Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
適応テンソル分解と主成分分析に基づく教師なし特徴抽出は、従来手法よりも生物学的に妥当な発現量差...
Search
Y-h. Taguchi
PRO
March 12, 2026
Science
57
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
適応テンソル分解と主成分分析に基づく教師なし特徴抽出は、従来手法よりも生物学的に妥当な発現量差のある遺伝子を選択する
SIGBIO84
https://www.ipsj.or.jp/kenkyukai/event/bio84.html
での講演スライドです。
Y-h. Taguchi
PRO
March 12, 2026
More Decks by Y-h. Taguchi
See All by Y-h. Taguchi
サンプル対応のない複数遺伝子発現プロファイルに対するテンソル分解型統合解析の要約
tagtag
PRO
0
210
AI(人工知能)の過去・現在・未来 ~AIは人類を越えるのか~
tagtag
PRO
0
120
presen_司法書士学員会.pdf
tagtag
PRO
1
86
生成AIと司法書士の未来.pdf
tagtag
PRO
0
140
データ駆動型ゲノム解析で迫る睡眠研究
tagtag
PRO
0
72
知能とはなにか -ヒトとAIのあいだ-
tagtag
PRO
0
96
Genomic Differentiation of Sleep and Anesthesia: The Role of RHO GTPase and Cortical Neurons
tagtag
PRO
0
57
睡眠と麻酔による無意識状態のゲノム的差異:RHO GTPaseと皮質ニューロンの役割
tagtag
PRO
0
83
Somatostatin-Expressing Neurons Regulate Sleep Deprivation and Recovery: A Data-Driven Transcriptomic Analysis
tagtag
PRO
1
58
Other Decks in Science
See All in Science
Endel Tulvingとエピソード記憶
rmaruy
0
150
AkarengaLT vol.40
hashimoto_kei
0
110
データベース01: データベースを使わない世界
trycycle
PRO
1
1.3k
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
1.1k
検索と推論タスクに関する論文の紹介
ynakano
1
250
Tensor Factorization Meets Deformed Information Geometry: Convex Relaxation under Deformed Algebra
gkazunii
0
120
YouTubeにおける撤回論文の参照実態 / metascience-meetup2026
corgies
3
310
Conversation is the New Dashboard: 属人性を排除する第4世代BIツールの勢力図
shomaekawa
1
610
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
380
やるべきときにMLをやる AIエージェント開発
fufufukakaka
2
1.5k
データベース03: 関係データモデル
trycycle
PRO
1
610
なぜエネルギーは保存する? 〜自由落下でわかる“対称性”とネーターの定理〜
syotasasaki593876
0
210
Featured
See All Featured
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Accessibility Awareness
sabderemane
1
160
Side Projects
sachag
455
43k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Odyssey Design
rkendrick25
PRO
2
730
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
The Spectacular Lies of Maps
axbom
PRO
1
860
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Transcript
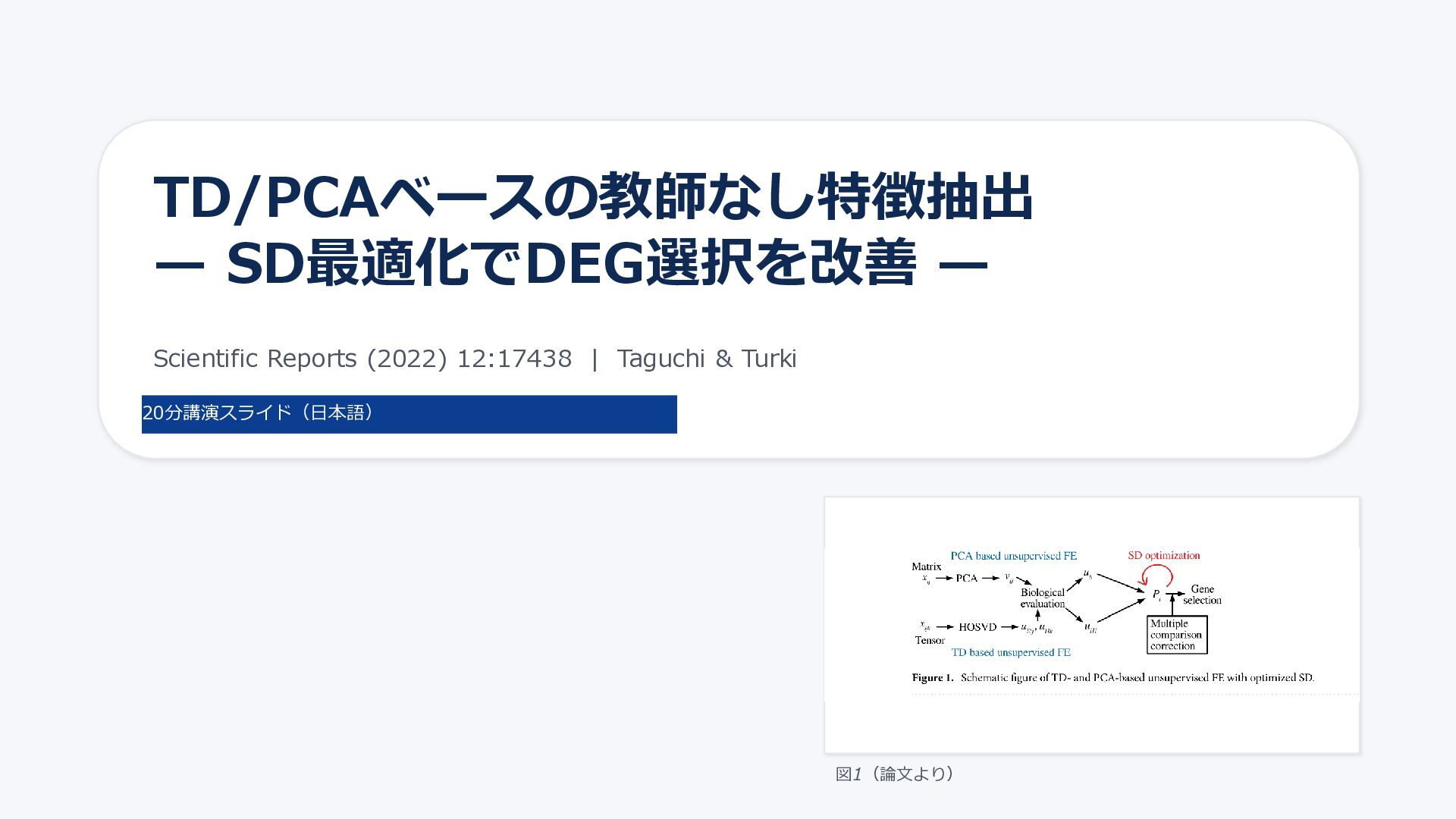
TD/PCAベースの教師なし特徴抽出 — SD最適化でDEG選択を改善 — Scientific Reports (2022) 12:17438 | Taguchi
& Turki 20分講演スライド(日本語) 図1(論文より)
本日の流れ 20分 アジェンダ 1. 背景:DEG選択の難しさ(large p, small n) 2. 方法:TD/PCAベース教師なし特徴抽出(FE)
3. 改良点:Gaussian仮定に合わせたSD最適化 4. 結果①:MAQC/SEQC(遺伝子数・分布の妥当性) 5. 結果②:SARS-CoV-2薬剤リポジショニング 6. 結果③:多臓器×多薬剤(生物学的妥当性) 7. まとめ Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 2
背景:DEG選択は「large p, small n」問題 背景 なぜ難しい? • 遺伝子数pが非常に多く、サンプル数nが少な い •
多重検定補正で有意になりにくい • 既存法(例:DESeq2)は - 負の二項分布(NB) - 分散関係(dispersion relation) などの仮定に依存 論文の狙い TD/PCAベース教師なしFEは、 「PC/特異値ベクトルがGaussianに従う 」 という比較的シンプルな仮定でDEGを抽 出。 ただし従来版は: • P値のヒストグラムが帰無仮説とズレ る • 選ばれる遺伝子数が少なすぎる → SD(標準偏差)を最適化して改善す る。 Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 3
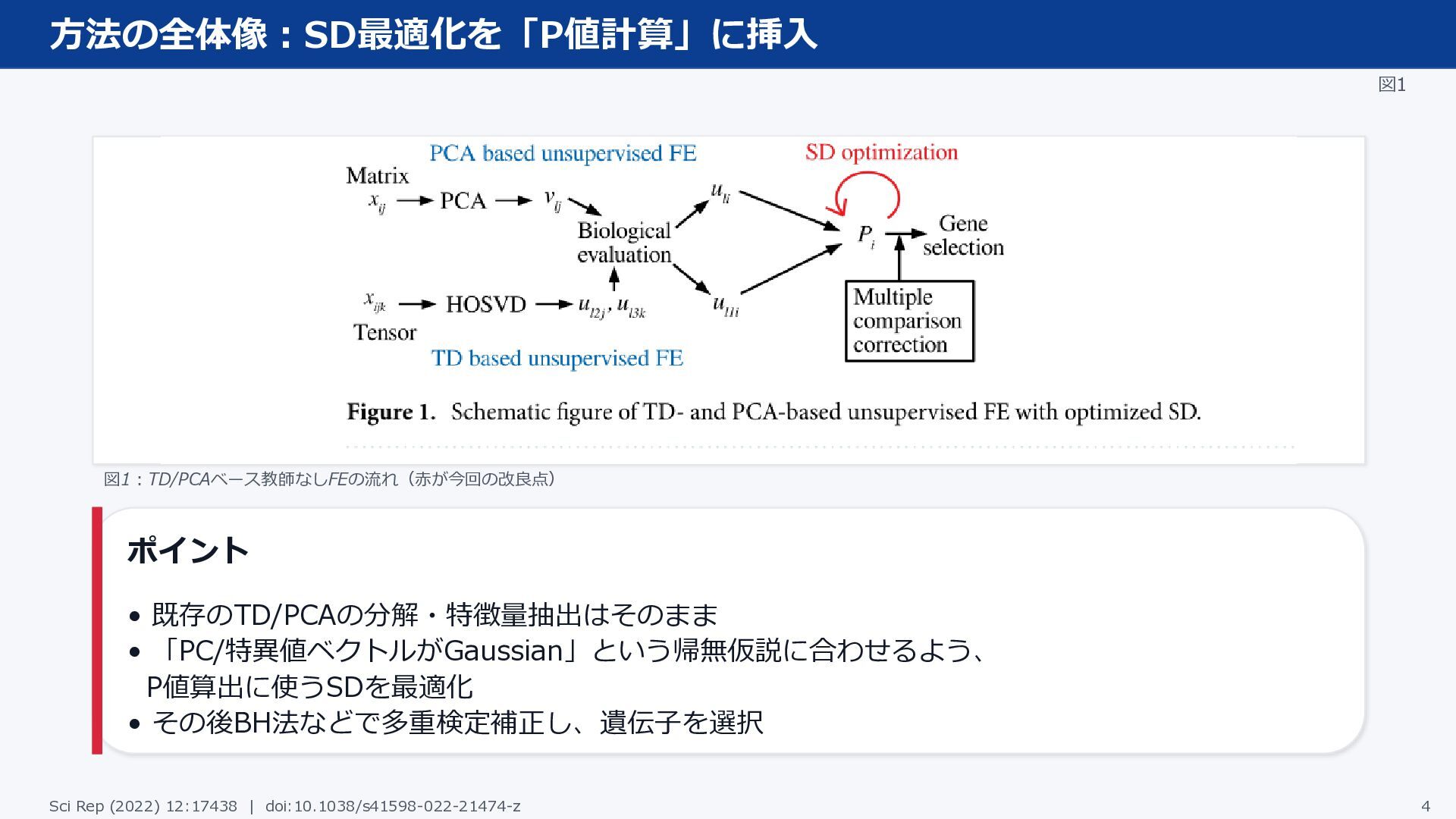
方法の全体像:SD最適化を「P値計算」に挿入 図1 図1:TD/PCAベース教師なしFEの流れ(赤が今回の改良点) ポイント • 既存のTD/PCAの分解・特徴量抽出はそのまま • 「PC/特異値ベクトルがGaussian」という帰無仮説に合わせるよう、 P値算出に使うSDを最適化 •
その後BH法などで多重検定補正し、遺伝子を選択 Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 4
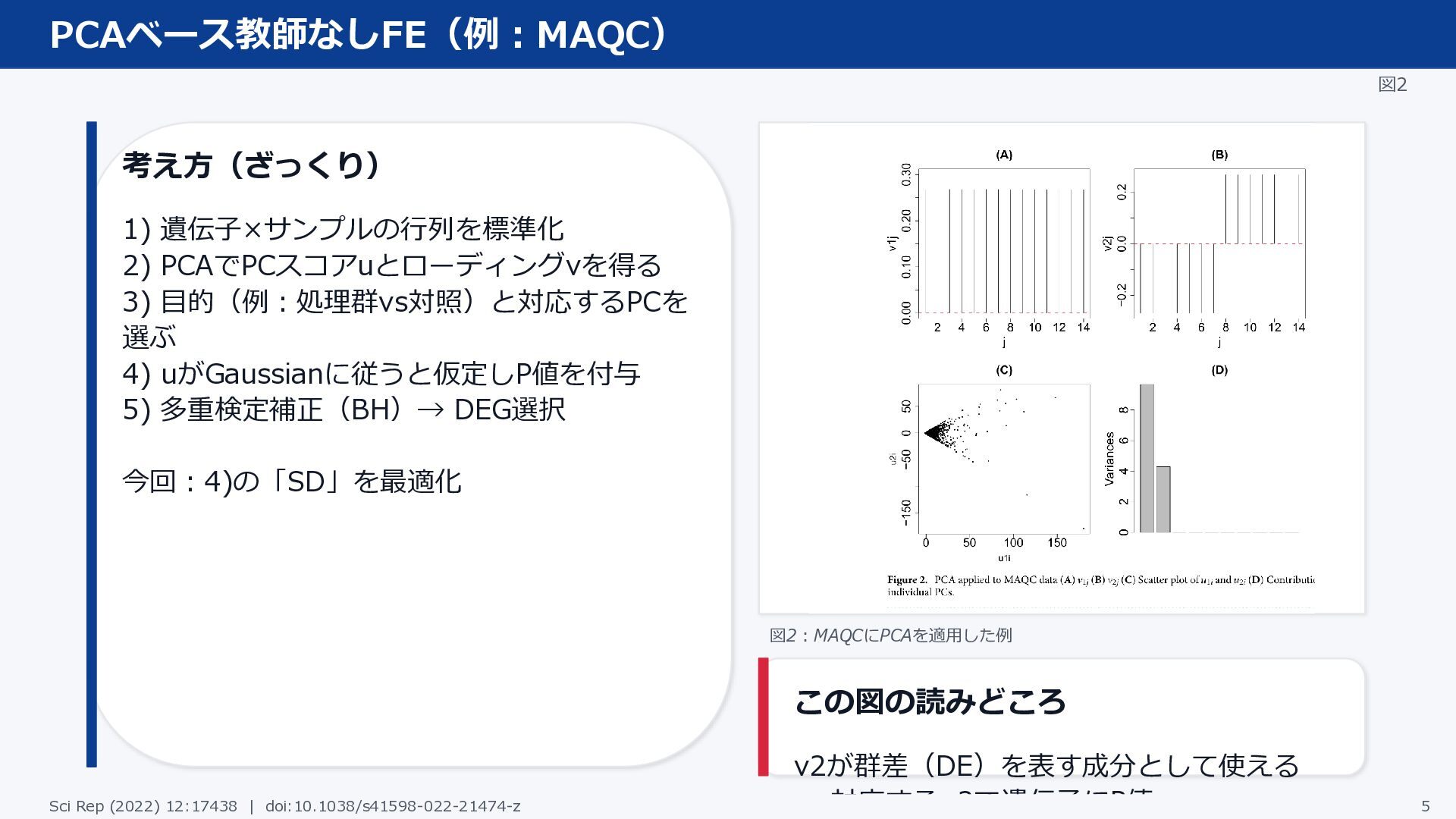
PCAベース教師なしFE(例:MAQC) 図2 考え方(ざっくり) 1) 遺伝子×サンプルの行列を標準化 2) PCAでPCスコアuとローディングvを得る 3) 目的(例:処理群vs対照)と対応するPCを 選ぶ
4) uがGaussianに従うと仮定しP値を付与 5) 多重検定補正(BH)→ DEG選択 今回:4)の「SD」を最適化 図2:MAQCにPCAを適用した例 この図の読みどころ v2が群差(DE)を表す成分として使える → 対応するu2で遺伝子にP値 Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 5
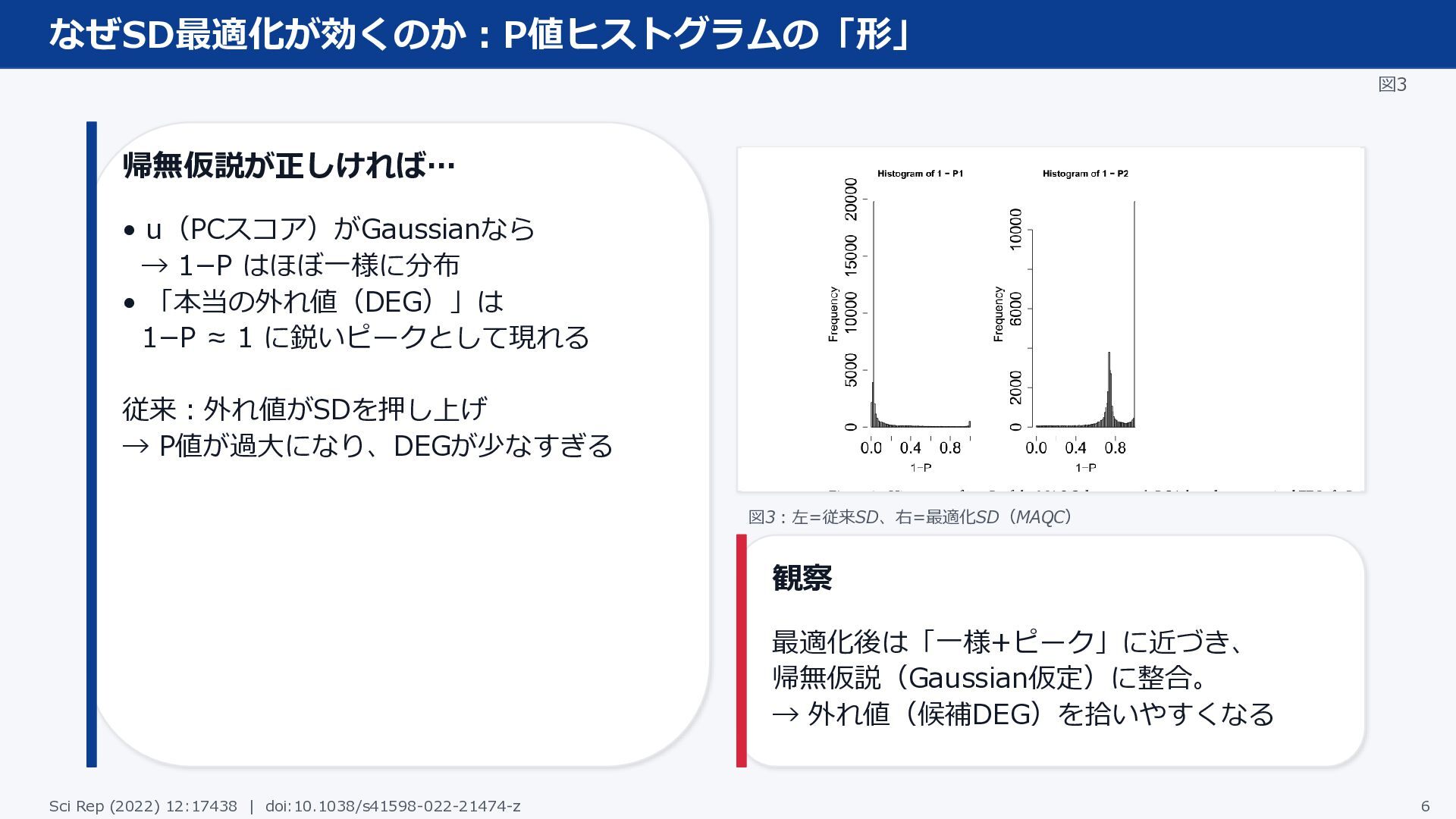
なぜSD最適化が効くのか:P値ヒストグラムの「形」 図3 帰無仮説が正しければ… • u(PCスコア)がGaussianなら → 1−P はほぼ一様に分布 • 「本当の外れ値(DEG)」は
1−P ≈ 1 に鋭いピークとして現れる 従来:外れ値がSDを押し上げ → P値が過大になり、DEGが少なすぎる 図3:左=従来SD、右=最適化SD(MAQC) 観察 最適化後は「一様+ピーク」に近づき、 帰無仮説(Gaussian仮定)に整合。 → 外れ値(候補DEG)を拾いやすくなる Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 6
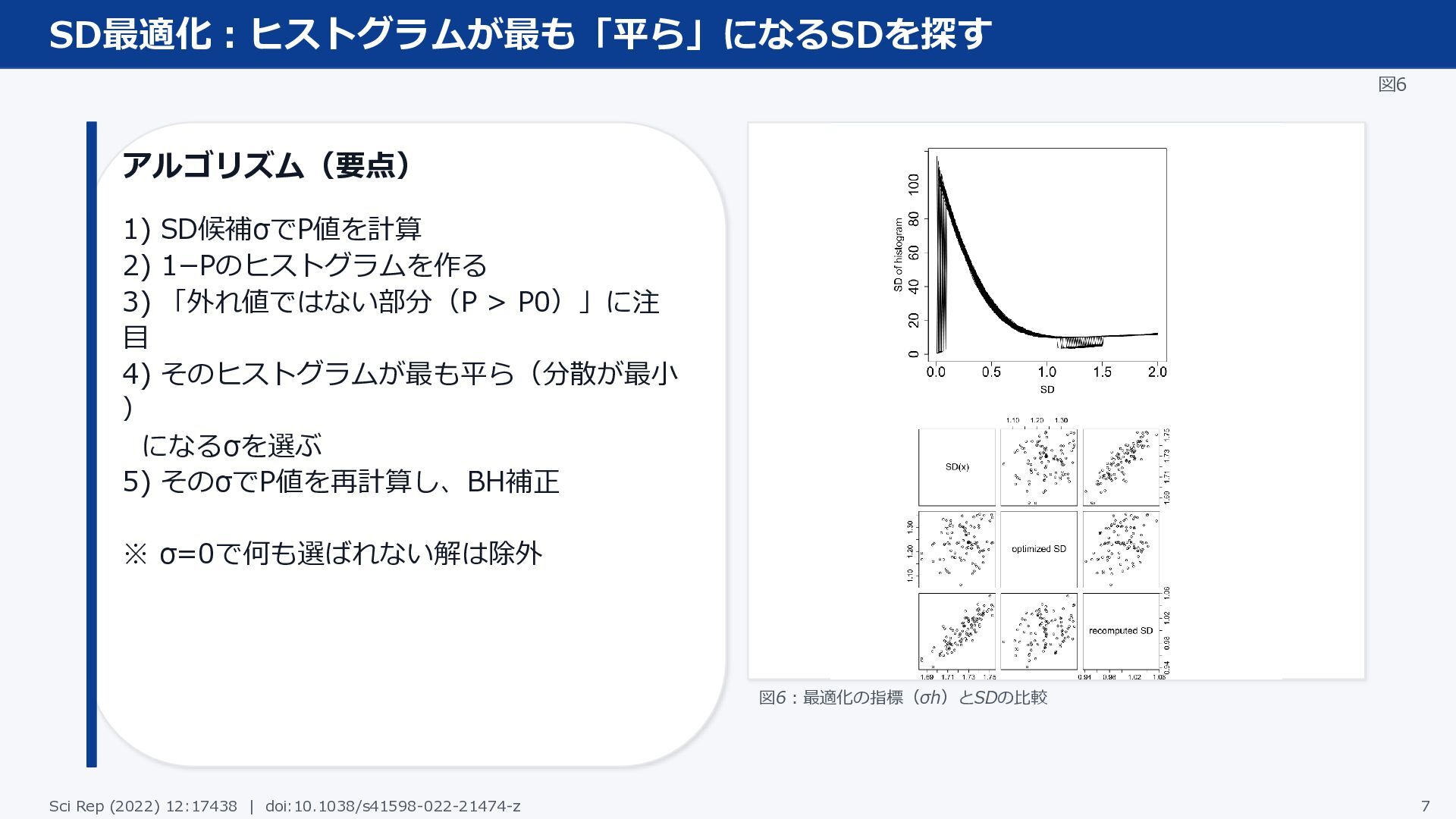
SD最適化:ヒストグラムが最も「平ら」になるSDを探す 図6 アルゴリズム(要点) 1) SD候補σでP値を計算 2) 1−Pのヒストグラムを作る 3) 「外れ値ではない部分(P >
P0)」に注 目 4) そのヒストグラムが最も平ら(分散が最小 ) になるσを選ぶ 5) そのσでP値を再計算し、BH補正 ※ σ=0で何も選ばれない解は除外 図6:最適化の指標(σh)とSDの比較 Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 7
結果①:MAQC(選択された遺伝子数が「現実的」へ) 表3 表3の要点 • 従来PCA-FE:344遺伝子(adj.P ≤ 0.01) • 最適化PCA-FE:12,252遺伝子 •
DESeq2:20,546遺伝子 論文の主張: 「344は少なすぎ、20,546は多すぎ」 最適化PCA-FEは中庸で、 偽陰性・偽陽性のバランスが改善 表3:MAQCでの遺伝子選択数 補足(MAQC) • P値の絶対値が適切になり、上位遺伝子ランキング 自体はDESeq2と整合(AUC高) • 「数が増えた」だけでなく、生物学的なエンリッチ メントも改善(後続図) Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 8
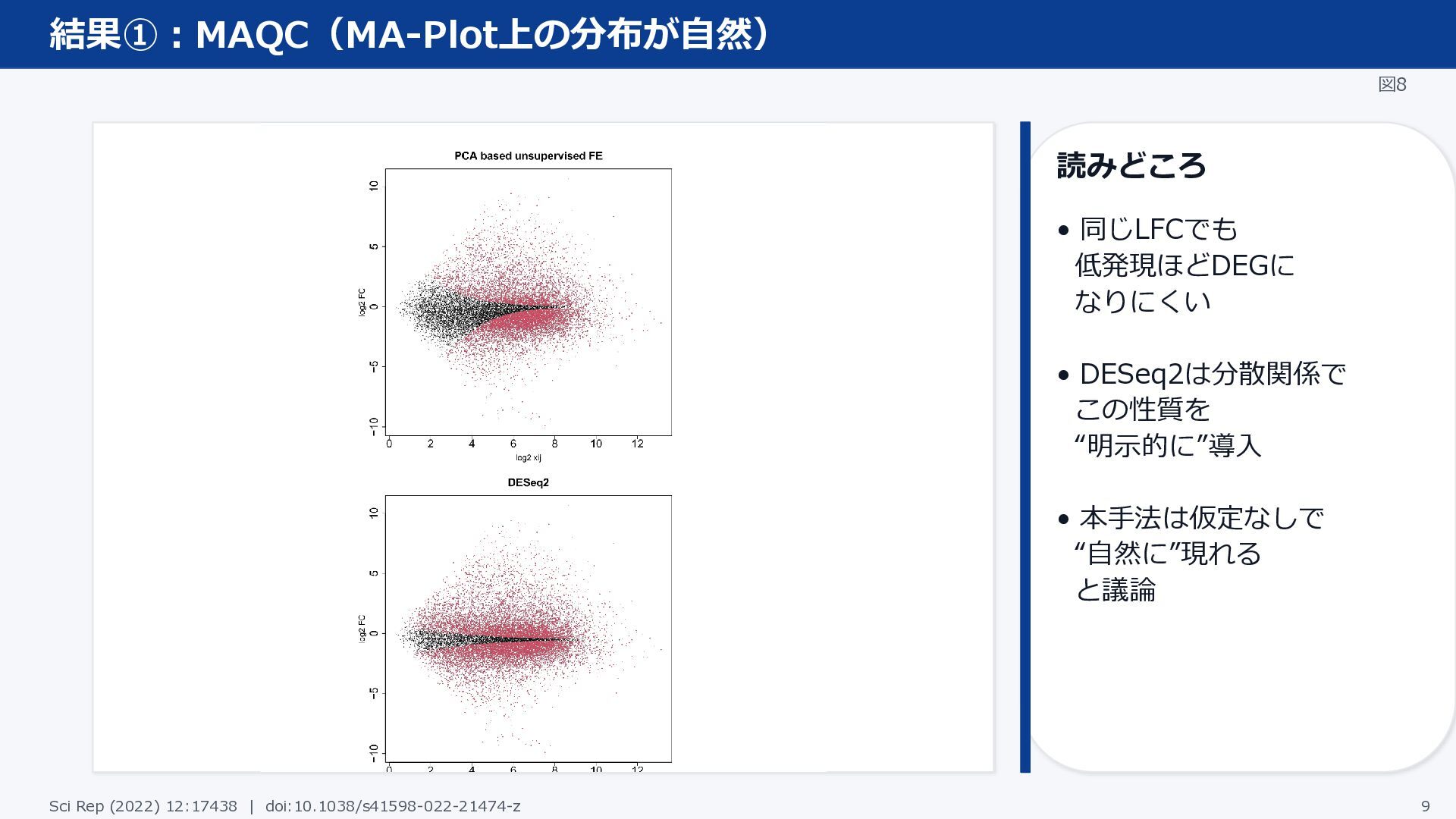
結果①:MAQC(MA-Plot上の分布が自然) 図8 読みどころ • 同じLFCでも 低発現ほどDEGに なりにくい • DESeq2は分散関係で この性質を
“明示的に”導入 • 本手法は仮定なしで “自然に”現れる と議論 Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 9
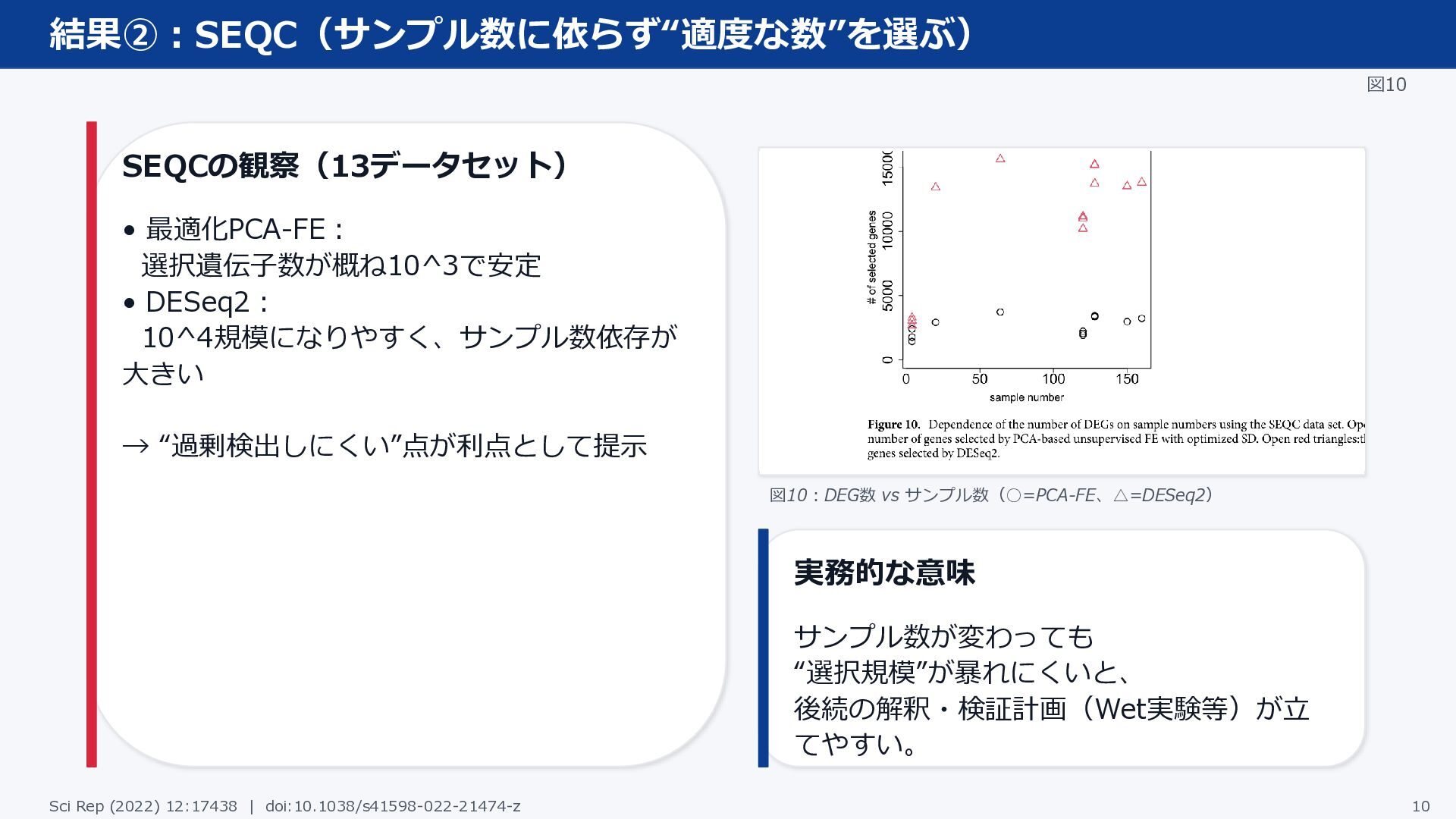
結果②:SEQC(サンプル数に依らず“適度な数”を選ぶ) 図10 SEQCの観察(13データセット) • 最適化PCA-FE: 選択遺伝子数が概ね10^3で安定 • DESeq2: 10^4規模になりやすく、サンプル数依存が 大きい
→ “過剰検出しにくい”点が利点として提示 図10:DEG数 vs サンプル数(◦=PCA-FE、△=DESeq2) 実務的な意味 サンプル数が変わっても “選択規模”が暴れにくいと、 後続の解釈・検証計画(Wet実験等)が立 てやすい。 Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 10
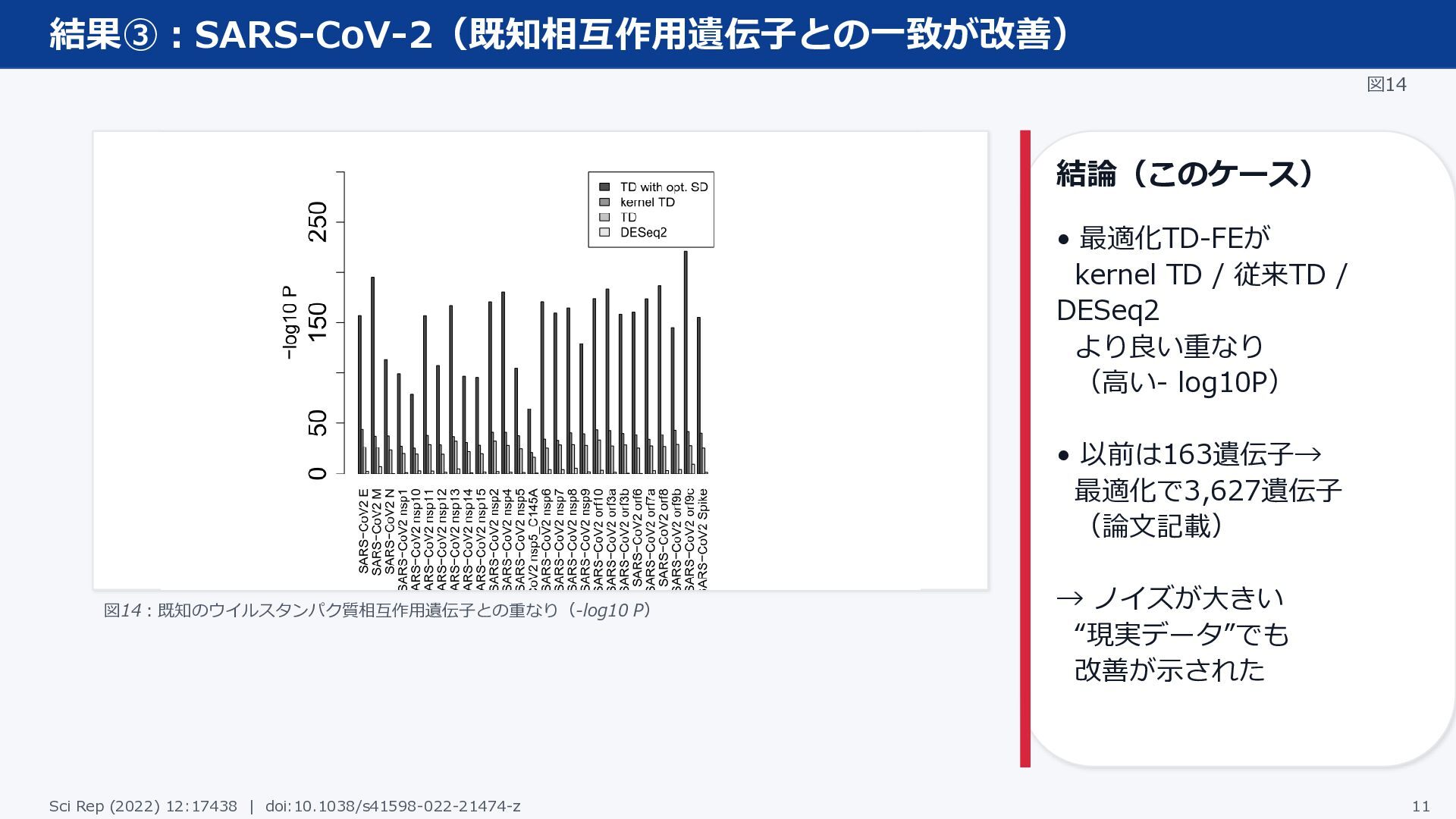
結果③:SARS-CoV-2(既知相互作用遺伝子との一致が改善) 図14 図14:既知のウイルスタンパク質相互作用遺伝子との重なり(-log10 P) 結論(このケース) • 最適化TD-FEが kernel TD /
従来TD / DESeq2 より良い重なり (高い- log10P) • 以前は163遺伝子→ 最適化で3,627遺伝子 (論文記載) → ノイズが大きい “現実データ”でも 改善が示された Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 11
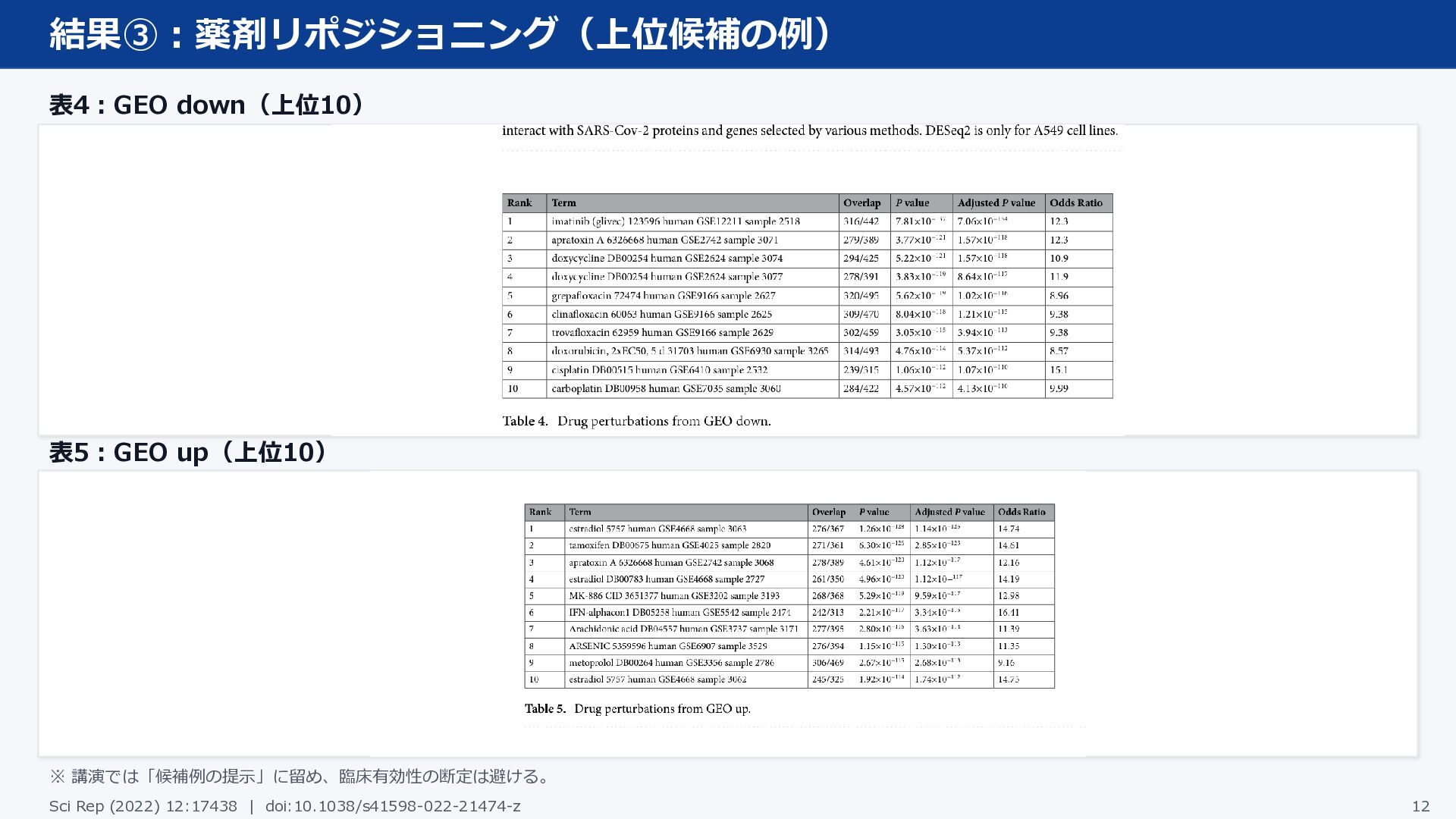
結果③:薬剤リポジショニング(上位候補の例) 表4:GEO down(上位10) 表5:GEO up(上位10) ※ 講演では「候補例の提示」に留め、臨床有効性の断定は避ける。 Sci Rep (2022)
12:17438 | doi:10.1038/s41598-022-21474-z 12
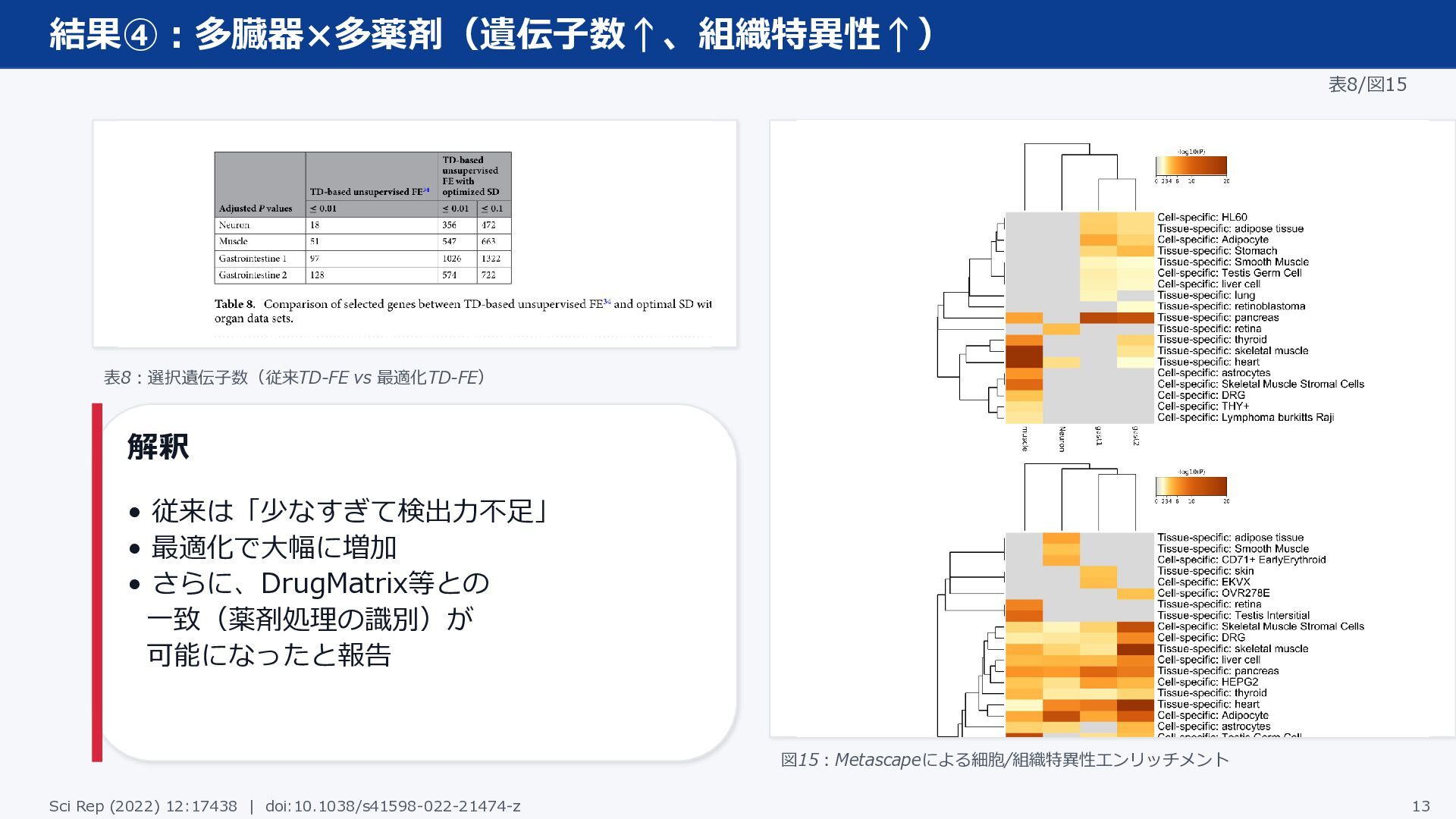
結果④:多臓器×多薬剤(遺伝子数↑、組織特異性↑) 表8/図15 表8:選択遺伝子数(従来TD-FE vs 最適化TD-FE) 解釈 • 従来は「少なすぎて検出力不足」 • 最適化で大幅に増加
• さらに、DrugMatrix等との 一致(薬剤処理の識別)が 可能になったと報告 図15:Metascapeによる細胞/組織特異性エンリッチメント Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 13
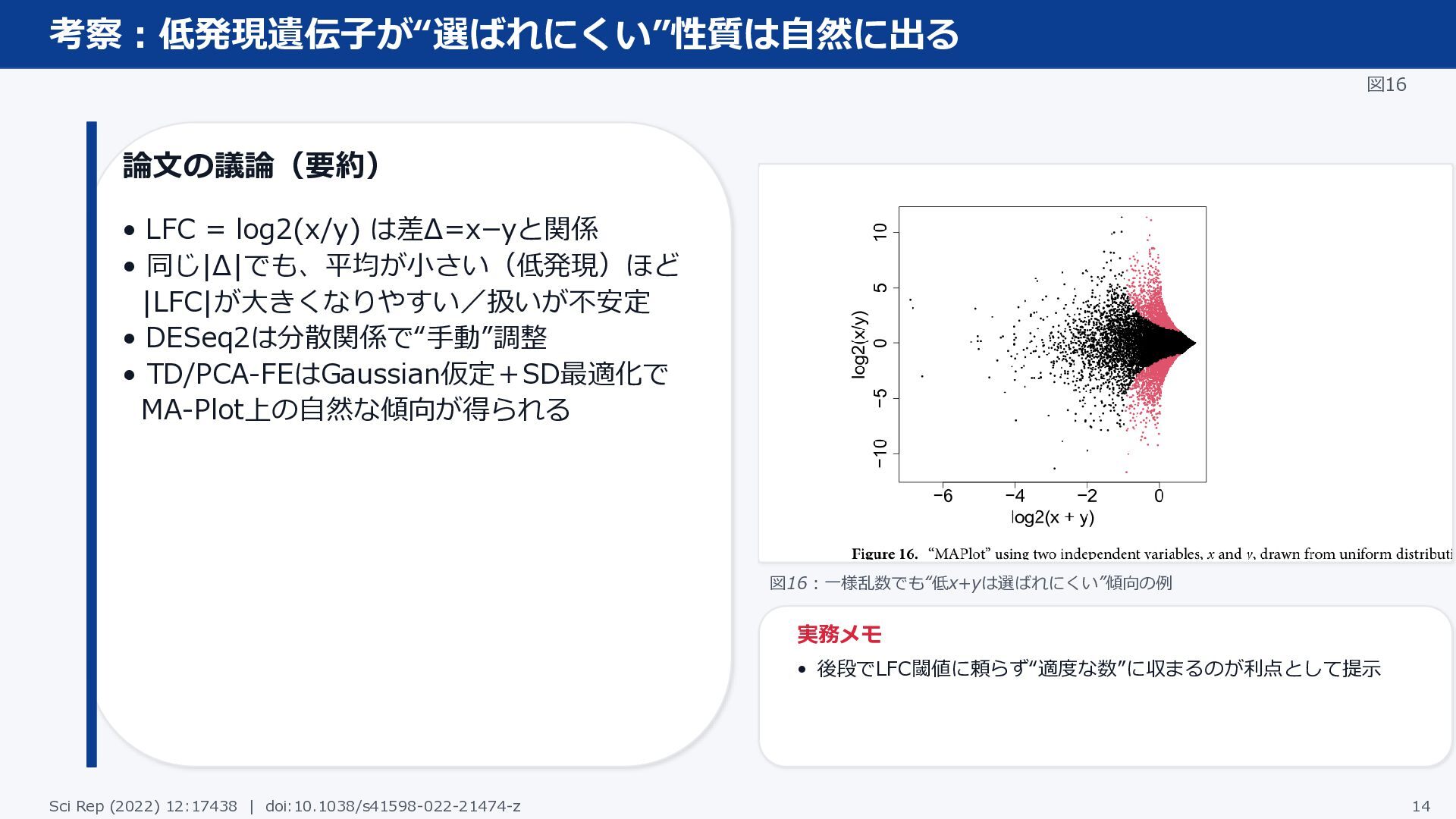
考察:低発現遺伝子が“選ばれにくい”性質は自然に出る 図16 論文の議論(要約) • LFC = log2(x/y) は差Δ=x−yと関係 • 同じ|Δ|でも、平均が小さい(低発現)ほど
|LFC|が大きくなりやすい/扱いが不安定 • DESeq2は分散関係で“手動”調整 • TD/PCA-FEはGaussian仮定+SD最適化で MA-Plot上の自然な傾向が得られる 図16:一様乱数でも“低x+yは選ばれにくい”傾向の例 実務メモ • 後段でLFC閾値に頼らず“適度な数”に収まるのが利点として提示 Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 14
まとめ Takeaways 今日の持ち帰り • TD/PCAベース教師なしFEは「Gaussian仮定」でDEGを抽出できる。 • 問題だった“P値ヒストグラムのズレ”と“遺伝子数の少なさ”を、SD最適化で改善。 • MAQC/SEQCなどのベンチマークで、過少・過剰検出のバランスが良い結果を提示。 •
SARS-CoV-2や多臓器データでも、生物学的妥当性(既知相互作用・組織特異性)が改善。 次の一歩:自分のデータで「P値ヒストグラムの形」と「選択数」をまず確認。 ご清聴ありがとうございました(質疑) Sci Rep (2022) 12:17438 | doi:10.1038/s41598-022-21474-z 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}