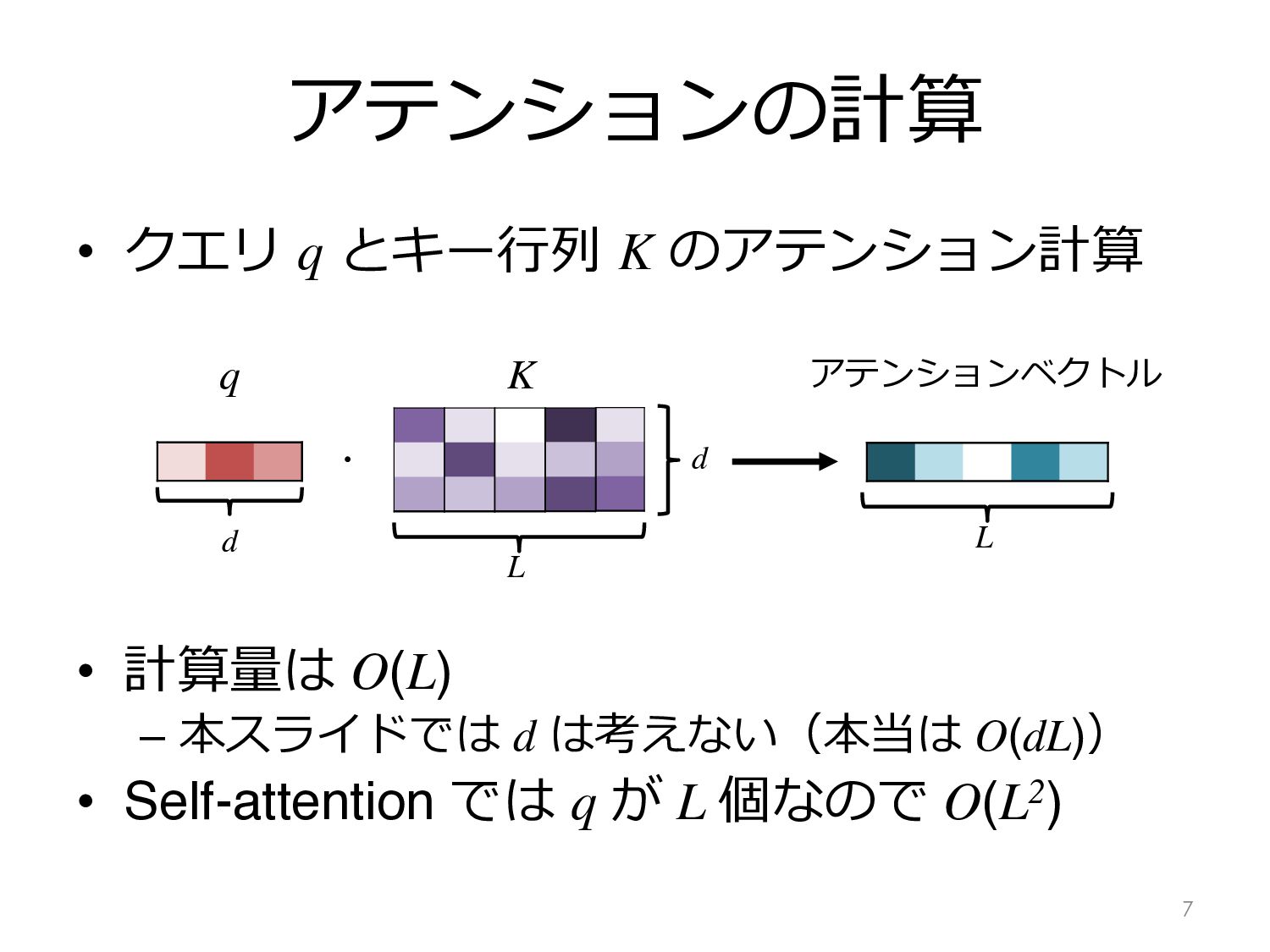
φi を i 番⽬の要素のみ 1 の one-hot ベクトルとすると K = ∑ φi ki T – 外積は例えば i = 4 のとき – よって i を 1 から L について計算した和を取ると K 8 [ 0 0 0 1 0 ] L φ4 k4 転地をとる d L d K において k4 に該当する 要素以外はゼロの⾏列
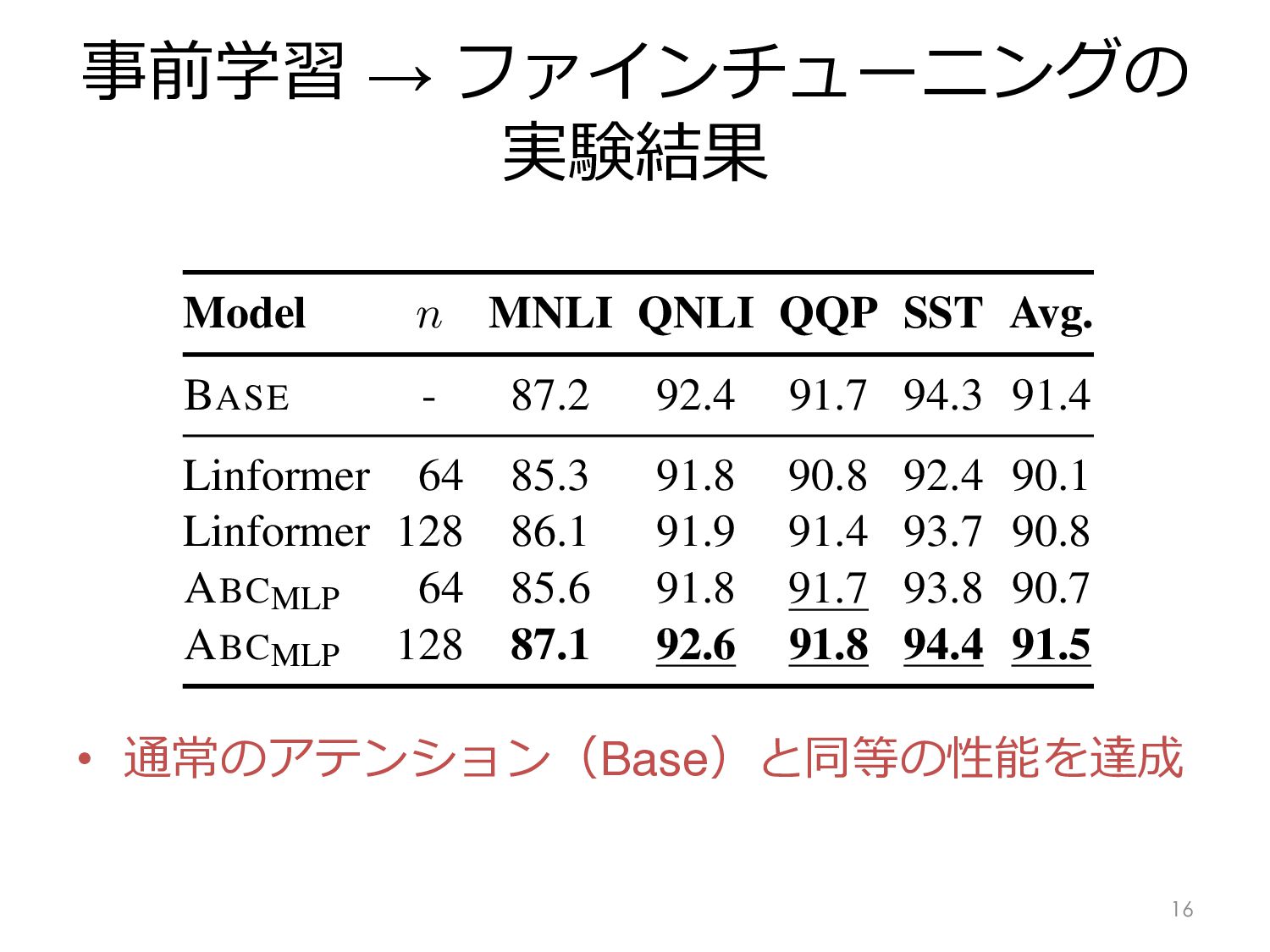
⼊⼒⾮依存の学習パラメータ︓Linformer • φi を⼊⼒に依存したベクトルにする – ⼊⼒に依存させた⽅が性能上がりそうなので – ⼊⼒を xi としたとき • この⼿法を ABCMLP と呼ぶ 13 and Table 2 details their complexity. 4 Learned Memory Control The ABC abstraction connects several existing ap- proaches that would otherwise seem distinct. This inspires the design of new architectures. We hy- pothesize that learning a contextualized strategy can achieve better performance. This section intro- duces ABCMLP. It parameterizes with a single- layer multi-layer perceptron (MLP) that takes as input the token’s representation xi, and determines which slots to write it into and how much. ↵i = exp (W xi) , i = ↵i , N X j=1 ↵j. (7) Matrix W is learned. exp is an elementwise activation function. The motivation is to allow for storing a “fractional” (but never negative) amount of input into the memory.4 Using a non-negative is small: inspire -MLP’s parame adds less than 1% ABCMLP: co dependent atten and show that two attention m context-agnostic with a context-de with a one-dime generalizes to hi Example 1. Con ory slot (n = 1). vector w , and xj). Since i is e K> = N X i=1 N X L デコーダで使う場合は ⼊⼒の地点 i まで
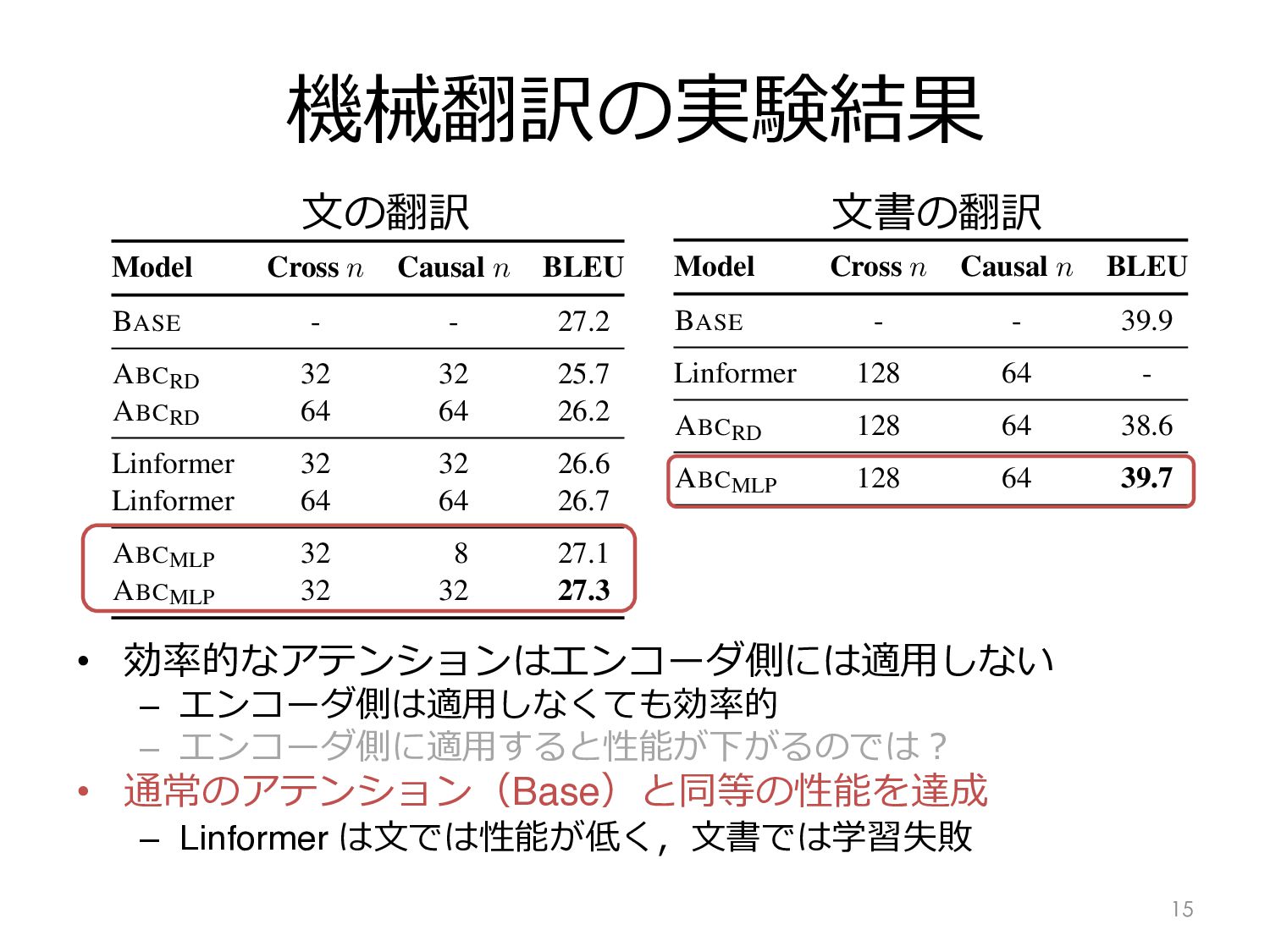
Linformer は⽂では性能が低く,⽂書では学習失敗 15 Model Cross n Causal n BLEU BASE - - 27.2 ABCRD 32 32 25.7 ABCRD 64 64 26.2 Linformer 32 32 26.6 Linformer 64 64 26.7 ABCMLP 32 8 27.1 ABCMLP 32 32 27.3 (a) Bolded number outperforms BASE. Model Cross n Causal n BLEU BASE - - 39.9 Linformer 128 64 - ABCRD 128 64 38.6 ABCMLP 128 64 39.7 Results. Table 4a summarizes sentence-level chine translation results on the WMT14 EN-DE set. Overall ABCMLP performs on par with BA with either 32-32 cross-causal memory sizes or 8. Even with smaller memory sizes, it outperfo other ABC variants by more than 1.1 BLEU. ferently from the trend in the language model experiment (§5.1), Linformer outperforms ABC by more than 0.5 BLEU. We attribute this to smaller sequence lengths of this dataset. ABC outperforms other ABC models by more than BLEU, even with smaller memory sizes. The trend is similar on document-level tr lation with IWSLT14 ES-EN (Table 4b), exc that ABCMLP slightly underperforms BASE by BLEU. This suggests that even with longer quences, ABCMLP is effective despite its boun memory size. Linformer fails to converge e with multiple random seeds, suggesting the lim Linformer 32 32 26.6 Linformer 64 64 26.7 ABCMLP 32 8 27.1 ABCMLP 32 32 27.3 (a) Bolded number outperforms BASE. Model Cross n Causal n BLEU BASE - - 39.9 Linformer 128 64 - ABCRD 128 64 38.6 ABCMLP 128 64 39.7 (b) Linformer fails to converge even with multiple random seeds. Bold number performs the best among ABC models. Table 4: Machine translation test SacreBLEU. Left: sentence-level translation with WMT14 EN-DE; right: document-level translation with IWSLT14 ES-EN. (Bojar et al., 2014). The preprocessing and data splits follow Vaswani et al. (2017). • Document-level translation with IWSLT14 ES- EN (Cettolo et al., 2014). We use Miculicich ⽂の翻訳 ⽂書の翻訳
Linformer ABCMLP n - 64 128 64 128 Speed 1.0⇥ 1.7⇥ 1.5⇥ 1.5⇥ 1.3⇥ Memory 1.0⇥ 0.5⇥ 0.6⇥ 0.5⇥ 0.6⇥ Table 6: Text encoding inference speed (higher is better) and memory (lower is better). Inputs are text segments with 512 tokens and batch size 16. Cross n 8 16 32 64 baselin improve Ackno We wou versity and the ful com by NSF Nikolao tional S 512トークンをエンコード・推論したときのコスト
language model • Mikolov+ 13: Distributed Representations of Words and Phrases and their Compositionality • Zaremba+ 14: Recurrent Neural Network Regularization • Bahdanau+ 14: Neural Machine Translation by Jointly Learning to Align and Translate • Vaswani+ 14: Attention Is All You Need • Tolstikhin+ 21: MLP-Mixer: An all-MLP Architecture for Vision • Gehring+ 17: Convolutional Sequence to Sequence Learning • Tay+ 21: Are Pre-trained Convolutions Better than Pre-trained Transformers? • Sun+ 21: Revisiting Simple Neural Probabilistic Language Models • Loem+ 22: Are Neighbors Enough? Multi-Head Neural n-gram can be Alternative to Self- attention • Roy+ 21: Efficient Content-Based Sparse Attention with Routing Transformers • Child+ 19: Generating Long Sequences with Sparse Transformers • Kitaev+ 20: Reformer: The Efficient Transformer • Wang+ 20: Linformer: Self-Attention with Linear Complexity 20
{kind=link}
{kind=link}
![⾃然⾔語処理における ニューラルモデルの代表的な研究 3 2014 2010 RNN⾔語モデル [Mikolov+ 10] LSTM⾔語モデル [Zaremba+](https://files.speakerdeck.com/presentations/4a42a09cc9d9444eb027ee04fdedc8e0/slide_2.jpg){kind=link}
![次代のモデルの探求 • Self-attetnion の代替 – MLP系(MLP-Mixer)[Tolstikhin+ 21] – CNN [Gehring+](https://files.speakerdeck.com/presentations/4a42a09cc9d9444eb027ee04fdedc8e0/slide_3.jpg){kind=link}
![次代のモデルの探求 • Self-attetnion の代替 – MLP系(MLP-Mixer)[Tolstikhin+ 21] – CNN [Gehring+](https://files.speakerdeck.com/presentations/4a42a09cc9d9444eb027ee04fdedc8e0/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![[重要] キー⾏列 K を外積で表す • K は各位置のキーベクトル ki をまとめた⾏列 –](https://files.speakerdeck.com/presentations/4a42a09cc9d9444eb027ee04fdedc8e0/slide_7.jpg){kind=link}
![[重要] φ で K を制御できる • φ の次元数で K の⼤きさを制御可能](https://files.speakerdeck.com/presentations/4a42a09cc9d9444eb027ee04fdedc8e0/slide_8.jpg){kind=link}
![例1︓直近 n トークンのみにアテンション (e.g., strided attention [Child+ 19]) • 定義︓直近](https://files.speakerdeck.com/presentations/4a42a09cc9d9444eb027ee04fdedc8e0/slide_9.jpg){kind=link}
![例2︓アテンション⾏列を n × d にしておく (e.g., Linformer [Wang+ 20]) •](https://files.speakerdeck.com/presentations/4a42a09cc9d9444eb027ee04fdedc8e0/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}