MM, FRASCOS, ETC) 3. PASSA TUDO P/ SINGULAR (RSLP-S) 4. VETORIZA CADA DESCRIÇÃO DE PRODUTO/SERVIÇO 5. TRANSFORMA EM TF-IDF (P/ DAR MAIS PESO ÀS PALAVRAS MAIS DISCRIMINANTES) 6. NORMALIZA (P/ CONTROLAR POR DESCRIÇÕES DE TAMANHOS MUITO DIFERENTES) PRÉ-PROCESSAMENTO:
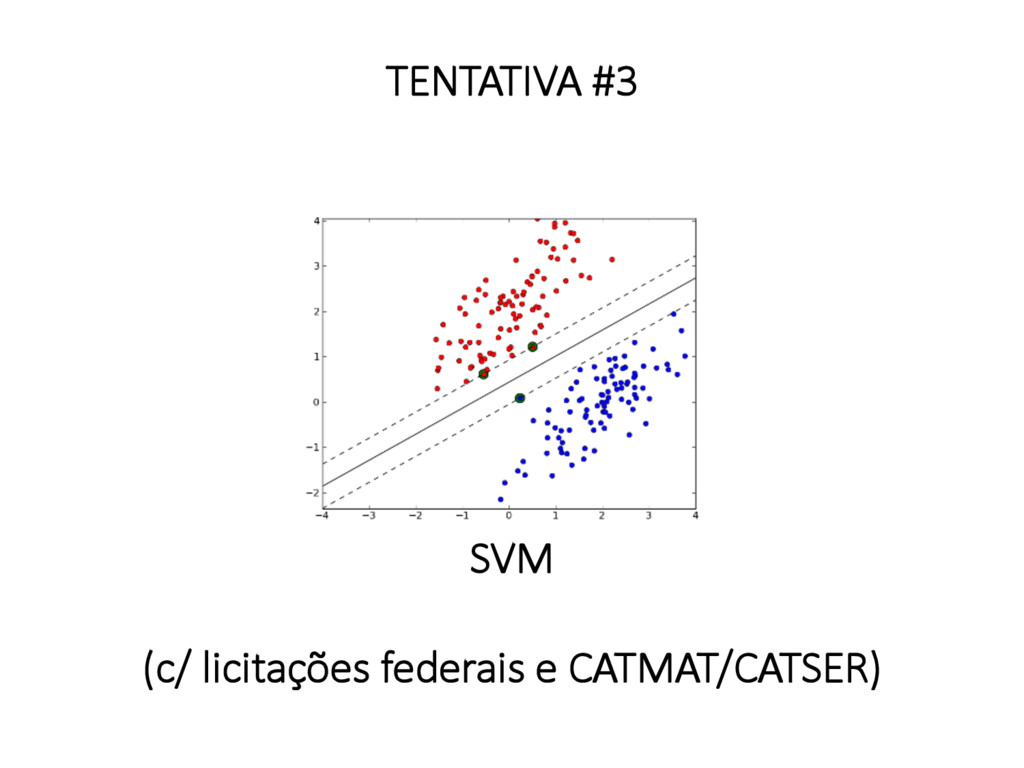
ENTRE AS CLASSES AS CLASSES NÃO SÃO DIVIDIDAS POR UMA LINHA MAS POR UM POLÍGONO DUAS MANEIRAS DE CONSEGUIR ISSO: SOFT- MARGIN (PENALIZA CLASSIFICAÇÕES NO POLÍGONO) OU KERNEL TRICK (AUMENTA # DE DIMENSÕES P/ QUE NADA CAIA NO POLÍGONO) SVM
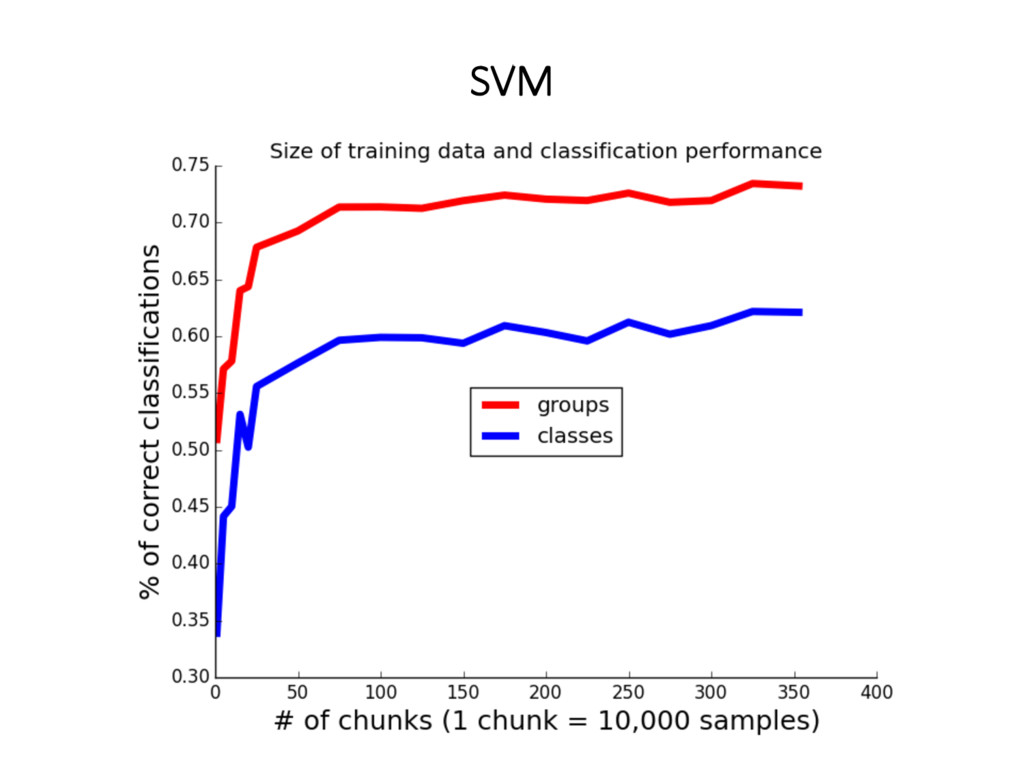
HUBER) 2. TERMO DE REGULARIZAÇÃO (L1, L2, ELASTICNET) 3. DIFERENTES NÍVEIS DO CATMAT/CATSER: GRUPOS (79) E CLASSES (670) 4. # DE PASSES SOBRE OS DADOS 5. TAXA DE APRENDIZADO 6. PESO MAIOR P/ PRIMEIRAS PALAVRAS 7. CONSISTÊNCIA GRUPO-CLASSE SVM
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}