Talk at MLconf Atlanta 2015 about the machine learning techniques used at Wildcard to do Structured Learning without Conditional Random Fields but with a trick from Deep Learning.
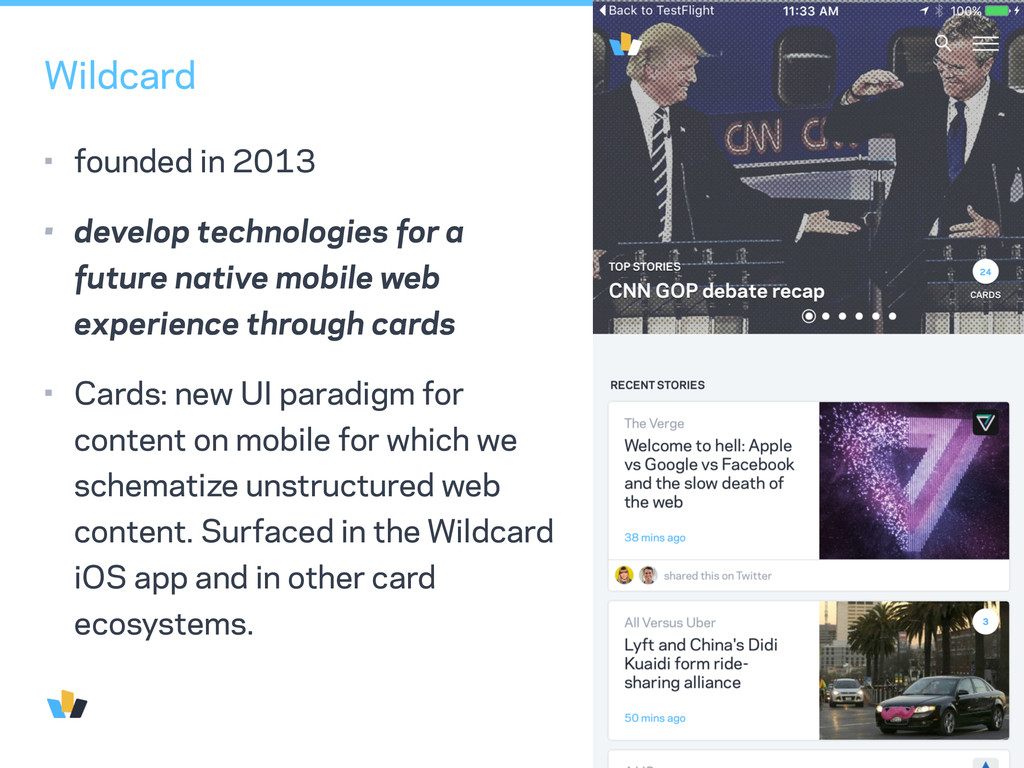
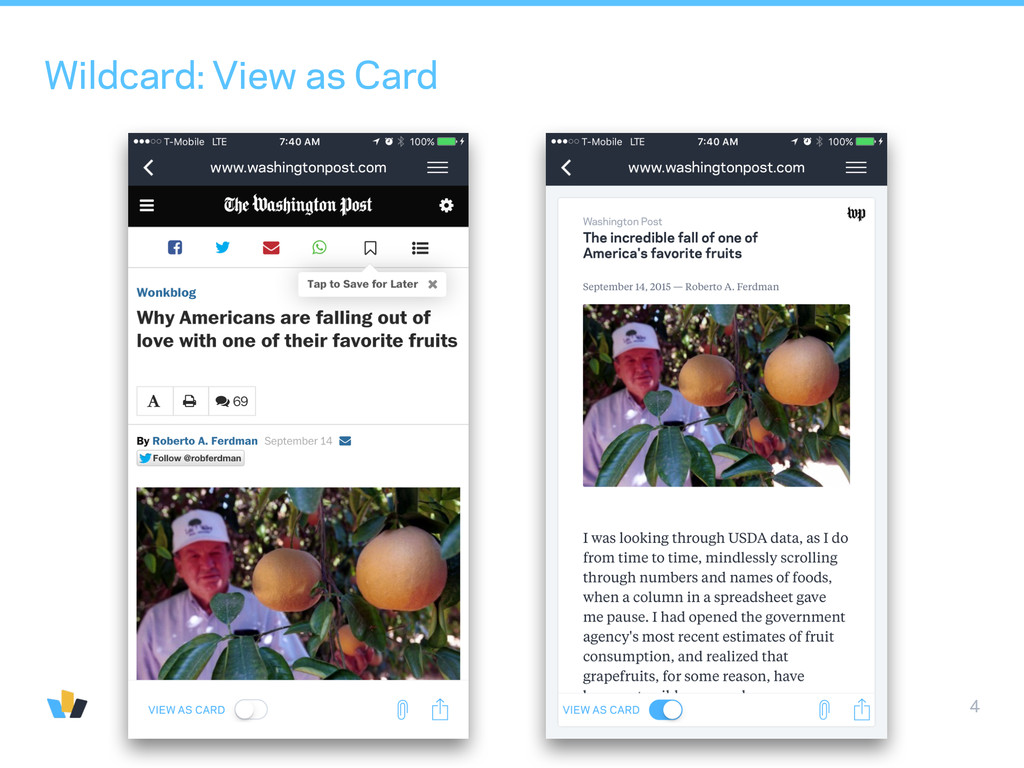
a future native mobile web experience through cards • Cards: new UI paradigm for content on mobile for which we schematize unstructured web content. Surfaced in the Wildcard iOS app and in other card ecosystems.
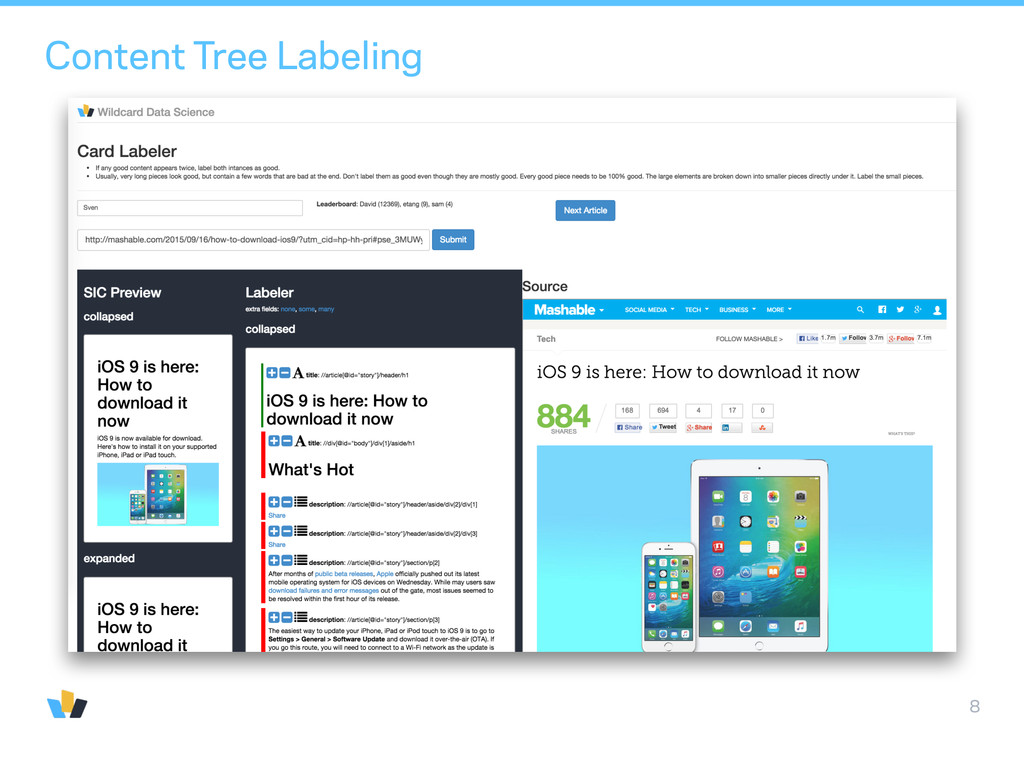
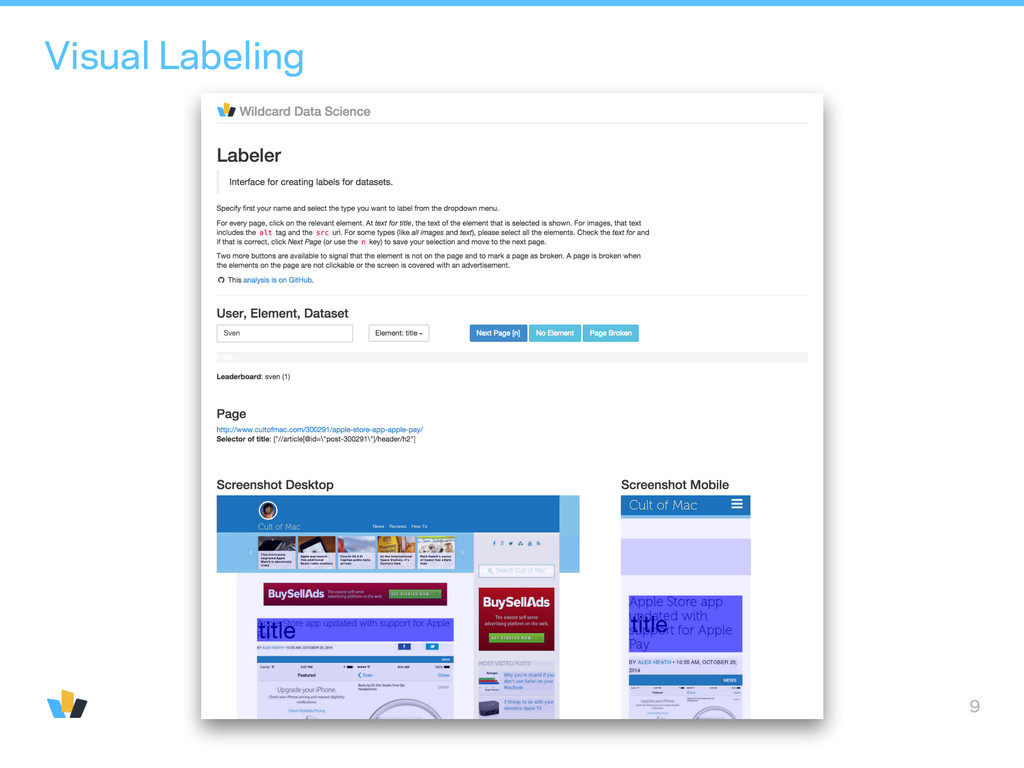
first 20 char identical to page’s meta title, … • BoW text: bag-of-words visible text • BoW meta: bag-of-words of CSS classes and other non-visible information inside HTML tags • html tag • Optional info from emulation: (x, y), (w, h), font-family, font-size, font-weight, …
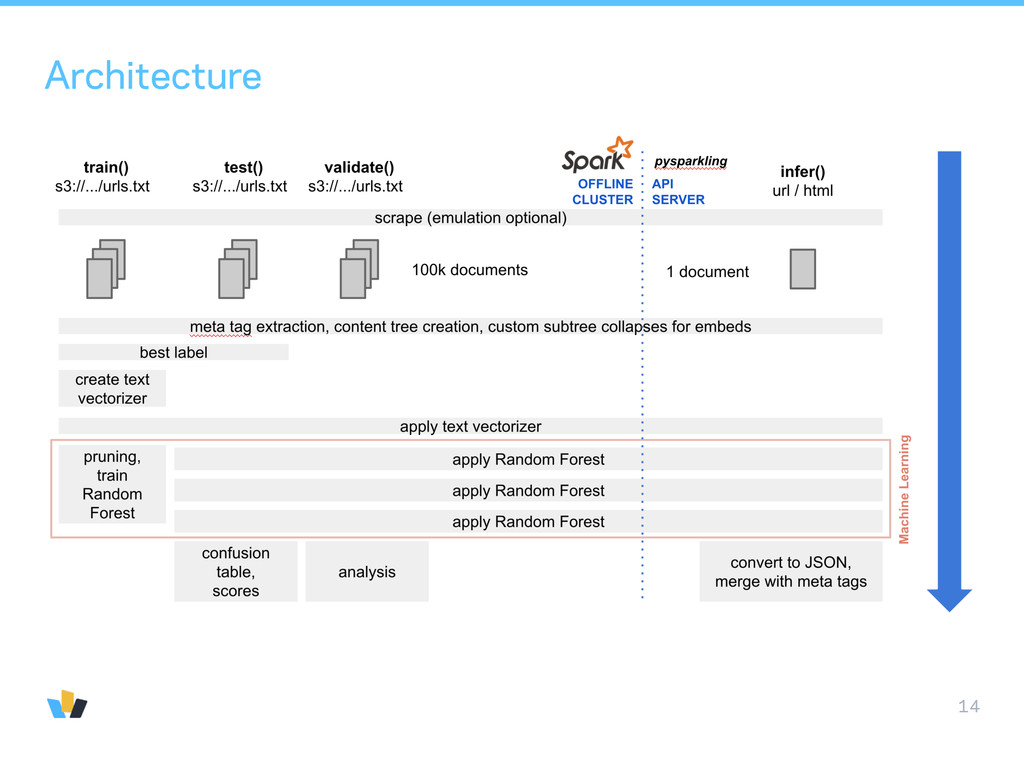
Spark. Starts from a list of urls. • Scrapes web pages. • Constructs Content Tree. • Matches labels. • Filters for quality. • Need the same processing for a single webpage but with low latency and small resource requirements: → pysparkling: pure Python implementation of Spark’s RDD interface
no dependence on the JVM • pysparkling.fileio can access local files, S3, HTTP, HDFS with a load-dump interface • used in Python micro-service endpoint applying scikit-learn classifiers • used in labeling and evaluation tools and local development • used in dataset preparation tools (train-test split, split urls by domain, …)
“256Gb ought to be enough for anybody” (for machine learning) - Andreas Mueller • multithread support, fast • use provided structured data (e.g. meta tags) as much as possible
Pellentesque odio nisi, euismod in, pharetra a, ultricies in, diam. • Praesent dapibus, neque id cursus faucibus. • Phasellus ultrices nulla quis nibh. Quisque a lectus.
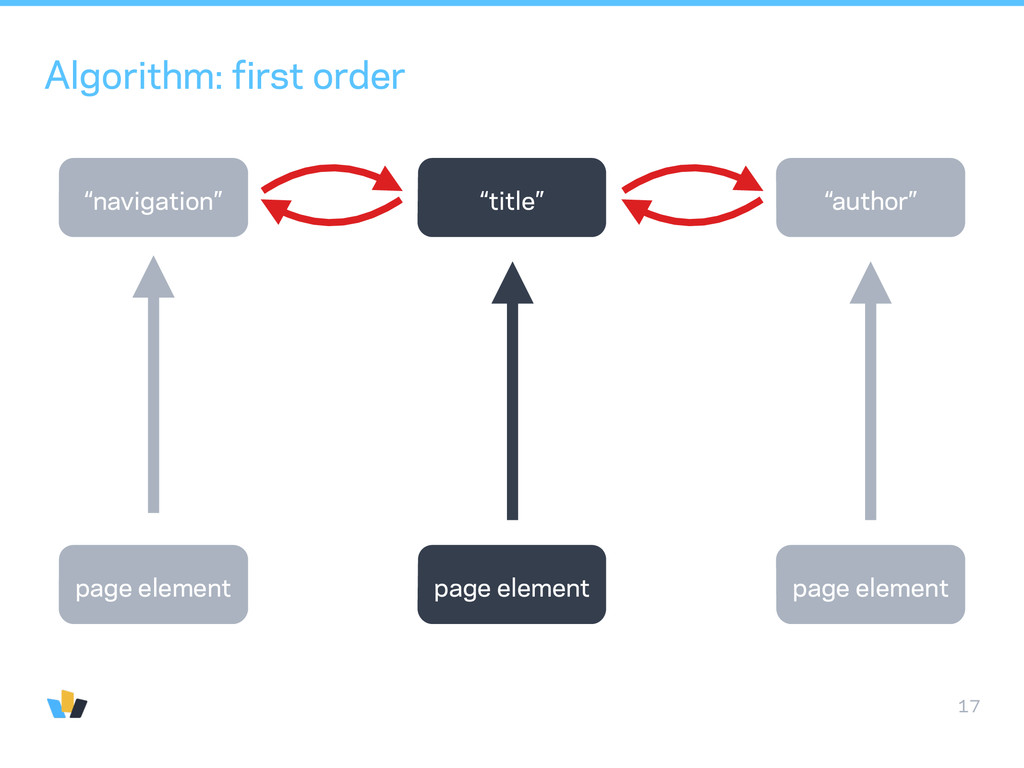
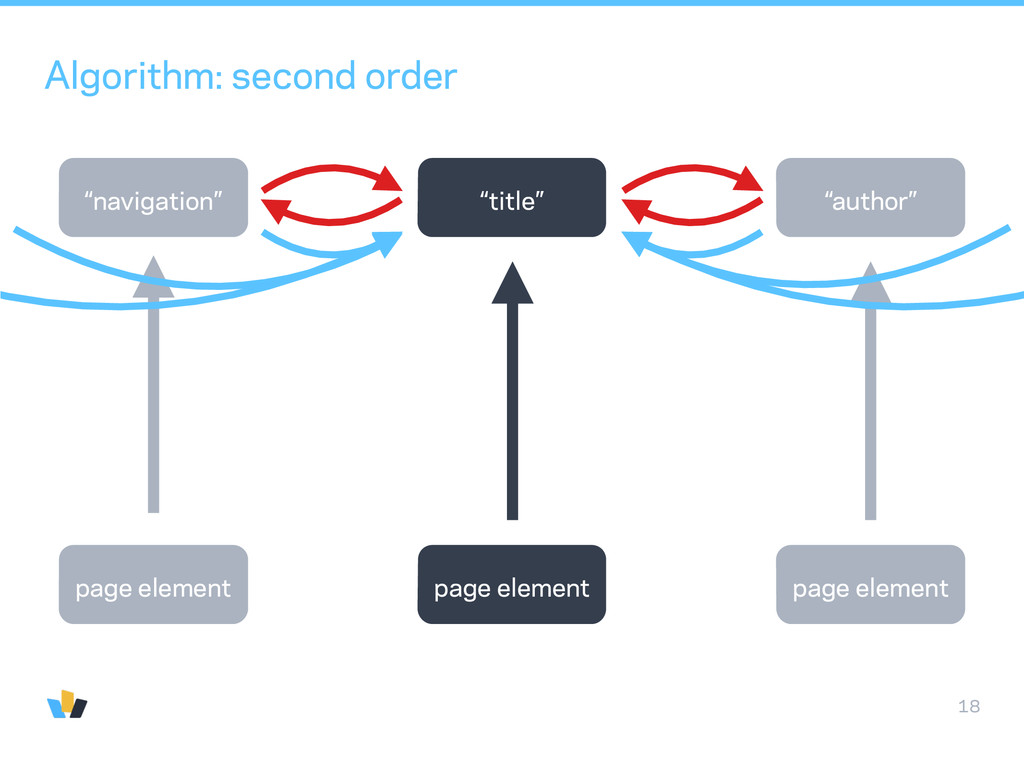
want to extend this to other types than news articles • clustering is too noisy: • ads in between paragraphs • cannot “cluster” authors after titles • CRF: complexity beyond linear-chain-CRF grows too quickly • want “single step” process: multi step algorithms erase information. Example: if first step is to remove ads then second step cannot use information about ads to infer content.
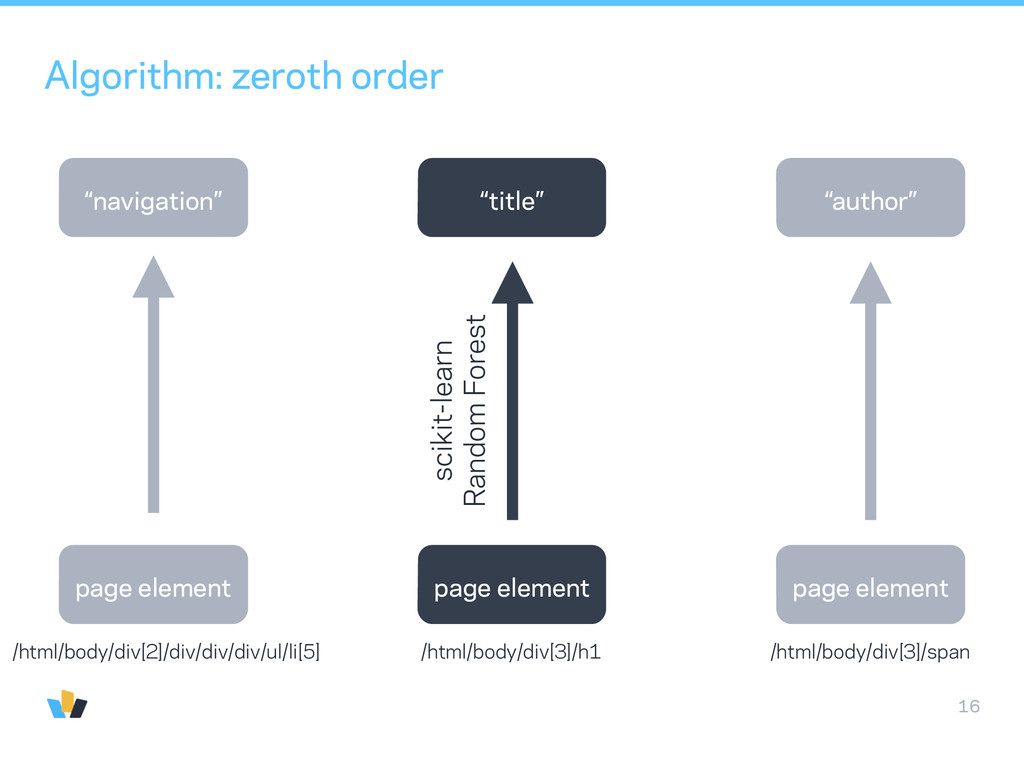
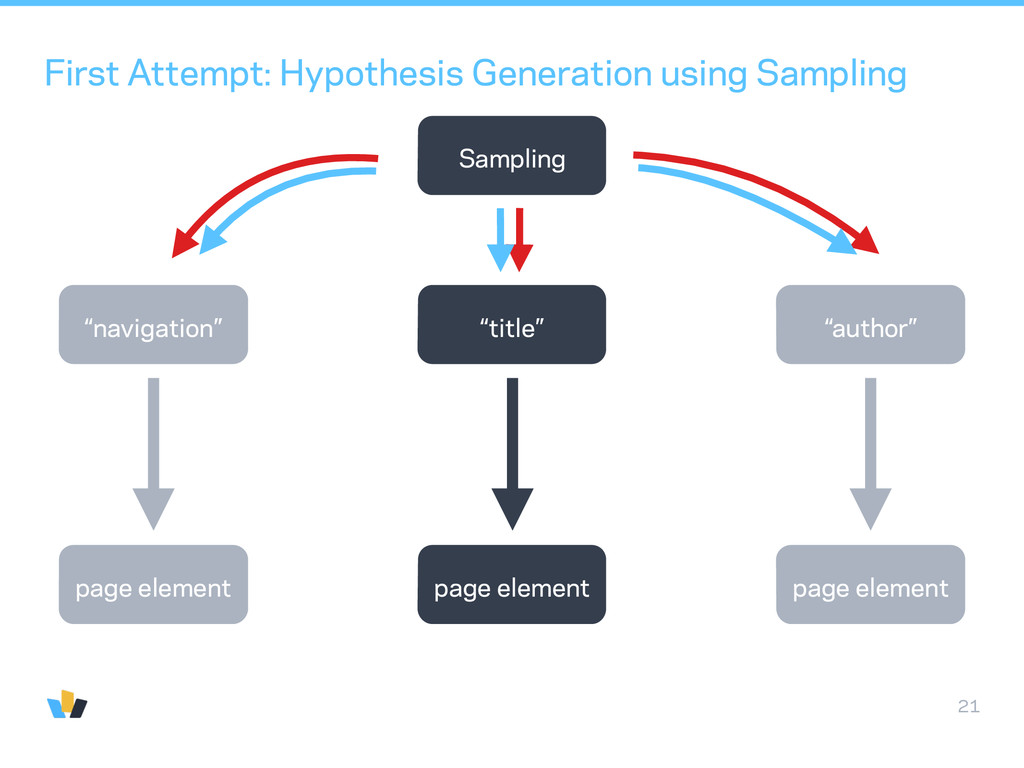
a guess (using zeroth order type classifier) • generate variations of that guess with a proposal function • evaluate an objective function based on a document-wide likelihood function of classification probabilities
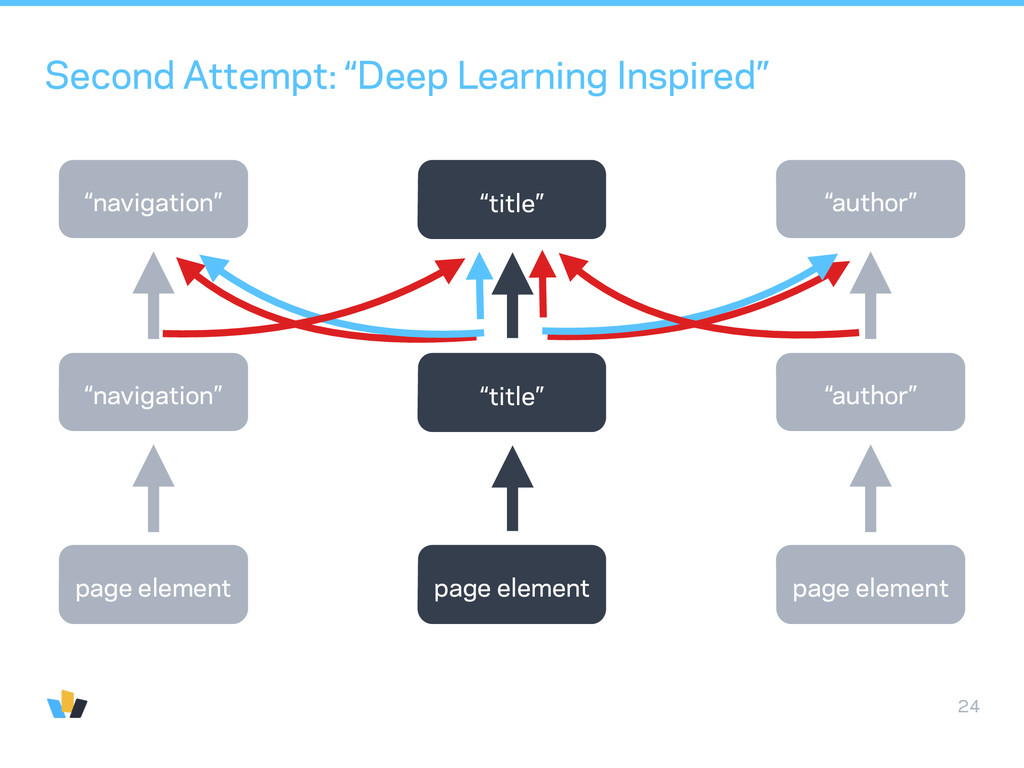
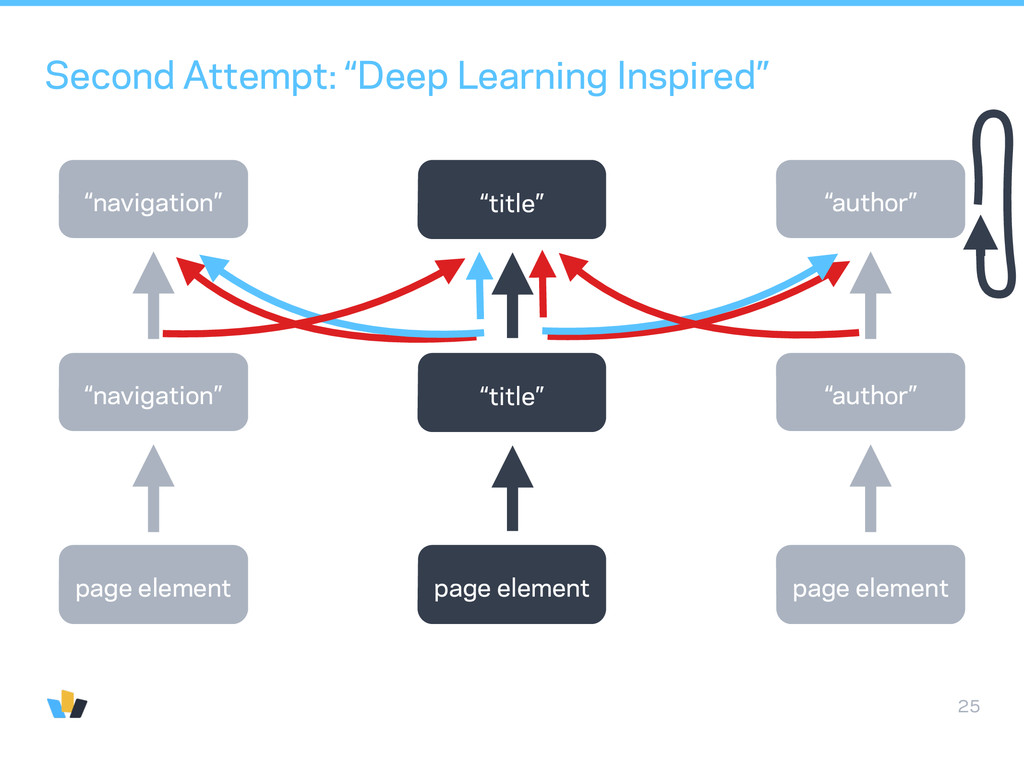
“scene description”. Traditionally done with scene graphs and CRFs. • With Deep Learning, can avoid building a graph and go straight to assigning a label to every pixel. Clément Farabet, 2011 http://www.clement.farabet.net/research.html#parsing
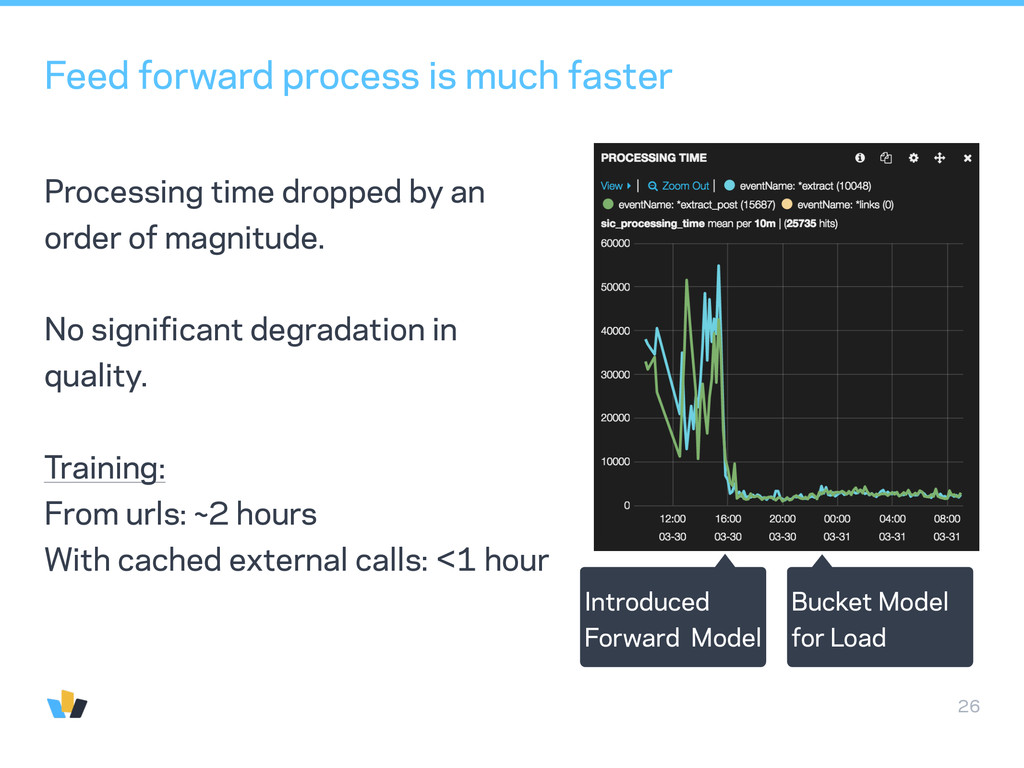
by an order of magnitude. No significant degradation in quality. Training: From urls: ~2 hours With cached external calls: <1 hour Introduced Forward Model Bucket Model for Load
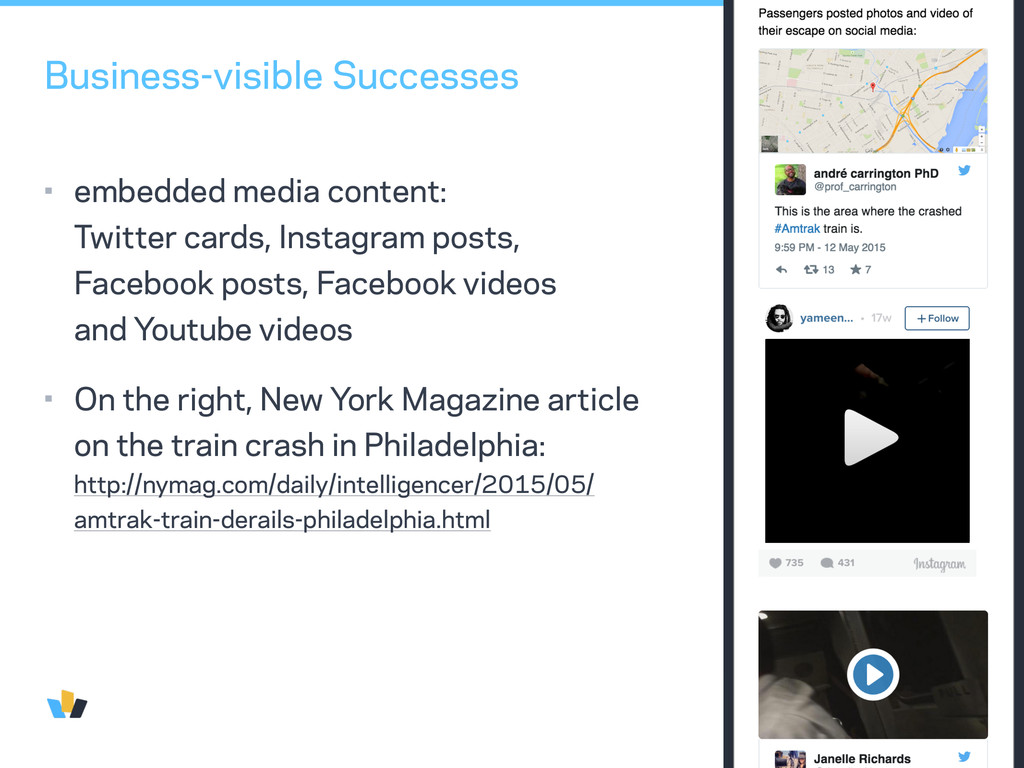
posts, Facebook posts, Facebook videos and Youtube videos • On the right, New York Magazine article on the train crash in Philadelphia: http://nymag.com/daily/intelligencer/2015/05/ amtrak-train-derails-philadelphia.html
emulation (e.g. websites with pure AngularJS) • fixed individual publishers with high visibility in our app • comparison to competition: third party 71-82%, inhouse 83% +/- 4%
evaluation tools, labeling tools, training and inference strategies implemented over the past year • chose tools that allow quick iteration: simple processing in parallel, ML on single node • two open source projects: databench.trivial.io pip install databench pysparkling.trivial.io pip install pysparkling • competitive performance, 54% of cards in Wildcard are powered by pure ML @svenkreiss
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}