Conference on Empirical Methods in Natural Language Processing, 2017 pp. 584–594 Zhang Xingxing, Lapata Mirella Nagaoka University of Technology Takumi Maruyama
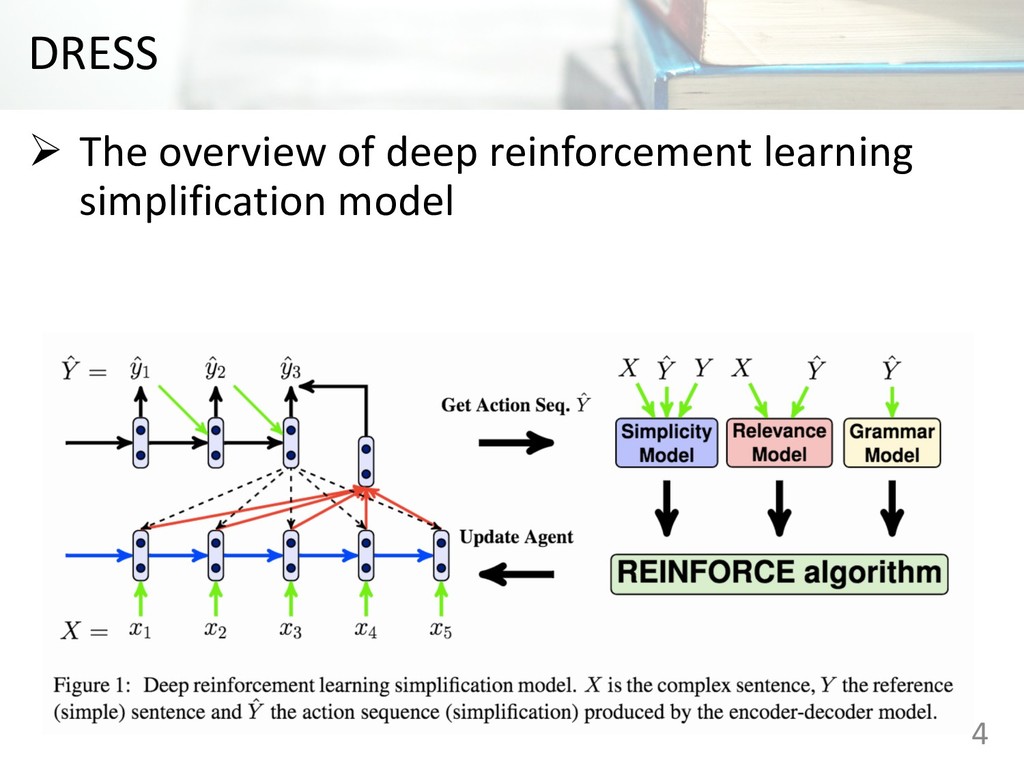
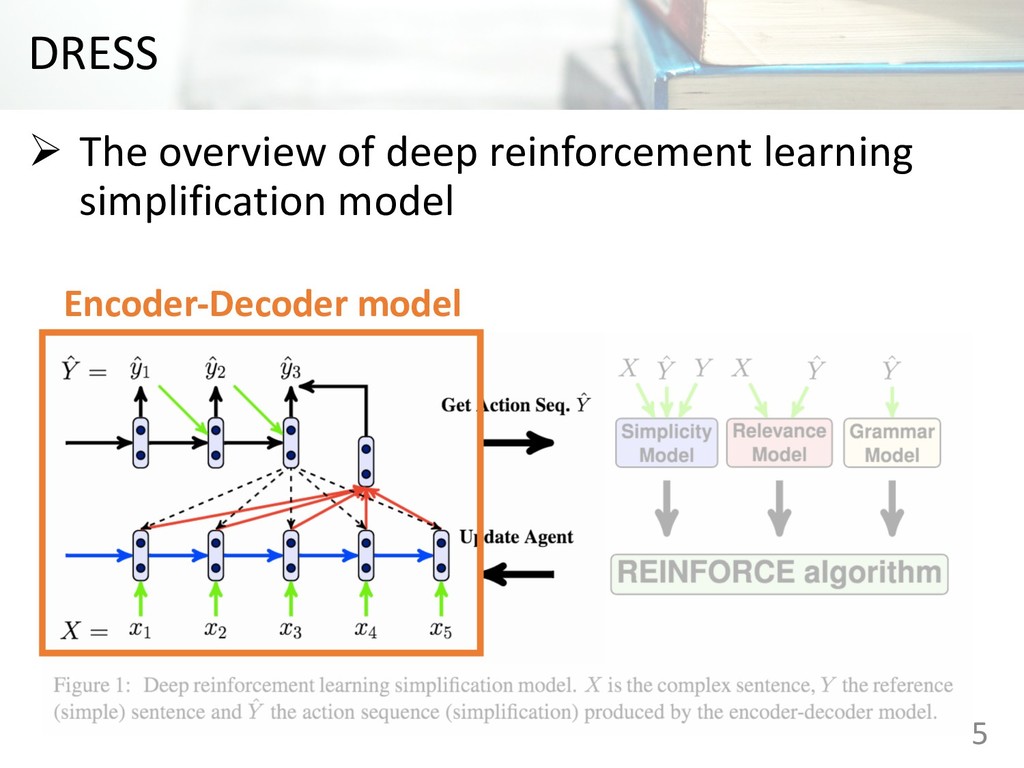
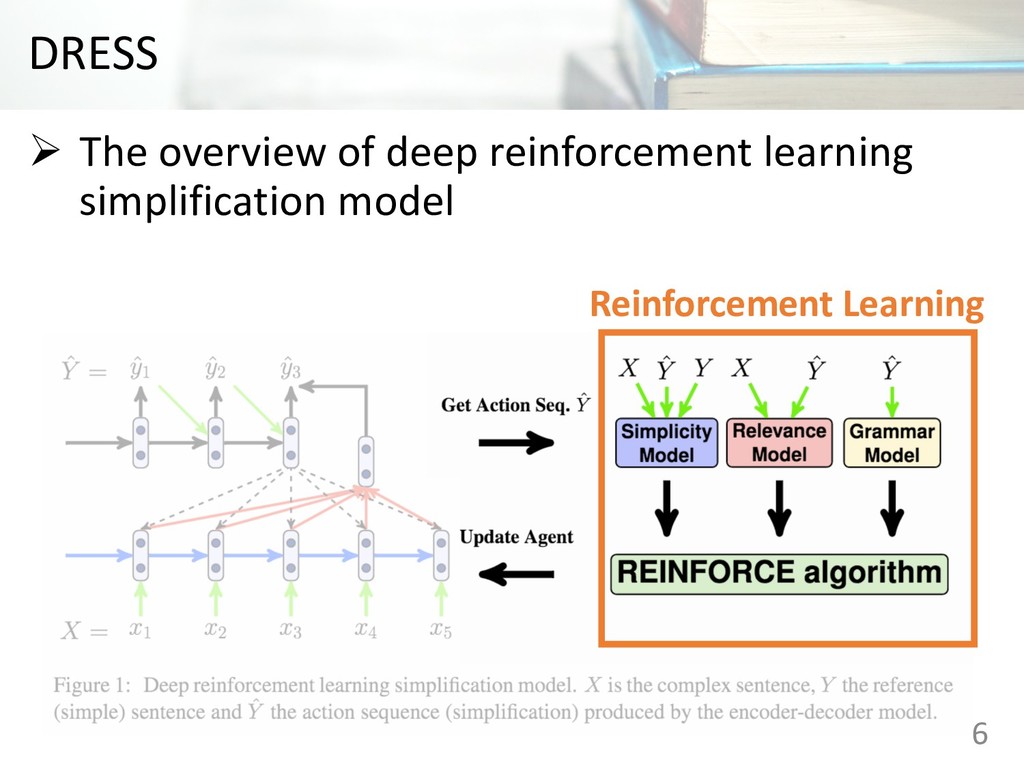
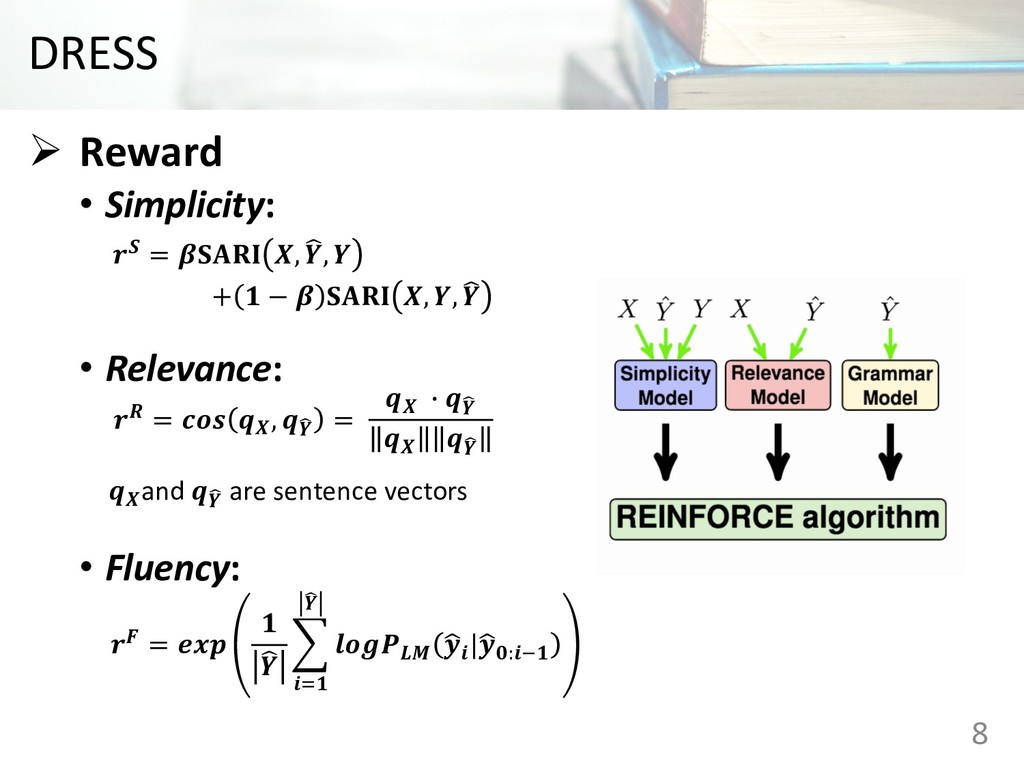
read and understand Ø This paper proposes encoder-decoder model coupled with a deep reinforcement learning frame work for text simplification Ø The proposed model outperforms competitive simplification systems on experiments. 2
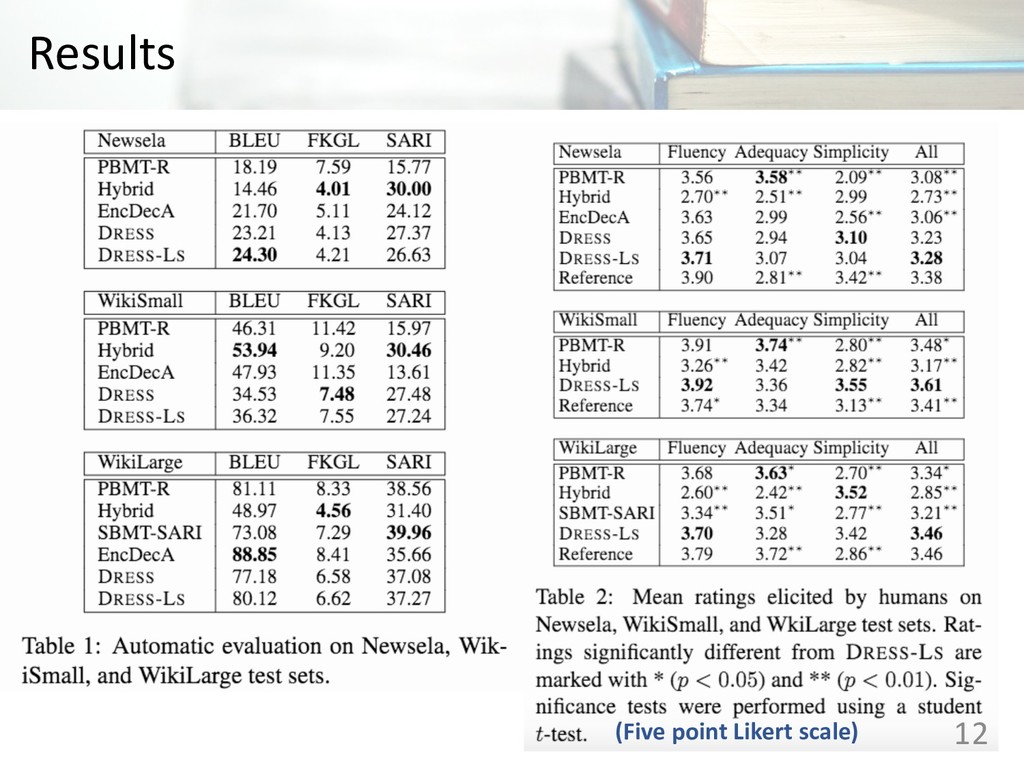
hybrid semantic-based model that combine simplification model and monolingual machine translation model • SBMT-SARI: A syntax-based translation model trained with PPDB and tuned with SARI A monolingual phrase base machine translation with a reranking post-processing step 11
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}