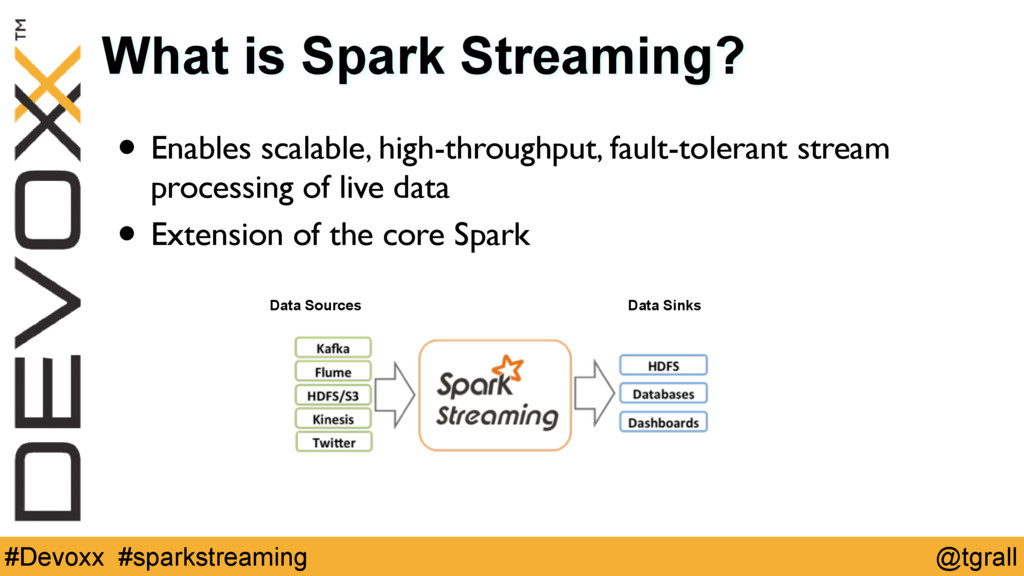
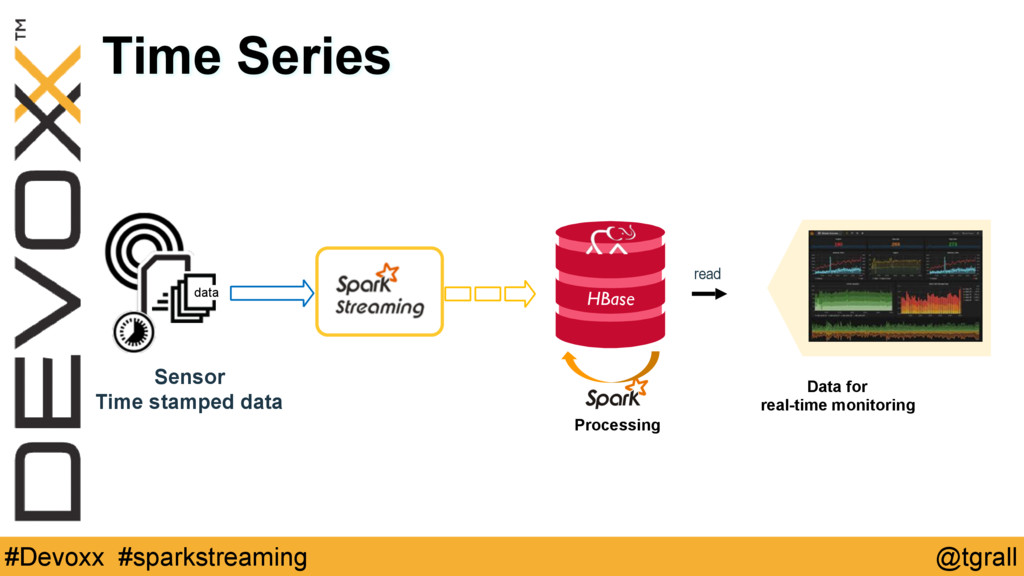
More and more applications have to store and process time series data, a very good example of this are all the Internet of Things -IoT- applications.
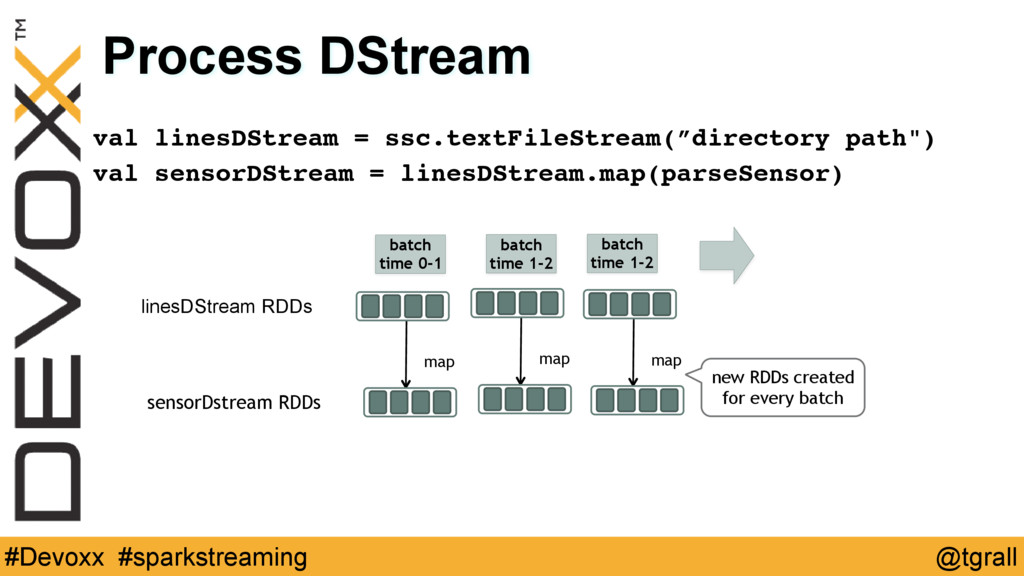
This hands on tutorial will help you get a jump-start on scaling distributed computing by taking an example time series application and coding through different aspects of working with such a dataset. We will cover building an end to end distributed processing pipeline using various distributed stream input sources, Apache Spark, and Apache HBase, to rapidly ingest, process and store large volumes of high speed data.
Participants will use Scala and Java to work on exercises intended to teach them the features of Spark Streaming for processing live data streams ingested from sources like Apache Kafka, sockets or files, and storing the processed data in HBase.
See: https://github.com/tgrall/spark-streaming-hbase-workshop
Open ./doc/index.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
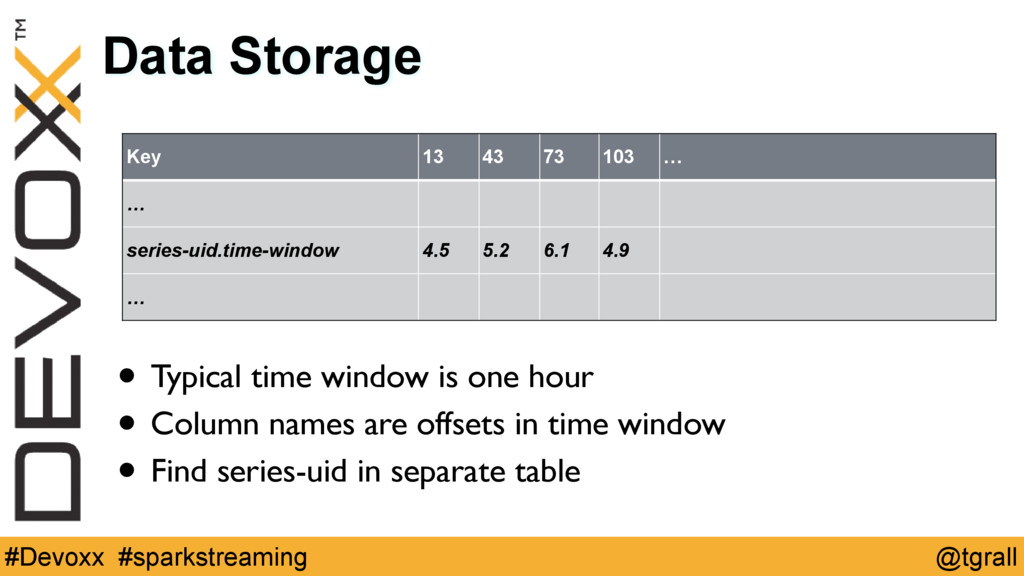{kind=link}
{kind=link}
{kind=link}
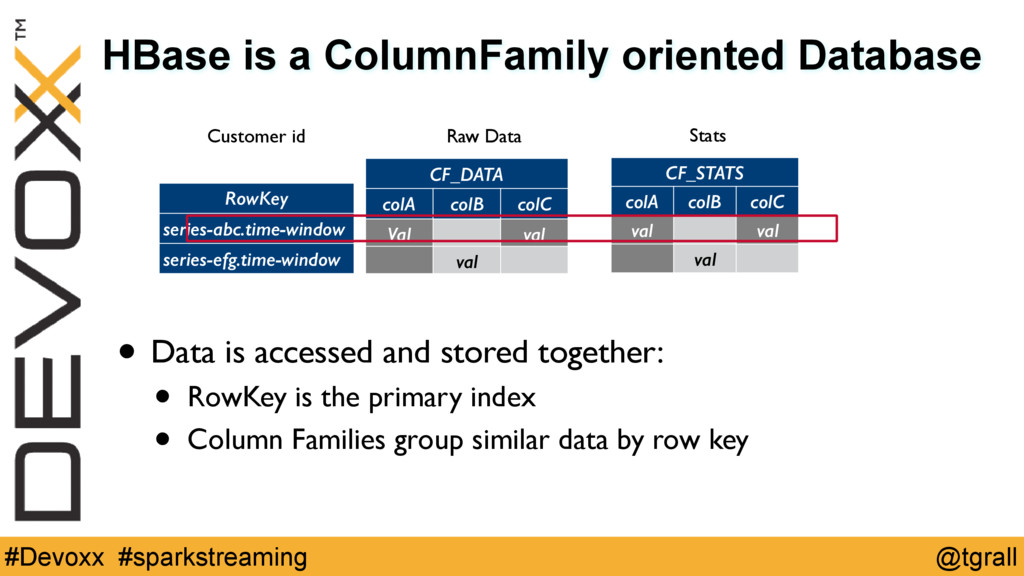{kind=link}
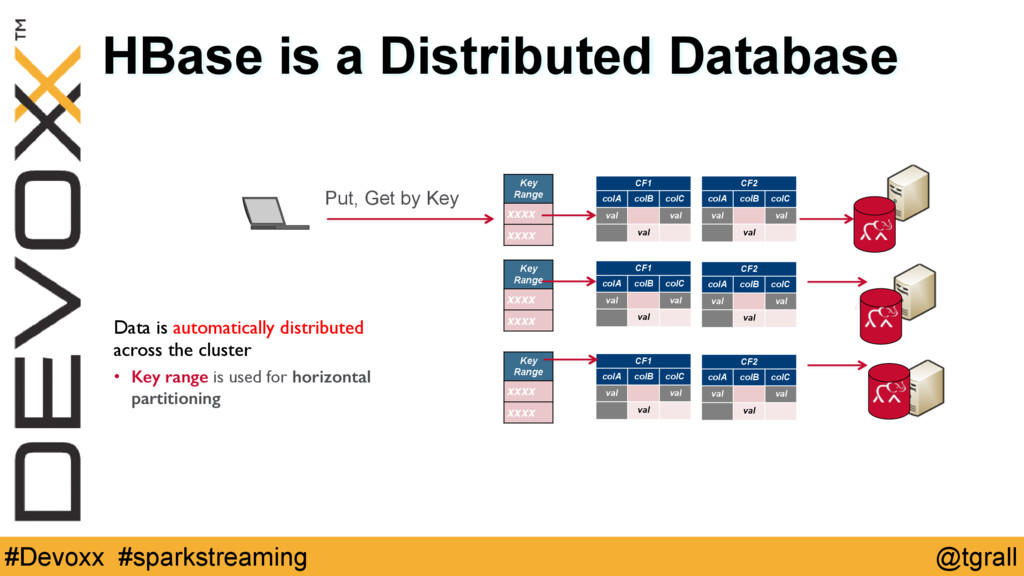{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
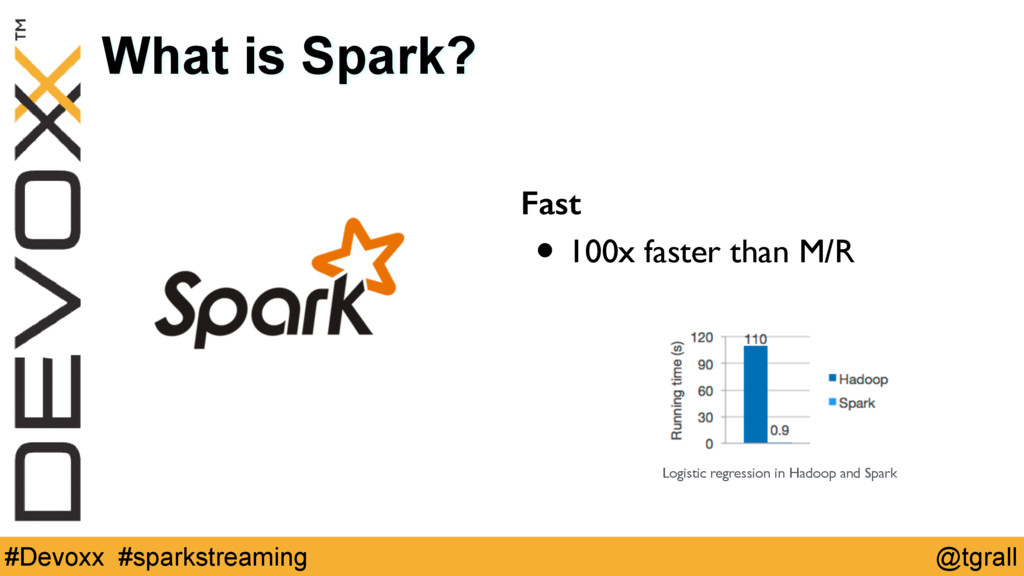{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}