Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
バイオ/医療データ解析の課題と展望/Challenges and Prospects of B...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Yohei Sugawara
March 04, 2019
Technology
690
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
バイオ/医療データ解析の課題と展望/Challenges and Prospects of Biomedical Data Analysis
「白金鉱業 Meetup Vol.6」(
https://brainpad-meetup.connpass.com/event/119149/
) での発表資料
Yohei Sugawara
March 04, 2019
Other Decks in Technology
See All in Technology
ロボティクスの技術 / Robotics Technology
ks91
PRO
0
130
MySQL & MySQL HeatWave Report - June 2026
freshdaz
0
150
“詰む”前に仕組みを作れ 〜技術の波に溺れないためのキャッチアップ術〜
takasyou
7
3.9k
スタートアップにAmazon EKSは早すぎる? マルチプロダクト戦略を加速する Platform Engineeringの実践 / Is Amazon EKS Too Soon for Startups? Practical Platform Engineering to Accelerate a Multi-Product Strategy
elmodev09
1
1.8k
脱SaaS!FDEを支えるプロビジョニングと分離設計
knih
0
300
LayerX コーポレートエンジニアリング室におけるサプライチェーンセキュリティへの取り組み / Supply Chain Security at LayerX Corporate Engineering
yuyatakeyama
3
840
AIチャットの改善から見えた、良いAI体験とは / What Constitutes a Good AI Experience: Insights from Improving AI Chat
kubode
0
120
元銀行員がAIだけでアプリを量産!「バイブコーディング実演セミナー 」
tatsuya1970
0
110
40代で“やっとエンジニアになれた”――閉じた学びを開き、空の青さを知る / 20260628 Naoki Takahashi
shift_evolve
PRO
4
890
「軸足」は 固定しなくていい - 熱量と強みで描く、しなやかなキャリアの形
kakehashi
PRO
1
270
Comment regagner la souveraineté de vos données tout en étant payé grâce à Nostr !
rlifchitz
0
200
Microsoft のサポートとフィードバック総まとめ
murachiakira
PRO
0
110
Featured
See All Featured
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Code Reviewing Like a Champion
maltzj
528
40k
Become a Pro
speakerdeck
PRO
31
6k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Practical Orchestrator
shlominoach
191
11k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
150
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
BBQ
matthewcrist
89
10k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.7k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.8k
Crafting Experiences
bethany
1
190
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
220
Transcript
バイオ/医療データ解析の課題と展望 Preferred Networks, Inc. Engineer 菅原 洋平 2019.03.04 / 白金鉱業
Meetup Vol.6
はじめに • 本発表の内容は個人の見解であり,所属組織を代表するものではありません. 一部編集を加えて,資料は公開予定です. • 本資料は,厳密さよりも分かりやすさを優先した記述を含んでいます. ご理解の程,何卒宜しくお願い申し上げます.
自己紹介 ★ 氏名: 菅原 洋平 ★ SNS: ◦ Twitter: @ywara93
◦ Facebook: ywara93 ◦ GitHub: suga93 ★ 略歴: ◦ 2015/3: 慶應義塾大学大学院理工学研究科基礎理工学専攻 後期博士課程単位取得退学 ◦ 2015/4 ~2017/4: BrainPad Inc.(新卒入社) ▪ ML/DLの実用化に向けた研究開発(画像解析,自然言語処理, etc) ◦ 2017/5~: Preferred Networks, Inc.(現職) ▪ ML/DLのバイオ・ヘルスケア領域への応用 ▪ メディカルAI学会オンライン講座資料作成 ★ 趣味: 料理,コーヒー(お気に入り店:Cafe Kuromimi Lapin @白金台)
弊社ライフサイエンス事業の紹介
Table of Contents 1) バイオ/医療データ解析概観 a) 「マルチオミックス解析」による「予測・予防・個別化医療」 b) 各研究領域における DL技術の応用事例
2) バイオ/医療データ解析の課題と展望 a) データ収集コスト,データ構造化 b) アノテーションコスト c) ラベル不均衡 d) 透明性(ブラックボックスモデル) e) 前処理,ドメイン知識
バイオ/医療データ解析概観
「マルチオミックス解析」による「予測・予防・個別化医療」 • オミックス(omics)とは ◦ 元々はギリシャ語の「すべて・完全」などを意味する接尾辞 (ome)に「学問」を意味する接尾辞 (ics)を合 成した言葉 (Wikipediaより) ◦
転じて,「対象とする生体分子等に関する知識や解析など,網羅的情報の総体」を指す用語 ▪ 遺伝子(gene) ⇒ Genomics ▪ 転写産物 (RNA etc) ⇒ Transcriptomics ▪ タンパク質 (protein) ⇒ Proteomics ▪ 代謝産物 (metabolite) ⇒ Metabolomics ▪ エピゲノム (epigenome) ⇒ Epigenomics ◦ 最近では,生体分子だけでなく解析対象の総体を指す用語としても使われ始めている ▪ 細菌叢 (腸内細菌等) ⇒ Metagenomics (Microbiomics) ▪ 放射線医学 (radiology) ⇒ Radiomics ▪ 病理学 (pathology) ⇒ Pathomics (omics一覧:https://en.wikipedia.org/wiki/List_of_omics_topics_in_biology)
「マルチオミックス解析」による「予測・予防・個別化医療」 • 「予測・予防・個別化医療 (PPPM)」とは ◦ 予測 (Predictive) ▪ 遺伝子検査,抗体検査などによって特定の病気の罹患リスク判定,発症診断,発 症前の早期診断を行うこと
◦ 予防 (Preventive) ▪ 予測に基づいて,発症前,発症早期の段階で治療・予防に介入すること ◦ 個別化 (Personalized) ▪ 患者個々人に最適な治療方法を選択すること
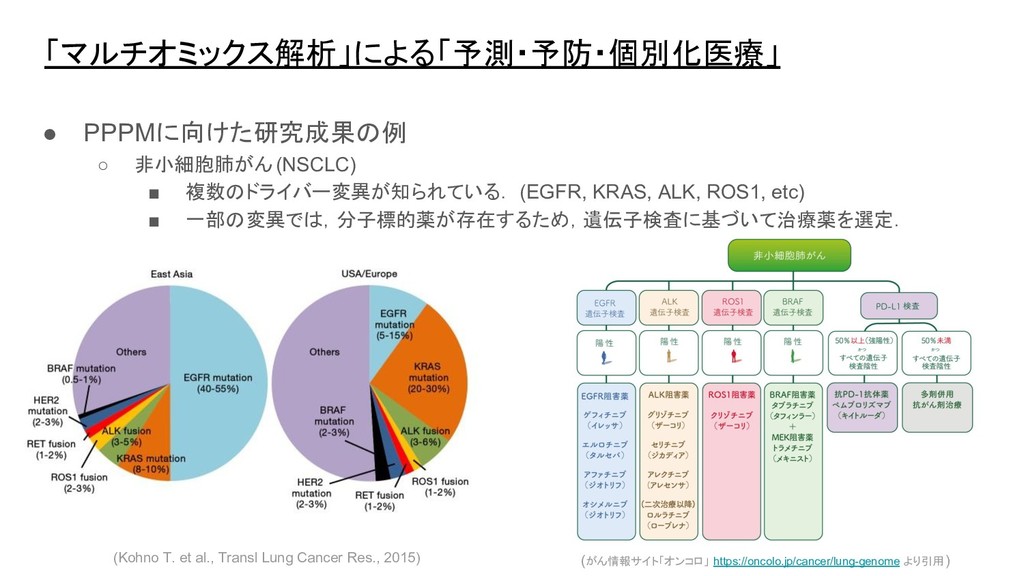
「マルチオミックス解析」による「予測・予防・個別化医療」 • PPPMに向けた研究成果の例 ◦ 非小細胞肺がん(NSCLC) ▪ 複数のドライバー変異が知られている. (EGFR, KRAS, ALK,
ROS1, etc) ▪ 一部の変異では,分子標的薬が存在するため,遺伝子検査に基づいて治療薬を選定. (Kohno T. et al., Transl Lung Cancer Res., 2015) (がん情報サイト「オンコロ」 https://oncolo.jp/cancer/lung-genome より引用)
「マルチオミックス解析」による「予測・予防・個別化医療」 (“The crucial role of multiomic approach in cancer research
and clinically relevant outcomes”, Lu M and Zhan X, EPMA Journal, 2018) • ゲノミクス ⇒ マルチオミックス Radiogenomics Proteogenomics • オミックス解析の融合
「マルチオミックス解析」による「予測・予防・個別化医療」 (“The crucial role of multiomic approach in cancer research
and clinically relevant outcomes”, Lu M and Zhan X, EPMA Journal, 2018) • ゲノミクス ⇒ マルチオミックス Radiogenomics Proteogenomics • オミックス解析の融合 マルチオミックス解析によって,PPPMをよ り精密なものにしていきたい ⇒ 各々の領域の発展が重要
各研究領域におけるDL技術の応用事例 • (ゲノム)変異コール ◦ DeepVariant (https://github.com/google/deepvariant) (Shanrong Zhao et al.,
Cloud Computing for Next-Generation Sequencing Data Analysis, 2017 ) 既存手法の多くは統計モデルベース DeepVariant ⇒ CNNで学習 (Ryan Poplin et al., bioRxiv, 2016)
各研究領域におけるDL技術の応用事例 • タンパク質立体構造予測 ◦ AlphaFold ▪ CASP (Critical Assessment of
techniques for protein Structure Prediction)という隔年開催のタンパク 質立体構造予測コンテストで2位を引 き離して優勝 ▪ 手法のアブストは掲載されている (http://predictioncenter.org/casp13/doc/CAS P13_Abstracts.pdf )
各研究領域におけるDL技術の応用事例 • メディカルAI学会オンライン講義資料 ( https://japan-medical-ai.github.io/medical-ai-course-materials/index.html ) ◦ 5章 ▪ 心臓MRI画像の左心室セグメンテーション
◦ 6章 ▪ 血液の顕微鏡画像からの細胞検出(物体検知) ◦ 7章 ▪ DNA塩基配列からの発現量予測(エピゲノム解析) ◦ 8章 ▪ 心電図波形データからの不整脈予測
バイオ/医療データ解析の課題と展望
バイオ/医療データ解析の課題 • バイオ/医療データを解析する際に発生する課題 (色々あるが全て列挙するときりがないので,本日は以下のトピックについて) ◦ データ収集コスト,データ構造化 ◦ アノテーションコスト ◦ ラベル不均衡
◦ 透明性(ブラックボックスモデル) ◦ 前処理,ドメイン知識
バイオ/医療データ解析の課題 • データ収集コスト,データ構造化 ▪ 前向き研究(prospective study)と後ろ向き研究(retrospective study) • 後ろ向き研究:仮説を立てて,比較検証に合うデータを収集 ◦
医療データの多くは,施設ごとに日々の診療の中で蓄積されてきたもの ◦ 各種バイアスが存在 ⇒ 適切な仮説の設定,データハンドリング • 前向き研究(コホート研究) :仮説検証のためにデータを前向きに収集 ◦ 費用と時間を要する ◦ 交絡因子が発生しないような研究デザインが必要 ▪ 膨大な所見テキストデータはあるが,自由記述形式(非構造化データ) • 専門用語,省略表現,列挙型の記述,単位, ... etc ◦ BERT先生に何とかして欲しいが,そう簡単にはいかないだろう ▪ 最近,BioBERTというのも出てきた(英語) https://arxiv.org/abs/1901.08746 • Stanfordが公開した単純X線画像データセット(CheXpert)のラベルは所見レポートから自 動抽出 (https://github.com/stanfordmlgroup/chexpert-labeler )
バイオ/医療データ解析の課題 • アノテーションコスト ▪ 医用画像データはたくさんあるが,アノテーションは付けられていない • 一般画像の場合,正解ラベル作成は比較的容易.医用画像の場合,正解 ラベルを作成できる人材が放射線科医等に限定されてしまう. • 展望(期待込み)
仕組み(制度) • 放射線科医等の専門家以外でも, 訓練を受けた人がアノテーション作 成に参加しやすい環境 • アノテーション作成作業に対する対 価(現状は,日常診療の中で蓄積さ れたものを利用するか,医師や分 析官がボランティアで作成するよう なケースが多い印象) • アノテーション作成を支援する機械学習的な アプローチ(主にセグメンテーション ) ◦ Interactive Full Image Segmentation ( https://arxiv.org/abs/1812.01888 ) ◦ Unsupervised Segmentation • 教師なし表現学習手法 ◦ Self-supervised Learning • 教師なしドメイン適応 技術 (Cheng Chen et al., MICCAI2018)
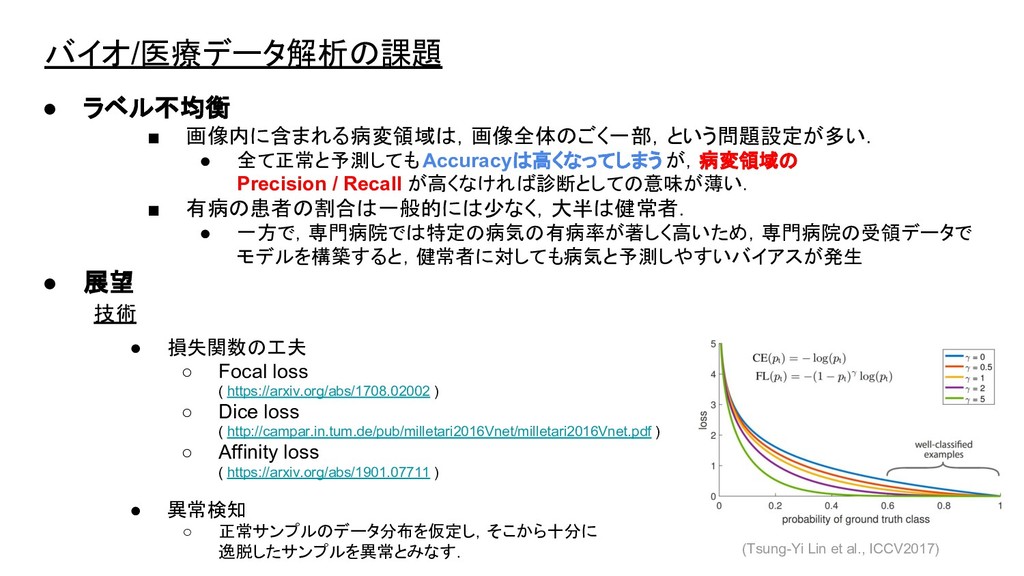
バイオ/医療データ解析の課題 • ラベル不均衡 ▪ 画像内に含まれる病変領域は,画像全体のごく一部,という問題設定が多い. • 全て正常と予測しても Accuracyは高くなってしまうが,病変領域の Precision /
Recall が高くなければ診断としての意味が薄い. ▪ 有病の患者の割合は一般的には少なく,大半は健常者. • 一方で,専門病院では特定の病気の有病率が著しく高いため,専門病院の受領データで モデルを構築すると,健常者に対しても病気と予測しやすいバイアスが発生 • 展望 技術 • 損失関数の工夫 ◦ Focal loss ( https://arxiv.org/abs/1708.02002 ) ◦ Dice loss ( http://campar.in.tum.de/pub/milletari2016Vnet/milletari2016Vnet.pdf ) ◦ Affinity loss ( https://arxiv.org/abs/1901.07711 ) • 異常検知 ◦ 正常サンプルのデータ分布を仮定し,そこから十分に 逸脱したサンプルを異常とみなす. (Tsung-Yi Lin et al., ICCV2017)
バイオ/医療データ解析の課題 • 透明性(ブラックボックスモデル) ▪ 深層学習を始めとする機械学習の多くの手法において,学習結果として得られた識別 ルールが人間にとって解釈困難であることが指摘されている. ▪ 一方,医療現場においては,診断の透明性や説明責任が強く要請される. • 展望
運用 • 「AIが医師の仕事を奪う」ではなく, 「技術が医師の仕事をサポートする」を目指す ◦ モデルの予測だけで意思決定を行うのでは なく,最終的に医師が介在する,等 技術 • 予測の判断基準を可視化 ◦ Grad-CAM / Grad-CAM++ ( https://arxiv.org/abs/1610.02391 ) ( https://arxiv.org/abs/1710.11063 ) ◦ BayesGrad (共著論文) (https://arxiv.org/abs/1807.01985 ) ◦ LIME, SHAP etc... (Pranav Rajpurkar, Andrew Ng et al., 2017)
バイオ/医療データ解析の課題 • 前処理,ドメイン知識 ◦ 画像解析の場合,CNNでうまくいってしまうタスクも多いが,その他の多くのデータにおいては,前 処理やドメイン知識を適切に取り込むこと(データの性質理解)が重要となる. ▪ DLのネットワーク構造をデータの性質に合わせて設計 ▪ 前処理も含めて深層学習でモデル化するような研究例もある.
• 展望 実践 • データの中身を確認する • 専門家とのコミュニケーション 技術 • DNA配列において遠い位置にある配列間の関係を モデル化するためにdilated convolutionを利用 (メディカルAI学会オンライン講座7章) • 心電図波形データは高周波/低周波のノイズが乗る 可能性があるため,ノイズ除去に線形フィルタ利用 (メディカルAI学会オンライン講座8章) • SincNet: 音声データをCNNで学習する際に,線形 フィルタも学習. ( https://arxiv.org/abs/1808.00158 )
まとめ バイオ/医療データ解析の概観 • マルチオミックス解析によって個別化医療の精密化が期待されている • 深層学習技術のバイオ/医療データへの応用事例が増えている ◦ 画像診断だけでなく,ゲノム解析や創薬等の研究領域でも盛んに活用 され始めている バイオ/医療データ解析の課題と展望
• 本発表で取り上げた課題(実際は他にもたくさんある) 1. データ収集・構造化,2. アノテーションコスト,3. ラベル不均衡,4. 透明性,5. 前処理・ドメイン知識 ◦ 仕組みや運用面で改善できる部分もある(はず) ◦ 機械学習(深層学習)を活用して,技術的に改善する方法も模索されている
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}