Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SNLP2020_mixtext
Search
Sho Takase
September 16, 2020
370
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SNLP2020_mixtext
Sho Takase
September 16, 2020
More Decks by Sho Takase
See All by Sho Takase
snlp2025_prevent_llm_spikes
takase
0
520
snlp2024_multiheadMoE
takase
0
730
snlp2023_beyond_neural_scaling_laws
takase
0
460
snlp2023_rogue_scores
takase
0
450
[SNLP2022] ABC: Attention with Bounded-memory Control
takase
0
450
SNLP2020_sandwich
takase
0
370
ニューラル言語モデルの 研究動向(NL研招待講演資料)
takase
12
5.3k
Featured
See All Featured
My Coaching Mixtape
mlcsv
0
180
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Accessibility Awareness
sabderemane
1
160
Utilizing Notion as your number one productivity tool
mfonobong
4
460
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
New Earth Scene 8
popppiees
3
2.4k
The Curse of the Amulet
leimatthew05
2
13k
Transcript
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
Jiaao Chen, Zichao Yang, Diyi Yang ACL 2020 発表者︓⾼瀬 翔(東京⼯業⼤学) 2020/9/25 1 結果やモデルの図・表は論⽂より引⽤
概要 • Mixup [Zhang+ 17] を⾔語に拡張(TMix) – Mixup: 画像処理でのデータ拡張⼿法,⼊⼒と出⼒ラベルを混ぜ,新規 の訓練事例とする
• Self-training でラベルなしデータにラベルを付与し学習データ増量 – Self-training と TMix をあわせたものが MixText • ⽂書分類で効果を確認 – ベースラインよりも性能は⾼い – 既存のデータ拡張よりも良いかは謎に思える – TMix の貢献が⼤きいかどうかも怪しい気が… • 論⽂内の主張がたまに⼤きすぎる気が… – 任意の⼿法に使⽤可能(ただし実験は⽂書分類のみ) – 無限に訓練データを増やせる 2 0.3 × + 0.7 × = 0.3 × リス + 0.7 × レッサーパンダ
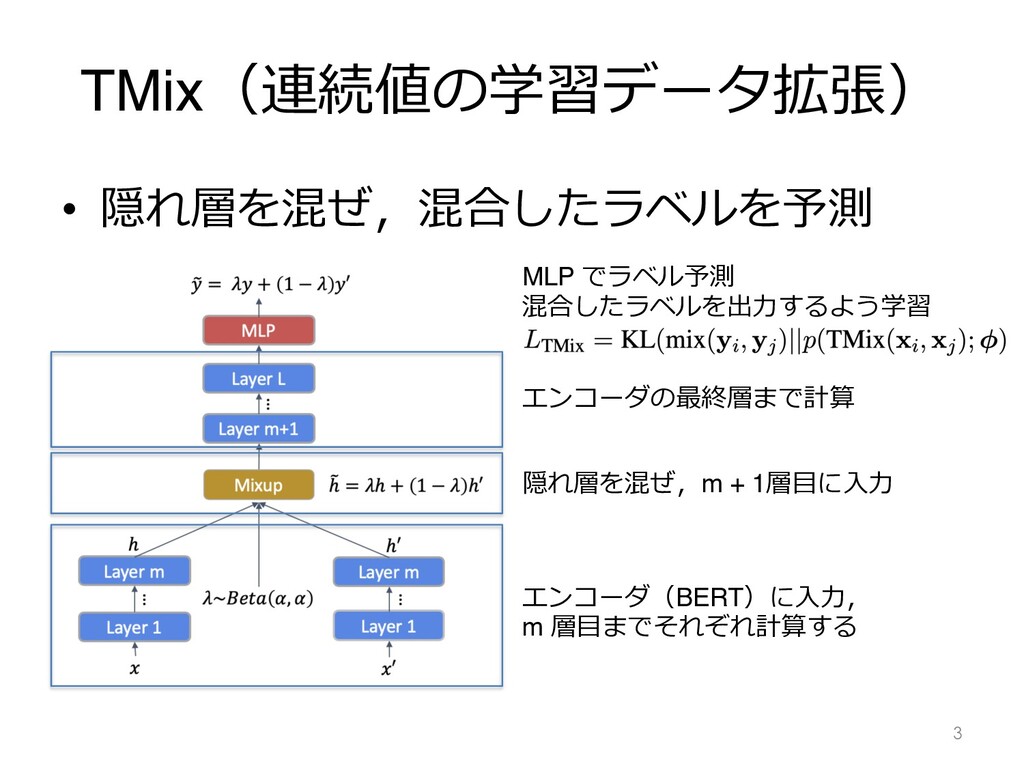
TMix(連続値の学習データ拡張) • 隠れ層を混ぜ,混合したラベルを予測 3 エンコーダ(BERT)に⼊⼒, m 層⽬までそれぞれ計算する 隠れ層を混ぜ,m + 1層⽬に⼊⼒
エンコーダの最終層まで計算 MLP でラベル予測 混合したラベルを出⼒するよう学習
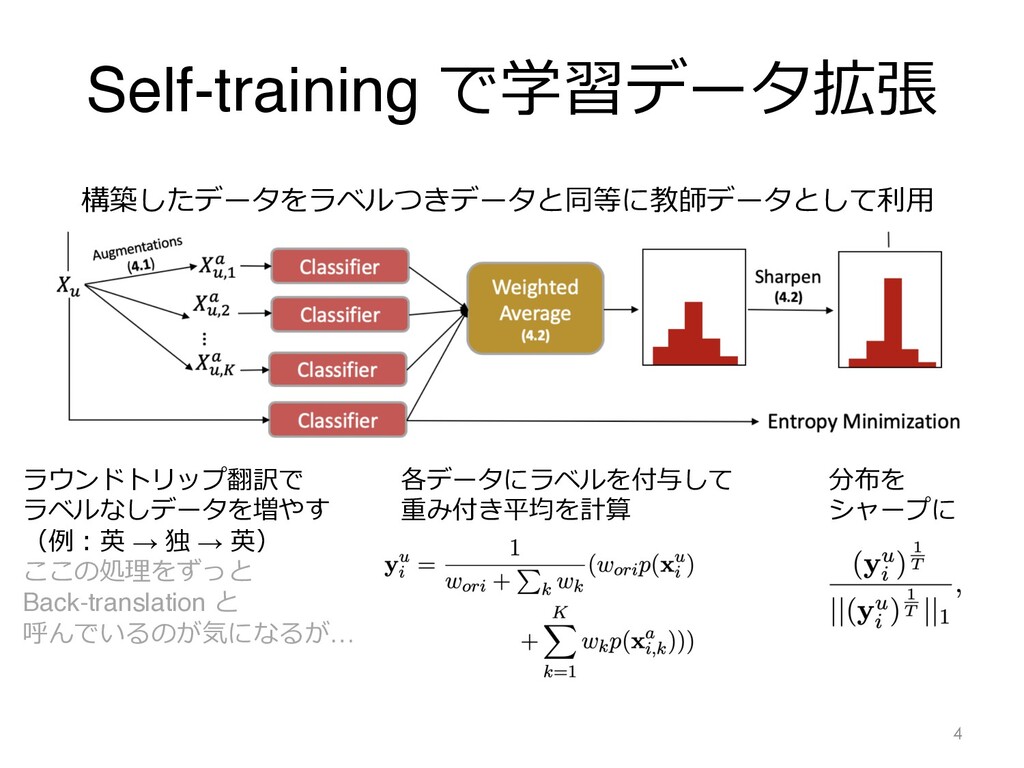
Self-training で学習データ拡張 4 ラウンドトリップ翻訳で ラベルなしデータを増やす (例︓英 → 独 → 英)
ここの処理をずっと Back-translation と 呼んでいるのが気になるが… 各データにラベルを付与して 重み付き平均を計算 分布を シャープに 構築したデータをラベルつきデータと同等に教師データとして利⽤
実験設定 • ⽂書分類の4つのデータで実験 • BERT-base をベースに実装 • ⽐較⼿法 – BERT︓データ拡張なしの
fine-tuning – UDA︓BERT base + 教師なしデータ拡張 [Xie+ 19] でデータ拡張 5
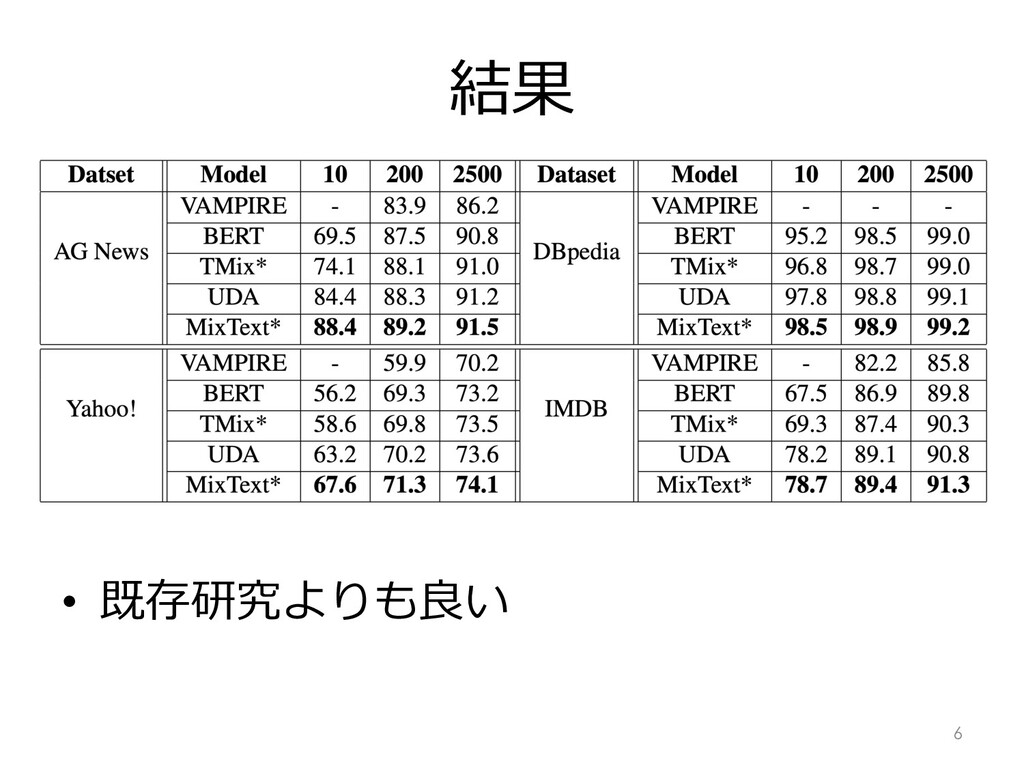
結果 • 既存研究よりも良い 6
Ablation study • 要素を抜いていったときの正解率の変化 7 ラベルなしデータを 抜いたときの性能低下が⼤きい TMix を⼊れた状態で ラベルなしデータを抜いた
結果が⾒たいが……
まとめ • Mixup [Zhang+ 17] を⾔語に拡張(TMix) – エンコーダの隠れ層を混合 – ラベルを混合し,教師データとして利⽤
• Self-training でラベルなしデータにラベルを 付与,学習データ増量 – ラウンドトリップ翻訳でラベルなし⼊⼒を増量 – ラベルなしデータにモデルの予測を付与 • ⽂書分類で効果を確認 – ベースラインよりも性能は⾼い – 既存のデータ拡張よりも良いかは謎に思える 8
{kind=link}
![概要 • Mixup [Zhang+ 17] を⾔語に拡張(TMix) – Mixup: 画像処理でのデータ拡張⼿法,⼊⼒と出⼒ラベルを混ぜ,新規 の訓練事例とする](https://files.speakerdeck.com/presentations/00a75ed1c77e4cf392a689071d98d733/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![まとめ • Mixup [Zhang+ 17] を⾔語に拡張(TMix) – エンコーダの隠れ層を混合 – ラベルを混合し,教師データとして利⽤](https://files.speakerdeck.com/presentations/00a75ed1c77e4cf392a689071d98d733/slide_7.jpg){kind=link}