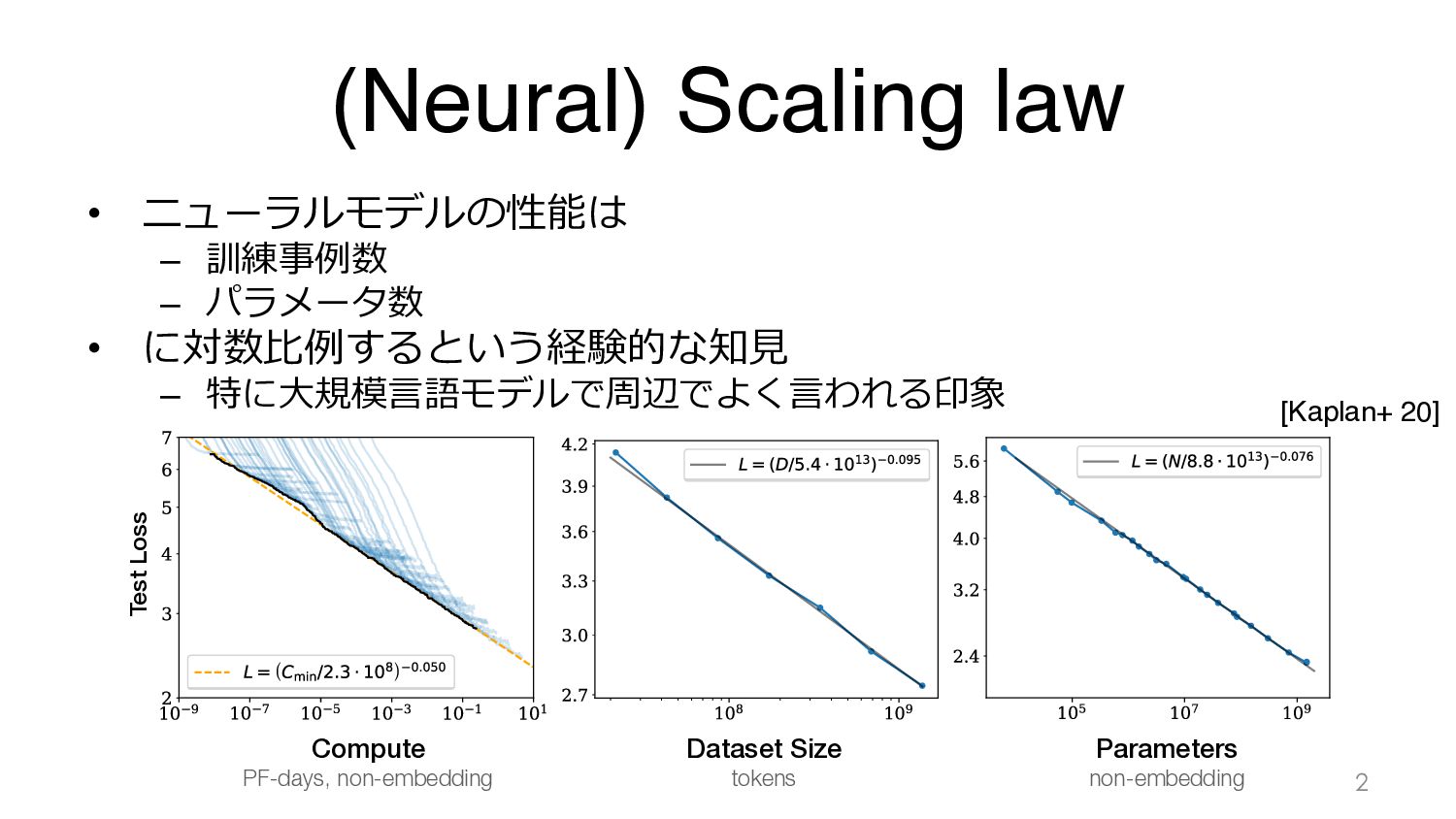
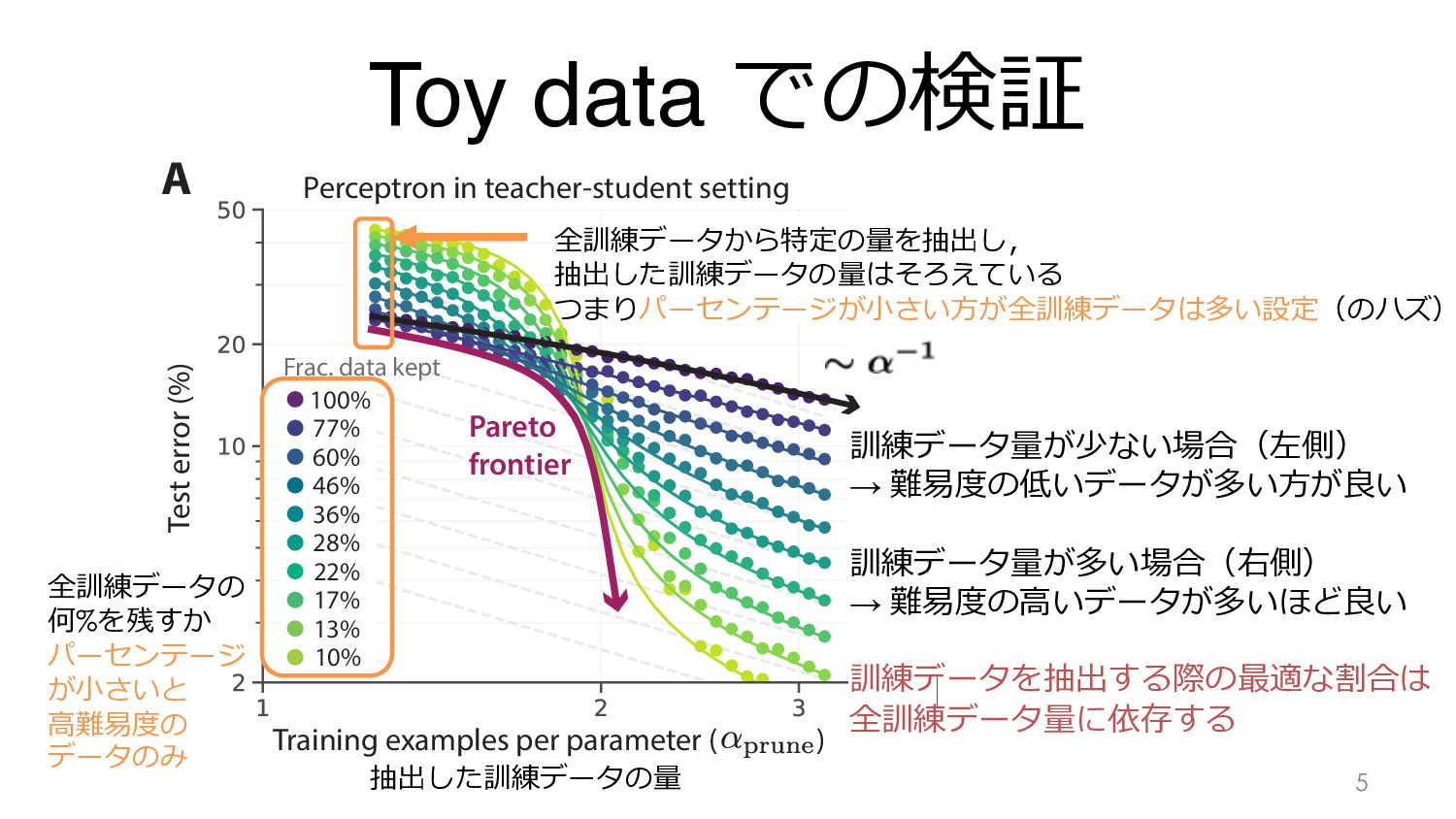
Simulation 100% Frac. data kept 77% 60% 46% 36% 28% 22% 17% 13% 10% Training examples per parameter ( ) Keep hard ResNet18 on CIFAR-10 D Keep easy examples Keep hard examples Perceptron in teacher-student setting Perceptron in teacher-student s B C A Frac. data kept t Total examples per parameter ( 抽出した訓練データの量 全訓練データの 何%を残すか パーセンテージ が⼩さいと ⾼難易度の データのみ 全訓練データから特定の量を抽出し, 抽出した訓練データの量はそろえている つまりパーセンテージが⼩さい⽅が全訓練データは多い設定(のハズ) 訓練データ量が少ない場合(左側) → 難易度の低いデータが多い⽅が良い 訓練データ量が多い場合(右側) → 難易度の⾼いデータが多いほど良い 訓練データを抽出する際の最適な割合は 全訓練データ量に依存する
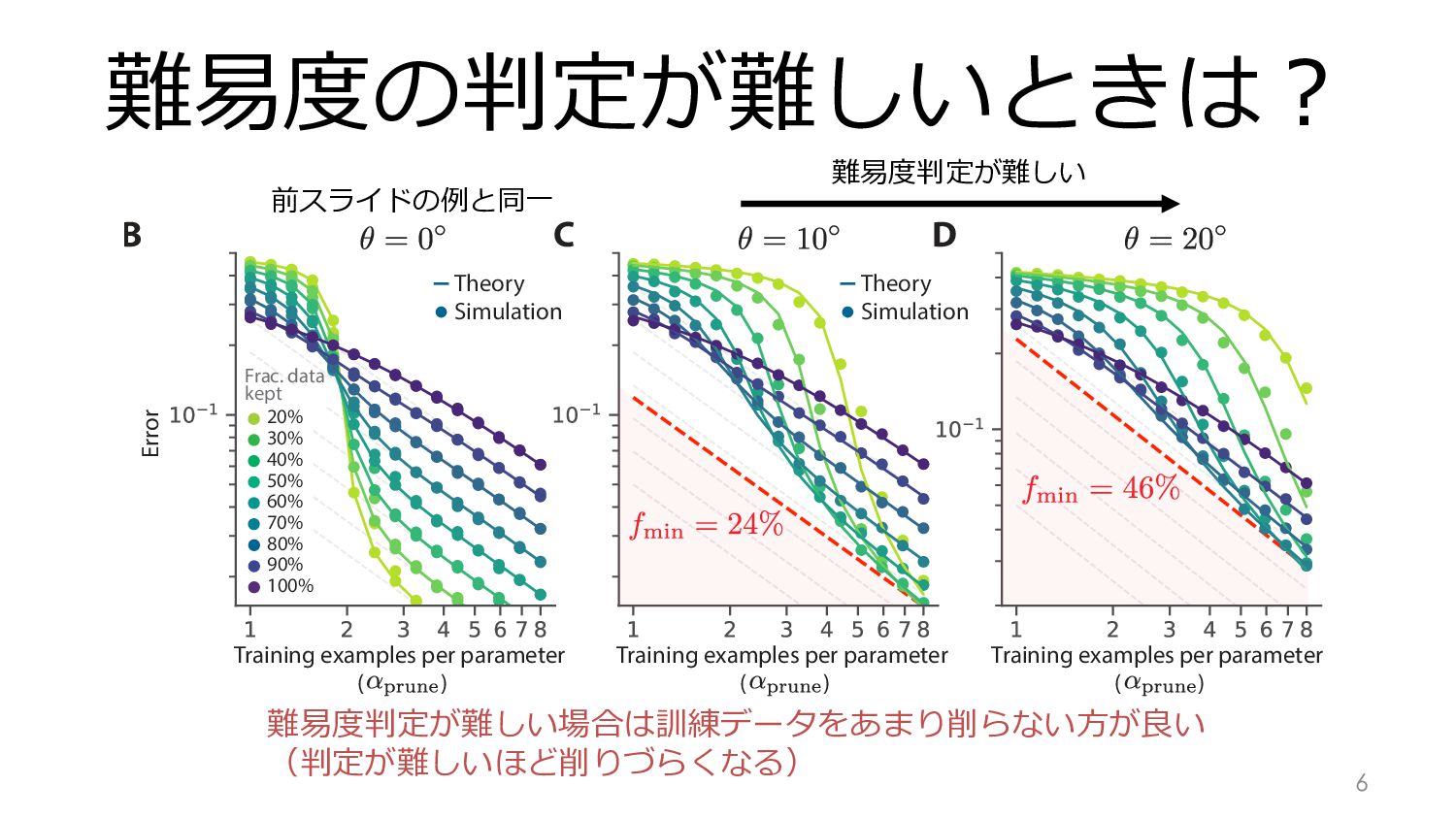
Simulation Theory Simulation 20% Frac. data kept 30% 40% 50% 60% 70% 80% 90% 100% Training examples per parameter ( ) Training examples per parameter ( ) Training examples per parameter ( ) Error ning with an imperfect metric. A: Weight vectors and decision boundaries for a
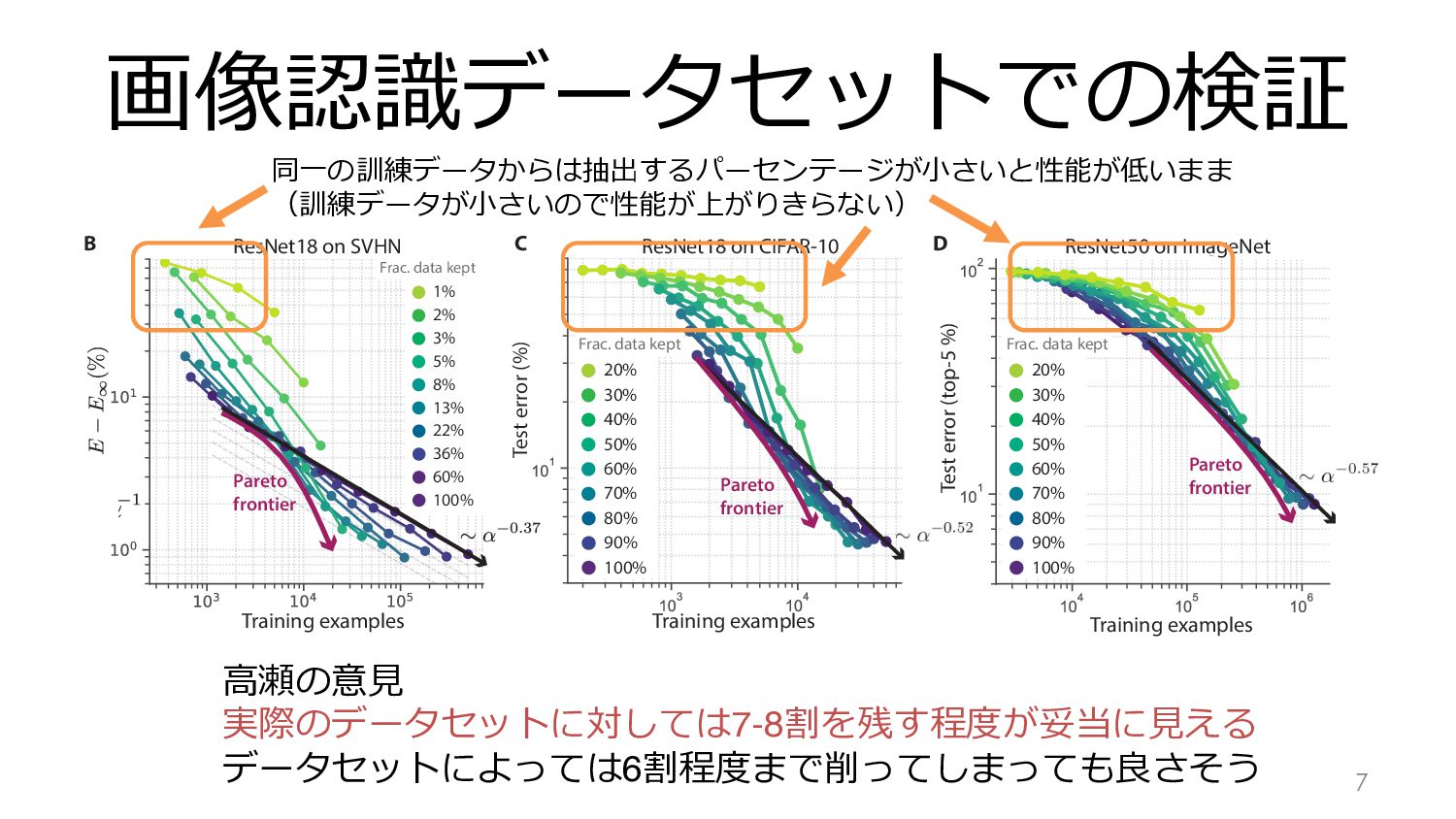
Pareto frontier Test error (top-5 %) Test error (%) setting B C D Pareto frontier ResNet18 on CIFAR-10 ResNet50 on ImageNet eory mulation 20% Frac. data kept 30% 40% 50% 60% 70% 80% 90% 100% 20% Frac. data kept 30% 40% 50% 60% 70% 80% 90% 100% 1% Frac. data kept 2% 3% 5% 8% 13% 22% 36% 60% 100% Training examples meter power law scaling in practice. A–D: Curves of test error against pruned dataset runing scores were EL2N [10] for CIFAR-10 and SVHN and memorization [13] App. B for all pruning/training details and App. D for similar ImageNet plots 7 同⼀の訓練データからは抽出するパーセンテージが⼩さいと性能が低いまま (訓練データが⼩さいので性能が上がりきらない) ⾼瀬の意⾒ 実際のデータセットに対しては7-8割を残す程度が妥当に⾒える データセットによっては6割程度まで削ってしまっても良さそう
CIFAR-10でチューニング 事前学習のデータ(ImageNet)を削る ImageNet を 7-8割程度まで削っても ・性能はあまり変化しない ・データの選択法によっては性能が上がる en larger datasets, scaling could improve further (e.g., dashed lines in A). E pruning (f = 1) are labeled with their best-fit power law scaling ⇠ ↵ ⌫. (N an asymptotic constant error E(P ! 1) = 1.1% is subtracted from each of he power law scaling more clearly.) B Frac. of ImageNet used for pretraining ResNet50 netuned on CIFAR-10 Test accuracy (%) 0.75 1.0 0.5 0.25 0 Figure 4: Data pruning improves trans learning. A: CIFAR-10 performance a ViT pre-trained on all of ImageNet2 and fine-tuned on different pruned subs of CIFAR-10 under the EL2N metric. CIFAR-10 performance of ResNet50s trained on different pruned subsets of I geNet1K and fine-tuned on all of CIFA 10.
Language Models Better [Lee+ 22] – ウェブデータには(部分的に)重複している⽂書が多い – 重複⽂書を除去することで • 学習効率が良くなる – 学習データ量に対して⾼い性能向上 • 性能が上がることもある s and C4 ex- g dataset con- nt to capture xt commonly Wiki-40B, we e text identi- nerated. The 9 重複削除を⾏って学習した場合 ⾔語モデルのPPLは ・性能に悪影響がない ・データによっては性能向上 近似重複削除 重複削除
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}