Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
intro_paper_0829.pdf
Search
MARUYAMA
August 28, 2017
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
intro_paper_0829.pdf
MARUYAMA
August 28, 2017
More Decks by MARUYAMA
See All by MARUYAMA
vampire.pdf
tmaru0204
0
200
Misspelling_Oblivious_Word_Embedding.pdf
tmaru0204
0
210
Simple_Unsupervised_Summarization_by_Contextual_Matching.pdf
tmaru0204
0
200
Controlling_Text_Complexity_in_Neural_Machine_Translation.pdf
tmaru0204
0
180
20191028_literature-review.pdf
tmaru0204
0
160
Hint-Based_Training_for_Non-Autoregressive_Machine_Translation.pdf
tmaru0204
0
150
Soft_Contextual_Data_Augmentation_for_Neural_Machine_Translation_.pdf
tmaru0204
0
180
An_Embarrassingly_Simple_Approach_for_Transfer_Learning_from_Pretrained_Language_Models_.pdf
tmaru0204
0
170
Addressing_Trobulesome_Words_in_Neural_Machine_Translation.pdf
tmaru0204
0
180
Featured
See All Featured
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
How GitHub (no longer) Works
holman
316
150k
Utilizing Notion as your number one productivity tool
mfonobong
4
420
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
340
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
New Earth Scene 8
popppiees
3
2.4k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Transcript
Exploring Neural Text Simplification Models S. Nisioi, S. Štajner, S.
P. Ponzetto, and L. P. Dinu Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pp. 85–91, 2017. B4 丸⼭ 拓海
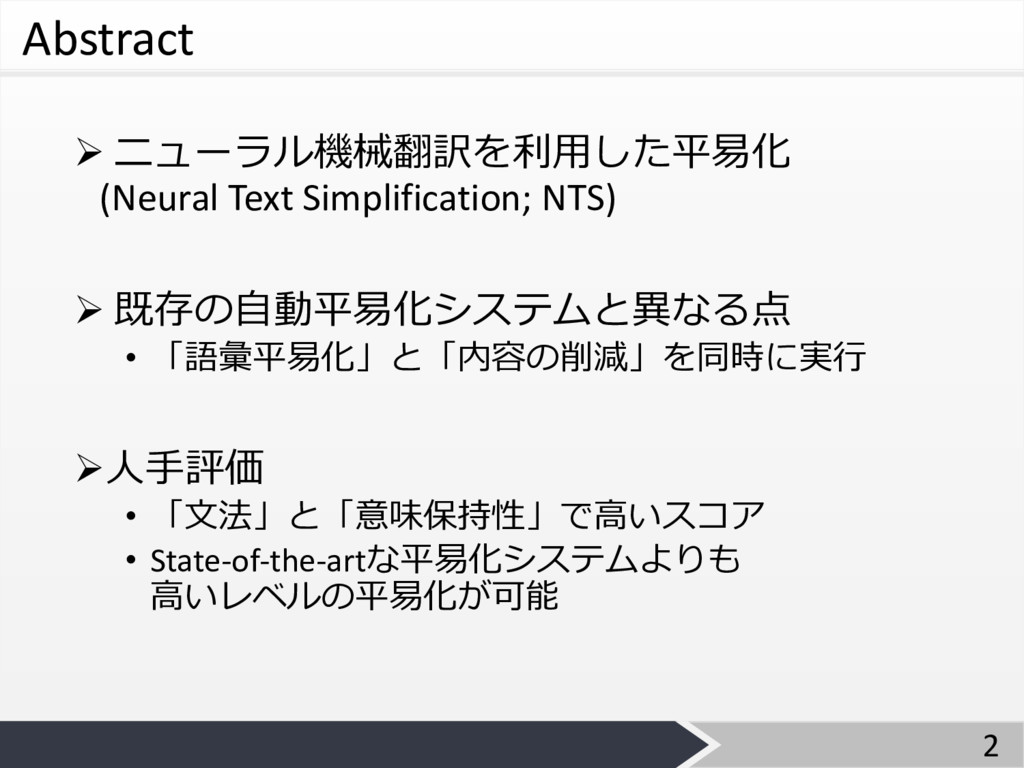
Abstract Ø ニューラル機械翻訳を利⽤した平易化 (Neural Text Simplification; NTS) Ø 既存の⾃動平易化システムと異なる点 •
「語彙平易化」と「内容の削減」を同時に実⾏ Ø⼈⼿評価 • 「⽂法」と「意味保持性」で⾼いスコア • State-of-the-artな平易化システムよりも ⾼いレベルの平易化が可能 2
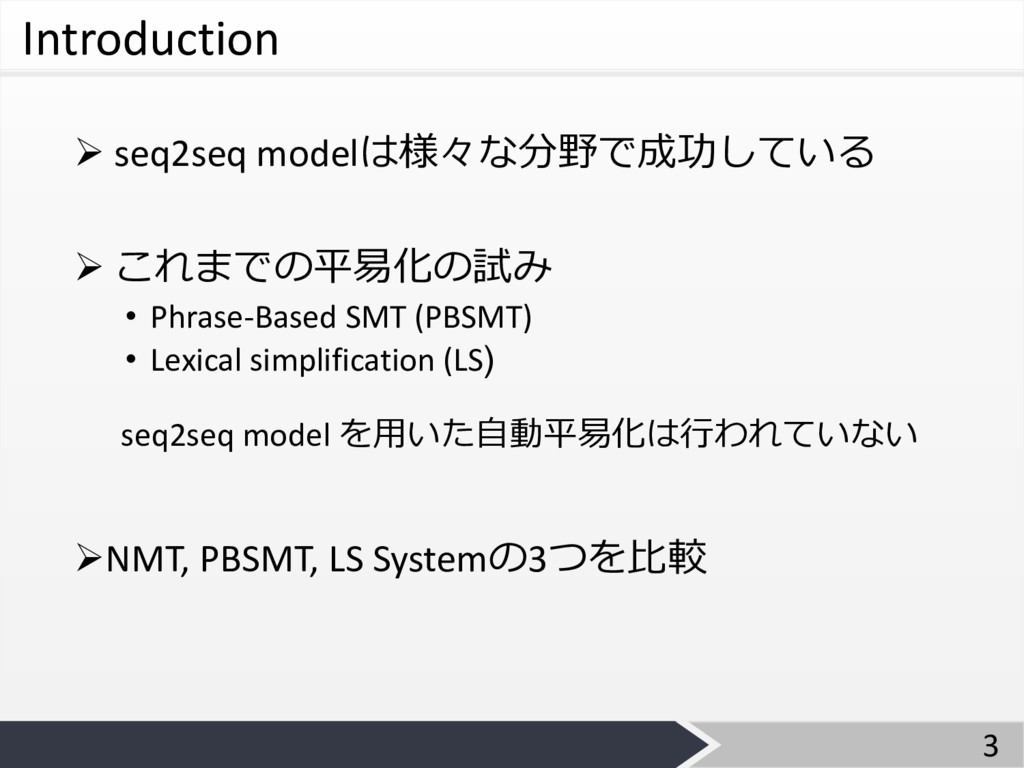
Introduction Ø seq2seq modelは様々な分野で成功している Ø これまでの平易化の試み • Phrase-Based SMT (PBSMT)
• Lexical simplification (LS) ØNMT, PBSMT, LS Systemの3つを⽐較 3 seq2seq model を⽤いた⾃動平易化は⾏われていない
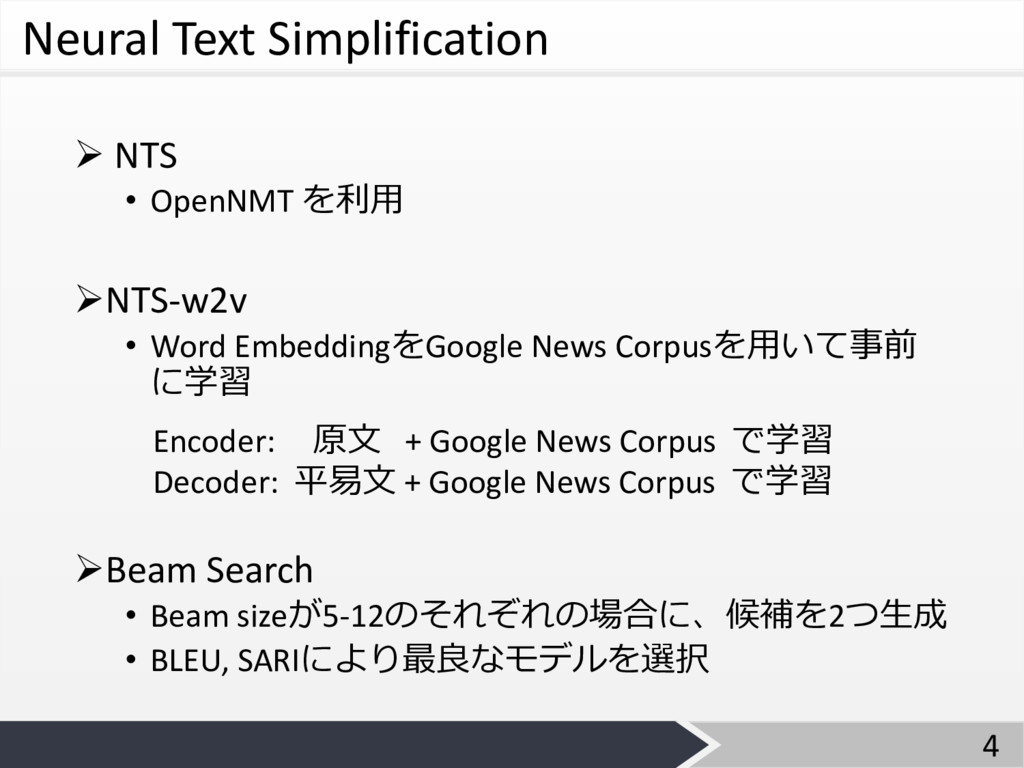
Neural Text Simplification Ø NTS • OpenNMT を利⽤ ØNTS-w2v •
Word EmbeddingをGoogle News Corpusを⽤いて事前 に学習 ØBeam Search • Beam sizeが5-12のそれぞれの場合に、候補を2つ⽣成 • BLEU, SARIにより最良なモデルを選択 4 Encoder: 原⽂ + Google News Corpus で学習 Decoder: 平易⽂ + Google News Corpus で学習
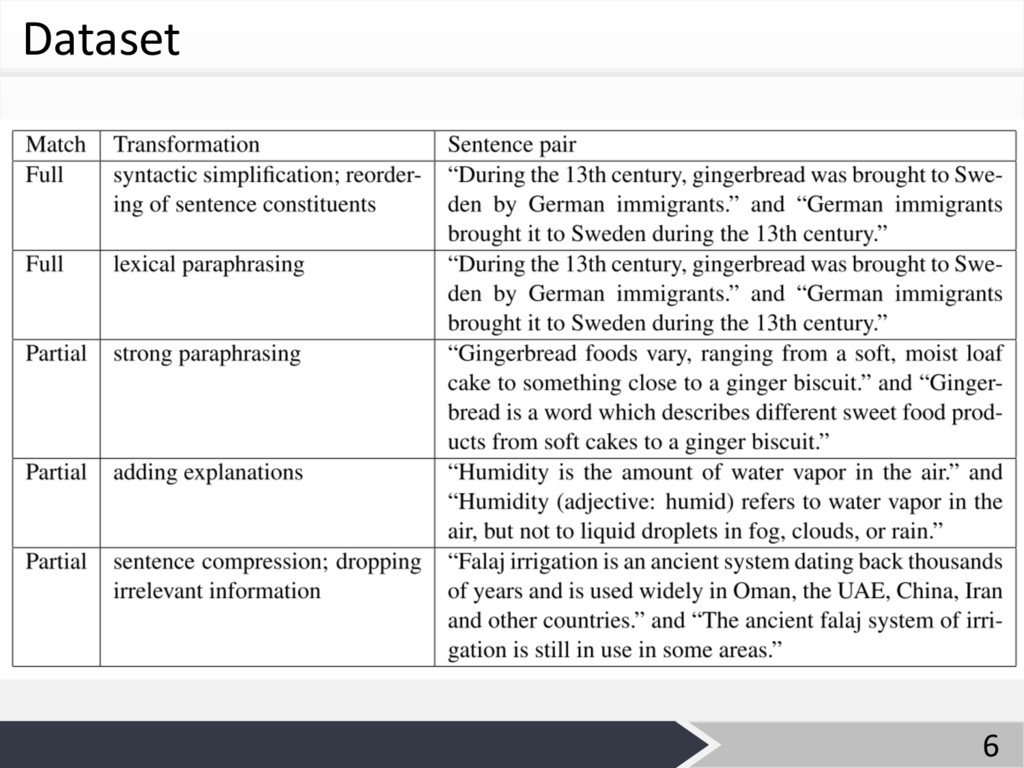
Dataset Ø Training data • English Wikipedia と Simple English
Wikipediaを対応付 けしたデータセット(EW-SEW dataset) • 適切に対応付いている280K⽂のみ利⽤ (150K full matches and 130K partial matches) • トークン数と固有表現 5
Dataset 6
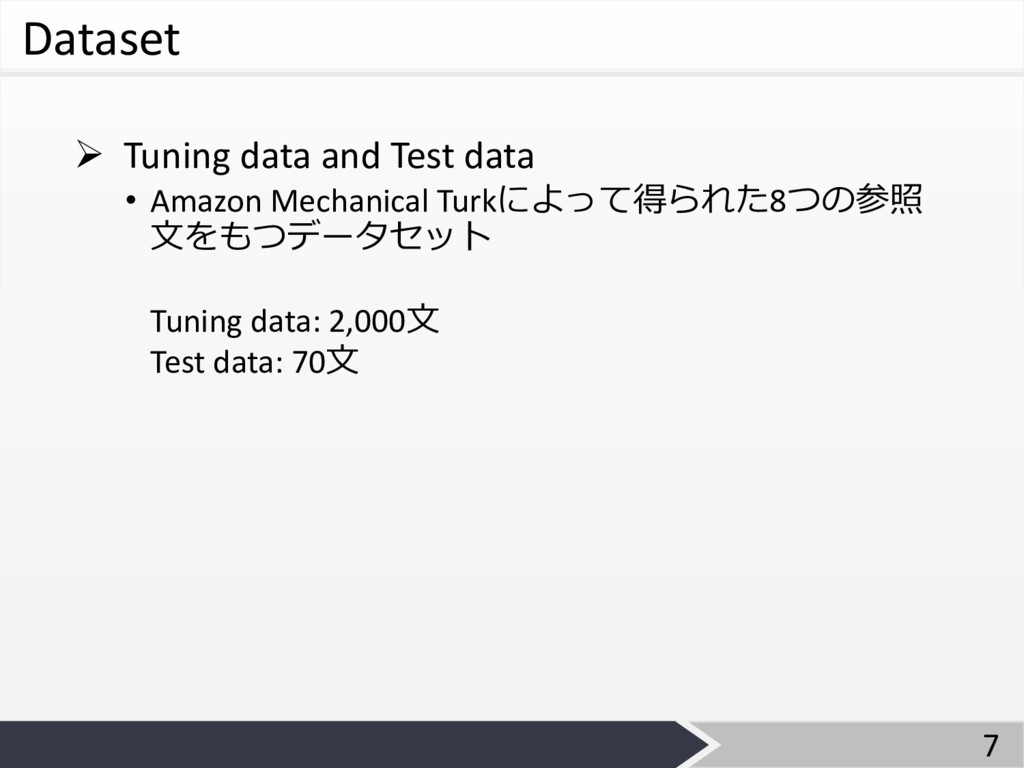
Dataset Ø Tuning data and Test data • Amazon Mechanical
Turkによって得られた8つの参照 ⽂をもつデータセット 7 Tuning data: 2,000⽂ Test data: 70⽂
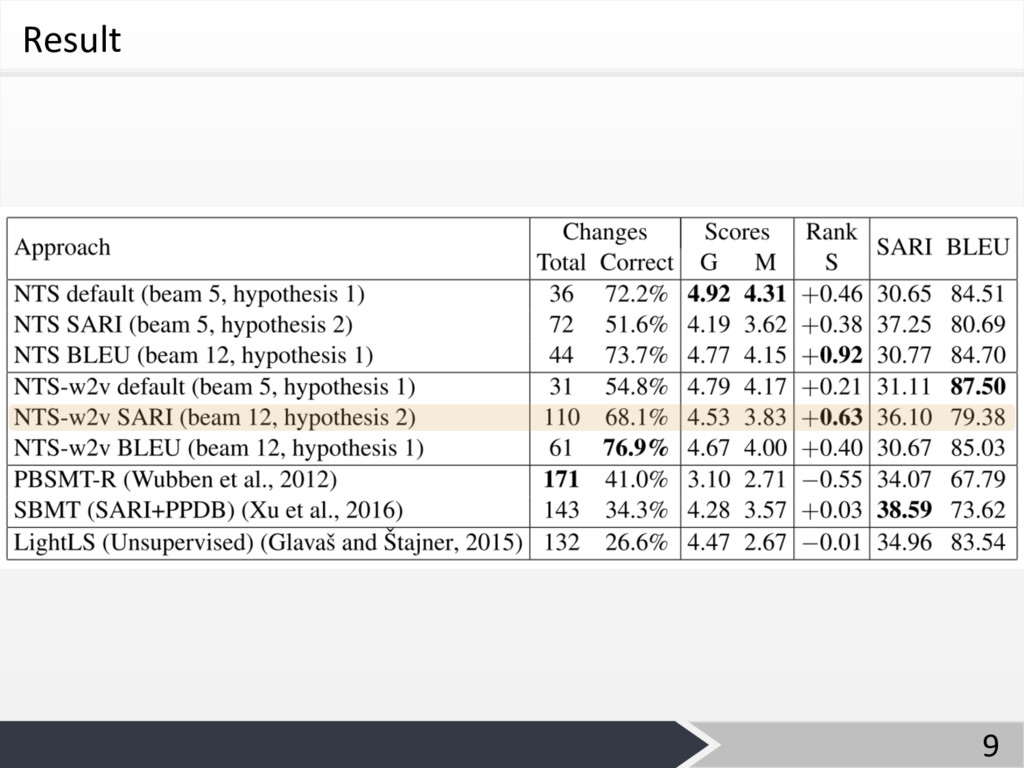
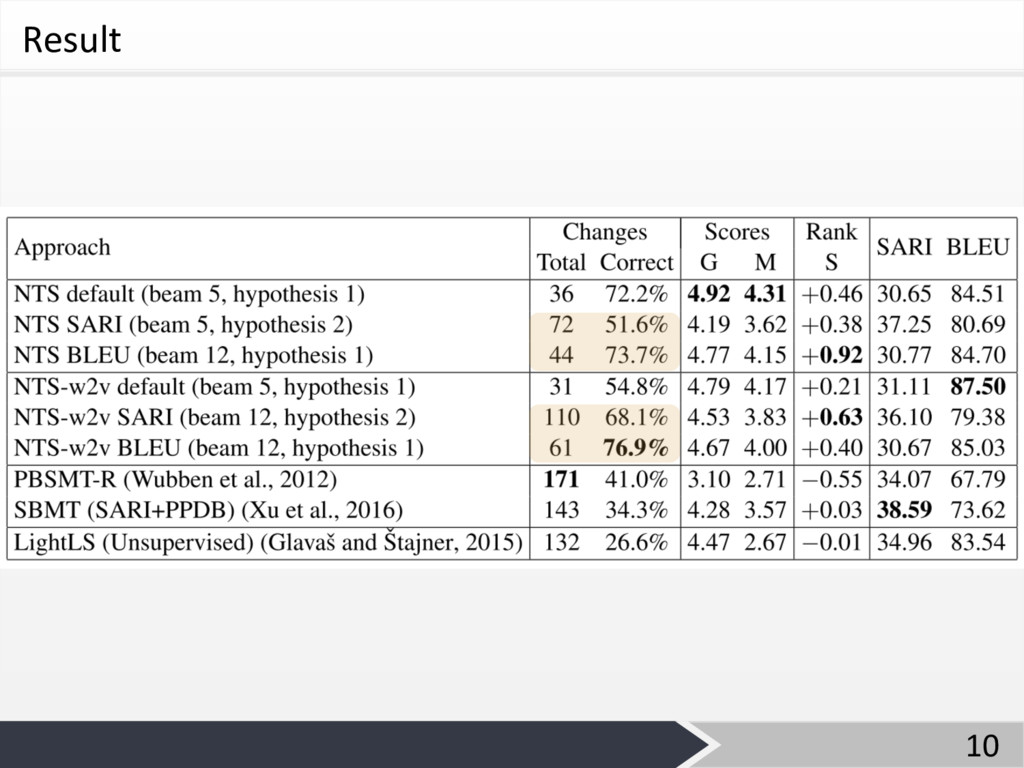
Evaluation Ø Human Evaluation • 70⽂を3⼈により評価に利⽤ − Correctness and Number
of Changes 句単位で「1つの変更」と数える − Grammaticality (G) and Meaning Preservation (M) 1 – 5の5段階でスコア付け 1: very bad 5: very good − Simplicity of sentences 平易化された度合いを -2 - +2の5段階で評価 -2: 参照⽂に⽐べ、より難しい⽂に変更されている +2: 参照⽂に⽐べ、より平易な⽂に変更されている 8
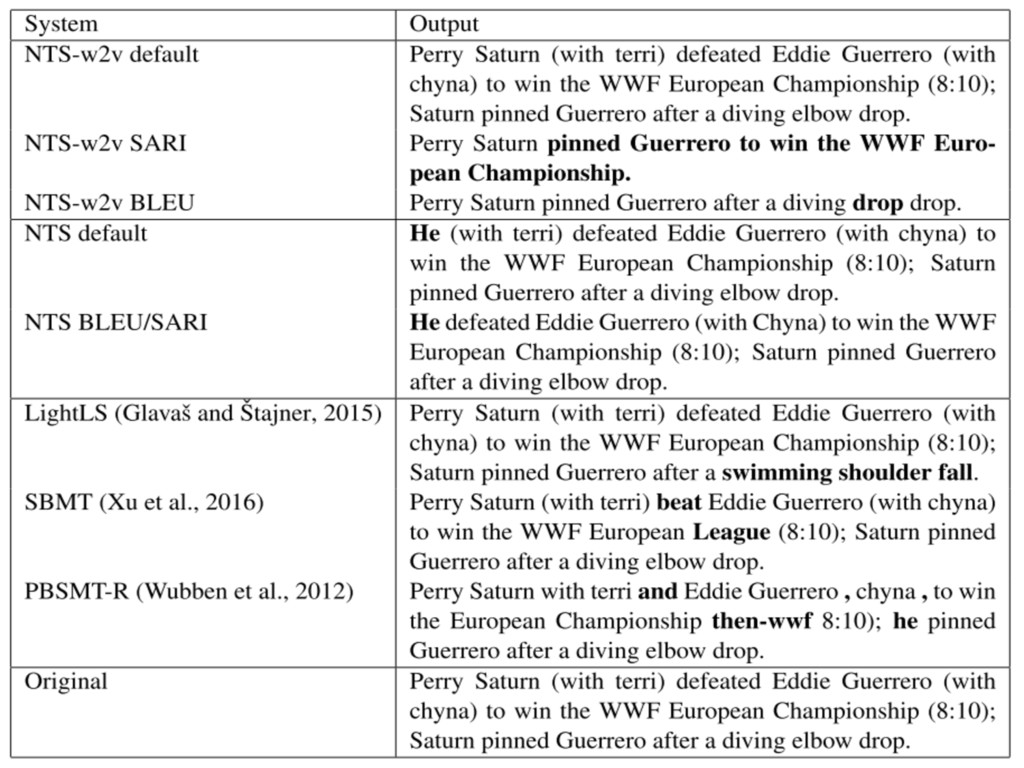
Result 9
Result 10
Conclusions Ø ニューラル機械翻訳を利⽤した平易化モデル の提案 Ø 既存のシステムよりも正確かつ平易に変換で きる Ø 「語彙平易化」と「内容の削減」を同時実⾏ 11
Result
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}