Not Only SQL - warum nicht immer SQL einsetzen? 3 Datenmodelle 4 CouchDB 5 Herausforderungen und Kritik K. Puschke (FU Berlin) NoSQL 13. September 2010 3 / 55
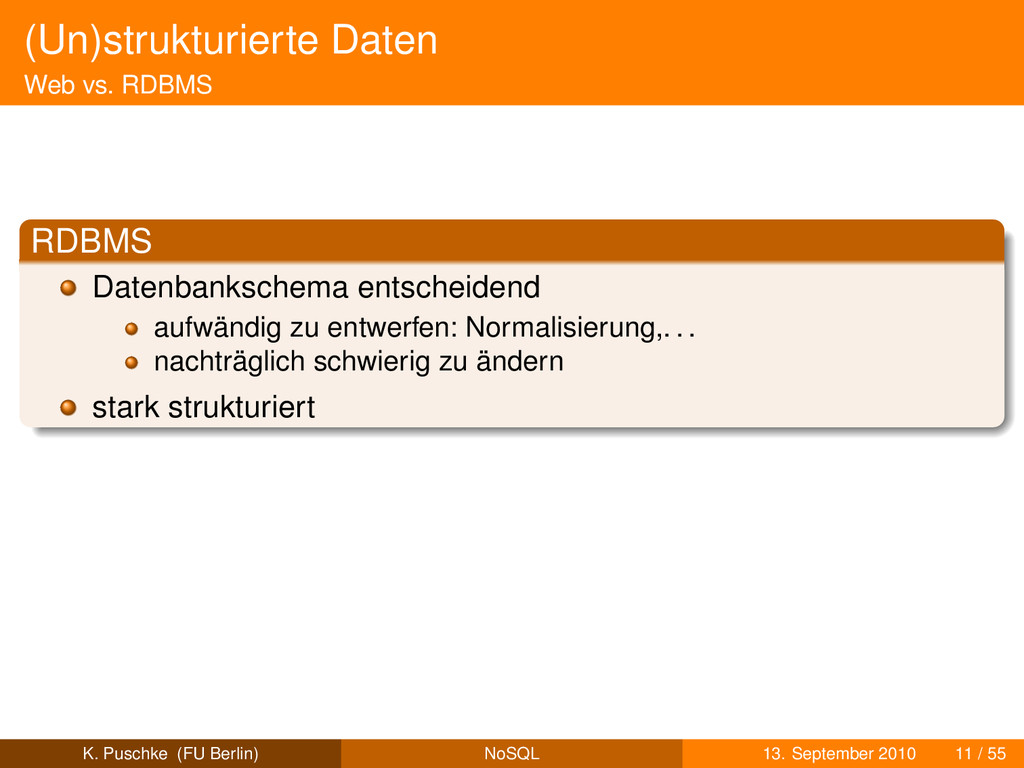
Regeln (1985) [4, 5] Vollständigkeit im Sinne der relationalen Algebra in der Praxis und im Kontext des Vortrags K. Puschke (FU Berlin) NoSQL 13. September 2010 4 / 55
Regeln (1985) [4, 5] Vollständigkeit im Sinne der relationalen Algebra in der Praxis und im Kontext des Vortrags zeilenbasierte Speicherung in Tabellen K. Puschke (FU Berlin) NoSQL 13. September 2010 4 / 55
Regeln (1985) [4, 5] Vollständigkeit im Sinne der relationalen Algebra in der Praxis und im Kontext des Vortrags zeilenbasierte Speicherung in Tabellen SQL oder vergleichbare Sprache K. Puschke (FU Berlin) NoSQL 13. September 2010 4 / 55
Regeln (1985) [4, 5] Vollständigkeit im Sinne der relationalen Algebra in der Praxis und im Kontext des Vortrags zeilenbasierte Speicherung in Tabellen SQL oder vergleichbare Sprache z.B. MySQL, Postgres, Oracle,. . . K. Puschke (FU Berlin) NoSQL 13. September 2010 4 / 55
Systeme (Sybase IQ) dokumentenorientierte Systeme (Lotus Notes) kaum Verbreitung im Vergleich zu relationalen Systemen K. Puschke (FU Berlin) NoSQL 13. September 2010 5 / 55
Systeme (Sybase IQ) dokumentenorientierte Systeme (Lotus Notes) kaum Verbreitung im Vergleich zu relationalen Systemen frühe Formen von NoSQL? K. Puschke (FU Berlin) NoSQL 13. September 2010 5 / 55
. era of “one-size-fits-all database” seems to be over. Instead of squeezing all your data into tables, we believe the future is about choosing a data store that best matches your data set and operational requirements. K. Puschke (FU Berlin) NoSQL 13. September 2010 8 / 55
. era of “one-size-fits-all database” seems to be over. Instead of squeezing all your data into tables, we believe the future is about choosing a data store that best matches your data set and operational requirements. It’s a future of heterogeneous data backends, polyglot persistence and choosing Not Only SQL but sometimes also a document database, a key-value store or a graph database. K. Puschke (FU Berlin) NoSQL 13. September 2010 8 / 55
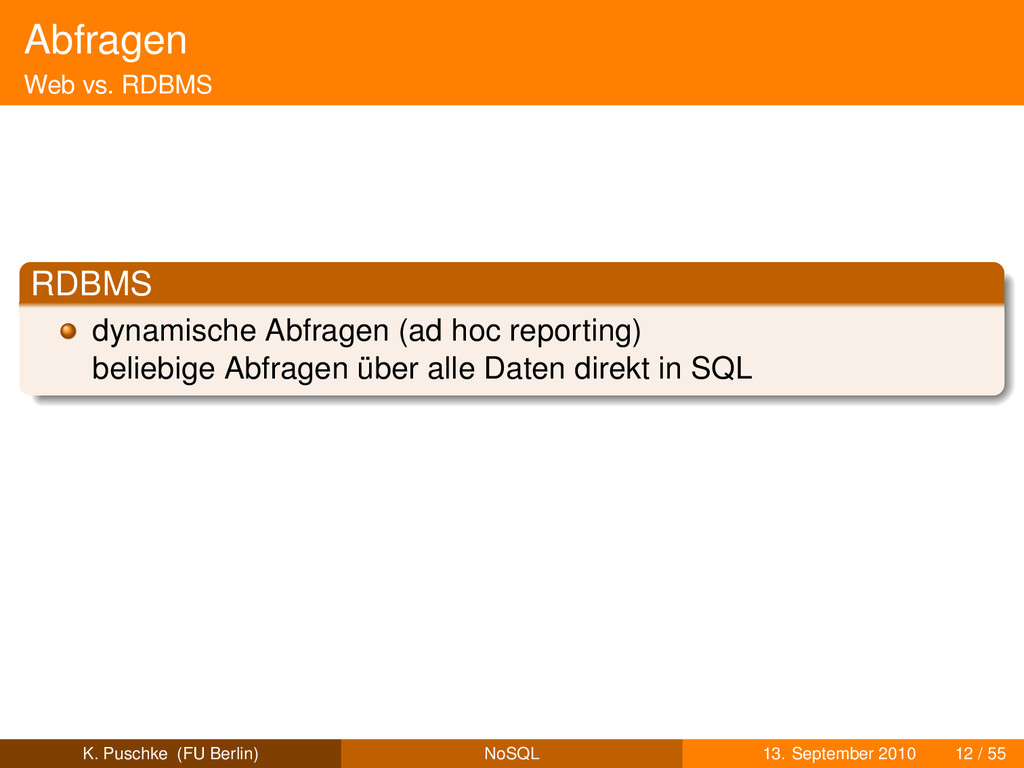
nicht immer SQL einsetzen? Web vs. RDBMS Verteilte Systeme NoSQL vs. SQL 3 Datenmodelle 4 CouchDB 5 Herausforderungen und Kritik K. Puschke (FU Berlin) NoSQL 13. September 2010 10 / 55
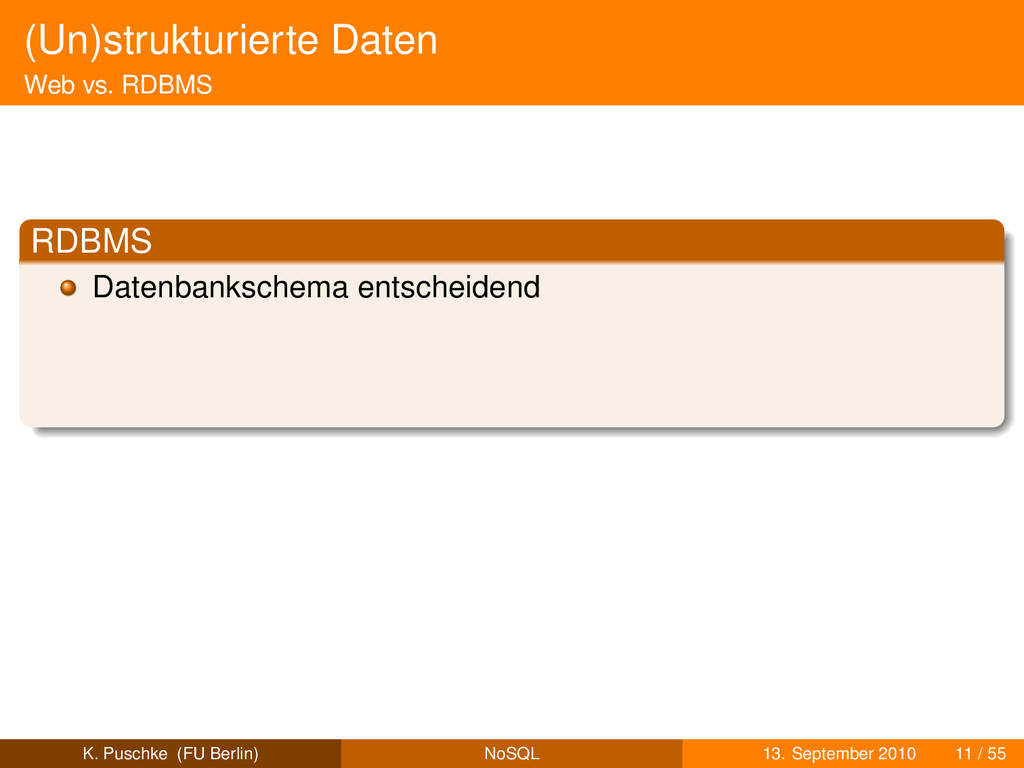
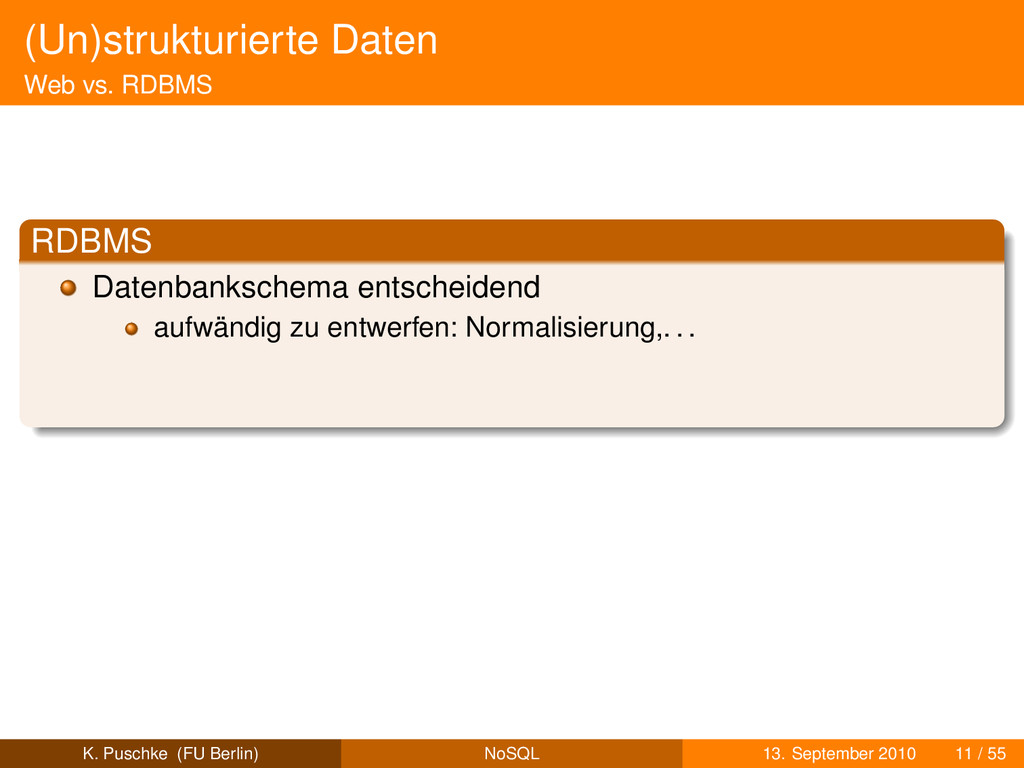
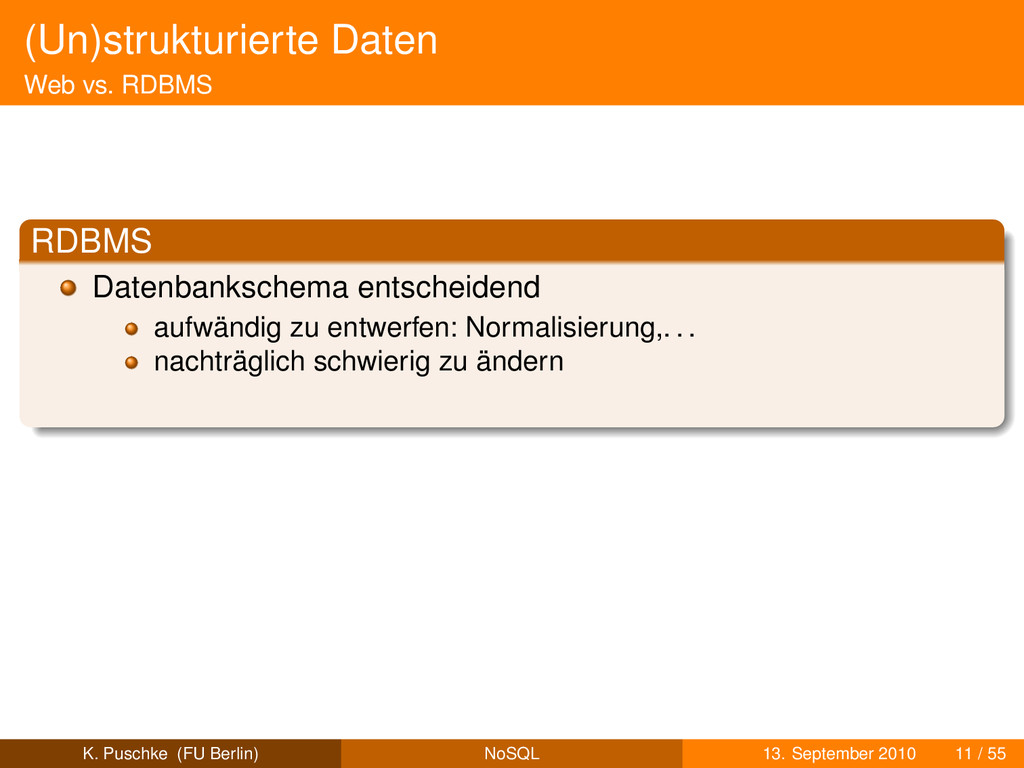
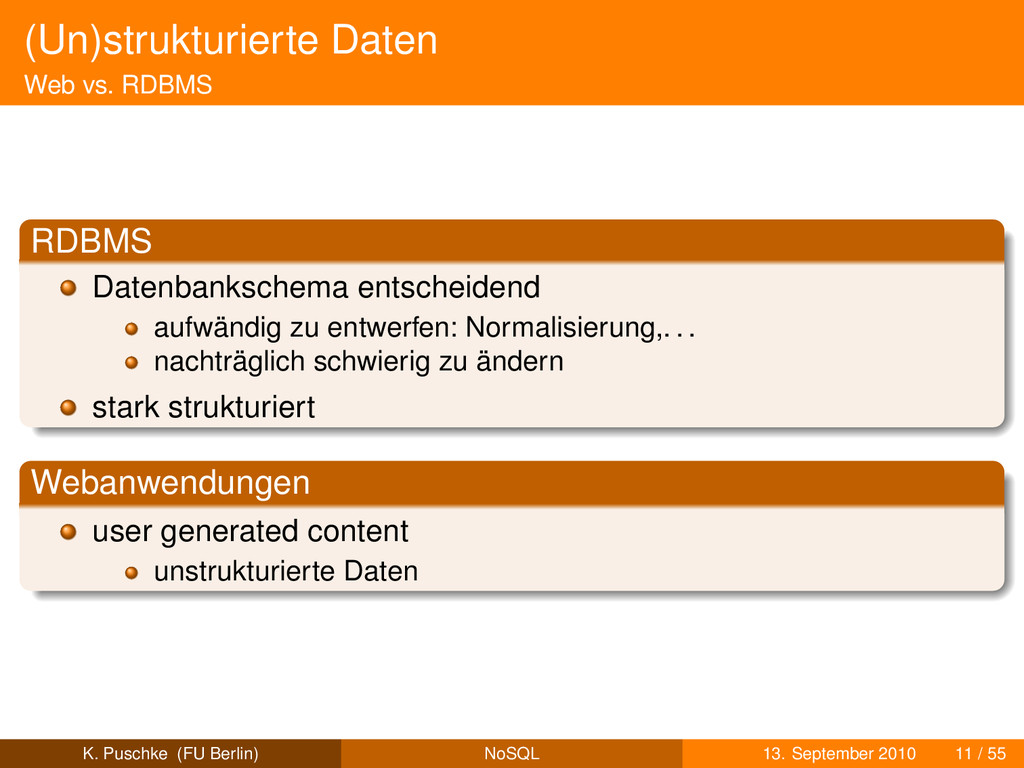
entwerfen: Normalisierung,. . . nachträglich schwierig zu ändern stark strukturiert Webanwendungen user generated content K. Puschke (FU Berlin) NoSQL 13. September 2010 11 / 55
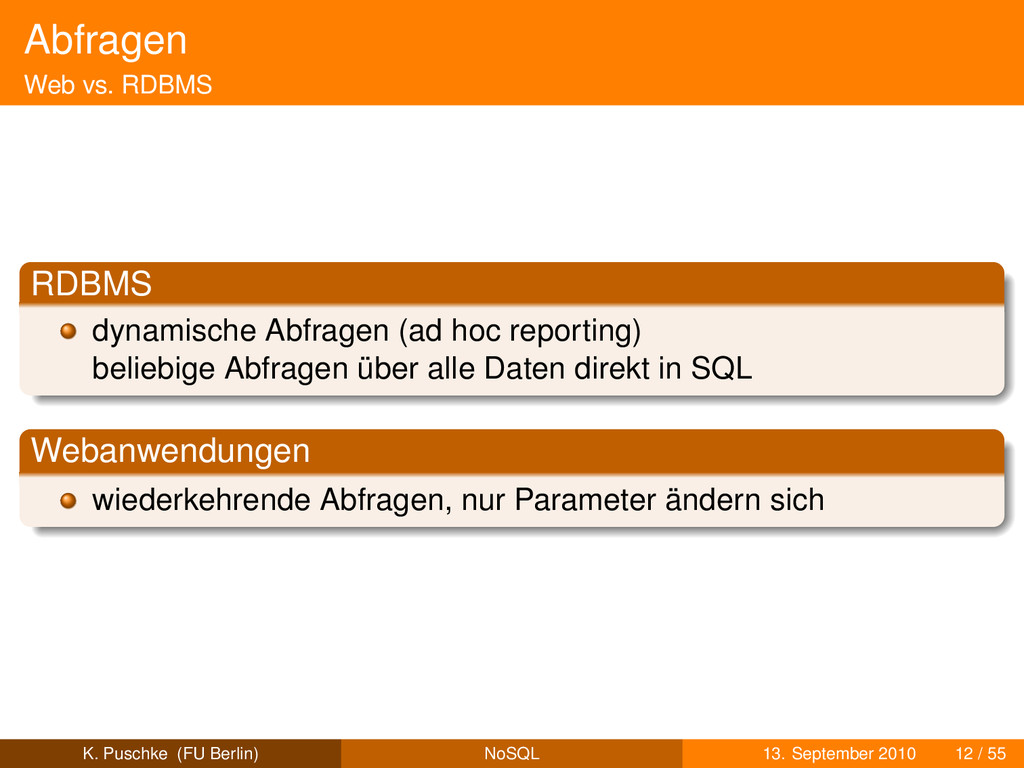
beliebige Abfragen über alle Daten direkt in SQL Webanwendungen wiederkehrende Abfragen, nur Parameter ändern sich K. Puschke (FU Berlin) NoSQL 13. September 2010 12 / 55
about 6 petabytes of data spread across thousands of machines Jeff Dean, Google I/O conference, Mai 2008 (Shankland [14]) K. Puschke (FU Berlin) NoSQL 13. September 2010 13 / 55
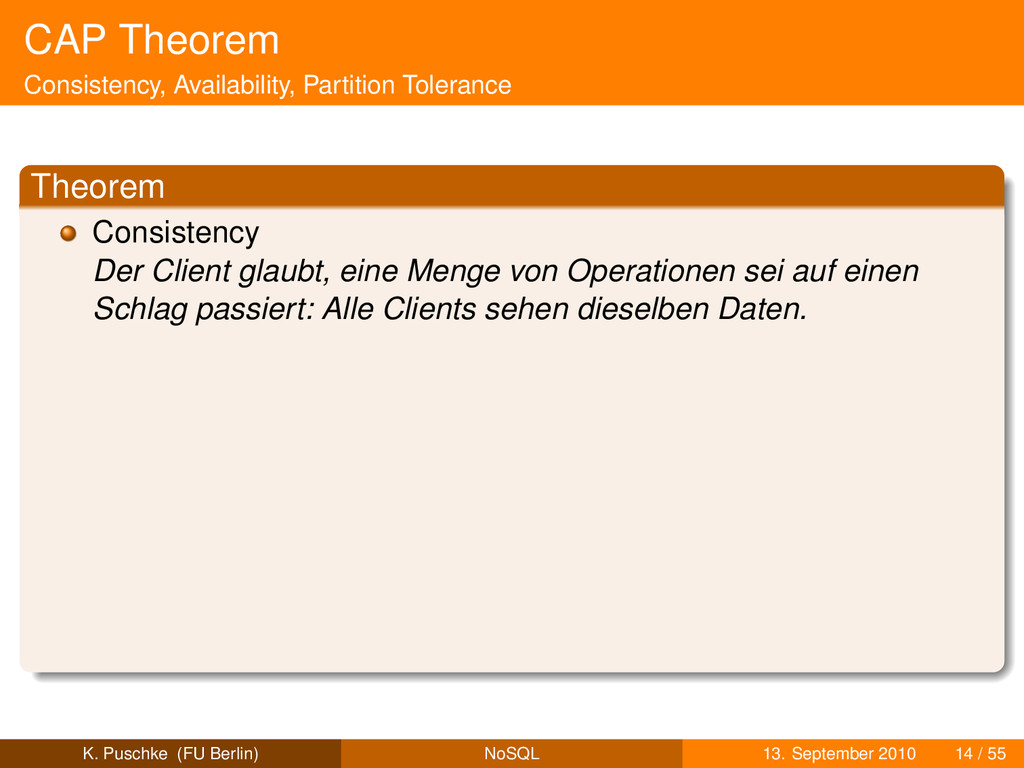
glaubt, eine Menge von Operationen sei auf einen Schlag passiert: Alle Clients sehen dieselben Daten. K. Puschke (FU Berlin) NoSQL 13. September 2010 14 / 55
glaubt, eine Menge von Operationen sei auf einen Schlag passiert: Alle Clients sehen dieselben Daten. Availability Jede Operation endet mit einer bestimmungsgemäßen Antwort: Alle Clients können auf eine Version der Daten zugreifen. K. Puschke (FU Berlin) NoSQL 13. September 2010 14 / 55
glaubt, eine Menge von Operationen sei auf einen Schlag passiert: Alle Clients sehen dieselben Daten. Availability Jede Operation endet mit einer bestimmungsgemäßen Antwort: Alle Clients können auf eine Version der Daten zugreifen. Partition Tolerance Operationen werden zu Ende geführt, auch wenn die Datenbank partitioniert ist. K. Puschke (FU Berlin) NoSQL 13. September 2010 14 / 55
glaubt, eine Menge von Operationen sei auf einen Schlag passiert: Alle Clients sehen dieselben Daten. Availability Jede Operation endet mit einer bestimmungsgemäßen Antwort: Alle Clients können auf eine Version der Daten zugreifen. Partition Tolerance Operationen werden zu Ende geführt, auch wenn die Datenbank partitioniert ist. Nur zwei der drei Eigenschaften sind gleichzeitig möglich! siehe Brewer [2] und Lynch & Gilbert [10] K. Puschke (FU Berlin) NoSQL 13. September 2010 14 / 55
abhängig von der Konfiguration - u.U. sogar pro Abfrage Network Partitioning oft unvermeidlich trade off: Consistency vs. Availability K. Puschke (FU Berlin) NoSQL 13. September 2010 15 / 55
abhängig von der Konfiguration - u.U. sogar pro Abfrage Network Partitioning oft unvermeidlich trade off: Consistency vs. Availability Abstufungen möglich K. Puschke (FU Berlin) NoSQL 13. September 2010 15 / 55
Verzicht auf Normalisierung Fokus auf Verfügbarkeit statt Konsistenz . . . dadurch aber Verlust vieler Vorteile, z.B. K. Puschke (FU Berlin) NoSQL 13. September 2010 17 / 55
Verzicht auf Normalisierung Fokus auf Verfügbarkeit statt Konsistenz . . . dadurch aber Verlust vieler Vorteile, z.B. Verlust von ACID-Garantien, K. Puschke (FU Berlin) NoSQL 13. September 2010 17 / 55
Verzicht auf Normalisierung Fokus auf Verfügbarkeit statt Konsistenz . . . dadurch aber Verlust vieler Vorteile, z.B. Verlust von ACID-Garantien, referentieller Integrität, K. Puschke (FU Berlin) NoSQL 13. September 2010 17 / 55
Verzicht auf Normalisierung Fokus auf Verfügbarkeit statt Konsistenz . . . dadurch aber Verlust vieler Vorteile, z.B. Verlust von ACID-Garantien, referentieller Integrität, . . . ggf. ein NoSQL-System die bessere Wahl K. Puschke (FU Berlin) NoSQL 13. September 2010 17 / 55
. spaltenorientierte Speicherung mehr Performanz für bestimmte Abfragen z.B. Aggregieren innerhalb einer Spalte K. Puschke (FU Berlin) NoSQL 13. September 2010 20 / 55
. spaltenorientierte Speicherung mehr Performanz für bestimmte Abfragen z.B. Aggregieren innerhalb einer Spalte flexibleres Schema Spalten dynamisch K. Puschke (FU Berlin) NoSQL 13. September 2010 20 / 55
. spaltenorientierte Speicherung mehr Performanz für bestimmte Abfragen z.B. Aggregieren innerhalb einer Spalte flexibleres Schema Spalten dynamisch keine ’echten’ Beziehungen K. Puschke (FU Berlin) NoSQL 13. September 2010 20 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) key K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) key identifiziert einen Eintrag in der column family K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) key identifiziert einen Eintrag in der column family wird bei Abfragen benutzt K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) key identifiziert einen Eintrag in der column family wird bei Abfragen benutzt keys sind lokal gleichnamige keys verschiedener column families sind verschieden K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) key identifiziert einen Eintrag in der column family wird bei Abfragen benutzt keys sind lokal gleichnamige keys verschiedener column families sind verschieden keine ’echten’ Beziehungen K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) key identifiziert einen Eintrag in der column family wird bei Abfragen benutzt keys sind lokal gleichnamige keys verschiedener column families sind verschieden keine ’echten’ Beziehungen column K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) key identifiziert einen Eintrag in der column family wird bei Abfragen benutzt keys sind lokal gleichnamige keys verschiedener column families sind verschieden keine ’echten’ Beziehungen column tupel (name, value, timestamp) K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
column family entspricht einer Datei Beispiel: ’Posts’ oder ’Users’ beliebig viele Einträge (key + columns) key identifiziert einen Eintrag in der column family wird bei Abfragen benutzt keys sind lokal gleichnamige keys verschiedener column families sind verschieden keine ’echten’ Beziehungen column tupel (name, value, timestamp) Beispiel: {name:username, value:foo, timestamp:12345} K. Puschke (FU Berlin) NoSQL 13. September 2010 21 / 55
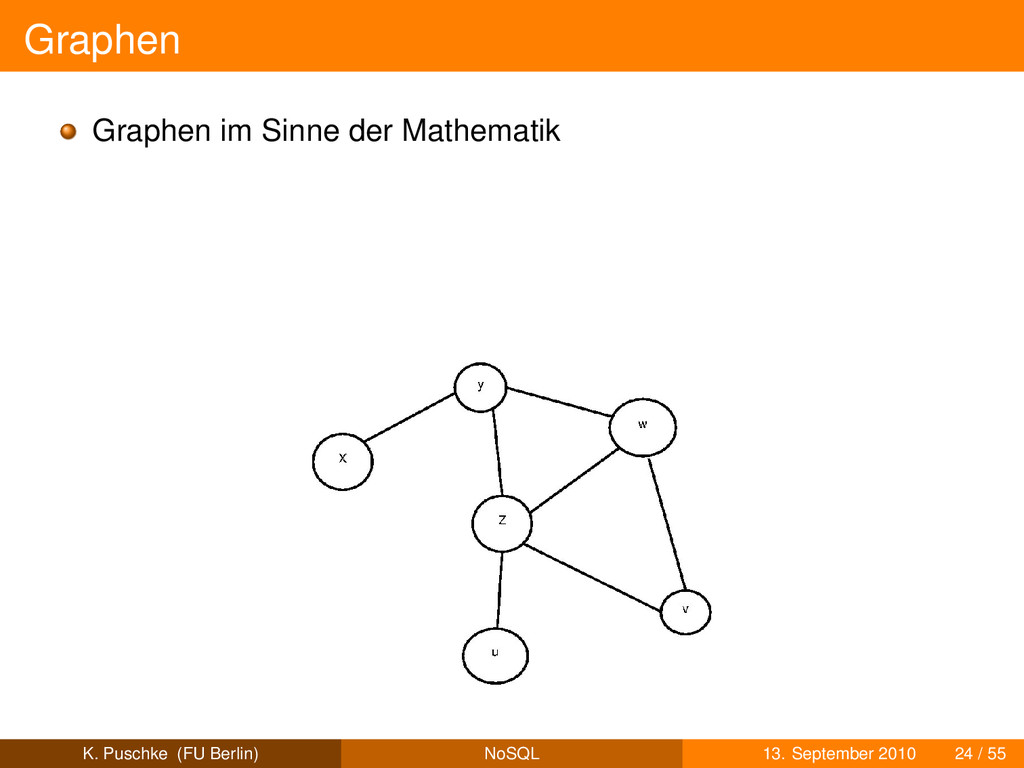
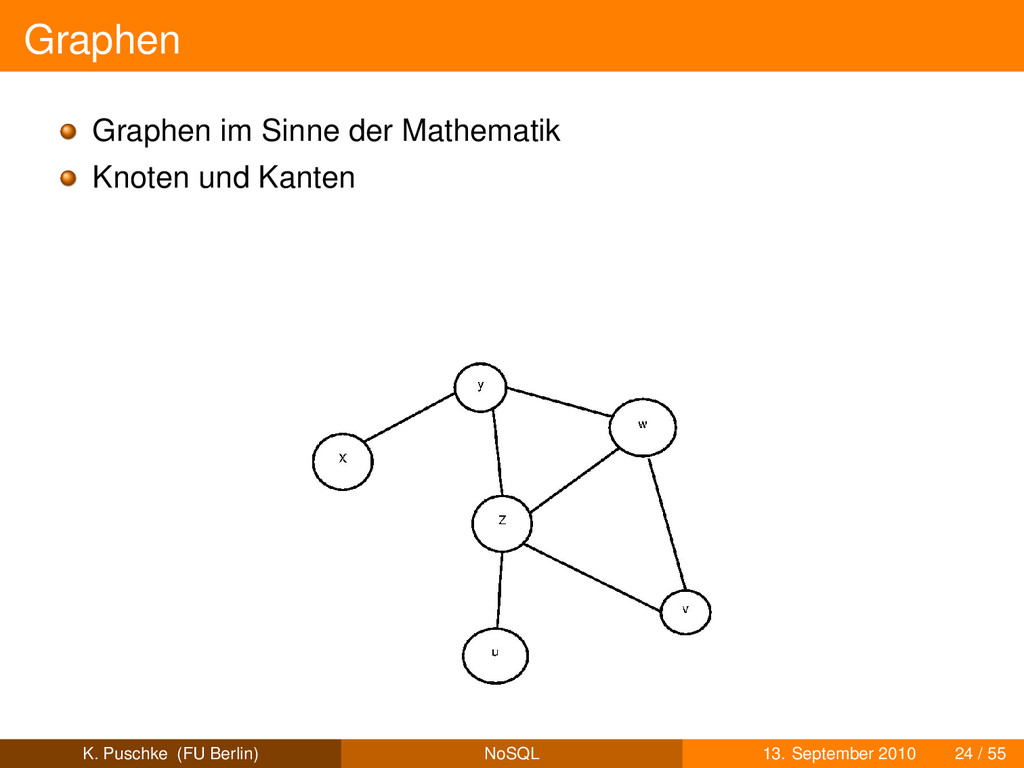
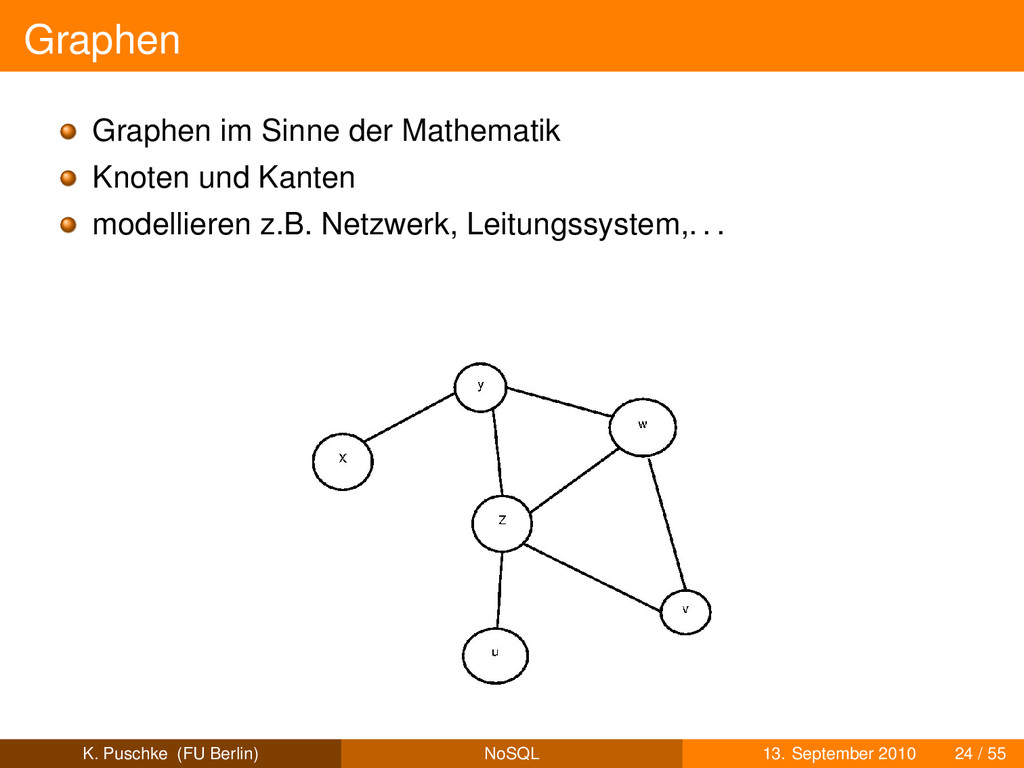
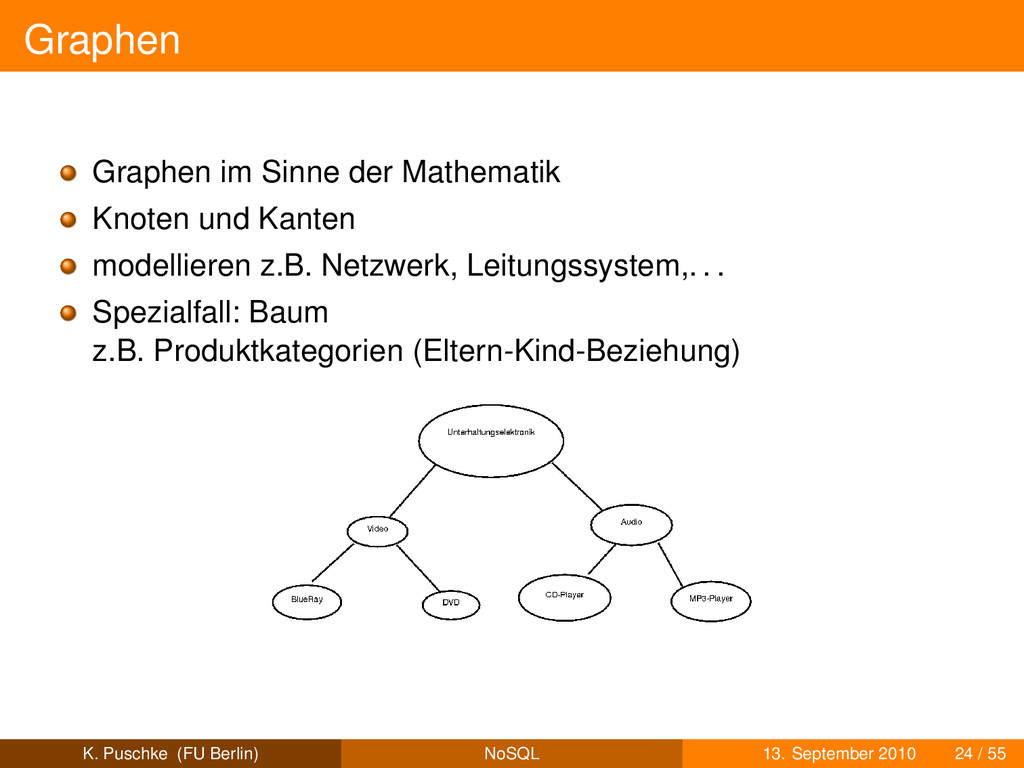
eigenständige Objekte wie Kunde, Bestellung,. . . Kanten sind Beziehungen zwischen Knoten schematisiert oder schemafrei K. Puschke (FU Berlin) NoSQL 13. September 2010 25 / 55
eigenständige Objekte wie Kunde, Bestellung,. . . Kanten sind Beziehungen zwischen Knoten schematisiert oder schemafrei Kanten sind “first class objects” K. Puschke (FU Berlin) NoSQL 13. September 2010 25 / 55
eigenständige Objekte wie Kunde, Bestellung,. . . Kanten sind Beziehungen zwischen Knoten schematisiert oder schemafrei Kanten sind “first class objects” häufige Operation: Traversierung K. Puschke (FU Berlin) NoSQL 13. September 2010 25 / 55
eigenständige Objekte wie Kunde, Bestellung,. . . Kanten sind Beziehungen zwischen Knoten schematisiert oder schemafrei Kanten sind “first class objects” häufige Operation: Traversierung gut geeignet für komplexe Beziehungsgeflechte z.B. social network K. Puschke (FU Berlin) NoSQL 13. September 2010 25 / 55
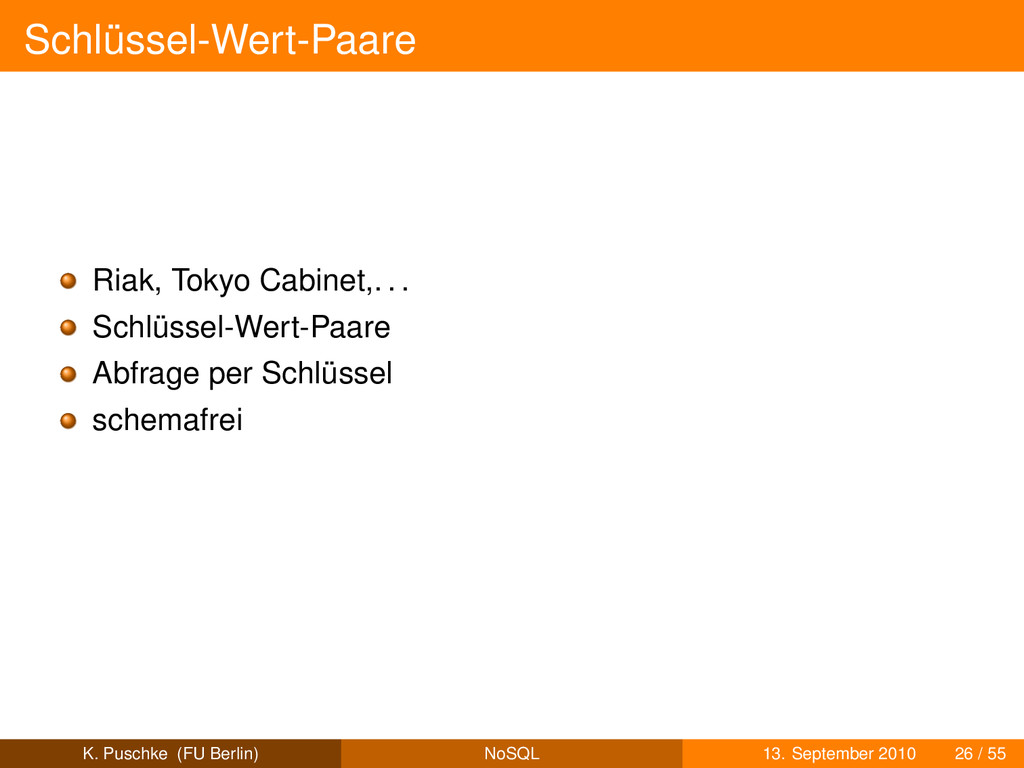
von Schlüssel-Wert-Paaren für sich genommen sinnvolle Informationseinheit meist Entsprechung im Real Life (Rechnung, Visitenkarte,. . . ) K. Puschke (FU Berlin) NoSQL 13. September 2010 27 / 55
von Schlüssel-Wert-Paaren für sich genommen sinnvolle Informationseinheit meist Entsprechung im Real Life (Rechnung, Visitenkarte,. . . ) üblicherweise kein leeren Felder K. Puschke (FU Berlin) NoSQL 13. September 2010 27 / 55
von Schlüssel-Wert-Paaren für sich genommen sinnvolle Informationseinheit meist Entsprechung im Real Life (Rechnung, Visitenkarte,. . . ) üblicherweise kein leeren Felder schemafrei K. Puschke (FU Berlin) NoSQL 13. September 2010 27 / 55
von Schlüssel-Wert-Paaren für sich genommen sinnvolle Informationseinheit meist Entsprechung im Real Life (Rechnung, Visitenkarte,. . . ) üblicherweise kein leeren Felder schemafrei keine ’echten’ Relationen K. Puschke (FU Berlin) NoSQL 13. September 2010 27 / 55
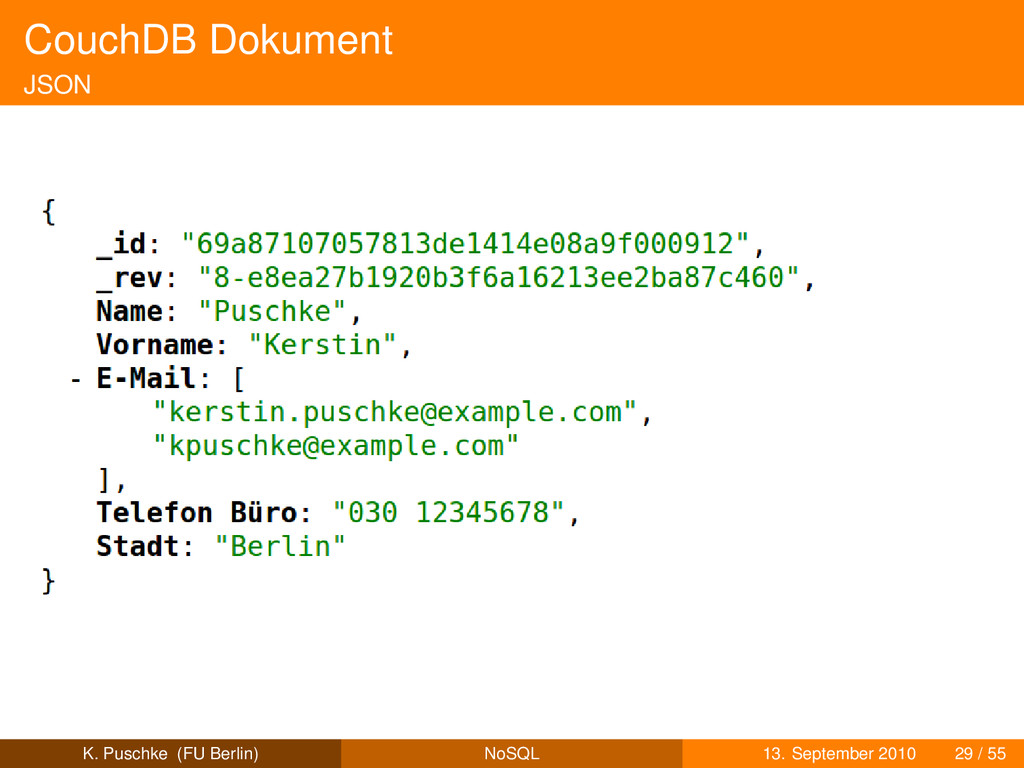
wird z.T. direkt vom Browser verstanden wenig Datentypen diese werden von nahezu allen Sprachen verstanden K. Puschke (FU Berlin) NoSQL 13. September 2010 28 / 55
wird z.T. direkt vom Browser verstanden wenig Datentypen diese werden von nahezu allen Sprachen verstanden Schlüssel-Wert-Paare K. Puschke (FU Berlin) NoSQL 13. September 2010 28 / 55
wird z.T. direkt vom Browser verstanden wenig Datentypen diese werden von nahezu allen Sprachen verstanden Schlüssel-Wert-Paare obligatorische Schlüssel: K. Puschke (FU Berlin) NoSQL 13. September 2010 28 / 55
wird z.T. direkt vom Browser verstanden wenig Datentypen diese werden von nahezu allen Sprachen verstanden Schlüssel-Wert-Paare obligatorische Schlüssel: _id zur eindeutigen Identifikation des Dokumentes (UUID), K. Puschke (FU Berlin) NoSQL 13. September 2010 28 / 55
wird z.T. direkt vom Browser verstanden wenig Datentypen diese werden von nahezu allen Sprachen verstanden Schlüssel-Wert-Paare obligatorische Schlüssel: _id zur eindeutigen Identifikation des Dokumentes (UUID), _rev zur Versionierung des Dokumentes K. Puschke (FU Berlin) NoSQL 13. September 2010 28 / 55
wird z.T. direkt vom Browser verstanden wenig Datentypen diese werden von nahezu allen Sprachen verstanden Schlüssel-Wert-Paare obligatorische Schlüssel: _id zur eindeutigen Identifikation des Dokumentes (UUID), _rev zur Versionierung des Dokumentes Dokumente können Attachments haben K. Puschke (FU Berlin) NoSQL 13. September 2010 28 / 55
auf unzuverlässiger Standardhardware Datenbanksystem (nicht nur) für Webanwendungen offene Webstandards Robuste Replikation schemafrei geeignet für unstrukturierte Daten Philosophie: entspanntes Arbeiten keine Entscheidungen, die nicht zu revidieren sind K. Puschke (FU Berlin) NoSQL 13. September 2010 31 / 55
[16] Erlang funktional, fehlertolerant, concurrency optimiert Viewserver in JavaScript (Indizes erstellen) alternativ via Plugins auch PHP, Ruby, Python, Perl, Common Lisp, Erlang,. . . K. Puschke (FU Berlin) NoSQL 13. September 2010 32 / 55
[16] Erlang funktional, fehlertolerant, concurrency optimiert Viewserver in JavaScript (Indizes erstellen) alternativ via Plugins auch PHP, Ruby, Python, Perl, Common Lisp, Erlang,. . . dokumentenbasierte Speicherung (JSON) Datenbank und Indizes als B-Tree gespeichert K. Puschke (FU Berlin) NoSQL 13. September 2010 32 / 55
[16] Erlang funktional, fehlertolerant, concurrency optimiert Viewserver in JavaScript (Indizes erstellen) alternativ via Plugins auch PHP, Ruby, Python, Perl, Common Lisp, Erlang,. . . dokumentenbasierte Speicherung (JSON) Datenbank und Indizes als B-Tree gespeichert eventual consistency (in verteilten Systemen) K. Puschke (FU Berlin) NoSQL 13. September 2010 32 / 55
[16] Erlang funktional, fehlertolerant, concurrency optimiert Viewserver in JavaScript (Indizes erstellen) alternativ via Plugins auch PHP, Ruby, Python, Perl, Common Lisp, Erlang,. . . dokumentenbasierte Speicherung (JSON) Datenbank und Indizes als B-Tree gespeichert eventual consistency (in verteilten Systemen) Storage Engine: ACID (lokal), optimistic locking, Multi Version Concurrency Control K. Puschke (FU Berlin) NoSQL 13. September 2010 32 / 55
Master-Slave,. . . Hot failover, backup, Lastverteilung,. . . extrem robust vermeidet die Fallacies of Distributed Computing K. Puschke (FU Berlin) NoSQL 13. September 2010 33 / 55
eines Dokumentes wird an Datenbankdatei angehängt Robust: was einmal auf Platte steht, wird nicht mehr angefaßt K. Puschke (FU Berlin) NoSQL 13. September 2010 34 / 55
eines Dokumentes wird an Datenbankdatei angehängt Robust: was einmal auf Platte steht, wird nicht mehr angefaßt Geschwindigkeit: neue Version kann angehängt werden, während alte noch gelesen wird K. Puschke (FU Berlin) NoSQL 13. September 2010 34 / 55
mit unveränderter Versionsnummer _rev Server prüft, ob diese _rev identisch ist mit der aktuell gespeicherten K. Puschke (FU Berlin) NoSQL 13. September 2010 35 / 55
mit unveränderter Versionsnummer _rev Server prüft, ob diese _rev identisch ist mit der aktuell gespeicherten wenn ja: Dokument wird gespeichert (Server vergibt neue _rev) K. Puschke (FU Berlin) NoSQL 13. September 2010 35 / 55
mit unveränderter Versionsnummer _rev Server prüft, ob diese _rev identisch ist mit der aktuell gespeicherten wenn ja: Dokument wird gespeichert (Server vergibt neue _rev) wenn nein: Konflikt K. Puschke (FU Berlin) NoSQL 13. September 2010 35 / 55
mit unveränderter Versionsnummer _rev Server prüft, ob diese _rev identisch ist mit der aktuell gespeicherten wenn ja: Dokument wird gespeichert (Server vergibt neue _rev) wenn nein: Konflikt keine Versionskontrolle es werden nicht alle Versionen aufbewahrt K. Puschke (FU Berlin) NoSQL 13. September 2010 35 / 55
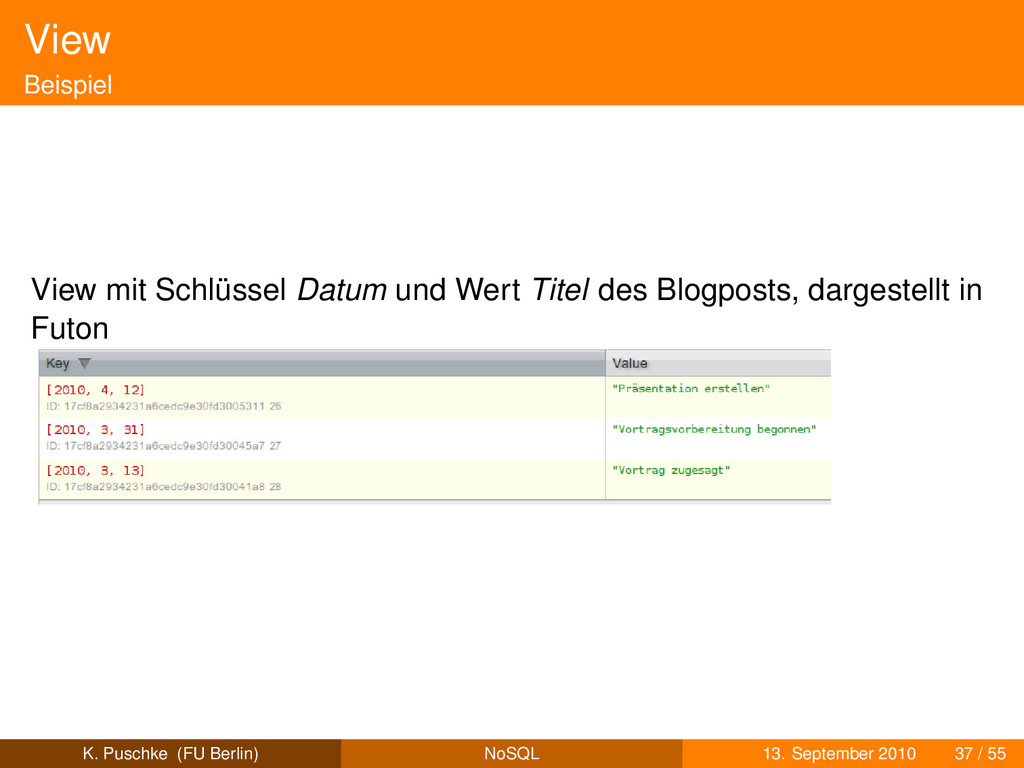
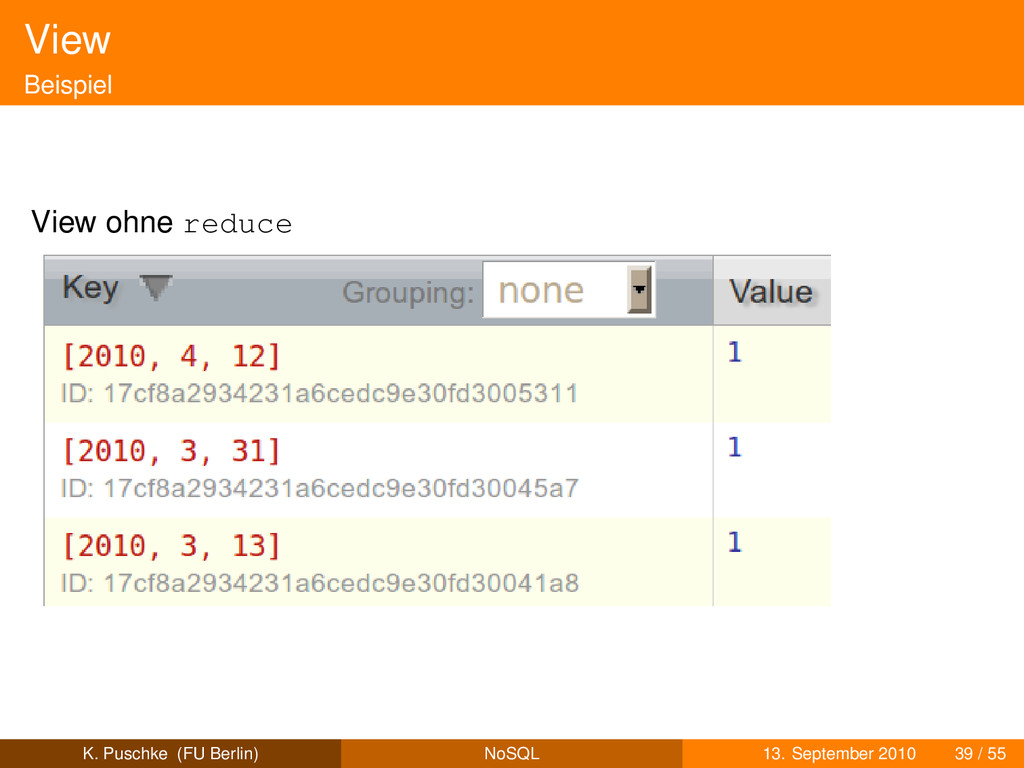
Werte aus Dokumenten Beispiel: Erstellungsdaten als Schlüssel, Blogposttitel als Werte können auch arrays von Werten (aus Dokumenten) sein K. Puschke (FU Berlin) NoSQL 13. September 2010 36 / 55
Werte aus Dokumenten Beispiel: Erstellungsdaten als Schlüssel, Blogposttitel als Werte können auch arrays von Werten (aus Dokumenten) sein Werte (im View) können auch aggregierte Werte (aus Dokumenten) sein K. Puschke (FU Berlin) NoSQL 13. September 2010 36 / 55
Werte aus Dokumenten Beispiel: Erstellungsdaten als Schlüssel, Blogposttitel als Werte können auch arrays von Werten (aus Dokumenten) sein Werte (im View) können auch aggregierte Werte (aus Dokumenten) sein sortiert nach Schlüsseln K. Puschke (FU Berlin) NoSQL 13. September 2010 36 / 55
Werte aus Dokumenten Beispiel: Erstellungsdaten als Schlüssel, Blogposttitel als Werte können auch arrays von Werten (aus Dokumenten) sein Werte (im View) können auch aggregierte Werte (aus Dokumenten) sein sortiert nach Schlüsseln effizientes Abfragen nach bestimmten Schlüsseln oder Bereichen von Schlüsseln ’Titel aller Blogposts von Mai 2009’ K. Puschke (FU Berlin) NoSQL 13. September 2010 36 / 55
Werte aus Dokumenten Beispiel: Erstellungsdaten als Schlüssel, Blogposttitel als Werte können auch arrays von Werten (aus Dokumenten) sein Werte (im View) können auch aggregierte Werte (aus Dokumenten) sein sortiert nach Schlüsseln effizientes Abfragen nach bestimmten Schlüsseln oder Bereichen von Schlüsseln ’Titel aller Blogposts von Mai 2009’ zur Abfragezeit erzeugt/aktualisiert durch MapReduce K. Puschke (FU Berlin) NoSQL 13. September 2010 36 / 55
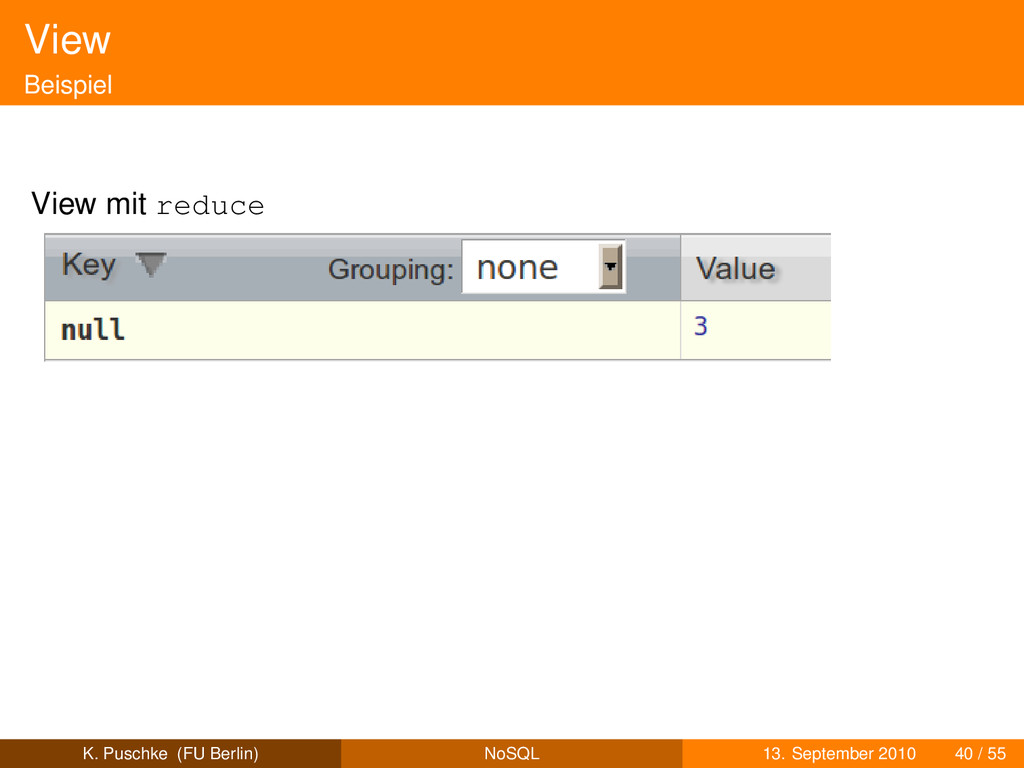
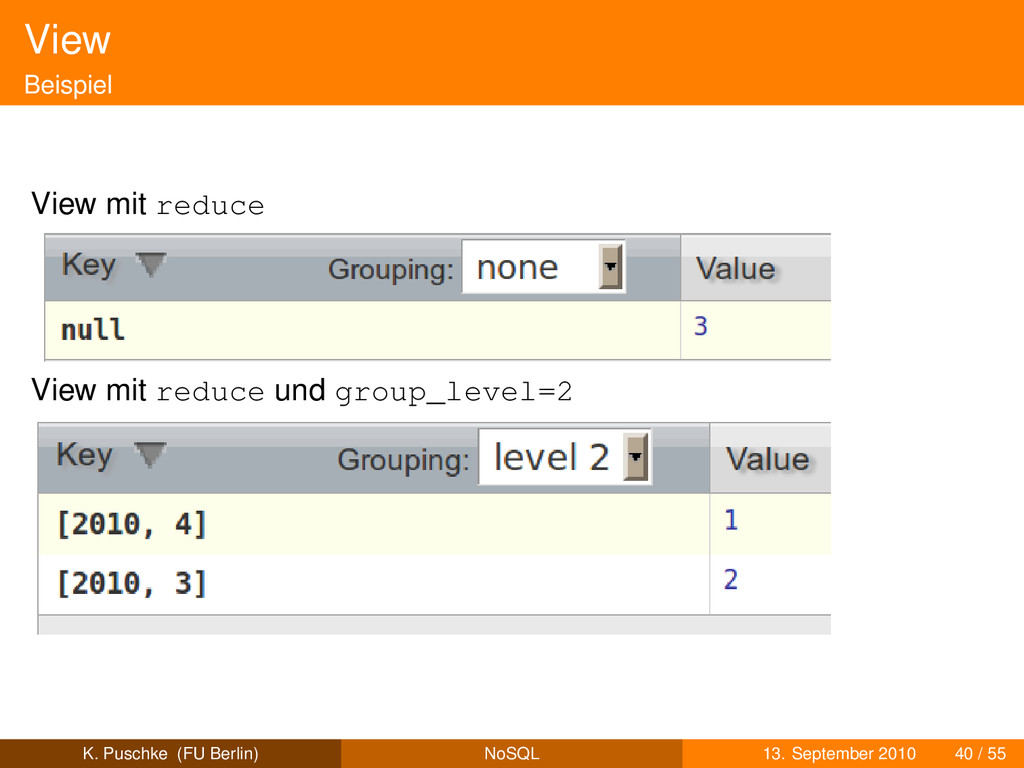
der funktionalen Programmierung parallele Verarbeitung großer Datenmengen MapReduce: framework zur verteilten Verarbeitung großer Datenmengen (freie Implementierung: Hadoop)siehe Dean & Ghemawat [6] map verarbeitet Dokumente erzeugt Schlüssel-Wert-Paare optionales reduce erzeugt aggregierte (Zwischen)Werte verarbeitet Ergebnisse von map oder rekursiv Zwischenergebnisse von reduce group: anwenden auf Objekte mit gleichem Schlüssel Beispiel: nicht alle Blogposts zählen, sondern Blogposts pro Tag K. Puschke (FU Berlin) NoSQL 13. September 2010 38 / 55
der funktionalen Programmierung parallele Verarbeitung großer Datenmengen MapReduce: framework zur verteilten Verarbeitung großer Datenmengen (freie Implementierung: Hadoop)siehe Dean & Ghemawat [6] map verarbeitet Dokumente erzeugt Schlüssel-Wert-Paare optionales reduce erzeugt aggregierte (Zwischen)Werte verarbeitet Ergebnisse von map oder rekursiv Zwischenergebnisse von reduce group: anwenden auf Objekte mit gleichem Schlüssel Beispiel: nicht alle Blogposts zählen, sondern Blogposts pro Tag Map-Reduce-Funktionen gespeichert in Dokumenten (Designdokumente) K. Puschke (FU Berlin) NoSQL 13. September 2010 38 / 55
Map-Reduce-Funktionen für Views Validation: Zulässigkeit von Updates input prüfen, nur eingeloggte user,. . . K. Puschke (FU Berlin) NoSQL 13. September 2010 41 / 55
Map-Reduce-Funktionen für Views Validation: Zulässigkeit von Updates input prüfen, nur eingeloggte user,. . . serverseitige Bearbeitung vor dem Speichern eines Dokumentes K. Puschke (FU Berlin) NoSQL 13. September 2010 41 / 55
Map-Reduce-Funktionen für Views Validation: Zulässigkeit von Updates input prüfen, nur eingeloggte user,. . . serverseitige Bearbeitung vor dem Speichern eines Dokumentes Show/List: JSON in HTML, XML,. . . konvertieren K. Puschke (FU Berlin) NoSQL 13. September 2010 41 / 55
middleware Show/List-Funktionen Attachments (HTML,CSS, Javascript) direkt ausliefern Ausgelieferte Webseite greift per Javascript/HTTP auf CouchDB zu K. Puschke (FU Berlin) NoSQL 13. September 2010 43 / 55
middleware Show/List-Funktionen Attachments (HTML,CSS, Javascript) direkt ausliefern Ausgelieferte Webseite greift per Javascript/HTTP auf CouchDB zu Replikation: update, fork, backup von Anwendungen K. Puschke (FU Berlin) NoSQL 13. September 2010 43 / 55
lokal beim user offline verfügbar lokale Datenhaltung = niedrige Latenz dezentral (gefilterte) Replikation mit anderen usern K. Puschke (FU Berlin) NoSQL 13. September 2010 44 / 55
bestehen kein ad hoc reporting BASE vs. ACID Zuverlässigkeit z.B. bei Finanztransaktionen Zweifel am Geschwindigkeitsvorteil von NoSQL-Systemen Stonebraker et al. [15], siehe auch Lai [9] und Pavlo et al. [12] K. Puschke (FU Berlin) NoSQL 13. September 2010 47 / 55
bestehen kein ad hoc reporting BASE vs. ACID Zuverlässigkeit z.B. bei Finanztransaktionen Zweifel am Geschwindigkeitsvorteil von NoSQL-Systemen Stonebraker et al. [15], siehe auch Lai [9] und Pavlo et al. [12] CouchApps und Co: Verteilte Identitäten K. Puschke (FU Berlin) NoSQL 13. September 2010 47 / 55
bestehen kein ad hoc reporting BASE vs. ACID Zuverlässigkeit z.B. bei Finanztransaktionen Zweifel am Geschwindigkeitsvorteil von NoSQL-Systemen Stonebraker et al. [15], siehe auch Lai [9] und Pavlo et al. [12] CouchApps und Co: Verteilte Identitäten serverseitiger Code nötig für Authentifizierung/Autorisierung K. Puschke (FU Berlin) NoSQL 13. September 2010 47 / 55
bestehen kein ad hoc reporting BASE vs. ACID Zuverlässigkeit z.B. bei Finanztransaktionen Zweifel am Geschwindigkeitsvorteil von NoSQL-Systemen Stonebraker et al. [15], siehe auch Lai [9] und Pavlo et al. [12] CouchApps und Co: Verteilte Identitäten serverseitiger Code nötig für Authentifizierung/Autorisierung vertrauenswürdiger Server nötig K. Puschke (FU Berlin) NoSQL 13. September 2010 47 / 55
the rules? ComputerWorld, Oktober 1985. Edgar F. Codd. Is your dbms really relational? ComputerWorld, Oktober 1985. Jeffrey Dean and Sanjay Ghemawat. Mapreduce: Simplified data processing on large clusters. In Sixth Symposium on Operating System Design and Implementation. 2004. URL http://labs.google.com/papers/mapreduce.html. K. Puschke (FU Berlin) NoSQL 13. September 2010 50 / 55
In Proceedings of the 7th International Conference on Very Large Databases, pages 144–154. 1981. Theo Haerder and Andreas Reuter. Principles of transaction-oriented database recovery. ACM Computing Surveys, 15:287–317, 1983. Eric Lai. Researchers: Databases still beat google’s mapreduce. Computer World, April 2009. URL http://www.computerworld.com/s/article/ 9131526/Researchers_Databases_still_beat_Google_ s_MapReduce. K. Puschke (FU Berlin) NoSQL 13. September 2010 51 / 55
Abadi, David J. Dewitt, Samuel Madden, and Michael Stonebraker. A comparison of approaches to large-scale data analysis. In SIGMOD ’09: Proceedings of the 2009 ACM SIGMOD International Conference. ACM, June 2009. URL http://database.cs.brown.edu/sigmod09/ benchmarks-sigmod09.pdf. Dan Pritchett. Base: An acid alternative. ACM Queue, 6(3):48–55, 2008. URL http://queue.acm.org/detail.cfm?id=1394128. K. Puschke (FU Berlin) NoSQL 13. September 2010 53 / 55
cnet news, Mai 2008. URL http://news.cnet.com/8301-10784_3-9955184-7.html. Michael Stonebraker, Daniel Abadi, David J. DeWitt, Sam Madden, Erik Paulson, Andrew Pavlo, and Alexander Rasin. Mapreduce and parallel dbmss: Friends or foes? Communications of the ACM, 53(1):64–71, 2010. ISSN 0001-0782. doi:http://doi.acm.org/10.1145/1629175.1629197. URL http://database.cs.brown.edu/papers/ stonebraker-cacm2010.pdf. K. Puschke (FU Berlin) NoSQL 13. September 2010 54 / 55
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Relationale Datenbanksysteme in der Theorie Codd (1970) [3] K. Puschke](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_8.jpg){kind=link}
![Relationale Datenbanksysteme in der Theorie Codd (1970) [3] Codd’s 12](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_9.jpg){kind=link}
![Relationale Datenbanksysteme in der Theorie Codd (1970) [3] Codd’s 12](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_10.jpg){kind=link}
![Relationale Datenbanksysteme in der Theorie Codd (1970) [3] Codd’s 12](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_11.jpg){kind=link}
![Relationale Datenbanksysteme in der Theorie Codd (1970) [3] Codd’s 12](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_12.jpg){kind=link}
![Relationale Datenbanksysteme in der Theorie Codd (1970) [3] Codd’s 12](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_13.jpg){kind=link}
![Relationale Datenbanksysteme in der Theorie Codd (1970) [3] Codd’s 12](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![NoSQL Begriffsklärung Ankündigung no:sql(eu) conference, April 2010 [11] . .](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_27.jpg){kind=link}
![NoSQL Begriffsklärung Ankündigung no:sql(eu) conference, April 2010 [11] . .](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_28.jpg){kind=link}
![NoSQL Begriffsklärung Ankündigung no:sql(eu) conference, April 2010 [11] . .](https://files.speakerdeck.com/presentations/c4d1a6a055f80130b56f12313815634b/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}