fazer com as previsões? demite servidor? desqualifica licitante? a tecnologia avança mais rápido que a legislação problema relacionado: grande qtde. de previsões; é impossível dar vazão a tudo
si nem mesmo quando os dados são públicos (!) “ok, mas só se firmarmos um convênio” “ok, mas a extração custa R$ 39.844.095.098.490.802.984.309.582.304” “como assim você queria os dados atualizados?” “como assim você queria todos os dados?”
– ComprasNet – não tem documentação “quem tinha essa documentação era o Zé das Couves mas ele se aposentou...” mito: “ciência de dados é 80% pré-processamento e 20% modelagem” realidade: ciência de dados é 80% entender os dados e 20% pré- processamento e modelagem
como float DD/MM/AA, MM/DD/AA, AA/MM/DD na mesma coluna -9, -1, -999, etc, como missing data (acaba entrando no cálculo das médias) valores absurdos (ex.: contrato de TI de US$ 1 quatrilhão)
semanas não dá em nada muitos falsos positivos, muitos falsos negativos, o problema deixou de ser relevante, etc é difícil estimar prazos (finais ou intermediários) chefia precisa estar ok com isso mas mais importante: é preciso poder errar perante os colegas “psychological safety” http://www.nytimes.com/2016/02/28/magazine/what-google-learned-from-its- quest-to-build-the-perfect-team.html
órgãos? cidadão? usuário não está pagando pelo serviço, então tem menos propensão a dar feedback não dá pra ouvir o usuário só no final, depois que o app levou meses p/ ser desenvolvido e o órgão gastou $$$$$ difícil lição: data product bacana != data product útil “fator uau” não prediz sucesso de funcionalidade CÉREBRO: grafo gravitacional na visualização de redes societárias usuário: “pq essas bolinhas ficam dançando na minha frente??”
estatística/mineração & desenvolvimento de software & domínio do negócio recrutamento é engessado no serviço público salários não são negociáveis concurso premia quem decora leis paliativos: negociar fringe benefits (horário flexível, trabalho remoto, capacitação) PNUD terceirização
mas é a norma especialmente p/ quem escreve código: leva ~25 minutos p/ retomar a produtividade após uma interrupção http://thetomorrowlab.com/2015/01/why-developers-hate-being-interrupted/ http://swizec.com/blog/why-programmers-work-at-night/swizec/3198 http://paulgraham.com/head.html http://tosbourn.com/a-pragmatic-approach-to-dealing-with-interruption-whilst- you-are-developing/ http://blog.ninlabs.com/2013/01/programmer-interrupted/ http://blog.fogcreek.com/protecting-developer-time-with-cases-not-chat/
Despesa Pública da CGU professor de estatística e machine learning (thiagomarzagao.com/teaching) pesquisador (thiagomarzagao.com/papers) entusiasta de LEGO Mindstorms (github.com/thiagomarzagao/ev3py) Ohio State University [email protected], @tmarzagao
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
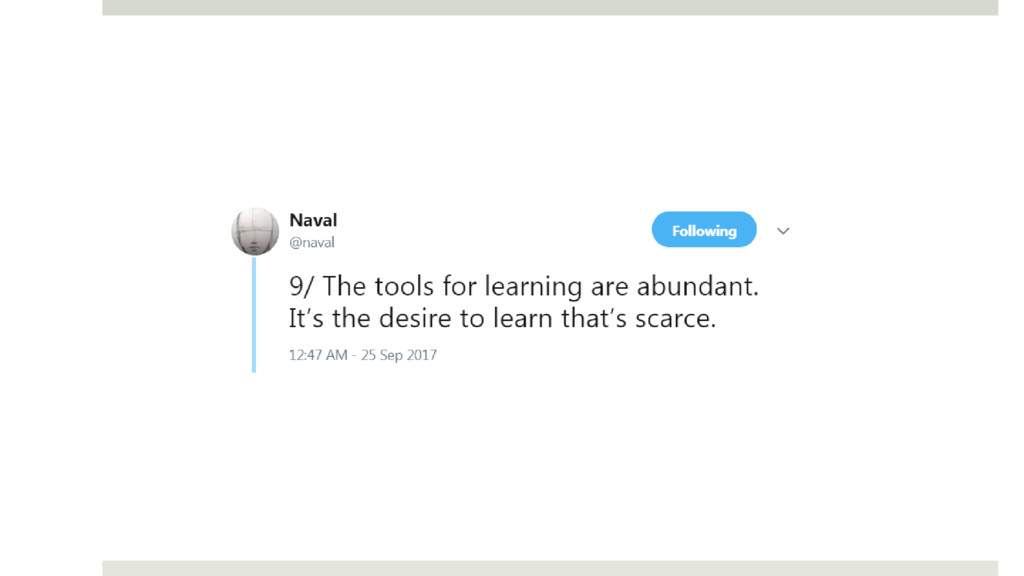{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}