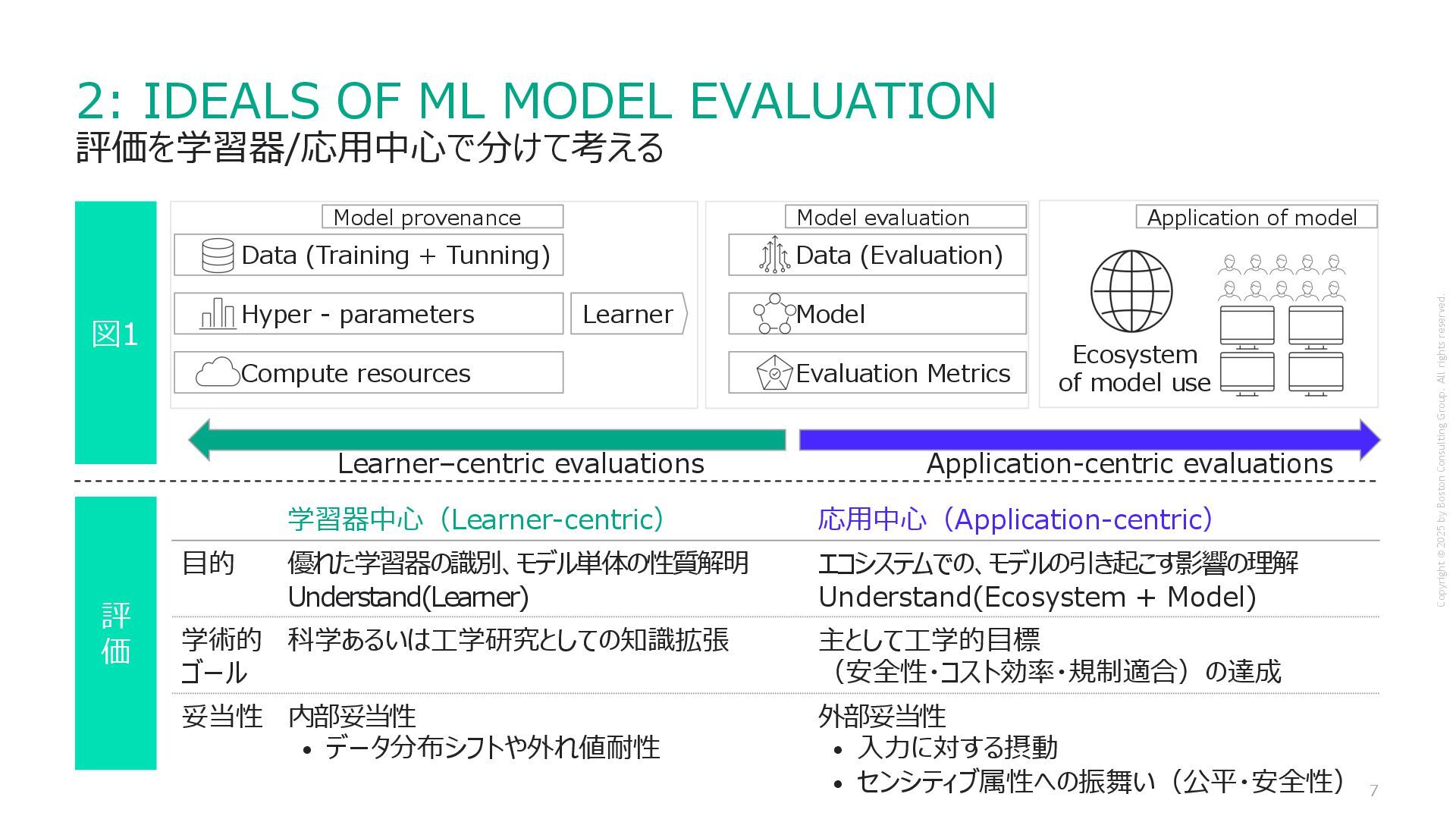
reserved. 2: IDEALS OF ML MODEL EVALUATION 評価を学習器/応⽤中⼼で分けて考える 図1 評 価 Data (Training + Tunning) Hyper - parameters Compute resources Learner Model provenance Data (Evaluation) Model Evaluation Metrics Model evaluation Application of model Ecosystem of model use Application-centric evaluations Learner–centric evaluations 学習器中⼼(Learner-centric) 応⽤中⼼(Application-centric) ⽬的 優れた学習器の識別、モデル単体の性質解明 Understand(Learner) エコシステムでの、モデルの引き起こす影響の理解 Understand(Ecosystem + Model) 学術的 ゴール 科学あるいは⼯学研究としての知識拡張 主として⼯学的⽬標 (安全性・コスト効率・規制適合)の達成 妥当性 内部妥当性 • データ分布シフトや外れ値耐性 外部妥当性 • ⼊⼒に対する摂動 • センシティブ属性への振舞い(公平・安全性)
reserved. 関連⽂献 • Aroyo, Lora, and Chris Welty. "Truth is a lie: Crowd truth and the seven myths of human annotation." AI Magazine 36.1 (2015): 15-24. • Powers, David MW. "What the F-measure doesn't measure: Features, Flaws, Fallacies and Fixes." arXiv preprint arXiv:1503.06410 (2015). • Raji, Inioluwa Deborah, et al. "AI and the everything in the whole wide world benchmark." arXiv preprint arXiv:2111.15366 (2021). • Eriksson, Maria, et al. "Can we trust ai benchmarks? an interdisciplinary review of current issues in ai evaluation." arXiv preprint arXiv:2502.06559 (2025). • Chandrasekaran, Jaganmohan, et al. "Test & evaluation best practices for machine learning- enabled systems." arXiv preprint arXiv:2310.06800 (2023). • Liao, Thomas, et al. "Are we learning yet? a meta review of evaluation failures across machine learning." Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). 2021.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}