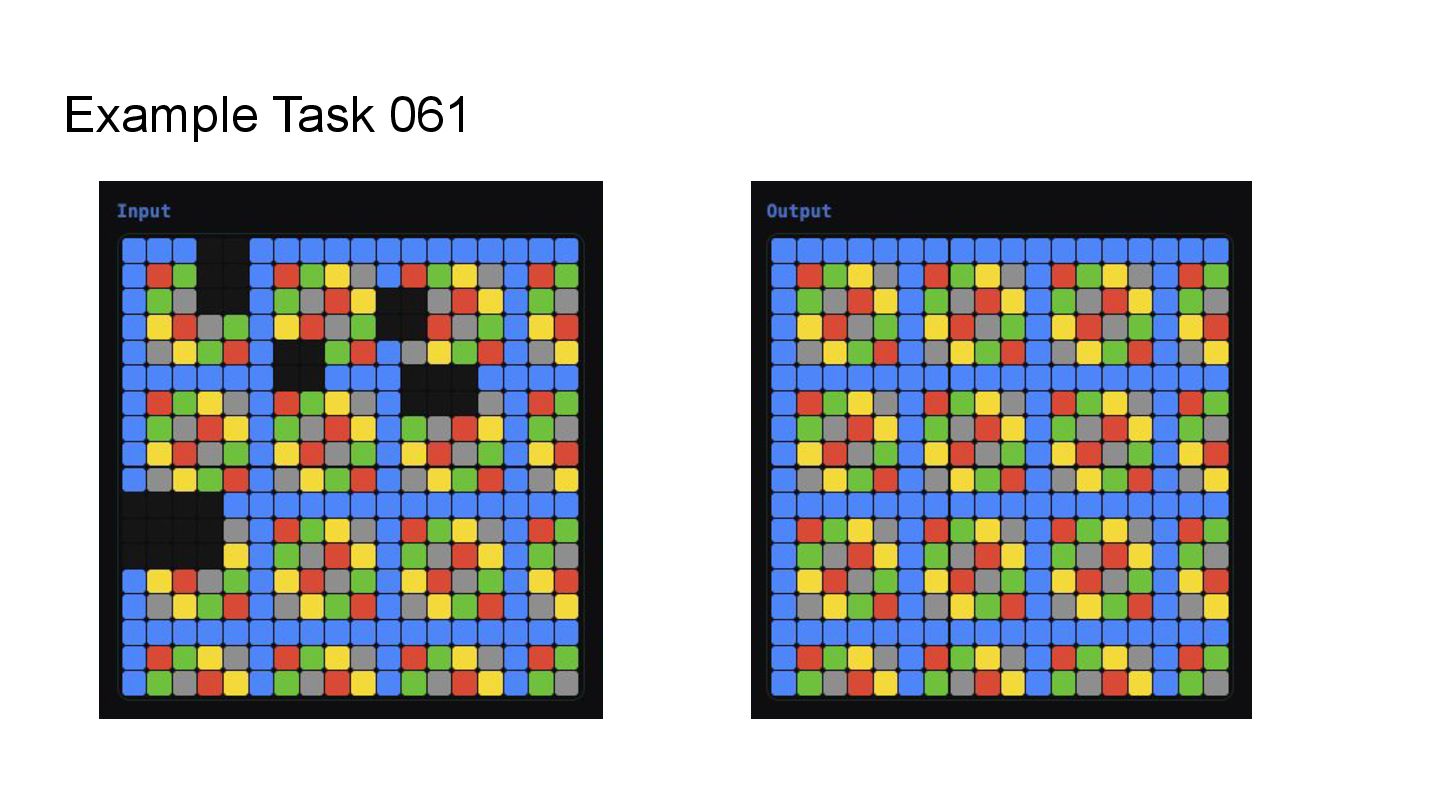
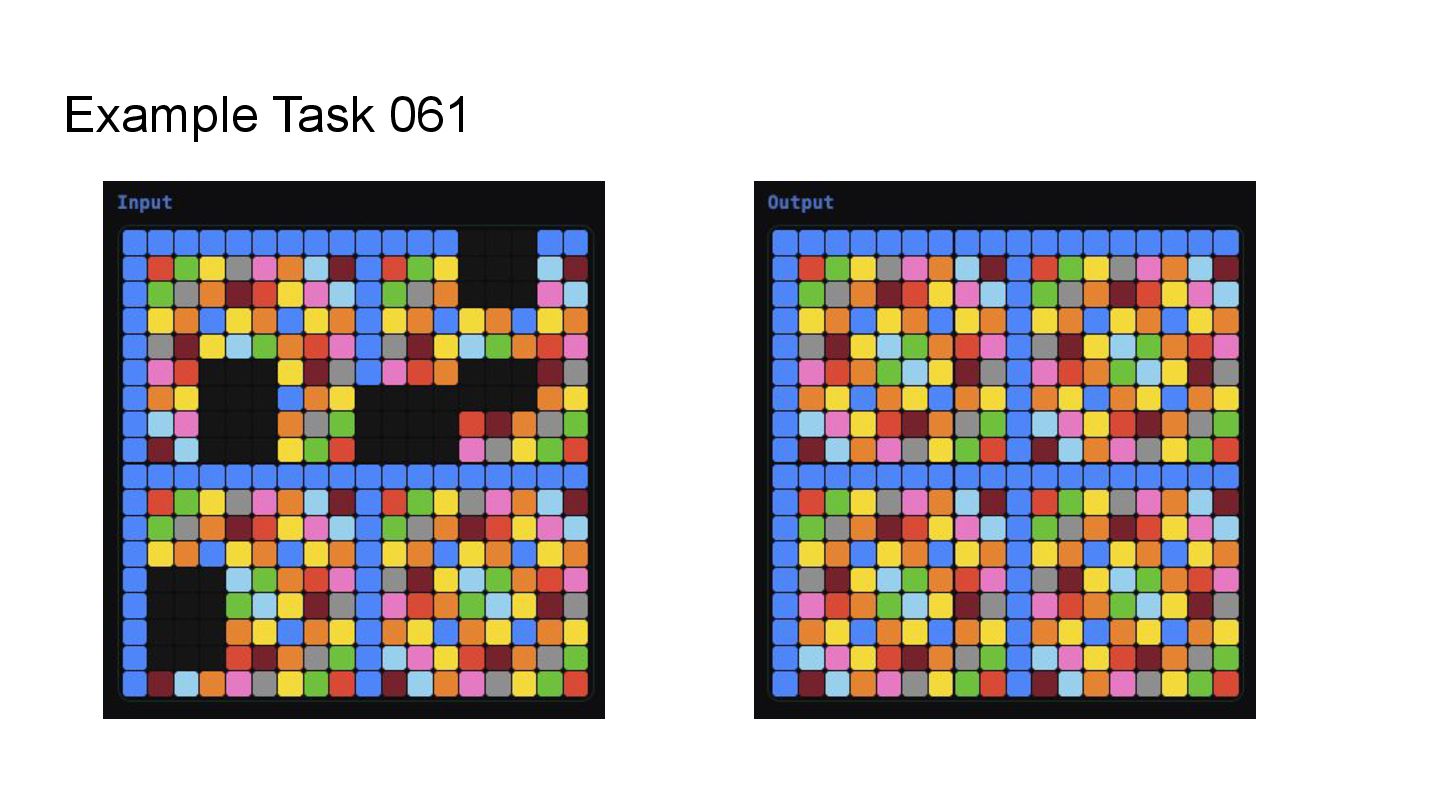
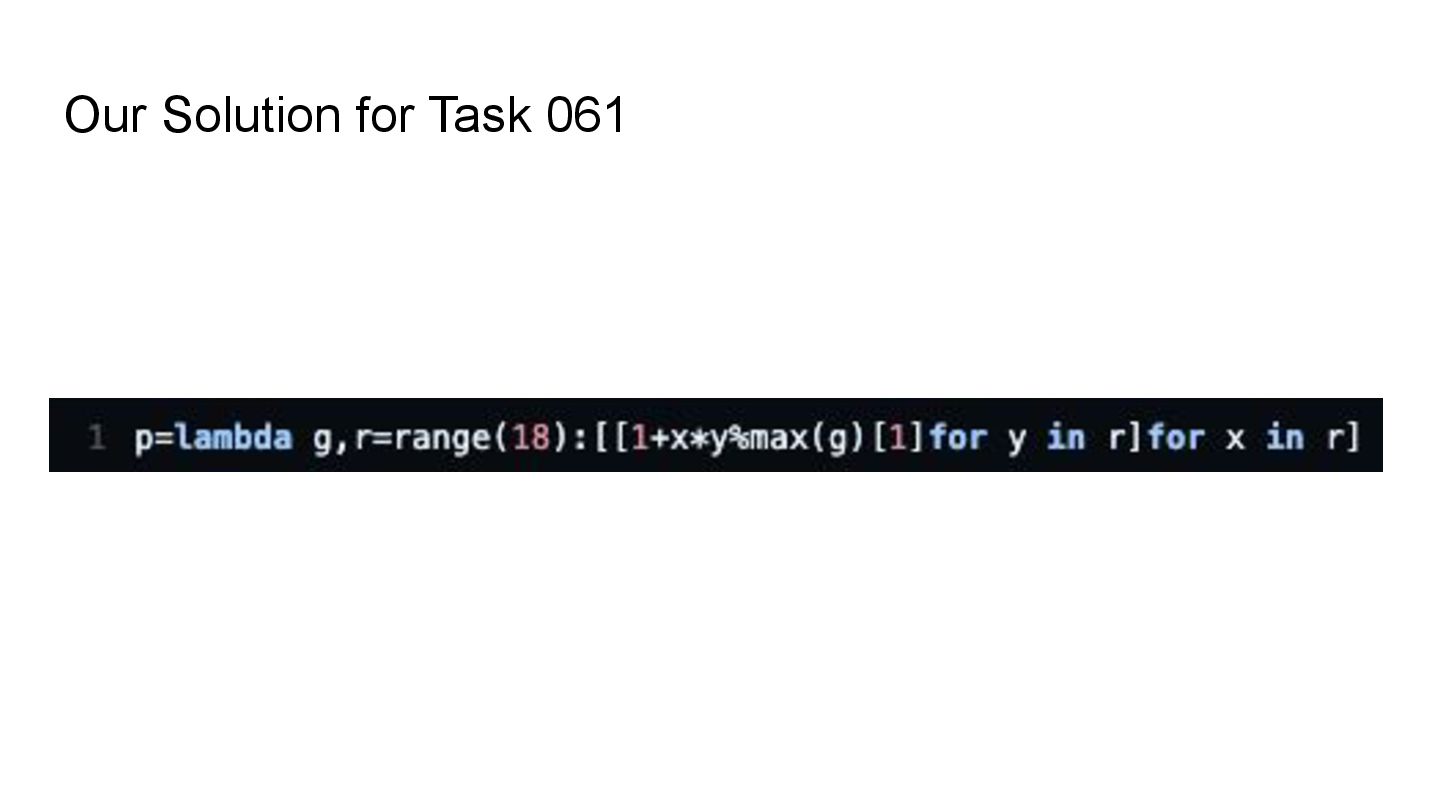
tasks (Abstract Reasoning Corpus) using Python. Constraint: Minimize source code length (bytes). Metric: • Per Task: Score = max(1, 2500 - Length) for correct solutions. • Final Ranking: Determined by the Cumulative Score across 400 tasks. Key Difficulty: • LLMs typically prioritize readability and explanation, not extreme brevity (Code Golf). • It's okay to solve it manually. Can LLM/AI agents beat professional golfers?
need to generate a first version that passes all tests. We used multiple, (semi-)automated approaches for this: - Give the LLM access to the raw test cases and ask it to write code that passes them - Additionally provide the code used to generate most of the test cases - If necessary, also manually describe (part of) the pattern
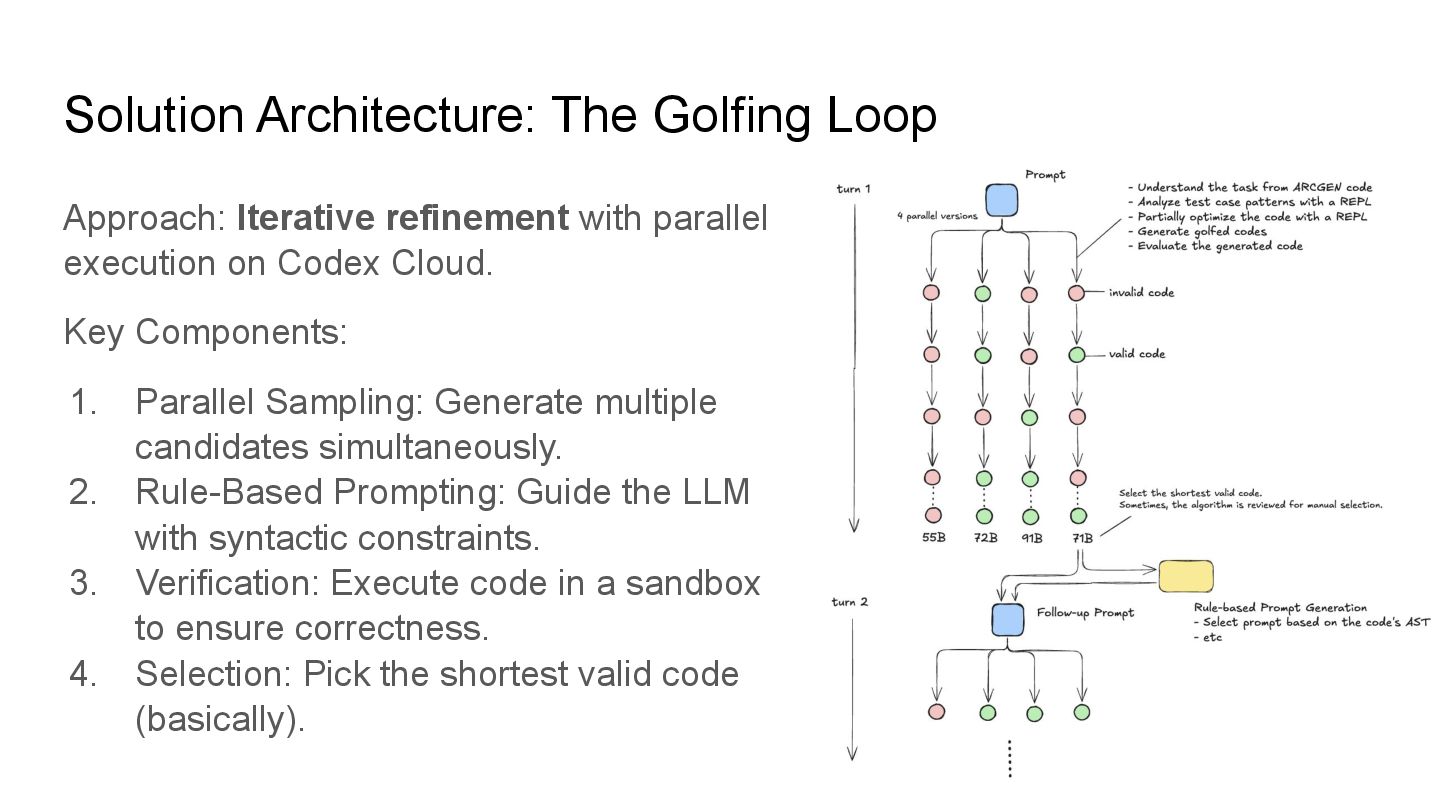
(Greedy/Temperature=0) is rarely optimal for “edge” constraints like code golfing. • Repeated Sampling (Best-of-N): Generating N solutions and selecting the best one significantly improves performance on hard reasoning tasks.[1]
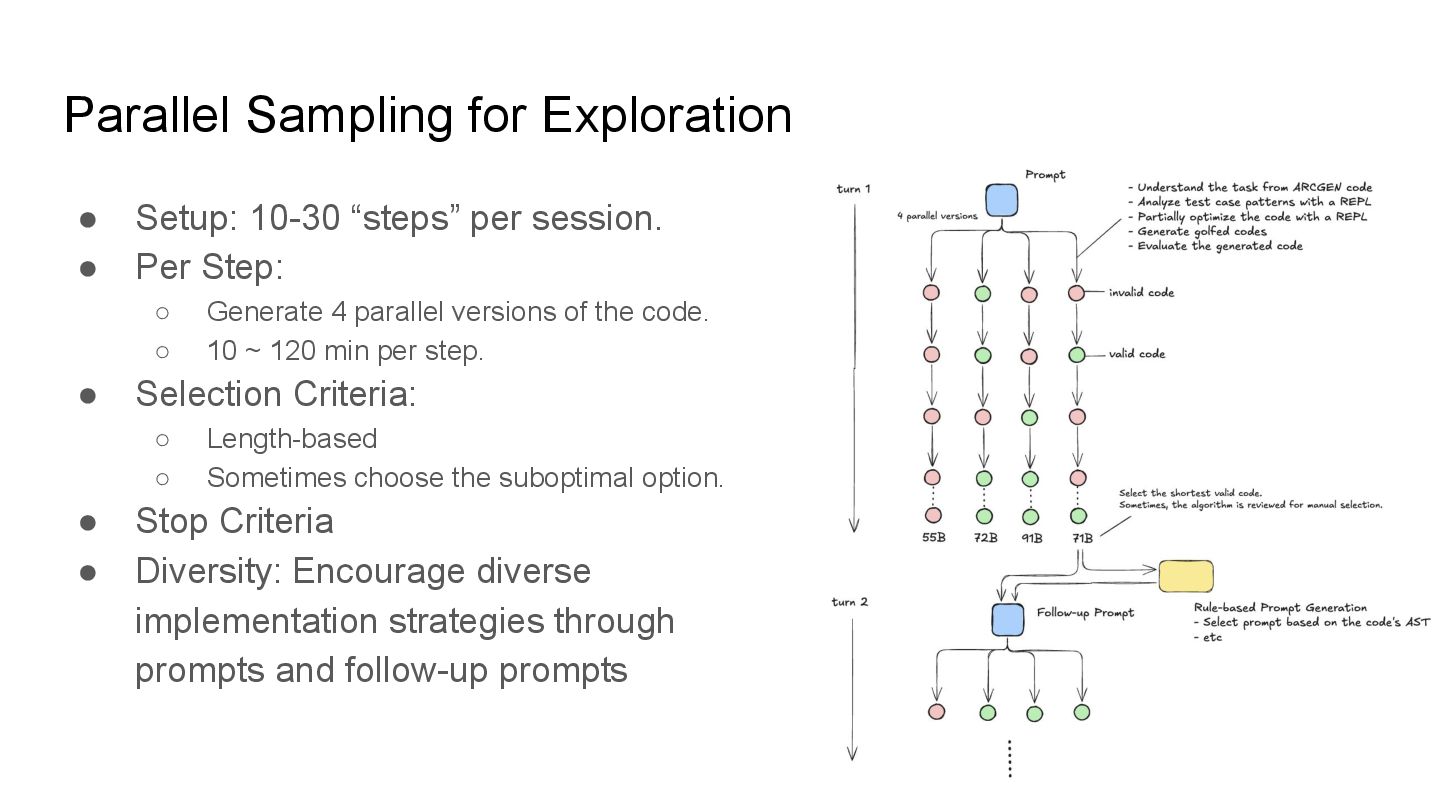
• Per Step: ◦ Generate 4 parallel versions of the code. ◦ 10 ~ 120 min per step. • Selection Criteria: ◦ Length-based ◦ Sometimes choose the suboptimal option. • Stop Criteria • Diversity: Encourage diverse implementation strategies through prompts and follow-up prompts
instruction. • Method: Analyze the current best code’s AST (Abstract Syntax Tree) to generate specific improvement rules. We believed there was significant room for improvement through regex, so we actively instructed LLMs to use regex in the latter half.
minimize the compressed size (e.g., using zopfli). Concept: Python allows executing compressed code: exec(zlib.decompress(b’...’)). Objective: Instruct the LLM to write “compressible” code (repetitive patterns, consistent variable naming) rather than just “short” code.
Iterative refinement (modifying previous code) quickly hits a plateau (Local Minima). The model gets “stuck” in a specific algorithmic approach. • The Solution: Forced Exploration via “From Scratch” Sampling. • Mechanism: ◦ Executing repeated sampling in a clean environment (using codex exec). ◦ Key Prompt Engineering: Explicitly instruct the model to “Ignore the current code and write a solution from scratch.” • Outcome: ◦ While most new sessions were worse, a small fraction discovered fundamentally different algorithms that were unreachable via incremental edits.
Dropout: ◦ In Deep Learning, Dropout prevents overfitting by randomly omitting information. ◦ Here, intentionally “dropping” the context of the current best solution prevents “structural overfitting.” • Exploration vs. Exploitation: ◦ Exploitation: Iteratively refining the best code (Rule-based). ◦ Exploration: “Blind” sampling without history.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}