on top of Hadoop. It facilitates querying large datasets residing on a distributed storage. It provides a mechanism to project structure on to the data and query the data using a SQL-like language called “HiveQL”. Why Hive was developed? Hive was developed by Facebook and was open sourced in 2008. Data stored in Hadoop is inaccessible to business users. High level languages like Pig, Cascading etc are geared towards developers. SQL is a common language that is known to many. Hive was developed to give access to data stored in Hadoop, translating SQL like queries into map reduce jobs.
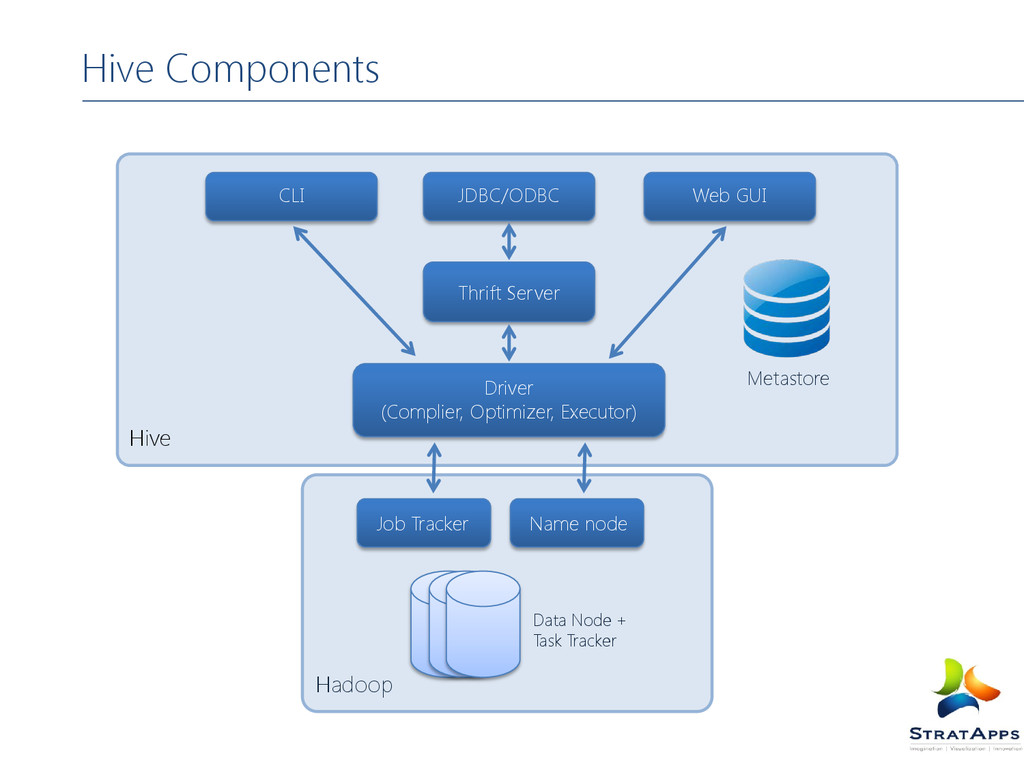
Server: This server exposes a very simple client API to execute HiveQL statements. Metastore: The metastore is the system catalog. All other components of Hive interact with the metastore Driver: It manages life cycle of HiveQL statement during compilation, optimization and execution. Query Compiler: The compiler is invoked by driver upon receiving a HiveQL statement. Execution Engine: The driver submits the individual map-reduce jobs from the DAG to the execution engine in a topological order.
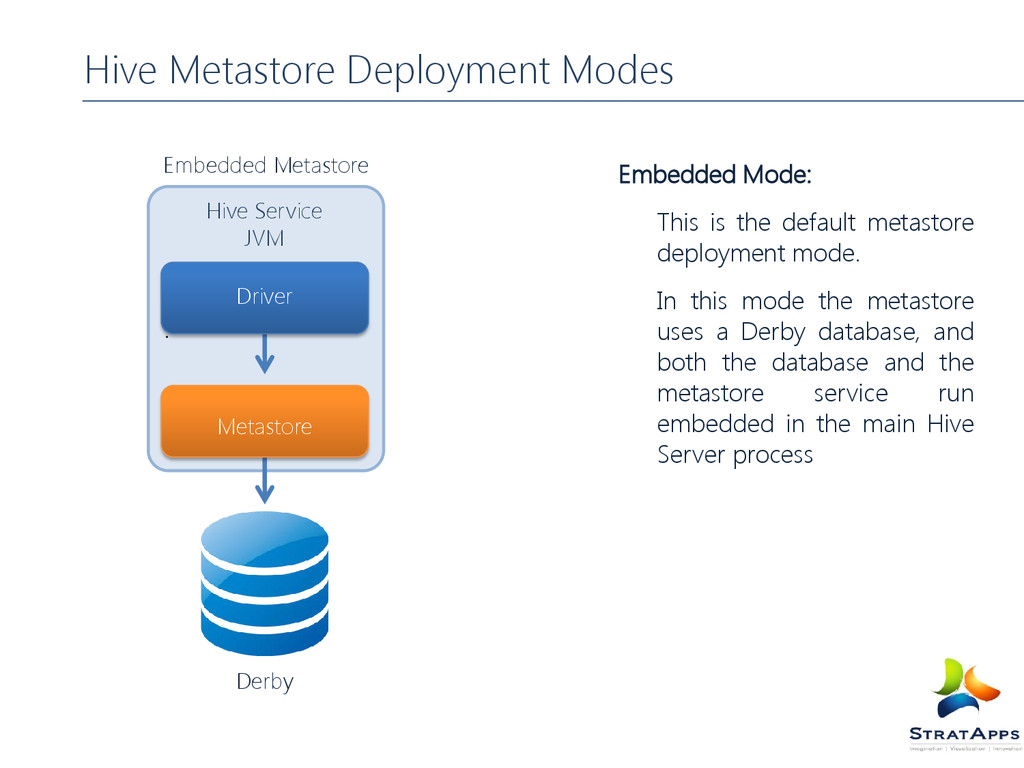
embedded Derby database. The disk storage location of this database is determined by the hive variable javax.jdo.option.ConnectionURL . By default this location is ./metastore.db As of now in default configuration, this metadata can be seen by one user at a time.
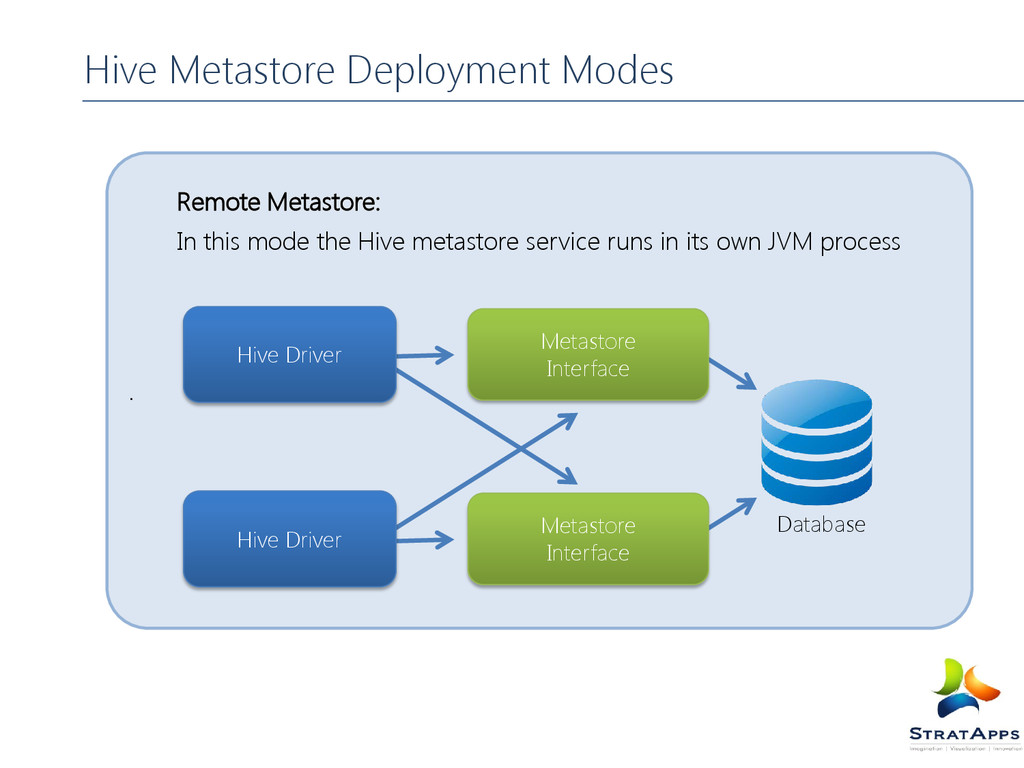
mapping to the data are stored in a Metastore. Metastore constitutes of The meta store service The database The metastore (service and database) can be configured in different ways Embedded Mode Local Mode Remote Mode
mapping to the data are stored in a Metastore. Metastore constitutes of The meta store service The database The metastore (service and database) can be configured in different ways Embedded Mode Local Mode Remote Mode
In this mode the metastore uses a Derby database, and both the database and the metastore service run embedded in the main Hive Server process Hive Metastore Deployment Modes Hive Service JVM Derby Metastore Driver Embedded Metastore
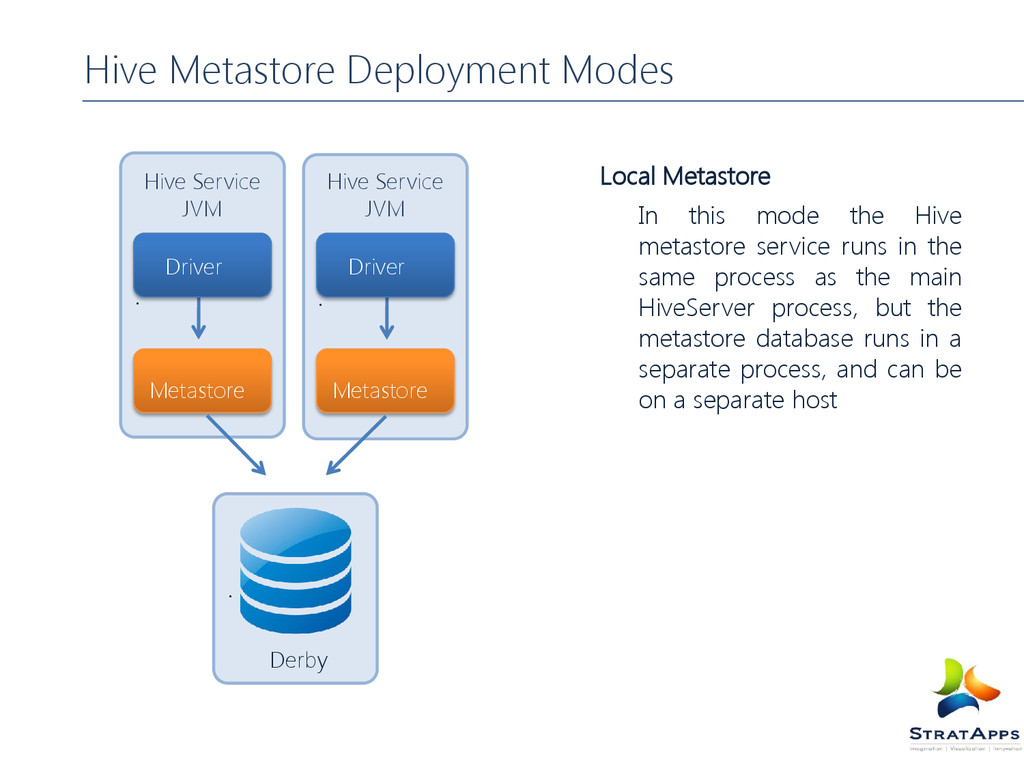
JVM Local Metastore In this mode the Hive metastore service runs in the same process as the main HiveServer process, but the metastore database runs in a separate process, and can be on a separate host Metastore Hive Service JVM Derby Driver Driver
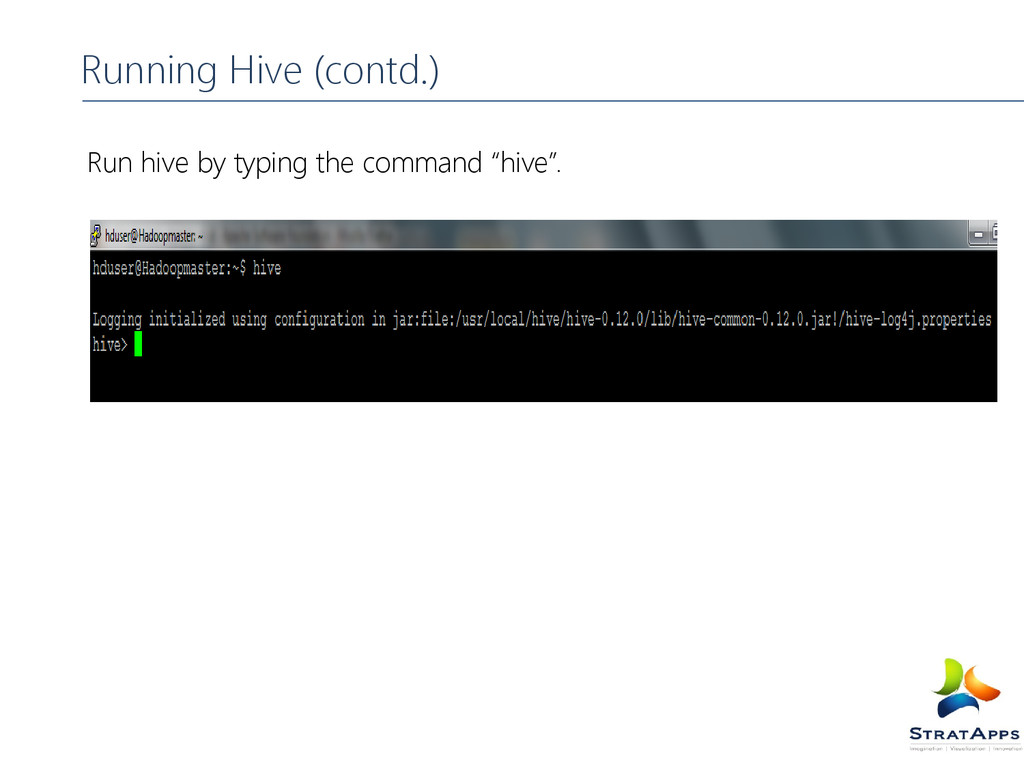
uses Hadoop. So you must have hadoop in the PATH environment variable OR export HADOOP_HOME=<hadoop-install-dir> You must have the following directories set up on the hdfs,/tmp and /user/hive/warehouse (hive.metastore.warehouse) directory on your hdfs Change the mode to g+w for this directory hadoop fs -mkdir /tmp hadoop fs -mkdir /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse Running Hive
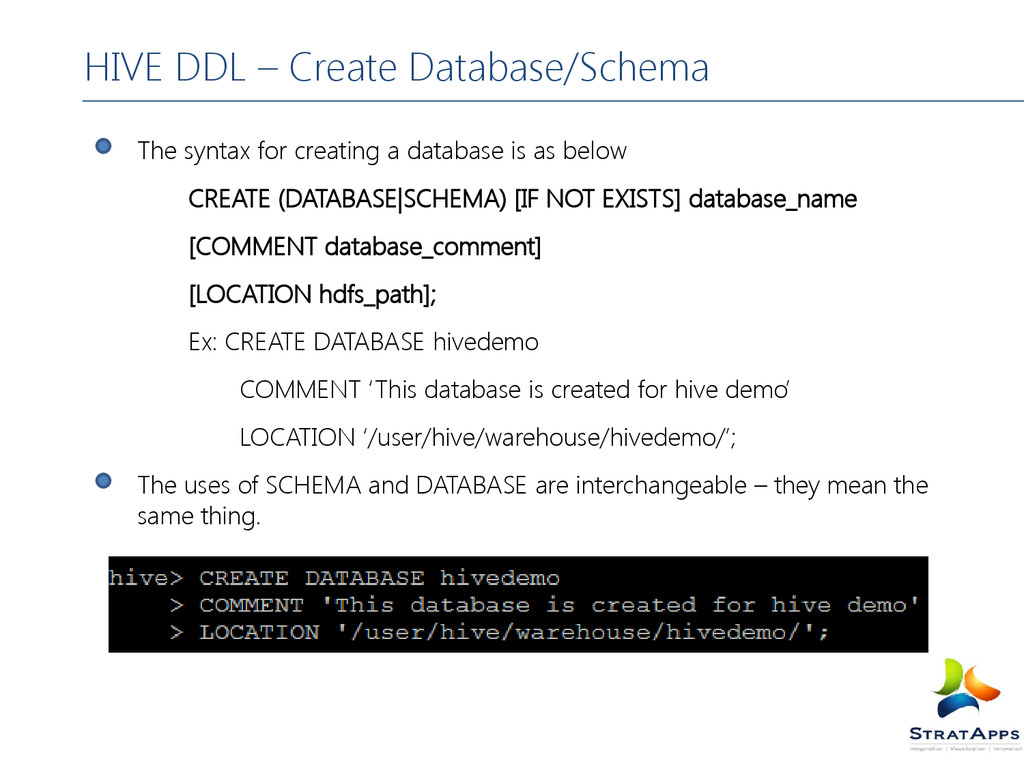
(DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path]; Ex: CREATE DATABASE hivedemo COMMENT ‘This database is created for hive demo’ LOCATION ‘/user/hive/warehouse/hivedemo/’; The uses of SCHEMA and DATABASE are interchangeable – they mean the same thing. HIVE DDL – Create Database/Schema
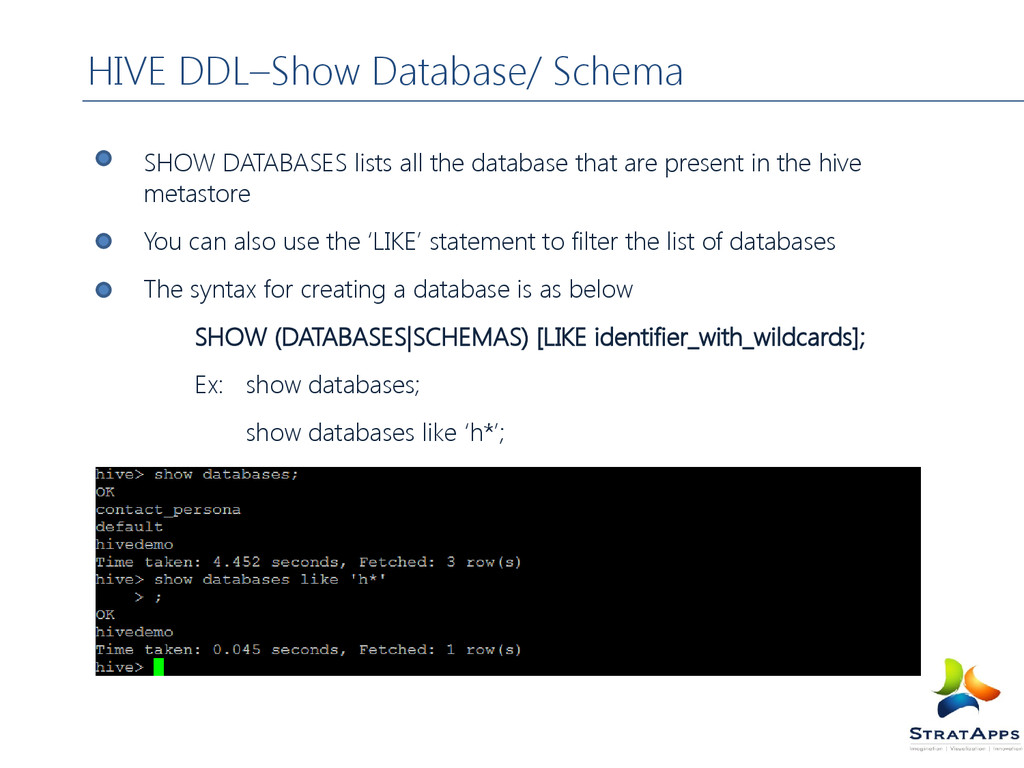
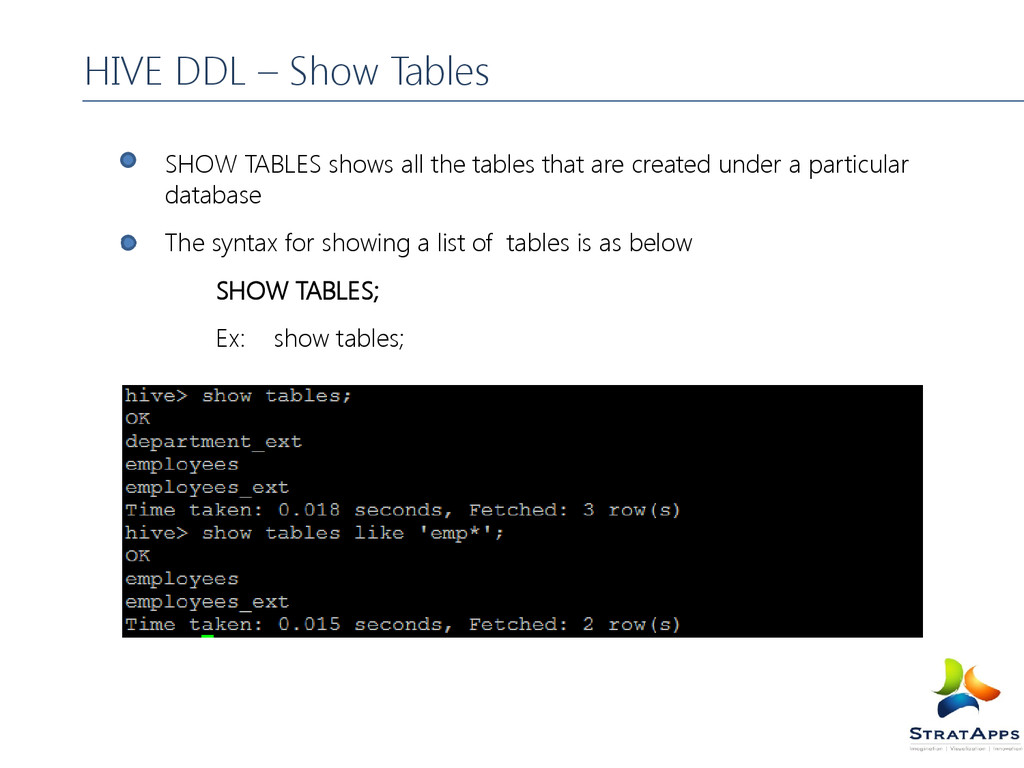
the hive metastore You can also use the ‘LIKE’ statement to filter the list of databases The syntax for creating a database is as below SHOW (DATABASES|SCHEMAS) [LIKE identifier_with_wildcards]; Ex: show databases; show databases like ‘h*’; HIVE DDL–Show Database/ Schema
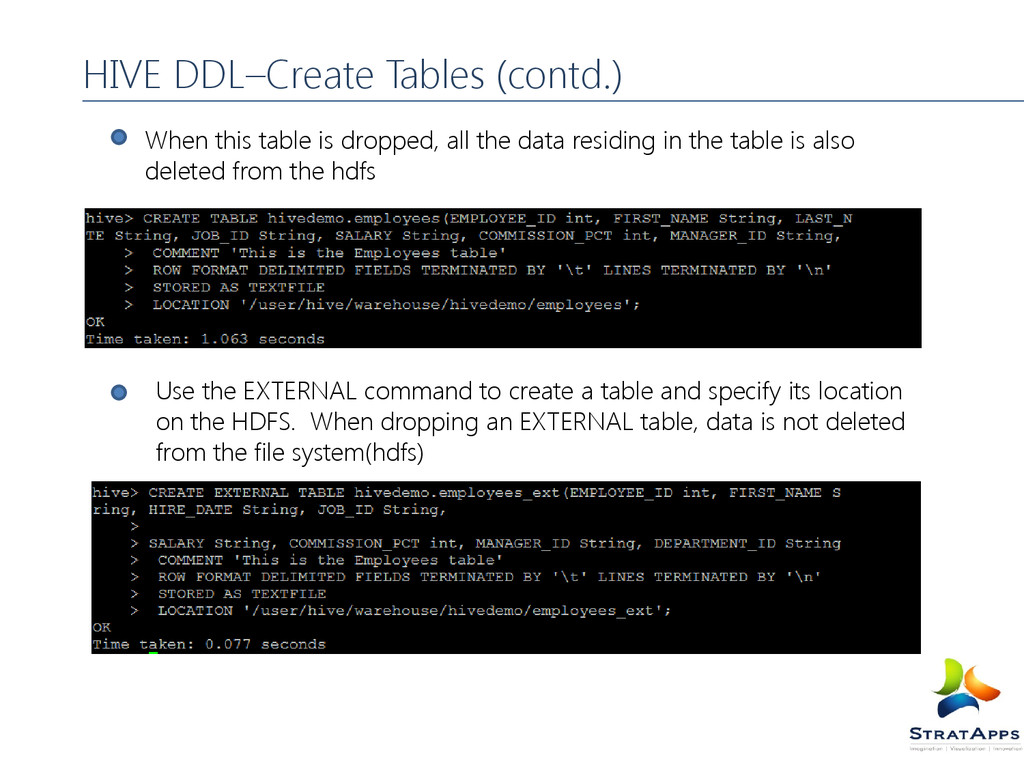
error is thrown if a table or view with the same name already exists. You can use IF NOT EXISTS to skip the error. The syntax for creating a table is as below CREATE TABLE table_name [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] Ex: CREATE TABLE hivedemo.employees (EMPLOYEE_ID int,FIRST_NAME String, LAST_NAME String, EMAIL String, PHONE_NUMBER String, HIRE_DATE String, JOB_ID String, SALARY String, COMMISSION_PCT int, MANAGER_ID String, DEPARTMENT_ID String) COMMENT 'This is the Employees table' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n’ STORED AS TEXTFILE LOCATION '/user/hive/warehouse/hivedemo/employees‘; HIVE DDL–Create Tables
the data residing in the table is also deleted from the hdfs Use the EXTERNAL command to create a table and specify its location on the HDFS. When dropping an EXTERNAL table, data is not deleted from the file system(hdfs)
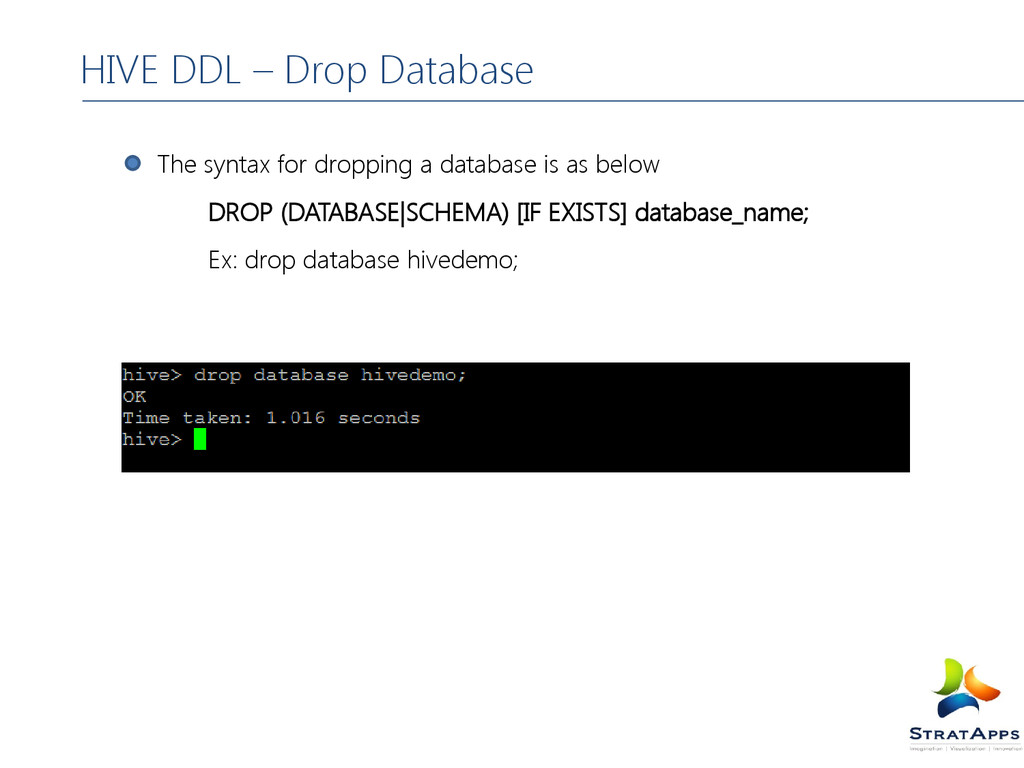
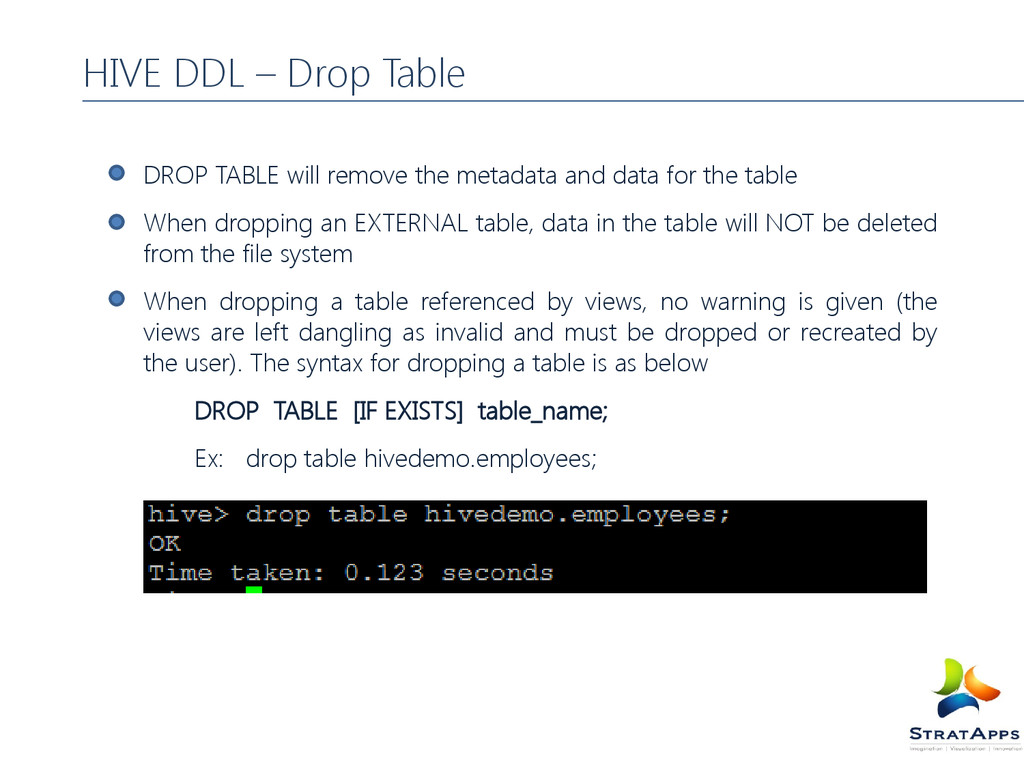
table When dropping an EXTERNAL table, data in the table will NOT be deleted from the file system When dropping a table referenced by views, no warning is given (the views are left dangling as invalid and must be dropped or recreated by the user). The syntax for dropping a table is as below DROP TABLE [IF EXISTS] table_name; Ex: drop table hivedemo.employees; HIVE DDL – Drop Table
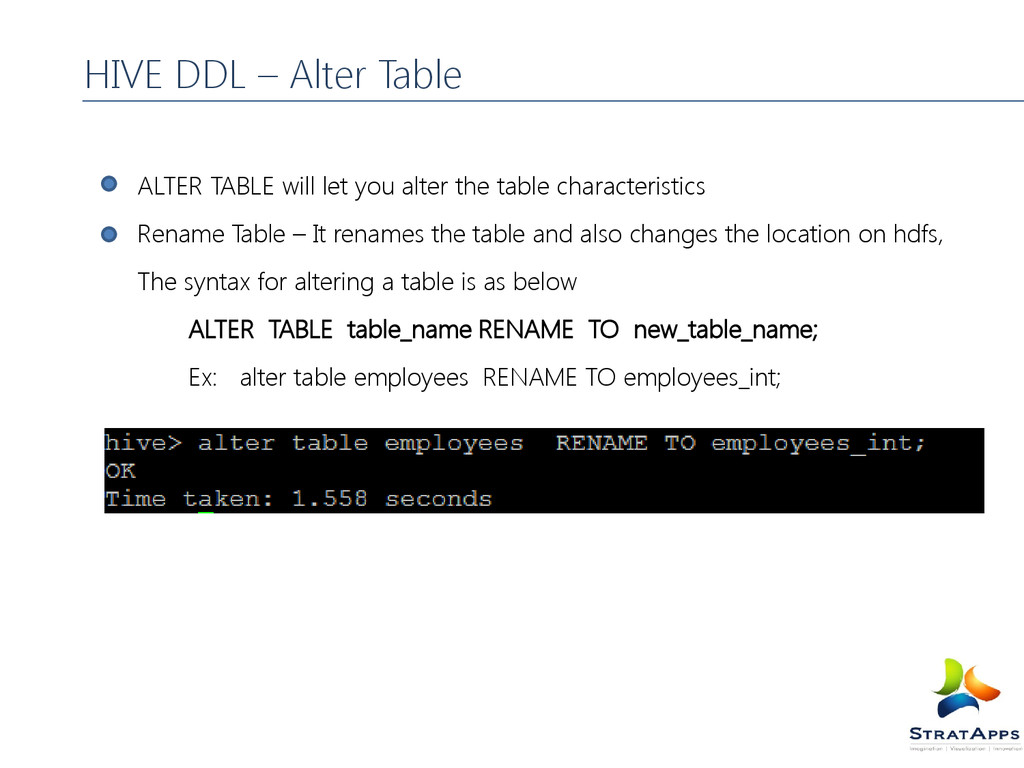
Table – It renames the table and also changes the location on hdfs, The syntax for altering a table is as below ALTER TABLE table_name RENAME TO new_table_name; Ex: alter table employees RENAME TO employees_int; HIVE DDL – Alter Table
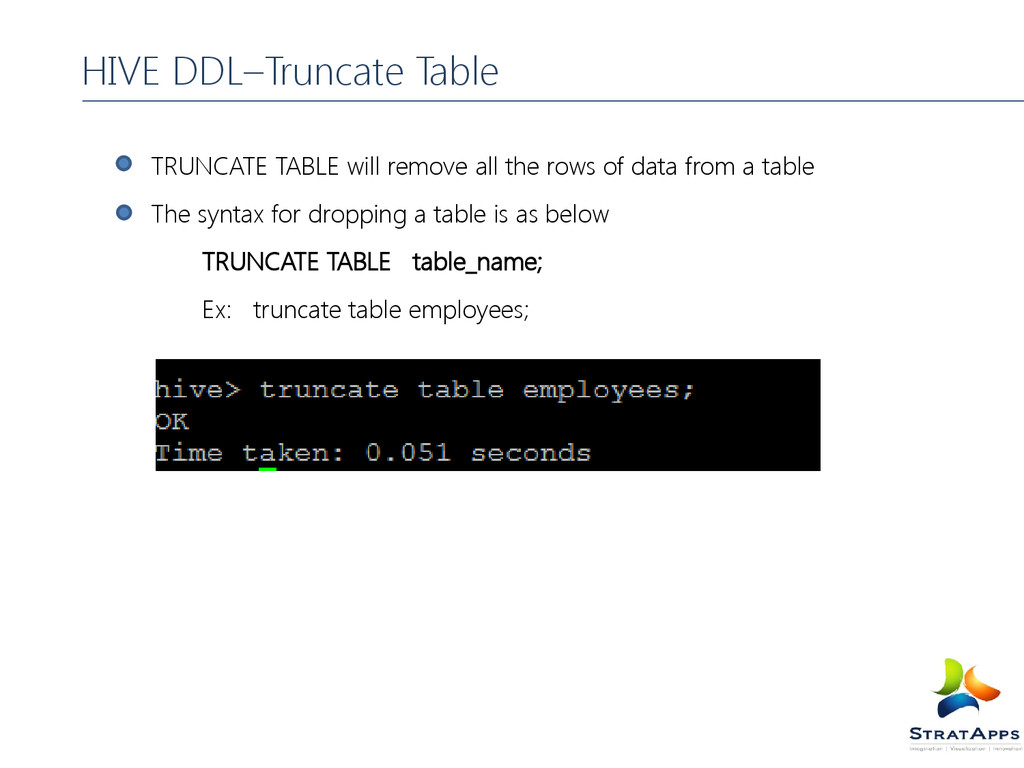
tables. Load operations are copy/move operations that move datafiles into locations corresponding to Hive tables. The syntax for loading a file into table is as below LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] Ex: LOAD DATA LOCAL INPATH '/home/hduser/Namita/hivedemo/employees.txt' INTO TABLE hivedemo.employees; LOCAL -> indicates the local file system. If not mentioned, hive will look in HDFS. OVERWRITE -> if mentioned, then overwrites the data, else keeps appendind HIVE DML–Load Files into Tables
table.not do any transformation while loading data into tables. The syntax for inserting query data into table is as below INSERT INTO TABLE tablename1 Select_statement1 FROM from_statement;I Ex: LOAD DATA LOCAL INPATH '/home/hduser/Namita/hivedemo/employees.txt' INTO TABLE hivedemo.employees; HIVE DML–Inserting Data into Hive table from queries
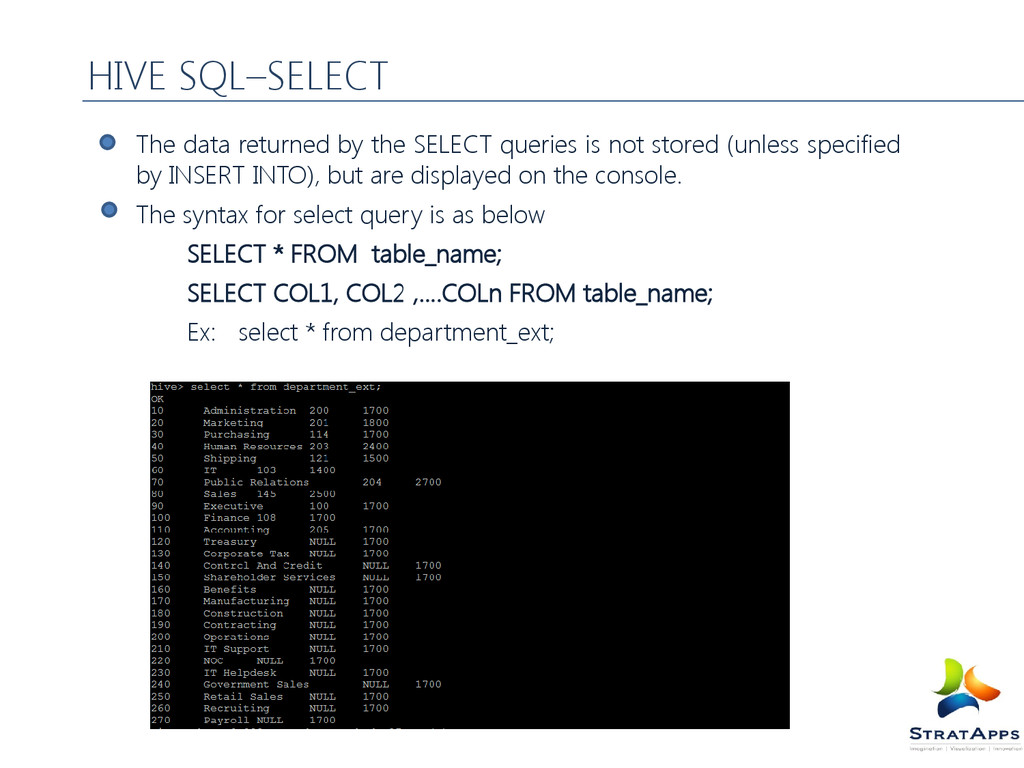
(unless specified by INSERT INTO), but are displayed on the console. The syntax for select query is as below SELECT * FROM table_name; SELECT COL1, COL2 ,.…COLn FROM table_name; Ex: select * from department_ext; HIVE SQL–SELECT
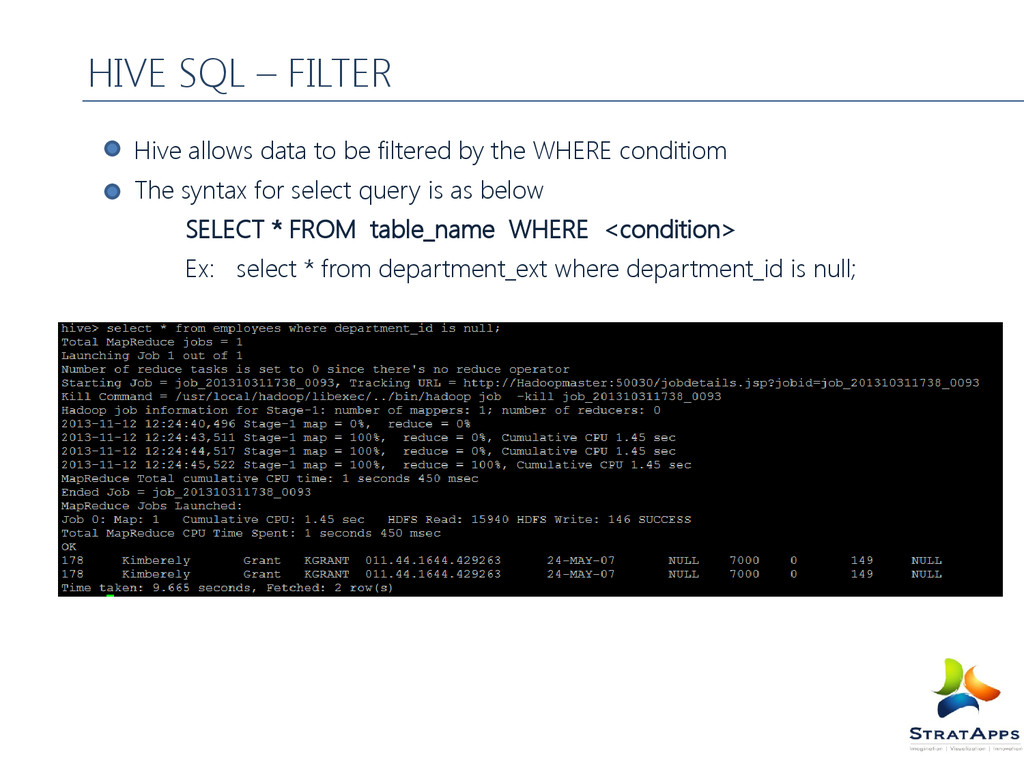
The syntax for select query is as below SELECT * FROM table_name WHERE <condition> Ex: select * from department_ext where department_id is null; HIVE SQL – FILTER
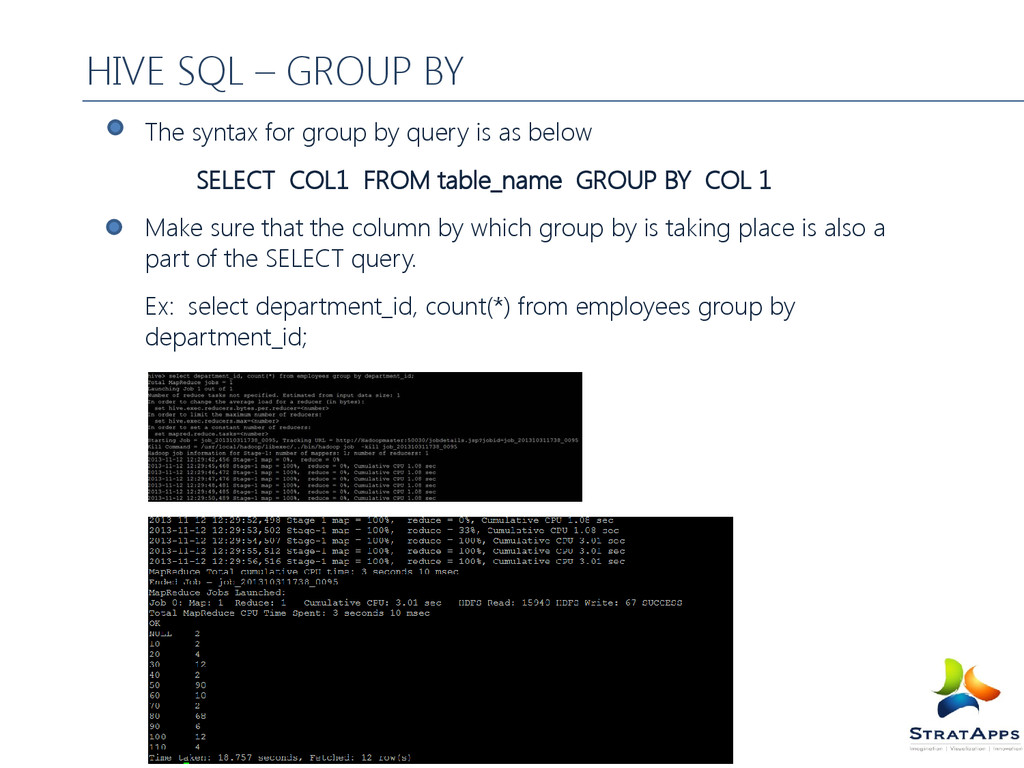
COL1 FROM table_name GROUP BY COL 1 Make sure that the column by which group by is taking place is also a part of the SELECT query. Ex: select department_id, count(*) from employees group by department_id; HIVE SQL – GROUP BY
Hive https://cwiki.apache.org/confluence/display/Hive/GettingStarted https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DML HIVE – More Information
developed by StratApps . It gives users an interface to visualize large datasets stored on Hadoop HDFS. Features of HiveDeveloper Connects to multiple databases UI like SQL developer Query data can be exported to excel All hive commands that run on console can be run via HiveDeveloper For more information and to download the tool visit http://stratapps.net/hive-developer-tool.php
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}