Семён Факторович (HDsoft) рассказывает про Unicode и историю кодировок.
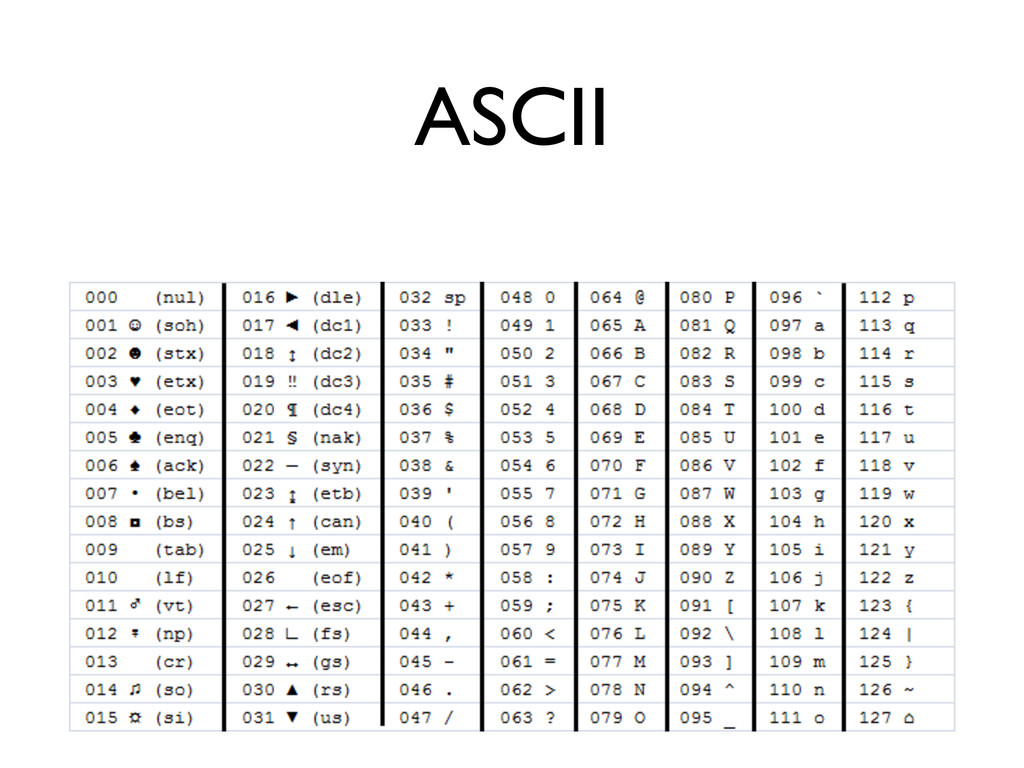
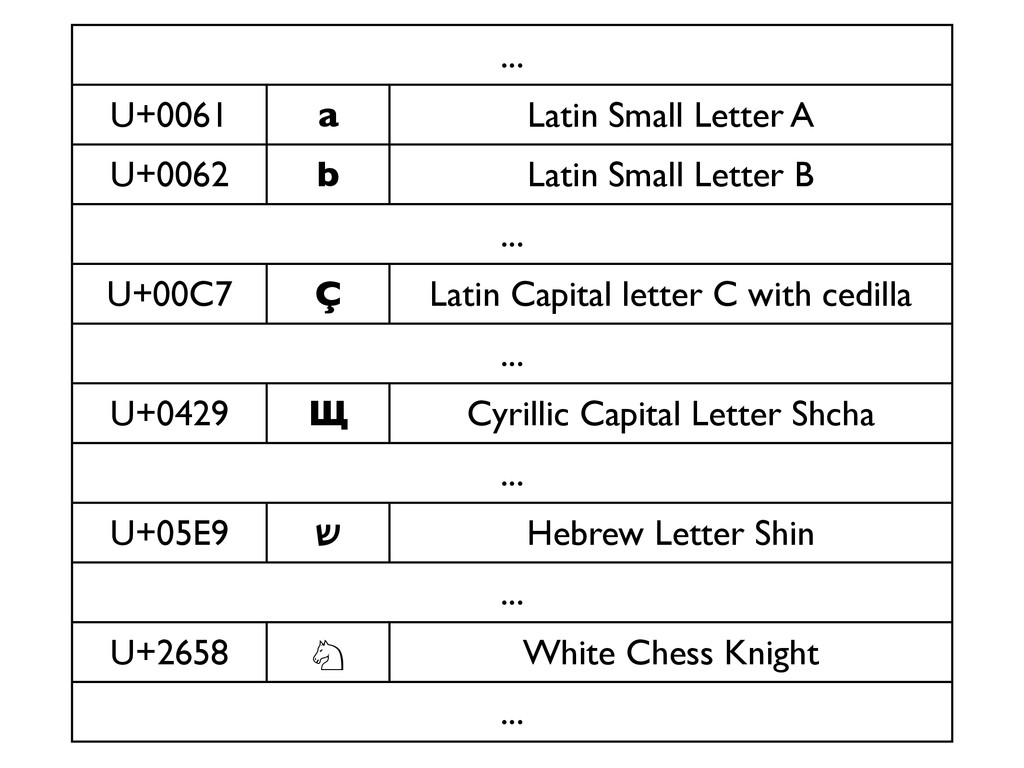
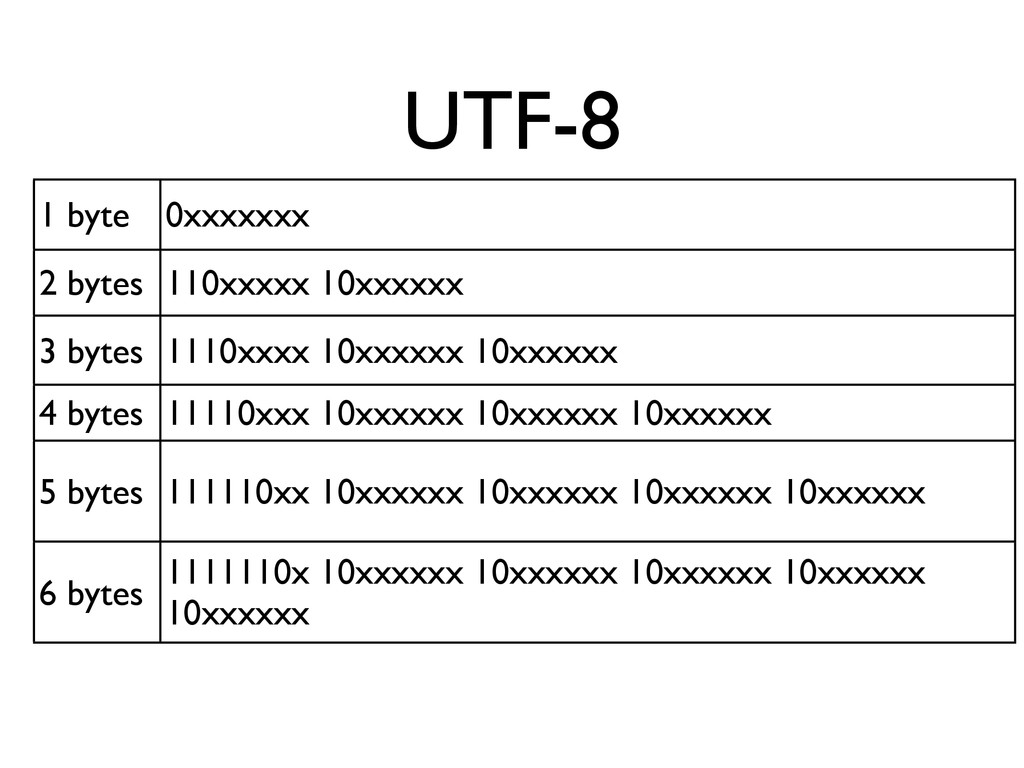
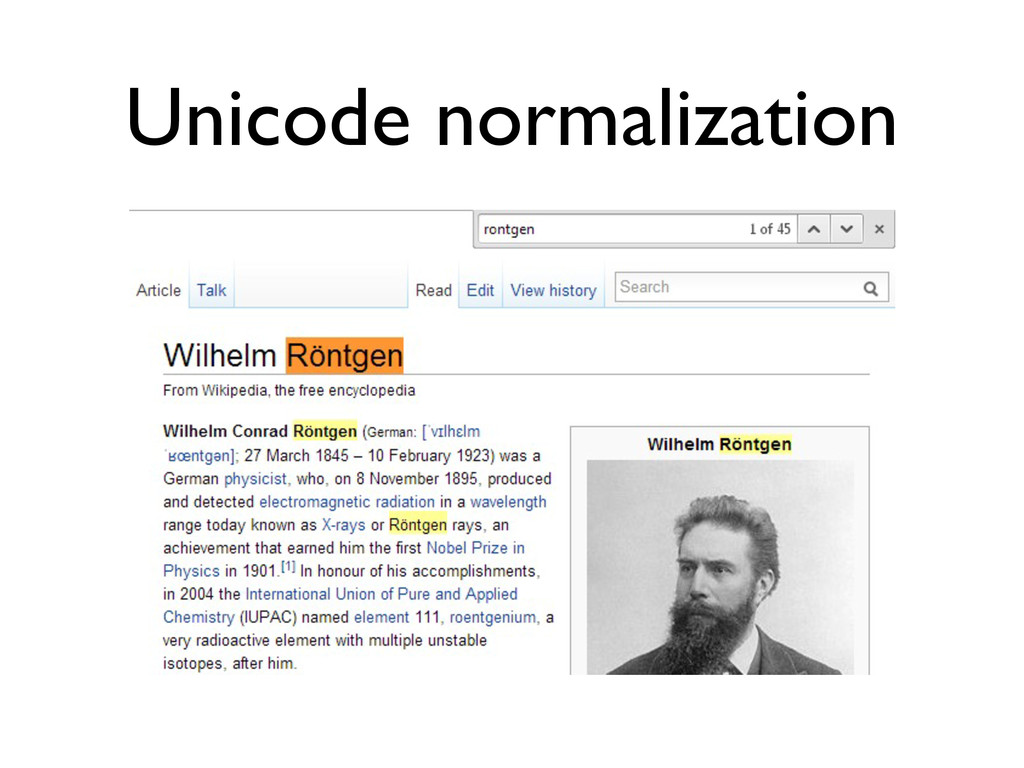
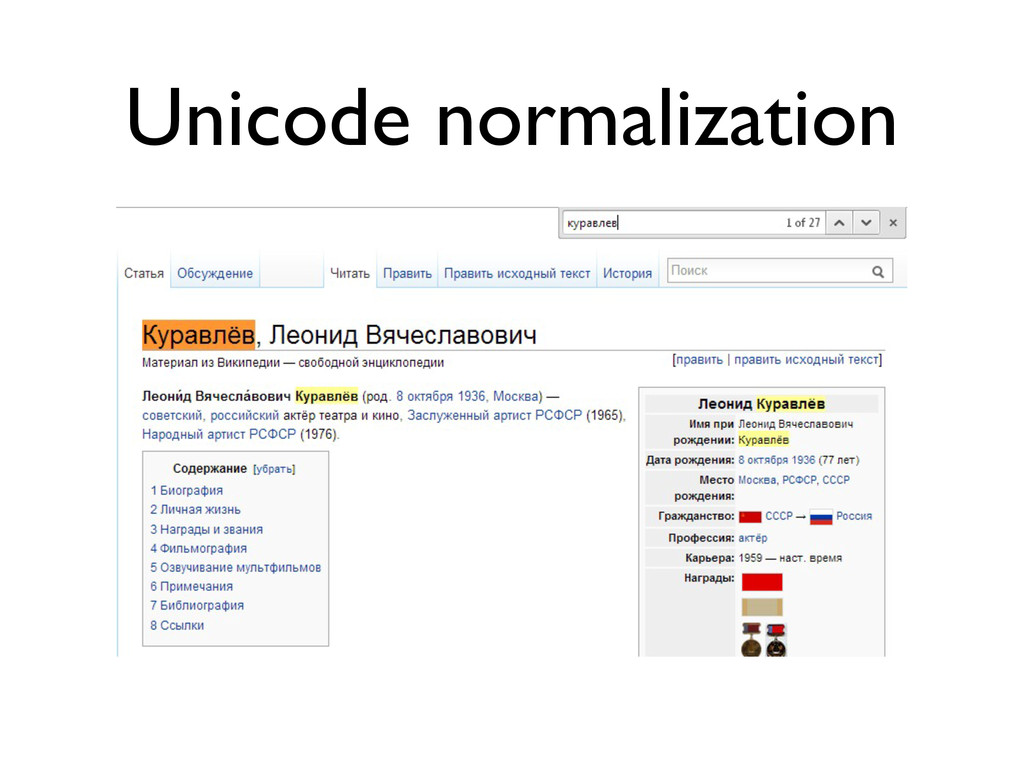
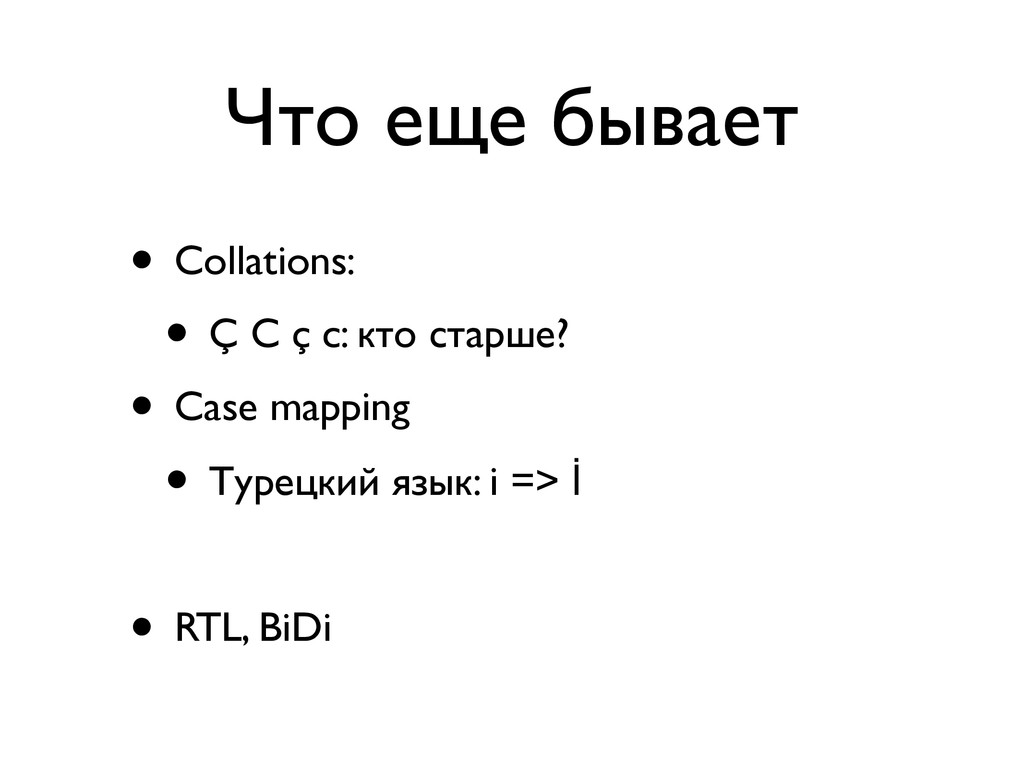
«Что лучше: UTF-8, UTF-16 или UTF-32? Сколькими байтами кодируется одна буква в UTF-16? Почему использование слова «буква» в предыдущем вопросе некорректно? Почему правильно реализовать strlen() или функцию переворачивания строки вовсе не так просто, как кажется? И почему, чёрт возьми, при попытке вывести русские буквы в консоль я вижу кракозябры?
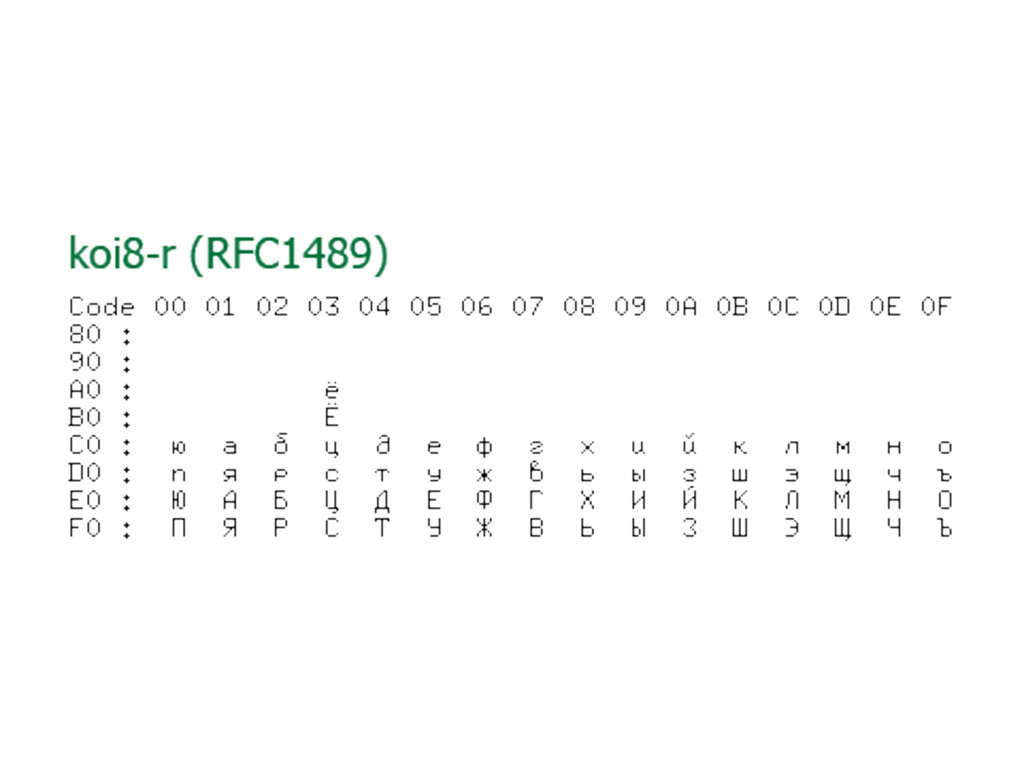
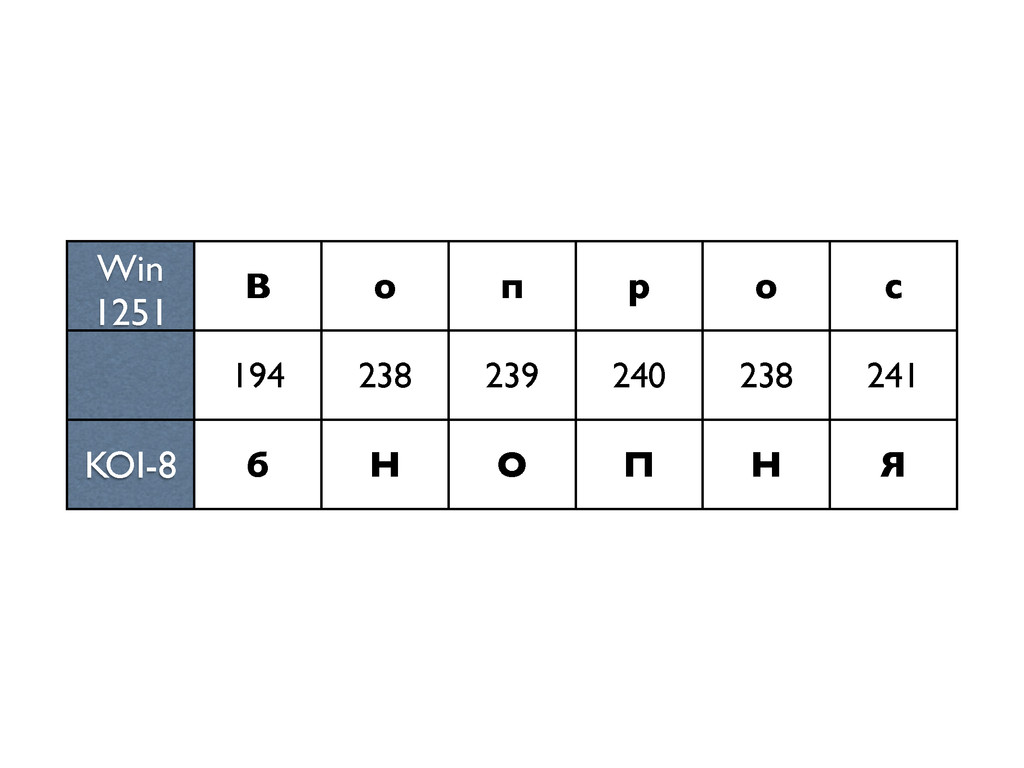
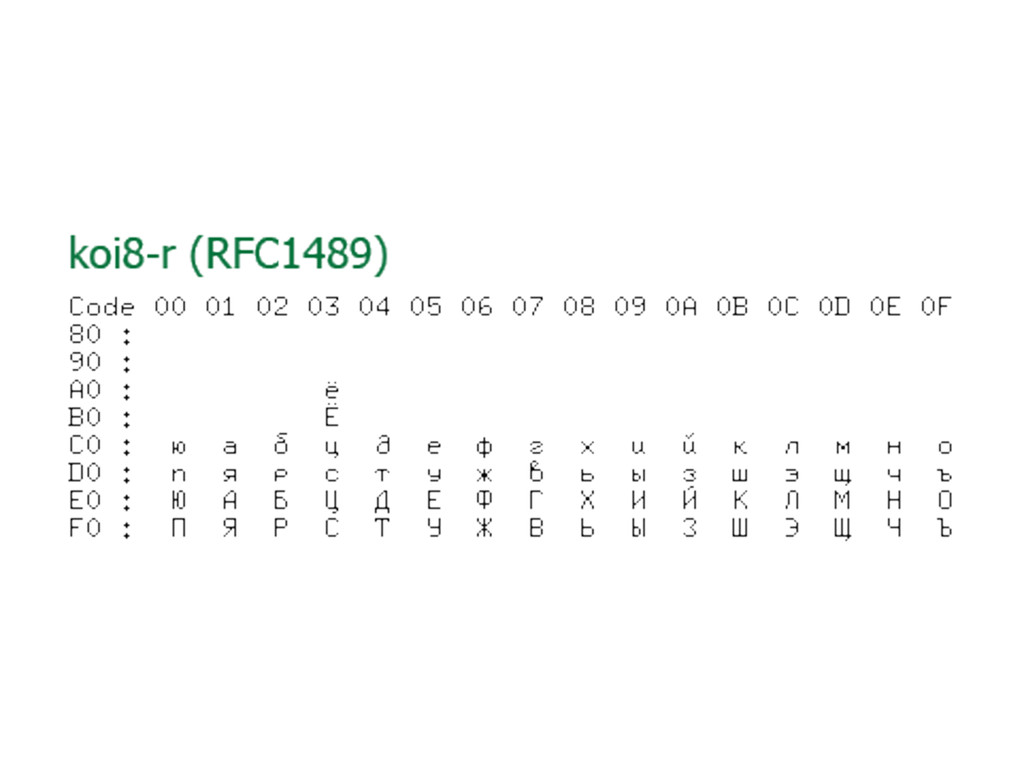
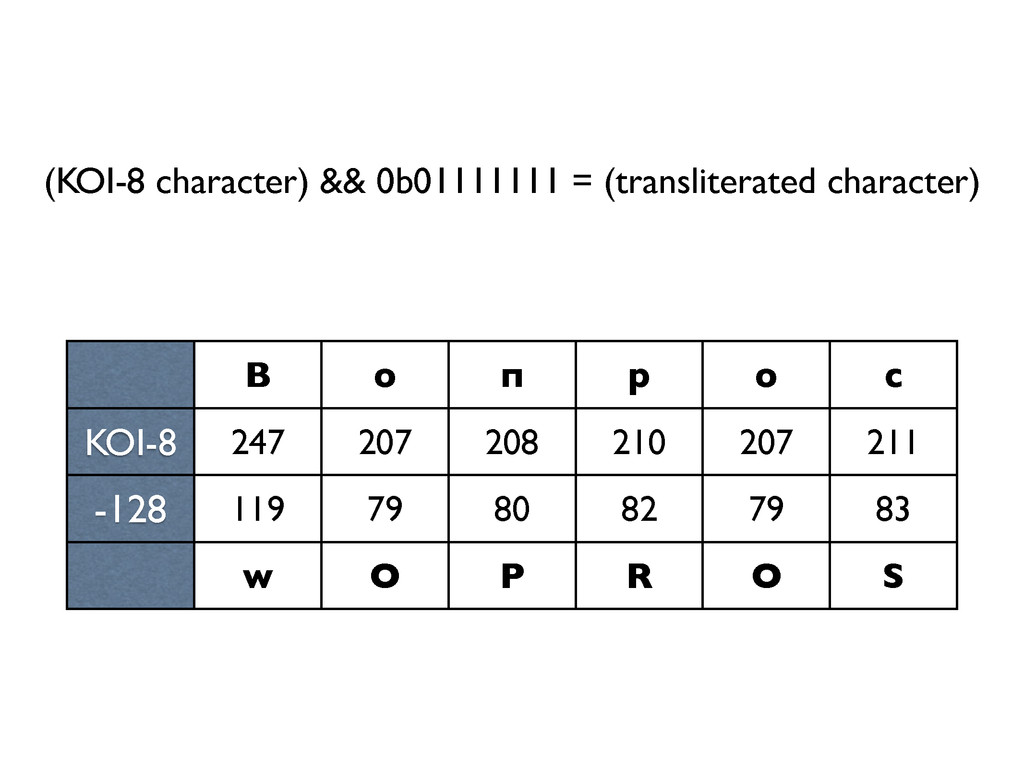
В лекции будут даны ответы на эти и некоторые другие вопросы о Unicode. Бонусом мы расскажем краткую историю кодировок от начала времен (точнее, от времен DOS CP 866 и KOI8-R)»
Видеозапись: http://www.youtube.com/watch?v=8HRq_-c5fn0
Подробности: http://techtalks.nsu.ru
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![résumé [ r e ˊ s u m e ˊ]](https://files.speakerdeck.com/presentations/91dd55904627013234d17a3f7c519e69/slide_58.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}