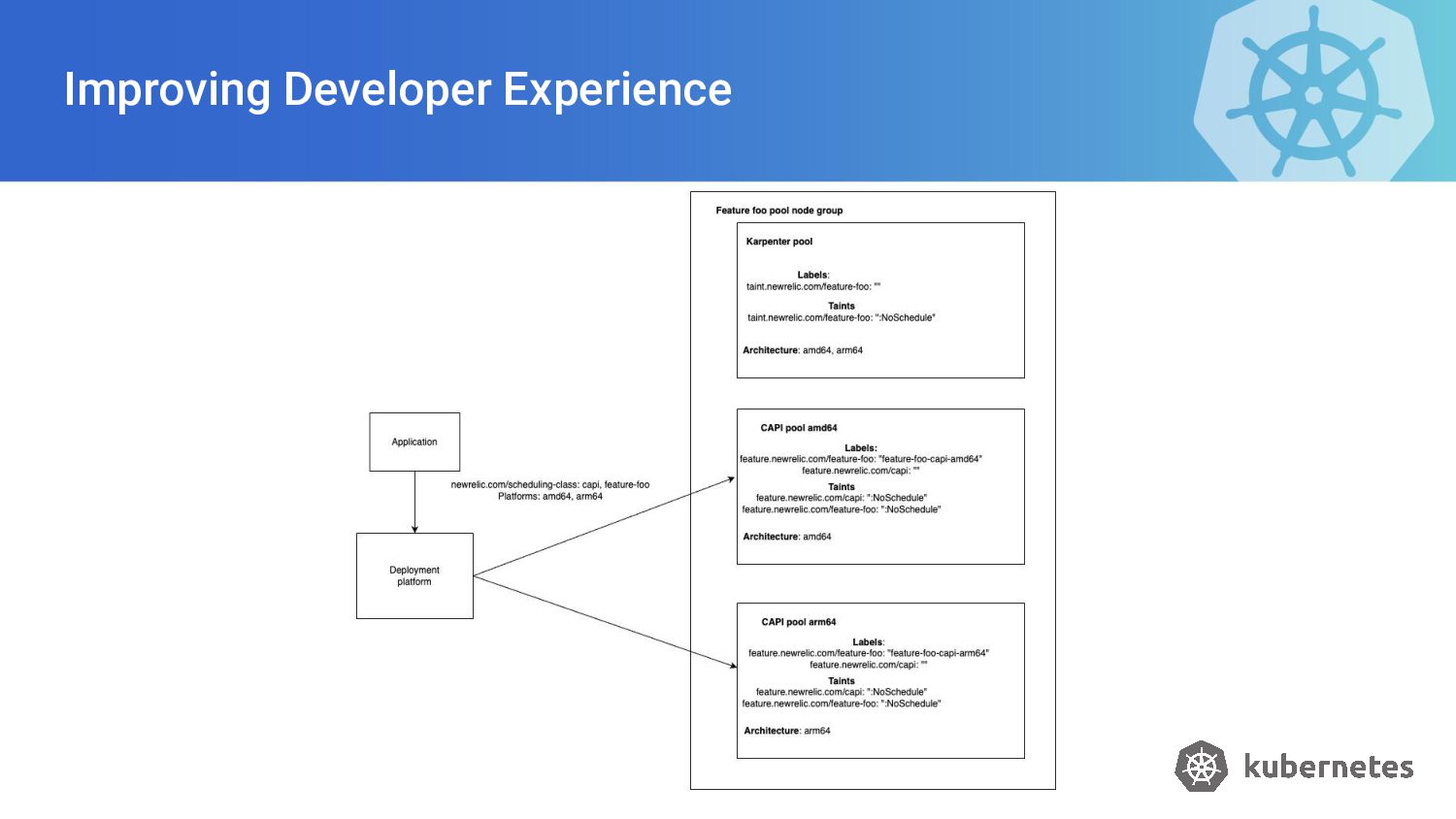
New Relic operates tens of thousands of nodes across hundreds of Kubernetes clusters. Pod assignment to these thousands of nodes is done every day, as applications get deployed. I'll share our experience in abstracting out the Kubernetes scheduling primitives from users, discuss their limitations and describe the solution. I'll cover:
* the complexity for end user, in specifying scheduling rules to Kubernetes at scale.
* how we built a scheduling engine by extending Kubernetes via mutating admission webhooks, to translate declarative requirements by user into native Kubernetes scheduling constraints.
* tradeoffs made in the system.
After this talk, attendees will be better prepared to deal with the complexity of extending Kubernetes, to abstract pod assignment to nodes, especially at scale, for end users.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
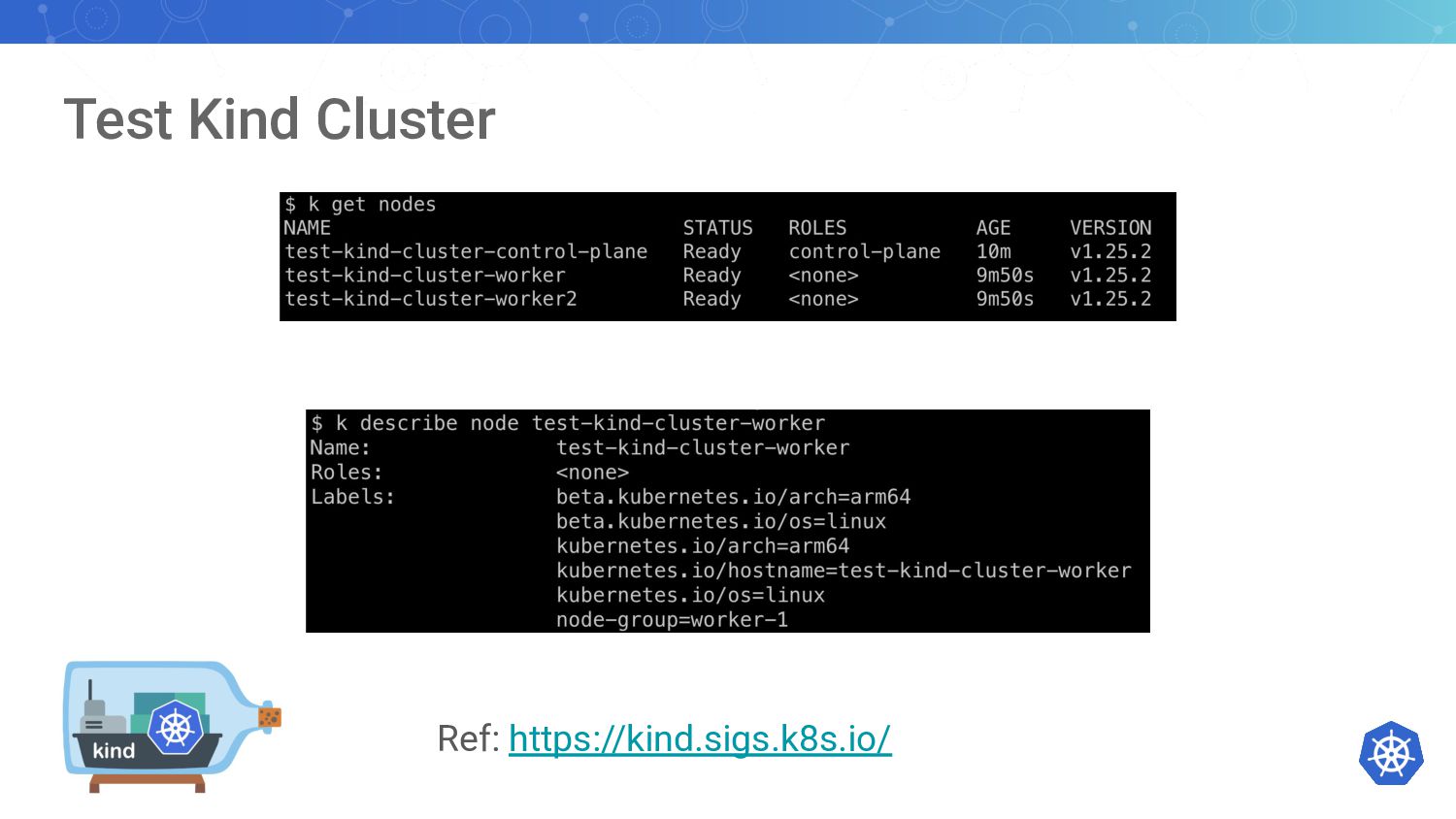{kind=link}
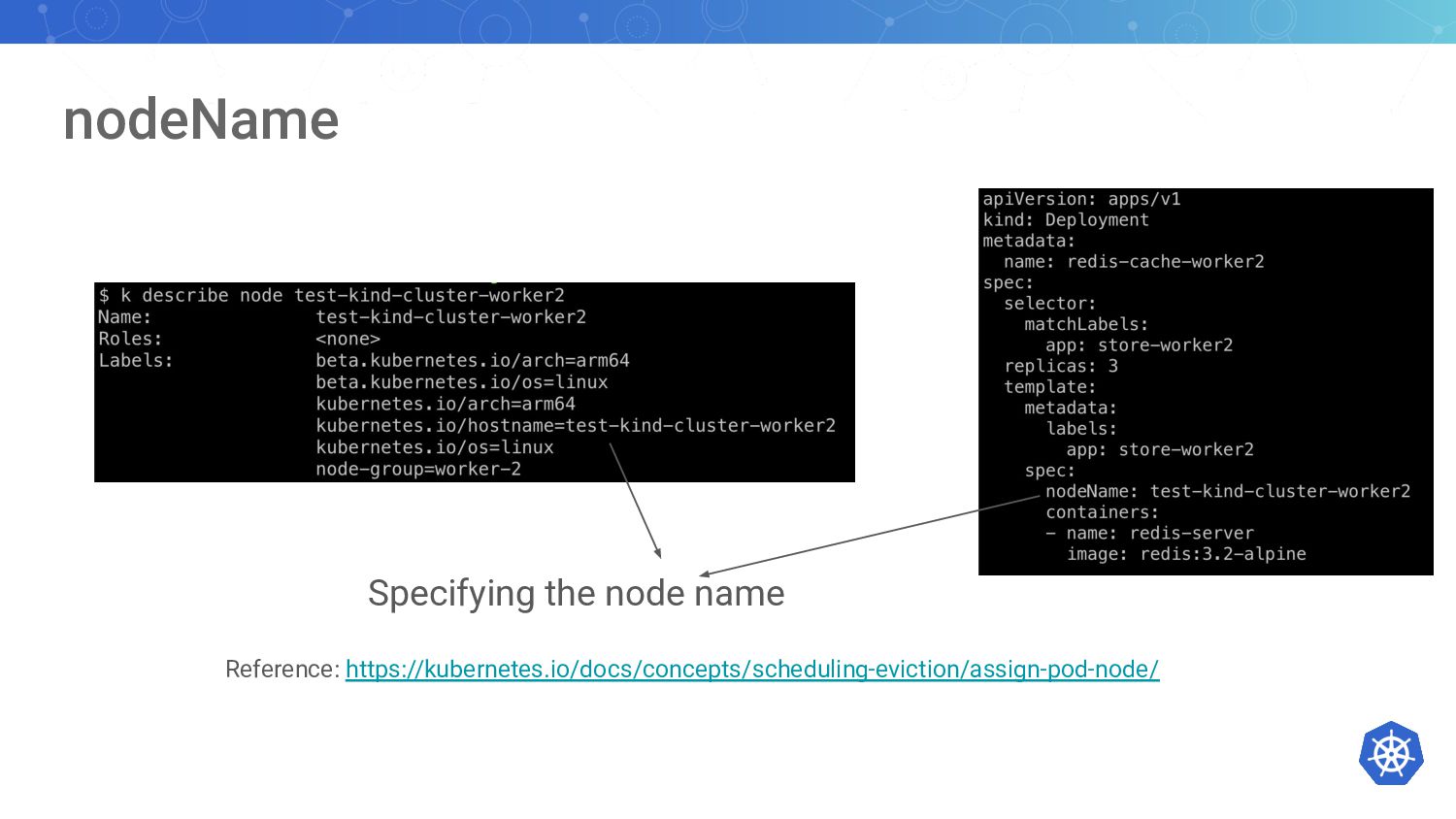{kind=link}
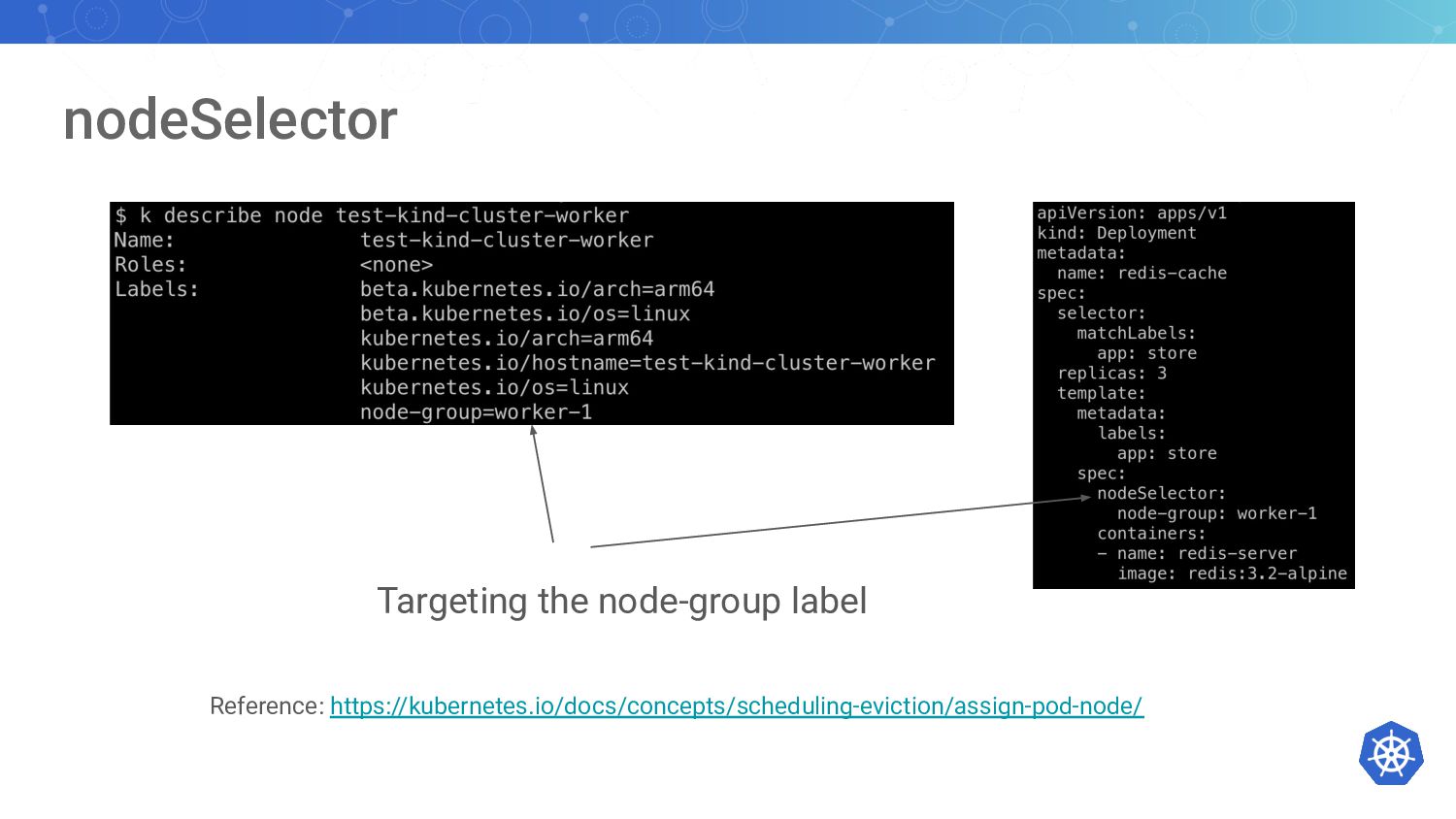{kind=link}
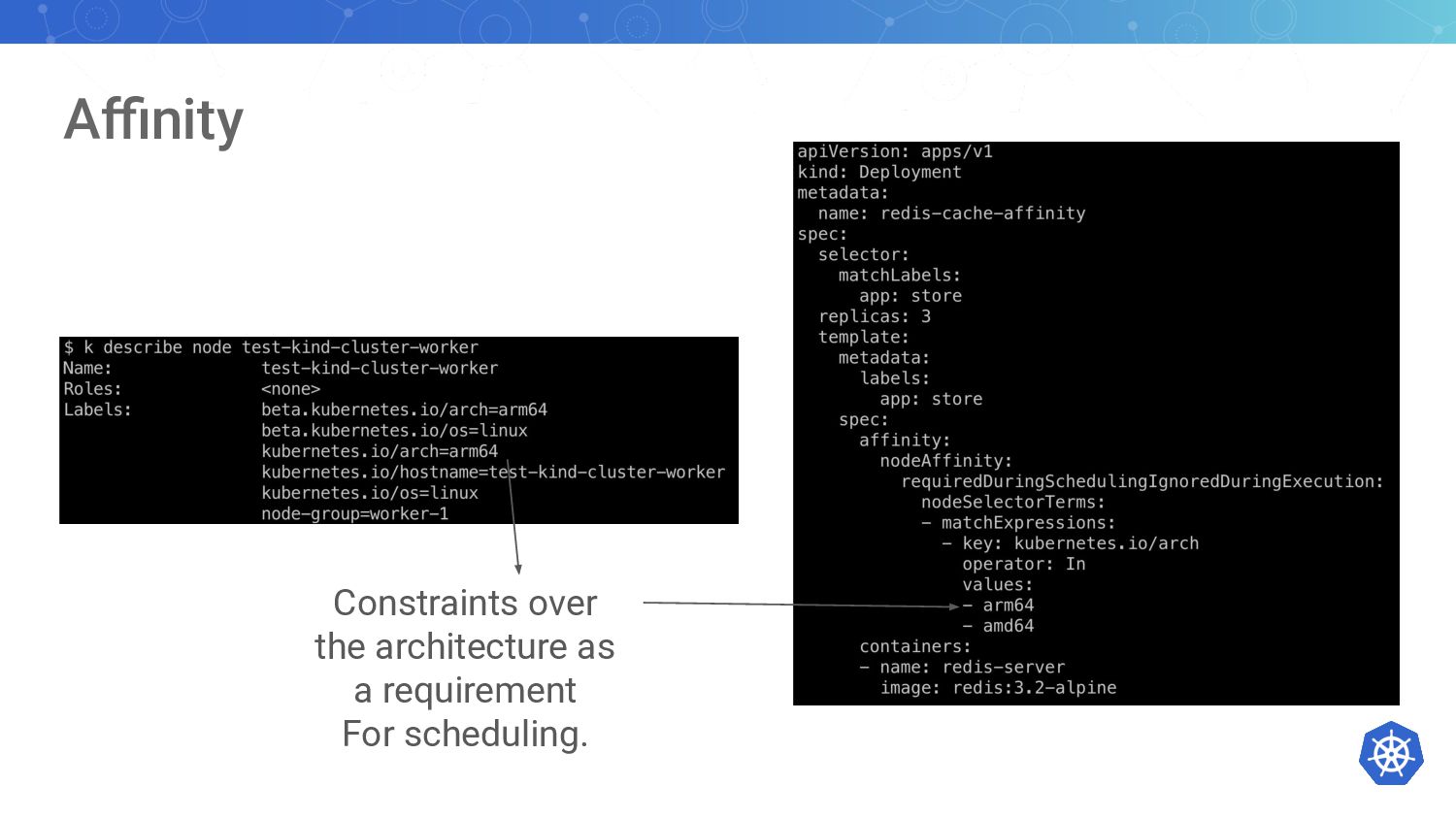{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
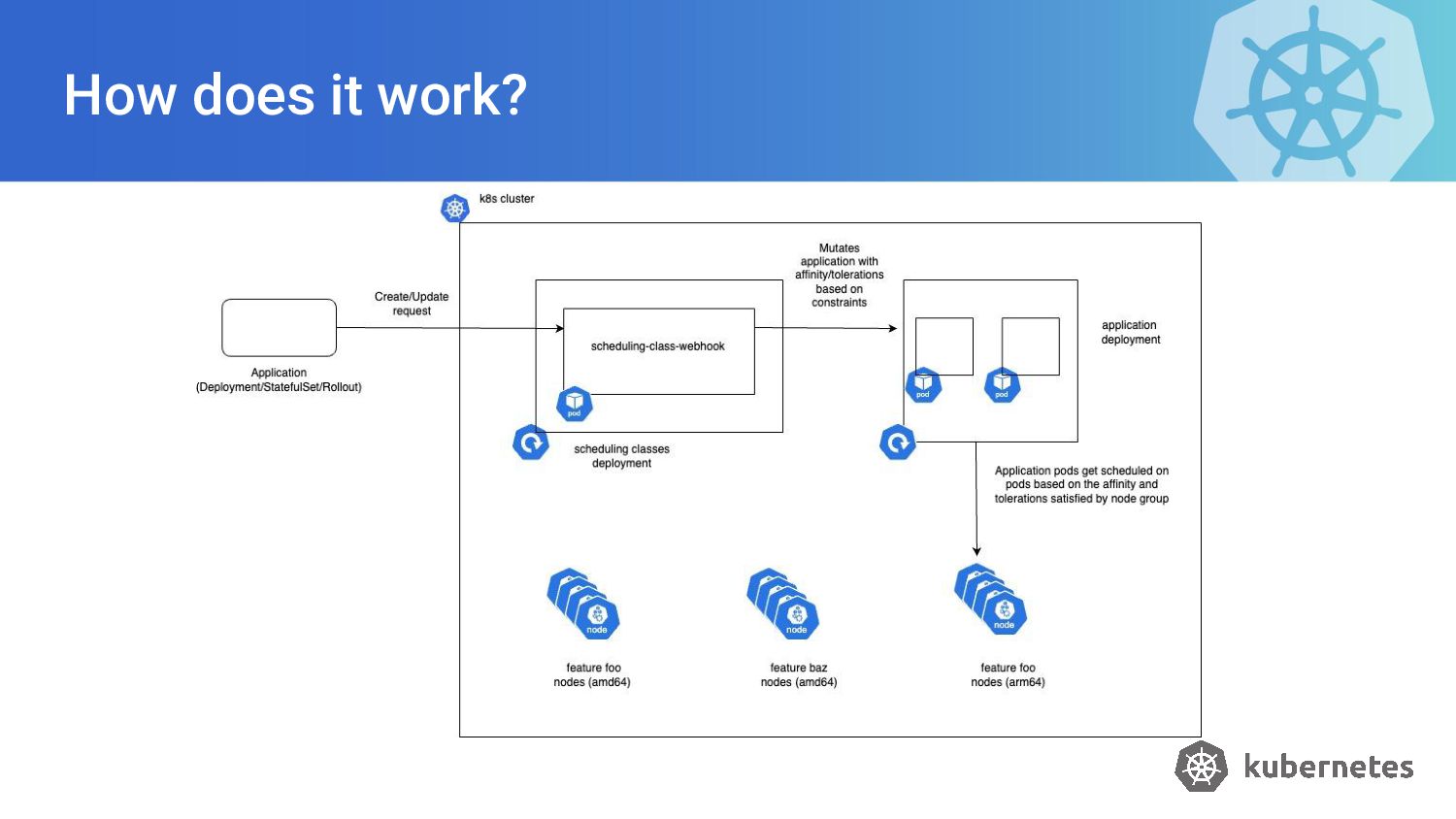{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
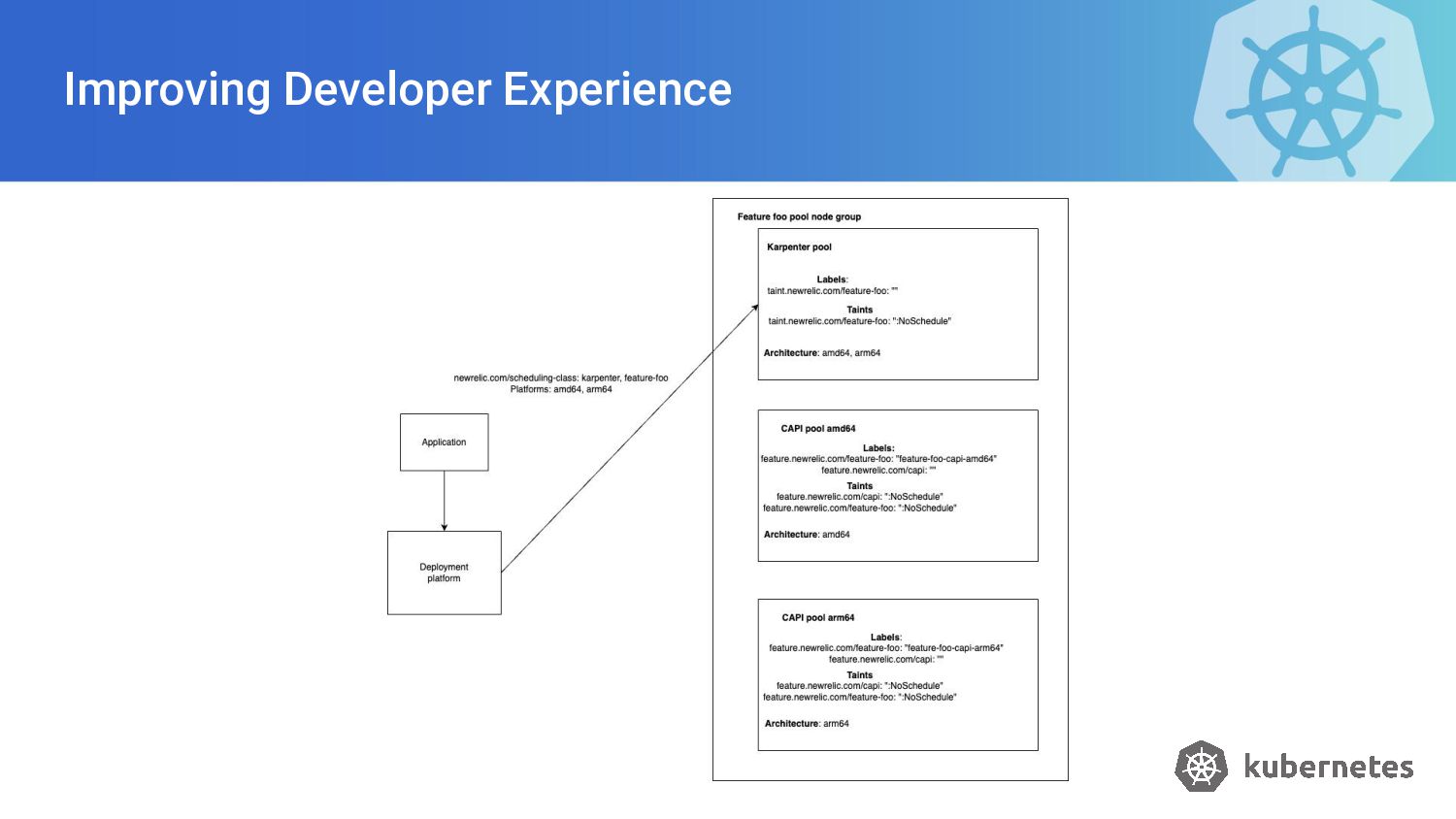{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}