Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
サンプル対応のない複数遺伝子発現プロファイルに対するテンソル分解型統合解析の要約
Search
Y-h. Taguchi
PRO
July 02, 2026
Science
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
サンプル対応のない複数遺伝子発現プロファイルに対するテンソル分解型統合解析の要約
SIGBIO85
2026/7/2
at OIST
https://www.ipsj.or.jp/kenkyukai/event/mps157bio85.html
Y-h. Taguchi
PRO
July 02, 2026
More Decks by Y-h. Taguchi
See All by Y-h. Taguchi
AI(人工知能)の過去・現在・未来 ~AIは人類を越えるのか~
tagtag
PRO
0
120
presen_司法書士学員会.pdf
tagtag
PRO
1
84
生成AIと司法書士の未来.pdf
tagtag
PRO
0
140
データ駆動型ゲノム解析で迫る睡眠研究
tagtag
PRO
0
72
適応テンソル分解と主成分分析に基づく教師なし特徴抽出は、従来手法よりも生物学的に妥当な発現量差のある遺伝子を選択する
tagtag
PRO
0
56
知能とはなにか -ヒトとAIのあいだ-
tagtag
PRO
0
96
Genomic Differentiation of Sleep and Anesthesia: The Role of RHO GTPase and Cortical Neurons
tagtag
PRO
0
57
睡眠と麻酔による無意識状態のゲノム的差異:RHO GTPaseと皮質ニューロンの役割
tagtag
PRO
0
83
Somatostatin-Expressing Neurons Regulate Sleep Deprivation and Recovery: A Data-Driven Transcriptomic Analysis
tagtag
PRO
1
58
Other Decks in Science
See All in Science
データベース14: B+木 & ハッシュ索引
trycycle
PRO
0
700
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
210
医療 LLM ベンチマークの現在地:多面的評価 と日本ローカライズ
analokmaus
1
600
データベース09: 実体関連モデル上の一貫性制約
trycycle
PRO
0
1.5k
SpatialRDDパッケージによる空間回帰不連続デザイン
saltcooky12
0
270
Inside the Mind of an LLM
baggiponte
0
200
Amusing Abliteration
ianozsvald
1
230
データベース03: 関係データモデル
trycycle
PRO
1
610
ダメな自分の育て方―性格タイプの「劣等機能」から理解するニガテ克服術
ppillc
0
220
(2025) Balade en cyclotomie
mansuy
0
640
機械学習 - SVM
trycycle
PRO
2
1.2k
データベース01: データベースを使わない世界
trycycle
PRO
1
1.3k
Featured
See All Featured
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
The Invisible Side of Design
smashingmag
301
52k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Into the Great Unknown - MozCon
thekraken
41
2.6k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
390
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
We Are The Robots
honzajavorek
0
280
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
A Soul's Torment
seathinner
6
3.1k
Transcript
サンプル対応なしで 複数の遺伝子発現プロファイルを統合 する Tensor Decomposition–based Unsupervised Feature Extraction による AD
データ統合 Y-h. Taguchi & Turki Turki Scientific Reports 12, 21242 (2022) Dataset 1 RNA-seq Dataset 2 RNA-seq Dataset 3 RNA-seq 共通の 遺伝子軸 Tensor
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
お断り:ここ数年「自分ではやらずに生成AIに発表スライドを作らせてど こまでいけるか」にチャレンジしてきて今回も論文のPDFをアップロード して生成AI(ChatGPT)に作らせてここまで出来るようになりました。プ ロセスは以下の通りで極力簡単なプロンプトでどこまで出来るかのトラ イアルです。 なお、論文からの図や表の大きさだけは最後は僕が手動で直しました。 https://chatgpt.com/share/6a457933-b36c-83e8-bc69-f726fba38291 まあ、これは「既発表論文を発表する」 という場合にしか使えないですが。 研究報告の原稿からでもしっかり作った原稿 からなら可能かもしれません(試してないです)
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
今日の結論 20分講演のロードマップ この論文の一番の貢献は、通常は統合できないデータを 「遺伝子 × 低次元成分 × データセット」のテンソルに落として統合した点です。 1 対応サンプルなし・共通ラベルなしでも統合可能 AD関連の複数RNA-seq・scRNA-seqを同じ枠組みで扱う 2 選択遺伝子は神経変性疾患・脳領域に濃縮 565 / 544 / 660 / 177遺伝子の複数解析で生物学的妥当性を確認 3 薬剤再配置・転移学習・scRNA-seq省メモリ化へ展開 分類性能の追求ではなく、共通する遺伝子軸の抽出が目的 2
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
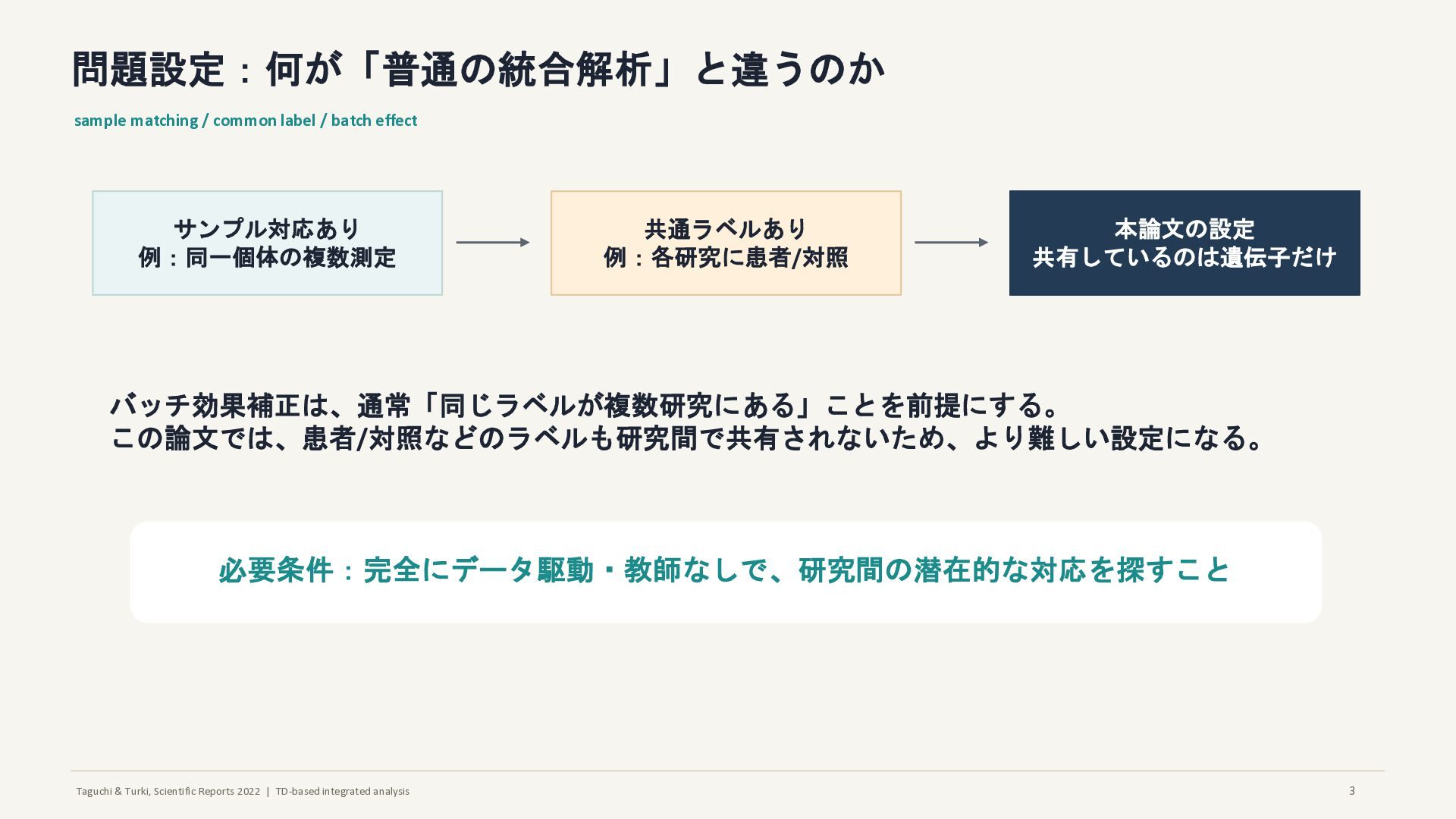
問題設定:何が「普通の統合解析」と違うのか sample matching / common label / batch effect サンプル対応あり 例:同一個体の複数測定 共通ラベルあり 例:各研究に患者/対照 本論文の設定 共有しているのは遺伝子だけ バッチ効果補正は、通常「同じラベルが複数研究にある」ことを前提にする。 この論文では、患者/対照などのラベルも研究間で共有されないため、より難しい設定になる。 必要条件:完全にデータ駆動・教師なしで、研究間の潜在的な対応を探すこと 3
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
なぜADデータでこの設定が重要なのか 研究の動機 小サンプル問題 • RNA-seqは遺伝子数が多い • 一方、疾患モデルや細胞 実験のサンプル数は少ない • 1研究だけでは安定した特 徴抽出が難しい 研究目的の違い • AD/対照比較 • AD関連遺伝子の操作 • 薬剤処理や標的遺伝子活 性化 • scRNA-seqの組織・疾患差 統合したい理由 疾患・加齢・遺伝子操作 ・薬剤応答に共通する 「遺伝子の変動方向」を 抽出したい。 AD研究では「直接対応しないデータを比べたい」場面が多い 4
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
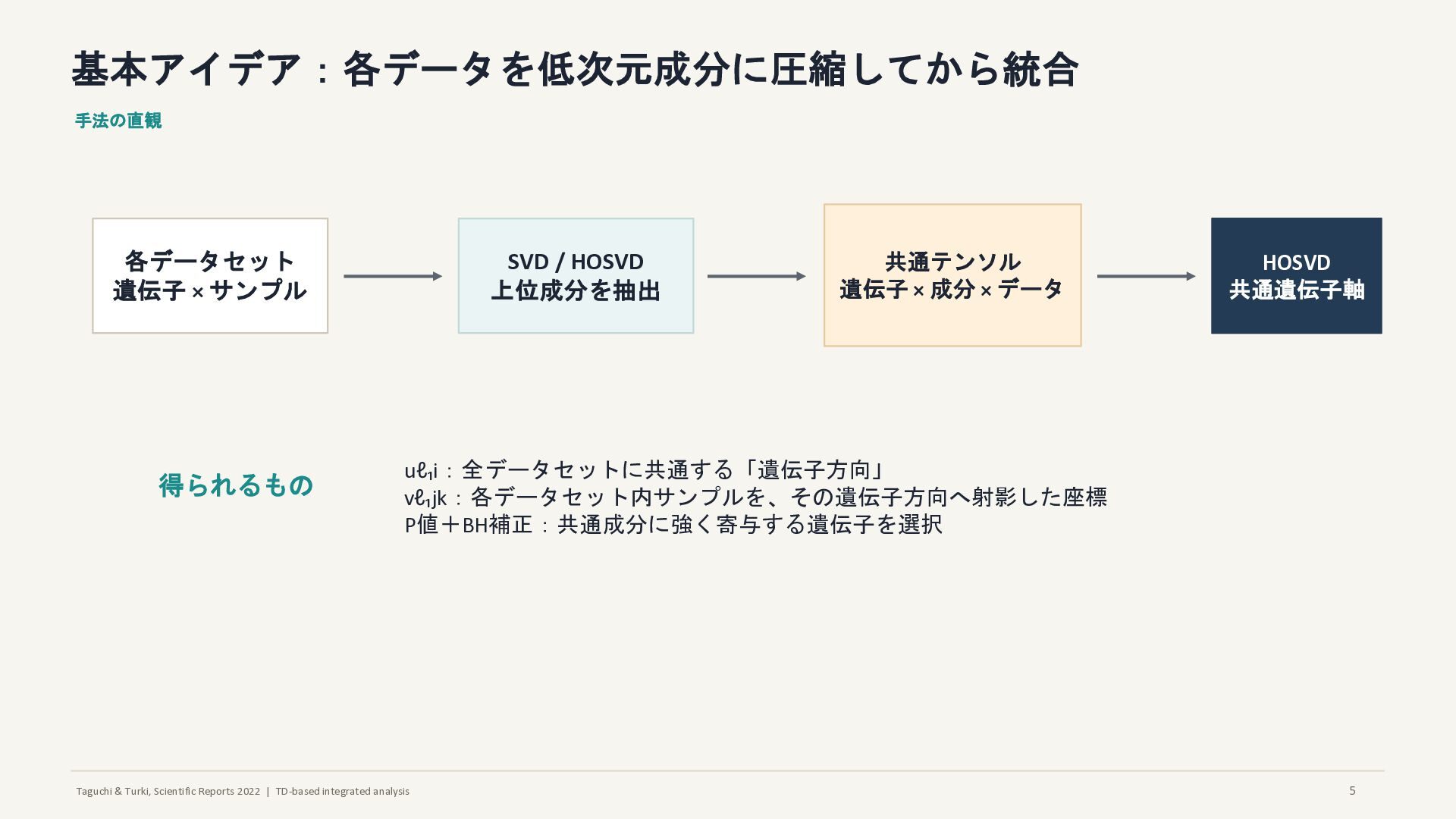
基本アイデア:各データを低次元成分に圧縮してから統合 手法の直観 各データセット 遺伝子 × サンプル SVD / HOSVD 上位成分を抽出 共通テンソル 遺伝子 × 成分 × データ HOSVD 共通遺伝子軸 得られるもの uℓ₁i:全データセットに共通する「遺伝子方向」 vℓ₁jk:各データセット内サンプルを、その遺伝子方向へ射影した座標 P値+BH補正:共通成分に強く寄与する遺伝子を選択 5
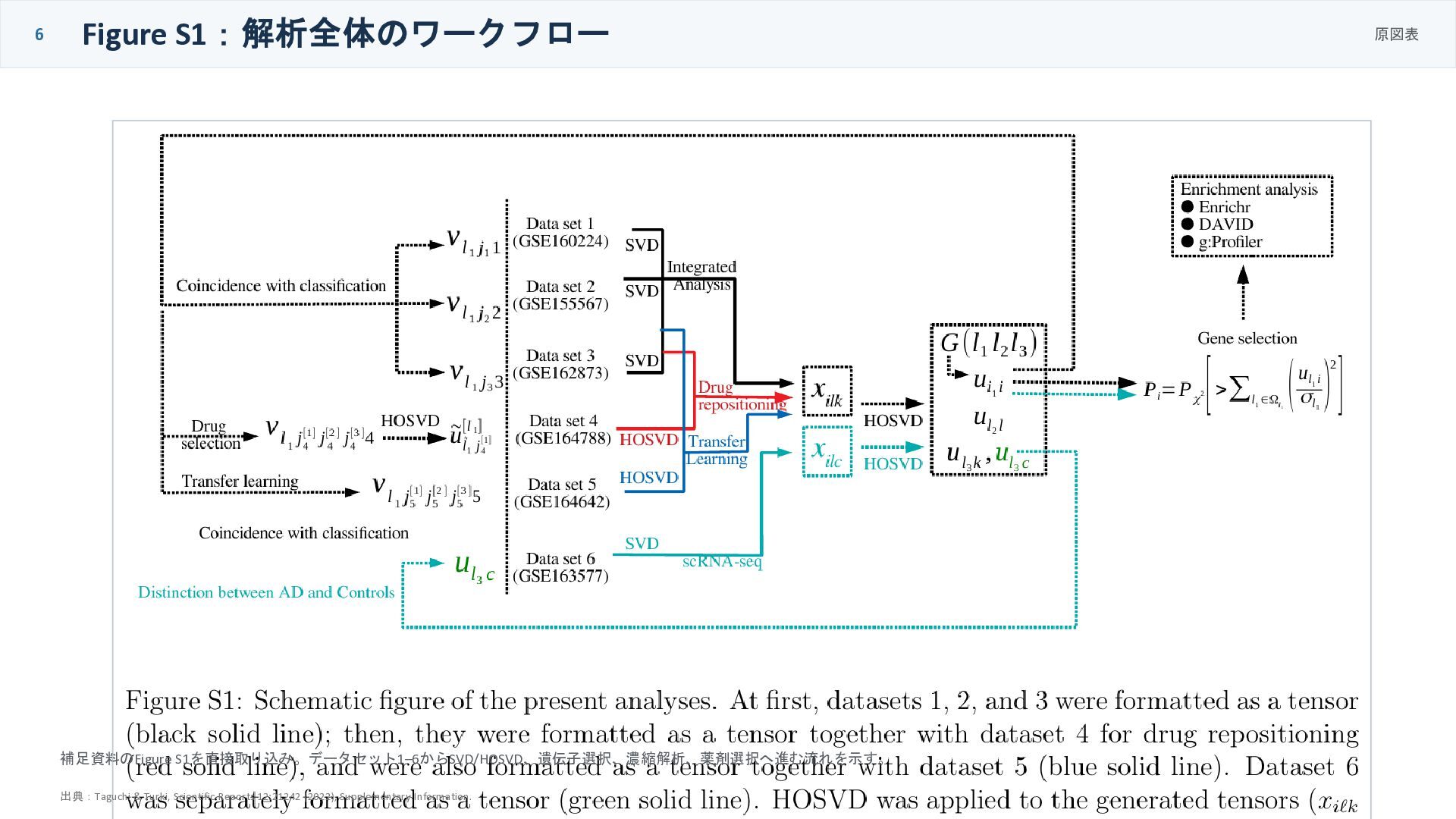
6 Figure S1:解析全体のワークフロー 原図表 補足資料のFigure S1を直接取り込み。データセット1–6からSVD/HOSVD、遺伝子選択、濃縮解析、薬剤選択へ進む流れを示す。 出典:Taguchi & Turki, Scientific
Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
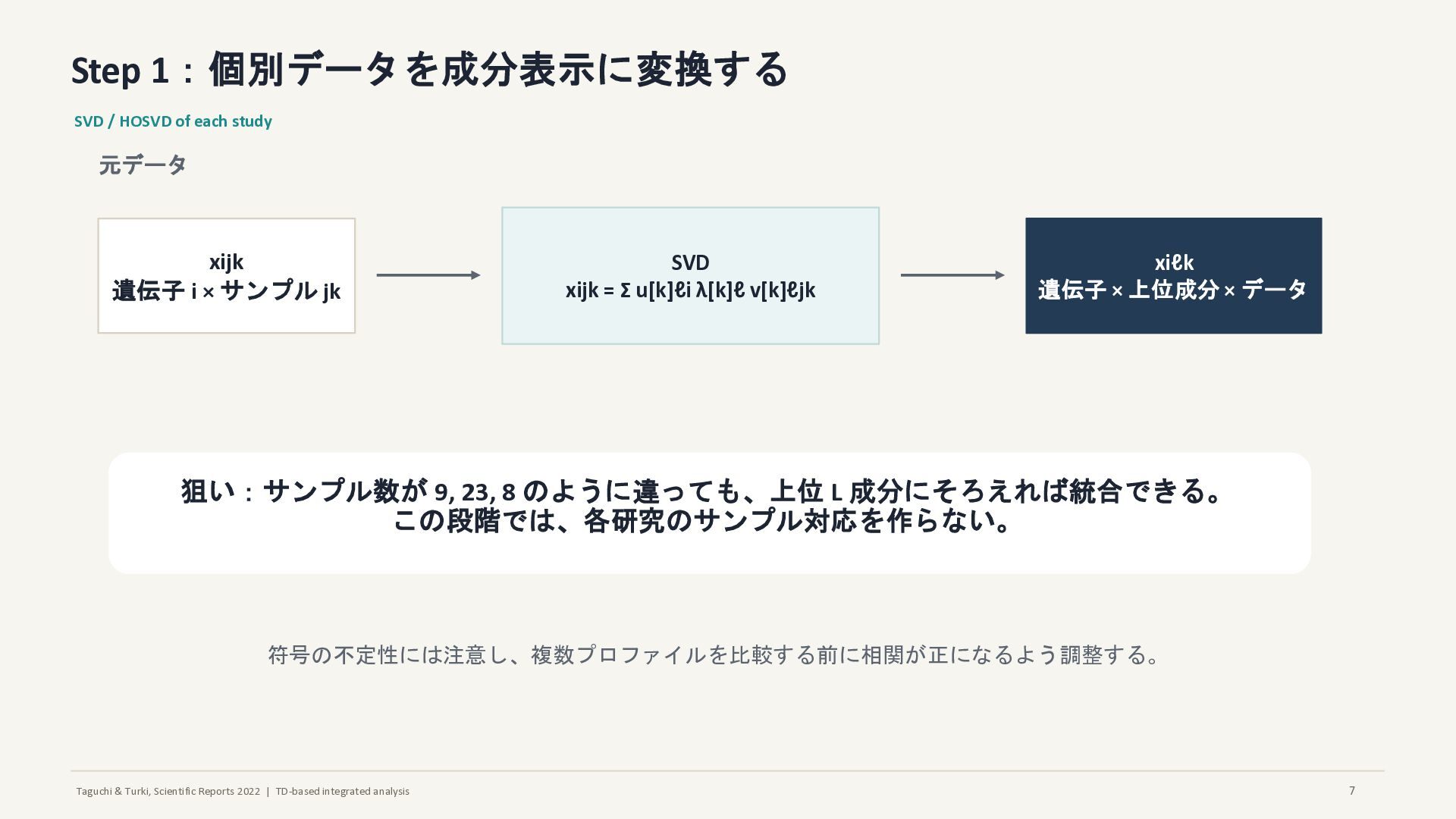
Step 1:個別データを成分表示に変換する SVD / HOSVD of each study 元データ xijk 遺伝子 i × サンプル jk SVD xijk = Σ u[k]ℓi λ[k]ℓ v[k]ℓjk xiℓk 遺伝子 × 上位成分 × データ 狙い:サンプル数が 9, 23, 8 のように違っても、上位 L 成分にそろえれば統合できる。 この段階では、各研究のサンプル対応を作らない。 符号の不定性には注意し、複数プロファイルを比較する前に相関が正になるよう調整する。 7
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
Step 2:統合テンソルをHOSVDし、遺伝子を選ぶ common gene directions xiℓk ∈ Rᴺ×ᴸ×ᴷ N:遺伝子数 L:各データの上位成分数 K:データセット数 xiℓk = Σ G(ℓ₁,ℓ₂,ℓ₃) × uℓ₁i × uℓ₂ℓ × uℓ₃k 遺伝子選択の流れ 1. 分類や条件と関連する成分 ℓ₁ を選 ぶ 2. 各遺伝子 i について、uℓ₁i の大きさ を統計量化 3. χ²分布でP値を付与 4. BH補正後 P < 0.01 を選択 教師なしFE:ラベルで学習せず、後から関連性 を見る サンプルを直接そろえない そろえるのは遺伝子軸だけ 8
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
使ったデータ:ADを軸に6つのGEOデータを統合 データセット # GEO 内容 サンプル構造 遺伝子数 1 GSE160224 ADモデル細胞 9 samples 58k genes 2 GSE155567 CD33/PTPN6操作 23 samples 61k genes 3 GSE162873 AD/normal細胞 8 samples 48k genes 4 GSE164788 化合物処理 94 drugs × 4 doses × 3 reps 28k genes 5 GSE164642 ABCC1活性化 3 RNAs × 2 treatments × 3 reps 58k genes 6 GSE163577 AD scRNA-seq 25 profiles, ~10⁴ cells each 34k genes 1–3:基礎統合 4:薬剤再配置 5:転移学習 6:scRNA-seq 9
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
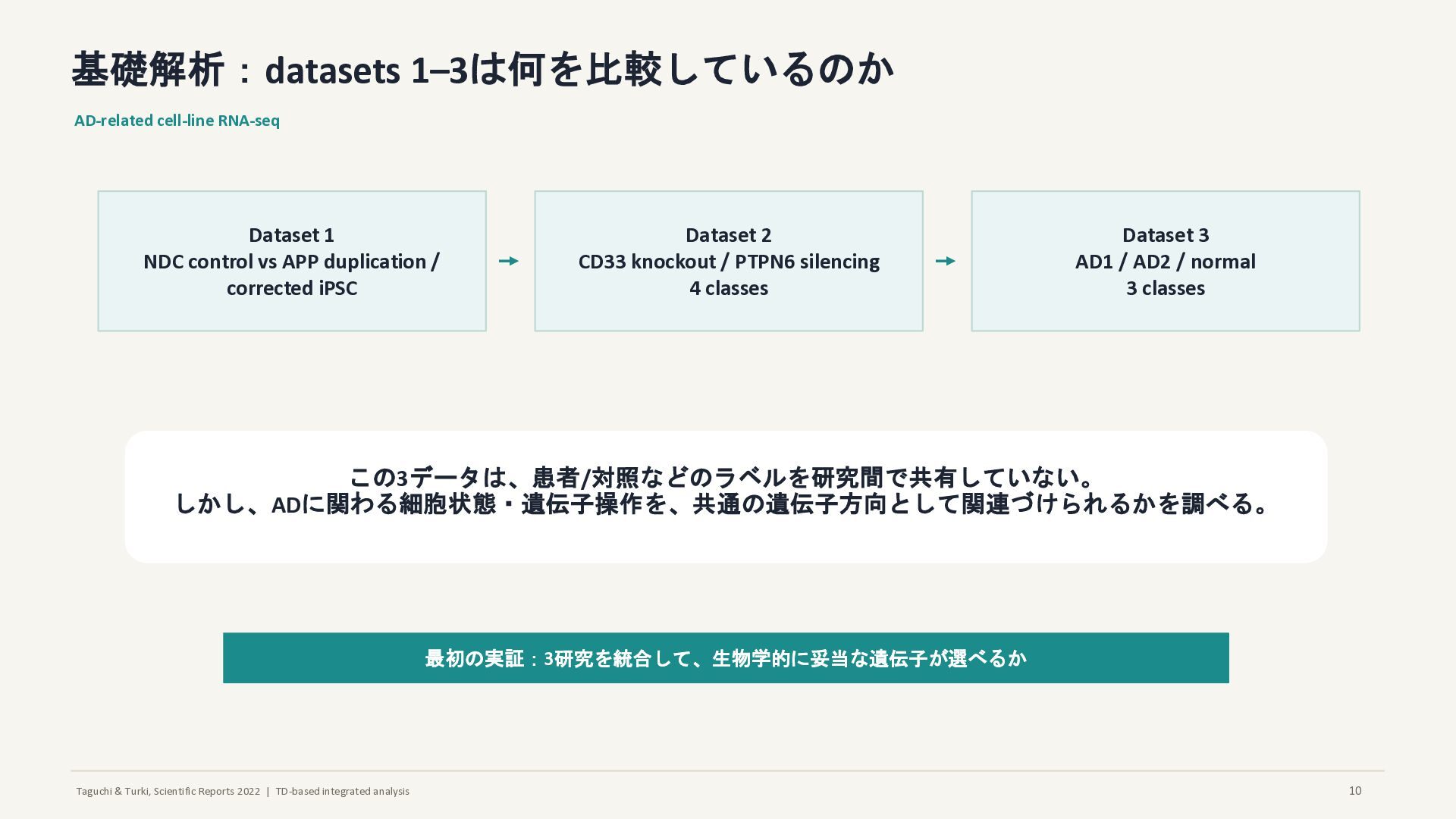
基礎解析:datasets 1–3は何を比較しているのか AD-related cell-line RNA-seq Dataset 1 NDC control vs APP duplication / corrected iPSC Dataset 2 CD33 knockout / PTPN6 silencing 4 classes Dataset 3 AD1 / AD2 / normal 3 classes この3データは、患者/対照などのラベルを研究間で共有していない。 しかし、ADに関わる細胞状態・遺伝子操作を、共通の遺伝子方向として関連づけられるかを調べる。 最初の実証:3研究を統合して、生物学的に妥当な遺伝子が選べるか 10
11 Table S1:潜在変数と分類の一致性 原図表 補足資料のTable S1を直接取り込み。統合・薬剤リポジショニング・transfer learningでのP値を一覧化。 出典:Taguchi & Turki,
Scientific Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
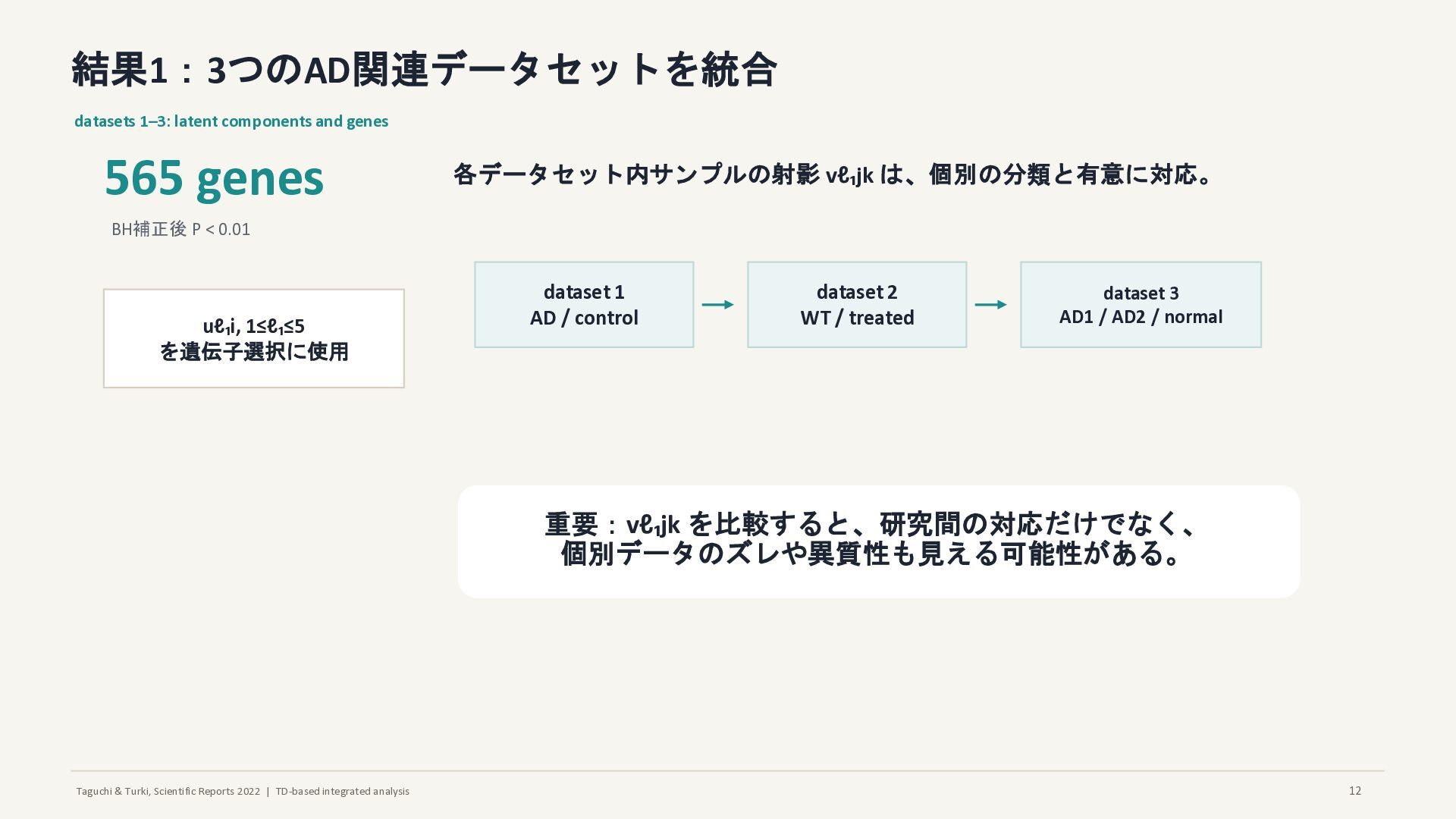
結果1:3つのAD関連データセットを統合 datasets 1–3: latent components and genes 565 genes BH補正後 P < 0.01 uℓ₁i, 1≤ℓ₁≤5 を遺伝子選択に使用 各データセット内サンプルの射影 vℓ₁jk は、個別の分類と有意に対応。 dataset 1 AD / control dataset 2 WT / treated dataset 3 AD1 / AD2 / normal 重要:vℓ₁jk を比較すると、研究間の対応だけでなく、 個別データのズレや異質性も見える可能性がある。 12
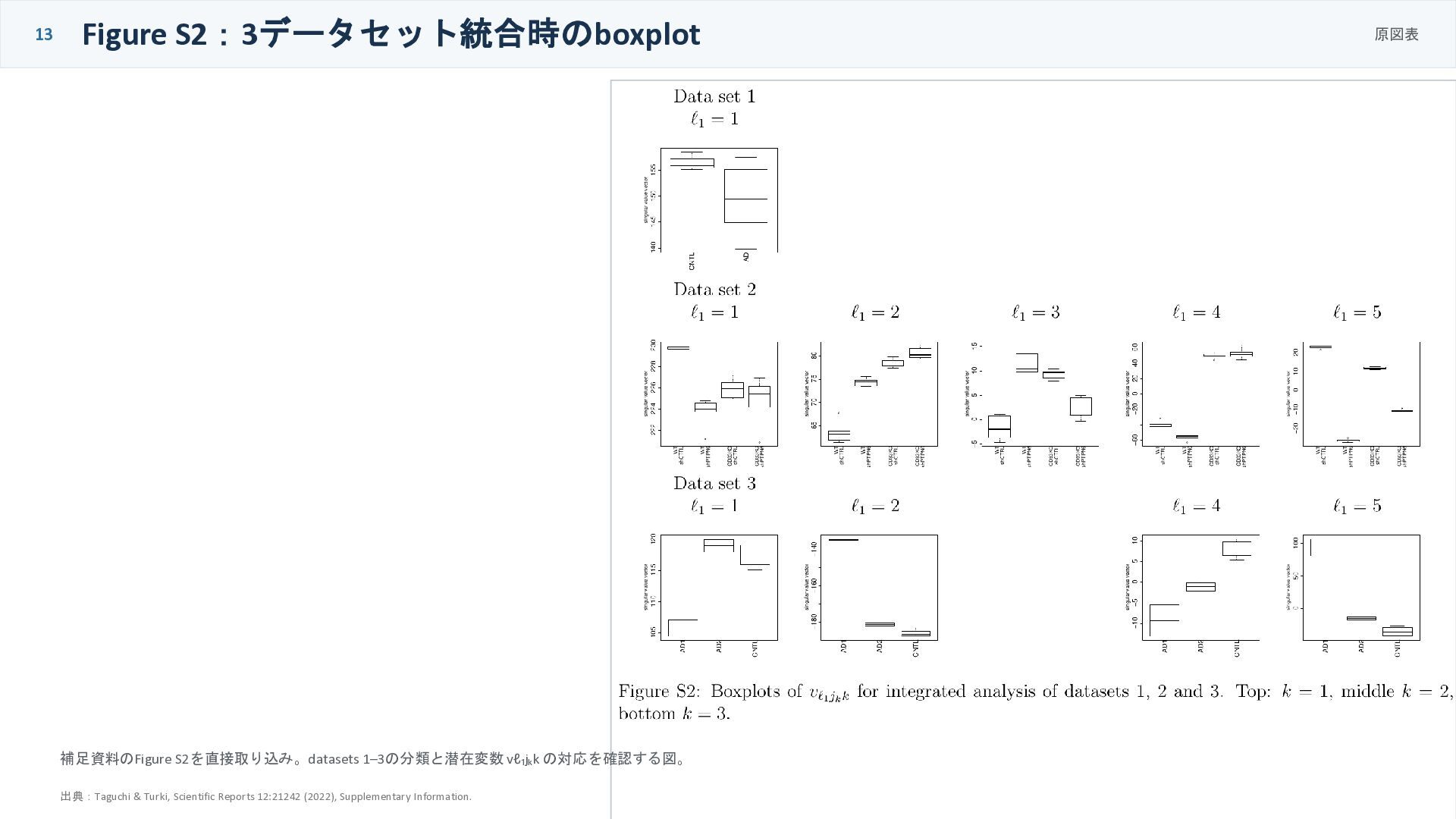
13 Figure S2:3データセット統合時のboxplot 原図表 補足資料のFigure S2を直接取り込み。datasets 1–3の分類と潜在変数 vℓ₁jₖk の対応を確認する図。 出典:Taguchi
& Turki, Scientific Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
結果1の生物学的検証:神経変性関連の濃縮 enrichment analysis 濃縮解析の主要シグナル KEGG 2021 Human 神経変性疾患関連経路がtop10に6件 Jensen Diseases 神経変性疾患がtop10に4件 DAVID GAD_DISEASE top10に5つの神経変性疾患 g:Profiler KEGG 有意な16経路中、6つが神経変性関連 統合で選ばれた遺伝子群は、ADを含む神経変性疾患・脳関連の生物学的語彙に一貫して結びつく。 14
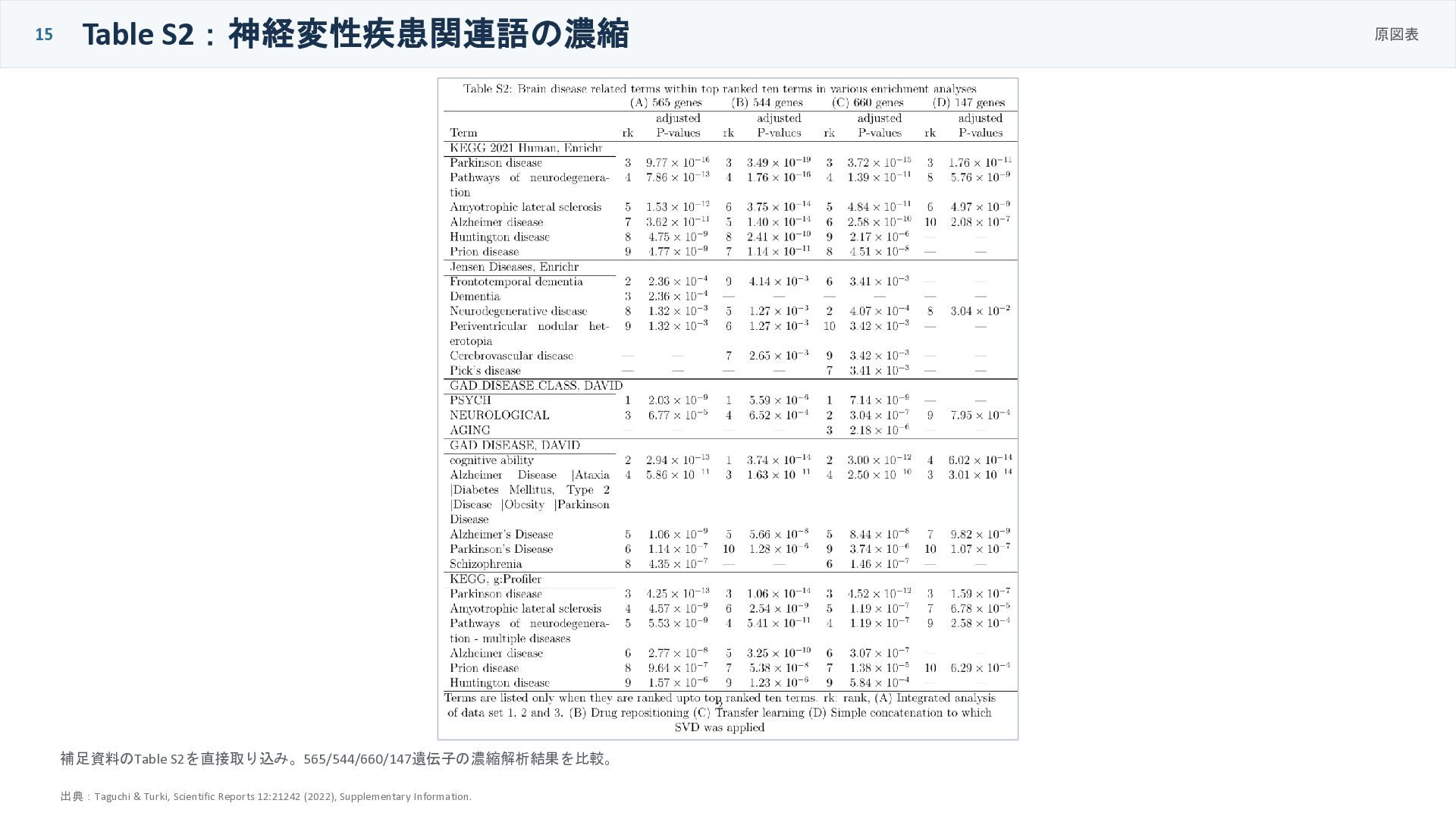
15 Table S2:神経変性疾患関連語の濃縮 原図表 補足資料のTable S2を直接取り込み。565/544/660/147遺伝子の濃縮解析結果を比較。 出典:Taguchi & Turki, Scientific
Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
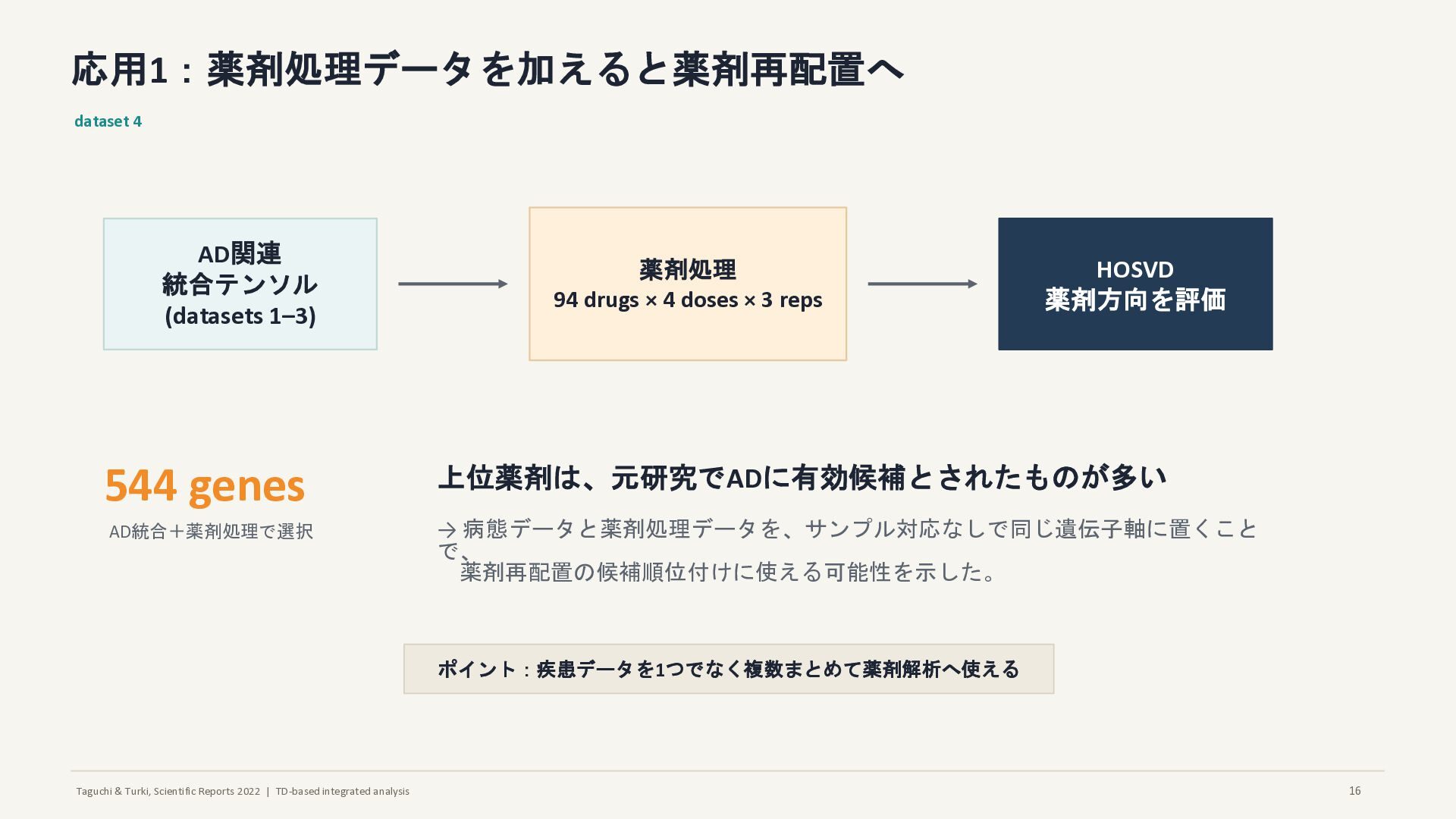
応用1:薬剤処理データを加えると薬剤再配置へ dataset 4 AD関連 統合テンソル (datasets 1–3) 薬剤処理 94 drugs × 4 doses × 3 reps HOSVD 薬剤方向を評価 544 genes AD統合+薬剤処理で選択 上位薬剤は、元研究でADに有効候補とされたものが多い → 病態データと薬剤処理データを、サンプル対応なしで同じ遺伝子軸に置くこと で、 薬剤再配置の候補順位付けに使える可能性を示した。 ポイント:疾患データを1つでなく複数まとめて薬剤解析へ使える 16
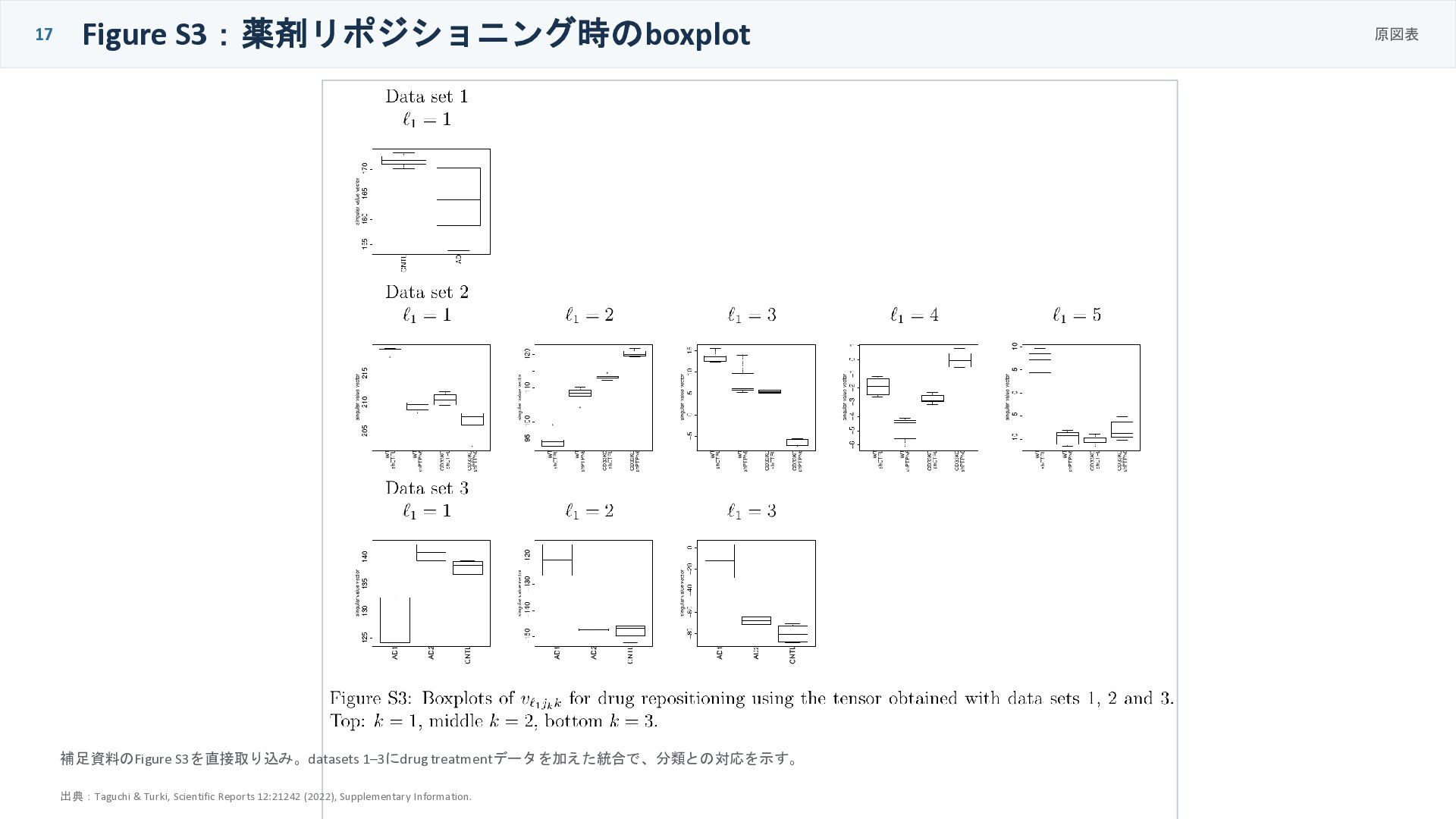
17 Figure S3:薬剤リポジショニング時のboxplot 原図表 補足資料のFigure S3を直接取り込み。datasets 1–3にdrug treatmentデータを加えた統合で、分類との対応を示す。 出典:Taguchi &
Turki, Scientific Reports 12:21242 (2022), Supplementary Information.
18 Table S3:薬剤ランキング上位5件 原図表 補足資料のTable S3を直接取り込み。各ℓ₁で上位に来た薬剤名とスコアを示す。 :Taguchi & Turki, Scientific
Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
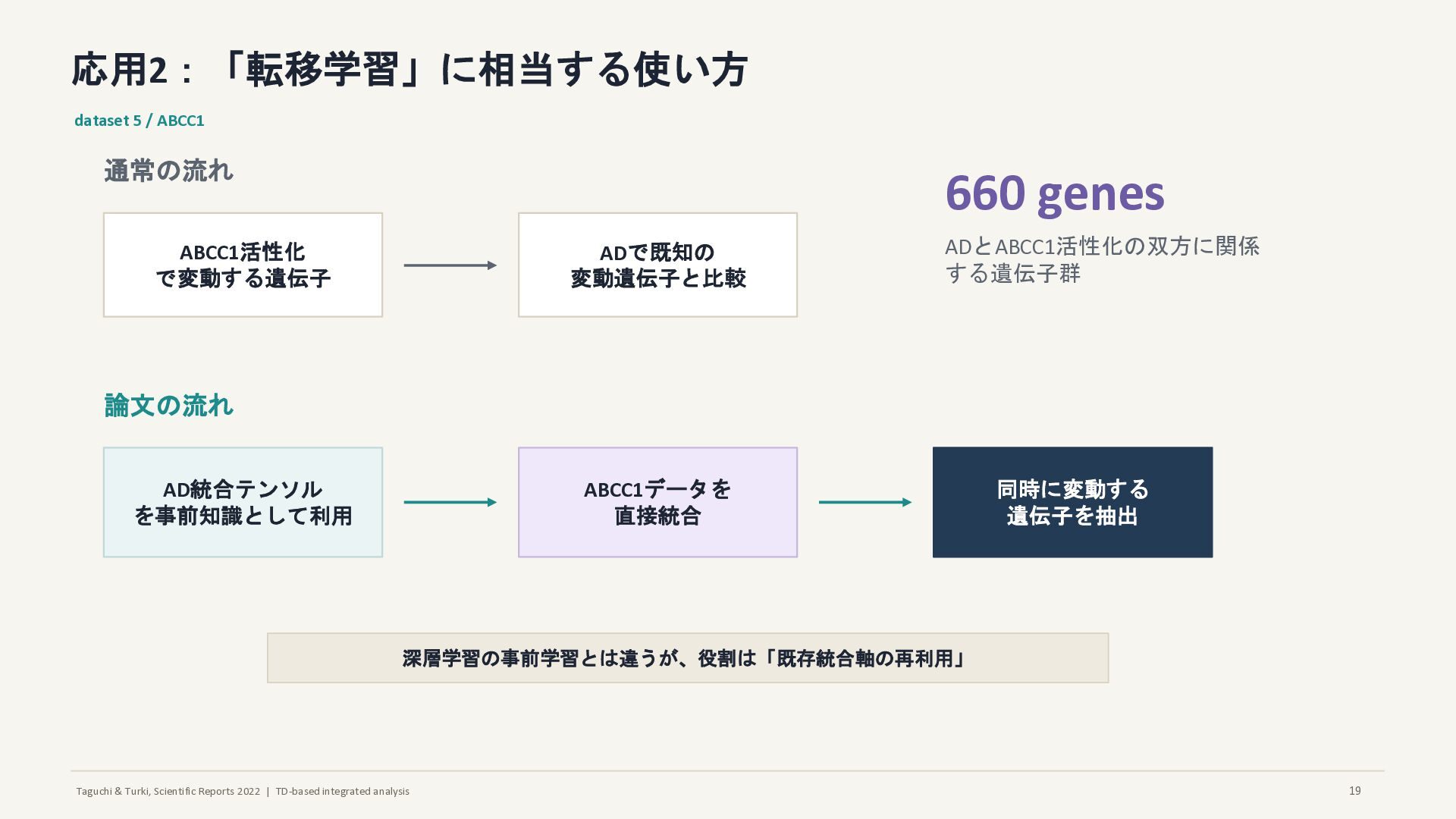
応用2:「転移学習」に相当する使い方 dataset 5 / ABCC1 通常の流れ ABCC1活性化 で変動する遺伝子 ADで既知の 変動遺伝子と比較 論文の流れ AD統合テンソル を事前知識として利用 ABCC1データを 直接統合 同時に変動する 遺伝子を抽出 660 genes ADとABCC1活性化の双方に関係 する遺伝子群 深層学習の事前学習とは違うが、役割は「既存統合軸の再利用」 19
20 Figure S4:Transfer learning時のboxplot 原図表 補足資料のFigure S4を直接取り込み。ABCC1過剰発現データを加えた場合の潜在変数と分類の対応を示す。 出典:Taguchi & Turki,
Scientific Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
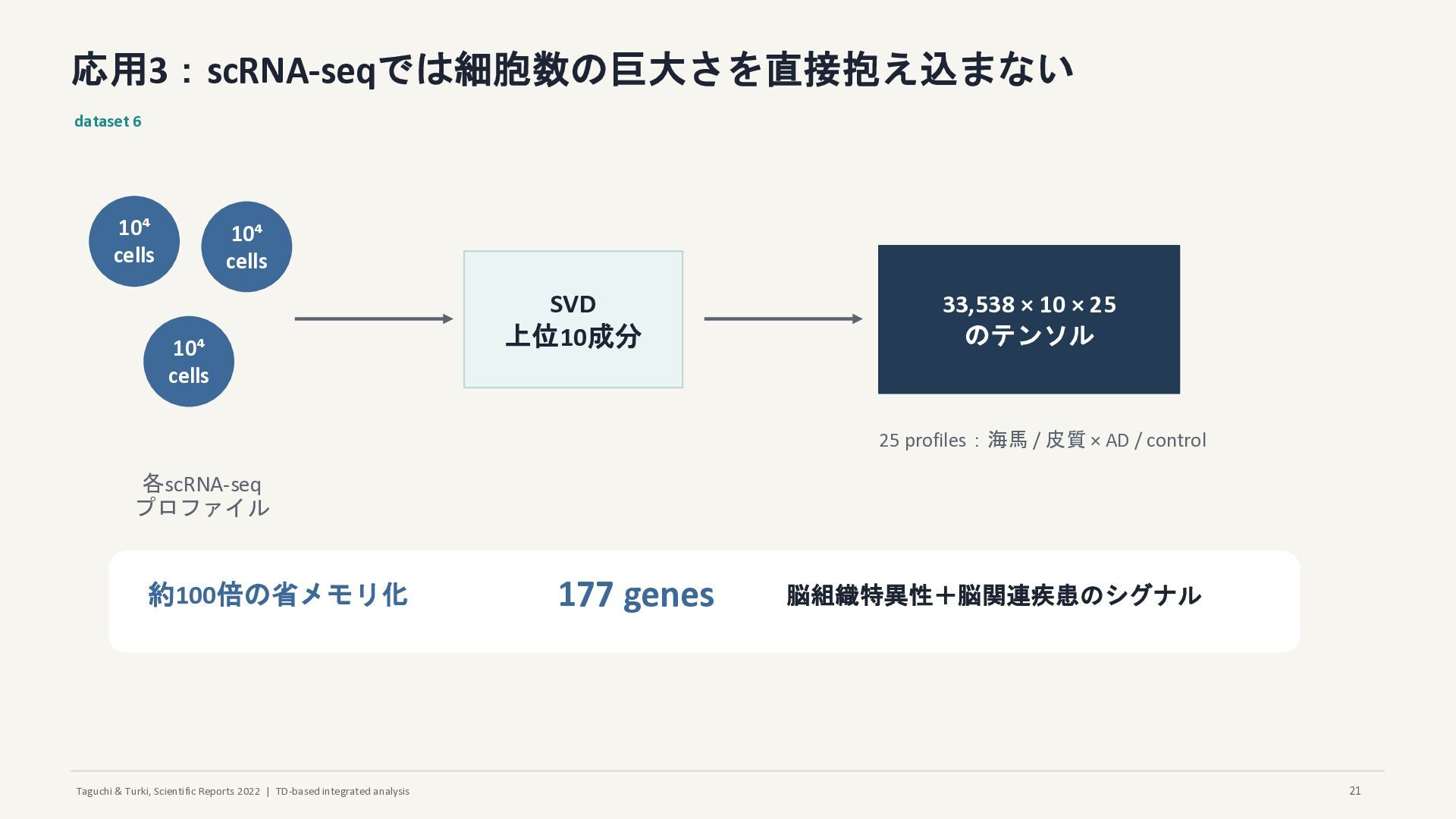
応用3:scRNA-seqでは細胞数の巨大さを直接抱え込まない dataset 6 10⁴ cells 10⁴ cells 10⁴ cells 各scRNA-seq プロファイル SVD 上位10成分 33,538 × 10 × 25 のテンソル 25 profiles:海馬 / 皮質 × AD / control 約100倍の省メモリ化 177 genes 脳組織特異性+脳関連疾患のシグナル 21
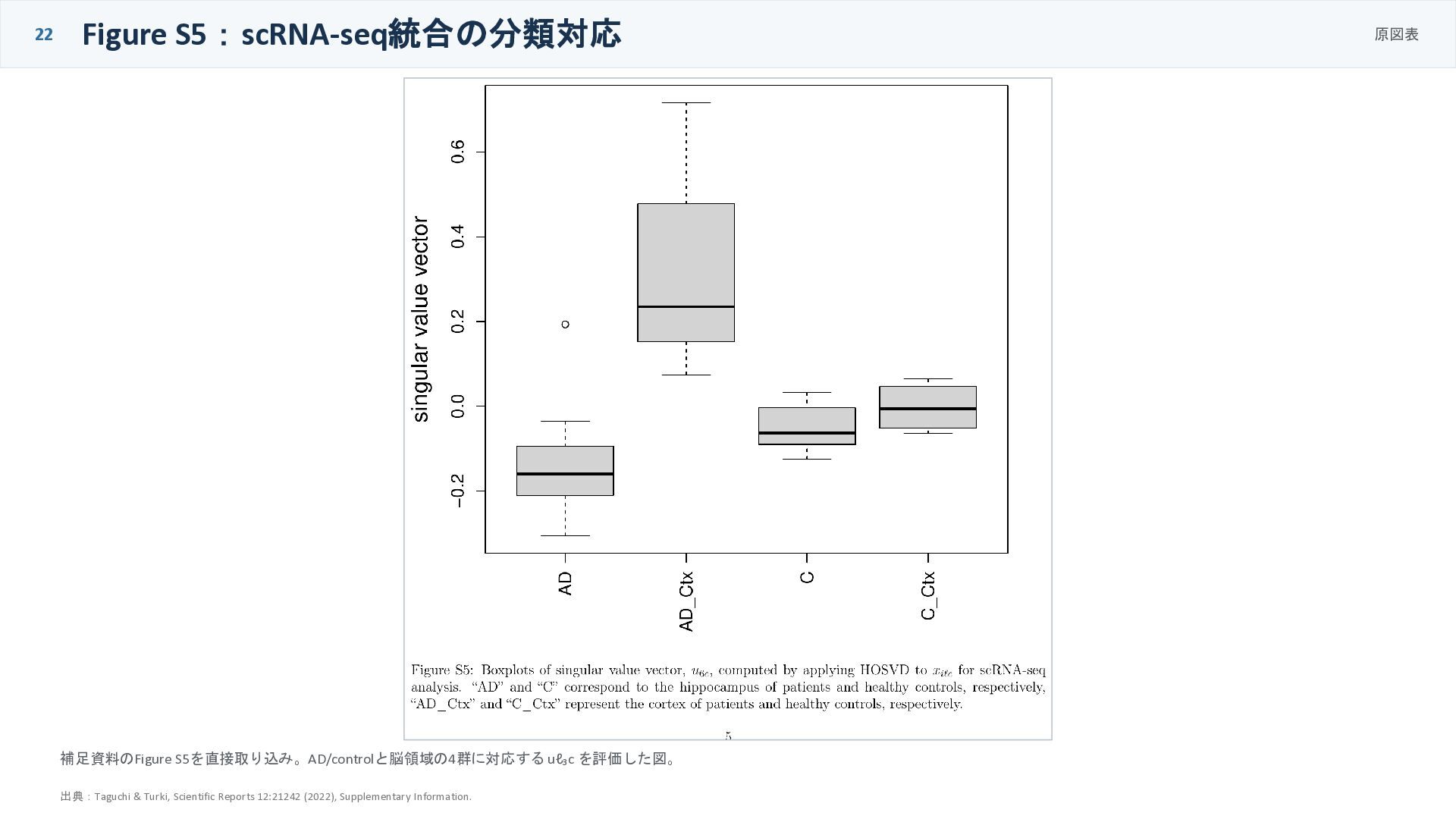
22 Figure S5:scRNA-seq統合の分類対応 原図表 補足資料のFigure S5を直接取り込み。AD/controlと脳領域の4群に対応する uℓ₃c を評価した図。 出典:Taguchi &
Turki, Scientific Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
scRNA-seqの結果の読み方 tissue specificity vs neurodegeneration RNA-seq統合とは濃縮結果の性質が少し違う 通常RNA-seq統合 神経変性疾患語が上位 scRNA-seq統合 Human Gene Atlasで脳組織が上 位 Disease Perturbations 脳関連疾患が多く出る 解釈 scRNA-seqでは、疾患差だけでなく、海馬・皮質などの組織差や細胞構成の違いが強く表れうる。 したがって、上位語が神経変性疾患そのものに限定されないことは、むしろ単一細胞データらしい結果 と読める。 23
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
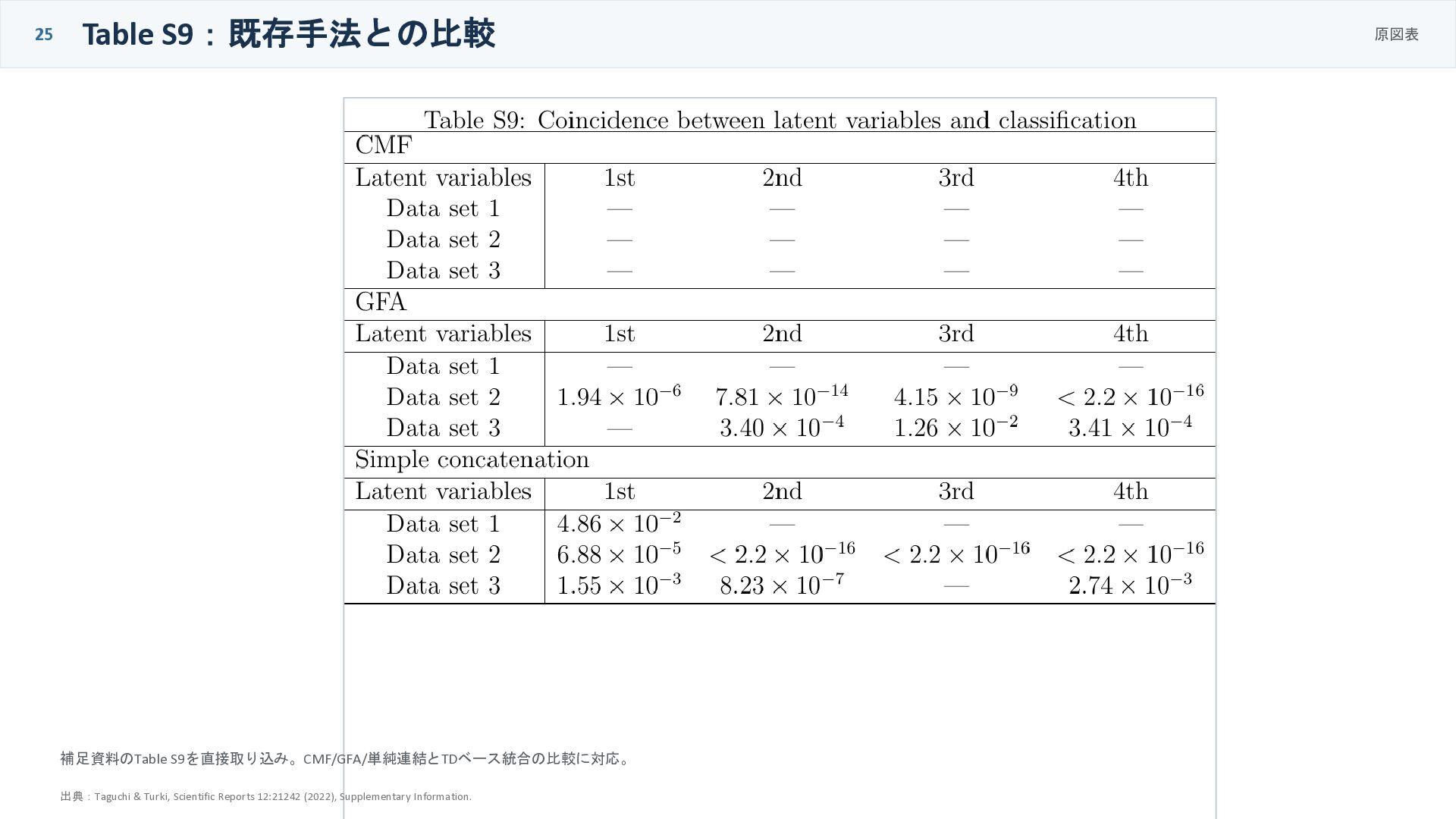
比較:既存法や単純連結より何が良いのか CMF / GFA / concatenation 方法 分類との対応 生物学的妥当性 TD-based FE 全3データの分類に 関連する成分を得る 神経変性関連の 濃縮が強い CMF 有意な潜在変数なし 不十分 GFA dataset 1で分類と 関連しない 不十分 単純連結 + SVD 一応関連するが弱い 147 genesで 濃縮が弱い 今回の目的は「サンプルを共有しない複数行列を統合する」こと。 既存の多くの統合・multi-view手法は、サンプル共有や共通ラベルを前提にしやすい。 24
25 Table S9:既存手法との比較 原図表 補足資料のTable S9を直接取り込み。CMF/GFA/単純連結とTDベース統合の比較に対応。 出典:Taguchi & Turki, Scientific
Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
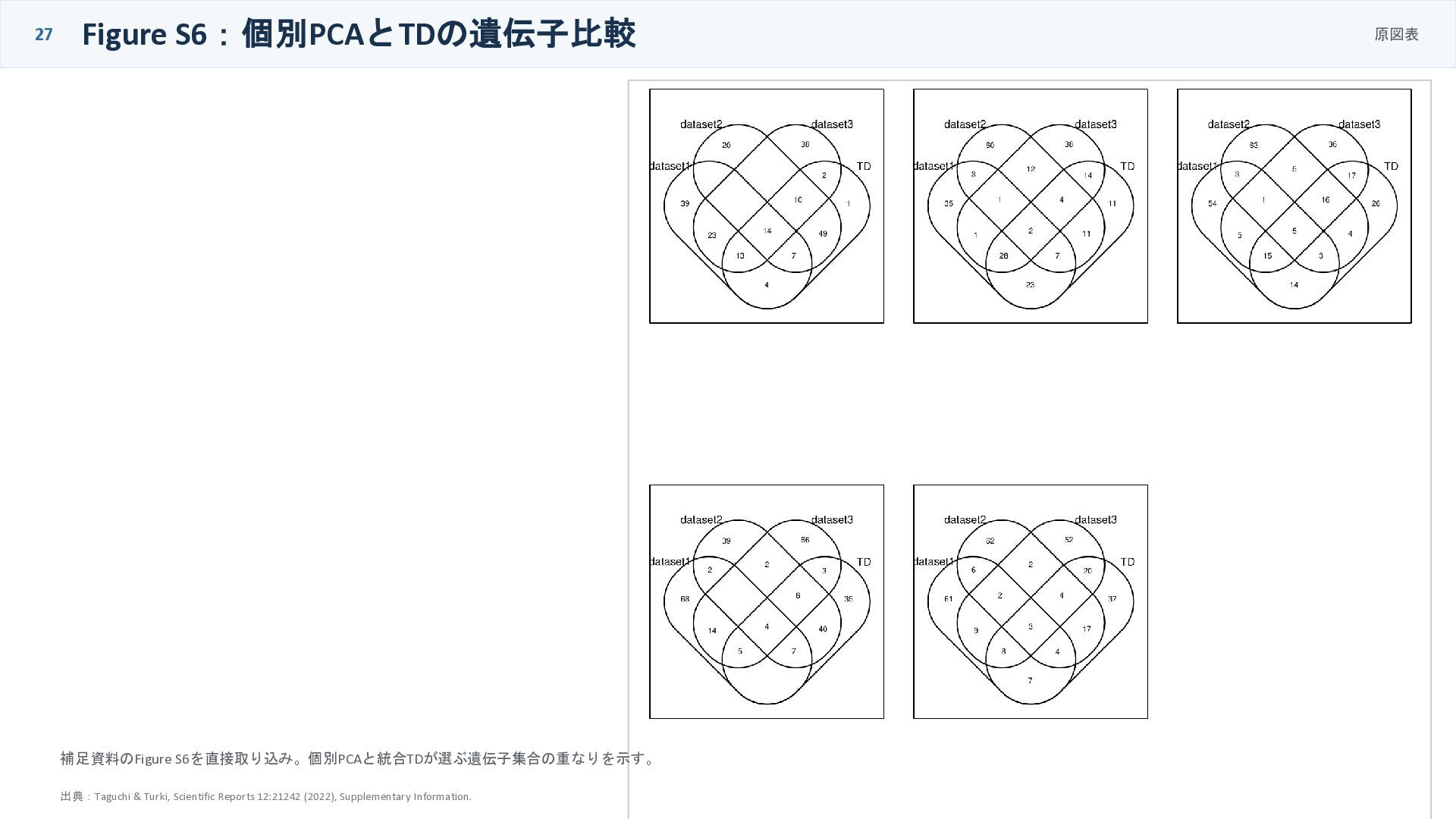
個別解析との比較:PCAを別々にかけるだけでは足りない separate PCA vs integrated TD 個別PCA dataset 1 dataset 2 dataset 3 それぞれのPCスコアは互いに相関しにくく、TDの uℓ₁i とも強く対応しない。 統合TD 共通の uℓ₁i 全データセットに有効な遺伝子方向 第4・第5成分のような、複数データにまたがる 重要成分も拾いやすい。 結論:別々に見てから重ねるより、最初から統合軸を推定するほうが本研究の目的に合う 26
27 Figure S6:個別PCAとTDの遺伝子比較 原図表 補足資料のFigure S6を直接取り込み。個別PCAと統合TDが選ぶ遺伝子集合の重なりを示す。 出典:Taguchi & Turki, Scientific
Reports 12:21242 (2022), Supplementary Information.
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
Discussion:この実装の利点 what the method enables 1. サンプル対応なしの統合 サンプル数が 9, 23, 8 のよう に異なる研究を、上位成分数 L にそろえて共通テンソル化 する。 2. 関係の可視化 共通遺伝子軸へ射影した vℓ₁jk を見ることで、異なる研究内 の分類やズレを比較できる。 3. 省メモリ化 scRNA-seqでは、全細胞を直 接統合せず、各プロファイル の上位成分だけを使う。 共通する考え方:大きく異なるデータを、まず低次元の「成分」に変換してから比較する 28
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
限界:何を主張しすぎてはいけないか classification and interpretation できること • サンプル対応なしに、データセット間の潜在的 対応を見る • データセット内サンプルを共通遺伝子軸へ射影 する • scRNA-seqの大量細胞を上位成分へ圧縮する 限界・注意点 • 分類性能を最大化する方法ではない • 通常のバッチ補正とは別問題 • 個別研究の目的と統合解析の比較軸は一致しな い • 生物学的解釈は濃縮解析などで検証が必要 この手法は「よく分類する」ためよりも、 異なる研究の間に共有される遺伝子方向を発見するための方法。 29
Taguchi & Turki, Scientific Reports 2022 | TD-based integrated analysis
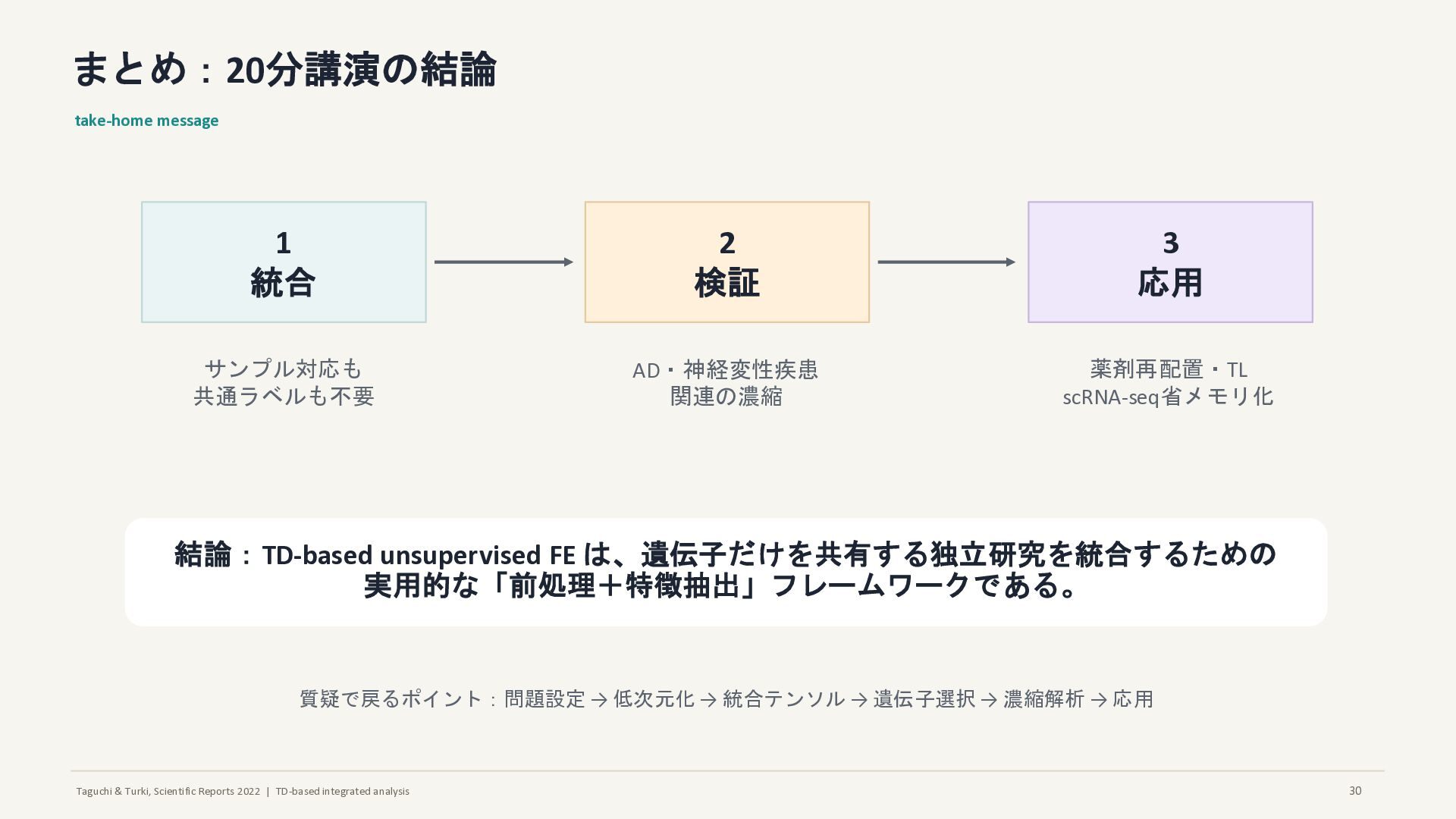
まとめ:20分講演の結論 take-home message 1 統合 2 検証 3 応用 サンプル対応も 共通ラベルも不要 AD・神経変性疾患 関連の濃縮 薬剤再配置・TL scRNA-seq省メモリ化 結論:TD-based unsupervised FE は、遺伝子だけを共有する独立研究を統合するための 実用的な「前処理+特徴抽出」フレームワークである。 質疑で戻るポイント:問題設定 → 低次元化 → 統合テンソル → 遺伝子選択 → 濃縮解析 → 応用 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}