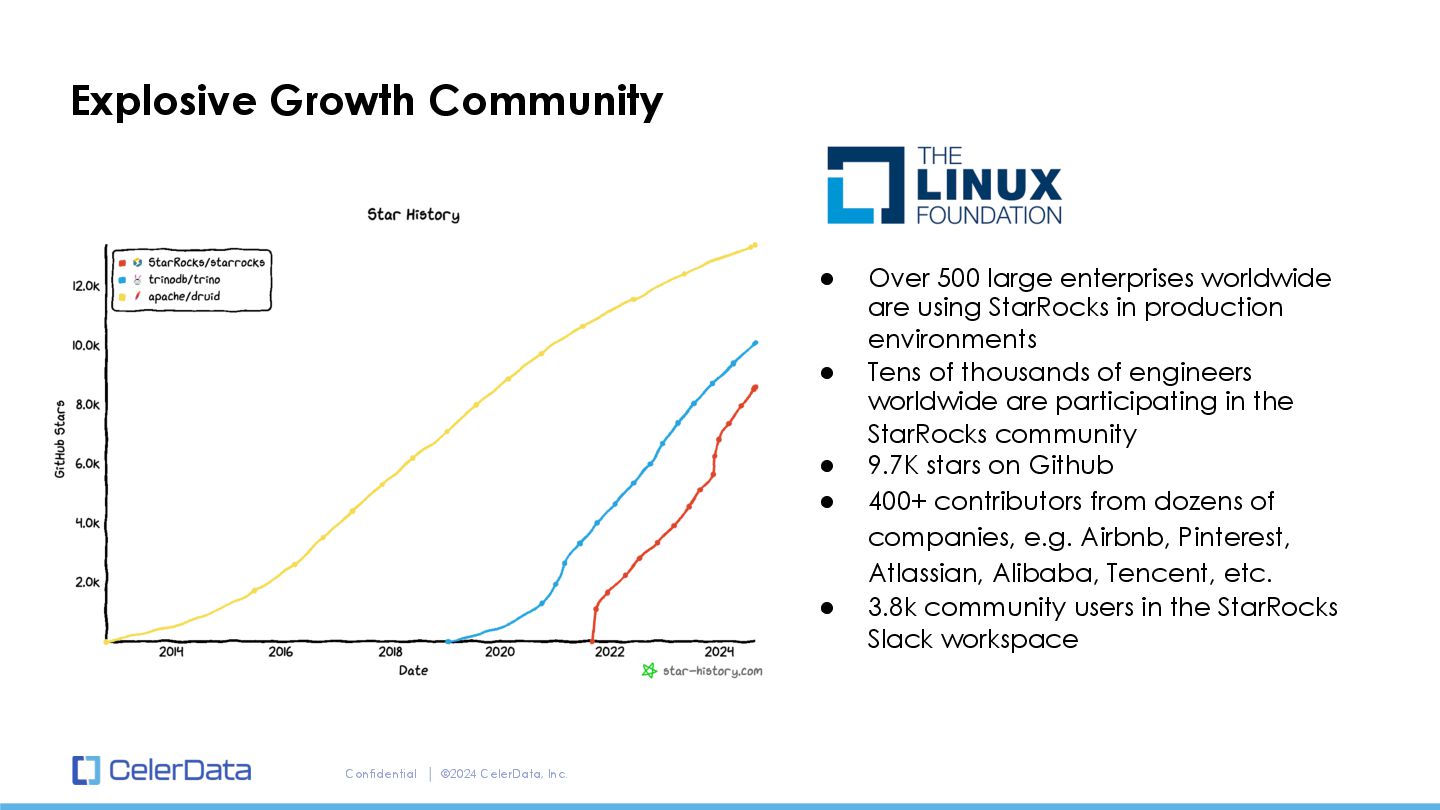
500 large enterprises worldwide are using StarRocks in production environments • Tens of thousands of engineers worldwide are participating in the StarRocks community • 9.7K stars on Github • 400+ contributors from dozens of companies, e.g. Airbnb, Pinterest, Atlassian, Alibaba, Tencent, etc. • 3.8k community users in the StarRocks Slack workspace
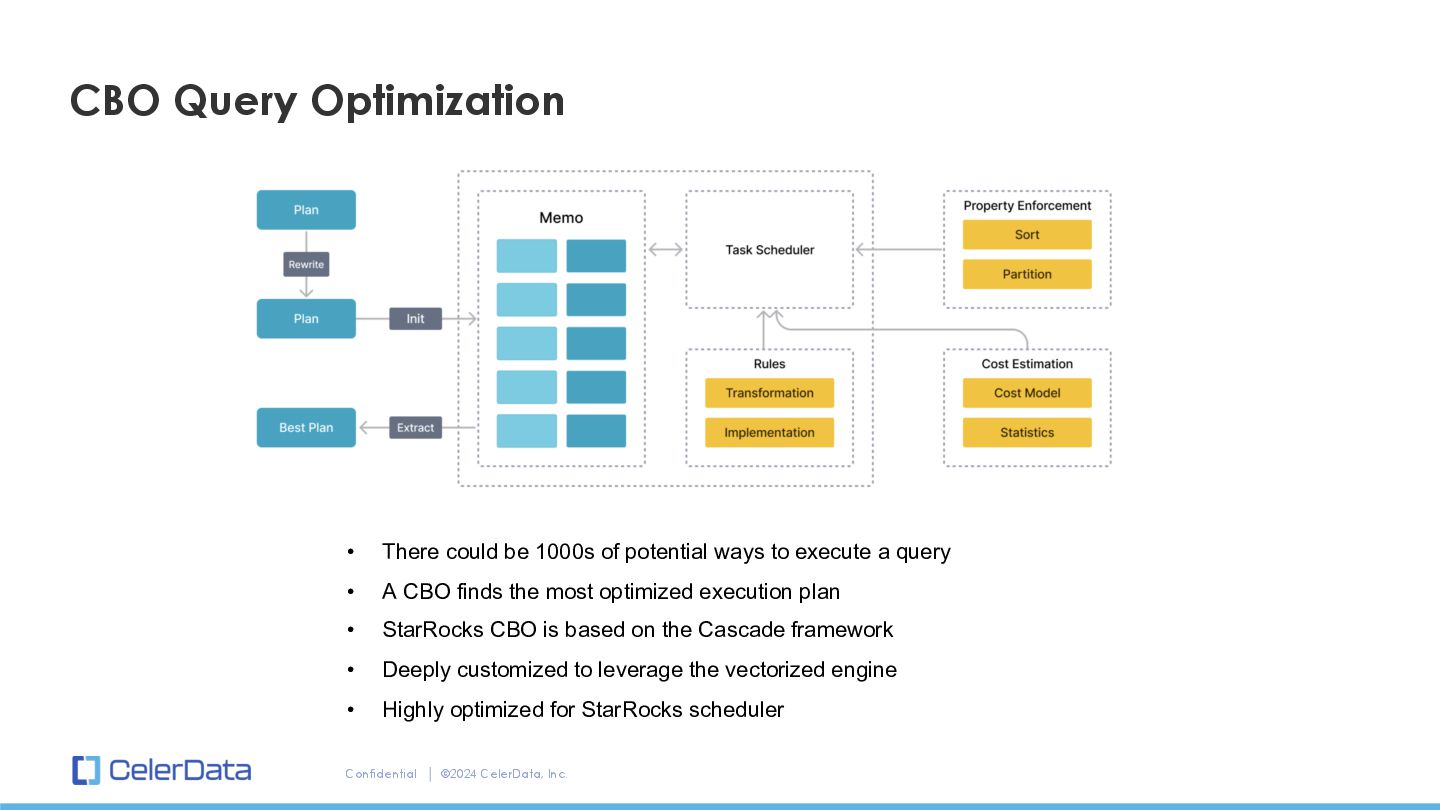
could be 1000s of potential ways to execute a query • A CBO finds the most optimized execution plan • StarRocks CBO is based on the Cascade framework • Deeply customized to leverage the vectorized engine • Highly optimized for StarRocks scheduler
Parquet Reader Optimization ◦ Operation on encoding data ◦ Leverage page index • ORC Reader Optimization ◦ Optimization for small stripes ◦ Predication push down • Generic IO Optimization ◦ IO Merge ◦ Late materialization • Distributed metadata plan ◦ Parse metadata in a distributed way • Manifest cache ◦ Cache parsed manifest information. • Adaptive Strategy Optimization on data lake
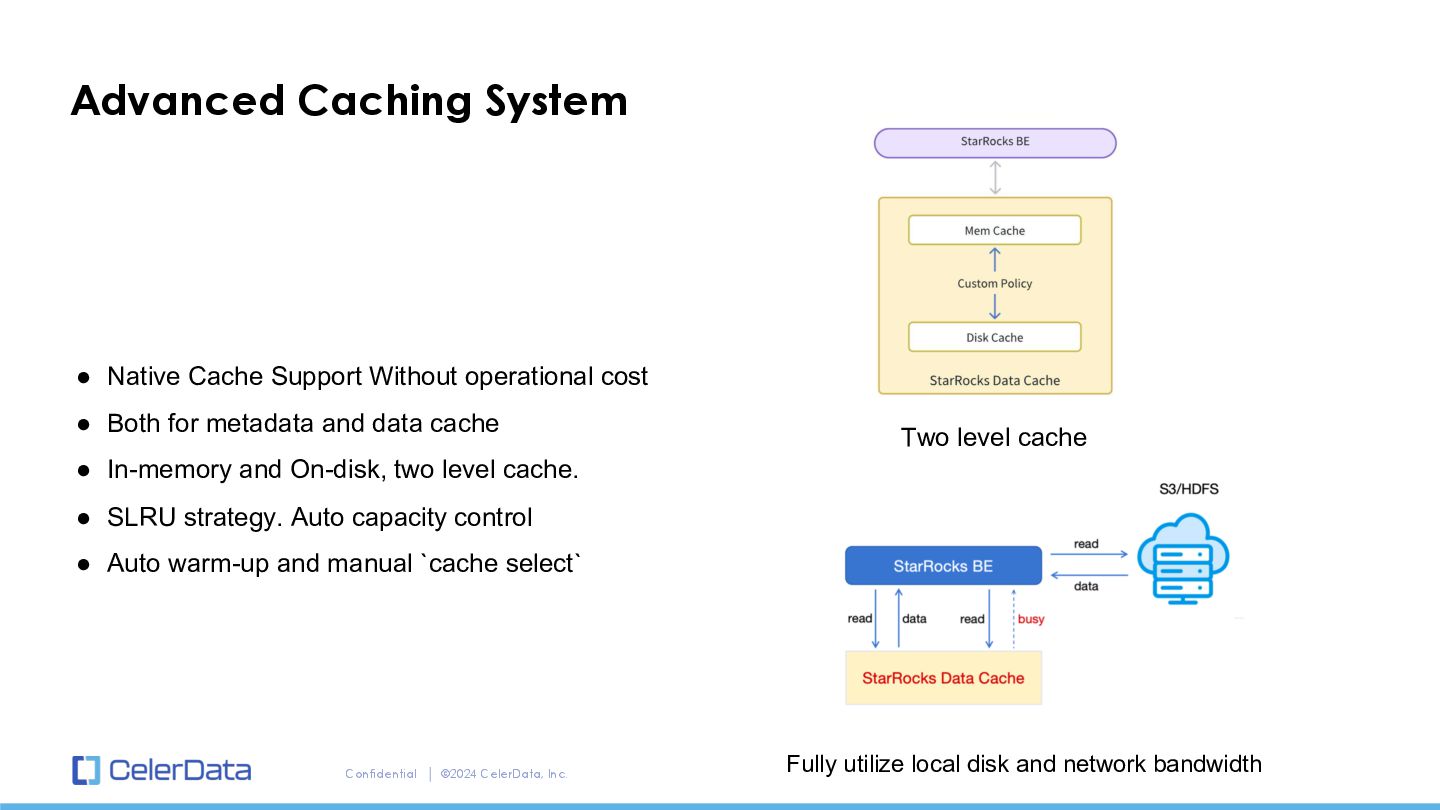
operational cost • Both for metadata and data cache • In-memory and On-disk, two level cache. • SLRU strategy. Auto capacity control • Auto warm-up and manual `cache select` Two level cache Fully utilize local disk and network bandwidth Advanced Caching System
StarRocks Solution Background and Pain Points • Performance Gains: 50% reduction in p90 latency with only 32% of the previous infrastructure, tripling cost-performance efficiency. ~1200 QPS. • Data Freshness: Achieved 10-second data freshness, streamlined ingestion. • Cost comparison: Druid 300 nodes vs StarRocks: 81 nodes, over $2M saved! • Pinterest serves over 500 million users, with advertisers relying on real-time insights to optimize their campaigns. • The existing system using Druid struggled with increasing data scale, high costs, and lacked advanced SQL support. • Complex, multi-dimensional queries and the need for real-time aggregations created performance challenges. Benefits • Real-Time Aggregation: aggregate tables • Query Performance: vectorized query engine, query caching, materialized views • Data ingestion: Use ANSI SQL and eliminated JSON configs. Partner insight is a customer facing dashboard service for advertisers Medium blog post by Pinterest Engineering StarRocks x Pinterest meetup: Customer Facing Analytics that Pays
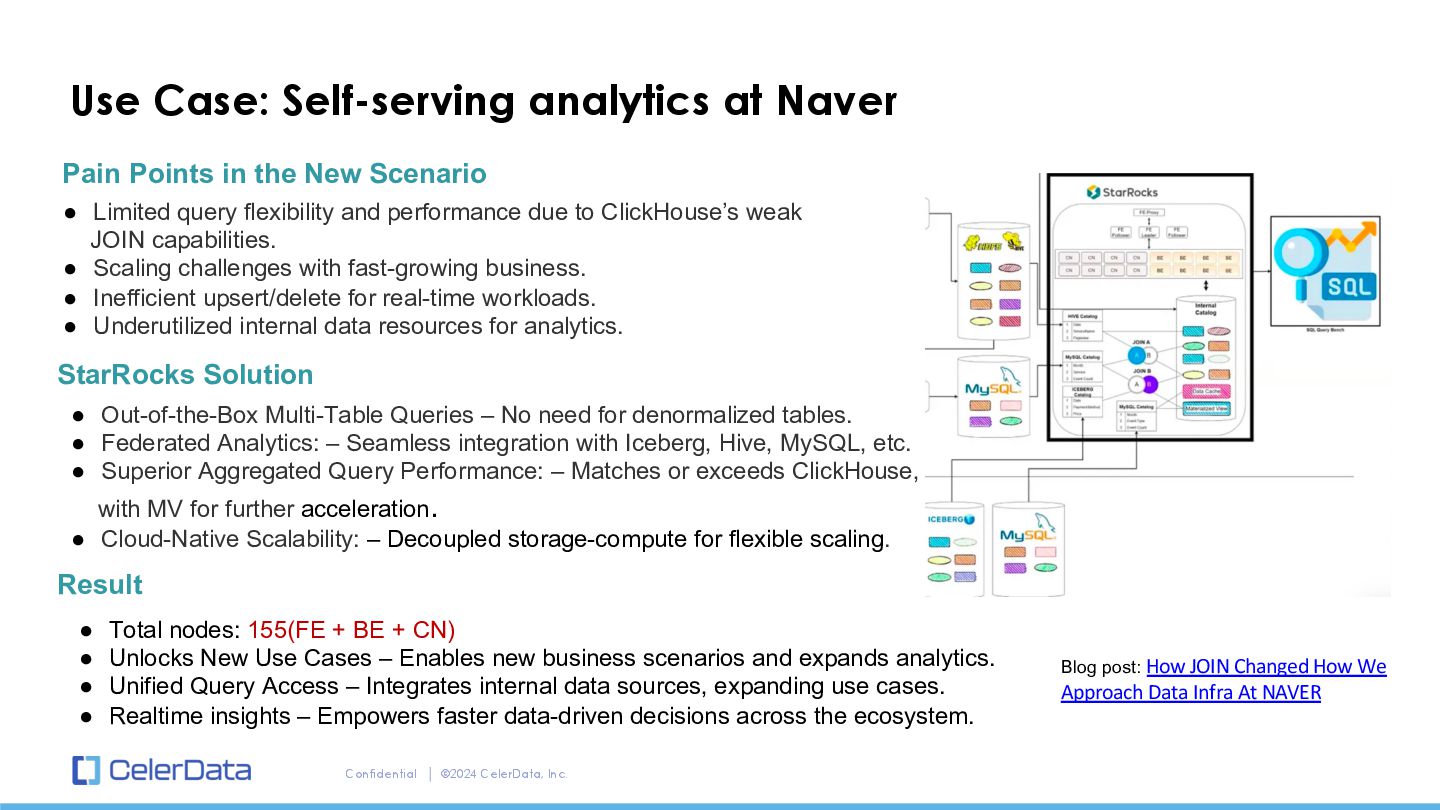
Naver Pain Points in the New Scenario Result StarRocks Solution • Total nodes: 155(FE + BE + CN) • Unlocks New Use Cases – Enables new business scenarios and expands analytics. • Unified Query Access – Integrates internal data sources, expanding use cases. • Realtime insights – Empowers faster data-driven decisions across the ecosystem. • Out-of-the-Box Multi-Table Queries – No need for denormalized tables. • Federated Analytics: – Seamless integration with Iceberg, Hive, MySQL, etc. • Superior Aggregated Query Performance: – Matches or exceeds ClickHouse, with MV for further acceleration. • Cloud-Native Scalability: – Decoupled storage-compute for flexible scaling. • Limited query flexibility and performance due to ClickHouse’s weak JOIN capabilities. • Scaling challenges with fast-growing business. • Inefficient upsert/delete for real-time workloads. • Underutilized internal data resources for analytics. Blog post: How JOIN Changed How We Approach Data Infra At NAVER
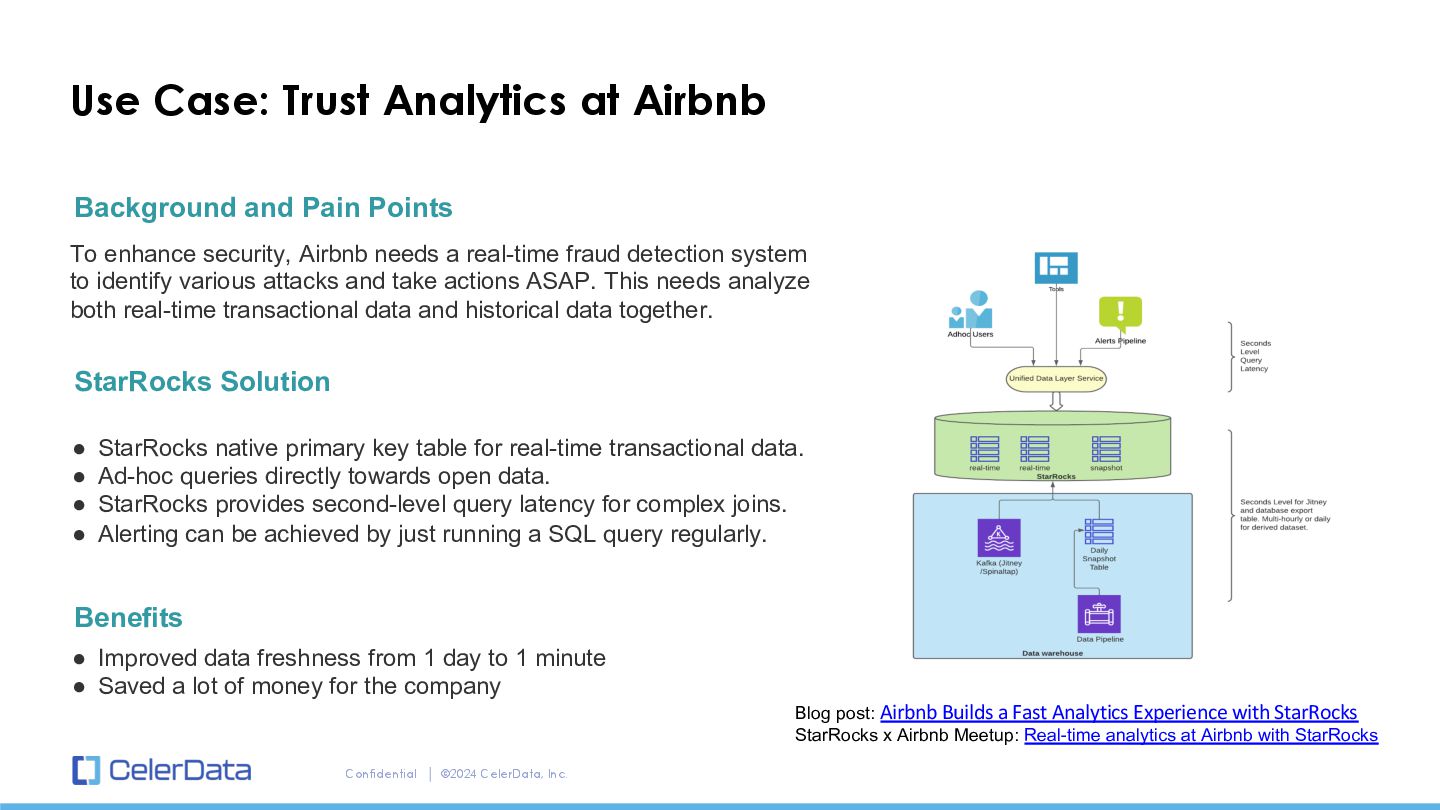
Airbnb StarRocks Solution To enhance security, Airbnb needs a real-time fraud detection system to identify various attacks and take actions ASAP. This needs analyze both real-time transactional data and historical data together. Background and Pain Points • StarRocks native primary key table for real-time transactional data. • Ad-hoc queries directly towards open data. • StarRocks provides second-level query latency for complex joins. • Alerting can be achieved by just running a SQL query regularly. Benefits • Improved data freshness from 1 day to 1 minute • Saved a lot of money for the company Blog post: Airbnb Builds a Fast Analytics Experience with StarRocks StarRocks x Airbnb Meetup: Real-time analytics at Airbnb with StarRocks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}