Map Reduce
Map Reduce use cases
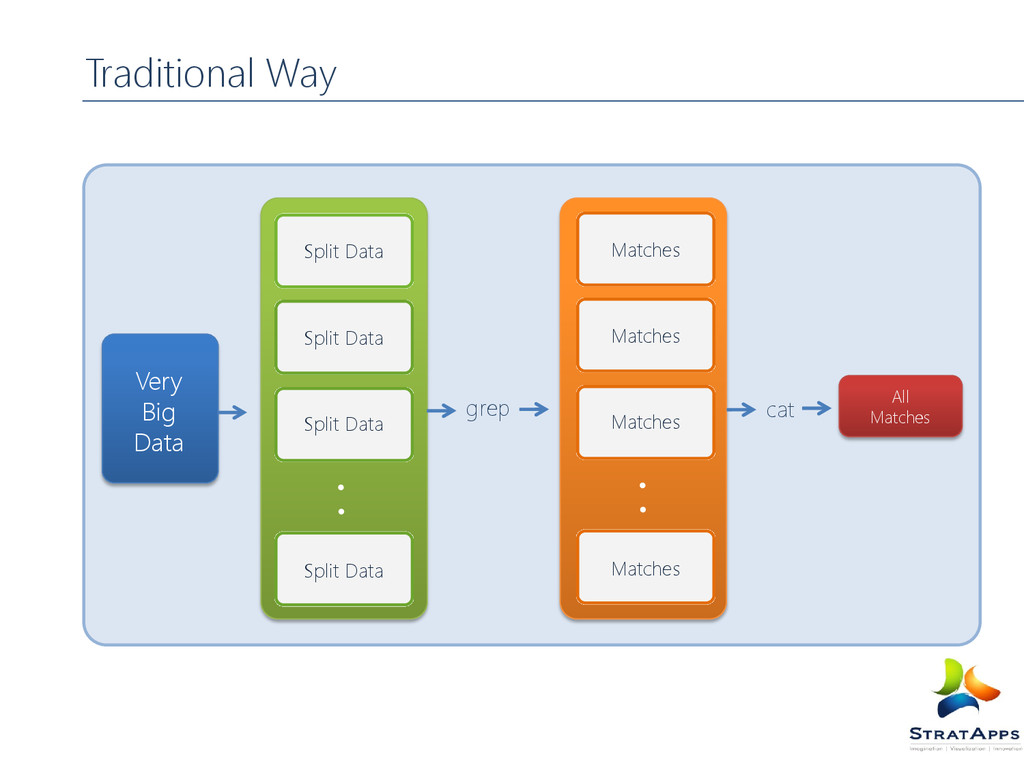
Traditional Way
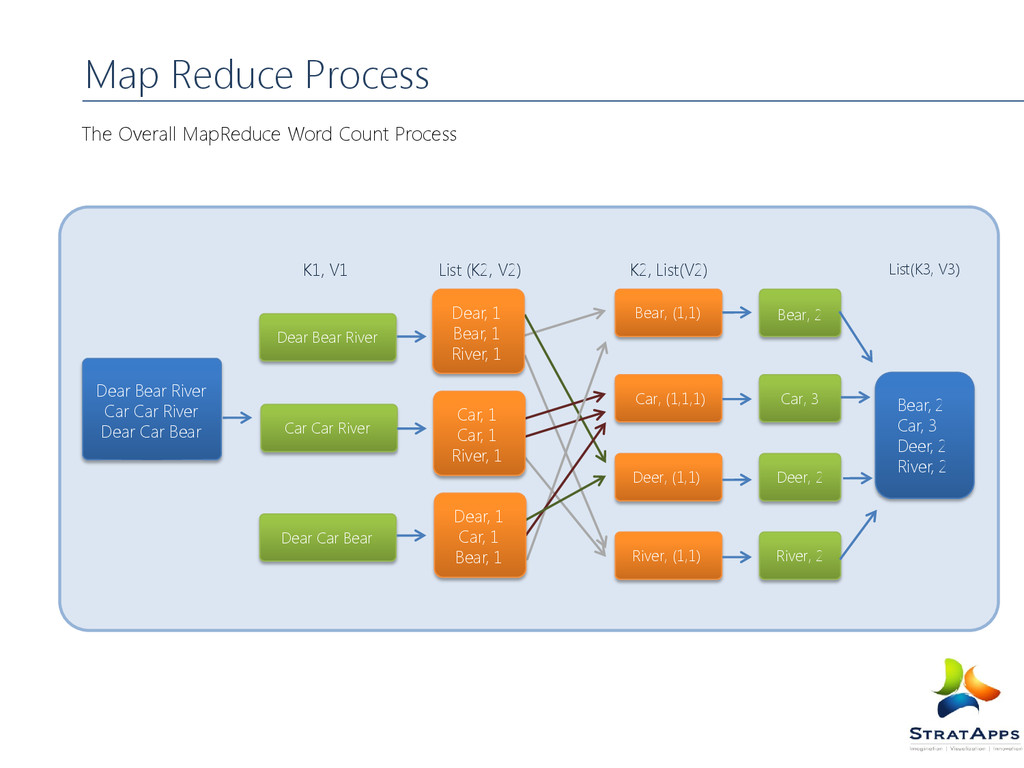
Map Reduce Process
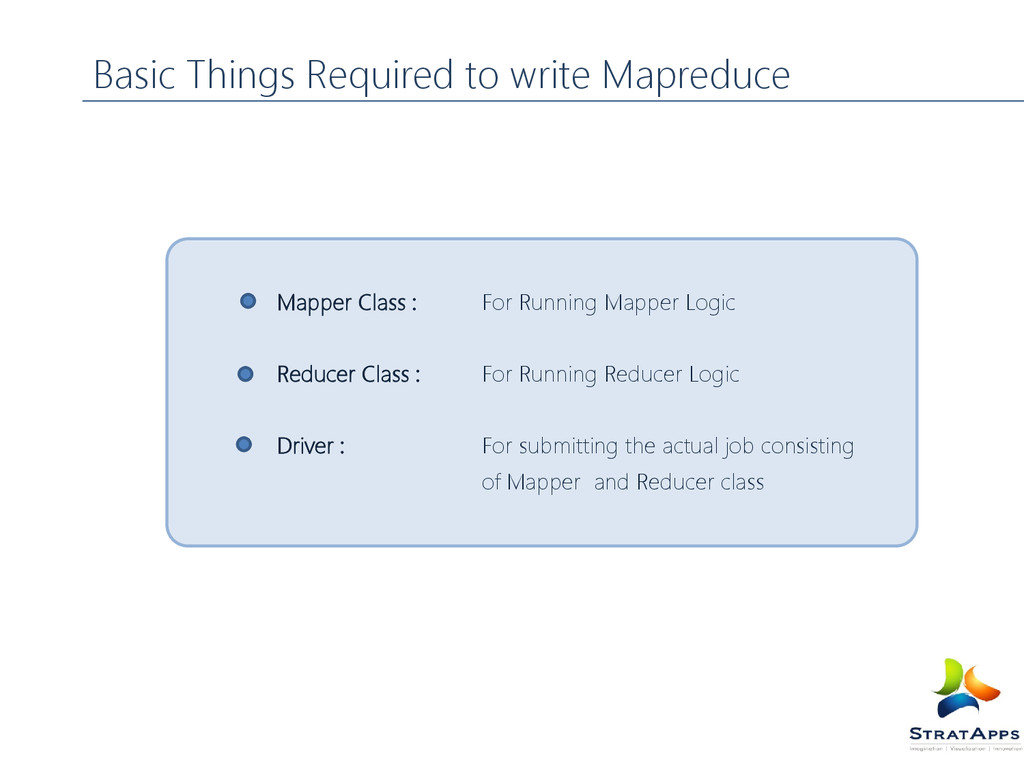
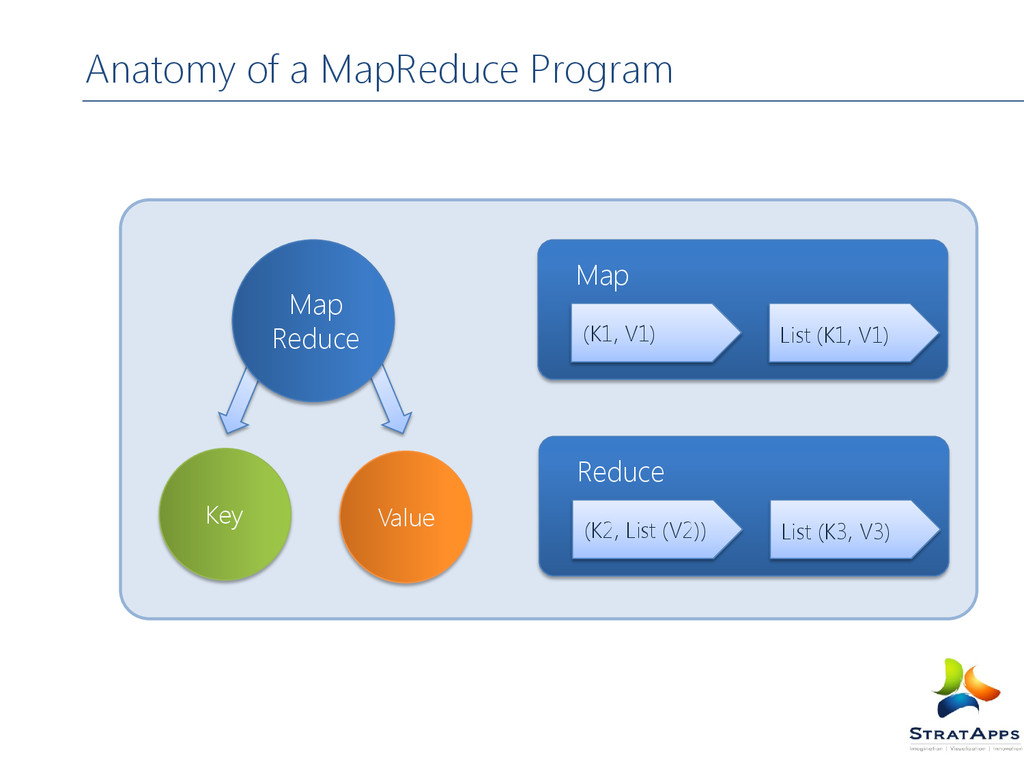
Anatomy of a Map Reduce program
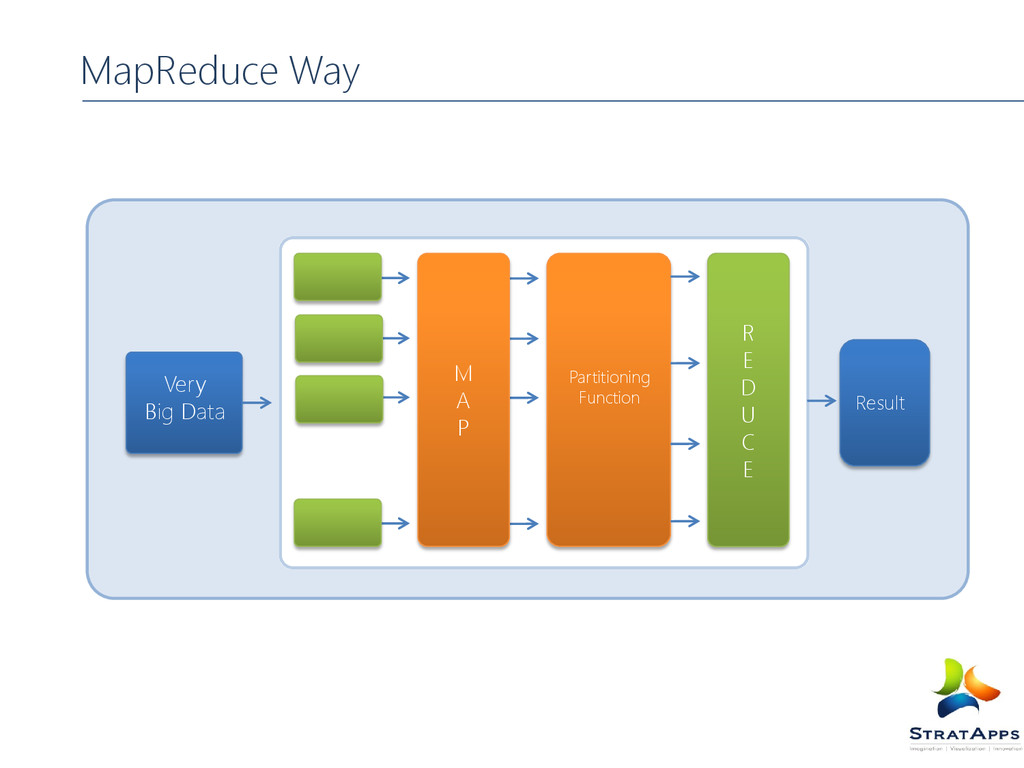
Map Reduce Way
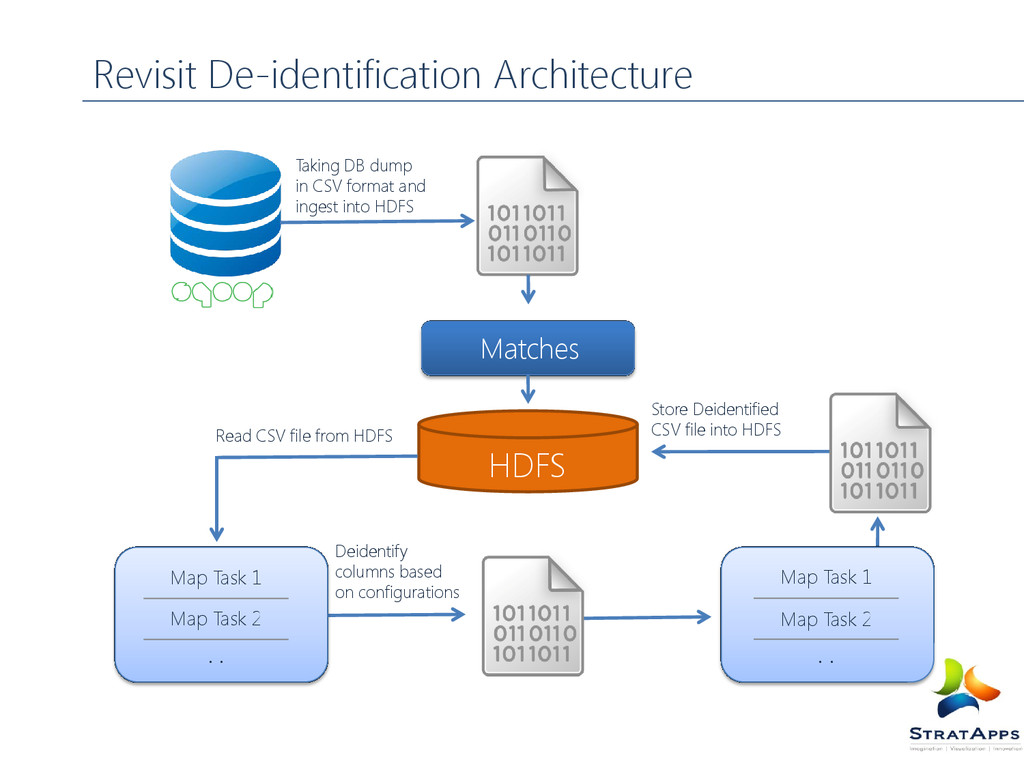
Revisit de-identification architecture
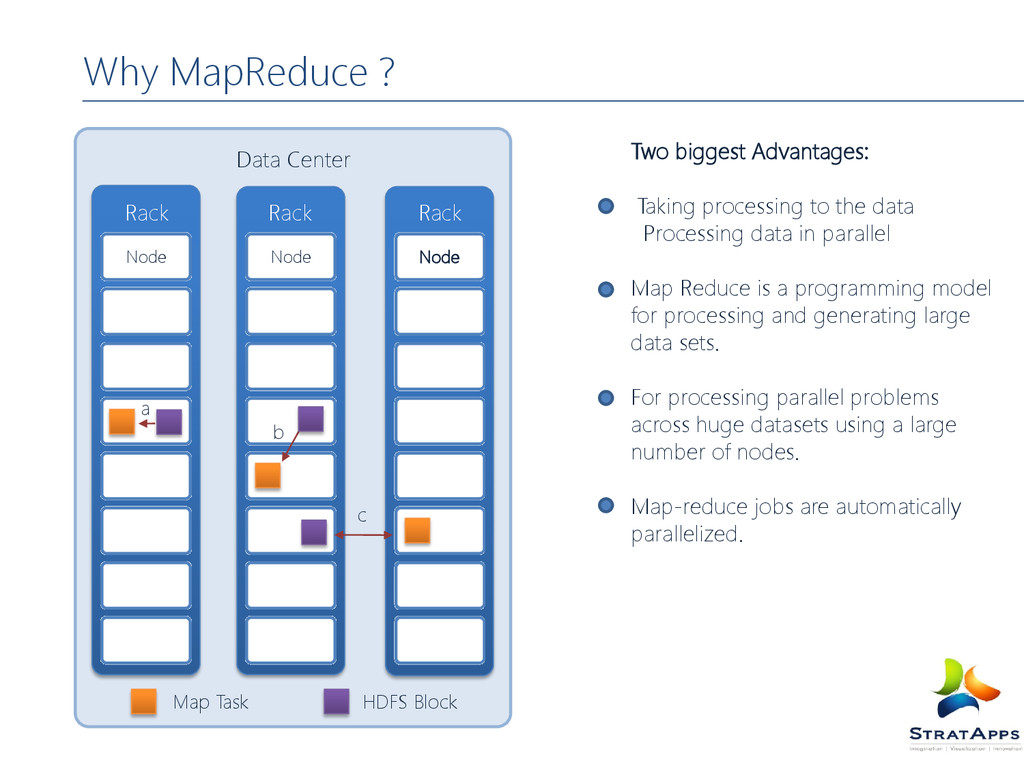
Why Map Reduce
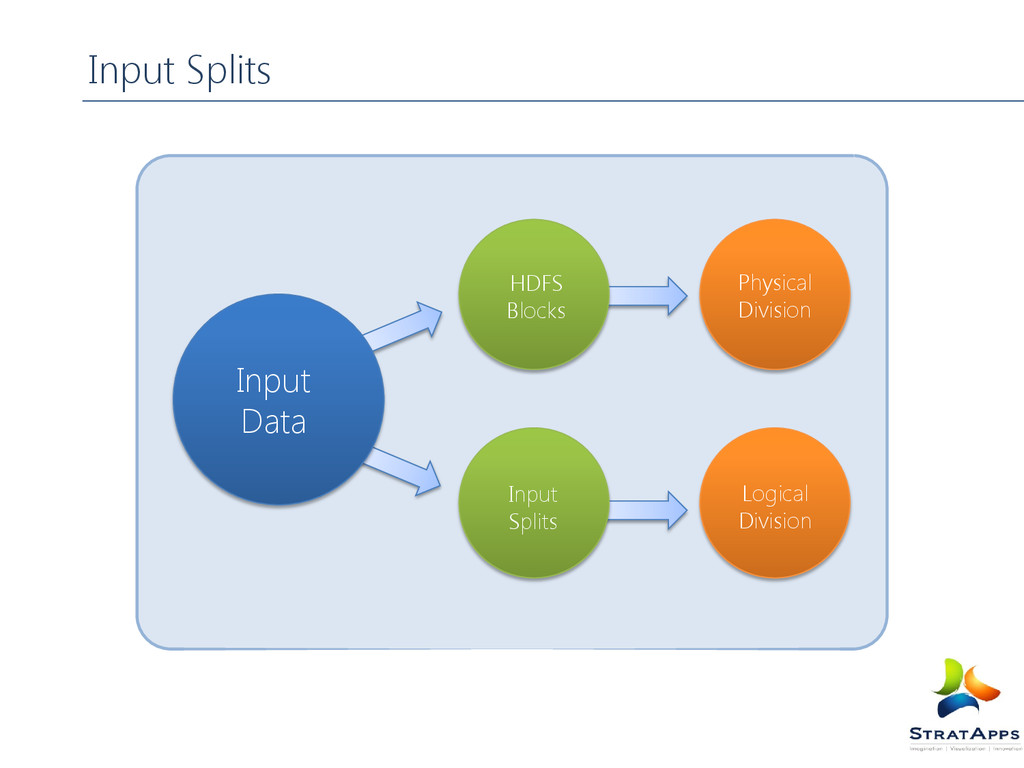
Traditional Way Map Reduce Process Anatomy of a Map Reduce program Map Reduce Way Revisit de-identification architecture Why Map Reduce Session Input Splits Relation between Input Splits & HDFS blocks Map Reduce Flow Distributed Cache Overview of Map Reduce Combiner & Partitioner Input Formats
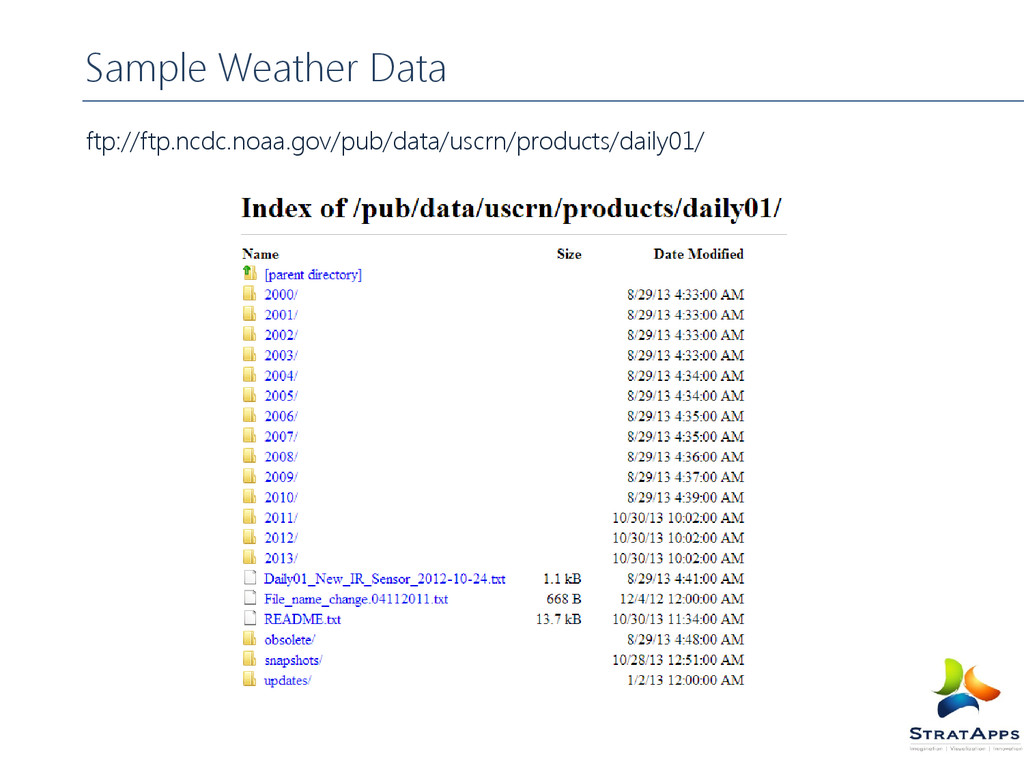
Gas Industry Map reduce is targeted towards cases where we need to process large datasets with parallel, distributed algorithm on a cluster setup. Let’s say, you need to process huge amount of data. You can process individual records of the data set serially through one software program but if you want the processing faster. One of the things you could do is to break the large chunk of data into smaller chunks and process them in parallel.
in CSV format and ingest into HDFS Read CSV file from HDFS Deidentify columns based on configurations HDFS Matches Map Task 1 Map Task 2 . . Map Task 1 Map Task 2 . .
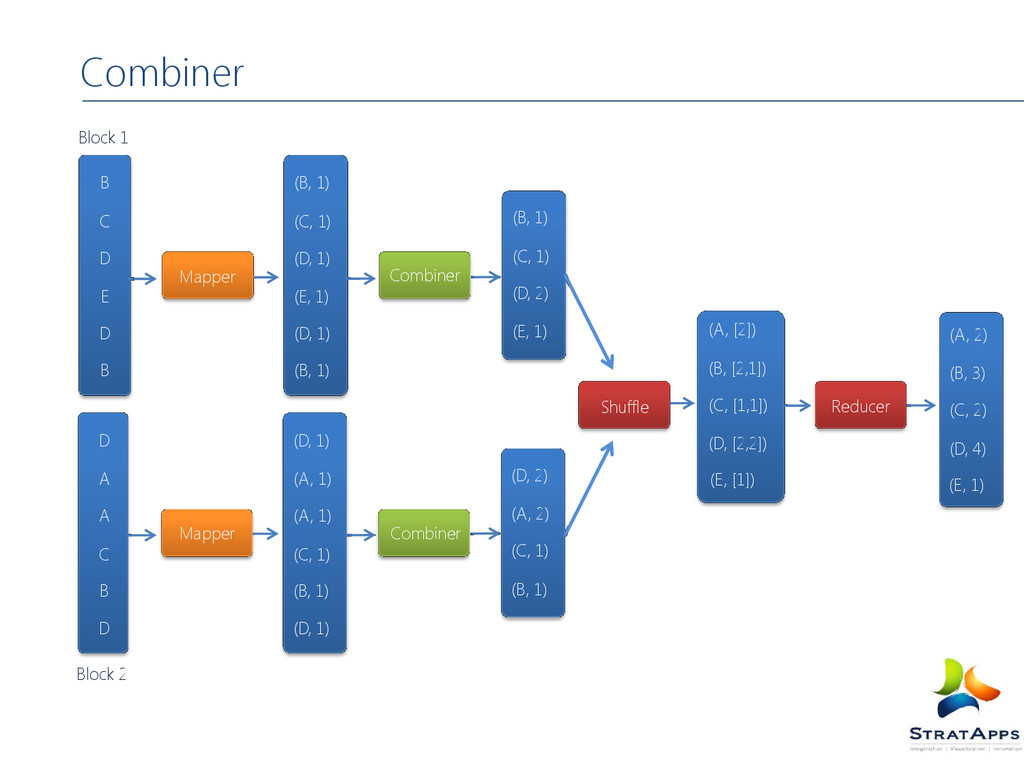
Bear River Bear, 2 Car, 3 Deer, 2 River, 2 Dear Bear River Car Car River Dear Car Bear Car Car River Dear Car Bear K1, V1 Bear, (1,1) Car, (1,1,1) Deer, (1,1) K2, List(V2) River, (1,1) Bear, 2 Car, 3 Deer, 2 River, 2 List(K3, V3) Dear, 1 Bear, 1 River, 1 Car, 1 Car, 1 River, 1 Dear, 1 Car, 1 Bear, 1 List (K2, V2)
counts how often words occur. The input is text files and the output is text files. Each mapper takes a line as input and breaks it into words. It then emits a key/value pair of the word and 1. Each reducer sums the counts for each word and emits a single key/value with the word and sum.
DB dump in CSV format and ingest into HDFS Read CSV file from HDFS Deidentify columns based on configurations HDFS Matches Map Task 1 Map Task 2 . . Map Task 1 Map Task 2 . .
data Processing data in parallel Map Reduce is a programming model for processing and generating large data sets. For processing parallel problems across huge datasets using a large number of nodes. Map-reduce jobs are automatically parallelized. Rack Rack Rack Data Center Map Task HDFS Block a b c Node Node Node
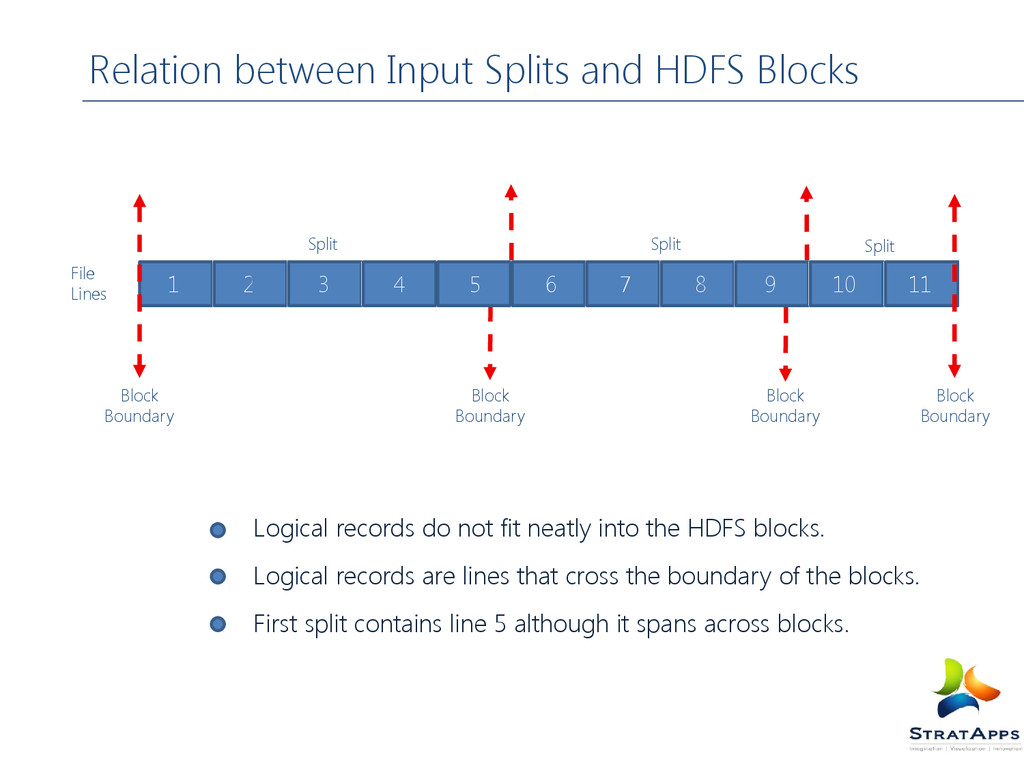
not fit neatly into the HDFS blocks. Logical records are lines that cross the boundary of the blocks. First split contains line 5 although it spans across blocks. 1 2 3 4 5 6 7 8 9 10 11 Block Boundary Block Boundary Block Boundary Block Boundary File Lines Split Split Split
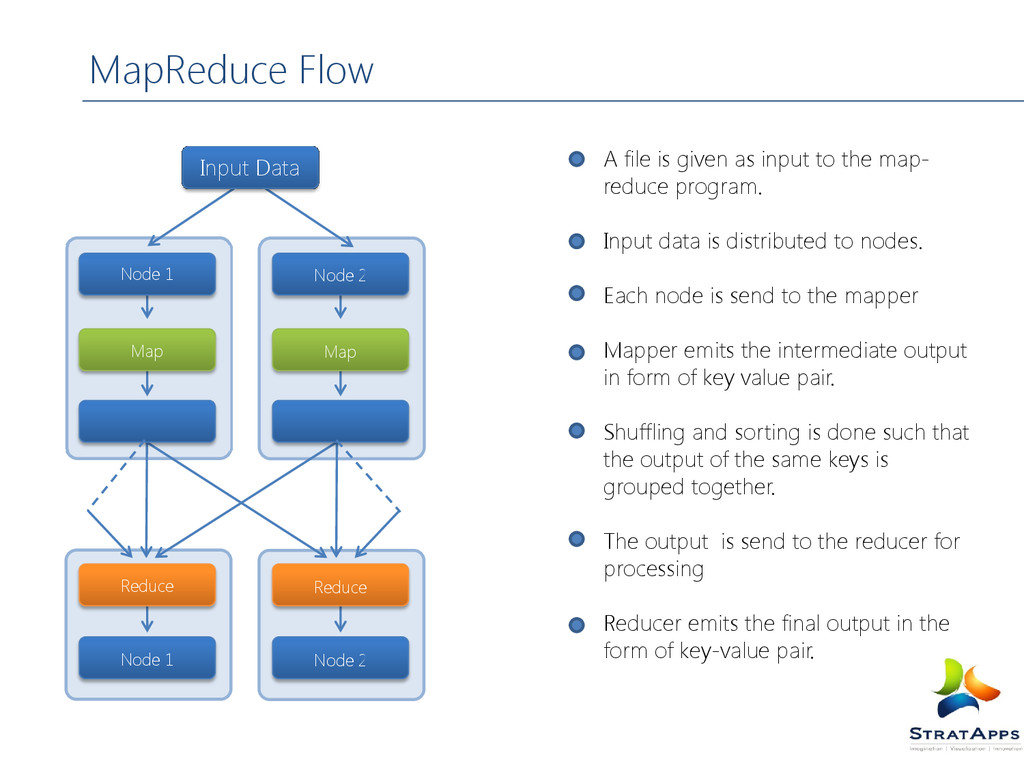
map- reduce program. Input data is distributed to nodes. Each node is send to the mapper Mapper emits the intermediate output in form of key value pair. Shuffling and sorting is done such that the output of the same keys is grouped together. The output is send to the reducer for processing Reducer emits the final output in the form of key-value pair. Node 1 Node 2 Reduce Reduce Node 1 Node 2 Map Map Input Data
information while execution. For Example: While retrieving keywords from a file, you want to use a file consisting of stop words Distributed Cache facility provides caching of the files (text, jar, zip, tar. gz, tgz etc) per JOB Map Reduce framework will copy the files to the slave nodes before executing the task on that node While using distributed cache: Files should be present in HDFS Distributed Cache facility tracks the modification time stamp of the file, so it should not be modified externally
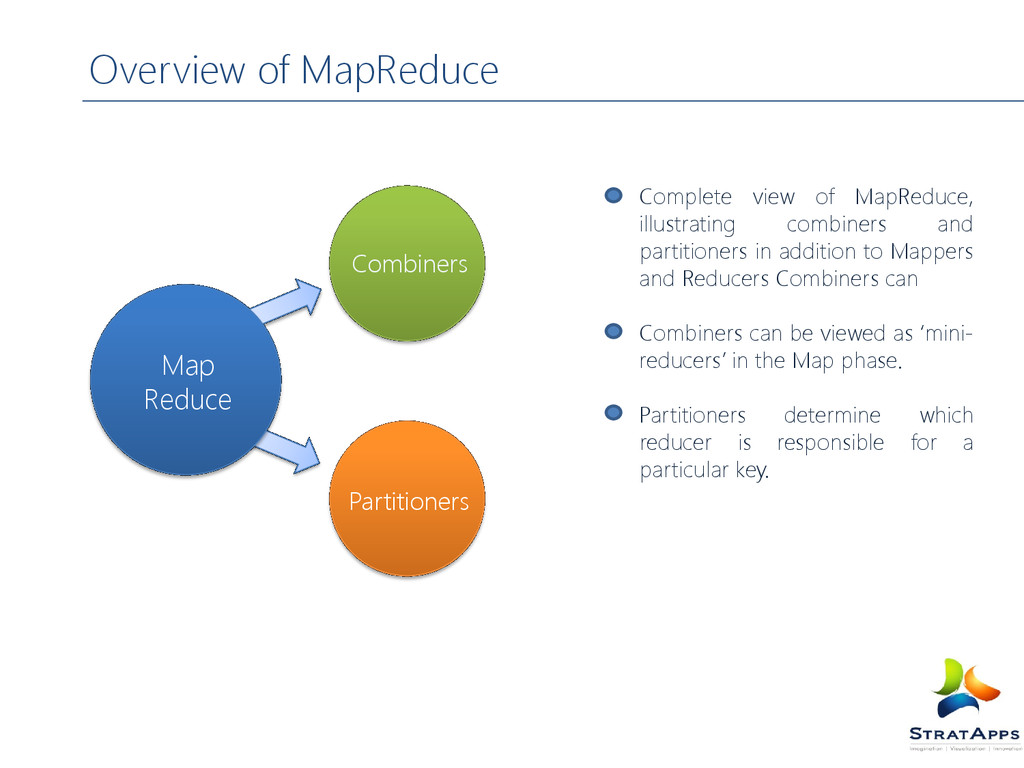
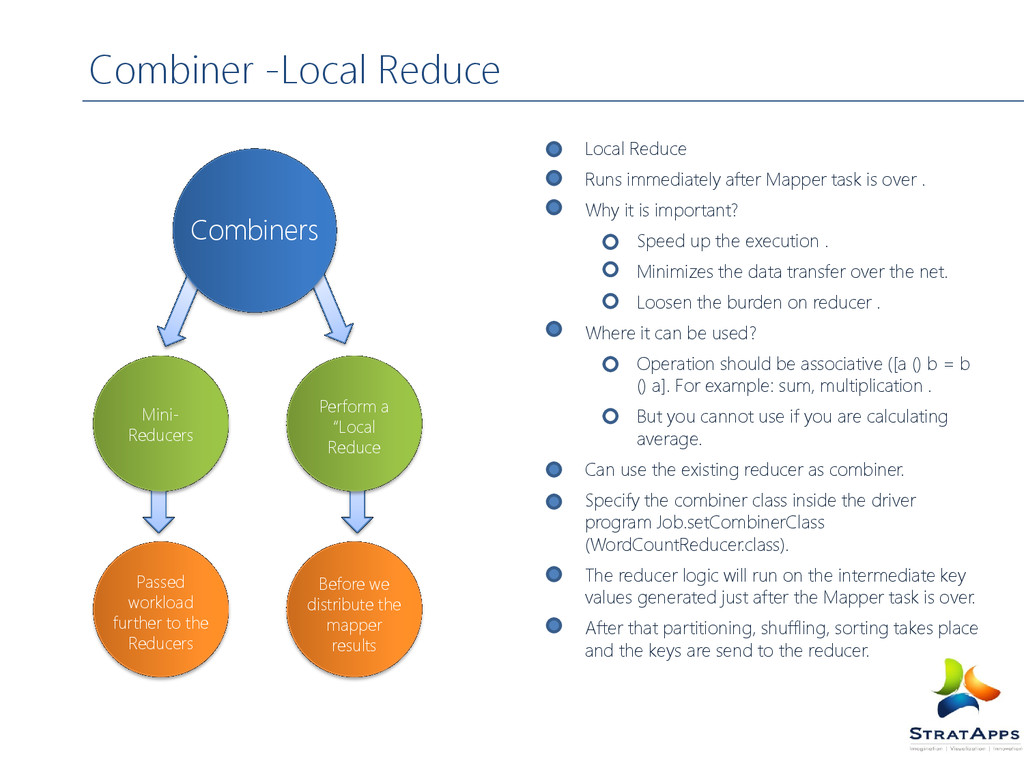
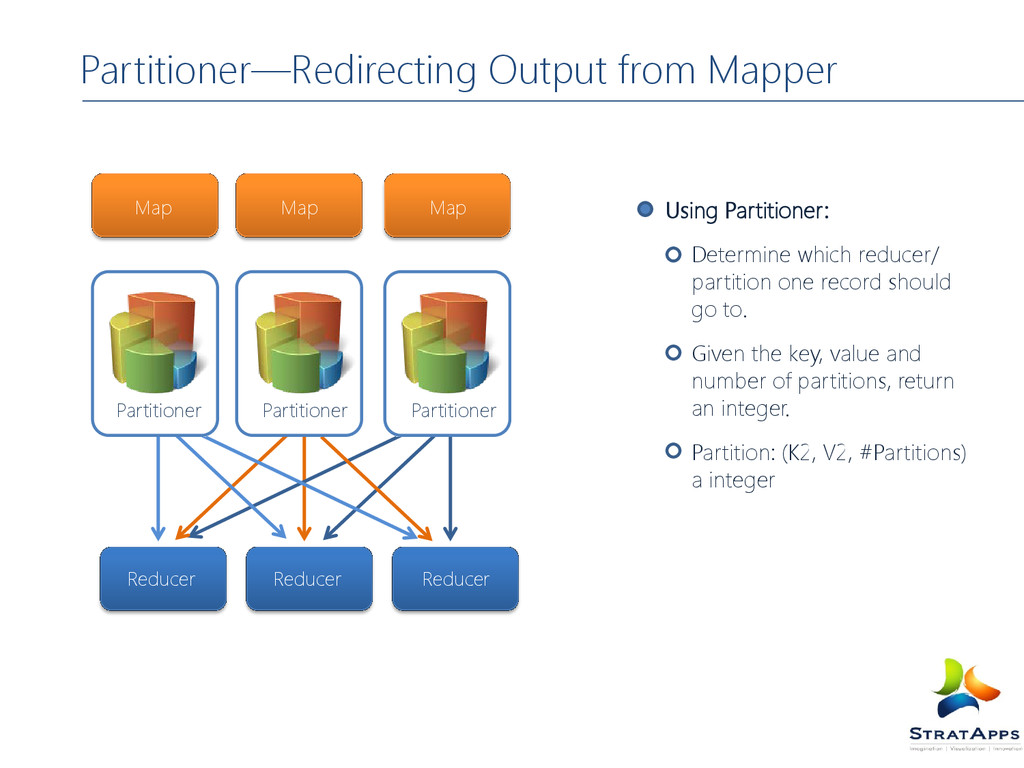
MapReduce, illustrating combiners and partitioners in addition to Mappers and Reducers Combiners can Combiners can be viewed as ‘mini- reducers’ in the Map phase. Partitioners determine which reducer is responsible for a particular key.
is over . Why it is important? Speed up the execution . Minimizes the data transfer over the net. Loosen the burden on reducer . Where it can be used? Operation should be associative ([a () b = b () a]. For example: sum, multiplication . But you cannot use if you are calculating average. Can use the existing reducer as combiner. Specify the combiner class inside the driver program Job.setCombinerClass (WordCountReducer.class). The reducer logic will run on the intermediate key values generated just after the Mapper task is over. After that partitioning, shuffling, sorting takes place and the keys are send to the reducer. Perform a “Local Reduce Mini- Reducers Before we distribute the mapper results Passed workload further to the Reducers Combiners
one record should go to. Given the key, value and number of partitions, return an integer. Partition: (K2, V2, #Partitions) a integer Reducer Reducer Reducer Map Map Map Partitioner Partitioner Partitioner
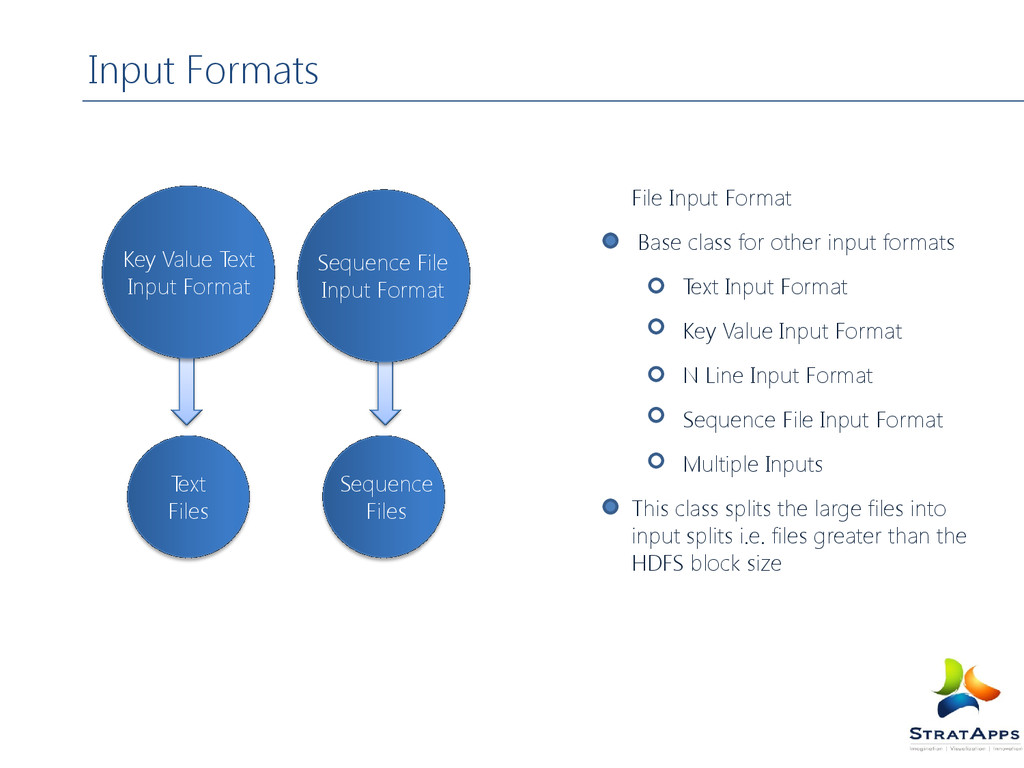
formats Text Input Format Key Value Input Format N Line Input Format Sequence File Input Format Multiple Inputs This class splits the large files into input splits i.e. files greater than the HDFS block size Sequence Files Text Files Key Value Text Input Format Sequence File Input Format
format KEY : Offset of a line with in a file VALUE : Entire Line as the value Key Value Text Input Format Scenario: Each line could be a key value par separated by delimiter Default delimiter is tab KEY: First word till the delimiter VALUE: Entire line after the delimiter Custom Delimiter: key.value.separator.in.input.line Text and Key Value Input Format
DB2, MySql Server etc Approach: Creating a small file in which data source connections are given in a separate line Accordingly input split is created if a specify the number of lines to mapper =1 Each mapper will take one data source at a time and connect to the data source and load the data from the source to HDFS Text input format and key value input format receives variable number of line Based on input split size Length of line Useful if mapper wants to receive fixed number of lines of input N Line Input Format
of binary key value pair Supports compression as part of the format Can store any types Sequence File As Text Input Format Converts to Text object Sequence File As Binary Input Format Encapsulates Byte Writable objects Multiple Inputs Use Case: Same data source is generating same file but in different format One is tab separated Another is sequence file Use the input format as Multiple Input Sequence File and Multiple Input Format
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}