ser independentes entre si. O lance da empresa A não pode nos ajudar a prever o lance da empresa B. O lance da empresa A não pode depender de quais são as outras empresas na licitação. ¤ Se esse requerimento é violado, temos uma suspeita de cartel. ¤ Catch: não dá p/ testar uma licitação individualmente. A lógica do teste é baseada num conjunto de licitações.
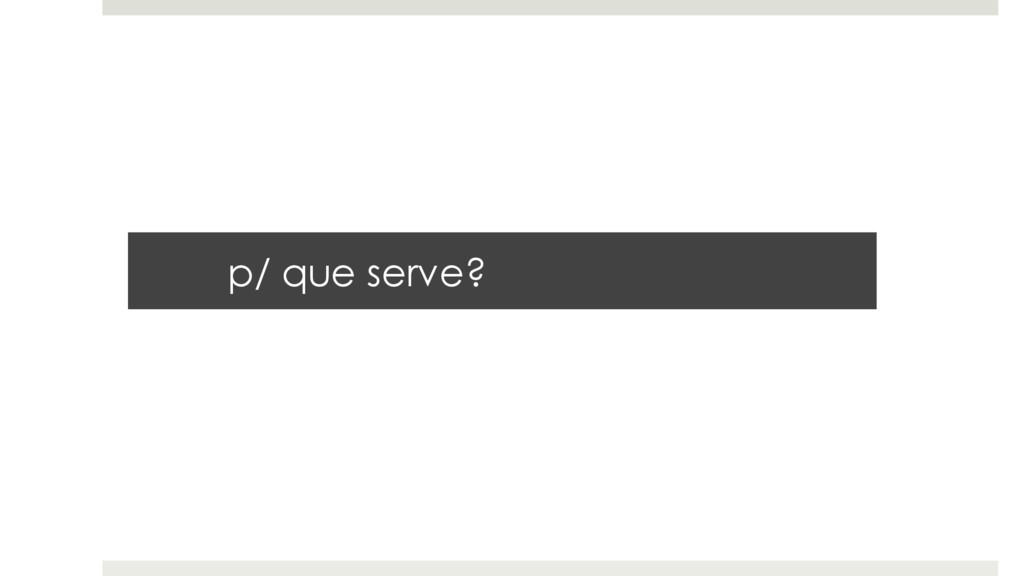
dados. ¤ Idéia é democratizar o acesso a ferramentas de mineração de dados e assim “empoderar” investigadores/analistas. ¤ Roda na intranet do CADE. ¤ Desenvolvido in-house.
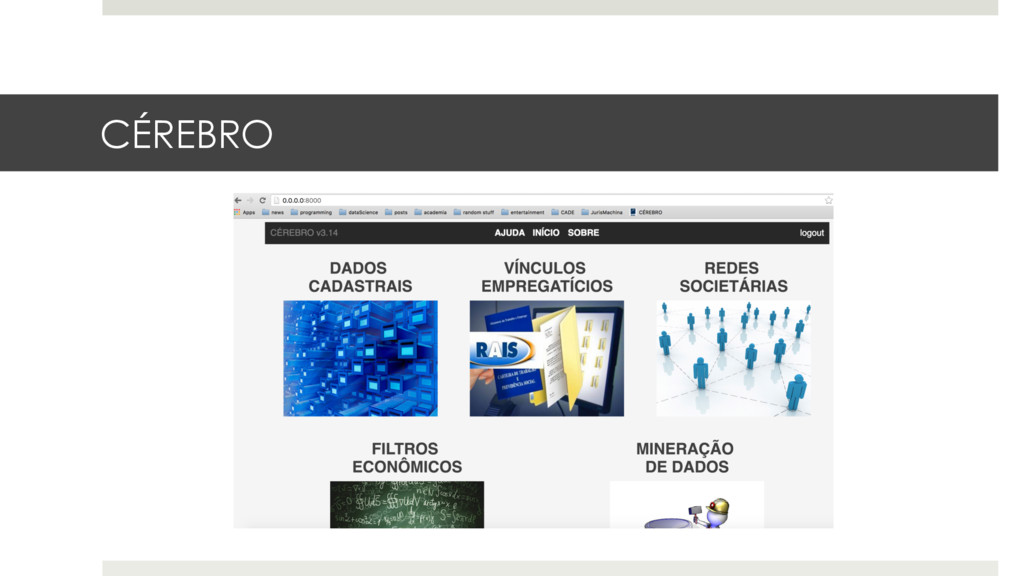
se o preço está razoável (muito alto? muito baixo?). ¤ Remoção de outliers, faixas de preço. ¤ Disponível p/ todo mundo (http://bancopreco.cgu.gov.br/consultarPreco/ index.jsf). ¤ Back-end desenvolvido in-house, front-end desenvolvido por empresa terceirizada. ¤ Nova versão em desenvolvimento (back to basics).
requerem licitação. ¤ Mas apenas p/ compras acima de R$ 8 mil. ¤ “Jeitinho”: dividir compra em lotes inferiores a R$ 8 mil cada. ¤ É crime! ¤ Como identificar? CGU: redes bayesianas.
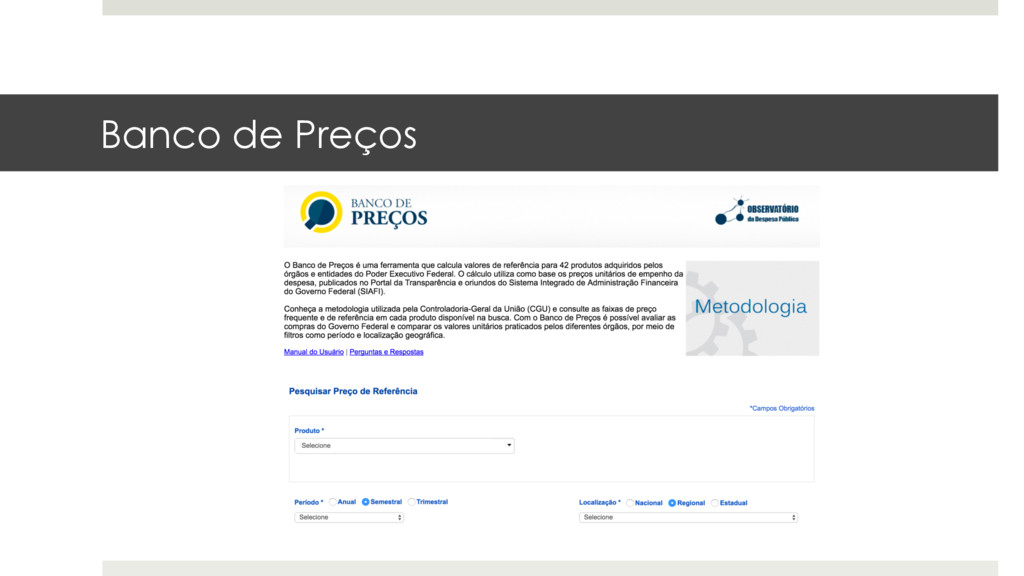
p/ estados e municípios, via convênios (obras públicas, etc). ¤ Esse $ freqüentemente é usado de forma irregular: contratação de empresa do próprio prefeito/governador, contratação de empresa inidônea, etc. ¤ Tudo isso é crime! ¤ Como identificar? TCU: árvores de decisão.
é feita de forma pouco transparente ¤ … aditivos aumentam o valor inicial do contrato ¤ ... funcionários do órgão já trabalham p/ o fornecedor ¤ A probabilidade de corrupção é maior. ¤ Como identificar? TCU: Naïve Bayes.
imposto a mais. ¤ Nesses casos pode-se pedir compensação. ¤ Mas nem sempre a compensação é devida. ¤ Como identificar? Receita Federal: regressão logística, Naïve Bayes, árvores de decisão.
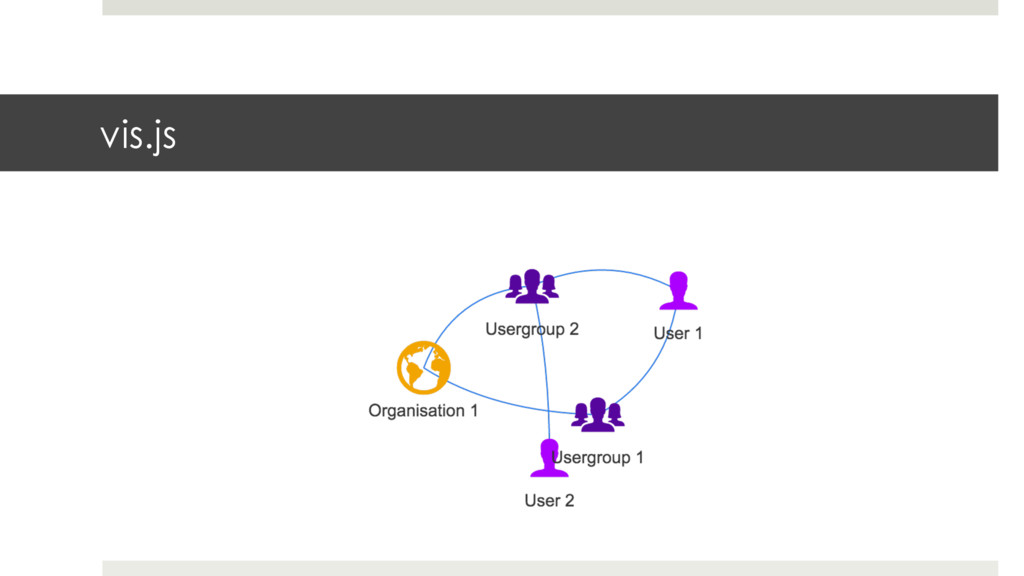
X? ¤ Qual a participação total da empresa X na empresa Y, incluindo participações diretas (X→Y) e indiretas (X → Z → Y)? ¤ Quais as pessoas a quem a pessoa X está vinculada (via emprego ou sociedade) c/ até 3 graus de separação? ¤ Neo4j é mais rápido que SQL Server p/ esse tipo de consulta. E as queries são mais simples de escrever.
si. ¤ Nem mesmo quando os dados são públicos (!). ¤ “Ok, mas só se firmarmos um convênio”. ¤ “Ok, mas a extração custa R$ 39.844.095.098.490.802.984.309.582.304”. ¤ “Como assim você queria os dados atualizados?” ¤ “Como assim você queria todos os dados?”
– ComprasNet – não tem documentação. ¤ Mito: “ciência de dados é 80% pré-processamento e 20% modelagem”. ¤ Realidade: ciência de dados é 80% tentando entender que diabo cada atributo é e 20% pré-processamento e modelagem. ¤ “Quem tinha essa documentação era o Zé das Couves mas ele se aposentou...”
como float. ¤ DD/MM/AA, MM/DD/AA, AA/MM/DD na mesma coluna. ¤ -9, -1, -999, etc, como missing data (acaba entrando no cálculo das médias) ¤ ... e assim por diante
mas é a norma no governo federal. ¤ Especialmente p/ quem escreve código: ¤ leva ~25 minutos p/ retomar a produtividade após uma interrupção ¤ http://thetomorrowlab.com/2015/01/why-developers-hate-being-interrupted/ ¤ http://swizec.com/blog/why-programmers-work-at-night/swizec/3198 ¤ http://paulgraham.com/head.html ¤ http://tosbourn.com/a-pragmatic-approach-to-dealing-with-interruption-whilst- you-are-developing/ ¤ http://blog.ninlabs.com/2013/01/programmer-interrupted/ ¤ http://blog.fogcreek.com/protecting-developer-time-with-cases-not-chat/
semanas não dá em nada. ¤ Muitos falsos positivos, muitos falsos negativos, o problema deixou de ser relevante, etc. ¤ É difícil estimar prazos (finais ou intermediários). ¤ Chefia precisa estar ok com isso. ¤ Mas mais importante: é preciso poder errar perante os colegas. ¤ “psychological safety” ¤ http://www.nytimes.com/2016/02/28/magazine/what-google-learned-from-its- quest-to-build-the-perfect-team.html
órgãos? Cidadão? ¤ Usuário não está pagando pelo serviço, então tem menos propensão a dar feedback. ¤ Não dá pra ouvir o usuário só final, depois que o app levou meses p/ ser desenvolvido e o órgão gastou $$$$$. ¤ Difícil lição: data product bacana != data product útil ¤ “fator uau” não prediz sucesso de funcionalidade ¤ CÉREBRO: grafo gravitacional na visualização de redes societárias ¤ usuário: “pq essas bolinhas ficam dançando na minha frente??”
¤ estatística/mineração & desenvolvimento de software & domínio do negócio ¤ Recrutamento é engessado no serviço público. ¤ salários não são negociáveis ¤ concurso premia quem decora leis ¤ Paliativos: ¤ negociar fringe benefits (horário flexível, trabalho remoto, capacitação) ¤ PNUD ¤ terceirização
nobre. ¤ Às vezes um algoritmo bobo pode resultar numa economia de milhões… ¤ ... ou mandar vários larápios p/ a cadeia. ¤ Há muita gente boa e empolgada fazendo mineração de dados no governo federal. ¤ Apoio institucional tem crescido.
tudo são carimbos e papelório. ¤ Áreas do governo federal que fazem mineração de dados: CGU, TCU, Receita Federal, CADE, Polícia Federal, (outros?). ¤ http://www.brasildigital.gov.br/ ¤ É preciso expandir p/ áreas não-punitivas: saúde, educação, meio- ambiente... ¤ Você pode contribuir: dados.gov.br
Despesa Pública da CGU. ¤ Professor de estatística e mineração de dados (thiagomarzagao.com/teaching). ¤ Pesquisador (thiagomarzagao.com/papers). ¤ Entusiasta de LEGO Mindstorms (github.com/thiagomarzagao/ev3py). ¤ EPPGG, Ex-Ohio State University. ¤ [email protected], @tmarzagao
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Neo4j MATCH (n)-[r*1..3]-(m) WHERE (n.CPF IN ['01234567890']) RETURN r](https://files.speakerdeck.com/presentations/df7b6e3b4f724dfb923f8ad5e6444e2f/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}