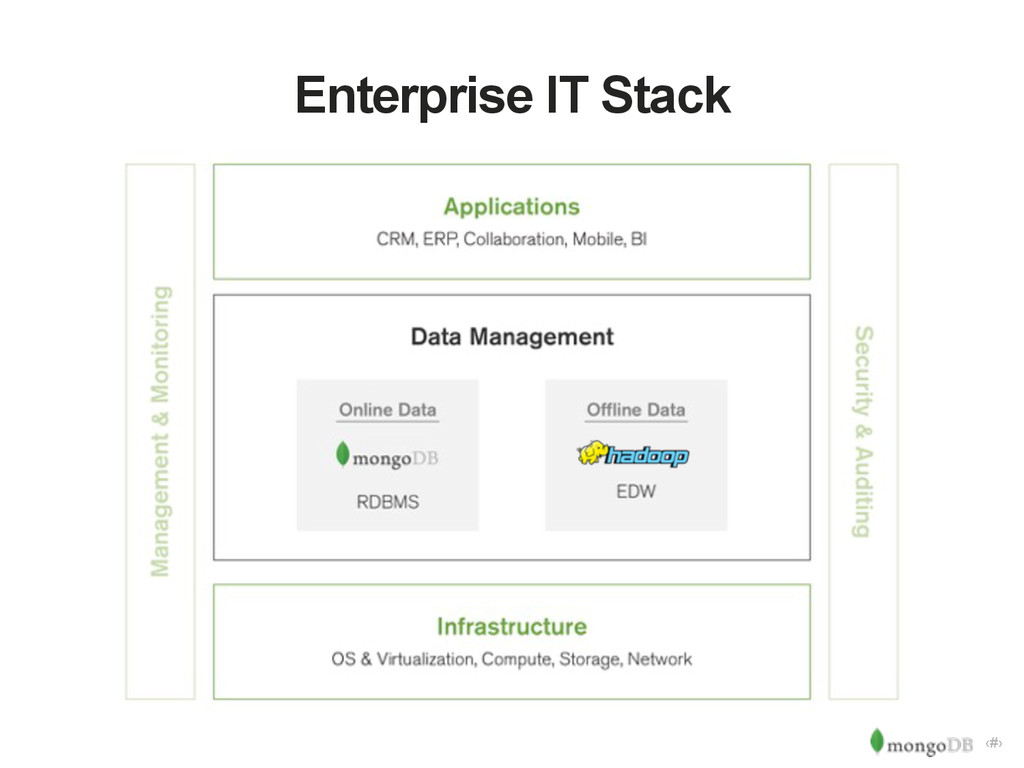
analytics Hadoop “The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.” http://hadoop.apache.org
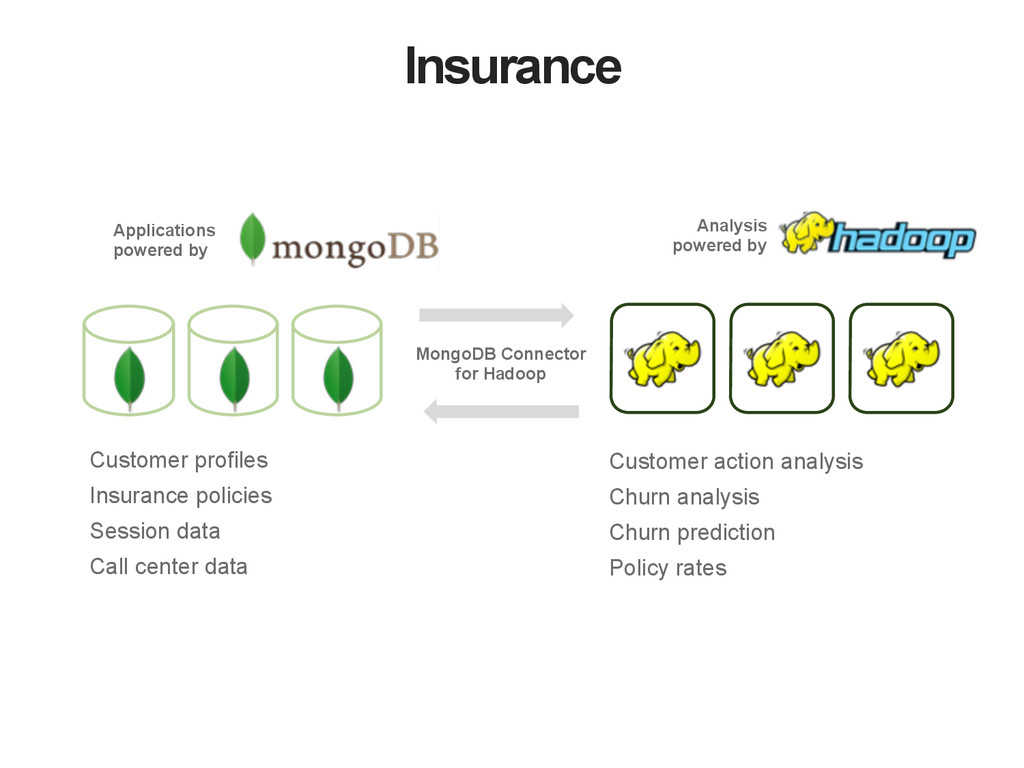
data • Single Node, Replica Sets, Sharded Clusters • Mappings for Pig and Hive • MongoDB as a standard data source/destination • Support for • Filtering data with MongoDB queries • Authentication • Reading from Replica Set tags • Appending to existing collections
LOAD ‘mongodb://mydb:27017/db.collection’ using com.mongodb.hadoop.pig.MongoLoader • Output: BSONStorage and MongoInsertStorage STORE records INTO ‘hdfs:///output.bson’ using com.mongodb.hadoop.pig.BSONStorage
Use with MongoStorageHandler or BSONStorageHandler CREATE TABLE mongo_users (id int, name string, age int) STORED BY "com.mongodb.hadoop.hive.MongoStorageHandler" WITH SERDEPROPERTIES("mongo.columns.mapping” = "_id,name,age”) TBLPROPERTIES("mongo.uri" = "mongodb://host:27017/test.users”)
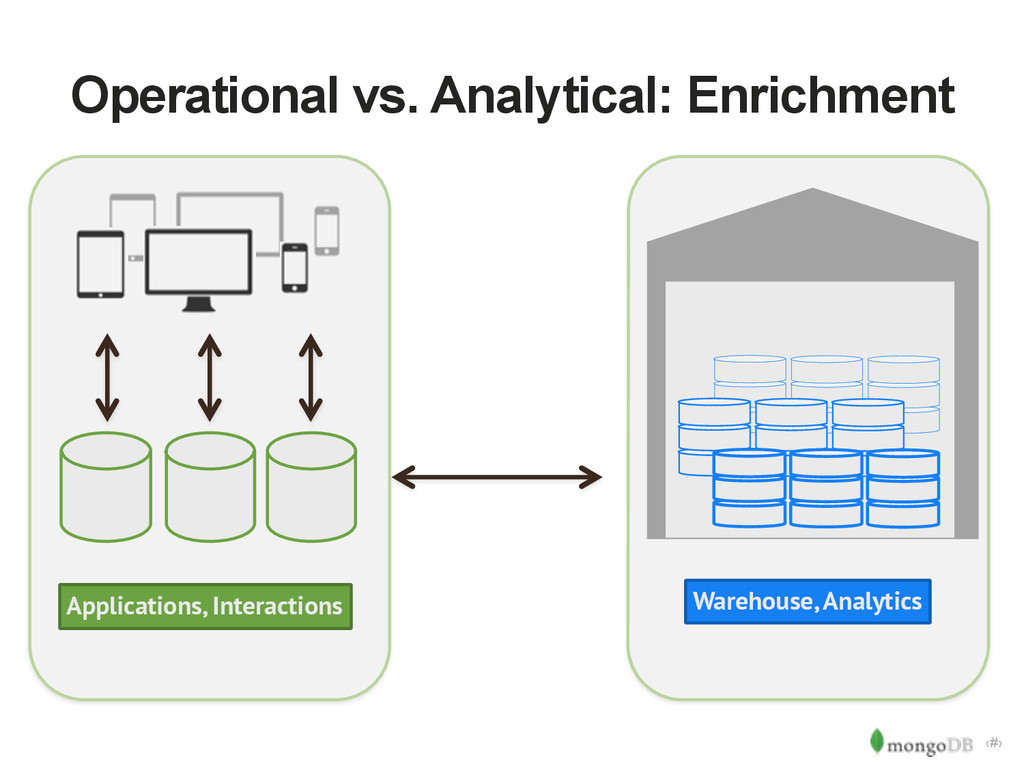
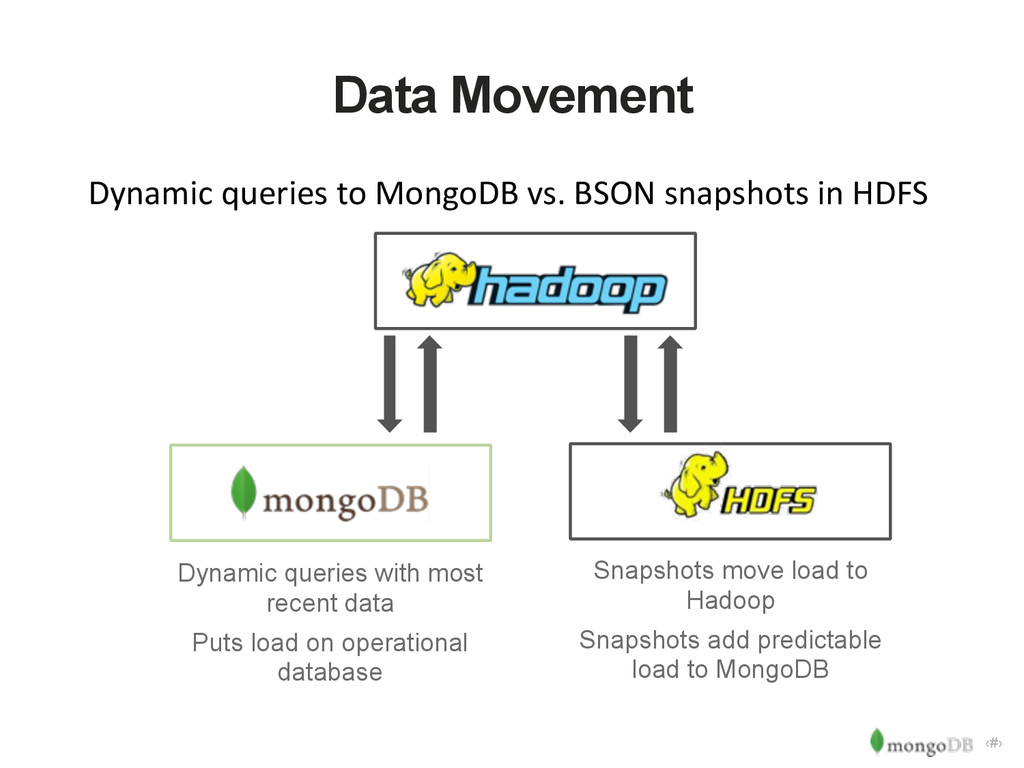
in HDFS Dynamic queries with most recent data Puts load on operational database Snapshots move load to Hadoop Snapshots add predictable load to MongoDB
all pairings Write Prediction to MongoDB collection Store BSON in HDFS Read BSON into Spark App Create user movie pairing Web Application exposes recommendations Repeat Process Train Model from existing ratings
![Paris Tugdual Grall Technical Evangelist [email protected] @tgrall](https://files.speakerdeck.com/presentations/821920d07bb00132936152670ac491d6/slide_0.jpg){kind=link}
![MongoDB & Hadoop Tugdual Grall Technical Evangelist [email protected] @tgrall](https://files.speakerdeck.com/presentations/821920d07bb00132936152670ac491d6/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
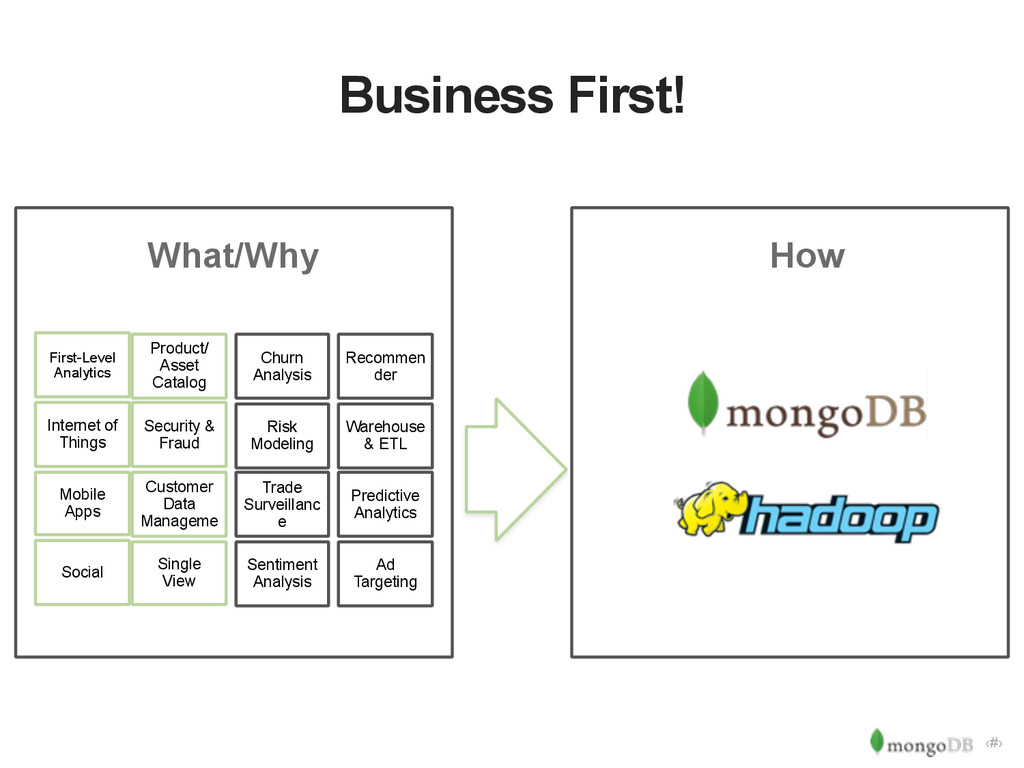{kind=link}
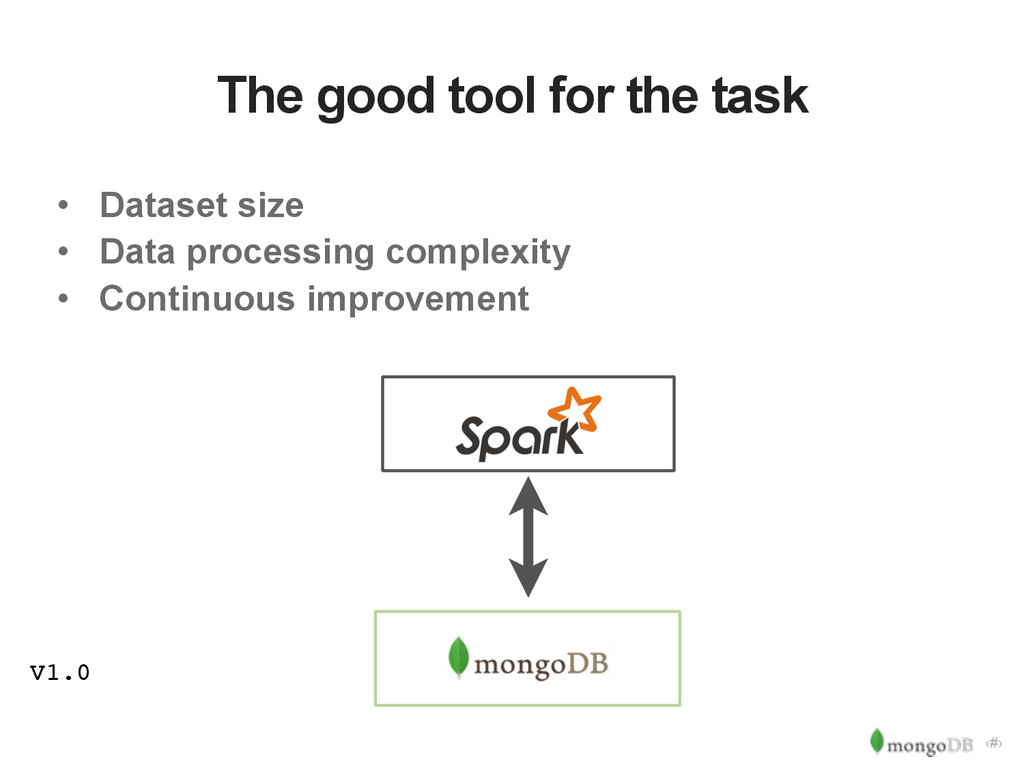{kind=link}
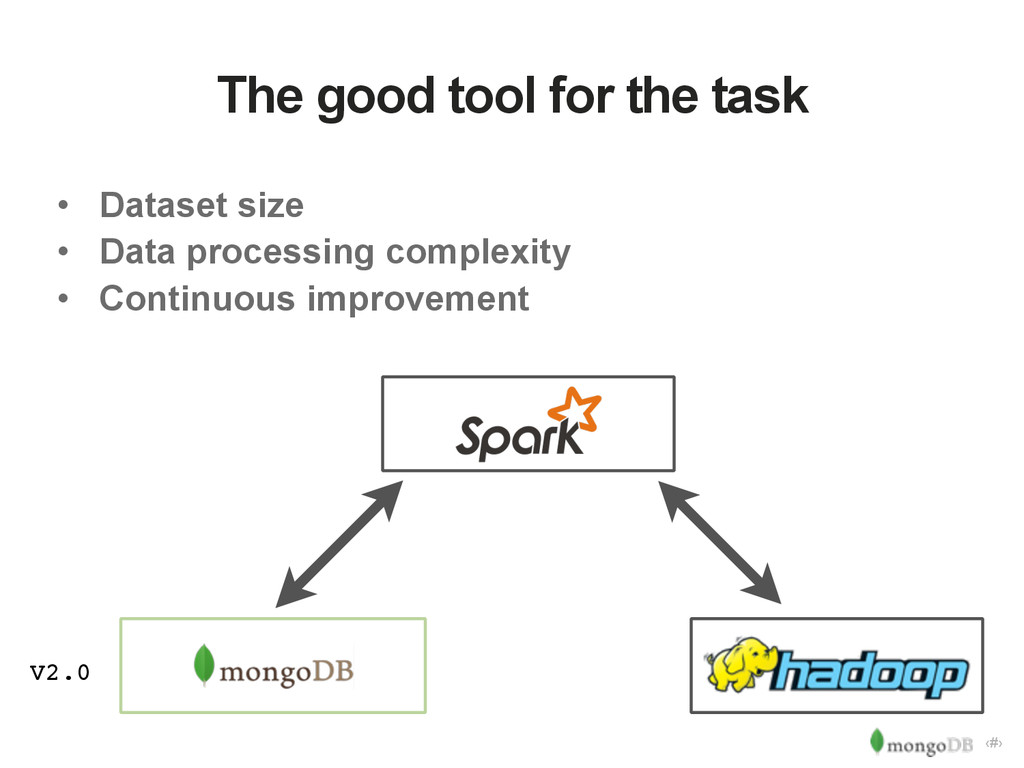{kind=link}
{kind=link}
![MongoDB & Hadoop Tugdual Grall Technical Evangelist [email protected] @tgrall](https://files.speakerdeck.com/presentations/821920d07bb00132936152670ac491d6/slide_34.jpg){kind=link}