why HBase Architecture When and where to Use HBase Storage and data Model Session HBase Components HBase vs RDBMS HBase Runtime Modes HBase API Running HBase
on top of the Hadoop Distributed File System (HDFS). It is columnar and provides fault-tolerant storage and quick access to large quantities of sparse data HBase is the Hadoop application to use when you require real-time read/write random-access to very large datasets. HBase is a non relational database that allows for low latency, quick lookups in Hadoop. It adds transactional capabilities to Hadoop It is a distributed column-oriented database built on top of HDFS. HBase is modeled with an HBase master node orchestrating a cluster of one or more region server slaves. The HBase master is responsible for bootstrapping a virgin install, for assigning regions to registered region servers, and for recovering region server failures. The region servers carry zero or more regions and field client read/write requests.
Hadoop is an opensource system to liably store and process data across many commodity computers HBase and Hadoop are written in Java A hadoop data storage A No SQL store for big data It is open source written in java It is distributed database Automatic Sharding , table data spread over cluster Automatic region server fail over
No real indexes rows are stored sequentially as are the columns within each row therefore no issues with index bloat Insert performance is independent of table size Automatic partitioning (As table grows they will automatically be split into regions across all available nodes) Scale linearly with new nodes Commodity hard ware Data in billions of rows Complex data High volume of I/O High level of data nodes , more than 5 No need of extra RDBMS functions i.e transactions
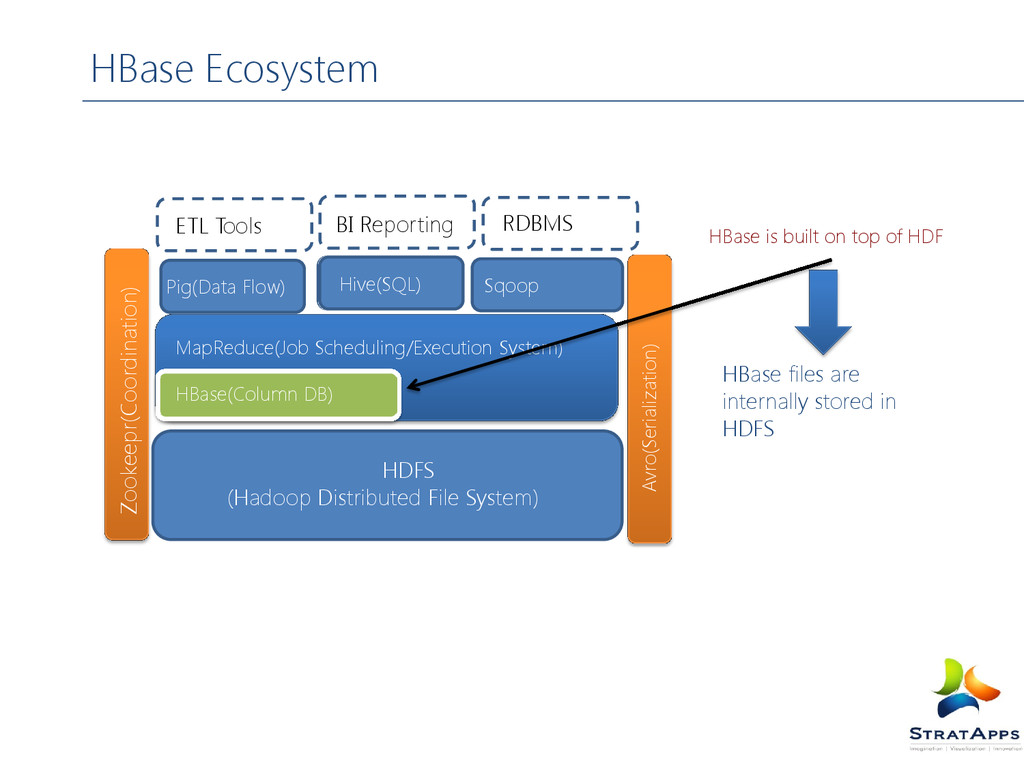
DB) MapReduce(Job Scheduling/Execution System) Pig(Data Flow) Sqoop Hive(SQL) ETL Tools BI Reporting RDBMS HBase is built on top of HDF HBase files are internally stored in HDFS
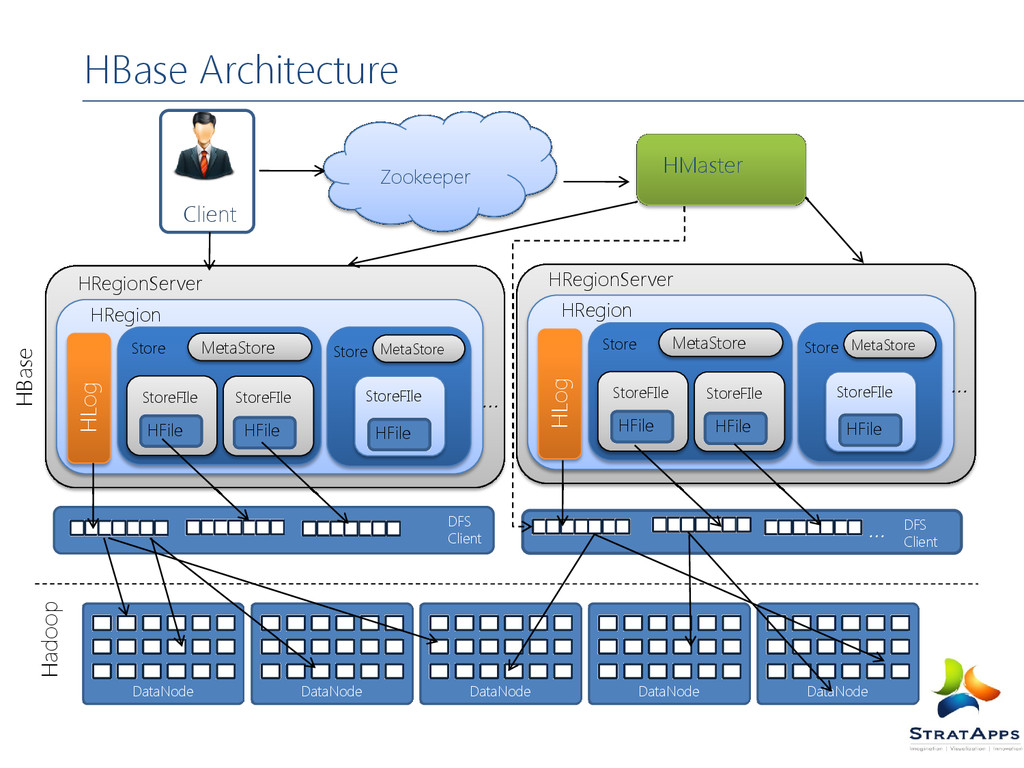
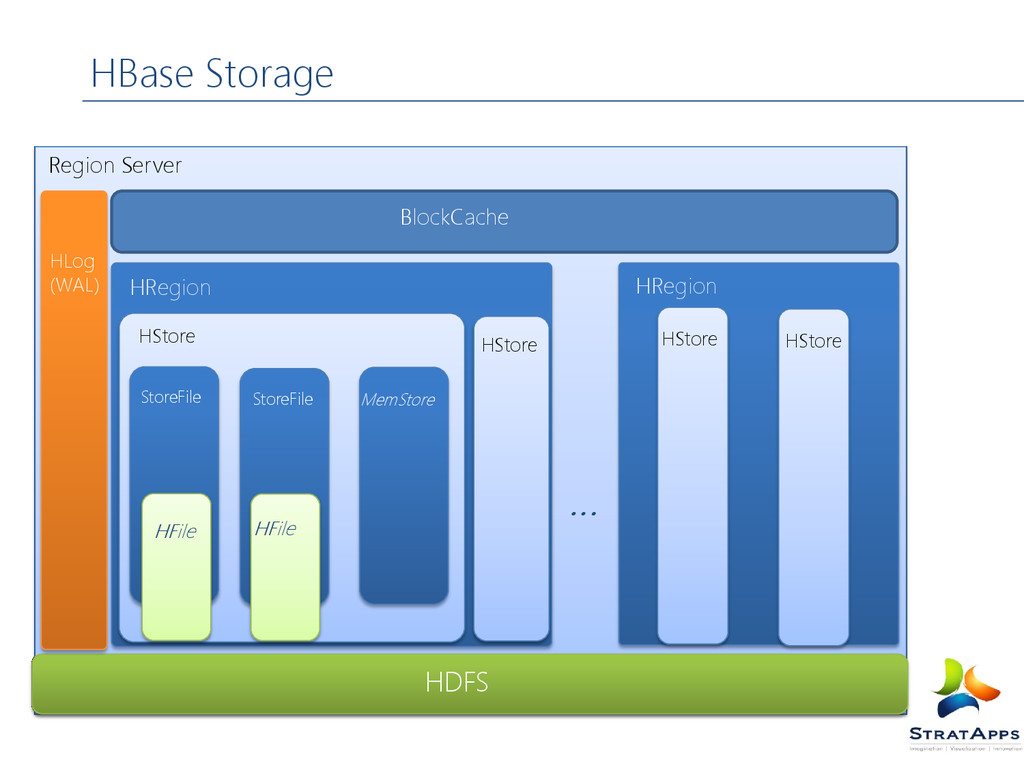
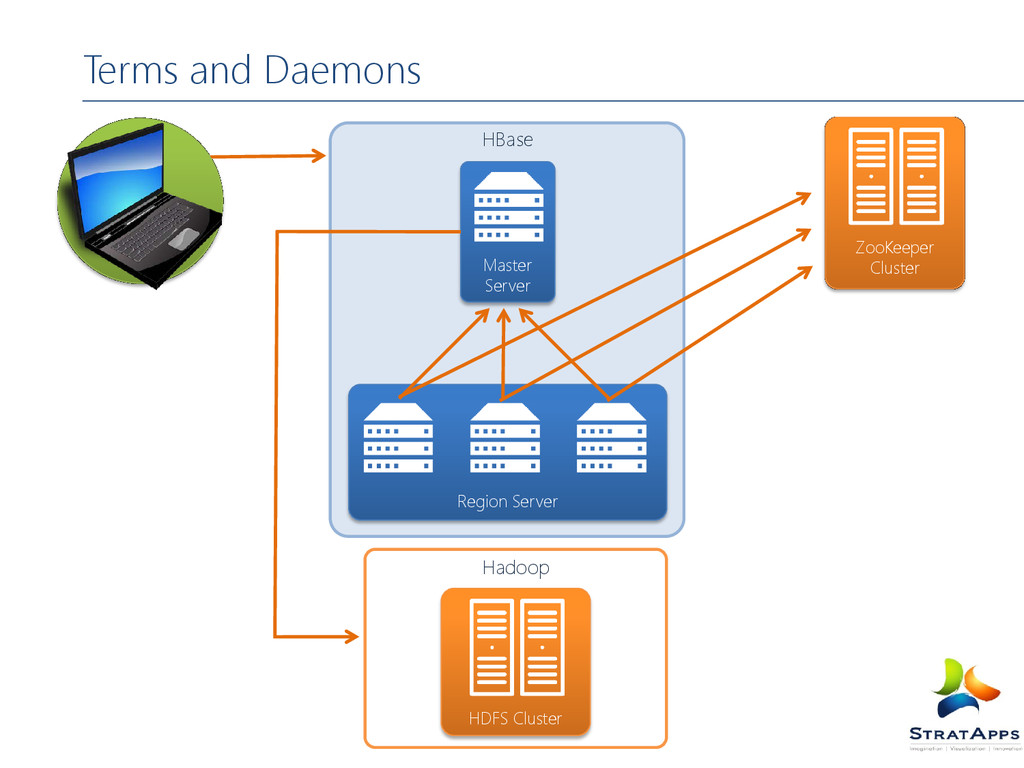
for distributed storage Data stored across region servers Region server data spread across HDFS data nodes A write ahead log (WAL) is used to record changes Table is made of regions Region – a range of rows stored together Single shard, used for scaling Dynamically split as they become too big and merged if too small Region Server serves one or more regions A region is served by only 1 Region Server Master Server daemon responsible for managing HBase cluster, aka Region Servers HBase stores its data into HDFS relies on HDFS's high availability and fault-tolerance features HBase utilizes Zookeeper for distributed coordination
as key value to region server Key value routed to region for now Data is written to WAL Data written to region memStore If region server cashes WAL can be used to recover data
to run client supplied code in the address space of the server Counters Compactions Strictly consistent reads and writes. Automatic and configurable sharding of tables Automatic failover support between RegionServers. Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables. Easy to use Java API for client access. Block cache and Bloom Filters for real-time queries. Query predicate push down via server side Filters Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding options Extensible jruby-based (JIRB) shell Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
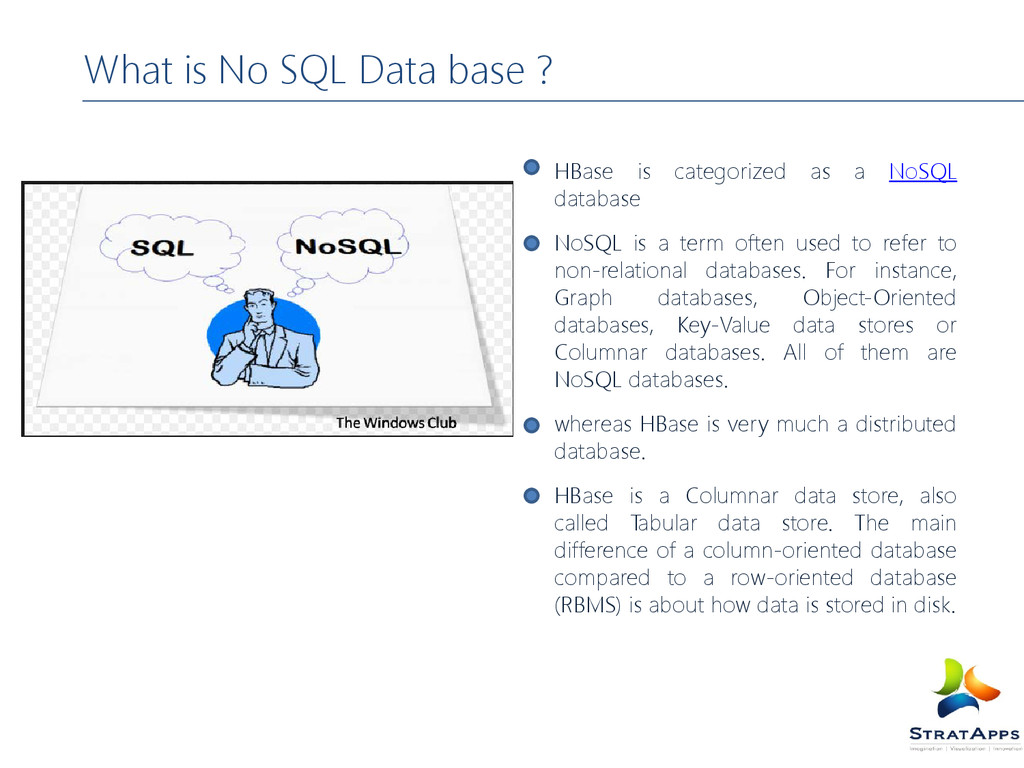
as a NoSQL database NoSQL is a term often used to refer to non-relational databases. For instance, Graph databases, Object-Oriented databases, Key-Value data stores or Columnar databases. All of them are NoSQL databases. whereas HBase is very much a distributed database. HBase is a Columnar data store, also called Tabular data store. The main difference of a column-oriented database compared to a row-oriented database (RBMS) is about how data is stored in disk.
Rows, each which has a primary key(row key). Each Row may have any number of columns. Table schema only defines Column Families(column family can have any number of columns) Each cell value has a timestamp.
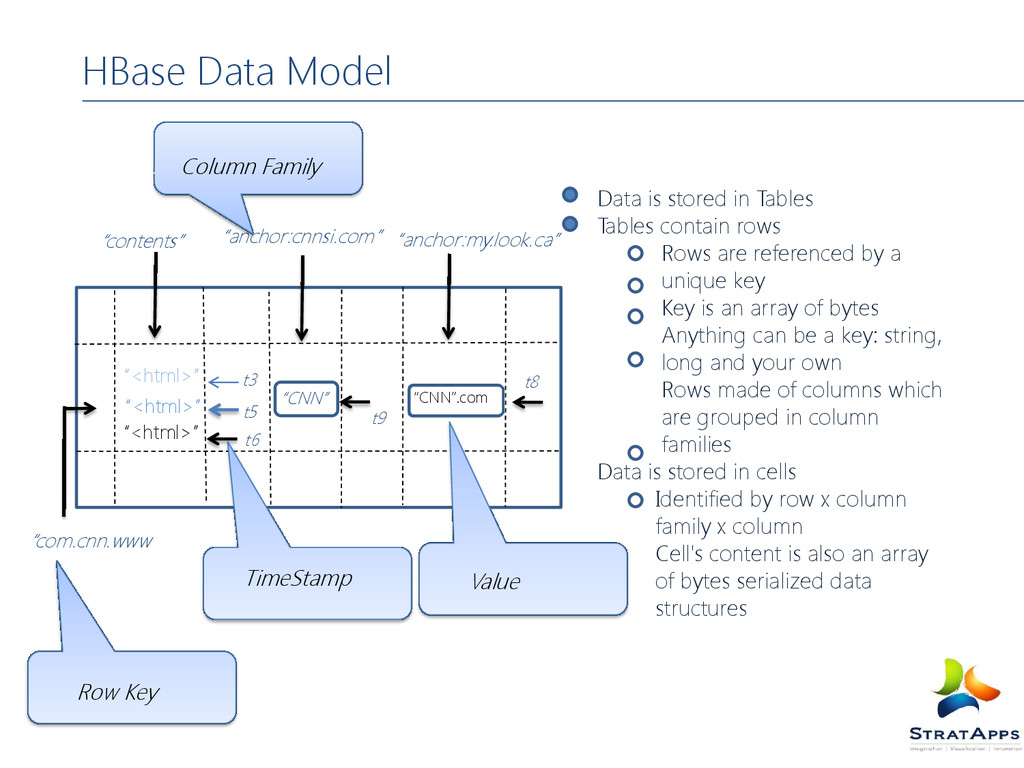
rows Rows are referenced by a unique key Key is an array of bytes Anything can be a key: string, long and your own Rows made of columns which are grouped in column families Data is stored in cells Identified by row x column family x column Cell's content is also an array of bytes serialized data structures “CNN” “CNN”.com “<html>” “<html>” “<html>” t3 t5 t6 t9 t8 “contents” “anchor:cnnsi.com” “anchor:my.look.ca” “com.cnn.www Column Family Row Key TimeStamp Value
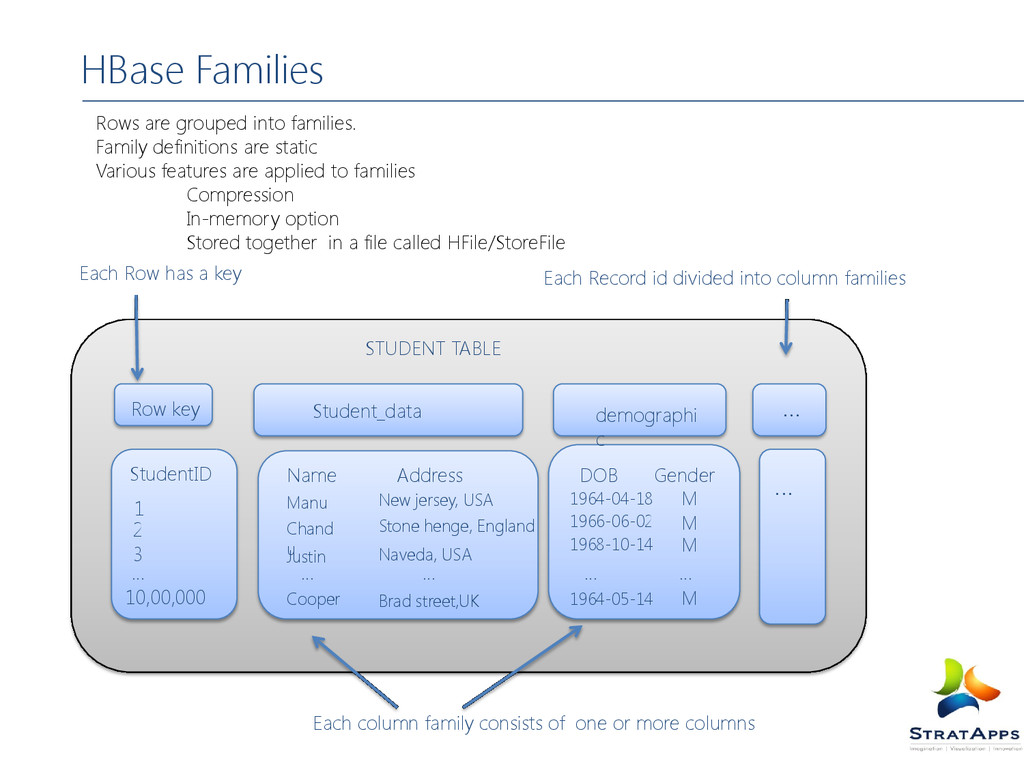
features are applied to families Compression In-memory option Stored together in a file called HFile/StoreFile HBase Families Row key Student_data demographi c ... StudentID 1 2 3 … 10,00,000 Name DOB Address Gender ... … … … … Manu Chand u Justin Cooper New jersey, USA Stone henge, England Naveda, USA Brad street,UK 1964-04-18 1966-06-02 1968-10-14 1964-05-14 M M M M STUDENT TABLE Each Row has a key Each Record id divided into column families Each column family consists of one or more columns
distributed file system that is well suited for the storage of large files.HBase, on the otherhand, is built on top of HDFS and provides fast record lookups (and updates) for large tables. HDFS has based on GFS file system HBase is Distributed uses HDFS for storage Column Oriented Multi Dimensional (Versions) Storage System
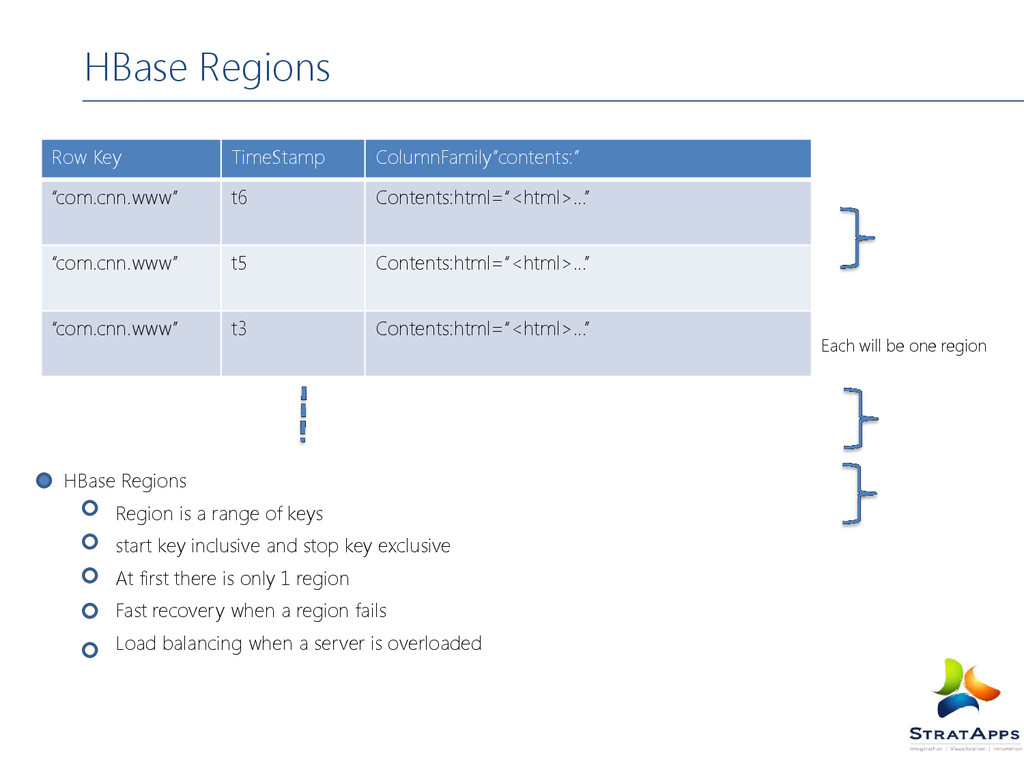
inclusive and stop key exclusive At first there is only 1 region Fast recovery when a region fails Load balancing when a server is overloaded HBase Regions Each will be one region Row Key TimeStamp ColumnFamily”contents:” “com.cnn.www” t6 Contents:html=“<html>…” “com.cnn.www” t5 Contents:html=“<html>…” “com.cnn.www” t3 Contents:html=“<html>…”
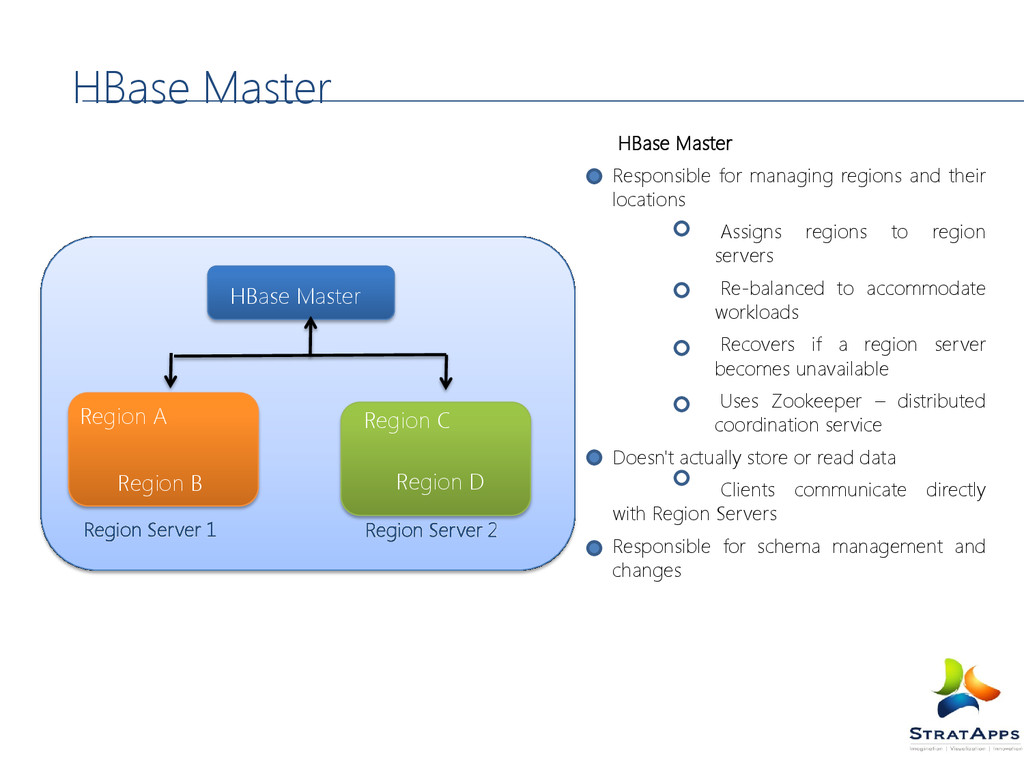
regions to region servers Re-balanced to accommodate workloads Recovers if a region server becomes unavailable Uses Zookeeper – distributed coordination service Doesn't actually store or read data Clients communicate directly with Region Servers Responsible for schema management and changes HBase Master HBase Master Region C Region Server 1 Region Server 2 Region B Region D Region A
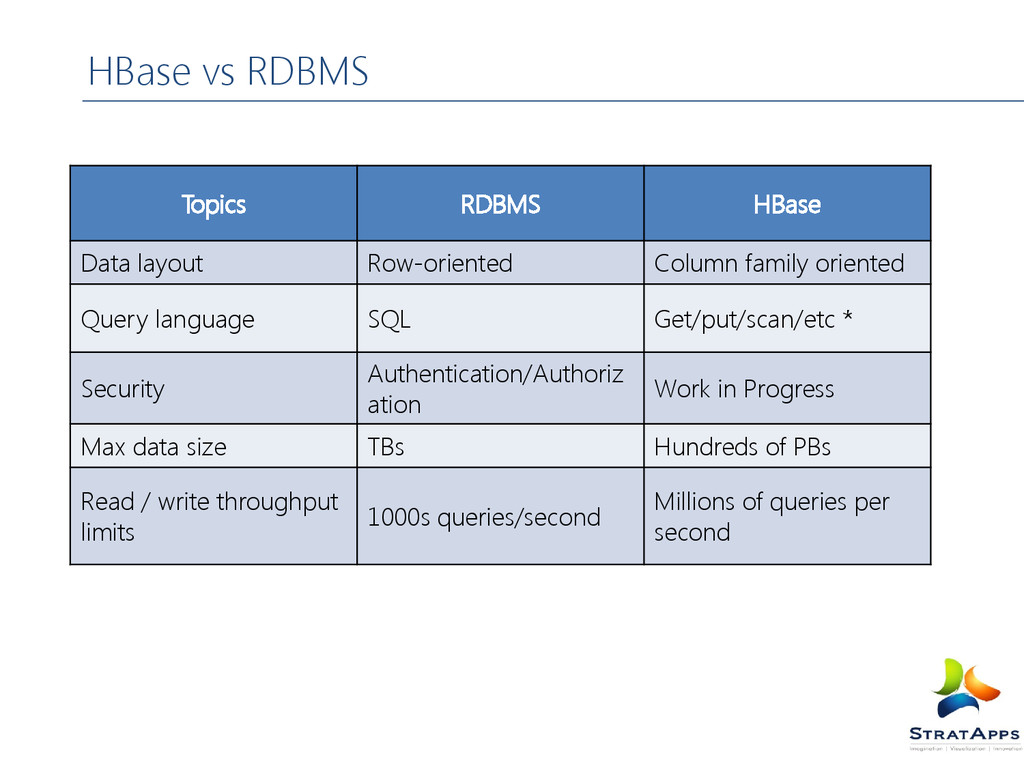
family oriented Query language SQL Get/put/scan/etc * Security Authentication/Authoriz ation Work in Progress Max data size TBs Hundreds of PBs Read / write throughput limits 1000s queries/second Millions of queries per second
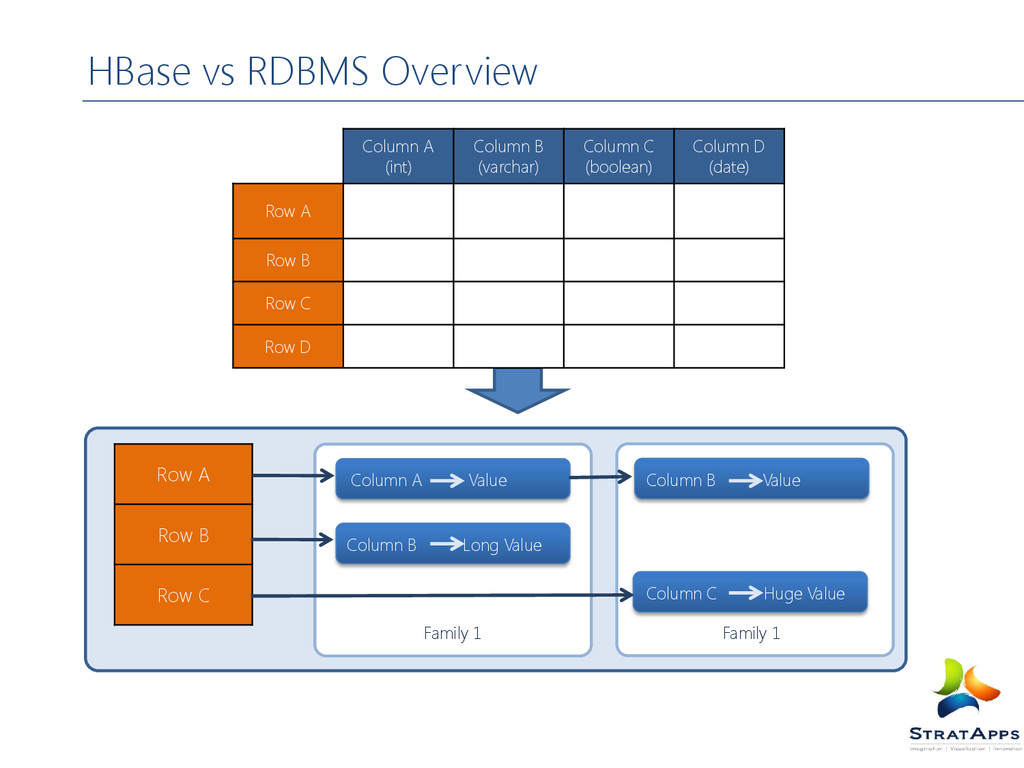
D (date) Row A Row B Row C Row D Row A Row B Row C Family 1 Column A Value Column B Long Value Family 1 Column B Value Column C Huge Value HBase vs RDBMS Overview
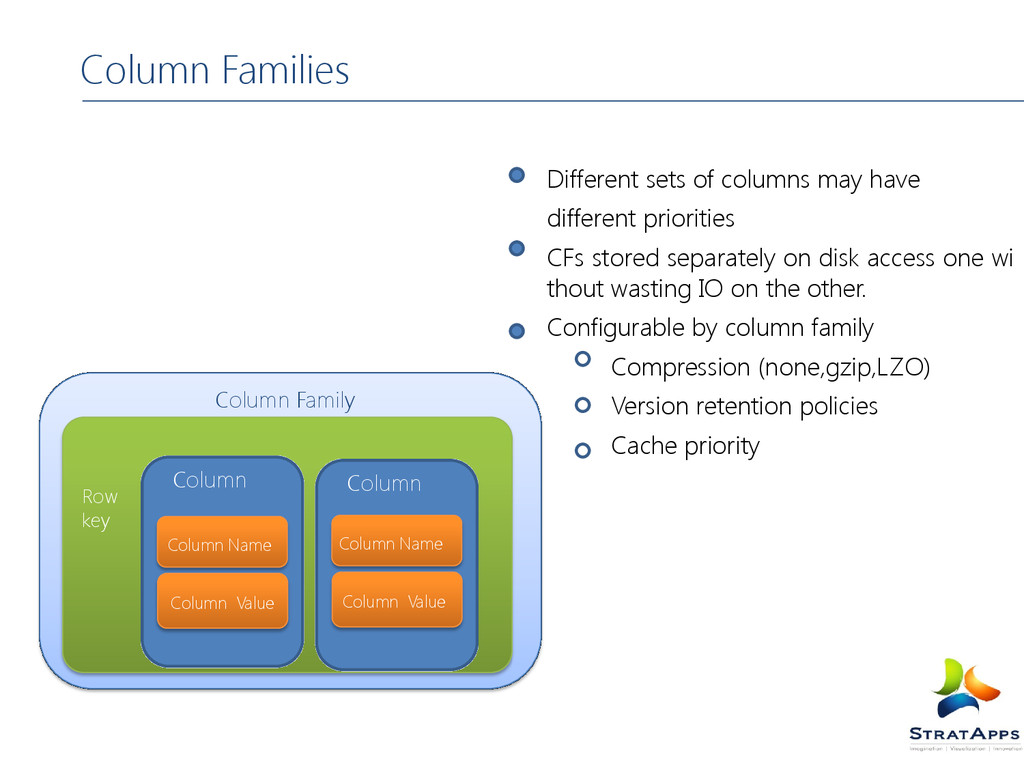
CFs stored separately on disk access one wi thout wasting IO on the other. Configurable by column family Compression (none,gzip,LZO) Version retention policies Cache priority Column Family Row key Column Column Name Column Value Column Column Name Column Value
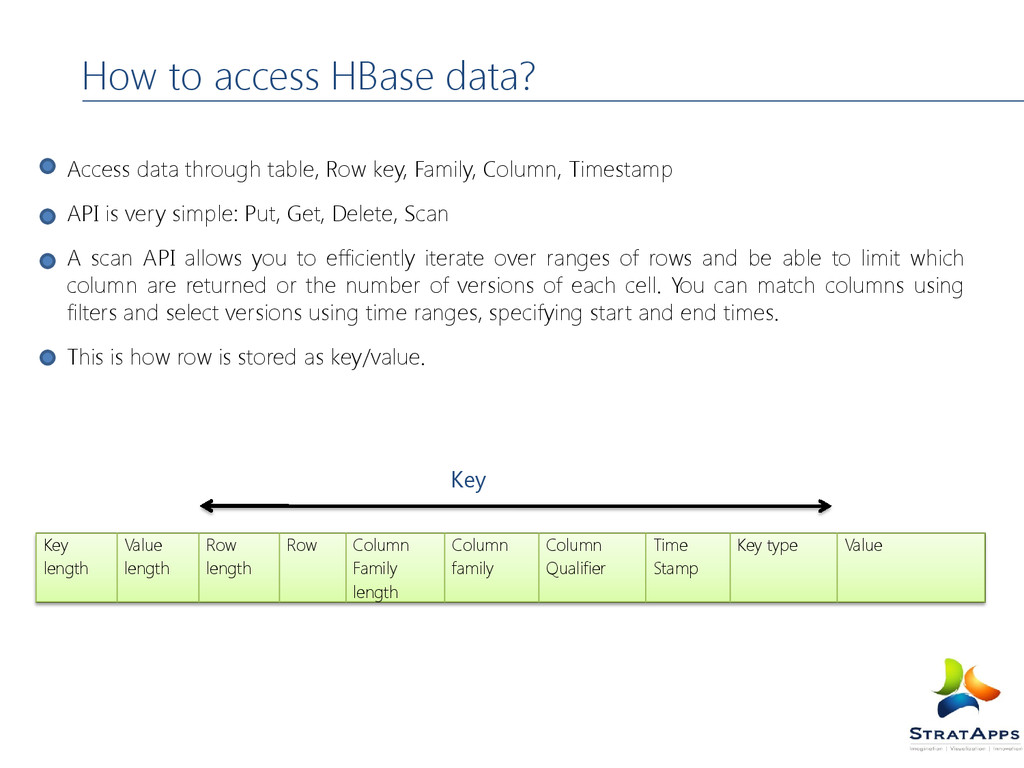
key, Family, Column, Timestamp API is very simple: Put, Get, Delete, Scan A scan API allows you to efficiently iterate over ranges of rows and be able to limit which column are returned or the number of versions of each cell. You can match columns using filters and select versions using time ranges, specifying start and end times. This is how row is stored as key/value. Key length Value length Row length Row Column Family length Column family Column Qualifier Time Stamp Key type Value Key
get started Uses local filesystem (not HDFS), NOT for production Runs HBase & Zookeeper in the same JVM Pseudo-Distributed Mode Requires HDFS Mimics Fully-Distributed but runs on just one host Good for testing, debugging and prototyping Not for production use or performance benchmarking! Development mode used in class Fully-Distributed Mode Run HBase on many machines Great for production and development clusters
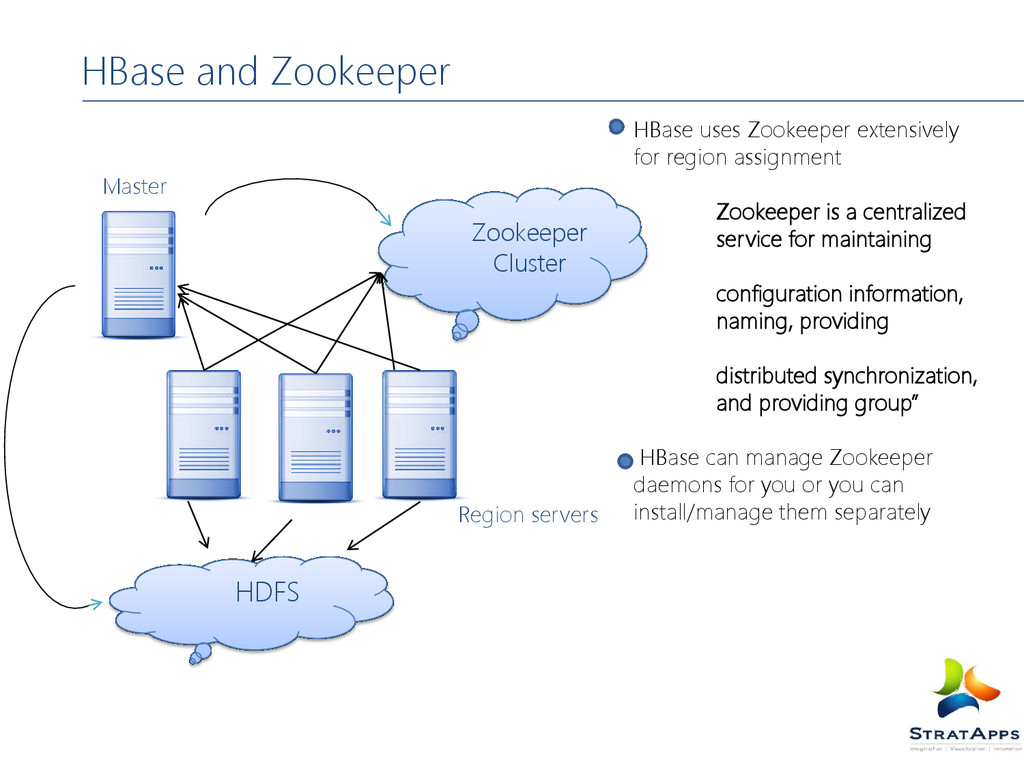
Zookeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group” HBase can manage Zookeeper daemons for you or you can install/manage them separately Zookeeper Cluster HDFS Region servers Master
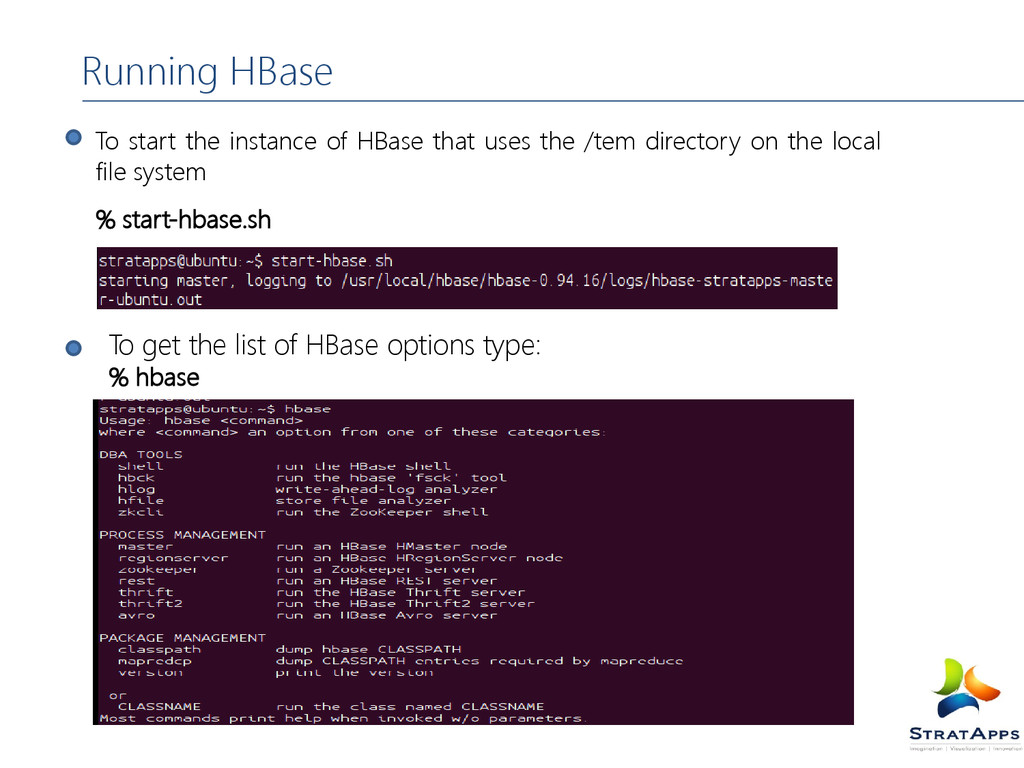
shell by typing % hbase shell Creating a table named ‘testable’ with a single column family named ‘data’ using defaults for table and column family attributes Create ‘table name’, ‘column family’ Create ‘testtable’, ‘data’ To see the new table just type list command this will output all the tables Hbase(main):09:0> list
columns in the data column family Hbase(main):09:0> put ‘testtable’, ‘row1’, ‘data:1’, ‘value1’ Hbase(main):09:0> put ‘testtable’, ‘row2’, ‘data:2’, ‘value2’ Hbase(main):09:0> put ‘testtable’, ‘row3’, ‘data:3’, ‘value3’ To see the content of the table type Hbase(main):09:0> scan ‘testtable’
disable it before dropping the table Hbase(main):09:0> disable ‘testtable’ Hbase(main):09:0> drop ‘testtable’ Stop the HBase instance by running % stop-hbase.sh
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}