While Lucene is known as a full text search library, there is much more functionality under the hood, including lots of different data structures. Performance is a core focus as well. In this talk we will dive deeper into performance, how latest JDKs and the operating system help and how Lucene stays fast by trying to skip as much data as possible when querying.
Full of code snippets to follow along!
Check out the code snippets in this GitHub repo: https://github.com/spinscale/understanding-lucene
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
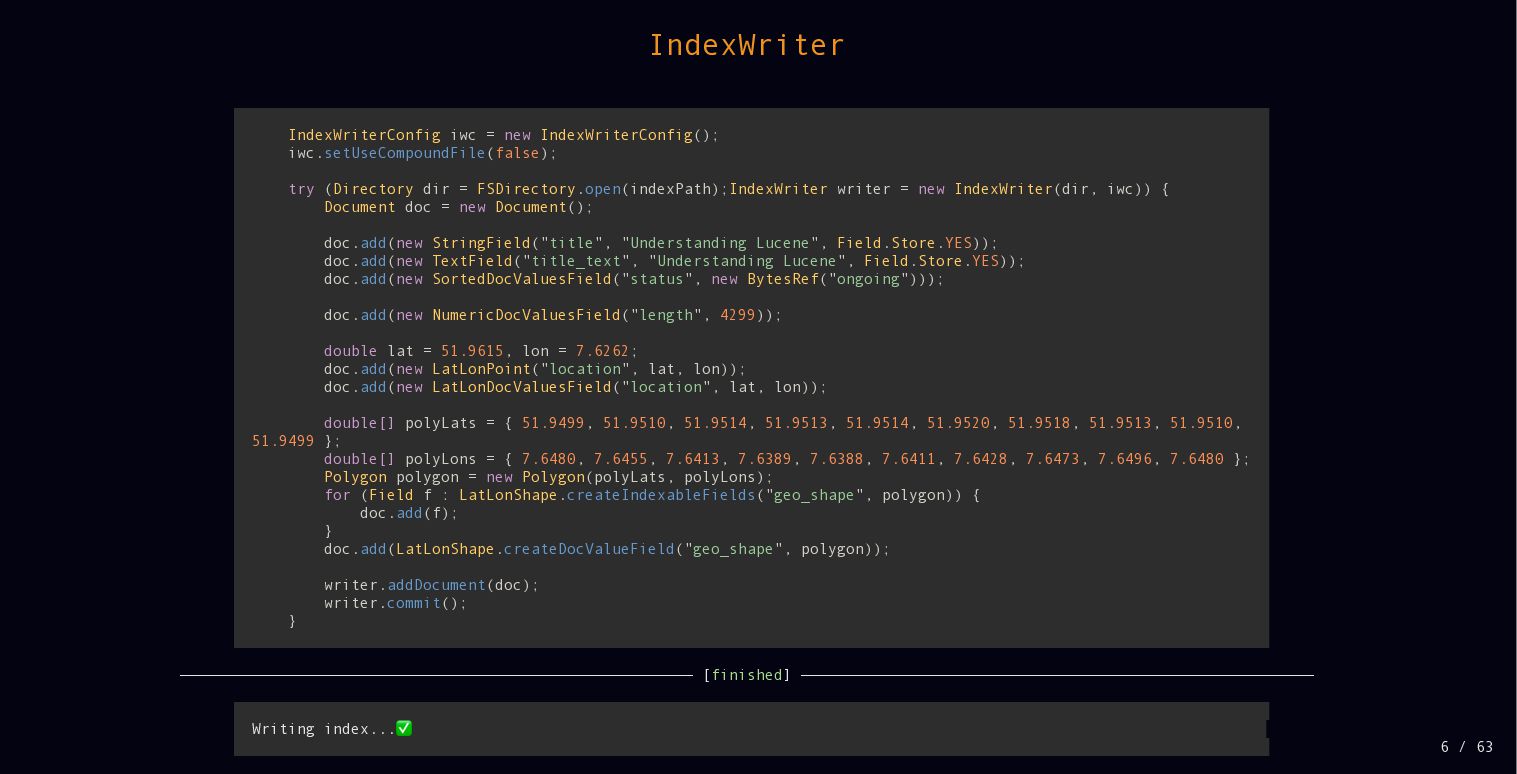
![IndexWriter lsd -1l --size=short --date=relative --color=always /tmp/lucene/001-index-writer ———————————————————————————————————— [finished] —————————————————————————————————————](https://files.speakerdeck.com/presentations/cbda796b84114b51808ffd8e6f6cdf35/slide_6.jpg){kind=link}
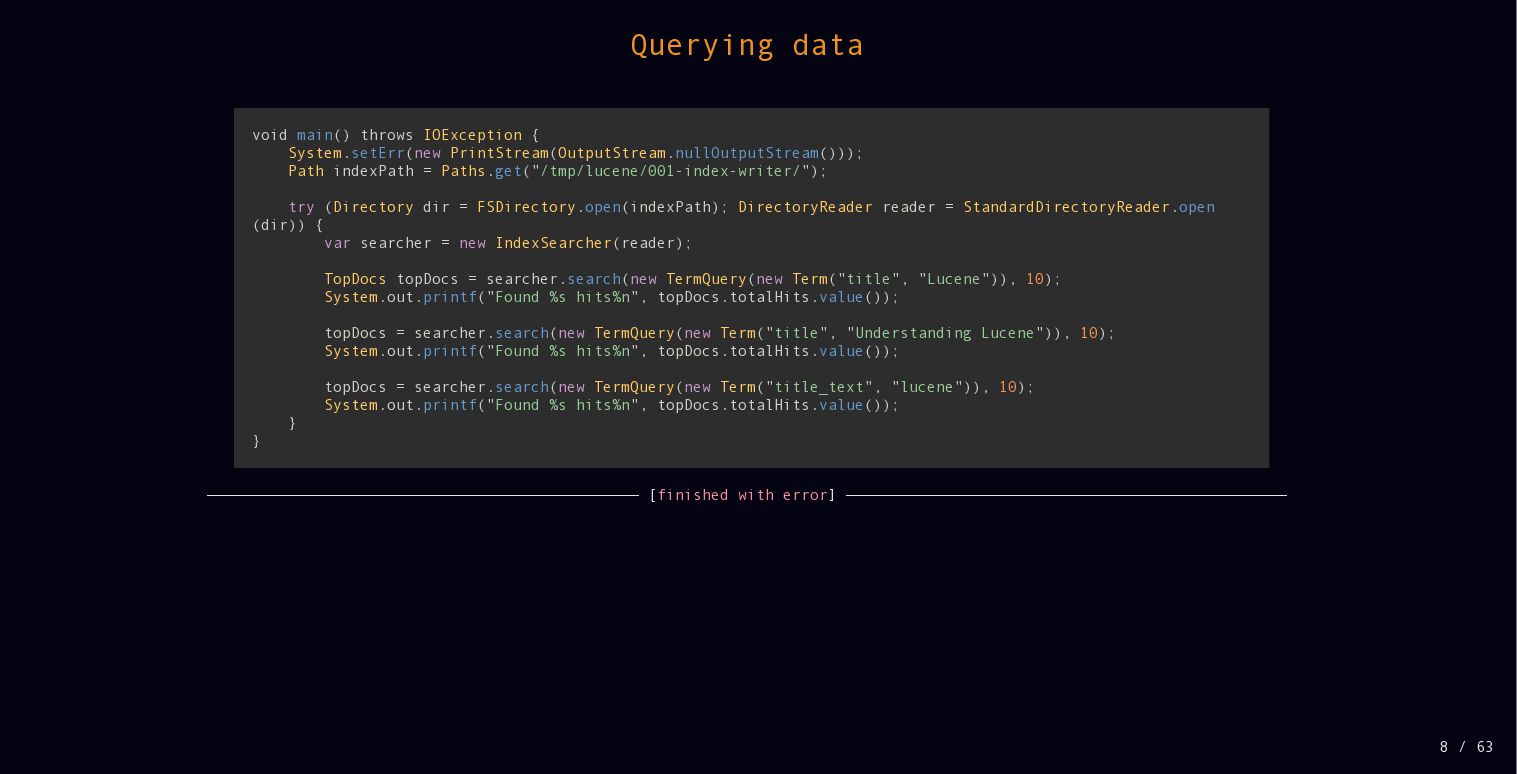{kind=link}
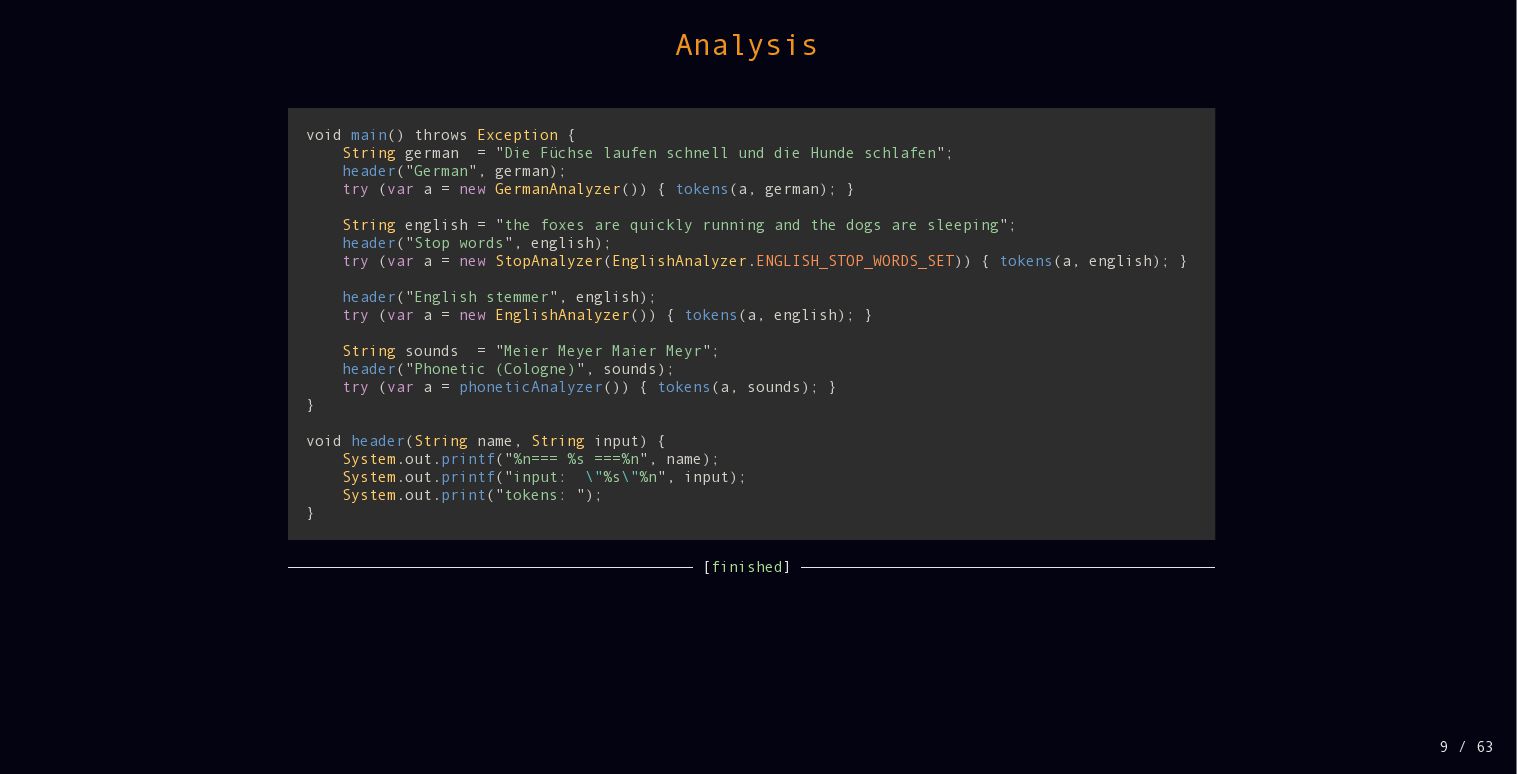{kind=link}
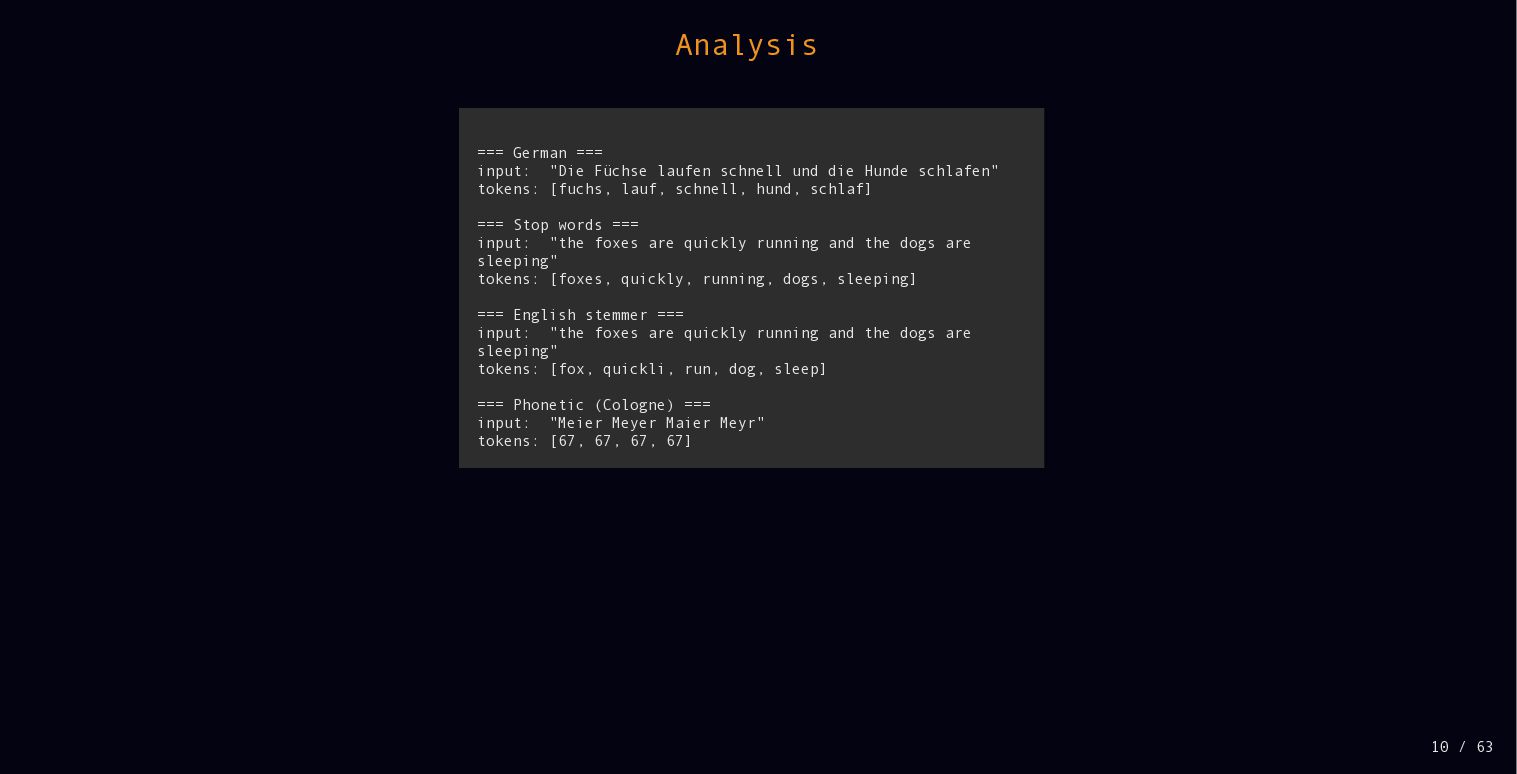{kind=link}
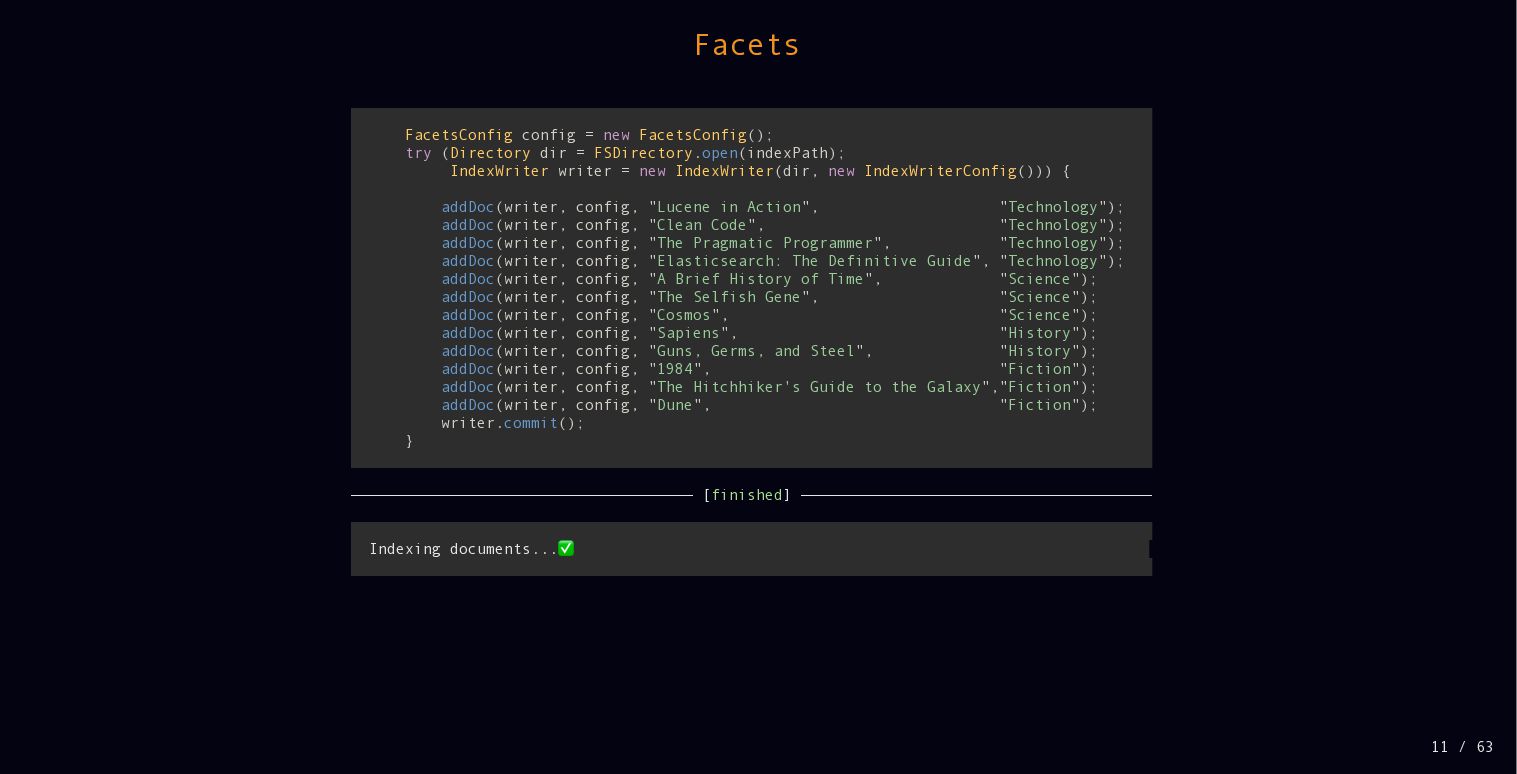{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TextCodec lsd -1l --size=short --date=relative --color=always /tmp/lucene/003-codec-example/ ————————————————————————————————————— [finished] ——————————————————————————————————————](https://files.speakerdeck.com/presentations/cbda796b84114b51808ffd8e6f6cdf35/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
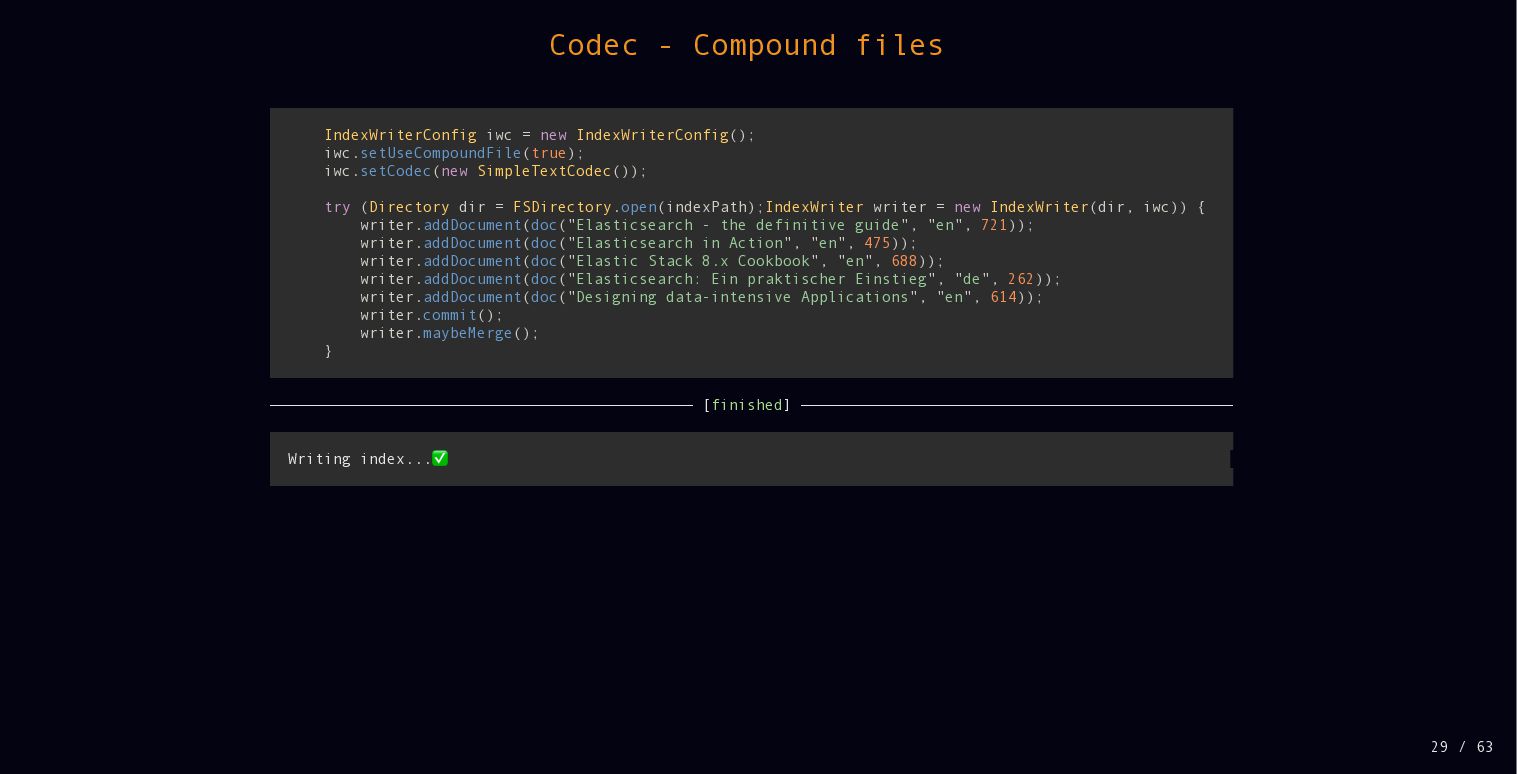{kind=link}
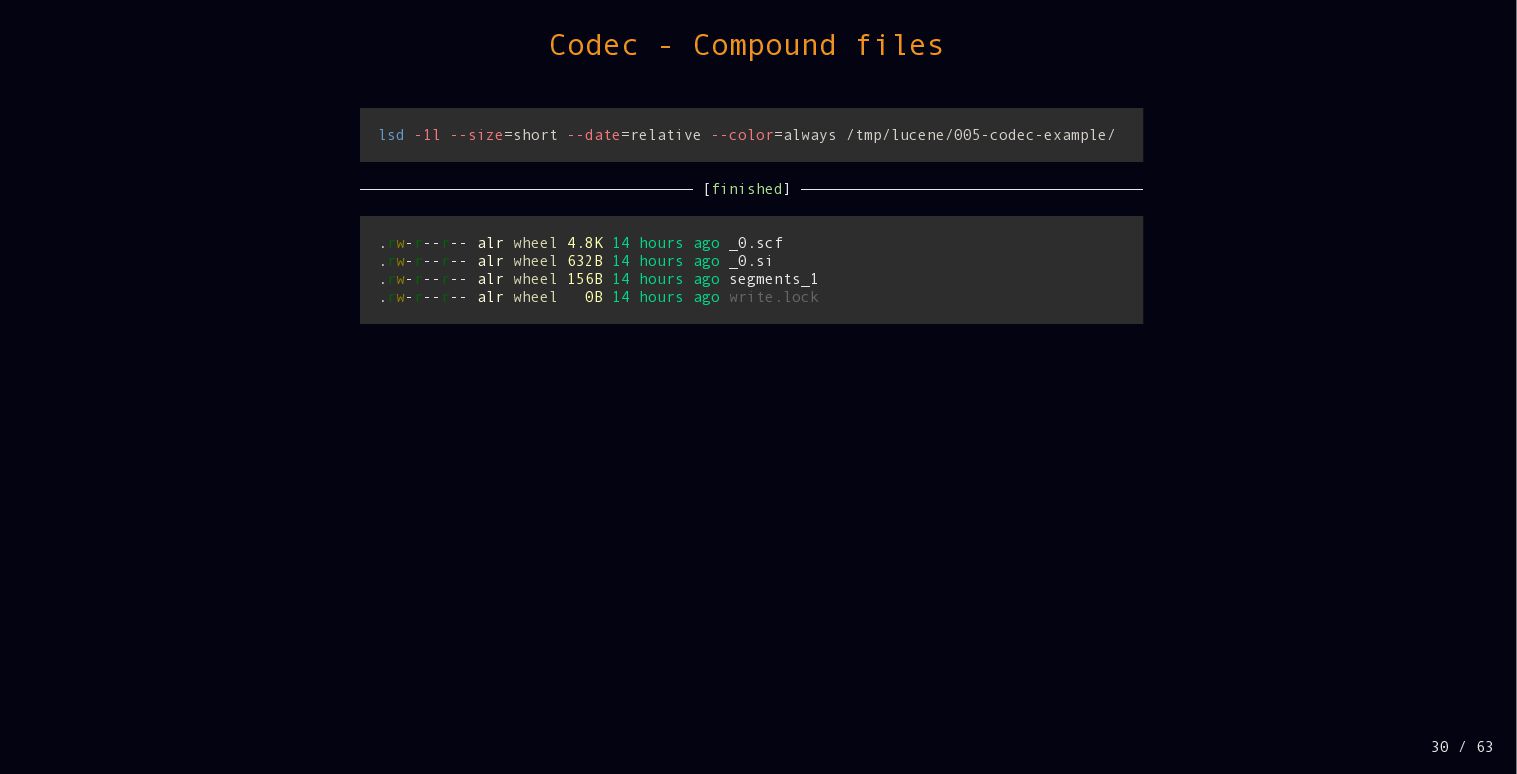{kind=link}
{kind=link}
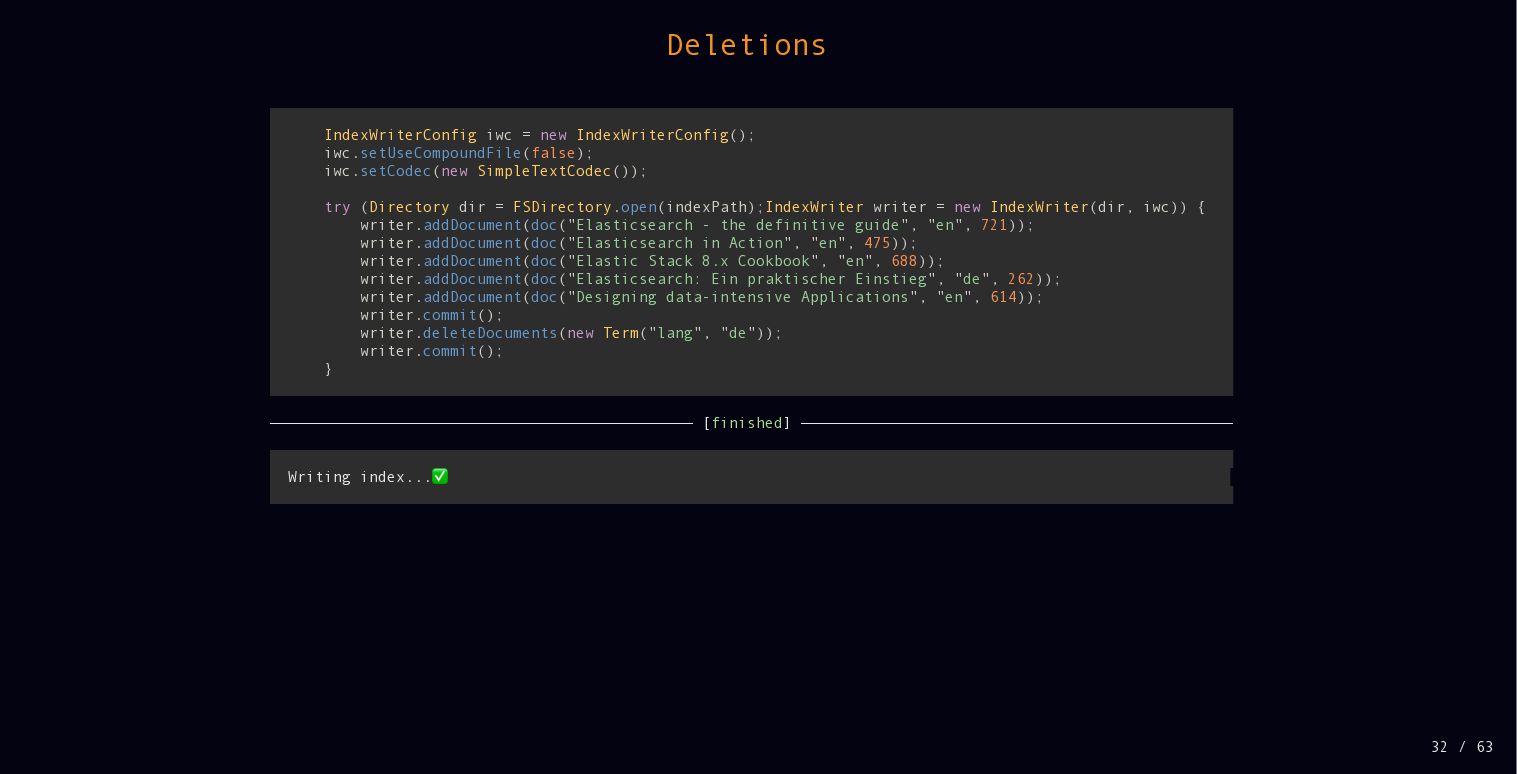{kind=link}
![Deletions cat /tmp/lucene/004-deletions/_0_1.liv ——————————————————— [finished] ——————————————————— size 5 doc 0](https://files.speakerdeck.com/presentations/cbda796b84114b51808ffd8e6f6cdf35/slide_32.jpg){kind=link}
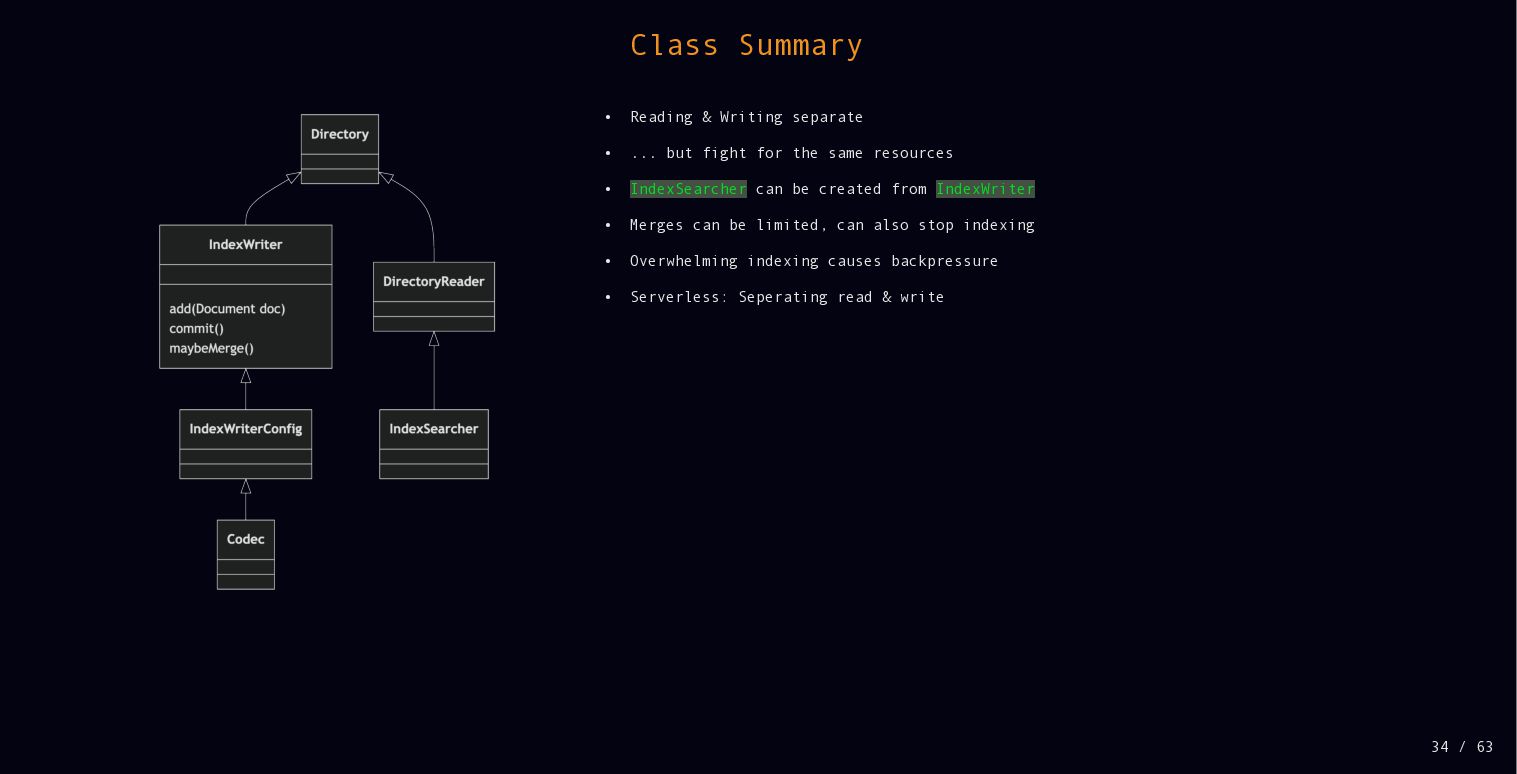{kind=link}
{kind=link}
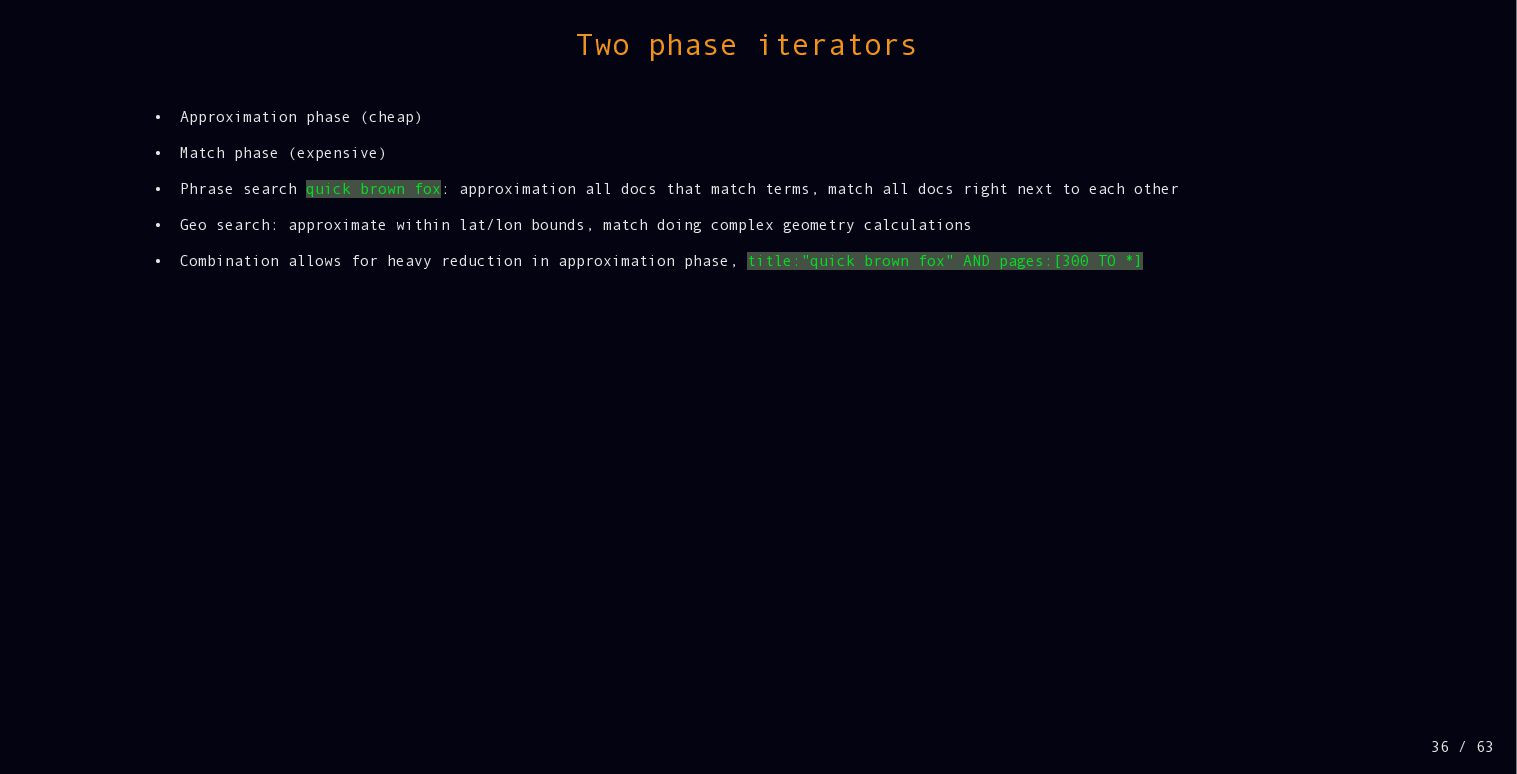{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
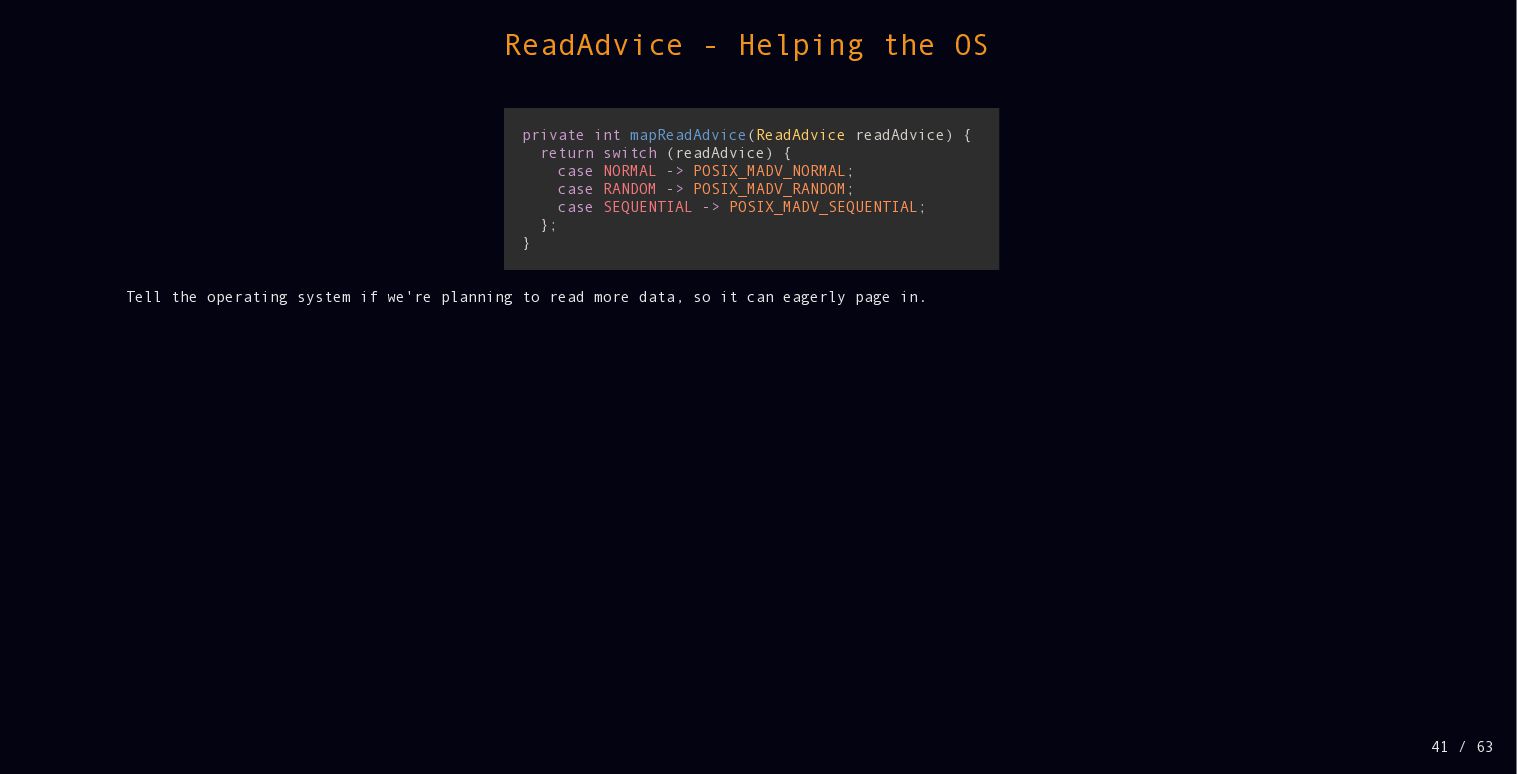{kind=link}
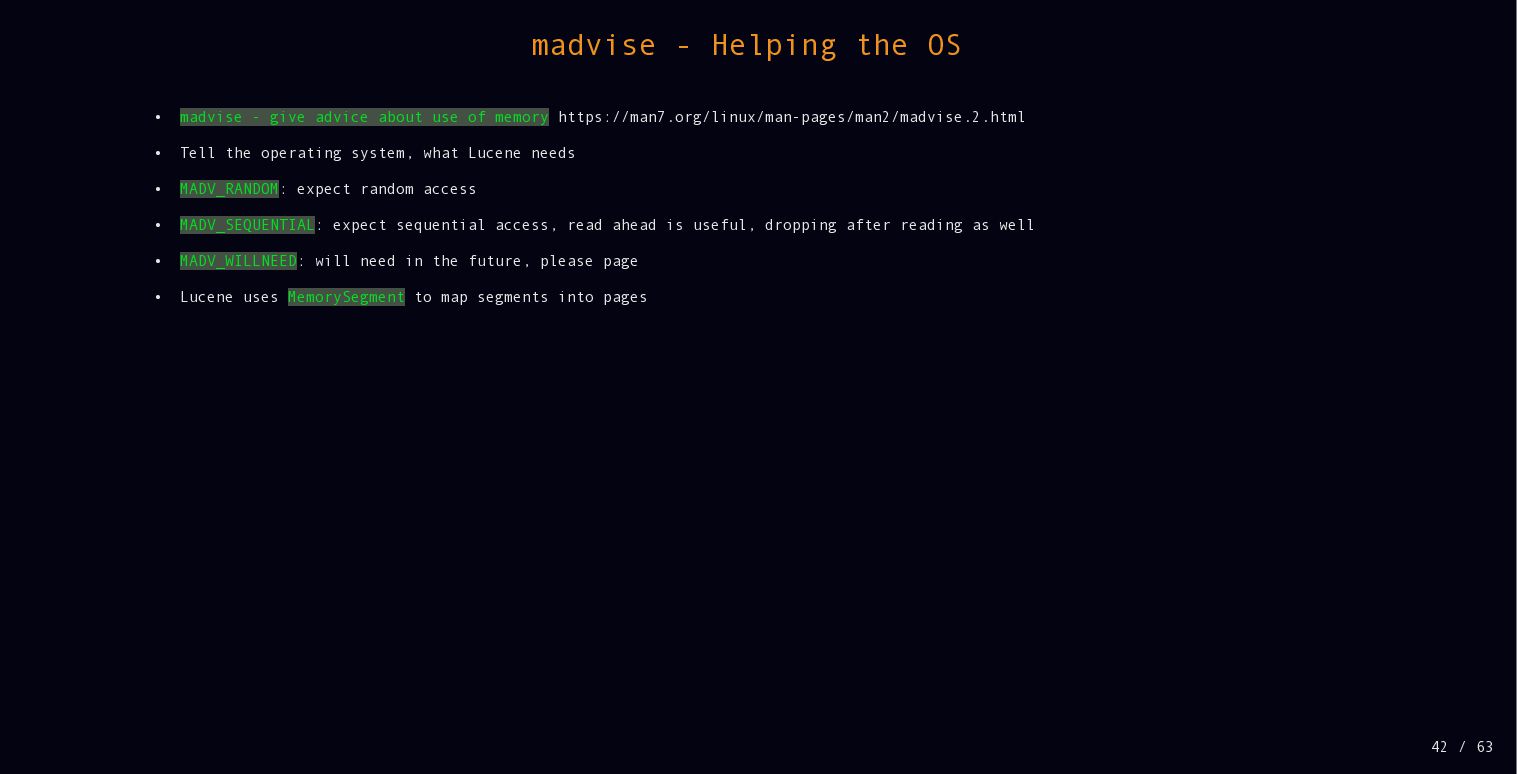{kind=link}
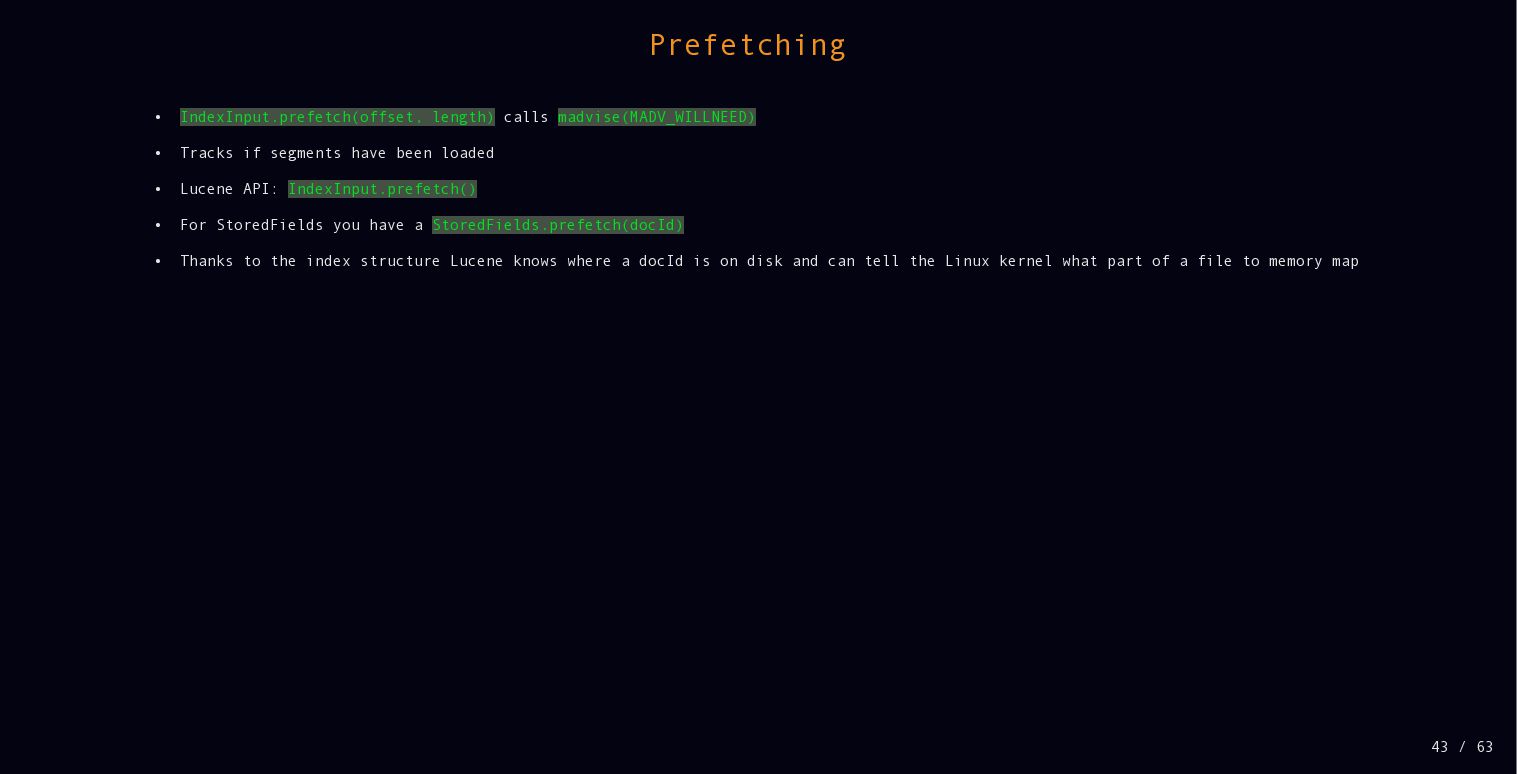{kind=link}
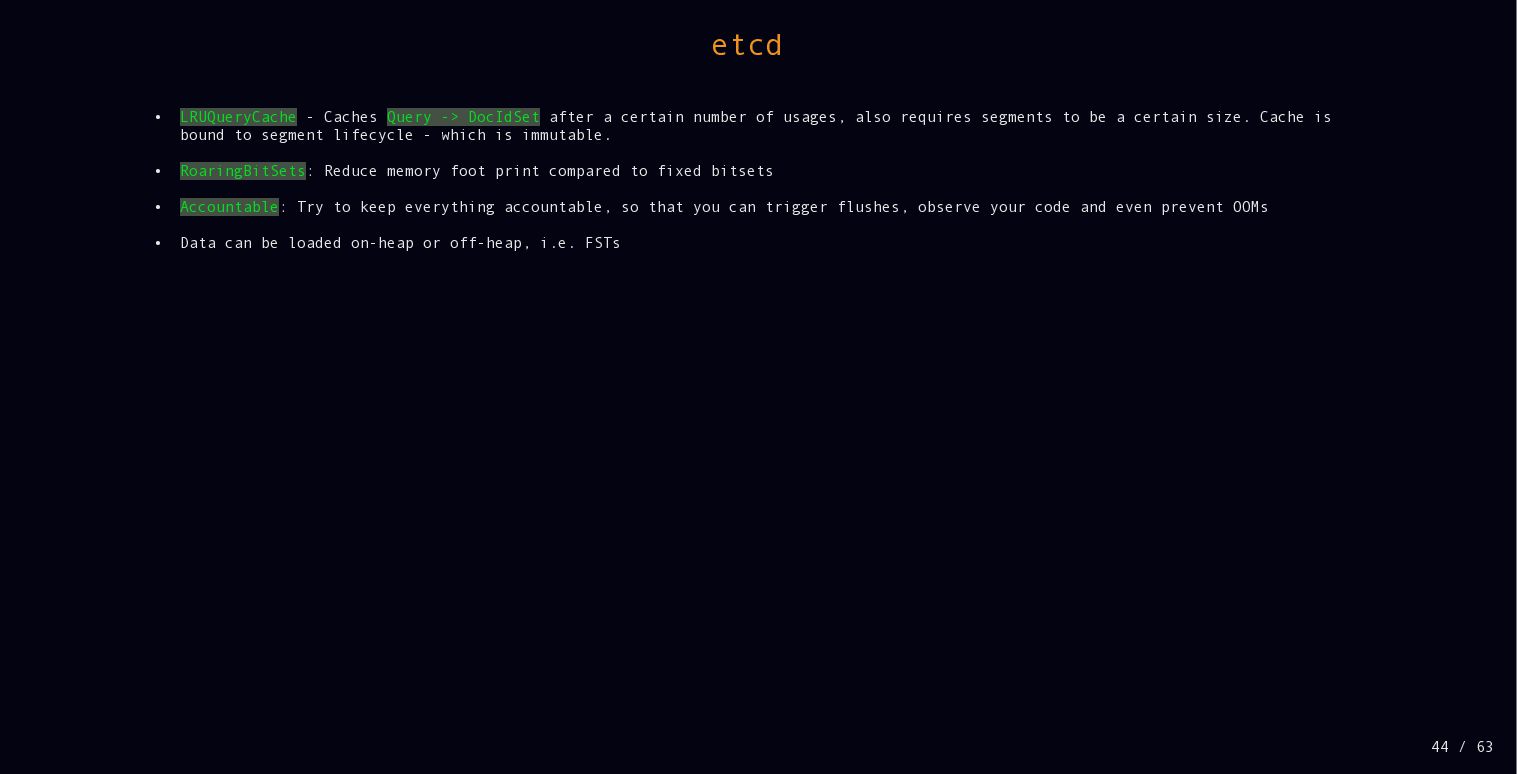{kind=link}
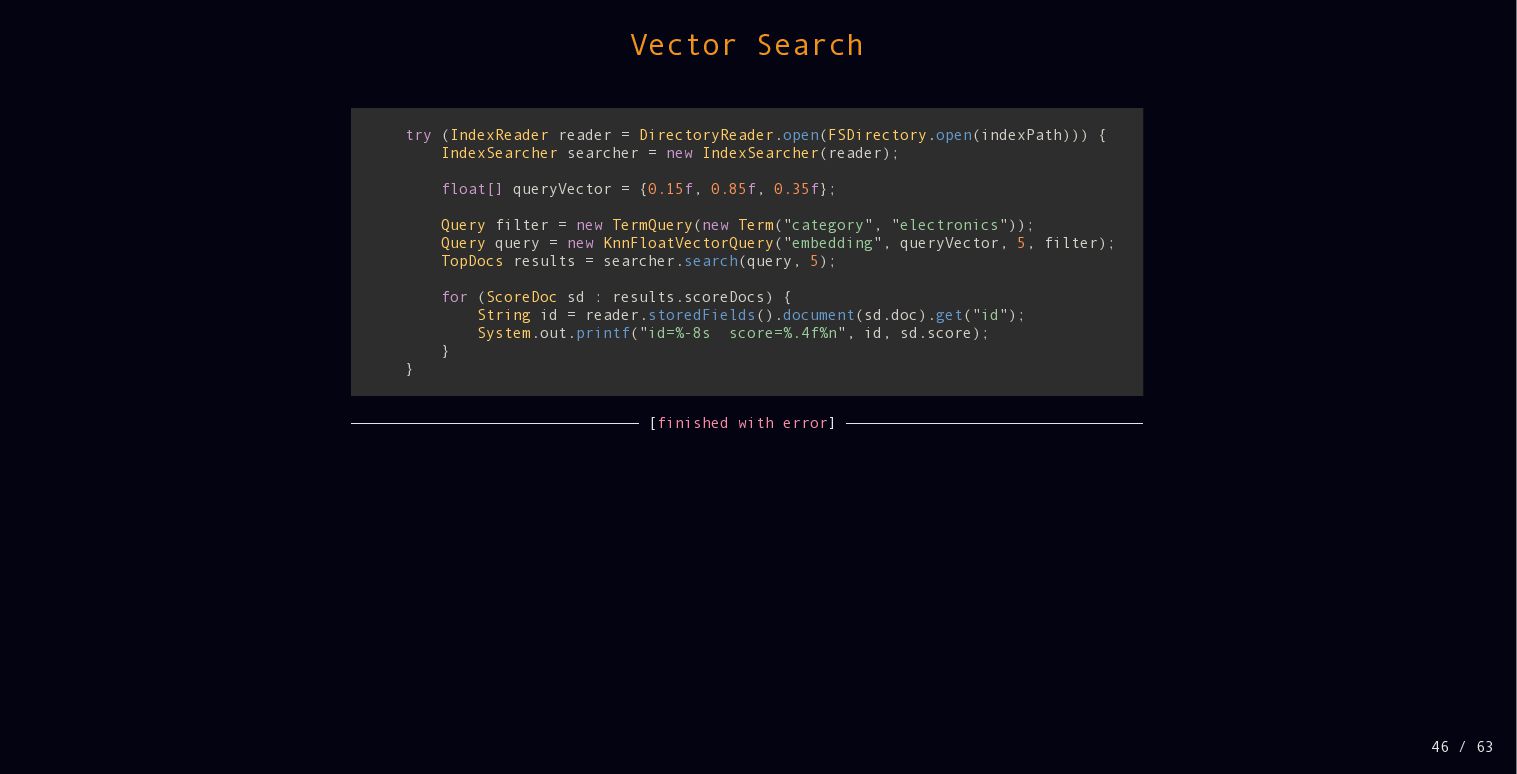
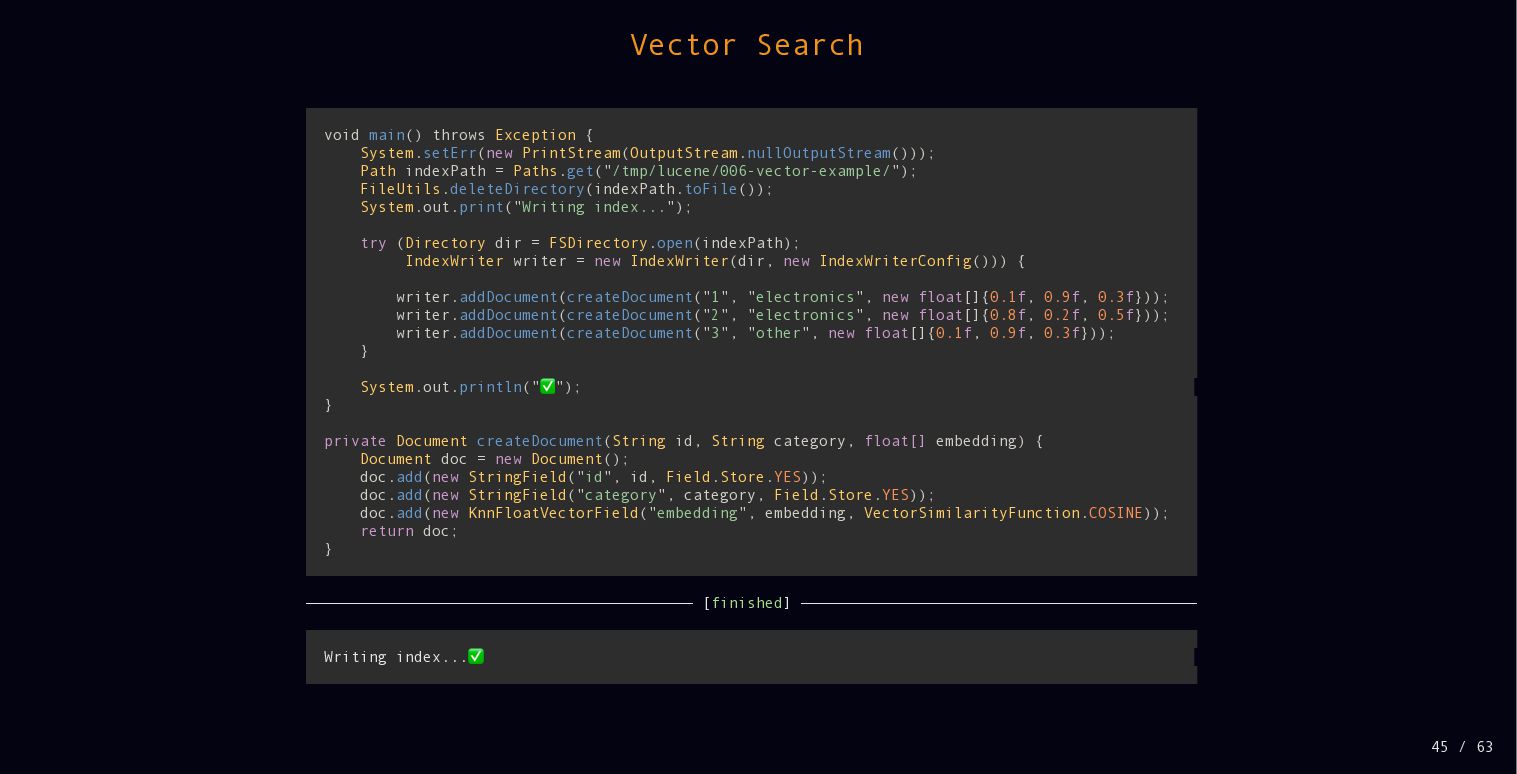{kind=link}
{kind=link}
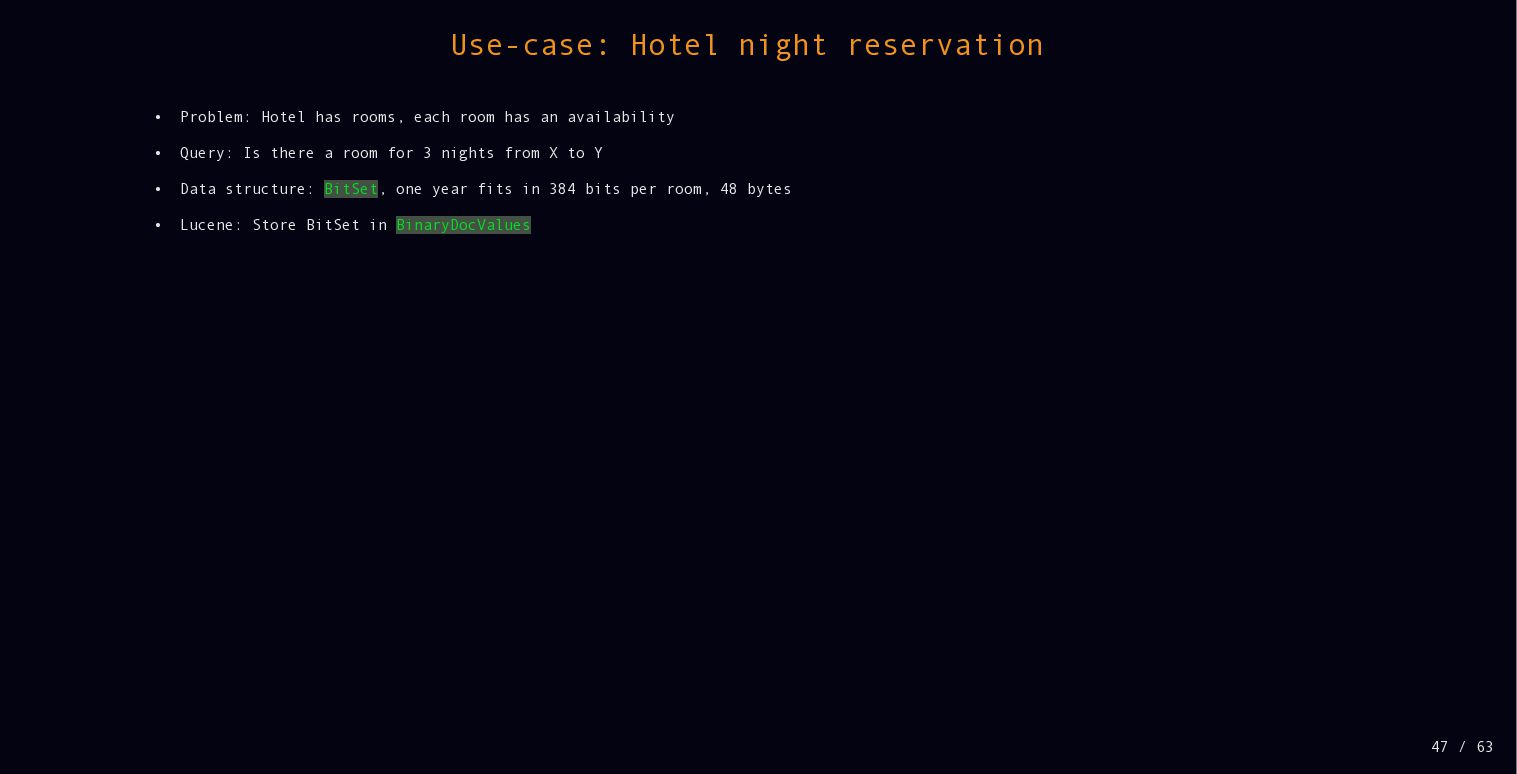{kind=link}
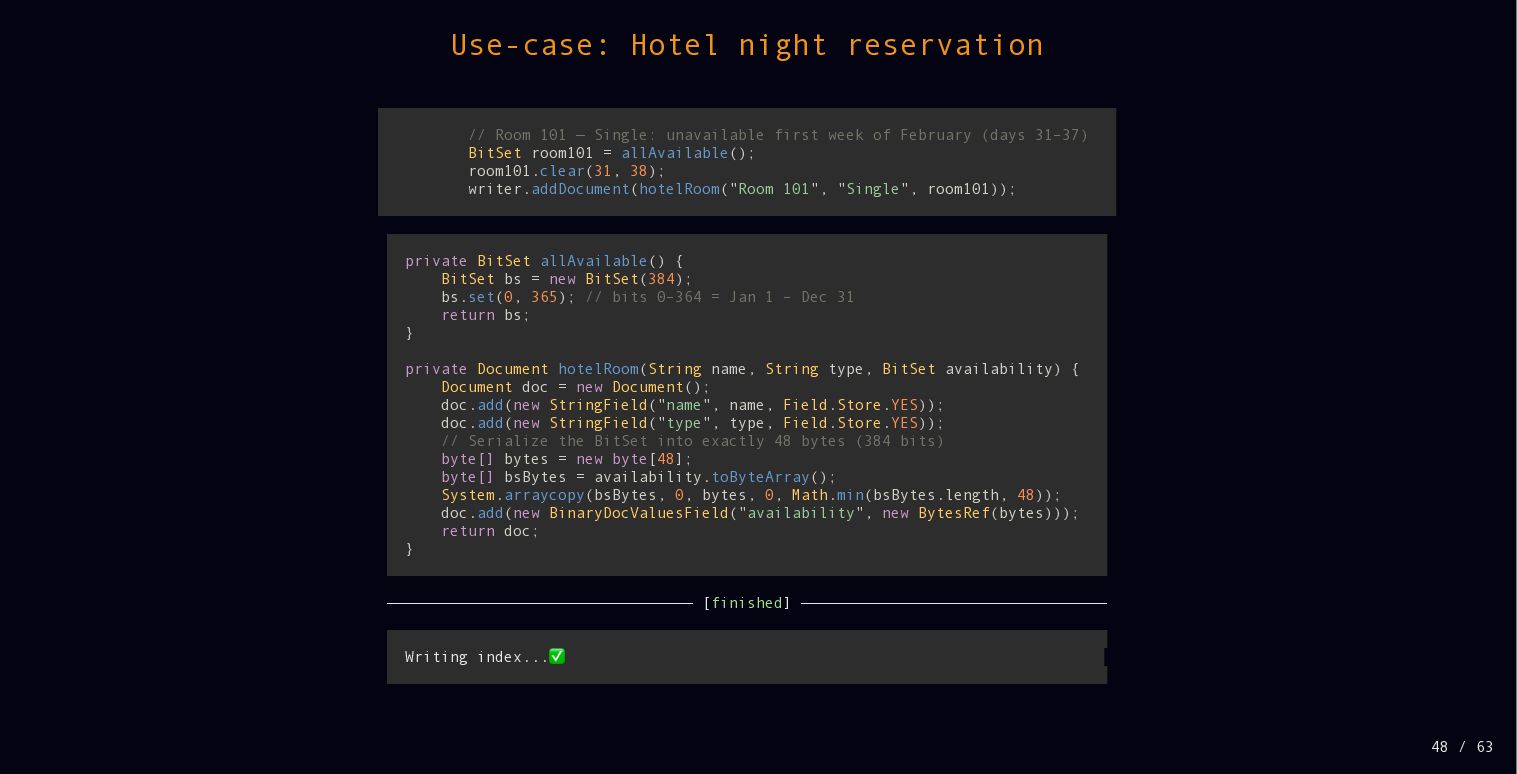{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
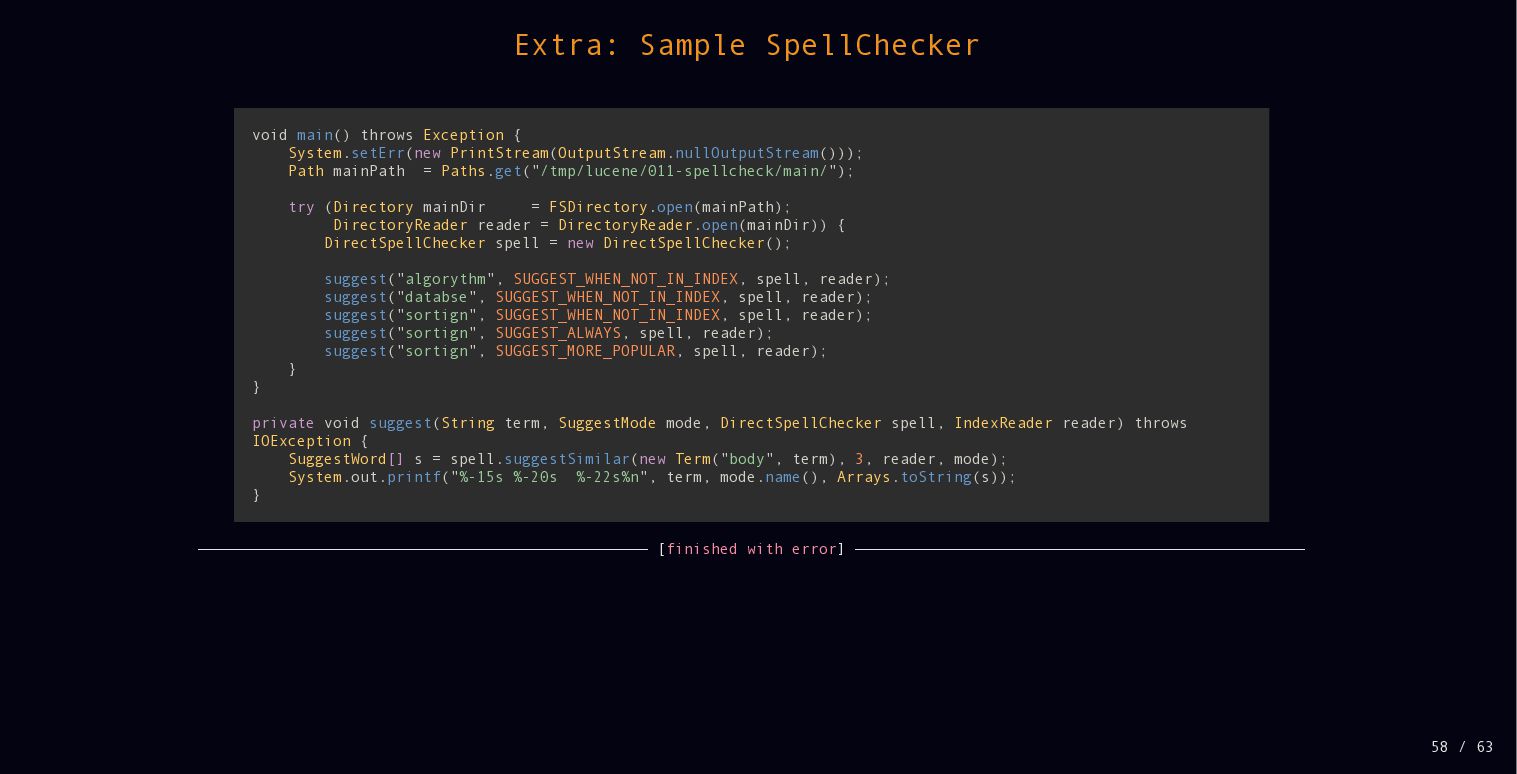{kind=link}
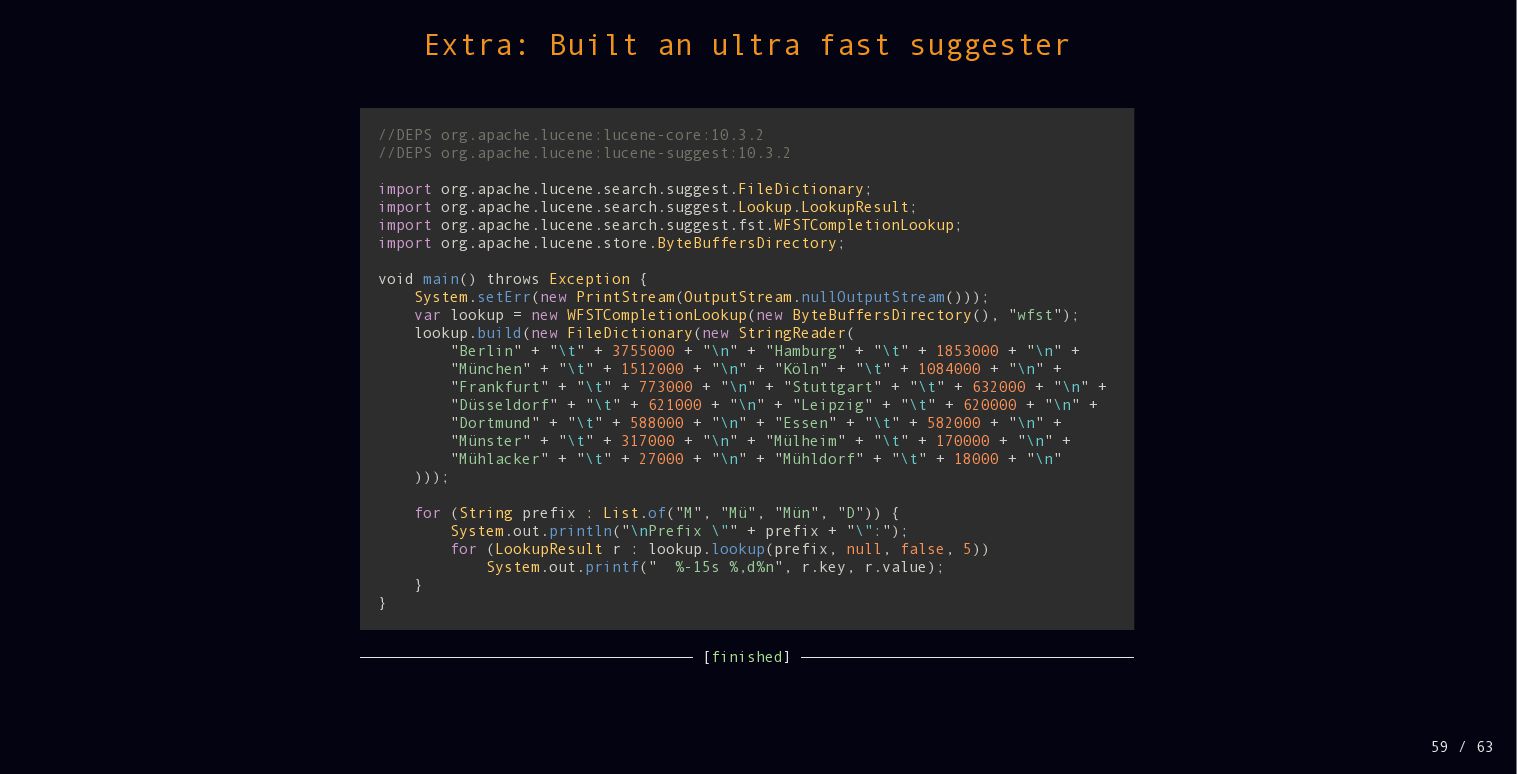{kind=link}
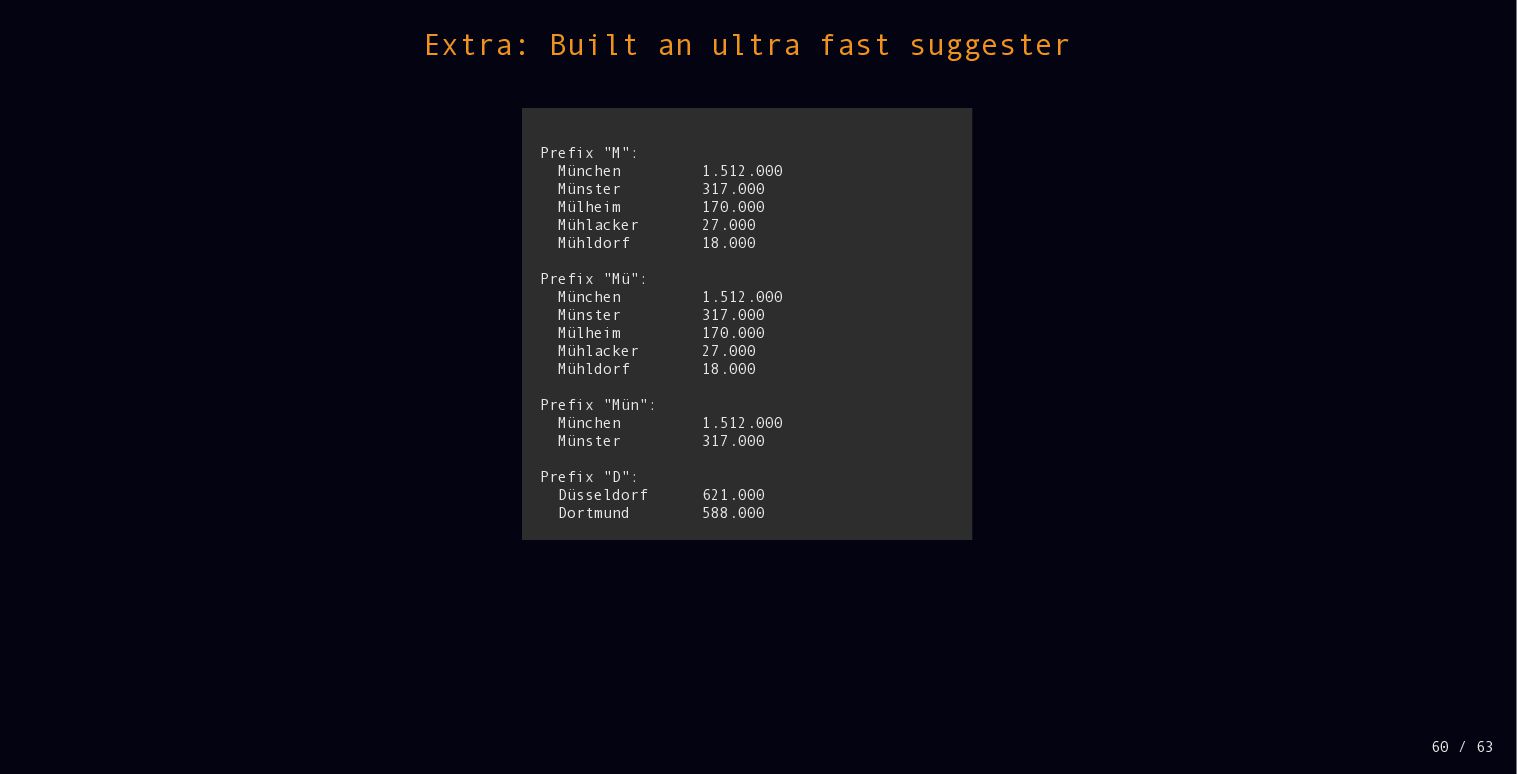{kind=link}
{kind=link}
{kind=link}
![Discussion ██ Questions? Answers? ▓▓▓ mailto:[email protected] ▓▓▓ web:spinscale.de ▓▓▓ mastodon:@[email protected]](https://files.speakerdeck.com/presentations/cbda796b84114b51808ffd8e6f6cdf35/slide_62.jpg){kind=link}