This presentation introduces the St8 server, an open-source, REST-enabled storage service built using Jersey, Jetty, Guice, and most importantly, HailDB (formerly Embedded InnoDB). We describe interfacing HailDB with Java using JNA, and review benchmarks showing just how fast the service can be (including SSD as well as single-disk and RAID0 benchmarks). We also review a few use cases that are possible by using HailDB outside the context of SQL, such as high-performance counters and more efficient updates.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
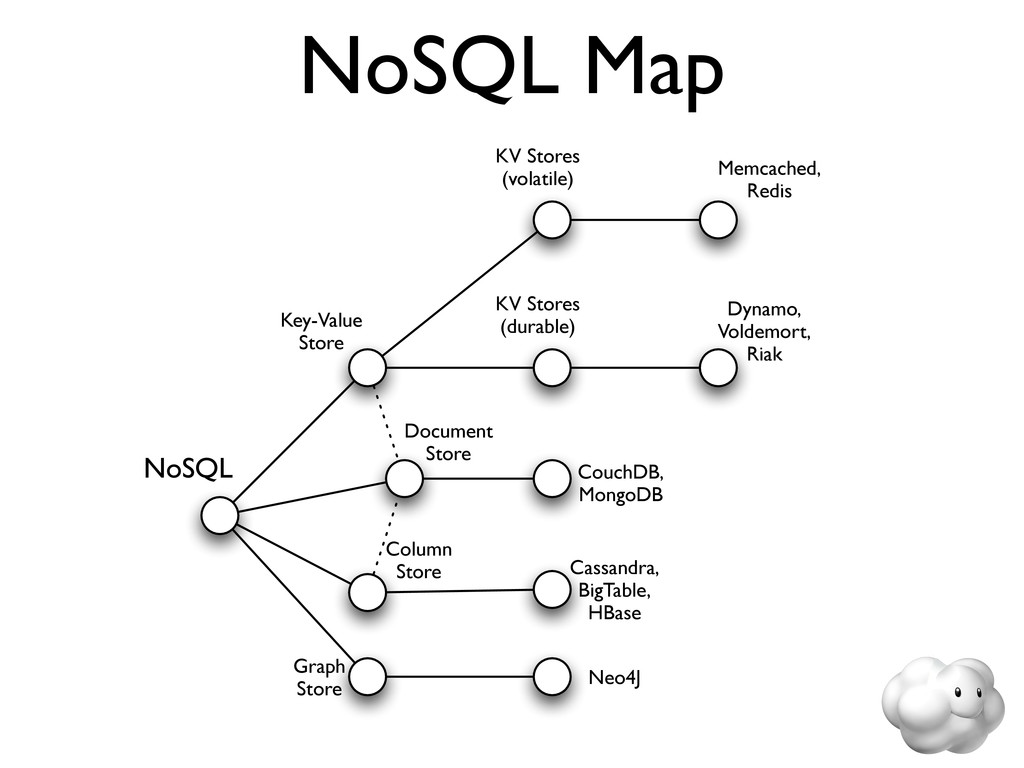{kind=link}
{kind=link}
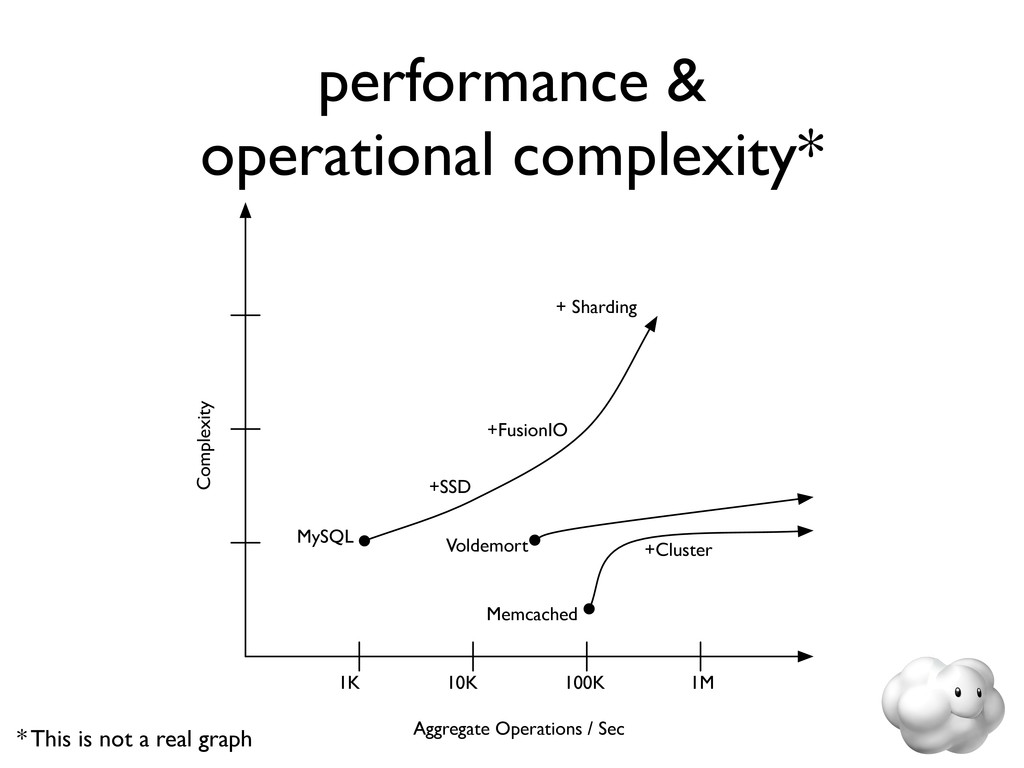{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![high-performance counts • GET /1.0/counts/mykey 0 • POST /1.0/counts/mykey[?inc=1] 1](https://files.speakerdeck.com/presentations/5febf1f08f290130e3e222000a8e94b5/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
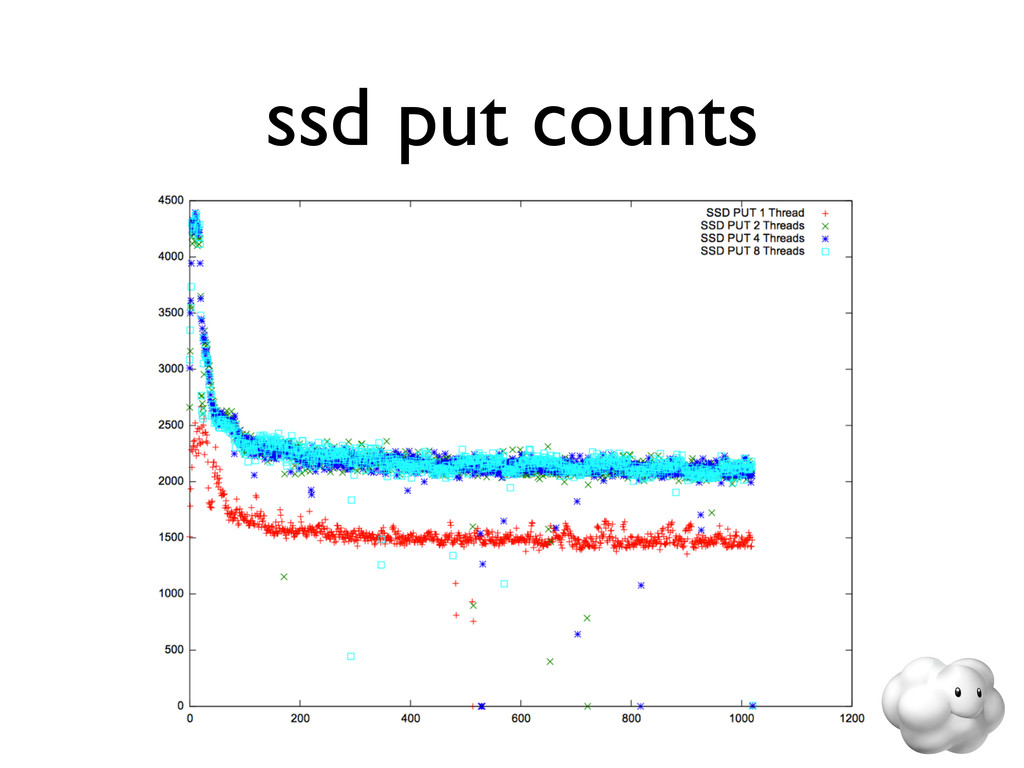{kind=link}
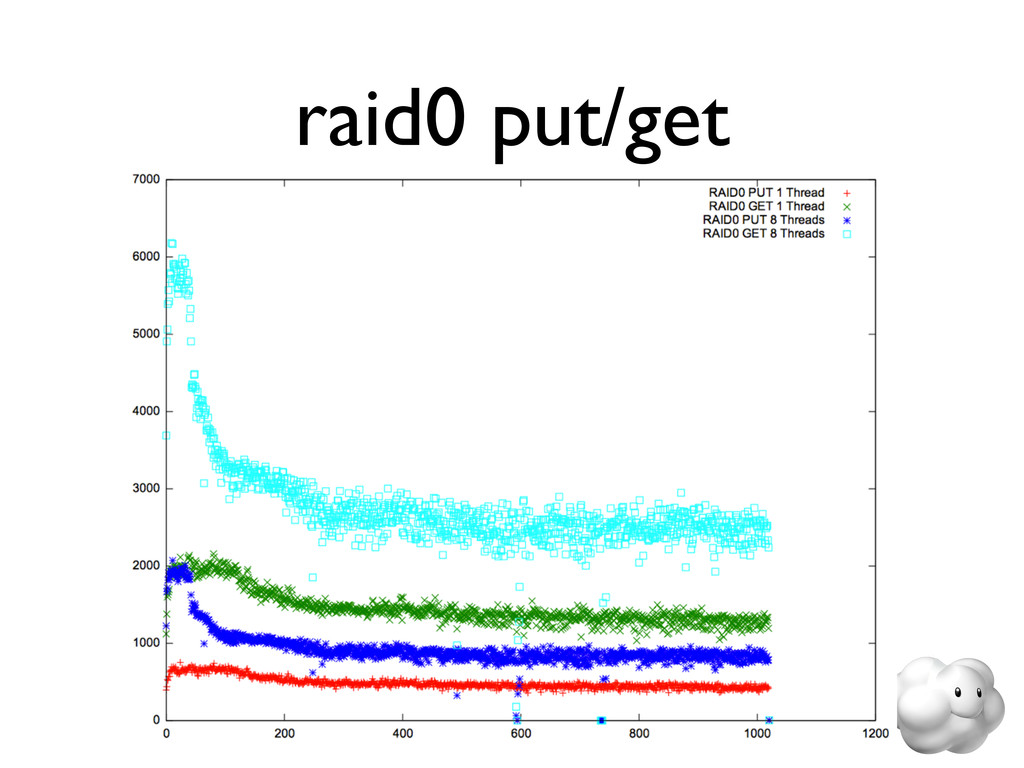{kind=link}
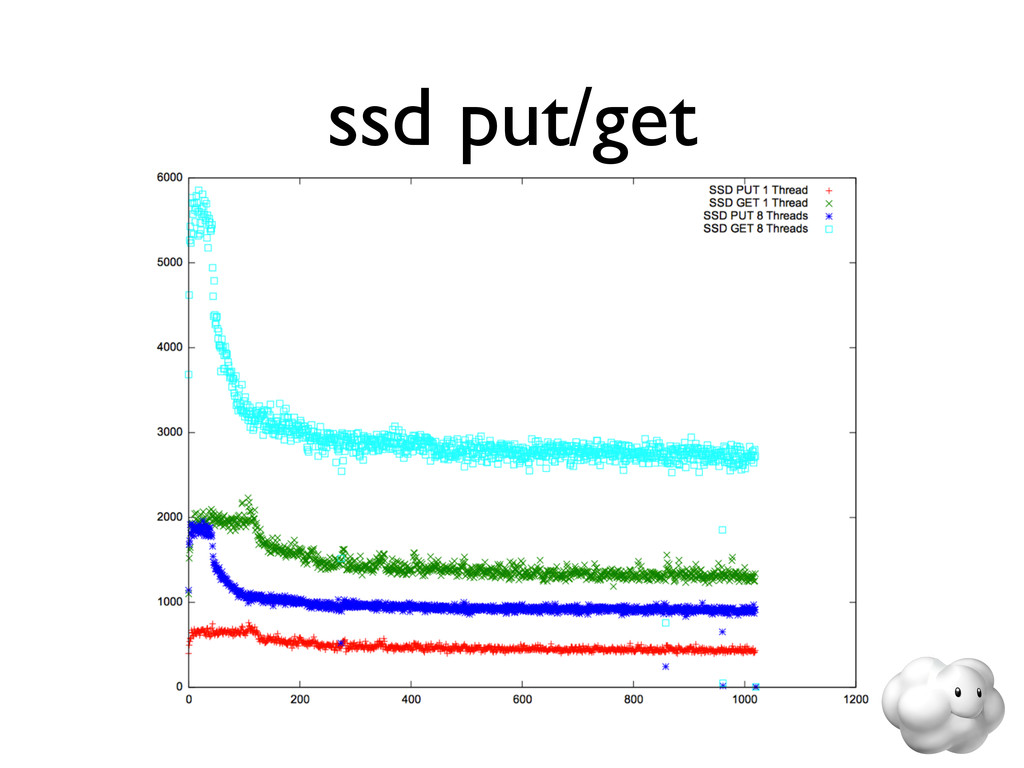{kind=link}
{kind=link}
![nifty graph store 1 GET /1.0/graph/bfs?a=1&maxDepth=3 => [[1, 0], [2,](https://files.speakerdeck.com/presentations/5febf1f08f290130e3e222000a8e94b5/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}