Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GSEA-InContext: identifying novel and common pa...
Search
Y-h. Taguchi
PRO
August 13, 2018
Science
290
1
Share
GSEA-InContext: identifying novel and common patterns in expression experiments
ISMB2018読み会
https://atnd.org/events/98383
でのプレゼンです。
Y-h. Taguchi
PRO
August 13, 2018
More Decks by Y-h. Taguchi
See All by Y-h. Taguchi
presen_司法書士学員会.pdf
tagtag
PRO
1
61
生成AIと司法書士の未来.pdf
tagtag
PRO
0
110
データ駆動型ゲノム解析で迫る睡眠研究
tagtag
PRO
0
53
適応テンソル分解と主成分分析に基づく教師なし特徴抽出は、従来手法よりも生物学的に妥当な発現量差のある遺伝子を選択する
tagtag
PRO
0
38
知能とはなにか -ヒトとAIのあいだ-
tagtag
PRO
0
72
Genomic Differentiation of Sleep and Anesthesia: The Role of RHO GTPase and Cortical Neurons
tagtag
PRO
0
43
睡眠と麻酔による無意識状態のゲノム的差異:RHO GTPaseと皮質ニューロンの役割
tagtag
PRO
0
73
Somatostatin-Expressing Neurons Regulate Sleep Deprivation and Recovery: A Data-Driven Transcriptomic Analysis
tagtag
PRO
1
44
Sstニューロンによる睡眠不足と回復の制御:データ駆動型トランスクリプトーム解析
tagtag
PRO
0
82
Other Decks in Science
See All in Science
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
510
DMMにおけるABテスト検証設計の工夫
xc6da
1
1.9k
白金鉱業Vol.21【初学者向け発表枠】身近な例から学ぶ数理最適化の基礎 / Learning the Basics of Mathematical Optimization Through Everyday Examples
brainpadpr
1
730
MATSUO Makiko
genomethica
0
140
20260220 OpenIDファウンデーション・ジャパン ご紹介 / 20260220 OpenID Foundation Japan Intro
oidfj
0
330
コミュニティサイエンスの実践@日本認知科学会2025
hayataka88
0
160
データベース05: SQL(2/3) 結合質問
trycycle
PRO
0
1.1k
データベース02: データベースの概念
trycycle
PRO
2
1.1k
アクシズを探せ! 各勢力の位置関係についての考察
miu_crescent
PRO
1
280
Conversation is the New Dashboard: 属人性を排除する第4世代BIツールの勢力図
shomaekawa
1
570
検索と推論タスクに関する論文の紹介
ynakano
1
220
Understanding CVP Waveforms: Interpretation and Clinical Implications in Anesthesiology
taka88
0
520
Featured
See All Featured
My Coaching Mixtape
mlcsv
0
130
Documentation Writing (for coders)
carmenintech
77
5.3k
Building Applications with DynamoDB
mza
96
7k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Thoughts on Productivity
jonyablonski
76
5.2k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
510
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
180
Building Flexible Design Systems
yeseniaperezcruz
330
40k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.8k
The SEO identity crisis: Don't let AI make you average
varn
0
470
The Curious Case for Waylosing
cassininazir
1
350
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
180
Transcript
ISMB2018読み会 GSEA-InContext: identifying novel and common patterns in expression experiments
Rani K. Powers, Andrew Goodspeed, Harrison Pielke-Lombardo, Aik-Choon Tan and James C. Costello Bioinformatics, 34, 2018, i555–i564 doi: 10.1093/bioinformatics/bty271 報告者: 中央大学理工学部物理学科 田口善弘
論文の目的: 論文の目的: GSEA(Gene Set Enrichment Analysis)は「遺伝子を『何か(例: 発現差の大きさ)の順番』で並べた場合、順番には意味があ る。ある遺伝子セットAが有意に上位に並ぶなら、そのセットに は『何か』の大きさが有意に大きい遺伝子のセットであるとい えるだろう」
というものですが、その場合「有意に上位に並ぶ」の判定をす るときの比較対象(=帰無仮説)が「完全にランダムな並び」 になっている。しかし、遺伝子はお互いに相関しているんだか ら、『何か』と全く無関係じゃない限り、遺伝子セットAはどっち にしろグループで動く(上位に来る)だろう。そうなると「遺伝 子セットAに意味があるか?」という検証にはなっても「順位 付けした『何か』と関係している」と言えなくないか? この問題は解決するには比較対象を完全にランダムな並び じゃなく、いろいろな実験での並びの集合に置き換えないとい けないのでは?
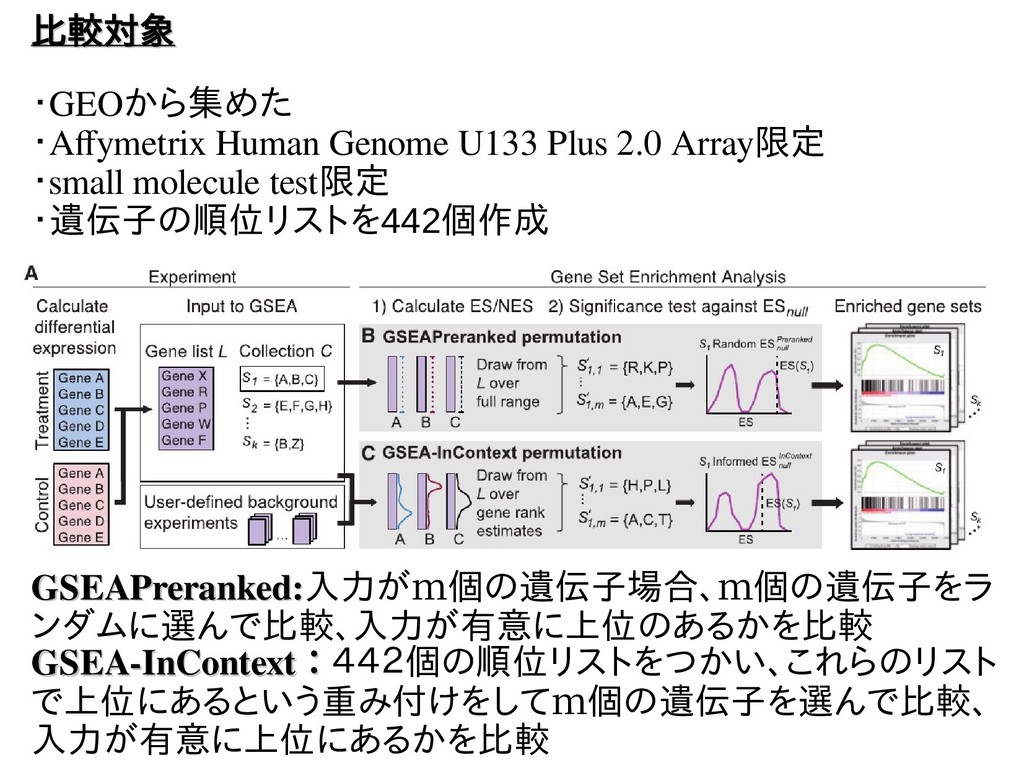
比較対象 比較対象 ・GEOから集めた ・Afymetrix Human Genome U133 Plus 2.0 Array限定
・small molecule test限定 ・遺伝子の順位リストを442個作成 GSEAPreranked: GSEAPreranked:入力がm個の遺伝子場合、m個の遺伝子をラ ンダムに選んで比較、入力が有意に上位のあるかを比較 GSEA-InContext GSEA-InContext: :442個の順位リストをつかい、これらのリスト で上位にあるという重み付けをしてm個の遺伝子を選んで比較、 入力が有意に上位にあるかを比較
B(α、β):β関数 β二項分布: バイアスのあるコインがたくさん入った袋がある。そこから一枚コイ ンを一枚抜き出して、n 回投げた。表の出る回数 k が従う分布は? ただし袋の中のコインの表の出る確率 p はベータ分布に従うこと
とする。 α、βの値は442個の遺伝子ランクをつかって、遺伝子ごとに決定 ある遺伝子がr位になる確率:β二項分布 ∫0 1 p(α−1)(1−p)α dp
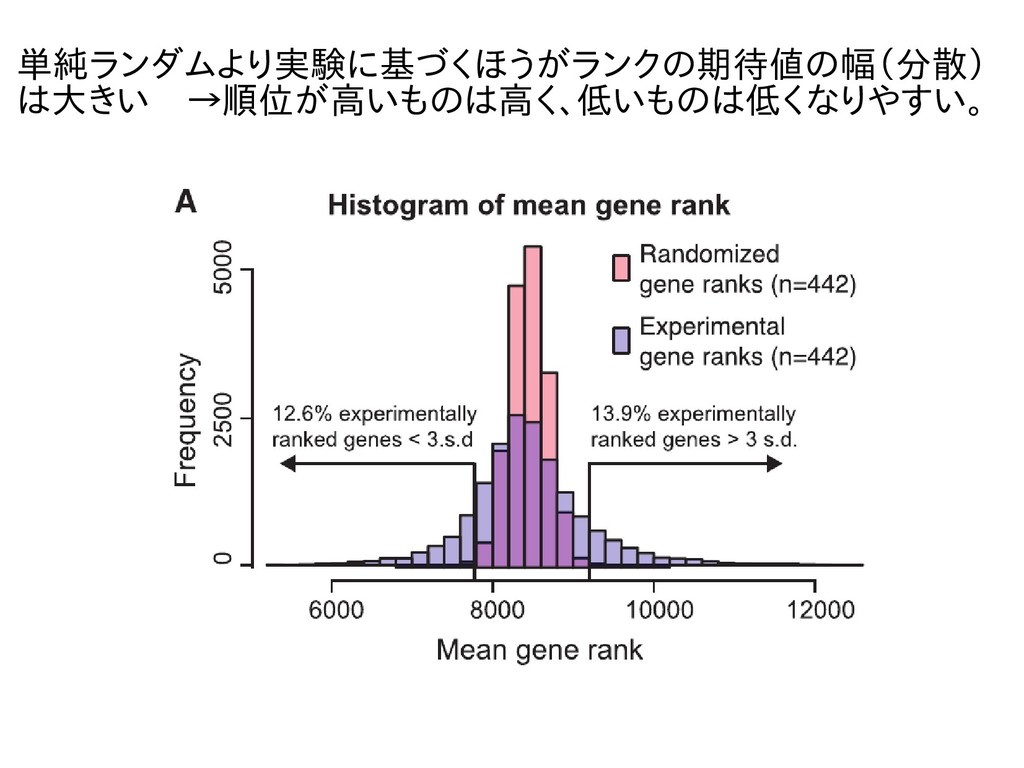
単純ランダムより実験に基づくほうがランクの期待値の幅(分散) は大きい →順位が高いものは高く、低いものは低くなりやすい。
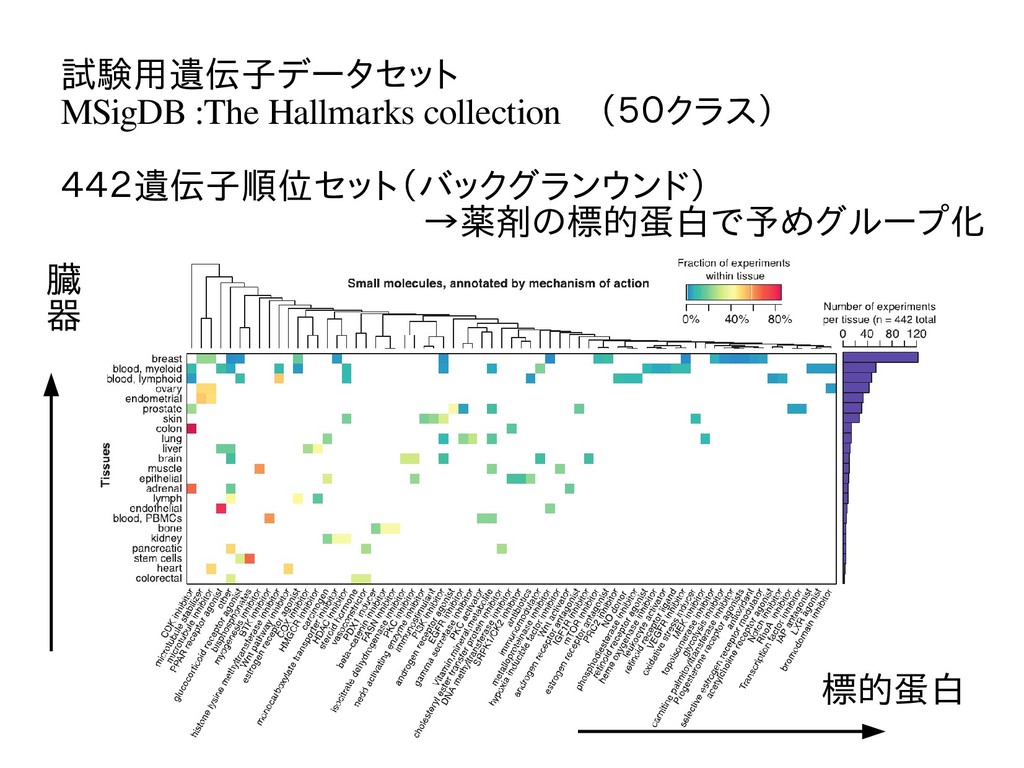
試験用遺伝子データセット MSigDB :The Hallmarks collection (50クラス) 442遺伝子順位セット(バックグランウンド) →薬剤の標的蛋白で予めグループ化 標的蛋白 臓 器
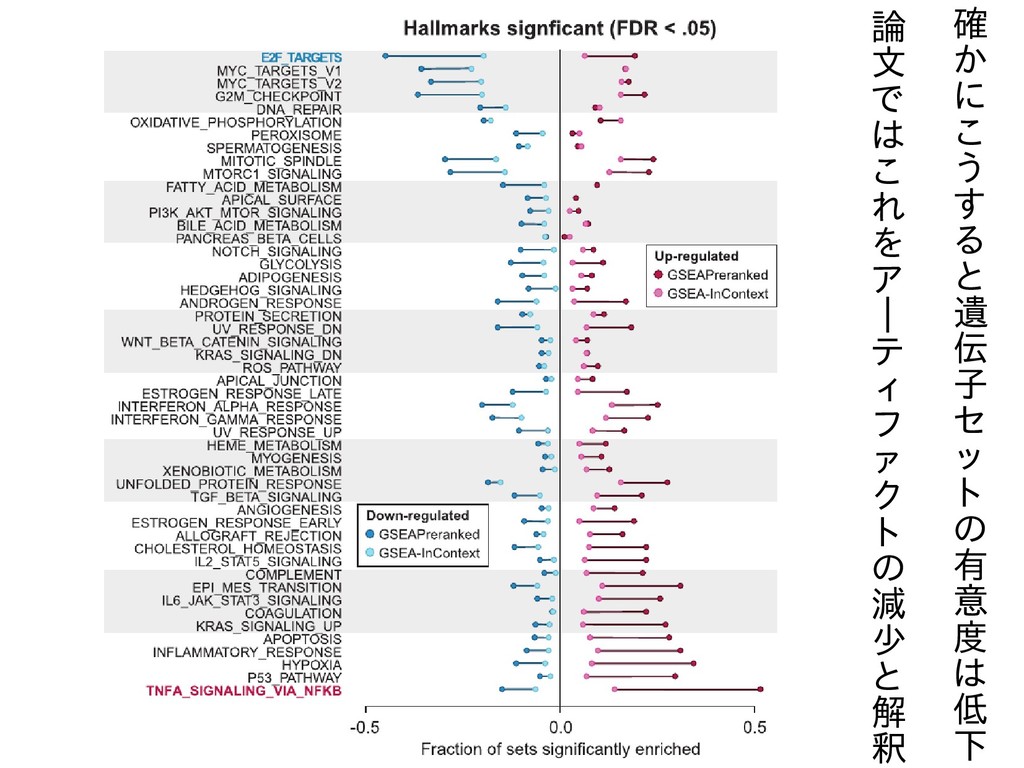
確 か に こ う す る と 遺 伝
子 セ ッ ト の 有 意 度 は 低 下 論 文 で は こ れ を ア | テ ィ フ ァ ク ト の 減 少 と 解 釈
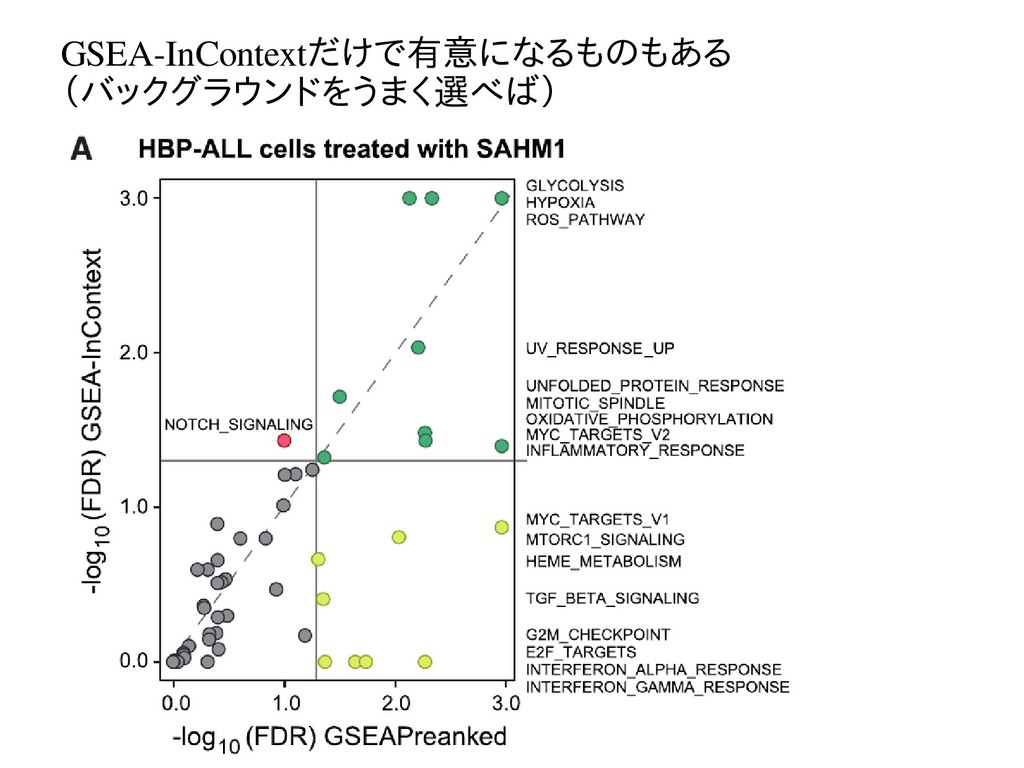
GSEA-InContextだけで有意になるものもある (バックグラウンドをうまく選べば)
なんで なんでISMB ISMB2018に採択されたの? 2018に採択されたの? 正直、何が面白いのか皆目わかりません。 コレポンはgoogle scholarの引用数が4000ある(2007年から論文 を書き始めた)。実験系の論文が多く、ファーストやコレポンは少な い。 多分、最初の論文から10年でgoogle
scholarの引用数を4000くら いにするのがISMBに論文通すコツなのでは? (僕にはもう実現できないハードルですが、過去のことなので)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}