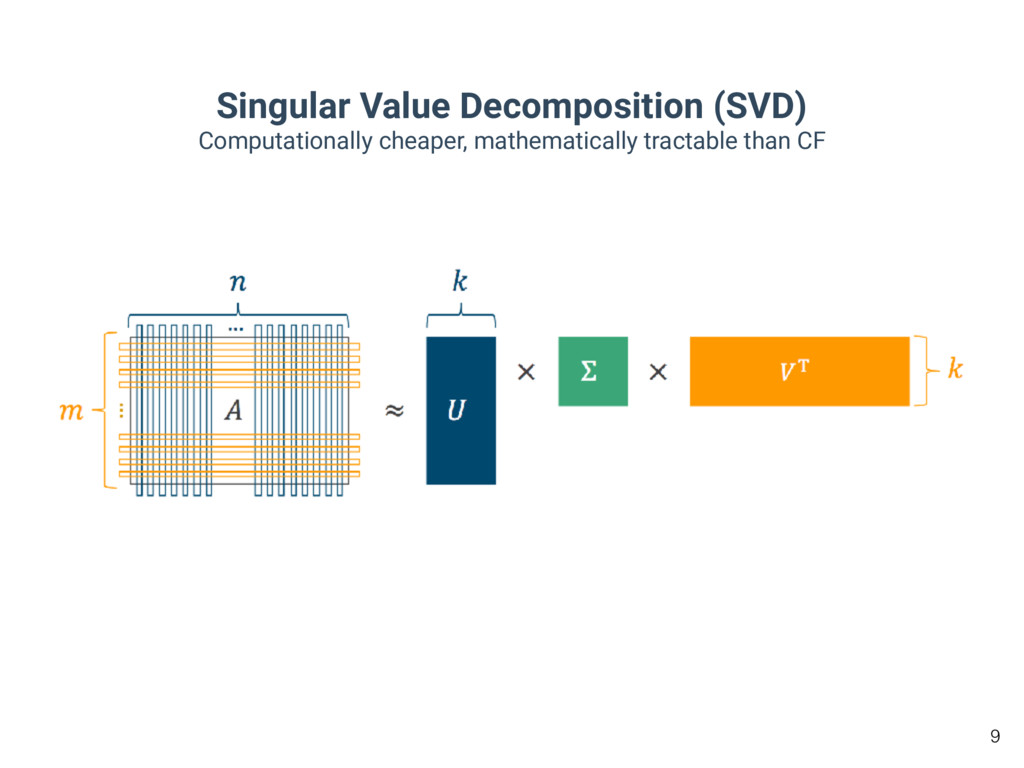
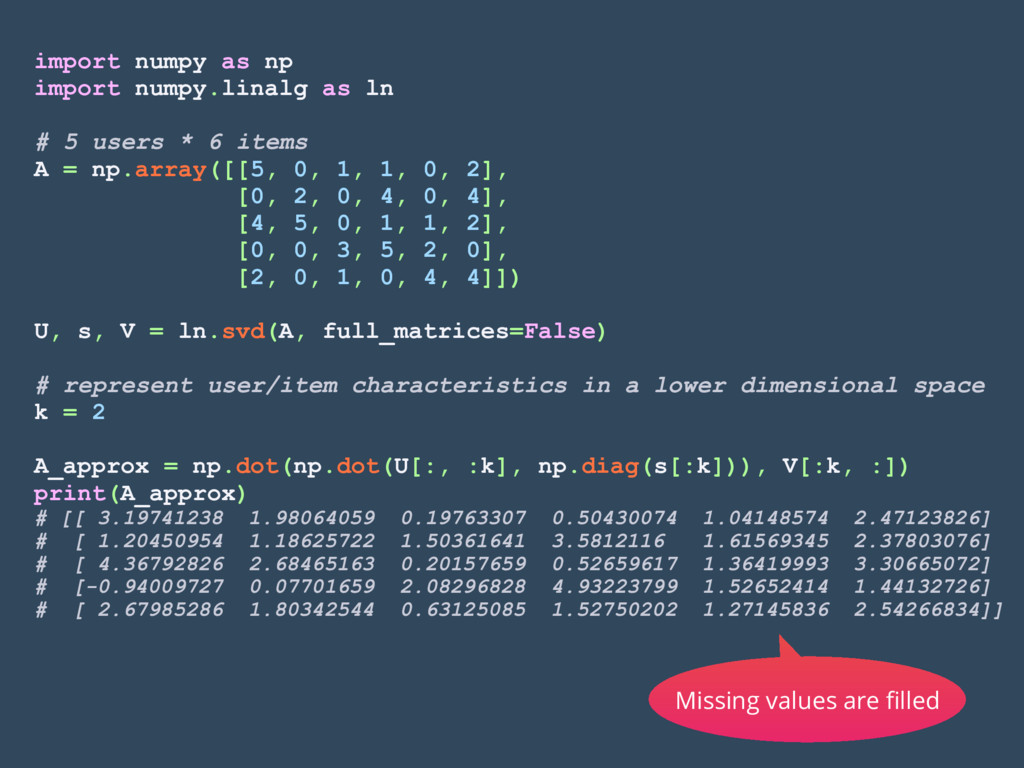
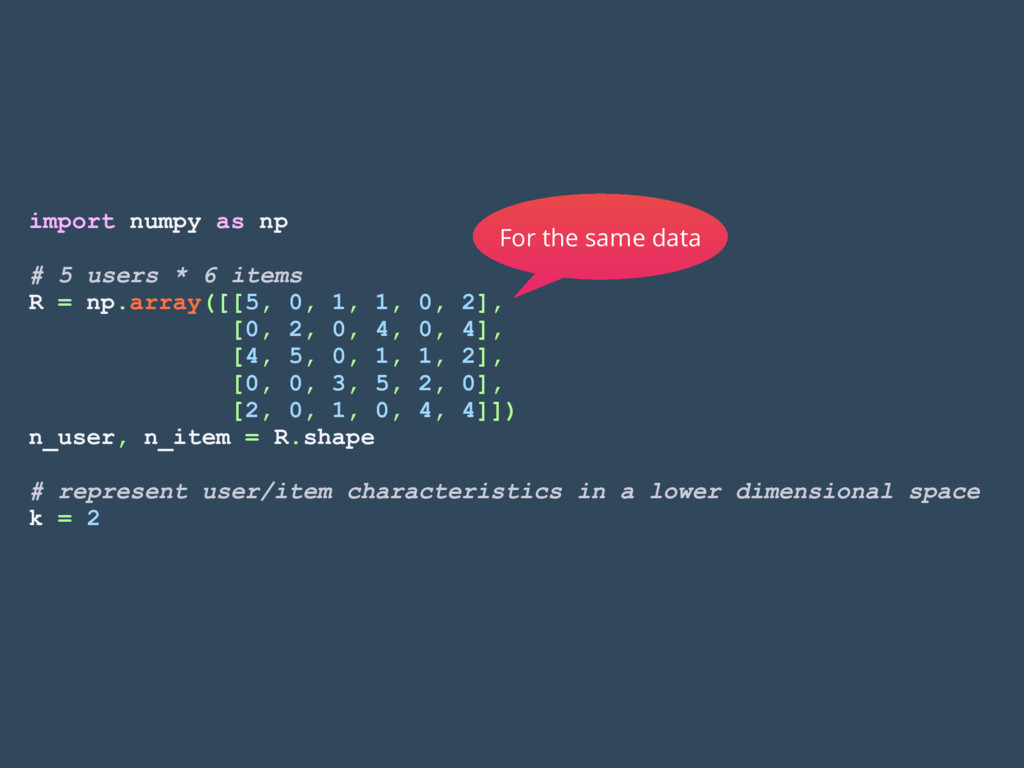
users * 6 items A = np.array([[5, 0, 1, 1, 0, 2], [0, 2, 0, 4, 0, 4], [4, 5, 0, 1, 1, 2], [0, 0, 3, 5, 2, 0], [2, 0, 1, 0, 4, 4]]) U, s, V = ln.svd(A, full_matrices=False) # represent user/item characteristics in a lower dimensional space k = 2 A_approx = np.dot(np.dot(U[:, :k], np.diag(s[:k])), V[:k, :]) print(A_approx) # [[ 3.19741238 1.98064059 0.19763307 0.50430074 1.04148574 2.47123826] # [ 1.20450954 1.18625722 1.50361641 3.5812116 1.61569345 2.37803076] # [ 4.36792826 2.68465163 0.20157659 0.52659617 1.36419993 3.30665072] # [-0.94009727 0.07701659 2.08296828 4.93223799 1.52652414 1.44132726] # [ 2.67985286 1.80342544 0.63125085 1.52750202 1.27145836 2.54266834]] Missing values are filled
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}