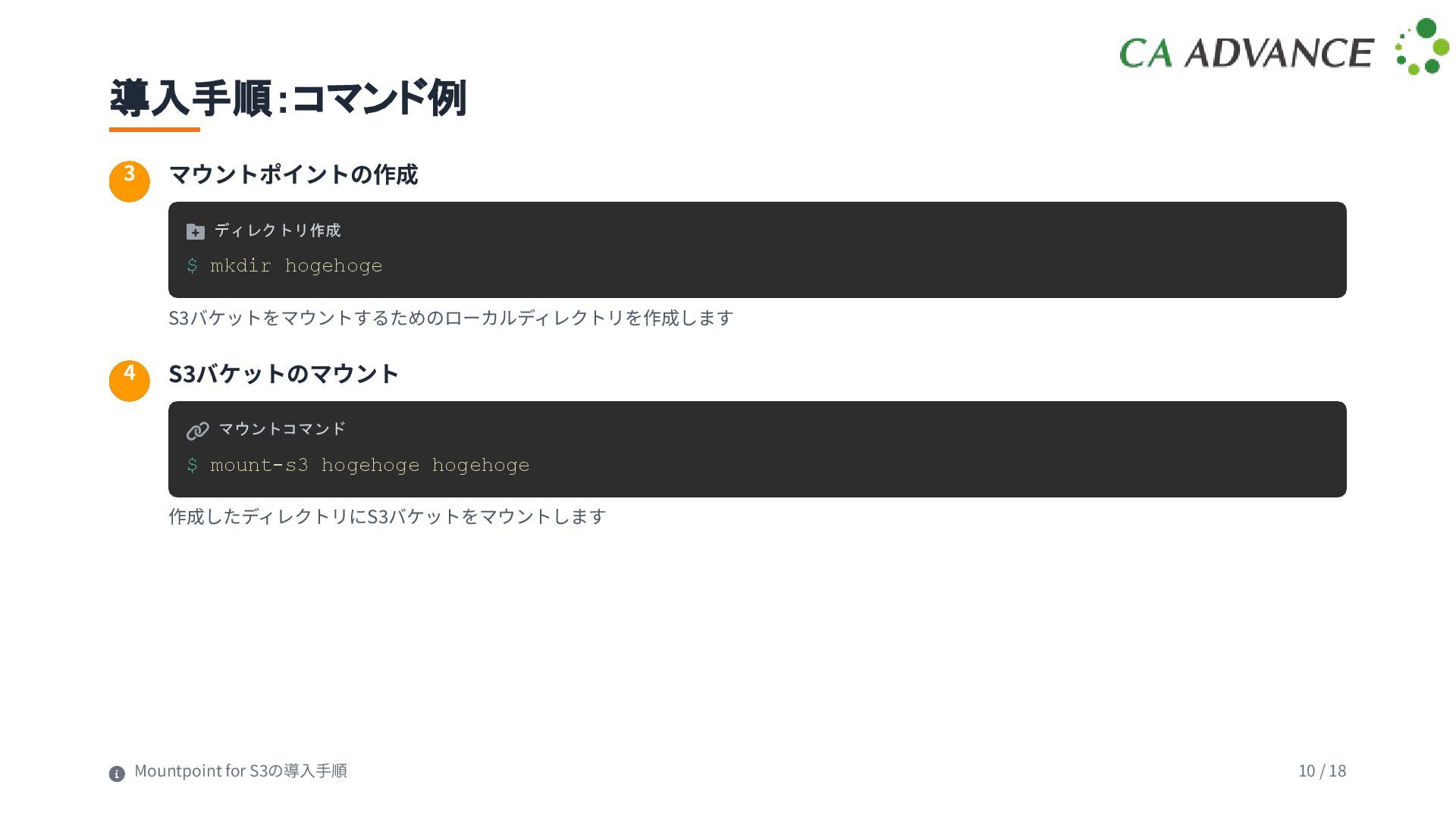
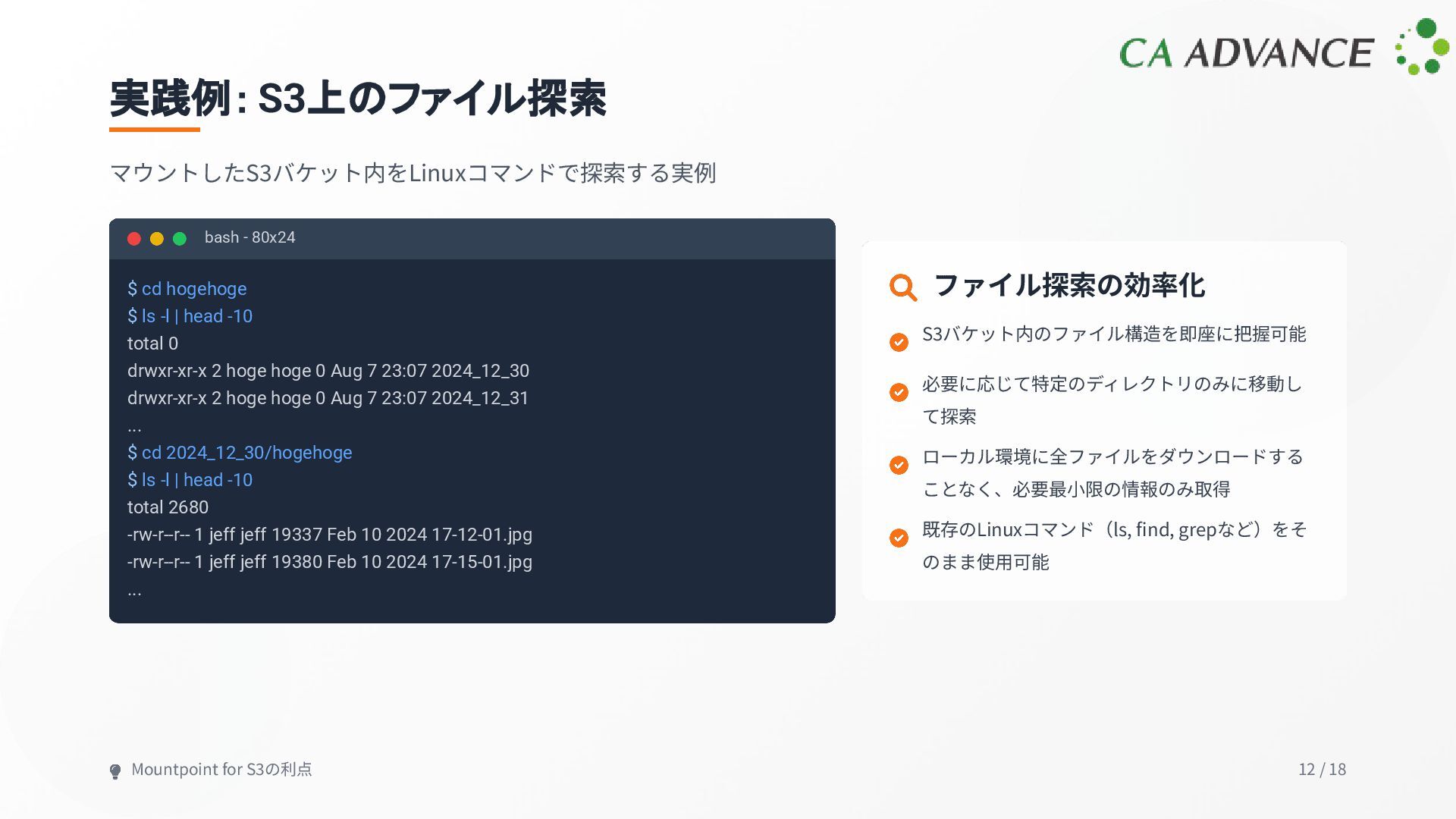
-l | head -10 total 0 drwxr-xr-x 2 hoge hoge 0 Aug 7 23:07 2024_12_30 drwxr-xr-x 2 hoge hoge 0 Aug 7 23:07 2024_12_31 ... $ cd 2024_12_30/hogehoge $ ls -l | head -10 total 2680 -rw-r--r-- 1 jeff jeff 19337 Feb 10 2024 17-12-01.jpg -rw-r--r-- 1 jeff jeff 19380 Feb 10 2024 17-15-01.jpg ... ファイル探索の効率化 S3バケット内のファイル構造を即座に把握可能 必要に応じて特定のディレクトリのみに移動し て探索 ローカル環境に全ファイルをダウンロードする ことなく、必要最⼩限の情報のみ取得 既存のLinuxコマンド(ls, find, grepなど)をそ のまま使⽤可能 Mountpoint for S3の利点 12 / 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}