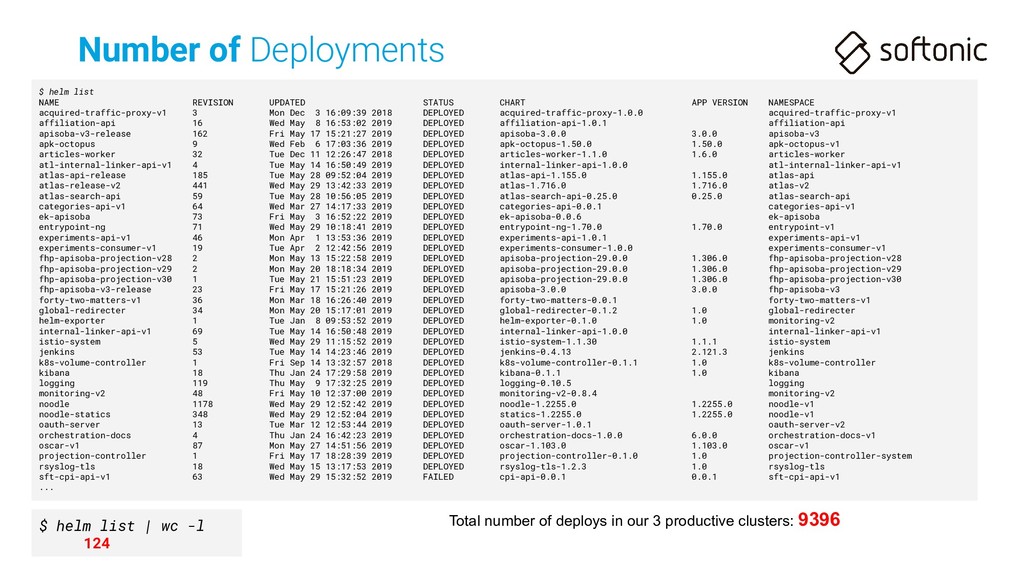
Mainly a download portal • Translated to many languages: EN, DE, ES, IT... => 20! (includes exotic languages like Vietnamese) • 4M daily visits, 12M daily page views • 10K docs/s written in logs in peak time on our services
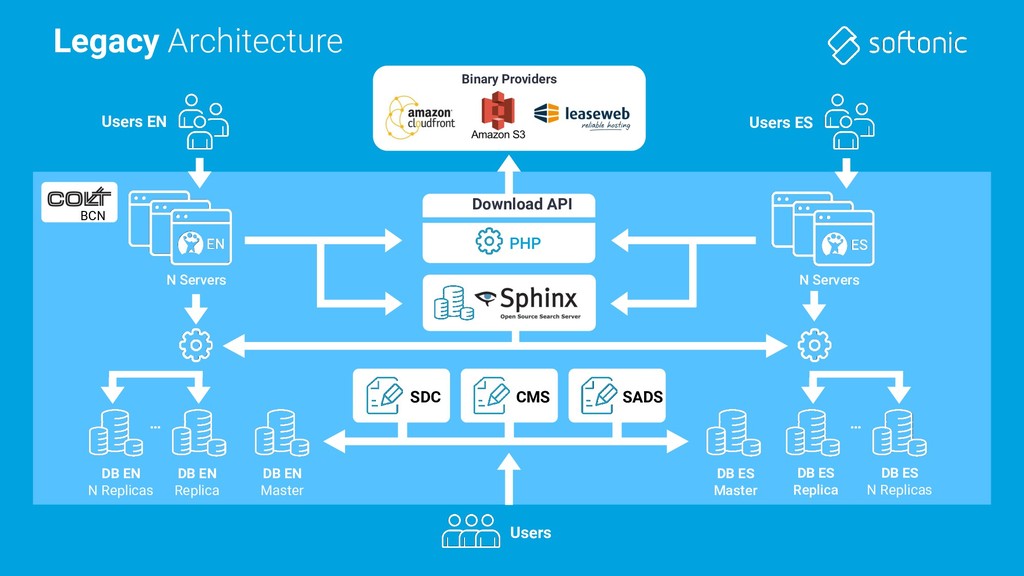
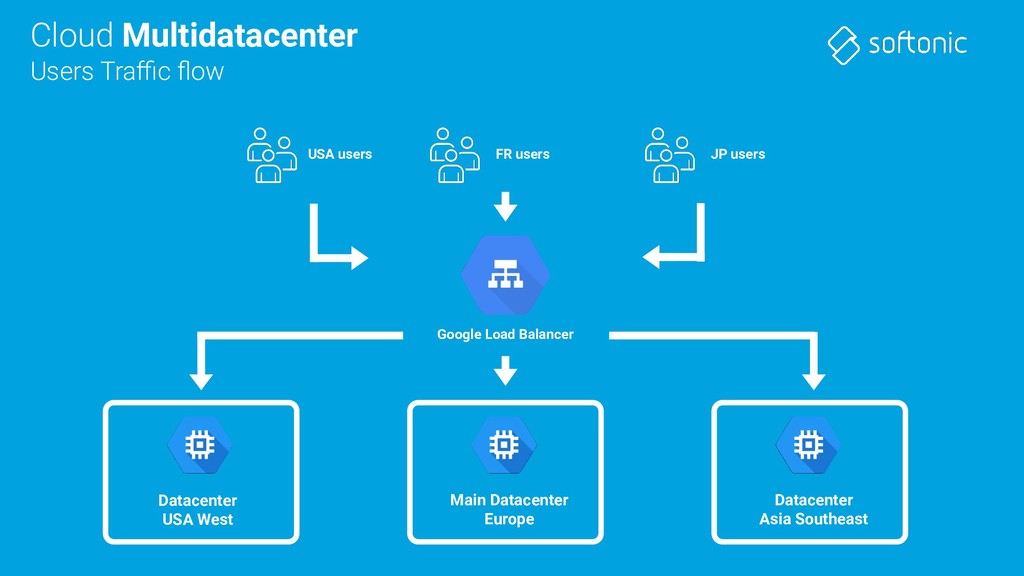
in bare-metal datacenter We have migrated “everything” to SOA and all our workloads run in a cloud provider: Google Cloud Google Kubernetes Engine (GKE) running in different regions and zones
in bare-metal datacenter We have migrated “everything” to SOA and all our workloads run in a cloud provider: Google Cloud Google Kubernetes Engine (GKE) running in different regions and zones We use Elasticstack for logs processing (and runtime database!)
in bare-metal datacenter We have migrated “everything” to SOA and all our workloads run in a cloud provider: Google Cloud Google Kubernetes Engine (GKE) running in different regions and zones We use Elasticstack for logs processing (and runtime database!) Prometheus+Grafana for monitoring
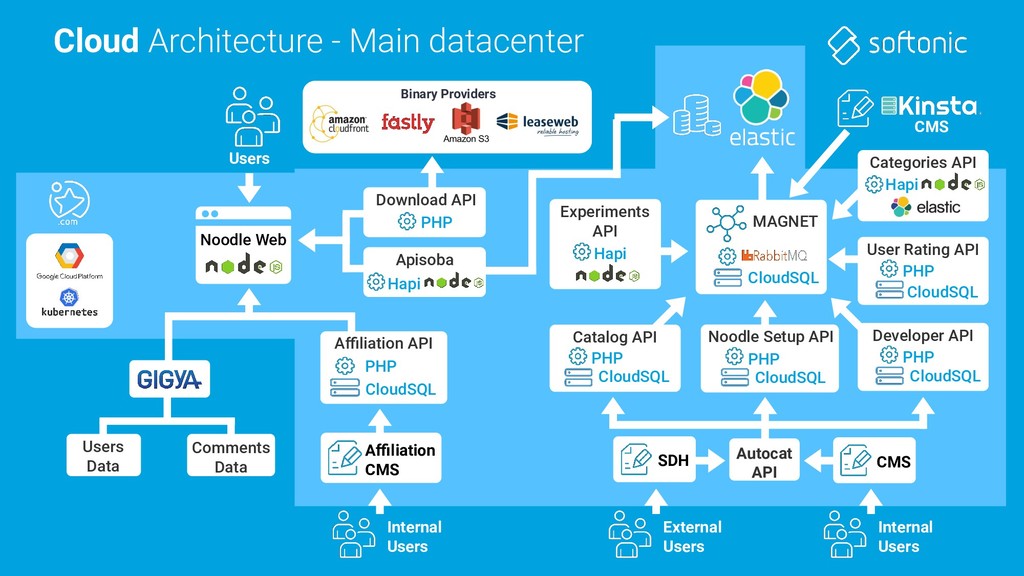
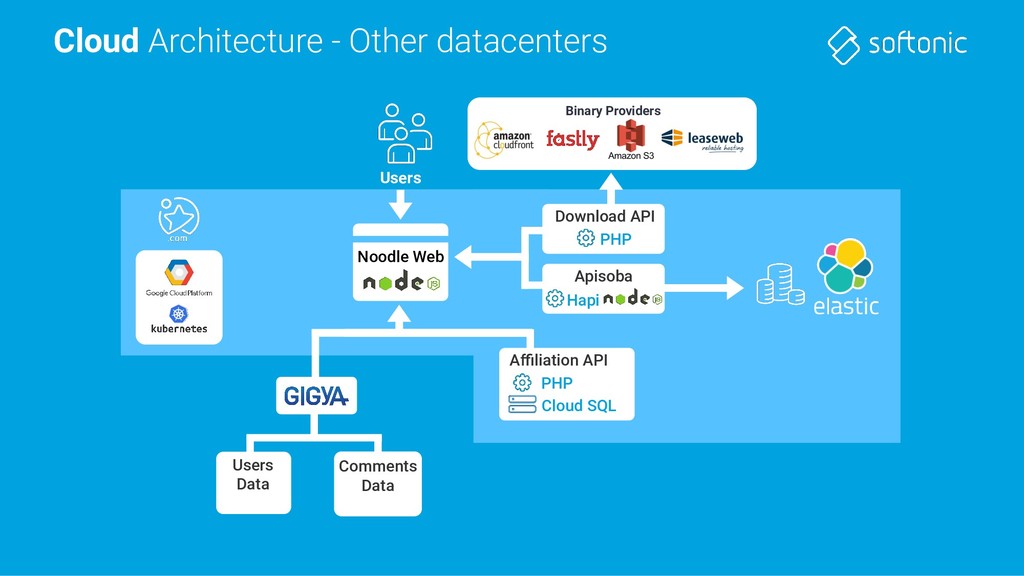
Web Download API PHP Affiliation CMS Users Data Comments Data Apisoba Hapi User Rating API PHP CloudSQL Developer API PHP CloudSQL MAGNET CloudSQL Experiments API Hapi SDH CMS Autocat API Internal Users External Users Internal Users Catalog API PHP CloudSQL Categories API Hapi Noodle Setup API PHP CloudSQL Affiliation API PHP CloudSQL
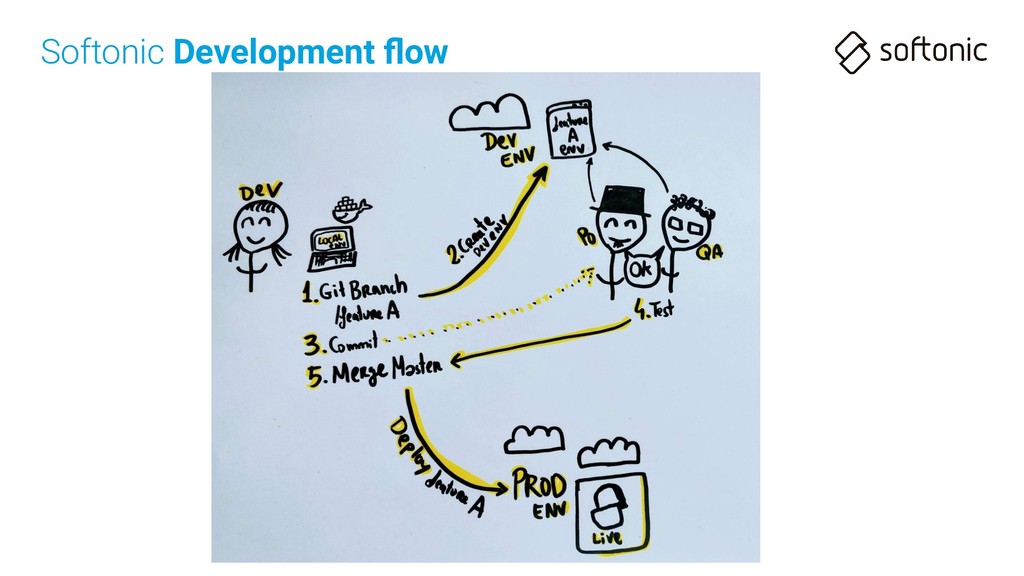
Each project uses its own source code repository based in Git • Central Git repository in Bitbucket • Using Github-flow like development application cycle Softonic Development flow
Each project uses its own source code repository based in Git • Central Git repository in Bitbucket • Using Github-flow like development application cycle • Continuous Integration: Each code push launches automatic tests (& staging env) Softonic Development flow
Each project uses its own source code repository based in Git • Central Git repository in Bitbucket • Using Github-flow like development application cycle • Continuous Integration: Each code push launches automatic tests (& staging env) • Continuous Deployment: Master goes to production “ALWAYS” Softonic Development flow
Docker Compose YAML files for Development ◦ docker-compose up -d • It should be enough for starting to develop! • Helm Charts for Production • Chartmuseum for some helm dependencies Softonic Development flow
Docker Compose YAML files for Development ◦ docker-compose up -d • It should be enough for starting to develop! • Helm Charts for Production • Chartmuseum for some helm dependencies • Jenkins pipeline definition for CI/CD Softonic Development flow
Docker Compose YAML files for Development ◦ docker-compose up -d • It should be enough for starting to develop! • Helm Charts for Production • Chartmuseum for some helm dependencies • Jenkins pipeline definition for CI/CD • Infrastructure as Code using Terraform Softonic Development flow
Docker Compose YAML files for Development ◦ docker-compose up -d • It should be enough for starting to develop! • Helm Charts for Production • Chartmuseum for some helm dependencies • Jenkins pipeline definition for CI/CD • Infrastructure as Code using Terraform • Secrets encrypted in repository (SOPS+Helm secrets plugin) Softonic Development flow
CI/CD which are essentially: • The same in many cases • Slightly different on some • Specific in rare cases We tried to abstract many behaviours in a Jenkins shared library. But before this...
• Get new release version number (SEMVER or whatever) • Build/push images • Notify build status to project repo & slack • Deploy on each target • Notify about the deployment to slack The virtual steps are basically these, but implementation can differ between services of different nature Example of Jenkinsfile that follows these steps
A. Single Helm Chart: An API, with docs and mysql-backup dependencies B. 2 Helm charts, with 2 releases: Frontend application, with statics C. Operator: Magnet+projection, introduced with needed steps and initial helm chart commands.
different REST/GraphQL APIs Most of them have the same deployment process, consists on: • Ensure data dependencies/infrastructure exist: Created via Terraform • Deploy the API via Helm chart ◦ API via main chart ◦ Subchart: cronjob that does automatic backups of MySQL data, or persistent volumes ◦ Subchart: documentation via Helm subchart Pipeline abstracted to a Jenkins shared library
call Terraform utility named Terraformer ◦ It’s a Helm-like application but for Terraform manifests ◦ It allows templating, useful when workspaces are not enough ◦ Searches for “values” and “secrets” files, predefined naming ◦ It uses sops with GCP KMS for managing the secrets, that are encrypted in the source repo Terraformer repo: OPEN SOURCE https://github.com/softonic/terraformer terraformer -f ${CONF} -s .${environment}.enc init &&\ (terraformer -f ${CONF} -s .${environment}.enc workspace select ${environment} ||\ terraformer -f ${CONF} -s .${environment}.enc workspace new ${environment}) &&\ terraformer -f ${CONF} -s .${environment}.enc validate &&\ terraformer -f ${CONF} -s .${environment}.enc apply --auto-approve
call Terraform utility named Terraformer ◦ It’s a Helm-like application but for Terraform manifests ◦ It allows templating, useful when workspaces are not enough ◦ Searches for “values” and “secrets” files, predefined naming ◦ It uses sops with GCP KMS for managing the secrets, that are encrypted in the source repo • We abstract job parameters (and “labels”) for provide a common interface that allows initial provisioning. Useful for: ◦ New clusters ◦ Disaster recovery On each JOB: contexts: ["master”, “replicas"] terraformer -f ${CONF} -s .${environment}.enc init &&\ (terraformer -f ${CONF} -s .${environment}.enc workspace select ${environment} ||\ terraformer -f ${CONF} -s .${environment}.enc workspace new ${environment}) &&\ terraformer -f ${CONF} -s .${environment}.enc validate &&\ terraformer -f ${CONF} -s .${environment}.enc apply --auto-approve Terraformer repo: OPEN SOURCE https://github.com/softonic/terraformer
different REST/GraphQL APIs Most of them have the same deployment process, consists on: • Ensure data dependencies exist: Created via Terraform • Deploy the API via Helm chart ◦ API via main chart ◦ Subchart: cronjob that does automatic backups of MySQL data, or persistent volumes ◦ Subchart: documentation via Helm subchart
different REST/GraphQL APIs Most of them have the same deployment process, consists on: • Ensure data dependencies exist: Created via Terraform OK • Deploy the API via Helm chart ◦ API via main chart ◦ Subchart: cronjob that does automatic backups of MySQL data, or persistent volumes ◦ Subchart: documentation via Helm subchart
different REST/GraphQL APIs Most of them have the same deployment process, consists on: • Ensure data dependencies exist: Created via Terraform OK • Deploy the API via Helm chart ◦ API via main chart ◦ Subchart: cronjob that does automatic backups of MySQL data, or persistent volumes ◦ Subchart: documentation via Helm subchart dependencies: - name: docs version: 2.0.2 repository: "@softonic" - name: k8s-snapshot-cronjob version: 0.1.5 repository: "@softonic" - name: mysql-backups version: 1.1.0 repository: "@softonic"
different REST/GraphQL APIs Most of them have the same deployment process, consists on: • Ensure data dependencies exist: Created via Terraform OK • Deploy the API via Helm chart ◦ API via main chart ◦ Subchart: cronjob that does automatic backups of MySQL data, or persistent volumes ◦ Subchart: documentation via Helm subchart dependencies: - name: docs version: 2.0.2 repository: "@softonic" - name: k8s-snapshot-cronjob version: 0.1.5 repository: "@softonic" - name: mysql-backups version: 1.1.0 repository: "@softonic" docs: enabled: true ingress: subdomain: developer-api image: repository: my.registry.com/developer-api/docs pullSecretName: registry-creds mysqlBackups: enabled: true mysql: database: developer_api host: X.X.X.X secret: name: credentials s3: bucket: mysqldump-sft-developer-api secret: name: mysqldump-aws-credentials
different REST/GraphQL APIs Most of them have the same deployment process, consists on: • Ensure data dependencies exist: Created via Terraform OK • Deploy the API via Helm chart ◦ API via main chart ◦ Subchart: cronjob that does automatic backups of MySQL data, or persistent volumes ◦ Subchart: documentation via Helm subchart dependencies: - name: docs version: 2.0.2 repository: "@softonic" - name: k8s-snapshot-cronjob version: 0.1.5 repository: "@softonic" - name: mysql-backups version: 1.1.0 repository: "@softonic" docs: enabled: true ingress: subdomain: developer-api image: repository: my.registry.com/developer-api/docs pullSecretName: registry-creds mysqlBackups: enabled: true mysql: database: developer_api host: X.X.X.X secret: name: credentials s3: bucket: mysqldump-sft-developer-api secret: name: mysqldump-aws-credentials Helm deployment command explained later
service, what renders our webpage. NodeJS based, uses HAPI framework Uses grunt & webpack: generate static assets for JS/CSS/etc files When you modify a file it generates a new bundle using a hash to identify it uniquely, this allows you to cache the static files and just generate new files in case the content changes between releases
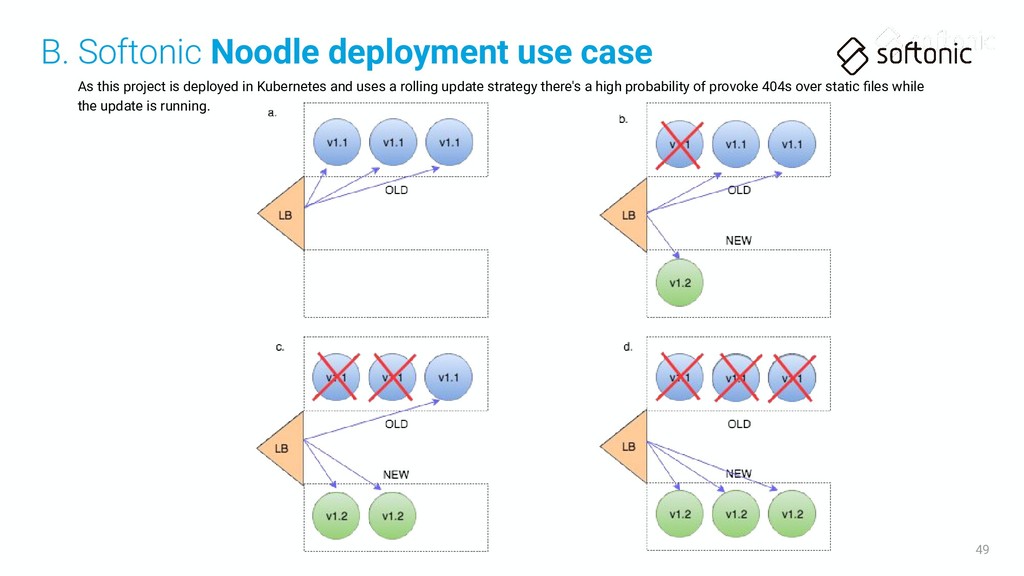
• It's a bit more complicated because of how the deploys are done in a system like Kubernetes: Rolling Update • It is automatically deployed in production when you merge your changes to the master branch Warning Merge your changes always via a PULL REQUEST in the bitbucket project! It's based in Jenkinsfile and it deploys automatically your changes. 48 B. Softonic Noodle deployment use case
a rolling update strategy there's a high probability of provoke 404s over static files while the update is running. B. Softonic Noodle deployment use case
static files (CSS/JS/etc) • These statics are inside the new server (noodle) image • When one new Pod is running it can receive requests and the HTML will use the new static resources • The browser, once loaded the HTML will request these new static resources going to our CDN (Fastly), that goes to origin • Origin is the service in front of the server (noodle) pods • If service decides to route the request to one of the pods that are still executing the old version (remember we are in a middle of an update) the new static resource request will return a 404 error • The 404 error is then served to the browser who's not able to load the CSS/JS/etc failed file • Only when the deploy has finished completely we can be sure no 404 errors will be produced because of this For fixing this problem we have decided to do a 2-steps deploy of each new Noodle release B. Softonic Noodle deployment use case
statics • Contains all the CSS/JS/IMG/Fonts/etc static files in the image • They are copied in BUILD time from the last server and noodle-statics images • It's additive, each new version contains the earlier statics • TODO: We should decide how to automatically clean very old noodle-statics not useful anymore 2. Noodle server • Contains the application logic • During build time all the static content is available under a well-known directory • This directory is used by the noodle-statics image for obtain the static content B. Softonic Noodle deployment use case FROM softonic/nginx-vts:1.15.8-1 COPY ./rootfs / COPY --from=my.registry.com/noodle/statics:latest /www/data /www/data COPY --from=my.registry.com/noodle/server:latest /usr/src/app/public /www/data
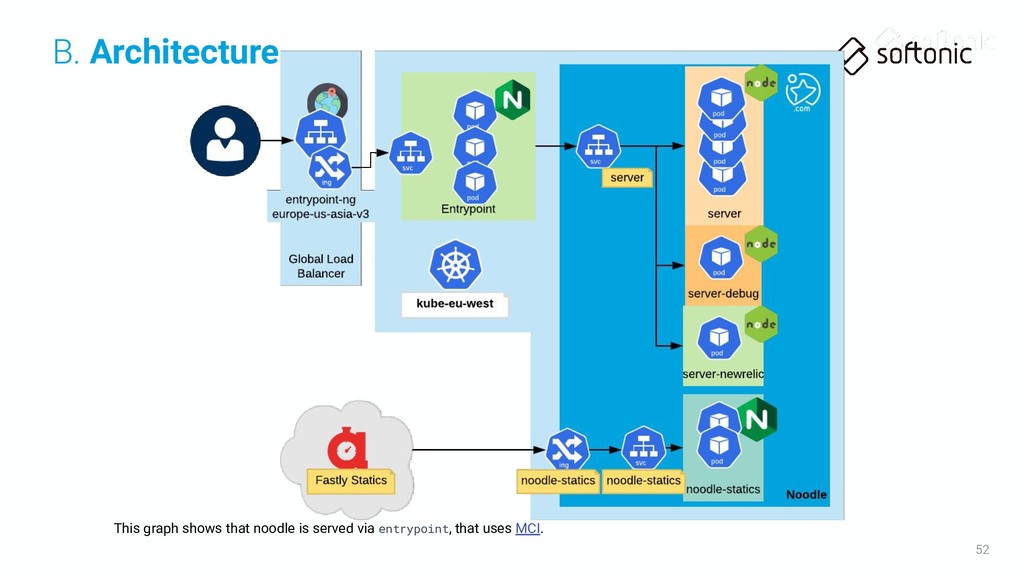
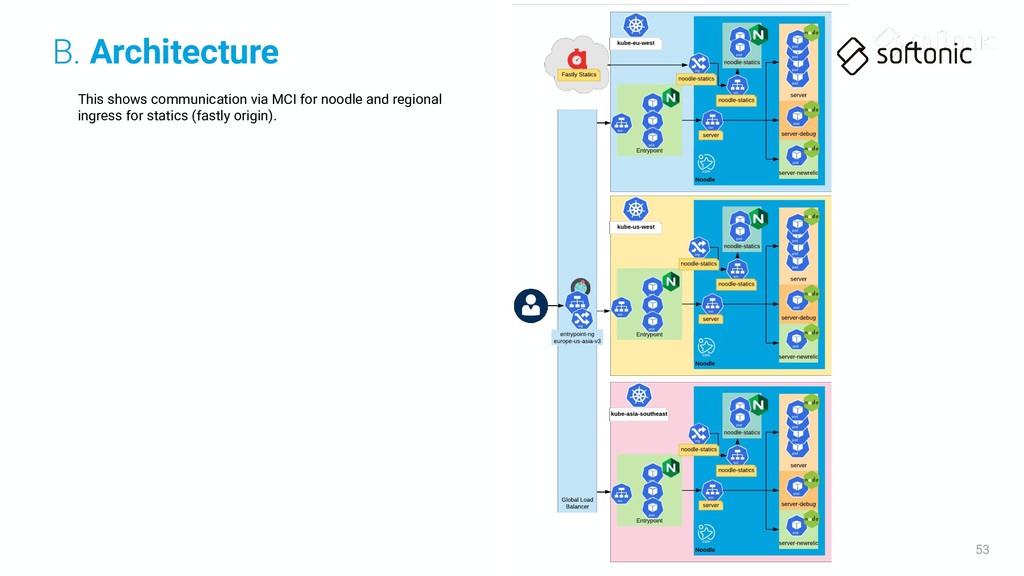
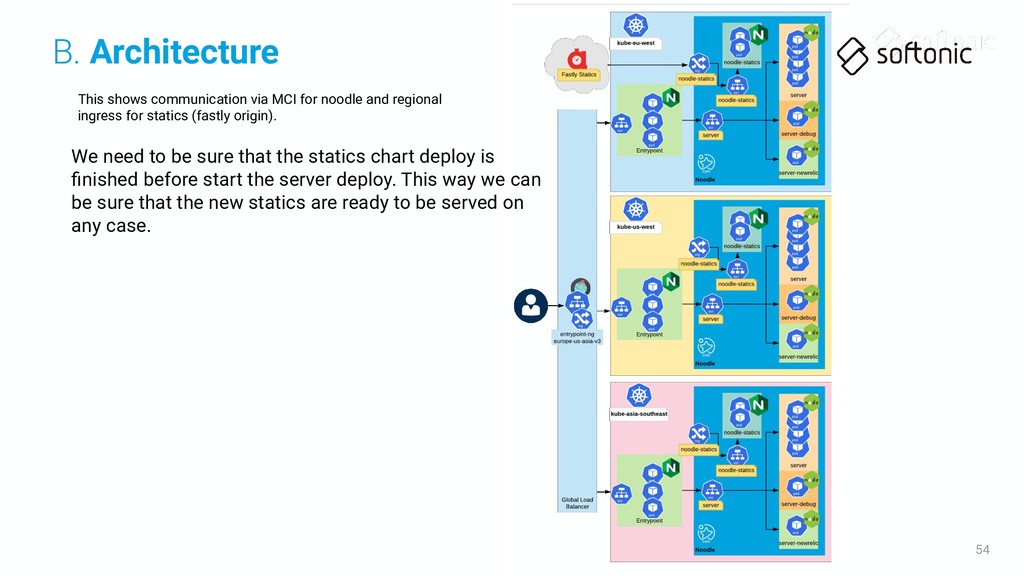
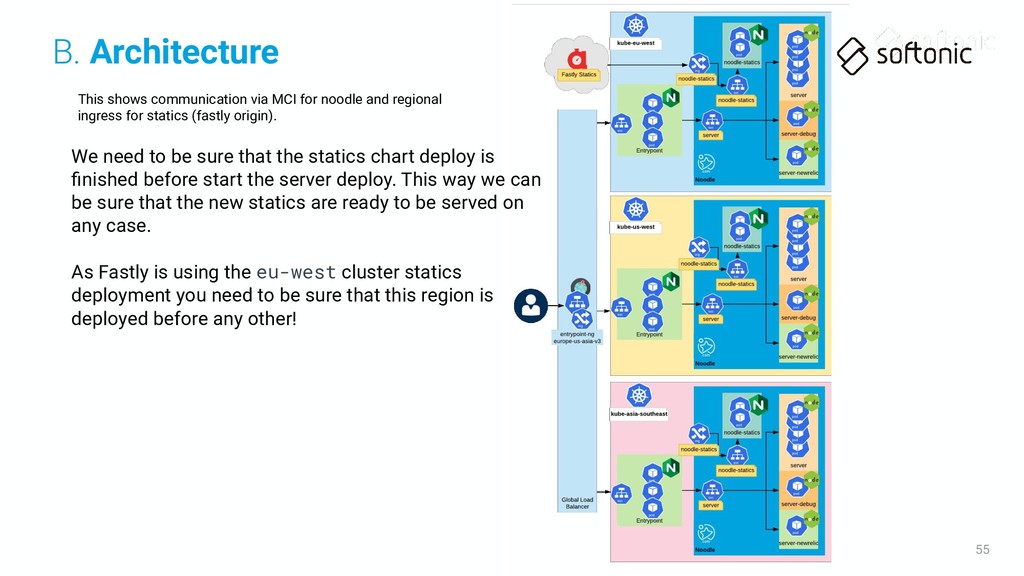
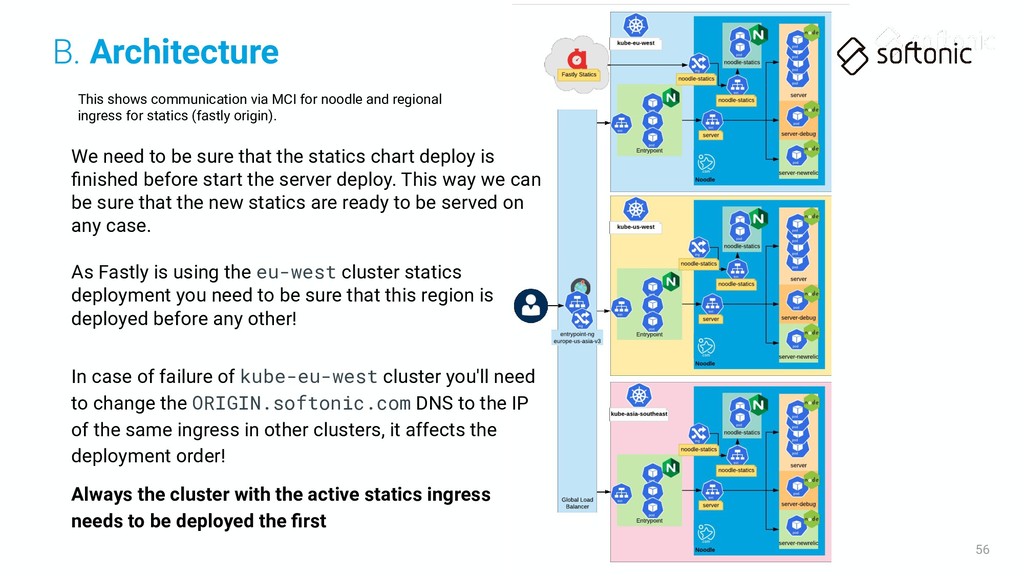
ingress for statics (fastly origin). We need to be sure that the statics chart deploy is finished before start the server deploy. This way we can be sure that the new statics are ready to be served on any case. B. Architecture
ingress for statics (fastly origin). We need to be sure that the statics chart deploy is finished before start the server deploy. This way we can be sure that the new statics are ready to be served on any case. As Fastly is using the eu-west cluster statics deployment you need to be sure that this region is deployed before any other! B. Architecture
ingress for statics (fastly origin). We need to be sure that the statics chart deploy is finished before start the server deploy. This way we can be sure that the new statics are ready to be served on any case. As Fastly is using the eu-west cluster statics deployment you need to be sure that this region is deployed before any other! In case of failure of kube-eu-west cluster you'll need to change the ORIGIN.softonic.com DNS to the IP of the same ingress in other clusters, it affects the deployment order! Always the cluster with the active statics ingress needs to be deployed the first B. Architecture
There are 2 different deploys per cluster: deployment and staticsDeployment 3. The staticsDeployment needs to be deployed first! And we need to be sure it's finished before start the noodle deploy 57 @Library('[email protected]') _ def project = [ name: "noodle", version: "unknown", icon: ":ramen:", deployUrl: "https://en.softonic.com" ] def staticsProject = [ name: "statics", version: "unknown", icon: ":ramen:", deployUrl: "https://en.softonic.com" ] ... B. Jenkinsfile
you can see something like this: helm secrets upgrade --install \ --namespace noodle-v1 \ noodle-statics \ helm/statics \ --set image.tag=1.1985.0 \ -f helm/statics/values.production.cluster-eu-west.yaml \ -f helm/statics/secrets.values.production.yaml --wait helm secrets upgrade --install \ --namespace noodle-v1 \ noodle \ helm/noodle \ --set image.server.tag=1.1985.0 \ -f helm/noodle/values.production.yaml \ -f helm/noodle/values.production.cluster-eu-west.yaml \ -f helm/noodle/secrets.values.production.yaml If you have permissions to decrypt the project secrets you could execute these commands from your shell in case of an emergency Pay attention to the --wait flag for statics, it waits until the deploy is finished before execute the next command
automatically use them as value files. In this example: • helm/noodle/values.yaml: Because Helm always loads this file • helm/noodle/values.production.yaml: Because the environment is production • helm/noodle/values.production.cluster-eu-west.yaml: Because the cluster to deploy is eu-west • helm/noodle/secrets.values.production.yaml: The same way as plain values files, in this case we don't need to override any secret value for an specific cluster, then the equivalent file for cluster-eu-west does not exist • Set values in --set flag: image.server.tag=1.1985.0 It merges each YAML file in this order, allowing you to redefine each value in the next files. B. Jenkinsfile: Deployment command
this application, use BLUE/GREEN deployment instead of Rolling Update. • It could allow us to avoid the 2-chart based deploy and save the “static” image but… as we are using a CDN that’s not simple. • And the Blue/green deployment is based in an Alpha feature provided by Argo Rollouts B. Bonus
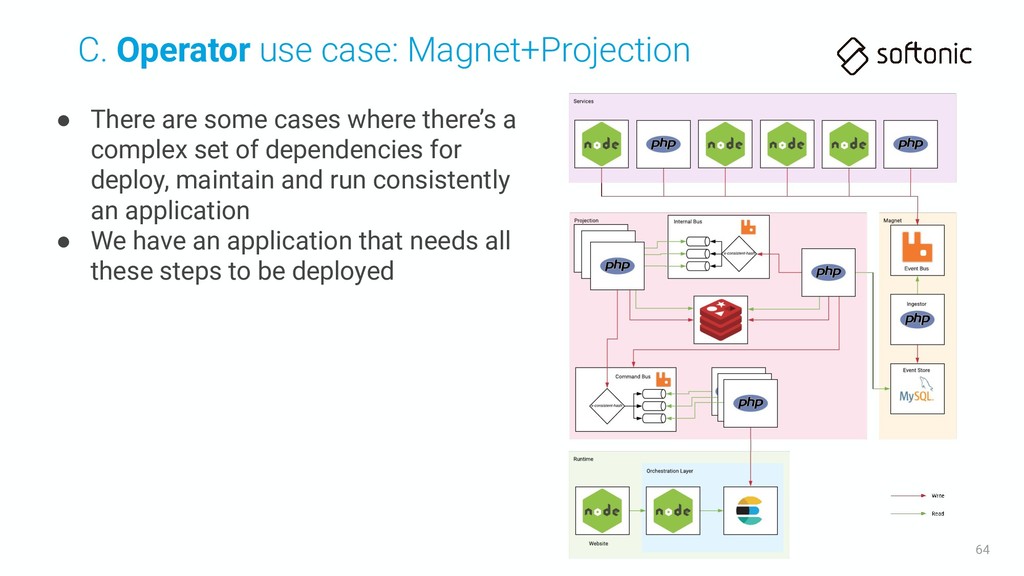
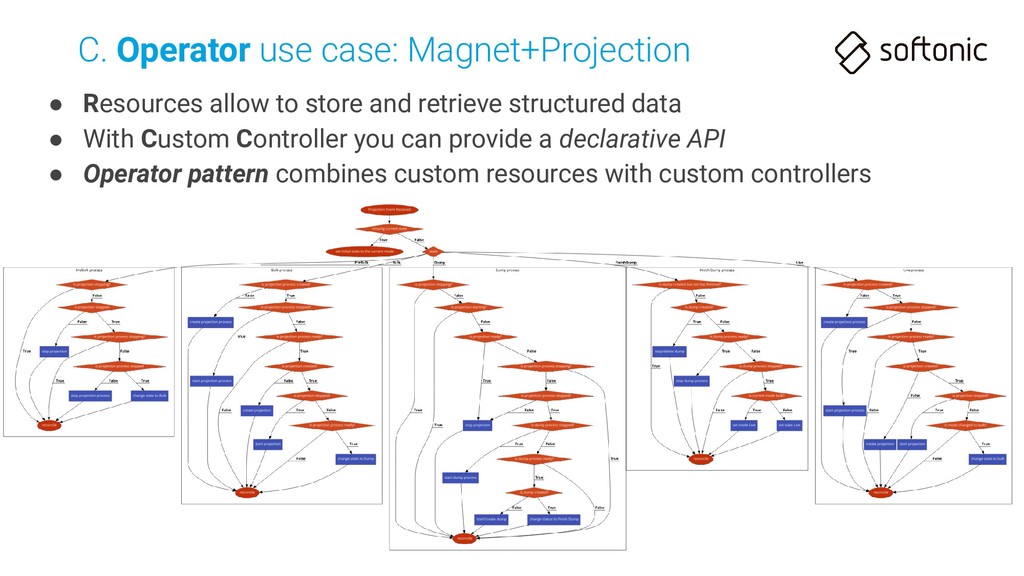
set of dependencies for deploy, maintain and run consistently an application • We have an application that needs all these steps to be deployed C. Operator use case: Magnet+Projection
set of dependencies for deploy, maintain and run consistently an application • We have an application that needs all these steps to be deployed C. Operator use case: Magnet+Projection
var to ensure the commands are launched to the right projection: version=23 1 - Ensure the environment variable GENERATE_PROJECTION=0 for appProjection and appProjectionProcess NOTE: you need to maintain it to 1 for appProjectionDump. 2 - Start processing messages scaling to 1 the appProjection consumer: kubectl --namespace apisoba-prj-${version} scale --replicas=1 statefulset.apps/apisoba-prj-${version}-projection-app-projection 3- Check all the messages have been processed and the queues are empty of messages: rabbit_user=nuokzqif rabbit_password=XXXXXXXX rabbit_host=<server endpoint> APISOBA_EVENTS_MSG=`rabbitmqadmin --username=$rabbit_user --password=$rabbit_password --host=$rabbit_host --ssl --port=443 --vhost=apisoba-${version} -f raw_json -d 3 list -S name queues name messages | jq -c '.[] | select(.name|test("apisoba-events."))' | jq -c .` while read i ; do MSG_COUNT=`echo $i | jq '.messages'` if [[ "$MSG_COUNT" -ne "0" ]]; then QUEUE=`echo $i | jq '.name'` echo "$QUEUE has still messages: $MSG_COUNT" false fi done <<< $APISOBA_EVENTS_MSG 4 - Once all the queues are empty, you need to scale down the appProjection for stop processing new incoming messages: kubectl --namespace apisoba-prj-${version} scale --replicas=0 statefulset.apps/apisoba-prj-${version}-projection-app-projection 5 - Now it's time to DUMP the REDIS view, for this you need to scale to one the "dump" process: dump_replicas=1 kubectl --namespace apisoba-prj-${version} scale --replicas=${dump_replicas} deployment.apps/apisoba-prj-${version}-projection-app-projection-dump 6 - But this still is not enough, this would process the programs 1 by one, but before doing it you need to know what these programs are, this is done executing the next commands: dump_pod=$(kubectl --namespace apisoba-prj-${version} get pods -l component=app-projection-dump -o=custom-columns=NAME:.metadata.name | grep -v NAME | head -n1) kubectl --namespace apisoba-prj-${version} exec -it "${dump_pod}" /docker-php-entrypoint php ./bin/refreshApplicationProjection.php ./config/container.php
queues are empty, it could take some time, you can disable the "BULK MODE" and go to "LIVE MODE". 1 - Ensure the message ratio for the apisoba-events-* queues are low. rabbit_user=nuokzqif rabbit_password=XXXXXXXX rabbit_host=<server endpoint> rabbitmqadmin --username=$rabbit_user --password=$rabbit_password --host=$rabbit_host --ssl --port=443 --vhost=apisoba-${version} -f raw_json -d 3 list -S name queues name messages | jq -c '.[] | select(.name|test("apisoba-events."))' | jq -c . 2 - Scale down to 0 the projector process, it's work has finished! kubectl --namespace apisoba-prj-${version} scale --replicas=0 deployment.apps/apisoba-prj-projection-${version}-app-projection-dump 3 - Reduce projection resources, live mode does not need so much resources rabbit_user=nuokzqif rabbit_password=XXXXXXXX rabbit_host=<server endpoint> kubectl --namespace apisoba-prj-${version} scale --replicas=1 statefulset.apps/apisoba-prj-${version}-projection-app-projection-process for i in {1..99}; do \ kubectl --namespace apisoba-prj-${version} delete pod/apisoba-prj-${version}-projection-app-projection-process-$i rabbitmqadmin --host=$rabbit_host --port=443 --ssl \ --username=$rabbit_user --password=$rabbit_password --vhost=apisoba-${version} delete queue name=apisoba-events-$i; \ Done # CHANGE CONTEXT TO regional cluster! -> kctx EUROPE, USA or ASIA kctx EUROPE region=eu-west rabbit_host=<server endpoint> kubectl --namespace apisoba-prj-v${version} scale --replicas=1 statefulset.apps/apisoba-prj-persistence-v${version}-projection-pers-upserte for i in {1..9}; do \ kubectl --namespace apisoba-prj-v${version} delete pod/apisoba-prj-persistence-v${version}-projection-pers-upserte-$i; \ rabbitmqadmin --host=$rabbit_host --port=443 --ssl \ --username=$rabbit_user --password=$rabbit_password --vhost=apisoba-${version} delete queue name=apisoba-cmd-$region-$i; \ done C. Operator use case: Magnet+Projection
USA or ASIA kctx USA region=us-west rabbit_host=<server endpoint> kubectl --namespace apisoba-prj-v${version} scale --replicas=1 statefulset.apps/apisoba-prj-persistence-v${version}-projection-pers-upserte for i in {1..9}; do \ kubectl --namespace apisoba-prj-v${version} delete pod/apisoba-prj-persistence-v${version}-projection-pers-upserte-$i; \ rabbitmqadmin --host=$rabbit_host --port=443 --ssl \ --username=$rabbit_user --password=$rabbit_password --vhost=apisoba-${version} delete queue name=apisoba-cmd-$region-$i; \ done # CHANGE CONTEXT TO regional cluster! -> kctx EUROPE, USA or ASIA kctx ASIA region=asia-southeast rabbit_host=<server endpoint> kubectl --namespace apisoba-prj-v${version} scale --replicas=1 statefulset.apps/apisoba-prj-persistence-v${version}-projection-pers-upserte for i in {1..9}; do \ kubectl --namespace apisoba-prj-v${version} delete pod/apisoba-prj-persistence-v${version}-projection-pers-upserte-$i; \ rabbitmqadmin --host=$rabbit_host --port=443 --ssl \ --username=$rabbit_user --password=$rabbit_password --vhost=apisoba-${version} delete queue name=apisoba-cmd-$region-$i; \ done # Go back to EUROPE to continue process kctx EUROPE 4 - GENERATE_PROJECTION: 1 for appProjection and appProjectionProcess kubectl edit statefulset.apps/apisoba-prj-v${version}-projection-app-projection ... kubectl edit statefulset.apps/apisoba-prj-v${version}-projection-app-projection-process ... 5 - Scale up appProjection for moving the processing to LIVE: kubectl --namespace apisoba-prj-v${version} scale --replicas=1 statefulset.apps/apisoba-prj-v${version}-projection-app-projection C. Operator use case: Magnet+Projection
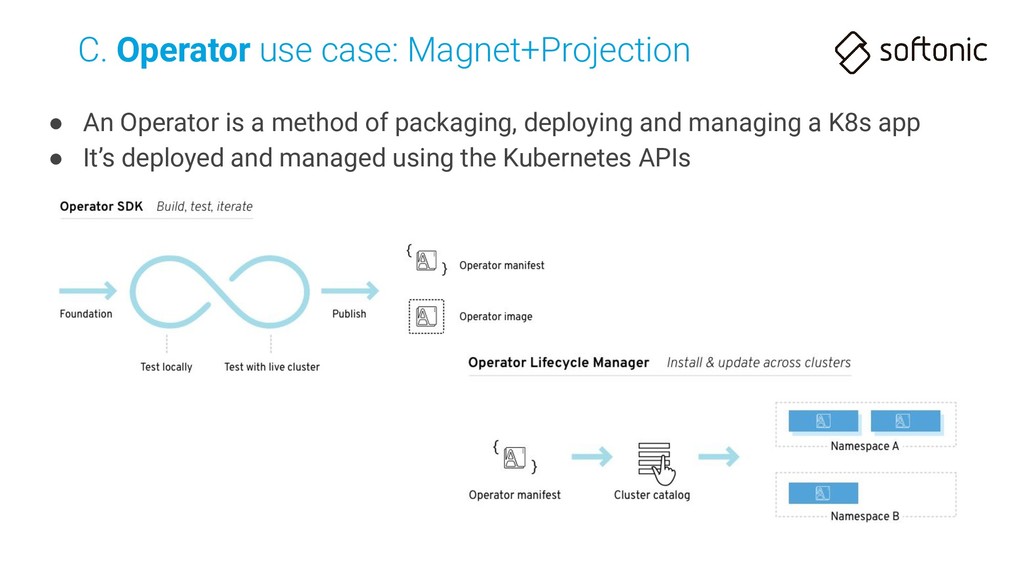
With Custom Controller you can provide a declarative API • Operator pattern combines custom resources with custom controllers C. Operator use case: Magnet+Projection
With Custom Controller you can provide a declarative API • Operator pattern combines custom resources with custom controllers C. Operator use case: Magnet+Projection
volatile-atlas-at-1802 volatile-cpi-cms-dsk-000 volatile-xxx-dsk-1461 volatile-xxx-fhp-131 volatile-xxx-fhp-229 volatile-xxx-fhp-77 volatile-noodle-bb-879 volatile-noodle-bb-939 volatile-noodle-bb-956 volatile-noodle-bb-957 volatile-noodle-bb-958 volatile-noodle-bb-966 volatile-noodle-bb-972 volatile-noodle-cat-1010 volatile-noodle-cat-1224 volatile-noodle-cat-861 volatile-noodle-dsk-1157 volatile-noodle-dsk-1386 volatile-noodle-dsk-1413 volatile-noodle-dsk-1446 volatile-noodle-dsk-1457 volatile-noodle-fhp-98 volatile-noodle-soal-978 volatile-noodle-tech-646 volatile-noodle-tech-678 volatile-noodle-tech-684 • 27 running right now • More info about them: ◦ The name is obtained from the GIT branch name ◦ The branch name is generated from the JIRA task name ◦ When the branch is merged/removed the volatile environment is deleted
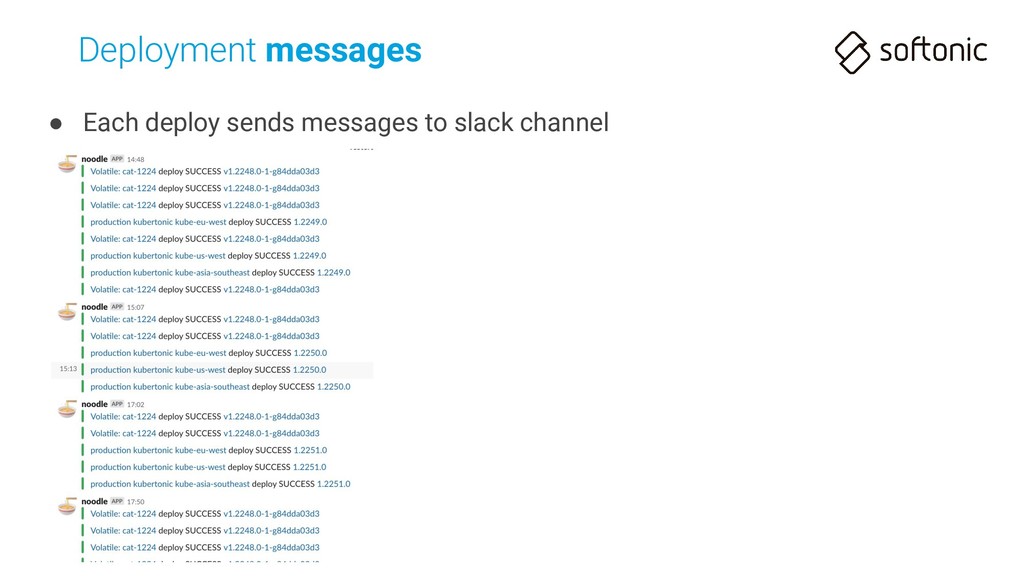
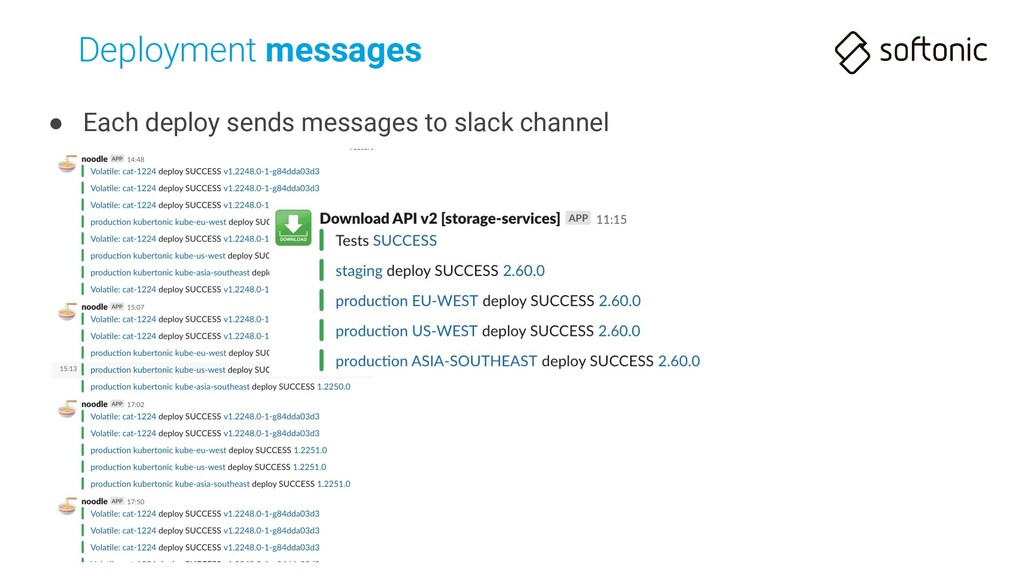
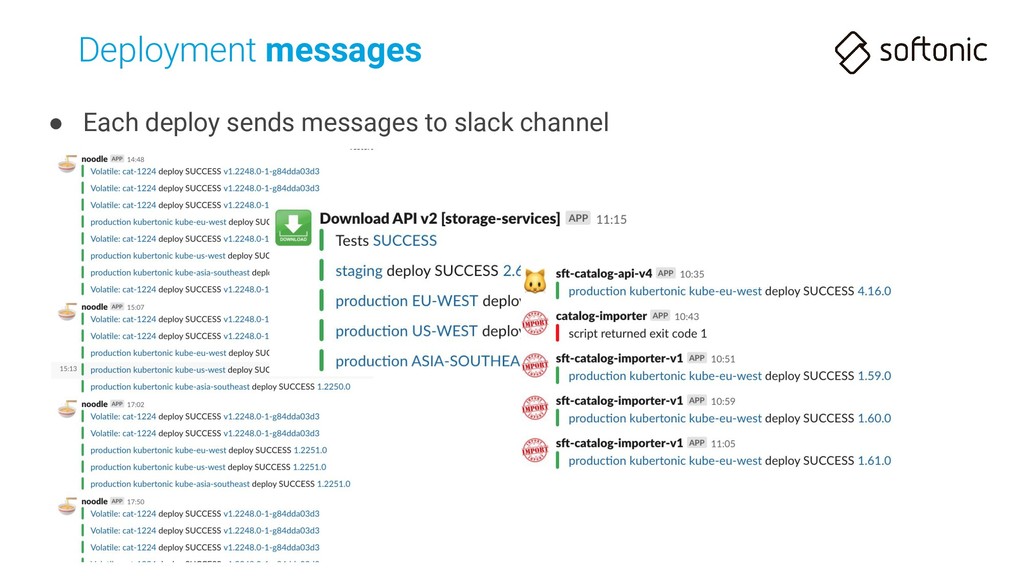
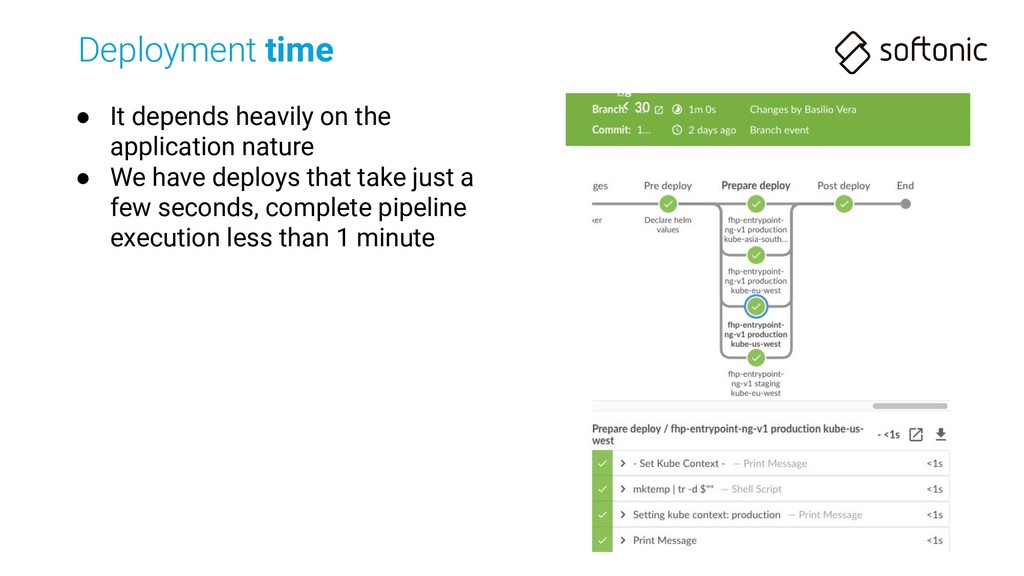
npm downloads the Internet • Deploy command (2-step deploy) can take 1 minute each • Deploy already finished (all Pods updated) after some more minutes!
npm downloads the Internet • Deploy command (2-step deploy) can take 1 minute each • Deploy already finished (all Pods updated) after some more minutes!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}