CMU Database Group - Future Data Systems Seminar Series (Fall 2025)
Speaker: Jark Wu ( / jarkwu )
December 8, 2025
https://db.cs.cmu.edu/events/future-data-apache-fluss-a-streaming-storage-for-real-time-lakehouse/
YouTube: https://www.youtube.com/watch?v=mcFHZFb1CAo
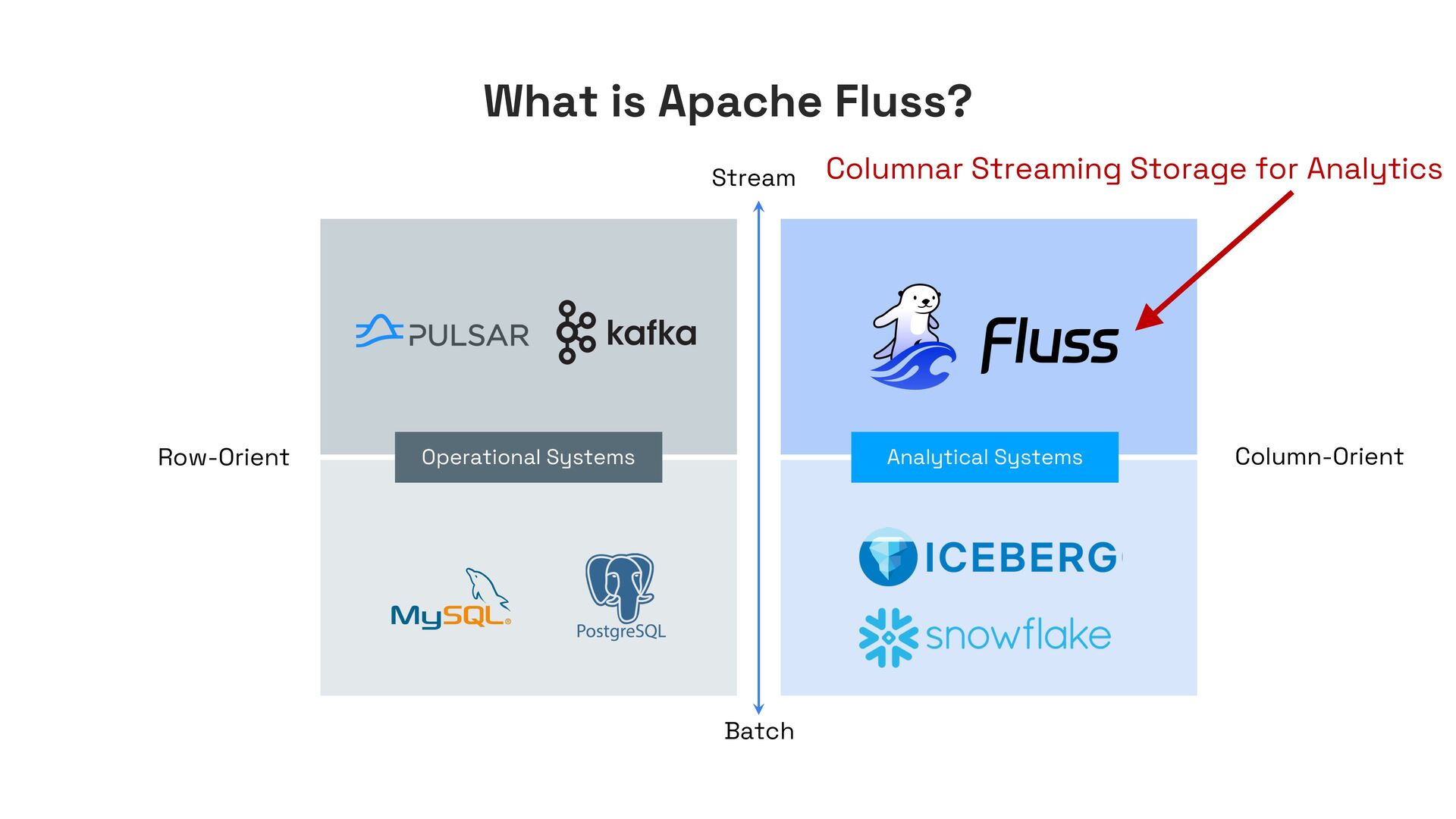
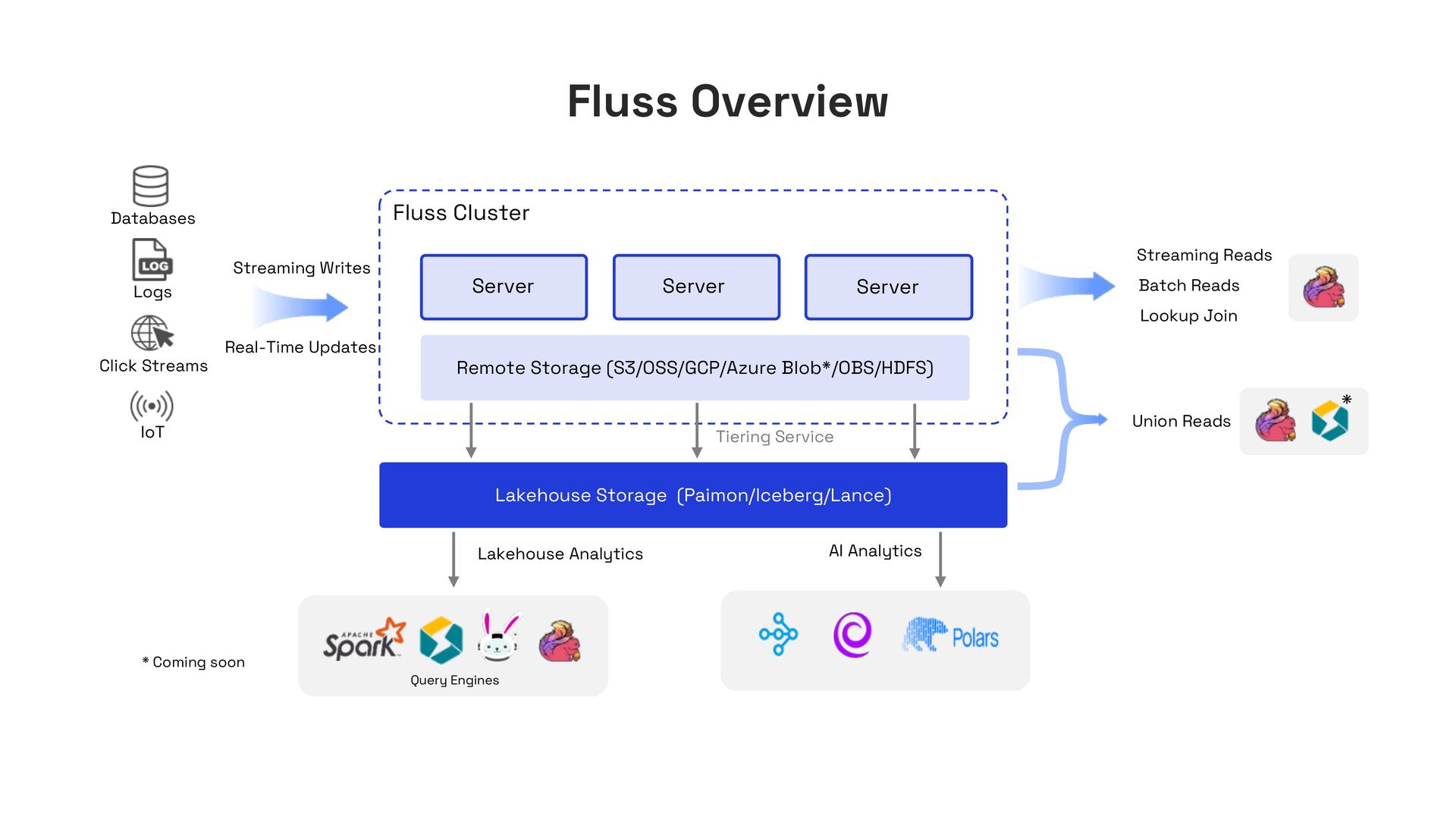
Modern data lakehouses promise unified batch and streaming processing, yet their storage layer remains inherently batch-oriented—optimized for large, immutable files. This mismatch forces streaming workloads to rely on external systems (e.g., Kafka), while analytical queries operate on stale snapshots, breaking end-to-end freshness.
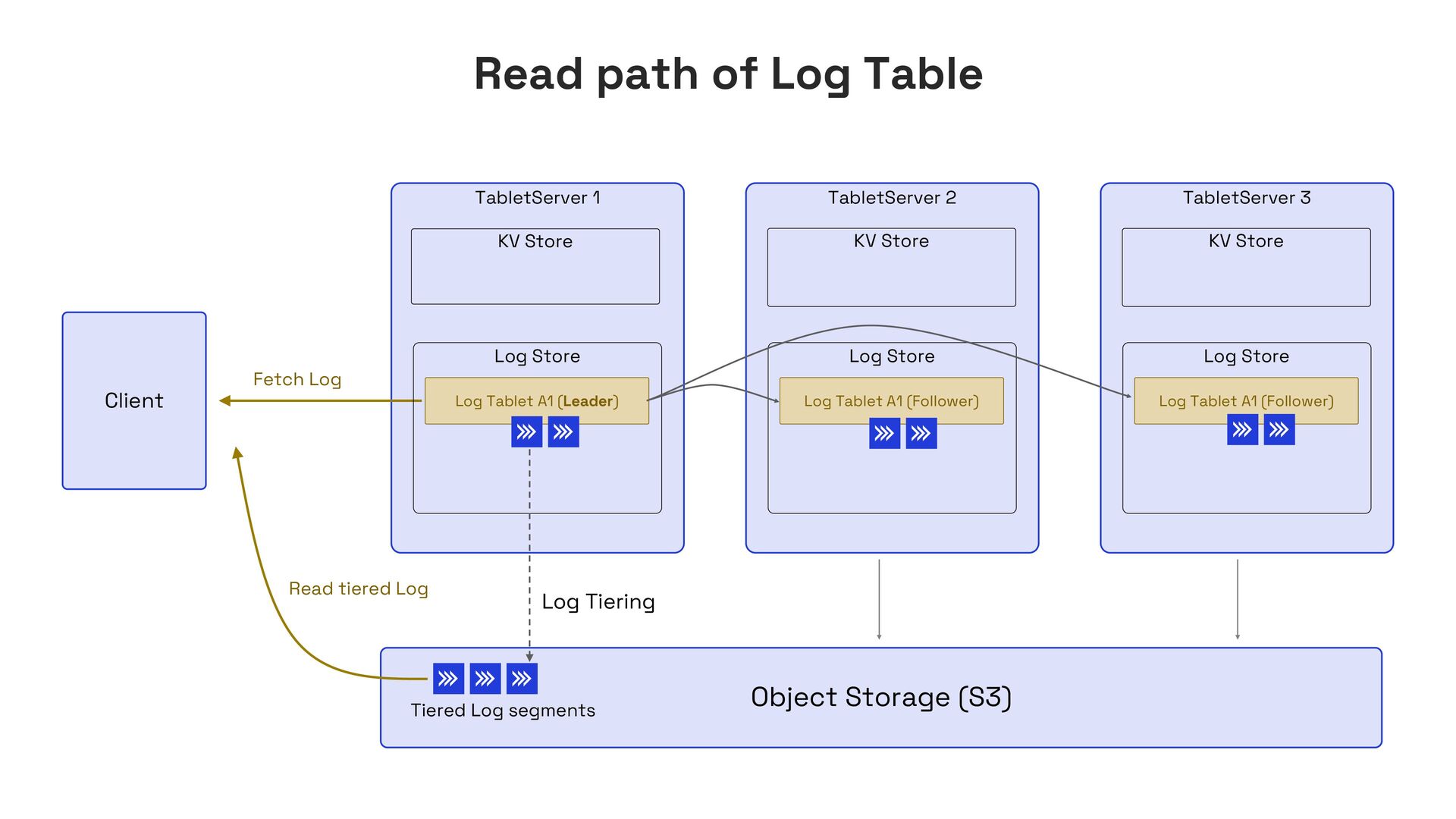
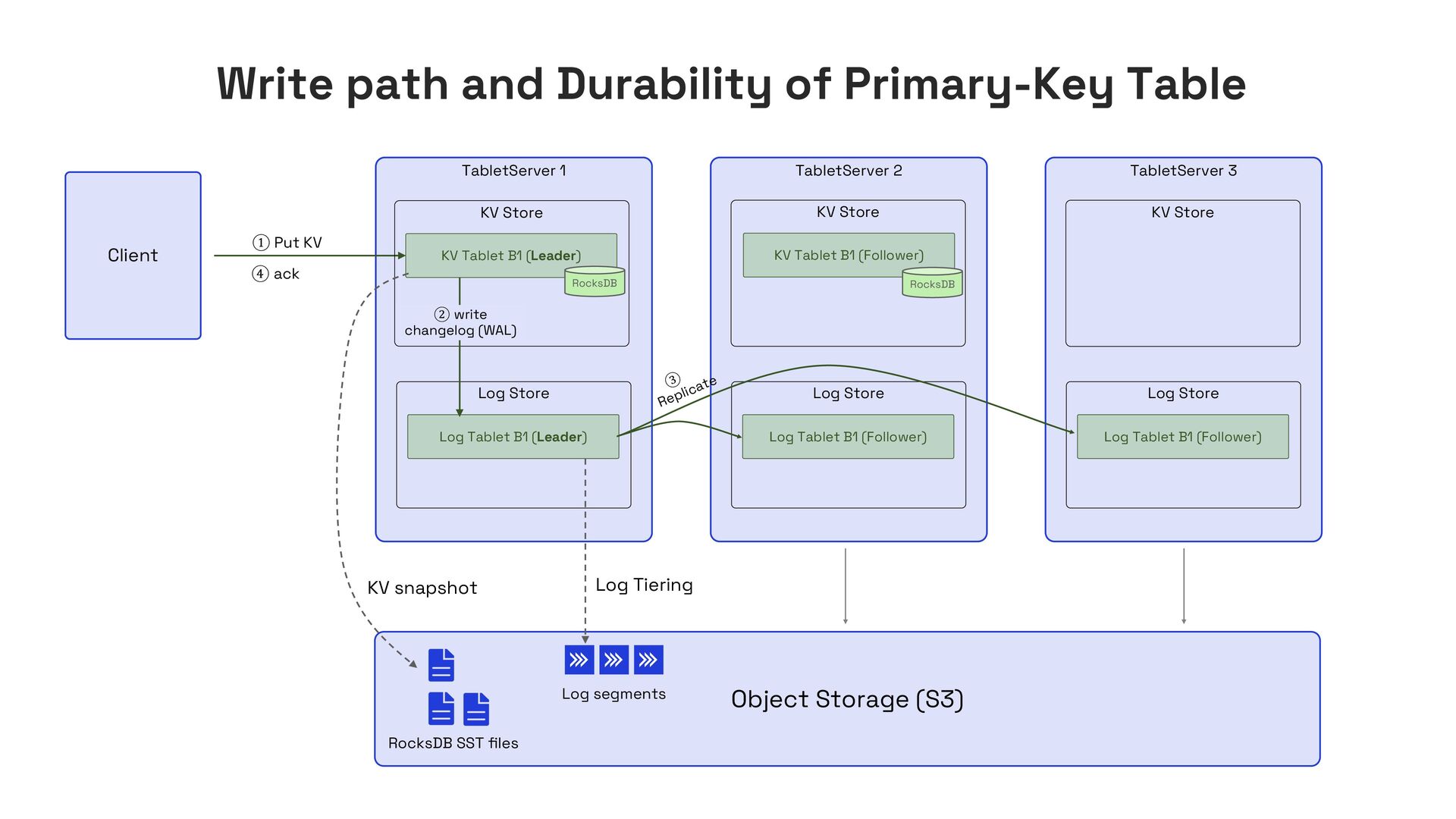
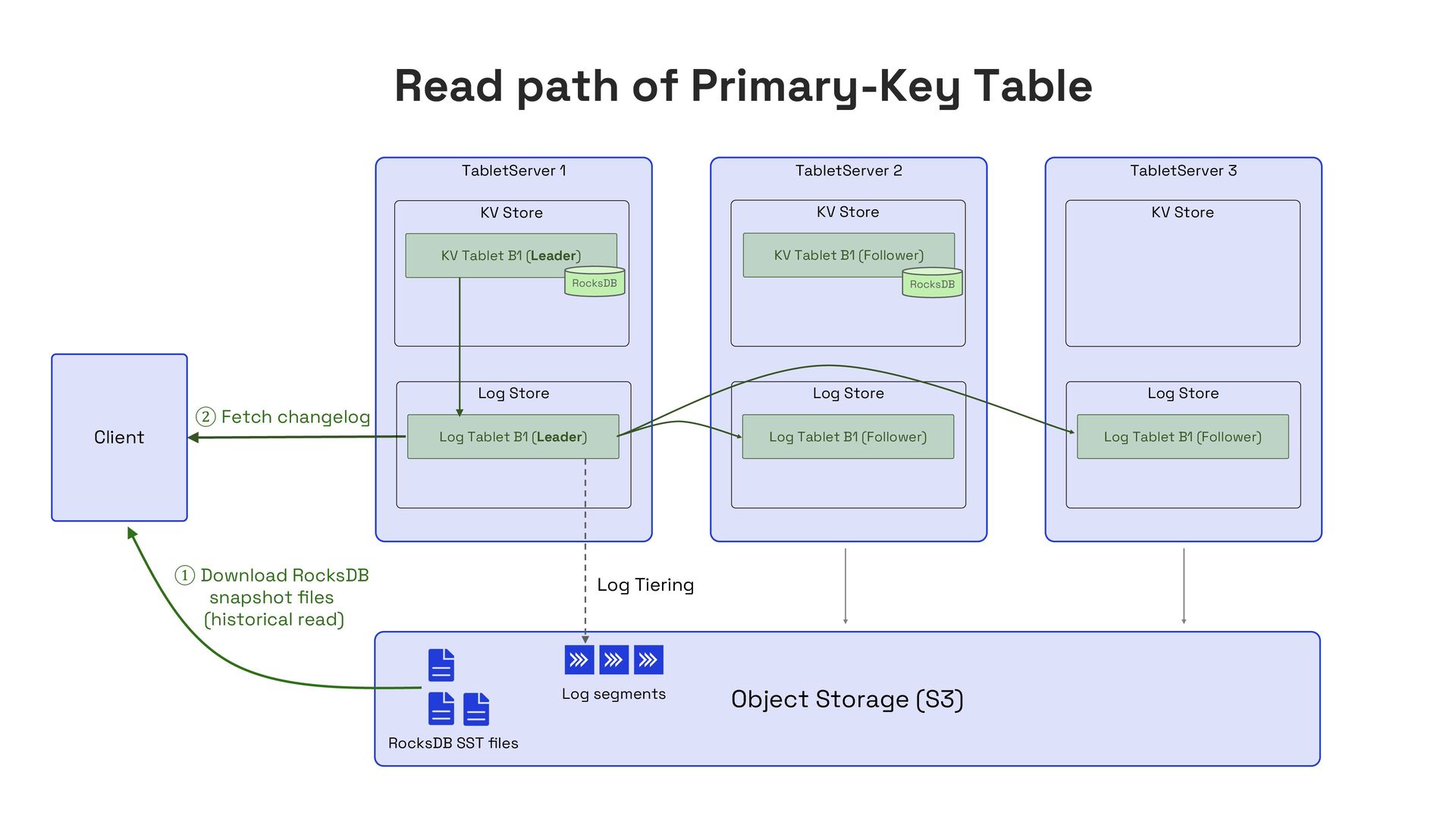
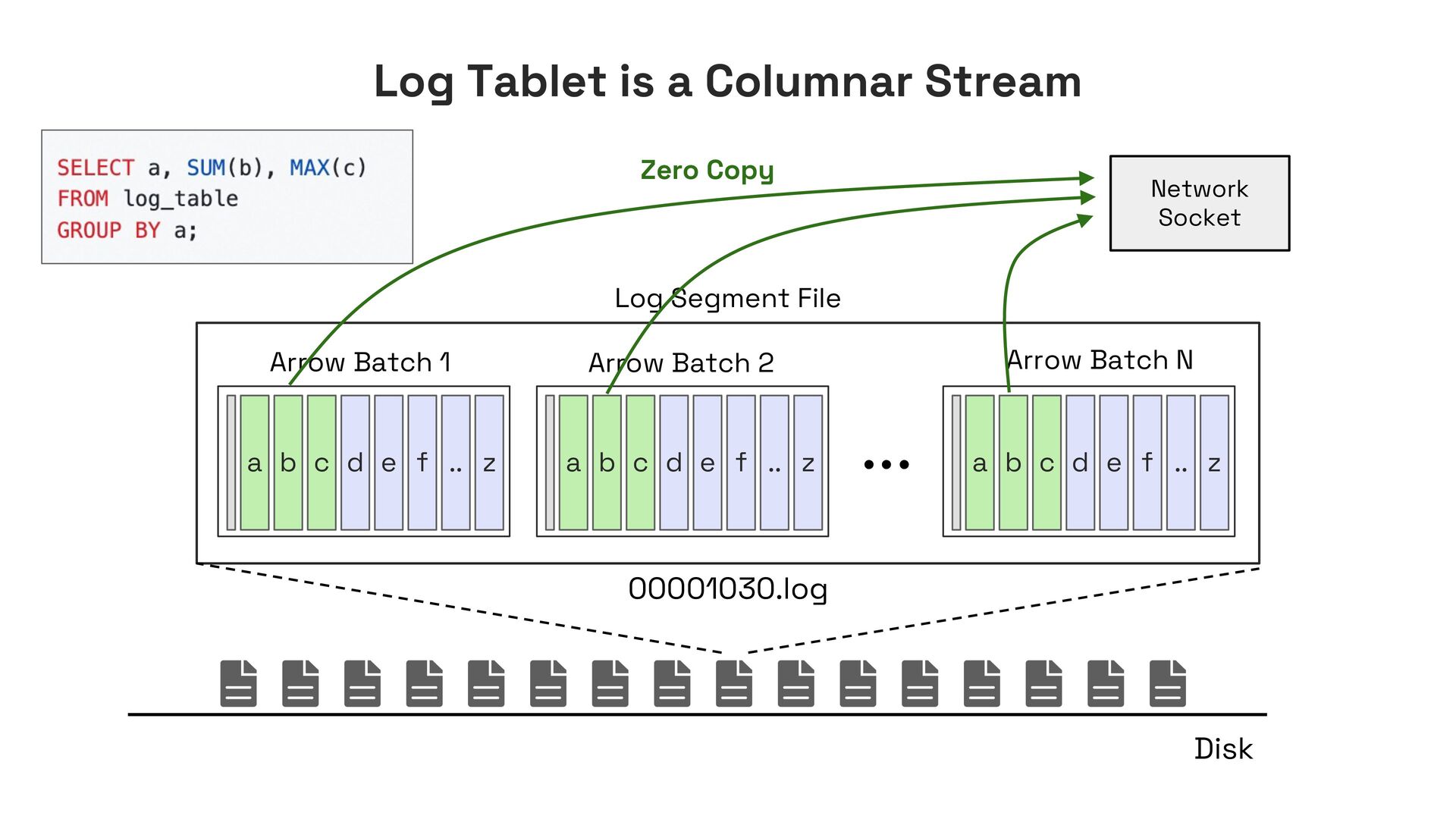
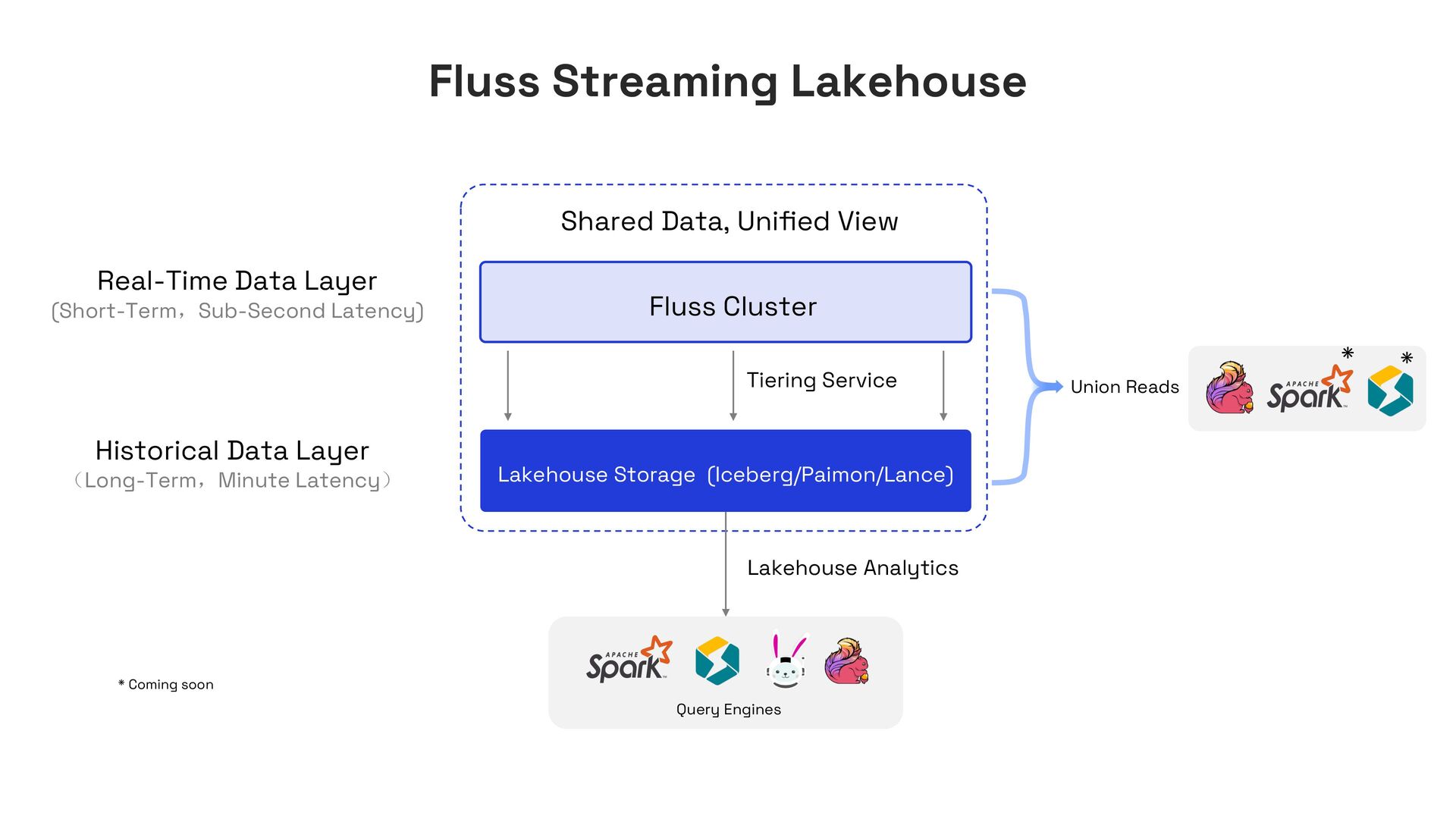
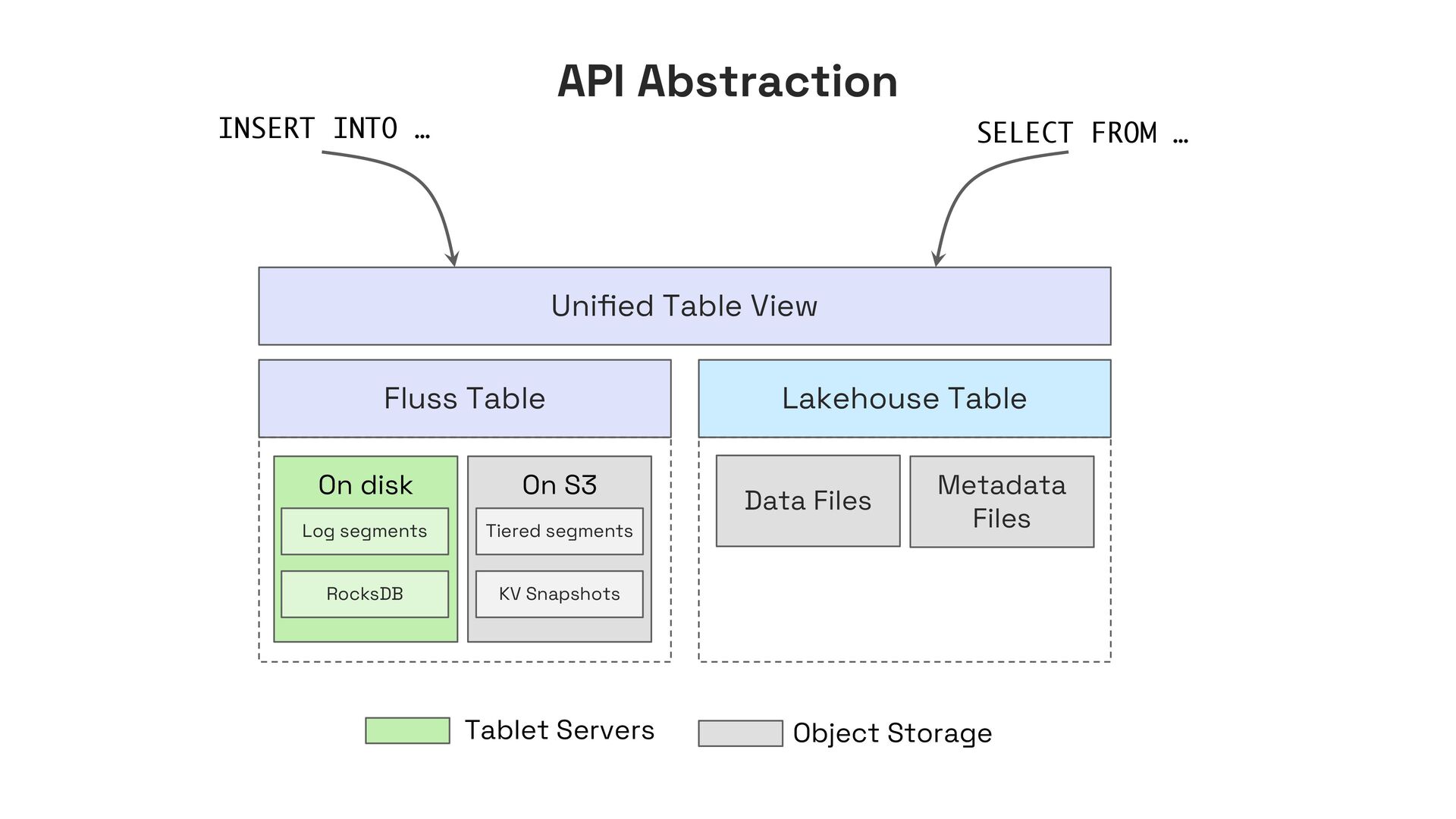
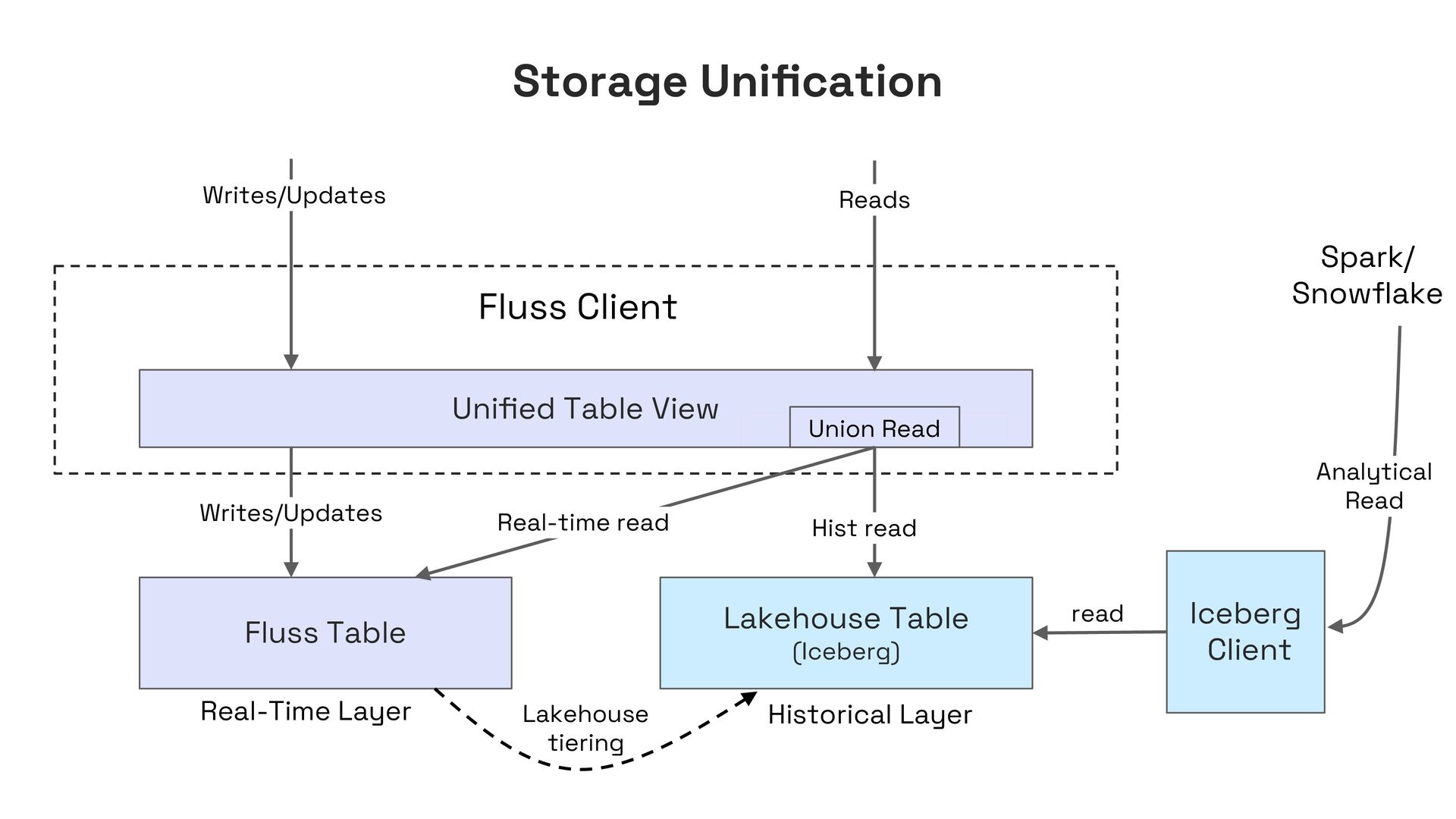
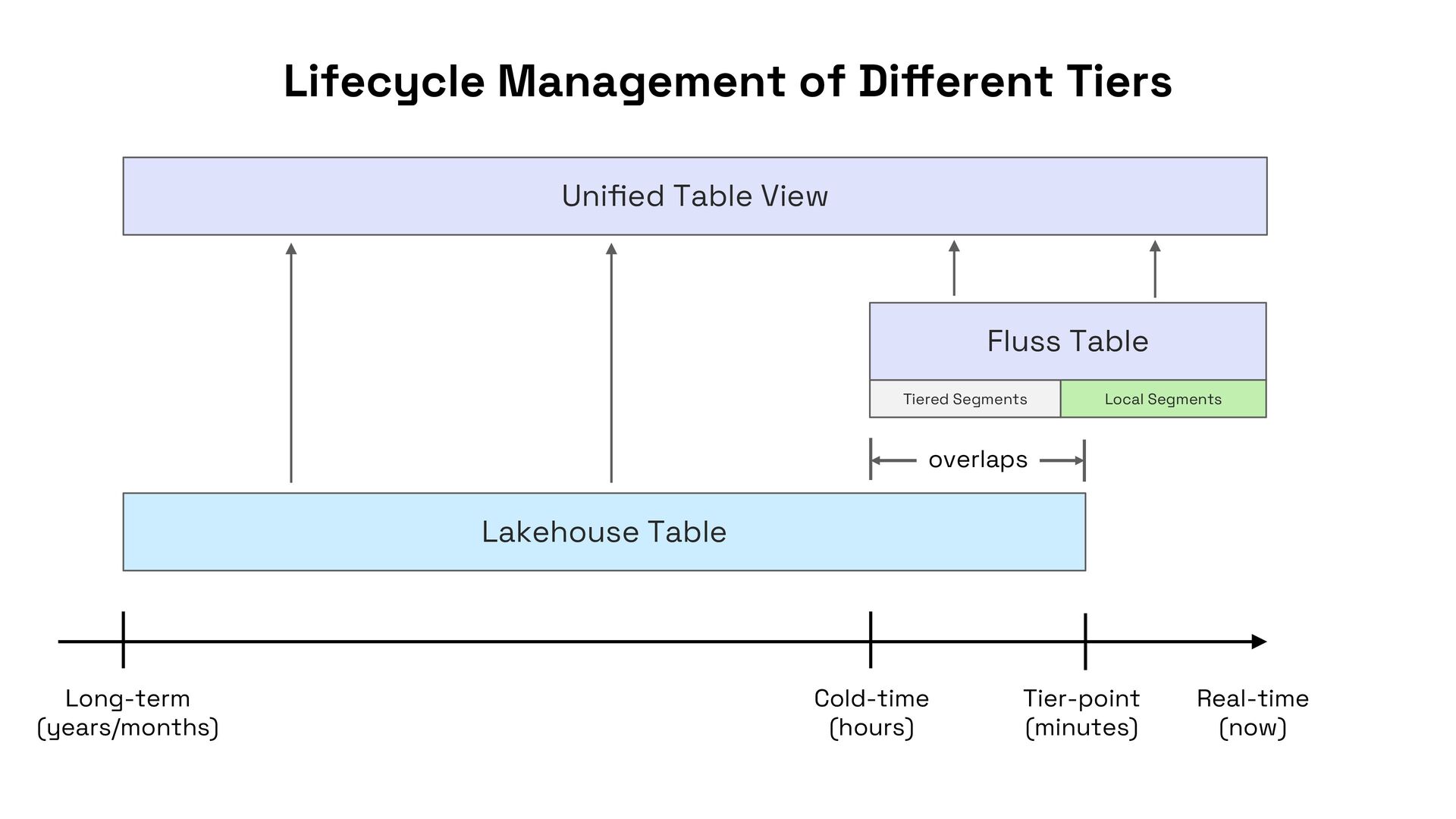
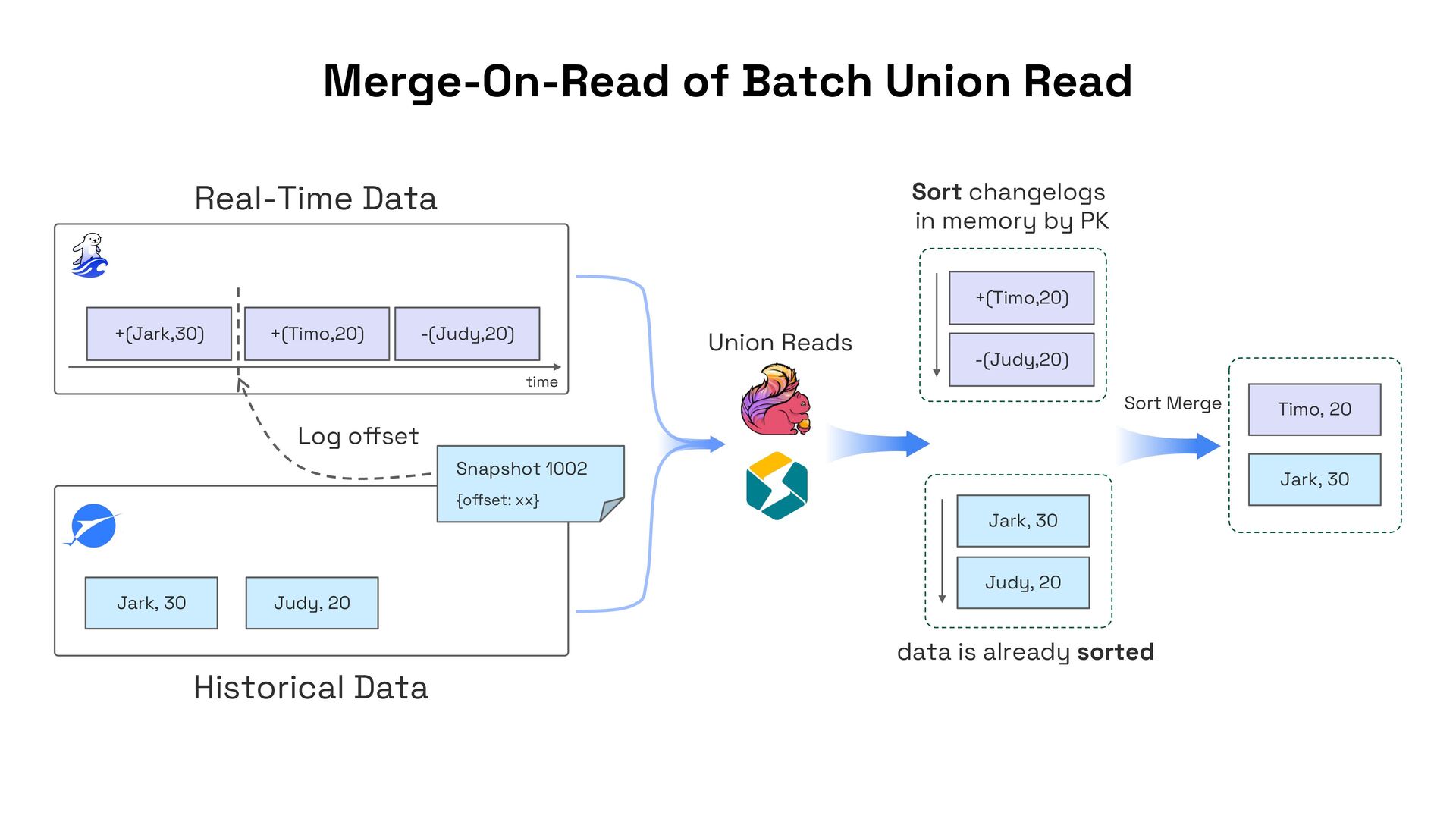
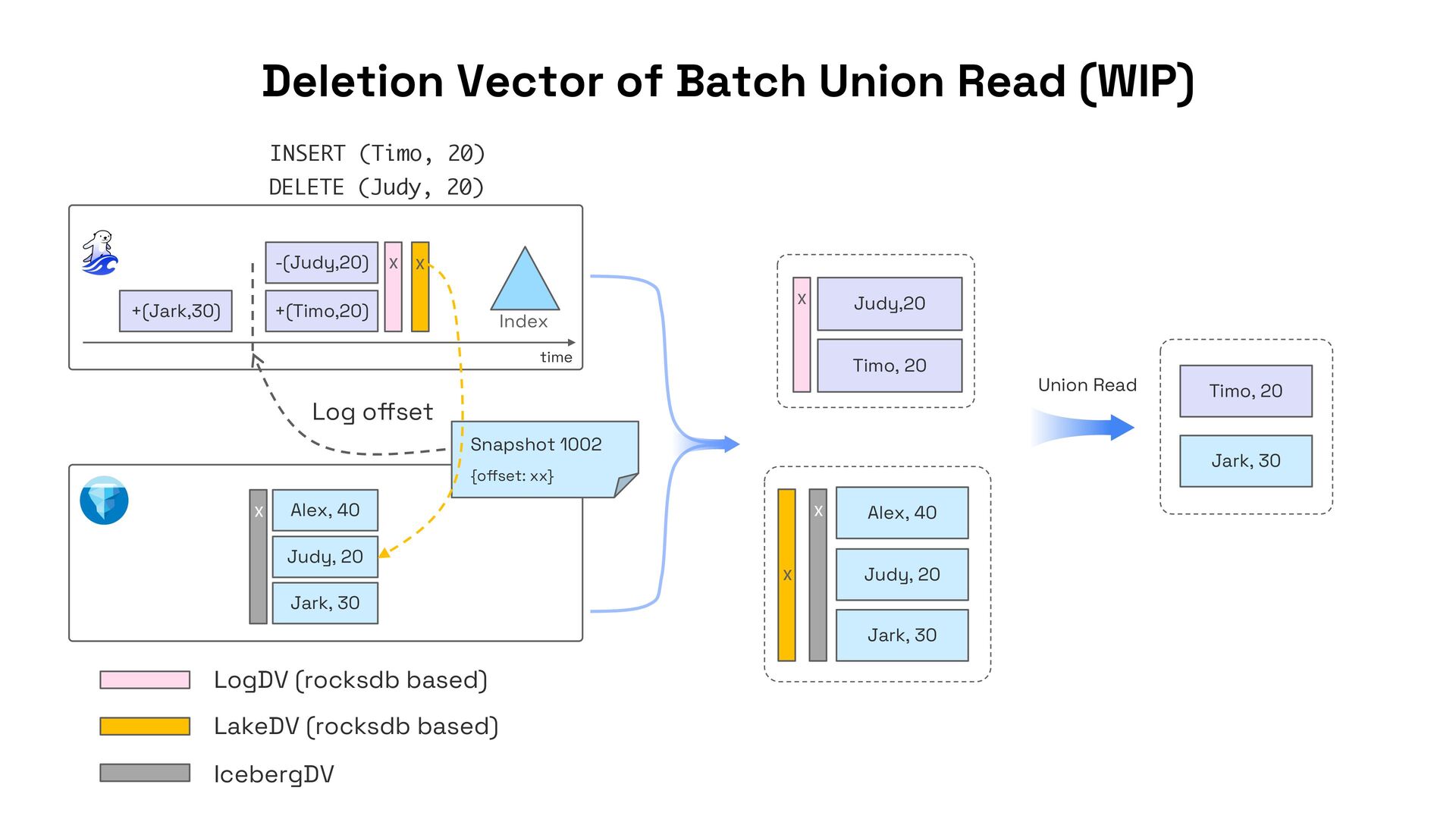
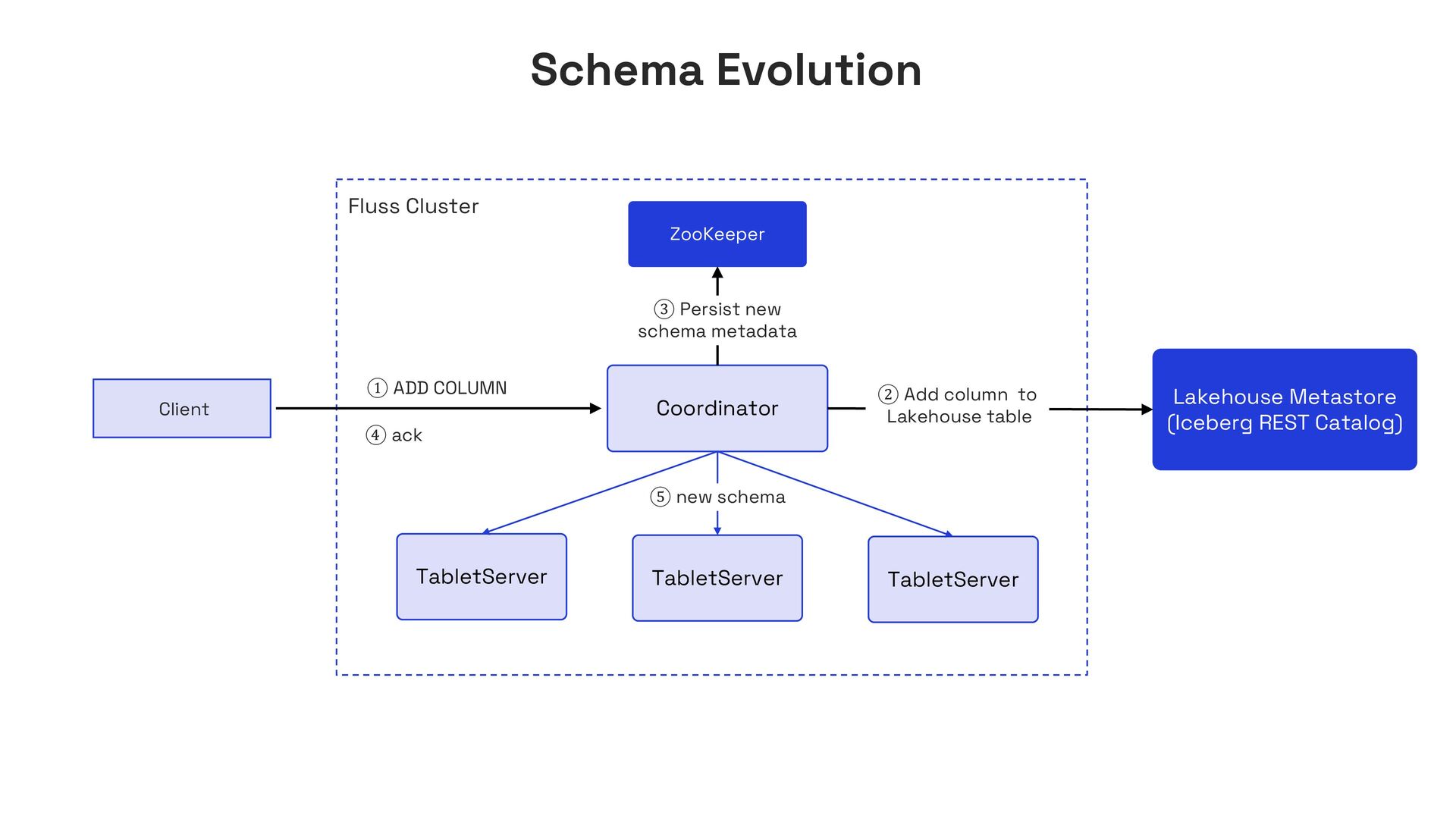
In this talk, I’ll present Apache Fluss (incubating), a lakehouse-native streaming storage system designed to bridge this gap. Fluss rethinks streaming storage from the ground up for analytical workloads. Its core abstraction is a columnar stream built on Apache Arrow, enabling sub-second ingestion and high-throughput analytical scans. Furthermore, Fluss introduces the "Streaming Lakehouse" concept that Fluss serves as the real-time data layer on top of Lakehouse. It allows query engines to seamlessly unify both fresh streaming data in Fluss and historical data in Lakehouse (Iceberg) to achieve truly real-time data analytics.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}