Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【統計情報】種類と役割【第1回】
Search
Shin
September 08, 2024
Programming
36
0
Share
【統計情報】種類と役割【第1回】
クエリの処理時間を1秒でも短縮するには、統計情報への理解が必要不可欠です。
そこで、統計情報の最初のとっかかりとして種類と役割についてピックアップしました。
Shin
September 08, 2024
More Decks by Shin
See All by Shin
【DWH】Snowflakeのクラスタリングキーについて
sk8er_boi_shin
0
8
【DWH】Snowflakeで等価条件なのにコストが変わる理由
sk8er_boi_shin
0
8
【DWH】 PostgreSQLとSnowFlake_設計思想とデータ管理の違い
sk8er_boi_shin
0
11
【PostgreSQL】メンテナンス系コマンドの種類
sk8er_boi_shin
0
22
【データベース】統計情報と物理順序
sk8er_boi_shin
0
48
感情を整える習慣で仕事はもっとラクになる
sk8er_boi_shin
0
18
【データベース】RedisとPostgreSQL
sk8er_boi_shin
0
110
【データベース】統計情報と単一カラムのヒストグラム
sk8er_boi_shin
0
13
伝わるプロジェクト_伝わらないプロジェクト.pdf
sk8er_boi_shin
0
15
Other Decks in Programming
See All in Programming
From Formal Specification to Property Based Test
ohbarye
0
680
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
460
ハーネスエンジニアリングにどう向き合うか 〜ルールファイルを超えて開発プロセスを設計する〜 / How to approach harness engineering
rkaga
27
18k
Don't Prompt Harder, Structure Better
kitasuke
0
810
WebAssembly を読み込むベストプラクティス 2026年春版 / Best Practices for Loading WebAssembly (Spring 2026)
petamoriken
5
1k
AWSコミュニティ活動は顧客のクラウド推進に効くのか / Do AWS community activities help customers adopt the cloud?
seike460
PRO
0
160
[RubyKaigi 2026] Require Hooks
palkan
1
280
🦞OpenClaw works with AWS
licux
1
320
AI時代のエンジニアリングの原則 / Engineering Principles in the AI Era
haru860
0
1k
(Re)make Regexp in Ruby: Democratizing internals for the JIT
makenowjust
3
970
HTML-Aware ERB: The Path to Reactive Rendering @ RubyKaigi 2026, Hakodate, Japan
marcoroth
0
620
ふりがな Deep Dive try! Swift Tokyo 2026
watura
0
270
Featured
See All Featured
Embracing the Ebb and Flow
colly
88
5k
Making Projects Easy
brettharned
120
6.6k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
The browser strikes back
jonoalderson
0
1k
The SEO Collaboration Effect
kristinabergwall1
1
440
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.4k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
110
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.2k
Faster Mobile Websites
deanohume
310
31k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
330
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.4k
Transcript
【データベース】 統計情報の役割と種類
目次 1. 統計情報の役割 2. 統計情報の主要な種類 3. 統計情報がクエリに与える影響 4. まとめ
1.統計情報の役割 • 概要 データベースがデータの全体像を把握して クエリを早く実行するために必要なガイド情報
1.統計情報の役割 • 役割 データベースがクエリを最適に実行するために、 フルスキャンやインデックススキャンを 選択する際の判断材料として利用される。
1.統計情報の役割 • 統計情報の例 ◦ テーブルにどれくらいの行があるか ◦ どのカラムにどんな値が多いか ◦ データの分布(平均値、最大値、最小値など)
2.統計情報の主要な種類 • テーブルレベルの統計情報 • カラムレベルの統計情報 • インデックスレベルの統計情報
2.統計情報の主要な種類 • テーブルレベルの統計情報: ◦ 概要 ▪ テーブル全体に関する情報。 ◦ 例 ▪
テーブルの総行数、NULL値の割合、重複度など。 ◦ 用途 ▪ テーブル全体をスキャンするか、インデックスを使うかの判断に利用。 ◦ SQL ▪ SELECT * FROM PEOPLE;
2.統計情報の主要な種類 • カラムレベルの統計情報: ◦ 概要 ▪ 各カラムのデータ分布に関する情報。 ◦ 例 ▪
カラムの値の分布(最小値、最大値、平均値) ▪ ユニークな値の数 ▪ データの頻度(ヒストグラム)など。 ◦ 用途: ▪ WHERE句の条件で、INDEXを使うかどうかを決定するために利用。 ◦ SQL ▪ SELECT * FROM PEOPLE WHERE NAME = ‘田中太郎’;
2.統計情報の主要な種類 • インデックスレベルの統計情報: ◦ 概要 ▪ インデックスに関する情報。 ◦ 例 ▪
インデックスのユニーク度(重複がどのくらいあるか) ▪ リーフレベルの深さ ▪ クラスタリングファクタ(INDEXの順序通りにデータが並んでいるか ) ◦ 用途 ▪ INDEXスキャンか、フルスキャンかを決定する際に利用。 ◦ SQL ▪ CREATE INDEX IDX_PEOPLE_1 ON PEOPLE (NAME, ADDRESS); ▪ SELECT * FROM PEOPLE WHERE NAME = ‘田中太郎’;
3.統計情報がクエリに与える影響 • ユニーク度(ヒストグラム) • 適切なインデックスの有無
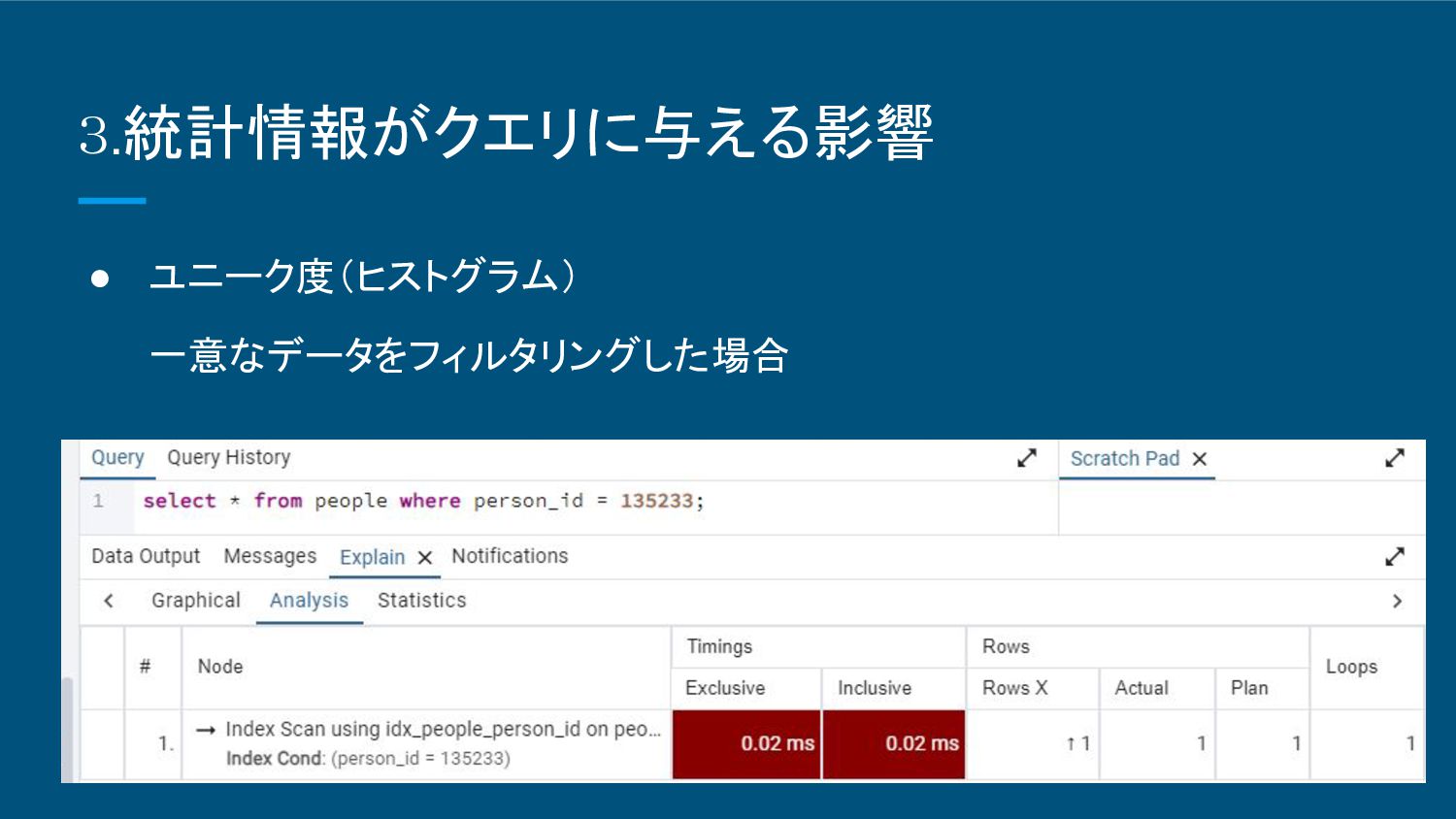
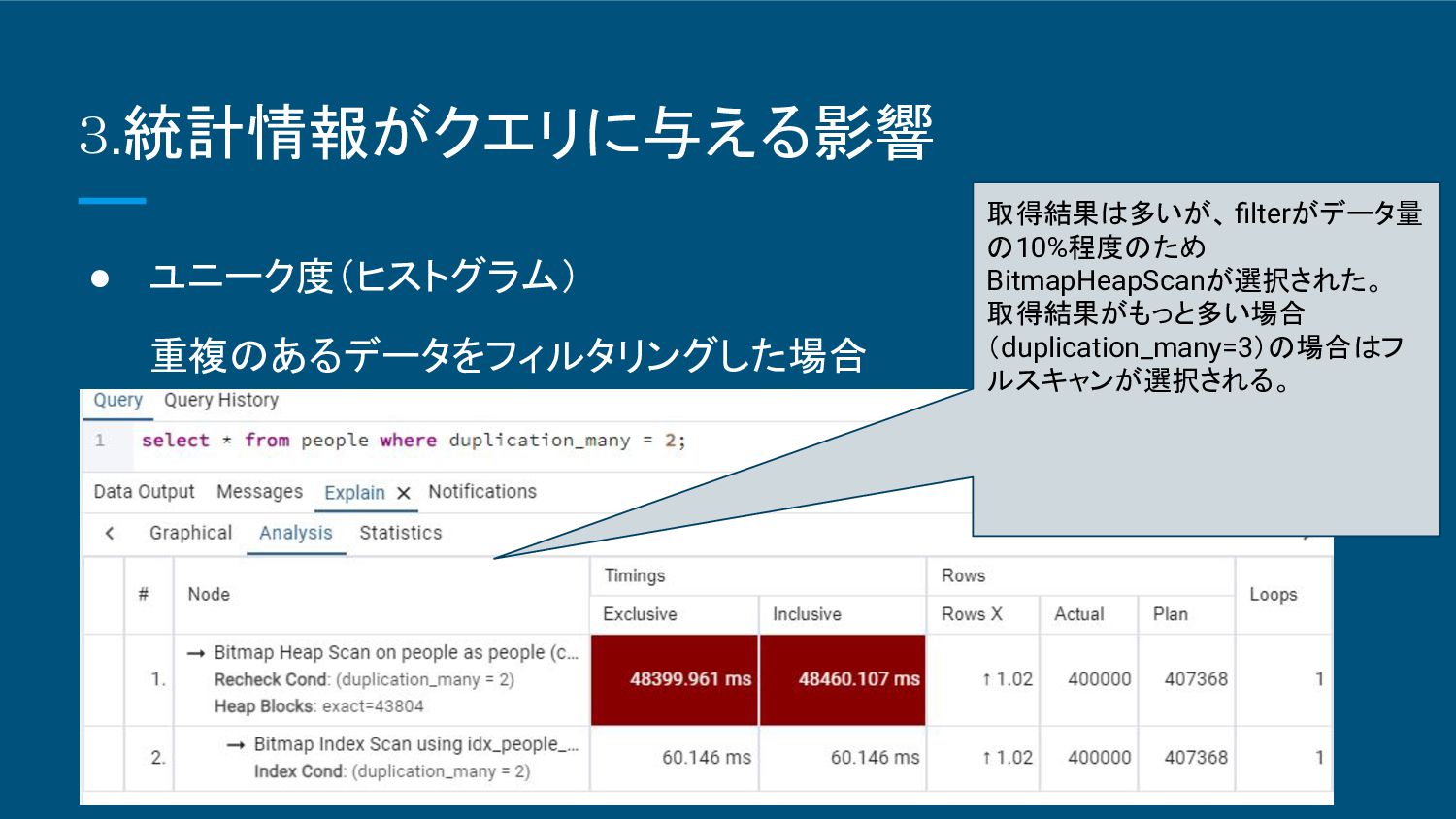
3.統計情報がクエリに与える影響 • ユニーク度(ヒストグラム) ◦ データベース Postgresql ◦ テーブル名 PEOPLE ◦ 統計情報は最新の状態 ◦
データ数 400万件 ◦ index ▪ index名:Idx_people_person_id 指定カラム: person_id ▪ index名:Idx_people_duplication_many 指定カラム: duplication_many ◦ カラム ▪ PERSON_ID(INTEGER型)(一意なデータ) ▪ DUPLICATION_MANY(INTEGER型)(重複のあるデータ) • 0 :40万件 • 1 :40万件 • 2 :40万件 • 3 :280万件
3.統計情報がクエリに与える影響 • ユニーク度(ヒストグラム) 一意なデータをフィルタリングした場合
3.統計情報がクエリに与える影響 • ユニーク度(ヒストグラム) 重複のあるデータをフィルタリングした場合 取得結果は多いが、 filterがデータ量 の10%程度のため BitmapHeapScanが選択された。 取得結果がもっと多い場合 (duplication_many=3)の場合はフ
ルスキャンが選択される。
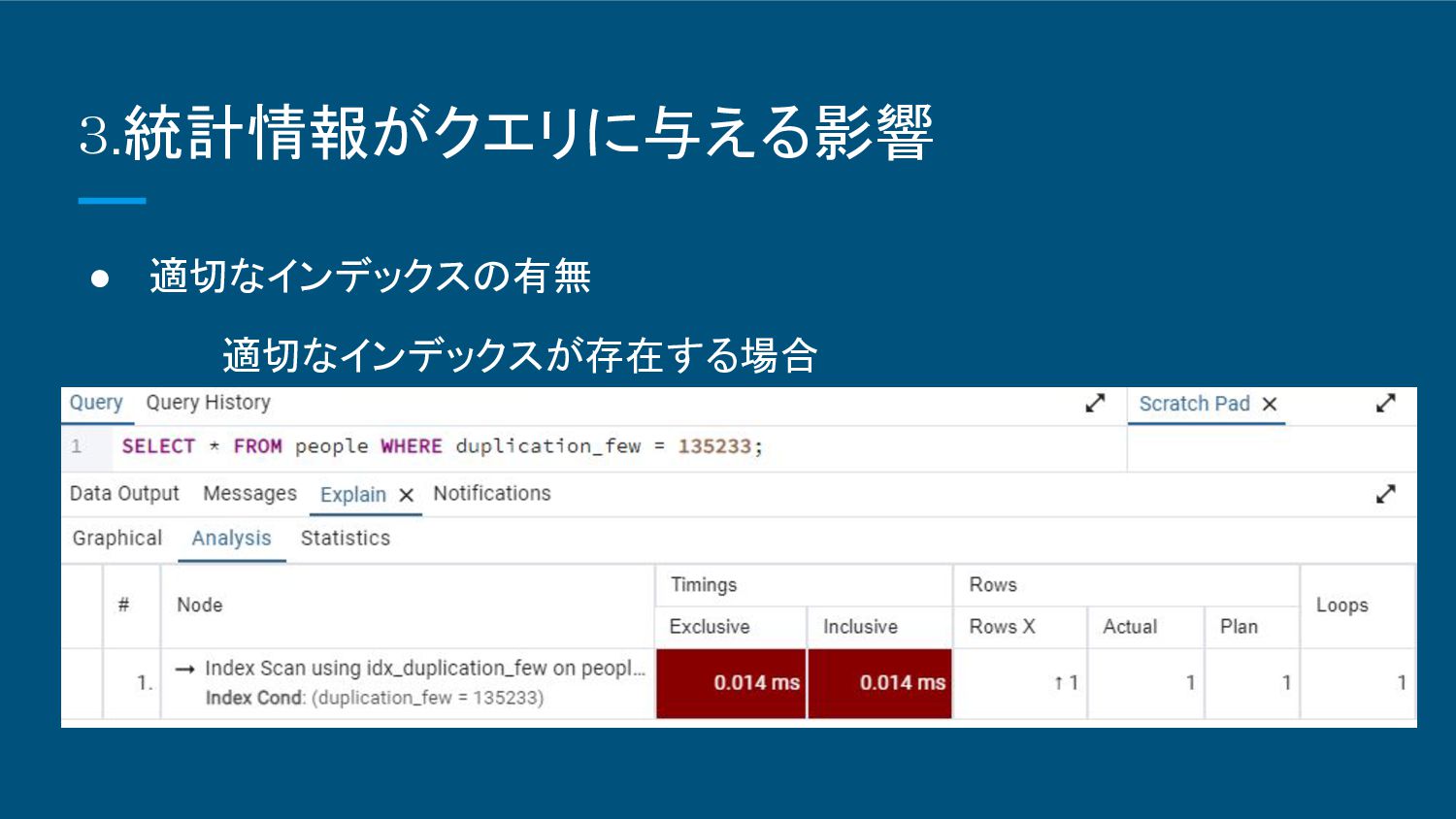
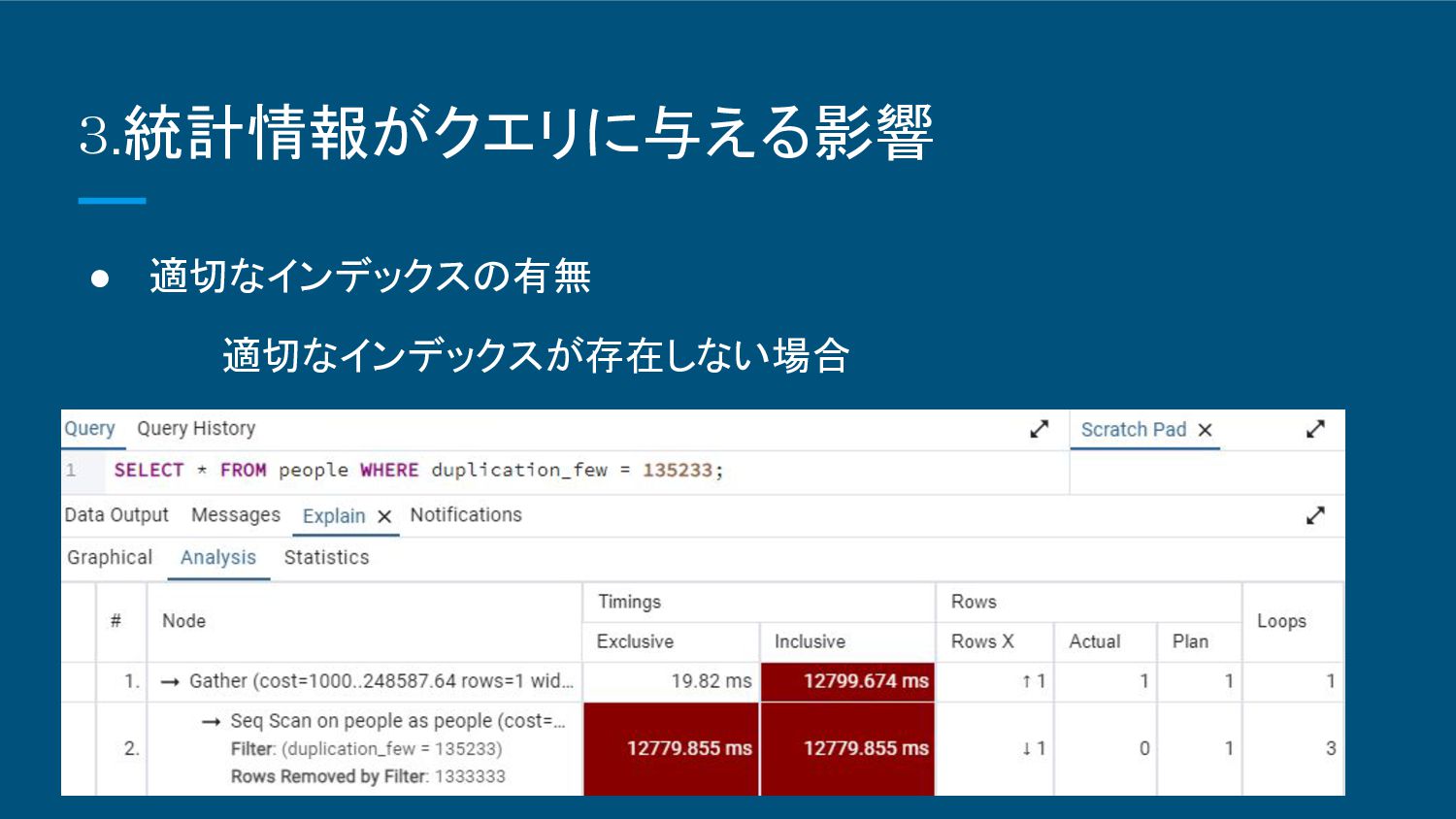
3.統計情報がクエリに与える影響 • 適切なインデックスの有無 ◦ データベース、テーブル名、統計情報最新、データ数の 4項目は先程同様 ◦ index ▪ index名:Idx_duplication_few
指定カラム: duplication_few ◦ カラム ▪ duplication_few(INTEGER型)(一意なデータ) ◦ クエリ ▪ Select * frrom people where duplication_few = 135233;
3.統計情報がクエリに与える影響 • 適切なインデックスの有無 適切なインデックスが存在する場合
3.統計情報がクエリに与える影響 • 適切なインデックスの有無 適切なインデックスが存在しない場合
4.まとめ • FROM、WHERE等を考慮しユニーク度の高いカラムからINDEXに定義 • ヒストグラムを意識したINDEX作成 ◦ 特にユニーク度が高いカラムには INDEXが効果的 ◦ ユニーク度が低くINDEXがあっても時間がかかる場合
▪ パーティション、キャッシュの利用、 LIMIT、OFFSET、非同期等
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}