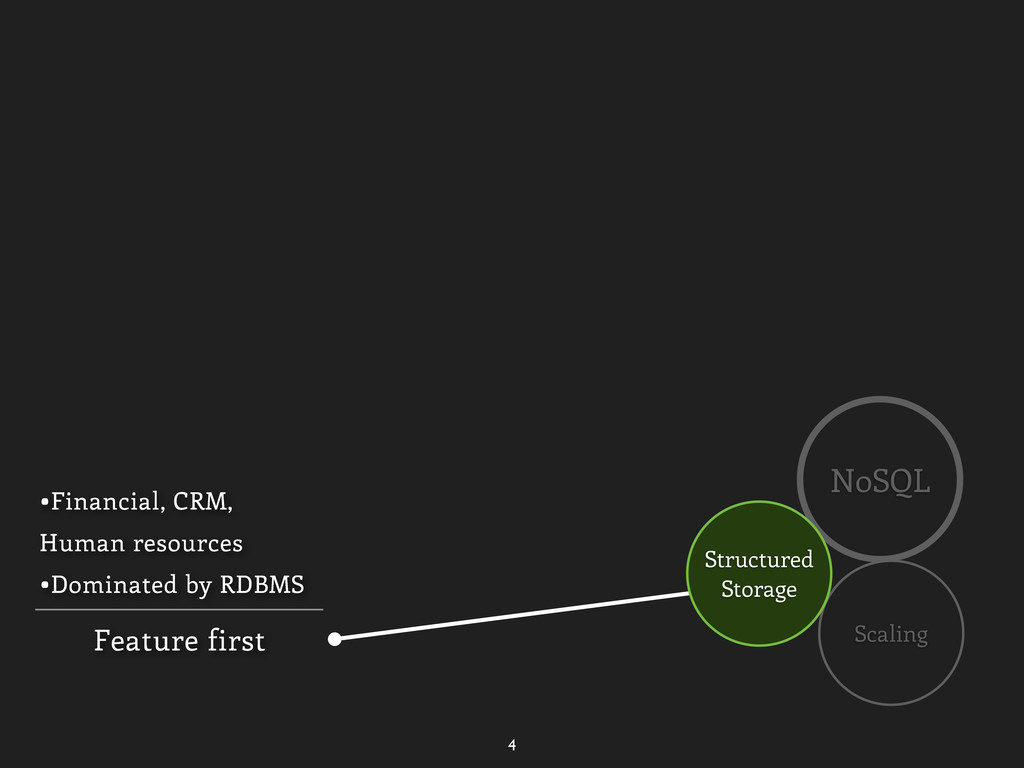
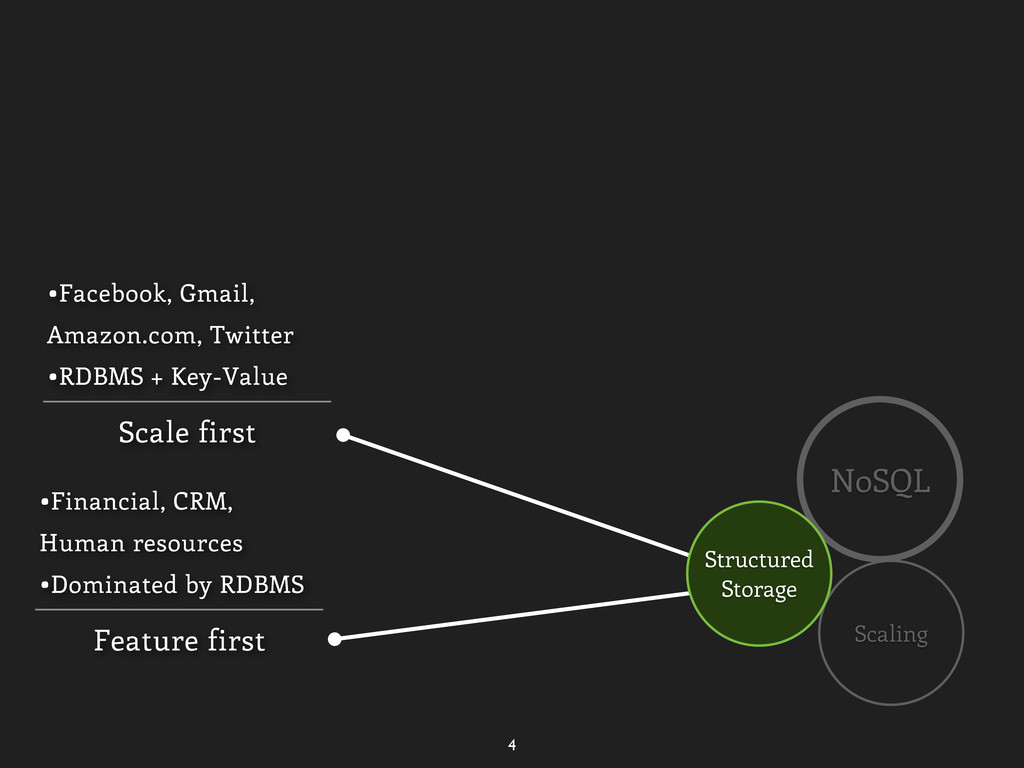
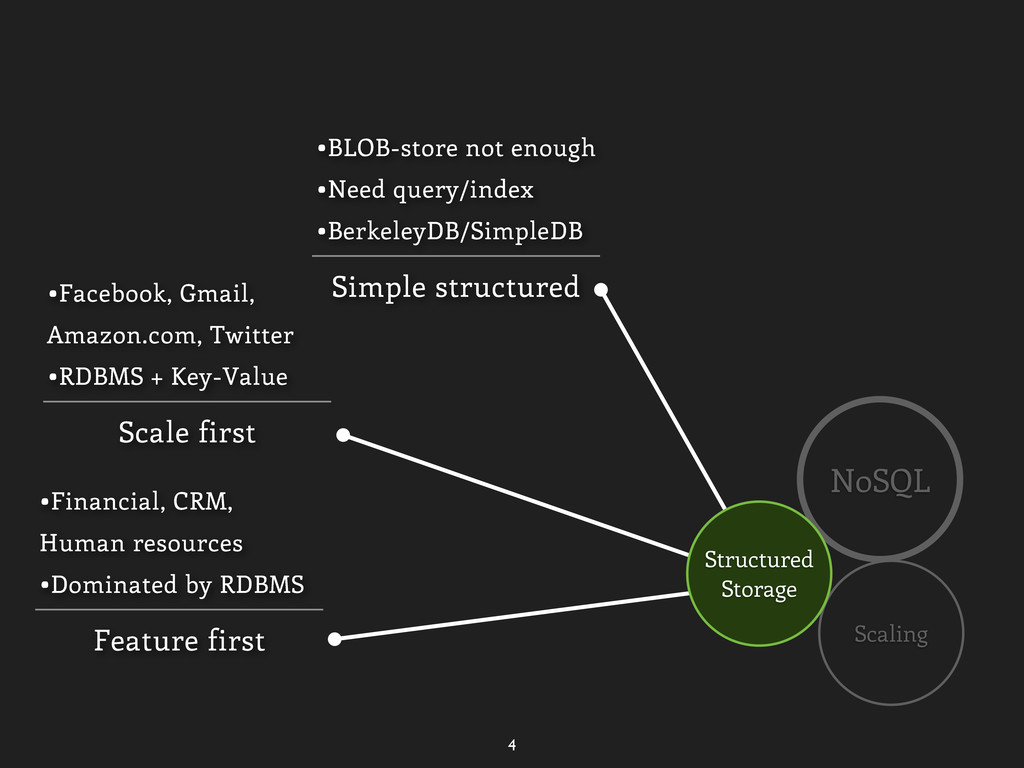
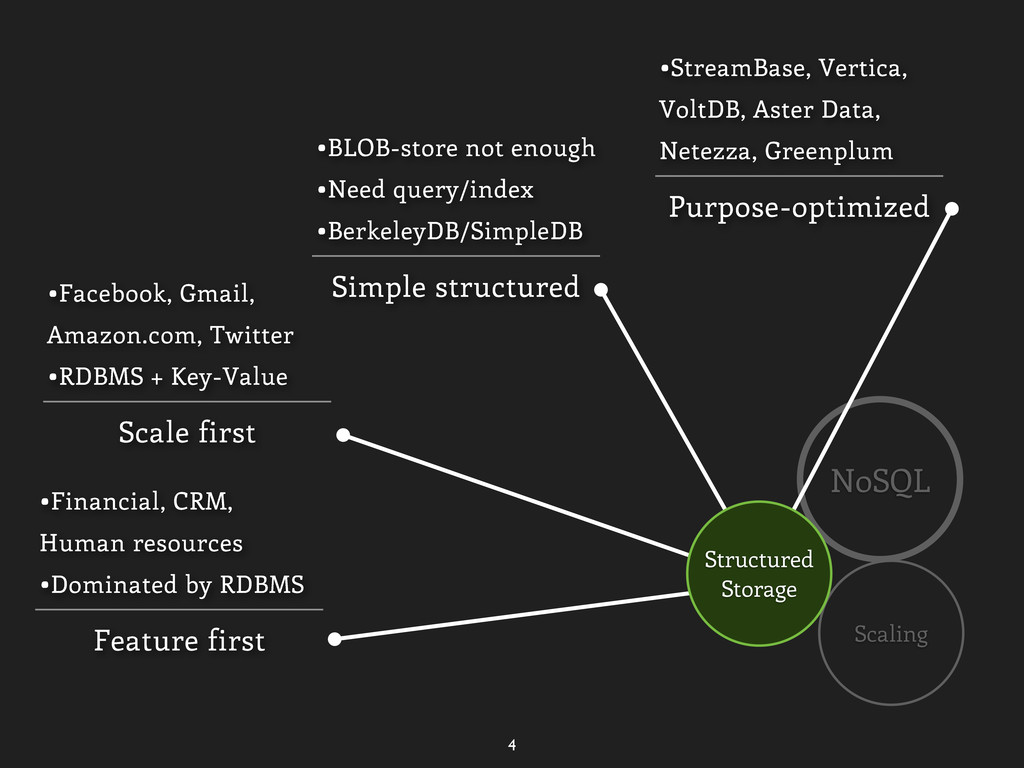
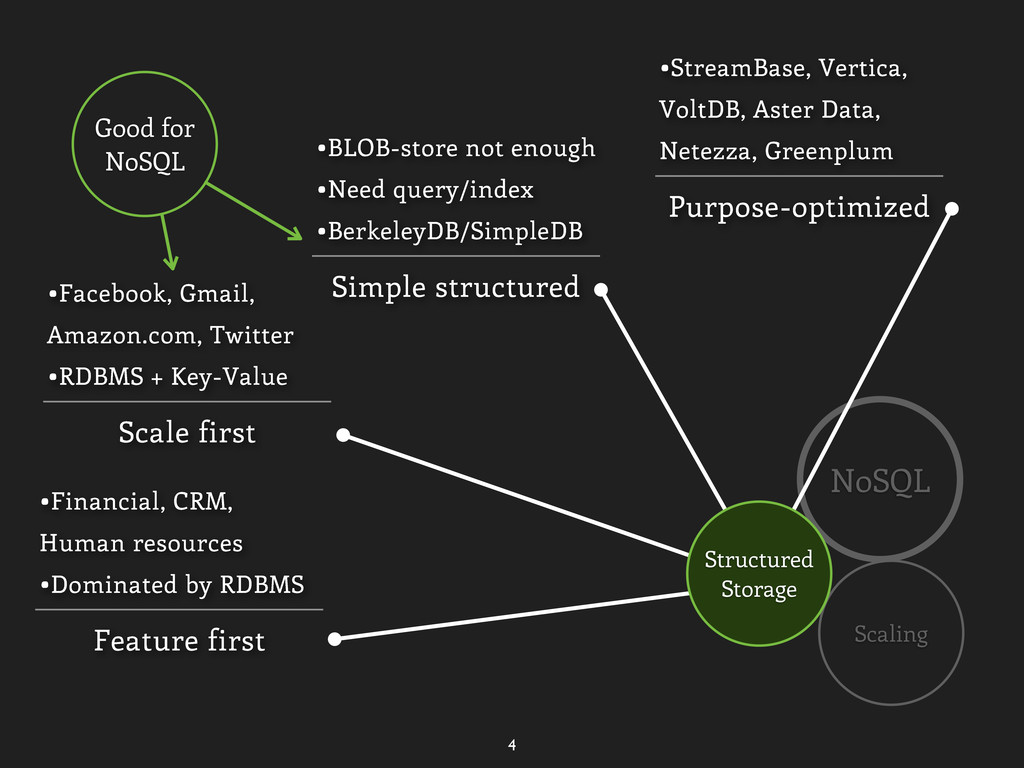
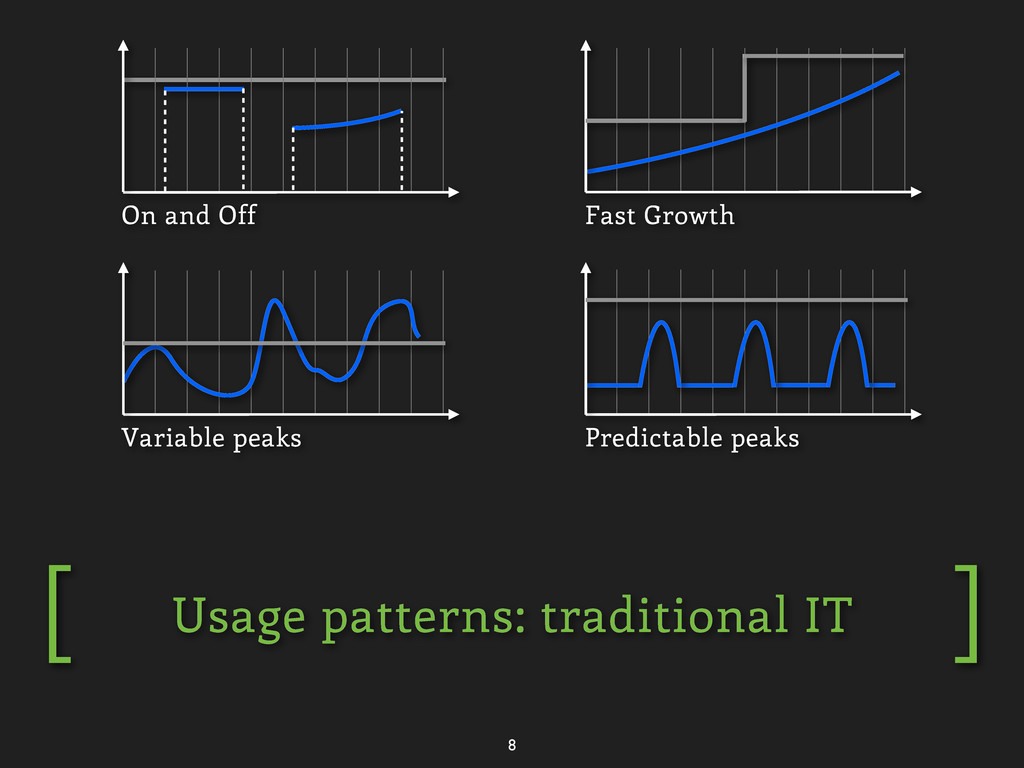
Greenplum Simple structured •BLOB-store not enough •Need query/index •BerkeleyDB/SimpleDB Scale first •Facebook, Gmail, Amazon.com, Twitter •RDBMS + Key-Value Feature first •Financial, CRM, Human resources •Dominated by RDBMS Structured Storage Good for NoSQL
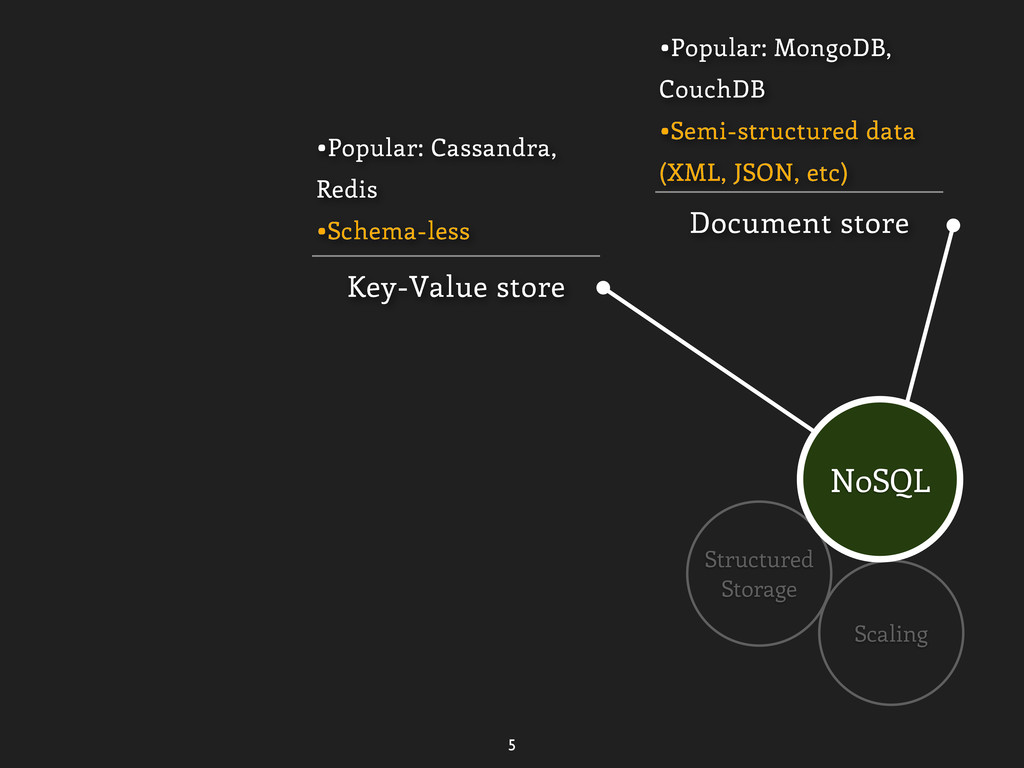
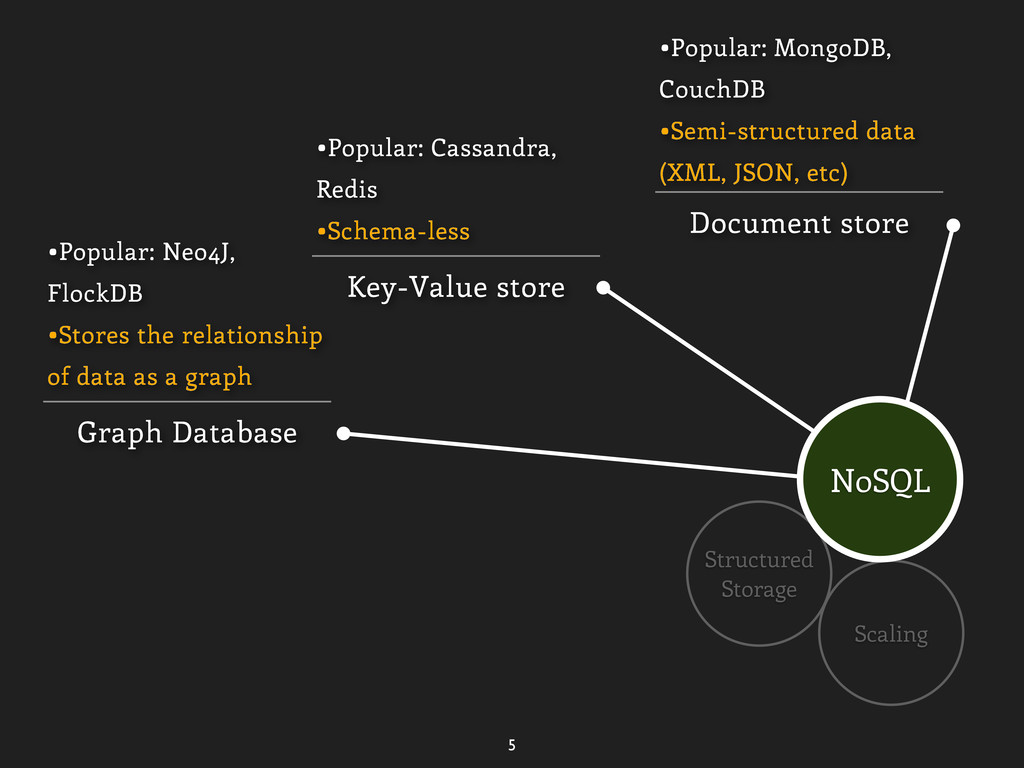
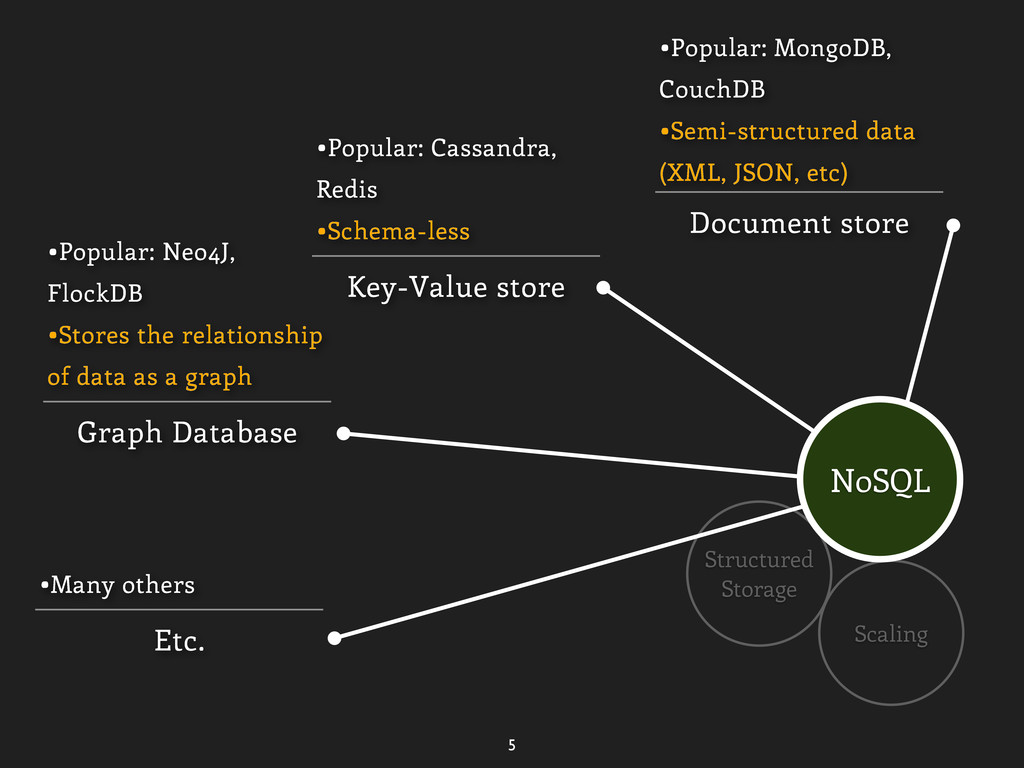
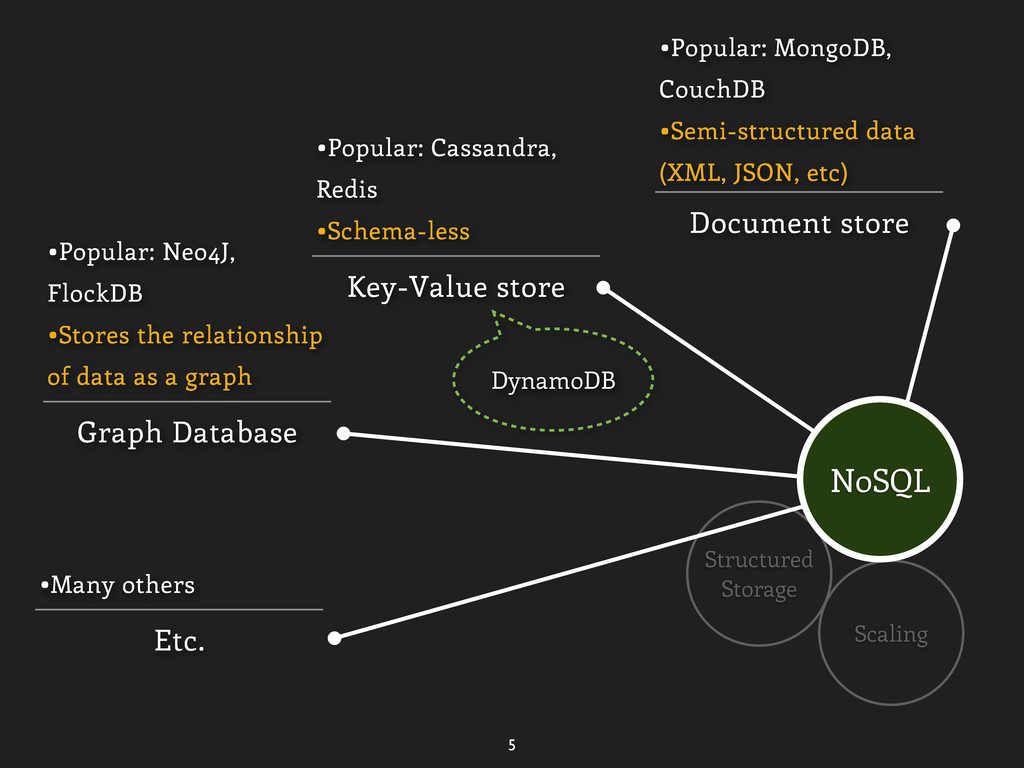
data (XML, JSON, etc) Key-Value store •Popular: Cassandra, Redis •Schema-less Graph Database •Popular: Neo4J, FlockDB •Stores the relationship of data as a graph NoSQL
data (XML, JSON, etc) Key-Value store •Popular: Cassandra, Redis •Schema-less Graph Database •Popular: Neo4J, FlockDB •Stores the relationship of data as a graph Etc. •Many others NoSQL
data (XML, JSON, etc) Key-Value store •Popular: Cassandra, Redis •Schema-less Graph Database •Popular: Neo4J, FlockDB •Stores the relationship of data as a graph Etc. •Many others NoSQL DynamoDB
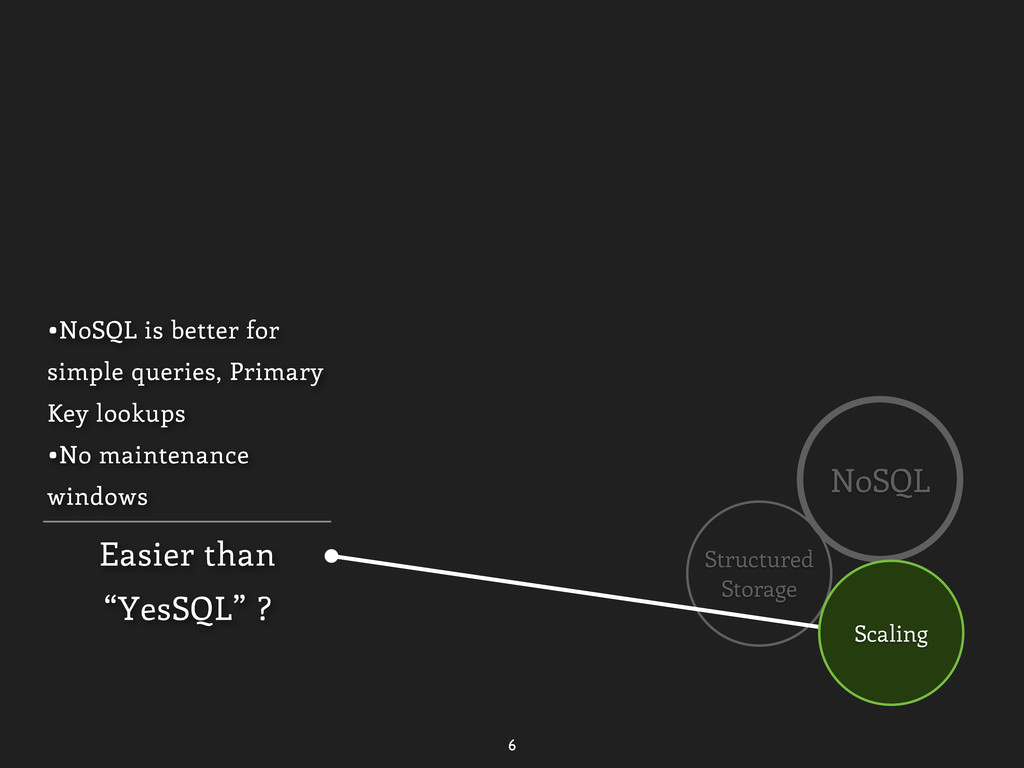
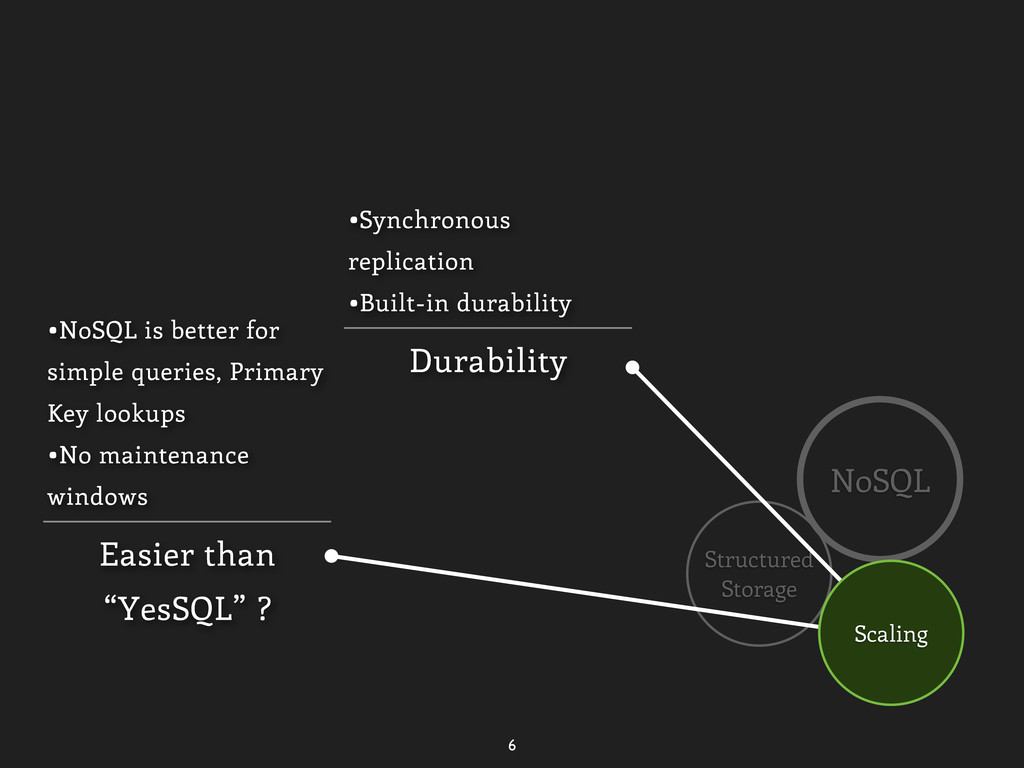
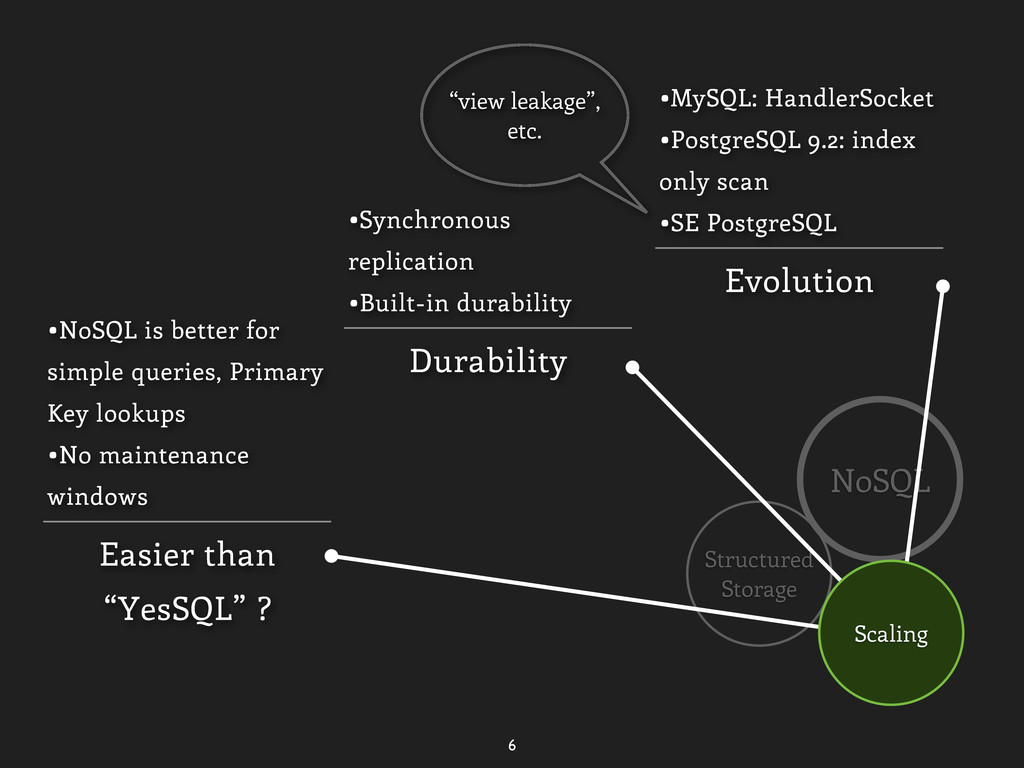
only scan •SE PostgreSQL Durability •Synchronous replication •Built-in durability Easier than “YesSQL” ? •NoSQL is better for simple queries, Primary Key lookups •No maintenance windows Scaling “view leakage”, etc.
Hash The key is hashed over the different partitions to optimize workload distribution Hash + Range When querying, the hash attribute needs to be uniquely matched, but a range operation can be specified for the range attribute. (e.g. all orders in the last 60 minutes)
on primary key (hash or composite) • Supports a subset of comparison operators on key attribute values. • Returns 1 MB per Query operation. • More efficient than Scan. http://docs.amazonwebservices.com/amazondynamodb/latest/developerguide/QueryAndScan.html
entire table • Supports a specific set of comparison operators (e.g. <=, >, ==). • Returns 1 MB / Scan. • Slower for bigger tables. Query • Search only on primary key (hash or composite) • Supports a subset of comparison operators on key attribute values. • Returns 1 MB per Query operation. • More efficient than Scan. http://docs.amazonwebservices.com/amazondynamodb/latest/developerguide/QueryAndScan.html
deliberate decision, to ensure that this API's performance will always remain predictable, no matter the scale of the table (size or throughput). ... Stefano @ AWS (on discussion forums) Query vs. Scan? ] [
deliberate decision, to ensure that this API's performance will always remain predictable, no matter the scale of the table (size or throughput). This limitation forces the developer to perform more work upfront, but it will yield a scalable workload no matter how much it grows. ... Stefano @ AWS (on discussion forums) Query vs. Scan? ] [
deliberate decision, to ensure that this API's performance will always remain predictable, no matter the scale of the table (size or throughput). This limitation forces the developer to perform more work upfront, but it will yield a scalable workload no matter how much it grows. An operation like CONTAINS could seem appealing on paper, but its performance would start slowing progressively as the dataset size grows, eventually requiring a painful rearchitecture down the road. Stefano @ AWS (on discussion forums) Query vs. Scan? ] [
the “Lost update”: Optimistic Concurrency Control (A.K.A. Conditional Writes) Put/Update/Delete are always ACID; “Isolation” only at Item level Atomicity Consistency Isolation Durability { (only at Item)
capacity” units (2x) •Consistency reached within 1,000 ms after last write Eventually Consistent Read •Can read immediately after a write (2 copies) •Read old or new value
capacity” units (2x) •Consistency reached within 1,000 ms after last write Eventually Consistent Read •Can read immediately after a write (2 copies) •Read old or new value (2 copies)
capacity” units (2x) •Consistency reached within 1,000 ms after last write Eventually Consistent Read •Can read immediately after a write (2 copies) •Read old or new value (2 copies) Let me explain...
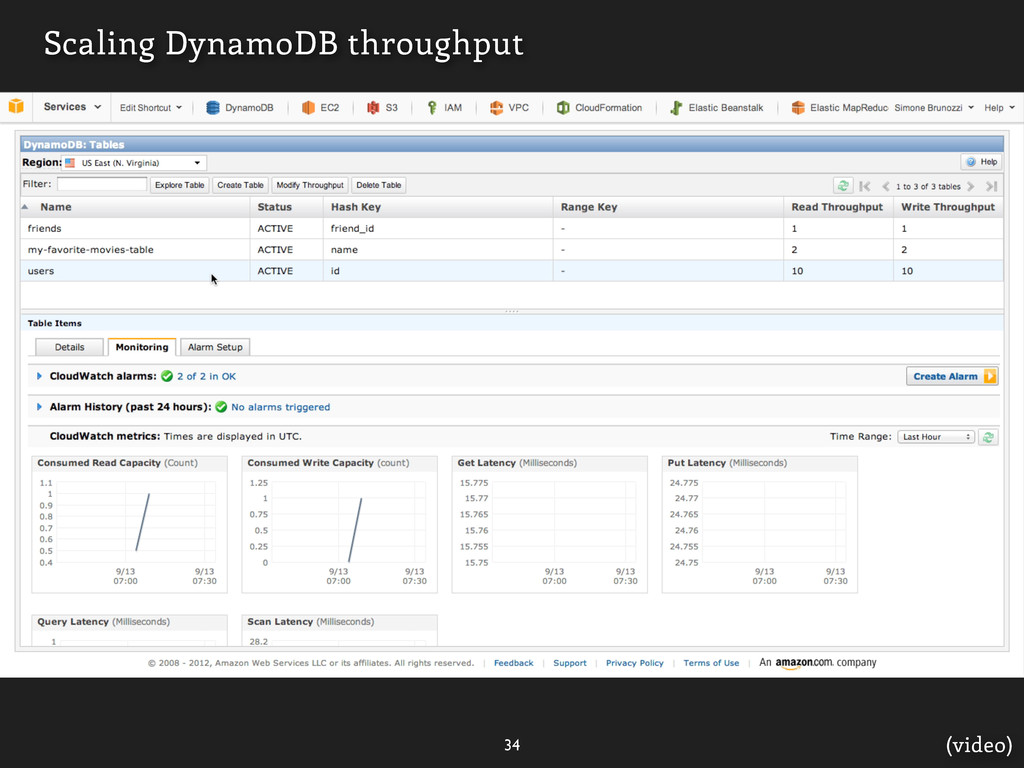
DynamoDB with CloudWatch ] [ Successful Request Latency Consumed Read Capacity Units Throttled Requests User Errors Returned Item Count System Errors Consumed Write Capacity Units
per 50 “strong” reads/second 1.00 $/month per GB Unlike Scan, Query only operates on matching records, not all records. You only pay for the throughput of the items that match, not for everything scanned.
per 50 “strong” reads/second 1.00 $/month per GB For large BLOBs or infrequently accessed data, use Amazon S3 (DynamoDB item limit: 64 KB) You can store smaller data elements or file pointers in DynamoDB
fails? On most NoSQL systems you would lose your most recent changes, or the data might be saved but could be offline and unavailable. ... James Hamilton, VP and Distinguished Engineer, Amazon Web Services
fails? On most NoSQL systems you would lose your most recent changes, or the data might be saved but could be offline and unavailable. With dynamoDB, if data is committed just as one entire datacenter burns to the ground, the data is safe, and the application can continue to run without negative impact at exactly the same provisioned throughput rate. The loss of an entire datacenter isn’t even inconvenient, and has no impact on your running application performance. ... James Hamilton, VP and Distinguished Engineer, Amazon Web Services
fails? On most NoSQL systems you would lose your most recent changes, or the data might be saved but could be offline and unavailable. With dynamoDB, if data is committed just as one entire datacenter burns to the ground, the data is safe, and the application can continue to run without negative impact at exactly the same provisioned throughput rate. The loss of an entire datacenter isn’t even inconvenient, and has no impact on your running application performance. Combining rock solid synchronous, multi-datacenter redundancy with average latency in the single digits, and throughput scaling to the millions of requests per second is both an excellent engineering challenge and one often not achieved. James Hamilton, VP and Distinguished Engineer, Amazon Web Services
updates • Atomic counters • Structured data and multi-valued data types • Fetching and updating single attributes • Strong consistency • No table size limits • Live repartitioning • Disk-only writes • IOPS per table No explicit way to handle conflicts other than conditions
{kind=link}
{kind=link}
![Who invented “NoSQL” ? ] [ 3](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_2.jpg){kind=link}
![Who invented “NoSQL” ? ] [ 3 “NoSQL” conceived in](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
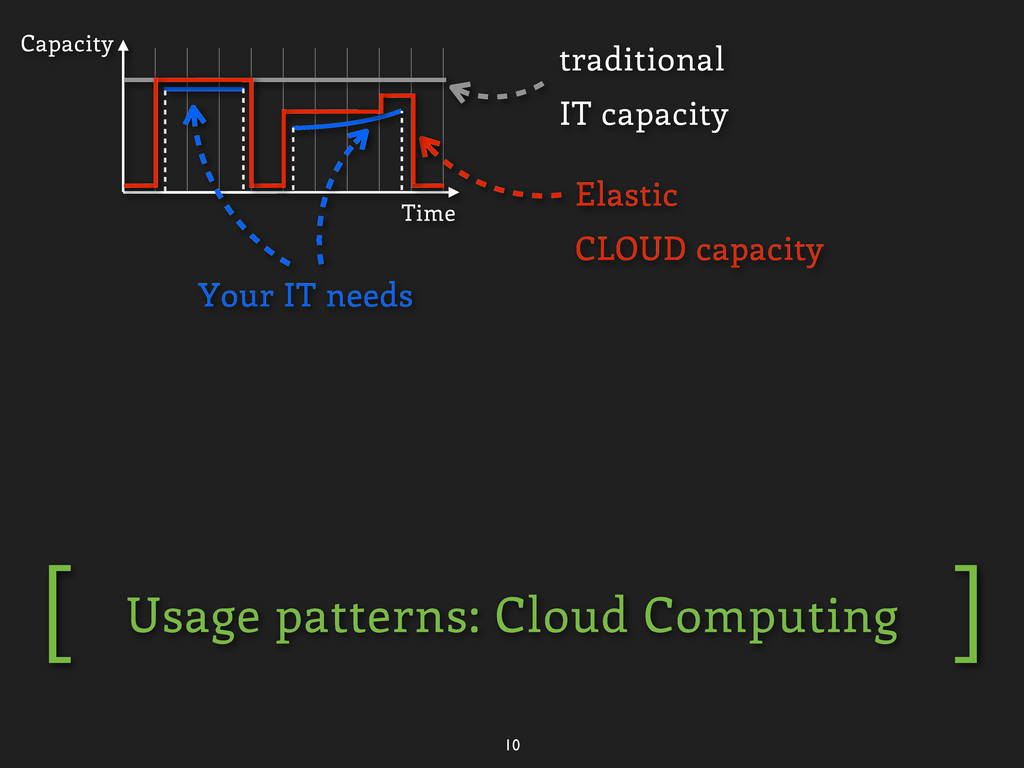
![Why scalability is important ] [ 7 traditional IT capacity](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_20.jpg){kind=link}
![8 Usage patterns: traditional IT ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_21.jpg){kind=link}
{kind=link}
![9 Usage patterns: traditional IT ] [ Variable peaks Fast](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_23.jpg){kind=link}
![9 Poor Service WASTE Usage patterns: traditional IT ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_24.jpg){kind=link}
{kind=link}
![11 Usage patterns: Cloud Computing ] [ Variable peaks Fast](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_26.jpg){kind=link}
![11 Usage patterns: Cloud Computing ] [ Variable peaks Fast](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_27.jpg){kind=link}
{kind=link}
![13 DynamoDB: Speeeed ] [ (image)](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_29.jpg){kind=link}
![13 DynamoDB: Speeeed ] [ Scale to 100,000+ Writes/second (image)](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_30.jpg){kind=link}
{kind=link}
![DynamoDB ] [ 15 DynamoDB](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_32.jpg){kind=link}
![DynamoDB ] [ 15 NoSQL • No schema (only Key)](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_33.jpg){kind=link}
![DynamoDB ] [ 15 NoSQL • No schema (only Key)](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_34.jpg){kind=link}
![DynamoDB ] [ 15 NoSQL • No schema (only Key)](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_35.jpg){kind=link}
{kind=link}
![Creating a table with the Java low-level API ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_37.jpg){kind=link}
![Creating a table with the Java low-level API ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_38.jpg){kind=link}
![Creating a table with BOTO library (Python) ] [ 18](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_39.jpg){kind=link}
![Creating a table with BOTO library (Python) ] [ 18](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_40.jpg){kind=link}
![Deleting a table? Careful... ] [ 19 >>> conn.delete_table(table)](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_41.jpg){kind=link}
![Deleting a table? Careful... ] [ 19 >>> conn.delete_table(table) Permanently](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_42.jpg){kind=link}
![Managing DynamoDB permissions with IAM ] [ 20 { "Statement":](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_43.jpg){kind=link}
![Managing DynamoDB permissions with IAM ] [ 20 { "Statement":](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_44.jpg){kind=link}
![Managing DynamoDB permissions with IAM ] [ 21 { "Statement":](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_45.jpg){kind=link}
![Managing DynamoDB permissions with IAM ] [ 21 { "Statement":](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
![DynamoDB Data Model ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_49.jpg){kind=link}
![DynamoDB Data Model ] [ Table(s) Item(s) Attribute(s)](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_50.jpg){kind=link}
![Example: Table, Items, Attributes ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_51.jpg){kind=link}
![Products Example: Table, Items, Attributes ] [ Table You must](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_52.jpg){kind=link}
![Products Example: Table, Items, Attributes ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_53.jpg){kind=link}
![Products Example: Table, Items, Attributes ] [ Item Item Item](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_54.jpg){kind=link}
![Products Example: Table, Items, Attributes ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_55.jpg){kind=link}
![Products Example: Table, Items, Attributes ] [ id=”301” id=”201” Author=”Simone”,](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_56.jpg){kind=link}
![Products Example: Table, Items, Attributes ] [ id=”301” id=”201” Author=”Simone”,](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_57.jpg){kind=link}
![Products Example: Table, Items, Attributes ] [ id=”301” id=”201” Author=”Simone”,](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_58.jpg){kind=link}
![DynamoDB Data Types ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_59.jpg){kind=link}
![DynamoDB Data Types ] [ Scalar Number (+/-, 38 digits)](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_60.jpg){kind=link}
![Primary Key: Hash / Hash + Range ] [ 30](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_61.jpg){kind=link}
![Primary Key: Hash / Hash + Range ] [ 30](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_62.jpg){kind=link}
![Primary Key: Hash / Hash + Range ] [ 30](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_63.jpg){kind=link}
![Primary Key: Hash / Hash + Range ] [ 31](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_64.jpg){kind=link}
![Primary Key: Hash / Hash + Range ] [ 31](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_65.jpg){kind=link}
![Primary Key: Hash / Hash + Range ] [ 31](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_66.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Query / Scan ] [ 36 http://docs.amazonwebservices.com/amazondynamodb/latest/developerguide/QueryAndScan.html](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_72.jpg){kind=link}
![Query / Scan ] [ 36 Query • Search only](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_73.jpg){kind=link}
![Query / Scan ] [ 36 Scan • Scans the](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_74.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
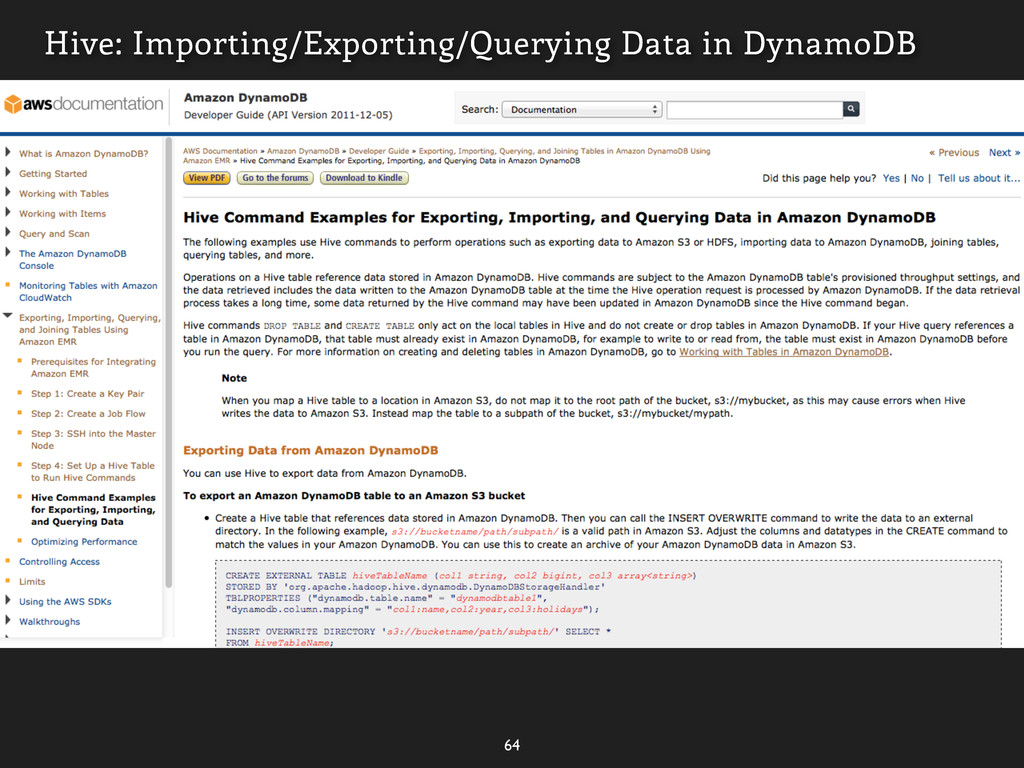
![Writing to DynamoDB ] [ 41 http://docs.amazonwebservices.com/amazondynamodb/latest/developerguide/QueryAndScan.html](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_79.jpg){kind=link}
![Writing to DynamoDB ] [ 41 http://docs.amazonwebservices.com/amazondynamodb/latest/developerguide/QueryAndScan.html How to solve](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_80.jpg){kind=link}
![Writing to DynamoDB ] [ 41 http://docs.amazonwebservices.com/amazondynamodb/latest/developerguide/QueryAndScan.html How to solve](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_81.jpg){kind=link}
![DynamoDB The “Lost update” concurrency issue ] [ Client 1](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_82.jpg){kind=link}
![DynamoDB The “Lost update” concurrency issue ] [ Client 1](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_83.jpg){kind=link}
![DynamoDB The “Lost update” concurrency issue ] [ Client 1](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_84.jpg){kind=link}
![DynamoDB How to fix it with Conditional Writes ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_85.jpg){kind=link}
![DynamoDB How to fix it with Conditional Writes ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_86.jpg){kind=link}
![DynamoDB How to fix it with Conditional Writes ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_87.jpg){kind=link}
![Conditional Writes or Atomic Counters? ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_88.jpg){kind=link}
![Conditional Writes or Atomic Counters? ] [ Conditional Writes •Idempotent](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_89.jpg){kind=link}
![Conditional Writes or Atomic Counters? ] [ Conditional Writes •Idempotent](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_90.jpg){kind=link}
{kind=link}
![(Eventually) Consistent Reads ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_92.jpg){kind=link}
![(Eventually) Consistent Reads ] [ Consistent Read •Consumes more “read](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_93.jpg){kind=link}
![(Eventually) Consistent Reads ] [ Consistent Read •Consumes more “read](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_94.jpg){kind=link}
![(Eventually) Consistent Reads ] [ Consistent Read •Consumes more “read](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_95.jpg){kind=link}
![(Eventually) Consistent Reads ] [ Consistent Read •Consumes more “read](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_96.jpg){kind=link}
![DynamoDB Durability in DynamoDB ] [ Client Time](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_97.jpg){kind=link}
![DynamoDB Durability in DynamoDB ] [ Client Id=1 Price=10 Id=1](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_98.jpg){kind=link}
![Example: Consistent Read (HTTP request) ] [ 49 // This](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_99.jpg){kind=link}
![Example: Consistent Read (HTTP request) ] [ 49 // This](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_100.jpg){kind=link}
![Consistency Availability Partition Tolerance CAP Theorem ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_101.jpg){kind=link}
{kind=link}
![DynamoDB APIs ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_103.jpg){kind=link}
![DynamoDB APIs ] [ Table •CreateTable •UpdateTable •DeleteTable •DescribeTable •ListTables](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_104.jpg){kind=link}
![53 (image) Monitoring DynamoDB with CloudWatch ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_105.jpg){kind=link}
{kind=link}
![A simple example ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_107.jpg){kind=link}
![A simple example ] [ Let’s take a look. How](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_108.jpg){kind=link}
{kind=link}
{kind=link}
![Table We are going to use this schema... ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_111.jpg){kind=link}
![Table We are going to use this schema... ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_112.jpg){kind=link}
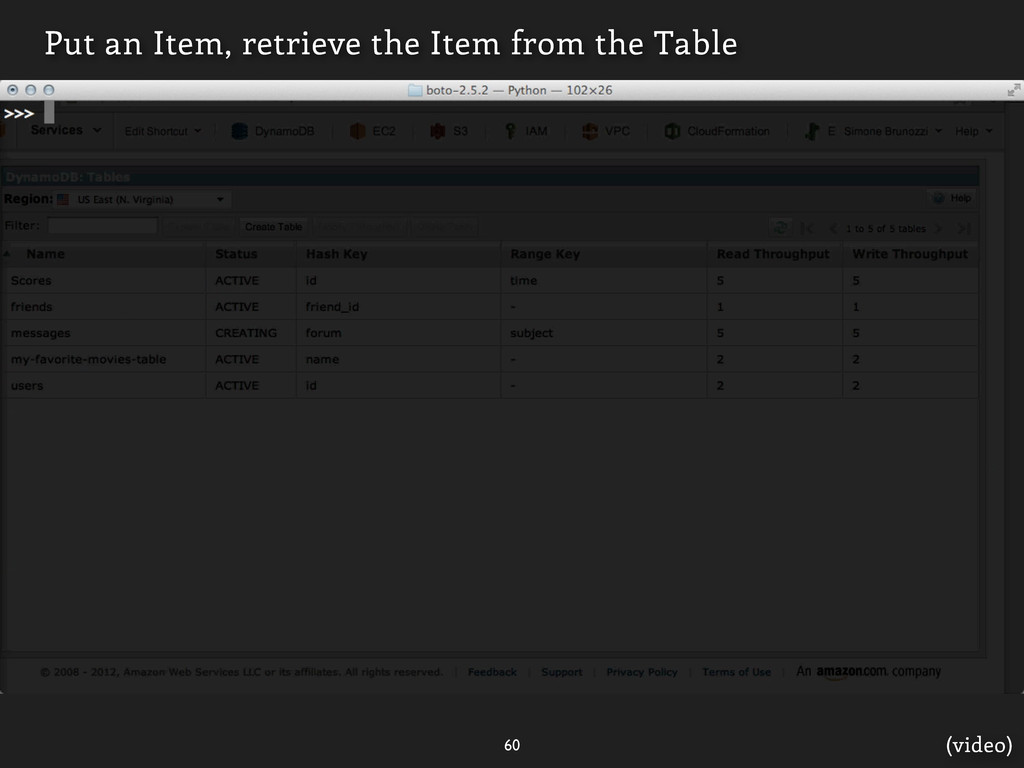
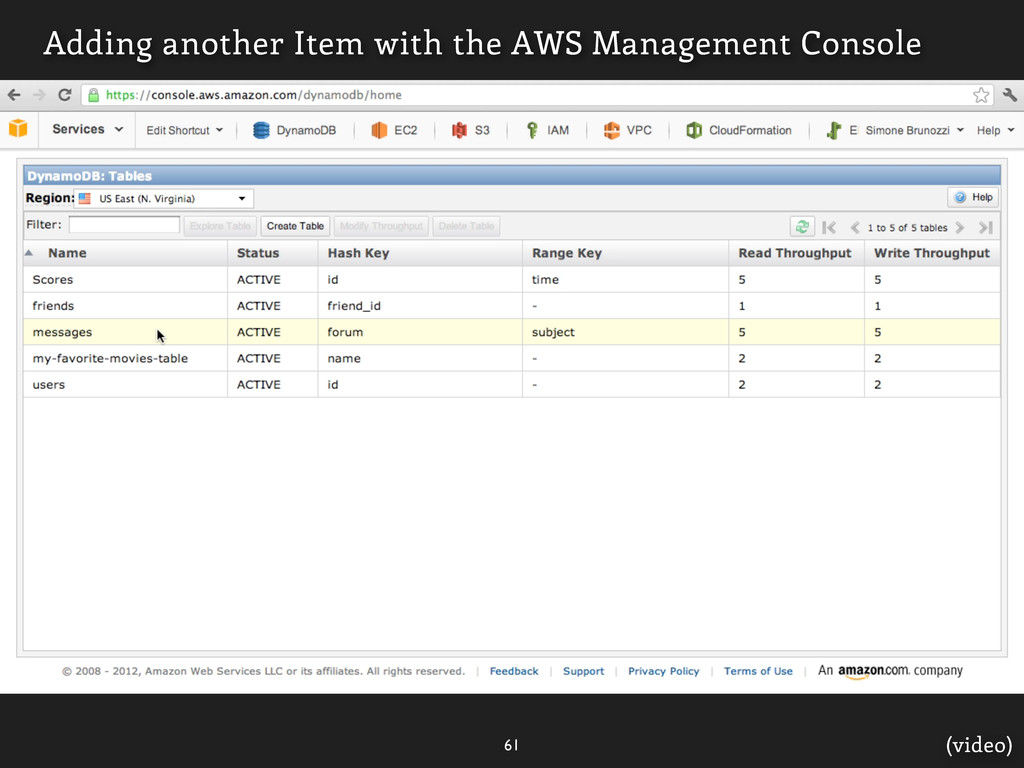
![Messages ... to create a table, and add items. ]](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_113.jpg){kind=link}
![Messages ... to create a table, and add items. ]](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_114.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Ok, I get BOTO. ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_118.jpg){kind=link}
![Ok, I get BOTO. ] [ Do you want more](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_119.jpg){kind=link}
![63 (image) Amazon DynamoDB libraries, mappers, etc. ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_120.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![73 (image) Live repartitioning, no downtime ] [](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_134.jpg){kind=link}
![Why DynamoDB ] [ • Sorted range keys • Conditional](https://files.speakerdeck.com/presentations/9060aa208e950130f883123138195151/slide_135.jpg){kind=link}
{kind=link}
{kind=link}